アマゾンケンドラ は、機械学習 (ML) を活用したインテリジェントな検索サービスです。 Amazon Kendra を使用すると、さまざまなコンテンツ リポジトリからコンテンツを一元化されたインデックスに簡単に集約できるため、すべての企業データをすばやく検索して最も正確な答えを見つけることができます。 Drupal コンテンツ管理ソフトウェアです。 私たちが毎日使用する多くの Web サイトやアプリケーションの作成に使用されています。 Drupal には、簡単なコンテンツ オーサリング、信頼性の高いパフォーマンス、セキュリティなどの優れた機能セットが備わっています。 多くの組織は Drupal を使用してコンテンツを保存しています。 Drupal を使用する多くの顧客にとって重要な要件の XNUMX つは、データ ソース内のすべてのドキュメントにわたって正確な情報を簡単かつ安全に見つけられる機能です。
Amazon Kendra Drupal コネクタを使用すると、Drupal コンテンツのインデックスを作成し、インデックスを作成するカスタムコンテンツのタイプをフィルタリングし、Amazon Kendra インテリジェント検索を使用して Drupal コンテンツを簡単に検索できます。
この投稿では、Amazon Kendra Drupal コネクタを使用して、Amazon Kendra インデックスのデータソースとしてコネクタを設定し、Drupal ドキュメントを検索する方法を説明します。 Drupal コネクタの構成に基づいて、コネクタを同期して、ブログや Wiki などのさまざまな種類の Drupal コンテンツをクロールし、インデックスを付けることができます。 コネクタは、各ファイルのアクセス制御リスト (ACL) 情報も取り込みます。 ACL 情報は次の目的で使用されます。 ユーザーコンテキストフィルタリング、クエリの検索結果は、ユーザーがアクセスを許可されているものによってフィルターされます。
前提条件
この投稿を参考にして Drupal 用の Amazon Kendra コネクタを試すには、以下が必要です。

Drupal 用の Amazon Kendra コネクタを使用してデータ ソースを設定する
Drupal コネクタを使用して Amazon Kendra インデックスにデータソースを追加するには、既存のインデックスを使用するか、 新しいインデックスを作成する. 次に、次の手順を完了します。 このトピックの詳細については、 AmazonKendra開発者ガイド.
- Amazon Kendraコンソールで、インデックスを開き、[ データソース ナビゲーションペインに表示されます。
- 選択する データソースを追加する.
- Drupal、選択する コネクタを追加.

- データソースの詳細を指定する セクションで、名前と説明を入力し、 Next.
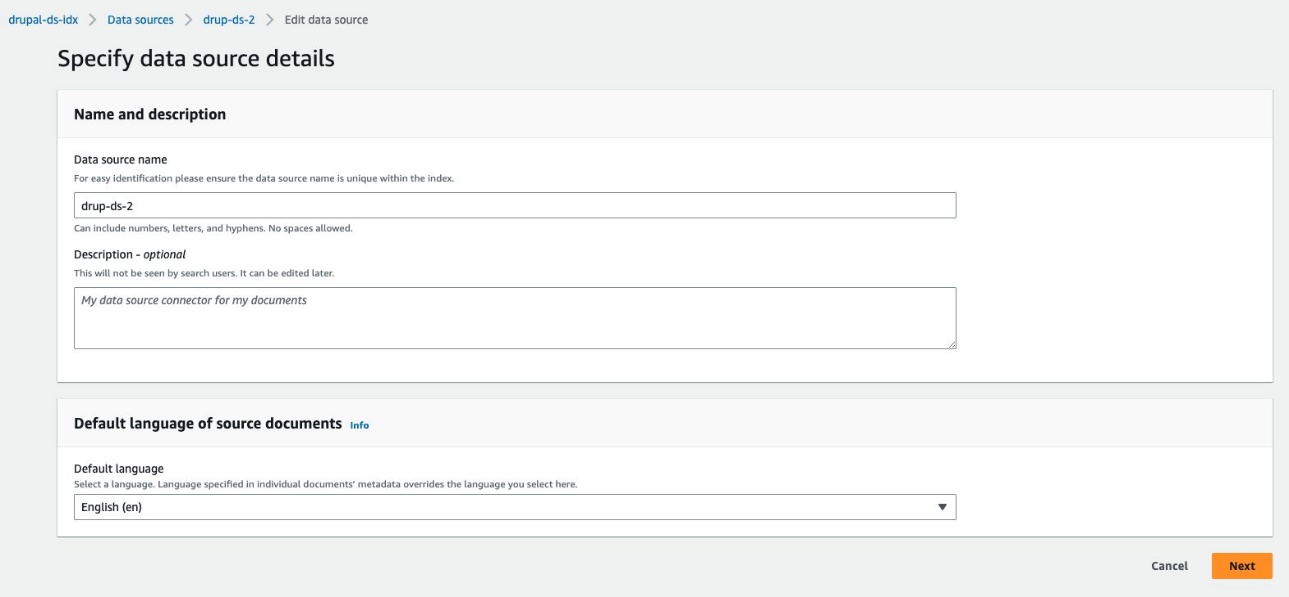
- ソフトウェア設定ページで、下図のように アクセスとセキュリティを定義する セクション、 Drupal ホスト URL、Drupal サイトの URL を入力します。
- SSL 証明書を構成するには、次のコマンドを使用して、このセットアップ用の自己署名証明書を作成できます。
openssl x509 -in mydrupalsite.pem -out drupal.crtコマンドを実行し、証明書を Amazon シンプル ストレージ サービス (Amazon S3) バケット。 秘密キーと証明書の生成の詳細については、を参照してください。 証明書の生成. - 選択する S3を参照 SSL 証明書を含む S3 バケットを選択します。
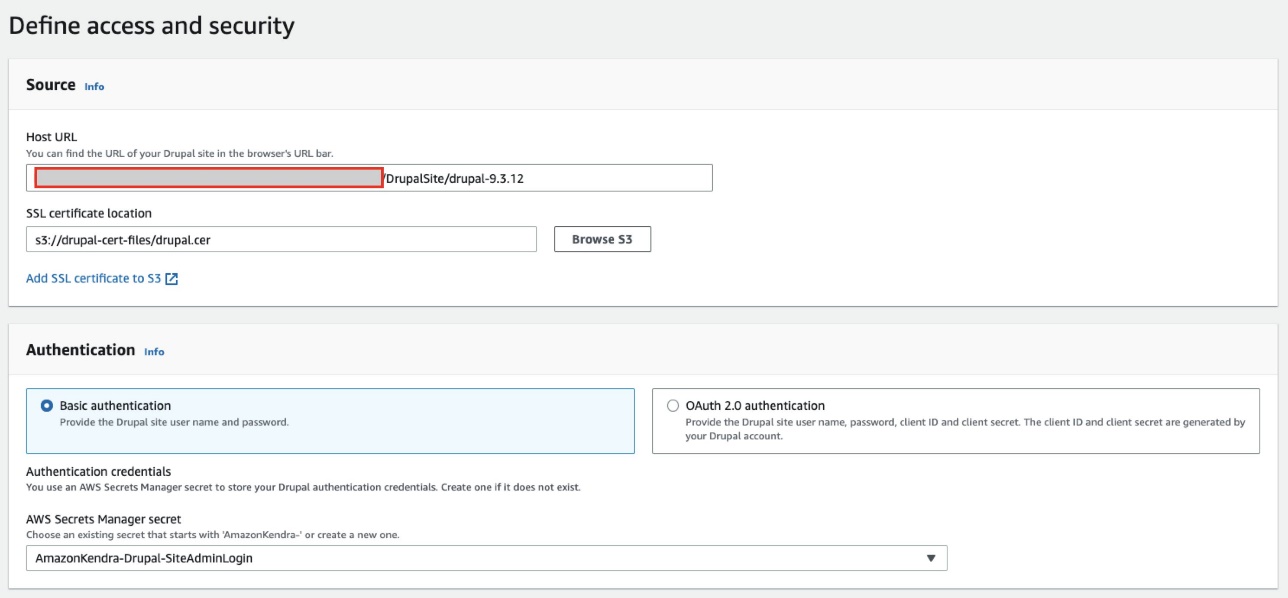
- 認証、次の2つのオプションがあります。
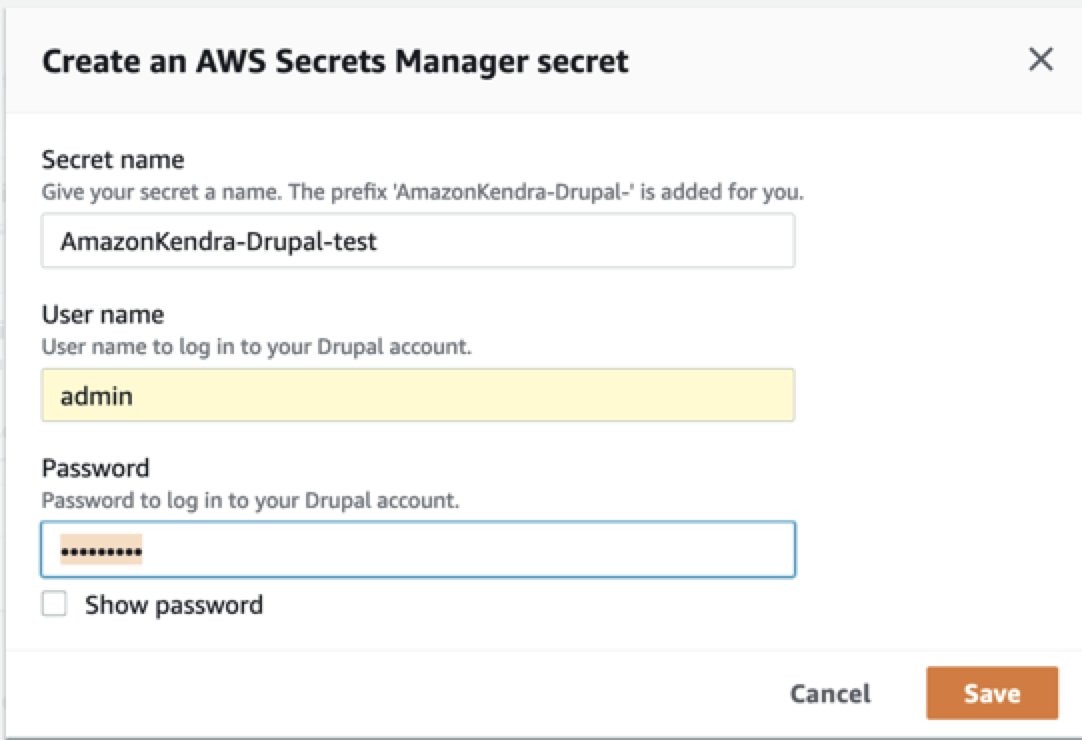
- Secrets Manager を使用して、新しい Drupal 認証資格情報を作成します。 Drupal 管理者のユーザー名とパスワードが必要です (さらに、OAuth 2.0 認証用のクライアント ID とクライアント シークレット)。
- コネクタにアクセスさせる Drupal 認証資格情報 (さらに、OAuth 2.0 認証のクライアント ID とクライアント シークレット) を持つ既存の Secrets Manager シークレットを使用します。
- 選択する シークレットを保存して追加.
- IAMの役割、選択する 新しい役割を作成する または、適切なIAMポリシーで構成された既存のIAMロールを選択して、Secrets Managerシークレット、Amazon Kendraインデックス、およびデータソースにアクセスします。
参照する データソースのIAMロール IAM ロールに必要な権限については。
- 選択する Next.

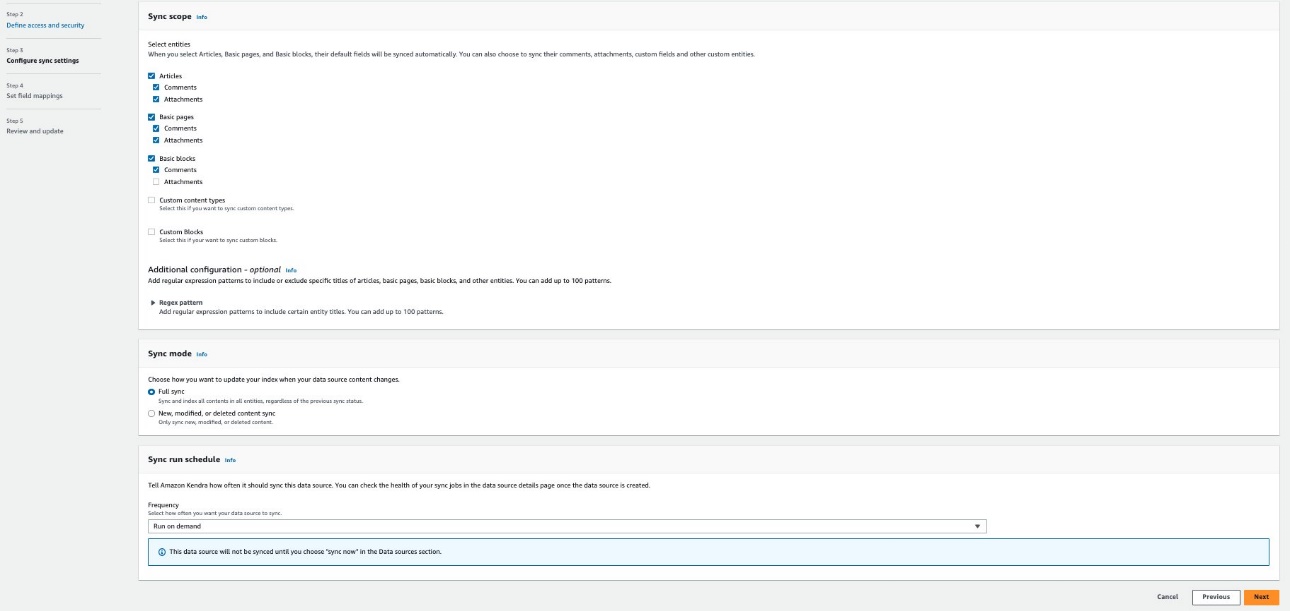
- 同期設定を構成する セクション、選択 記事一覧, 基本ページ, 基本ブロック, カスタムコンテンツタイプ, カスタムブロック 必要に応じてコメントや添付ファイルをクロールするオプションも含まれます。
- 必要に応じて、エンティティ タイトルの包含/除外パターンを入力します。
- 同期範囲 (フルまたはデルタのみ) に関する情報を入力し、実行スケジュールを指定します。
- 選択する Next.

- フィールドマッピングを設定する セクションで、同期するカスタム Drupal フィールドとそれぞれの Amazon Kendra フィールド マッピングを追加します。 必須フィールドは Amazon Kendra によって事前にマップされています。
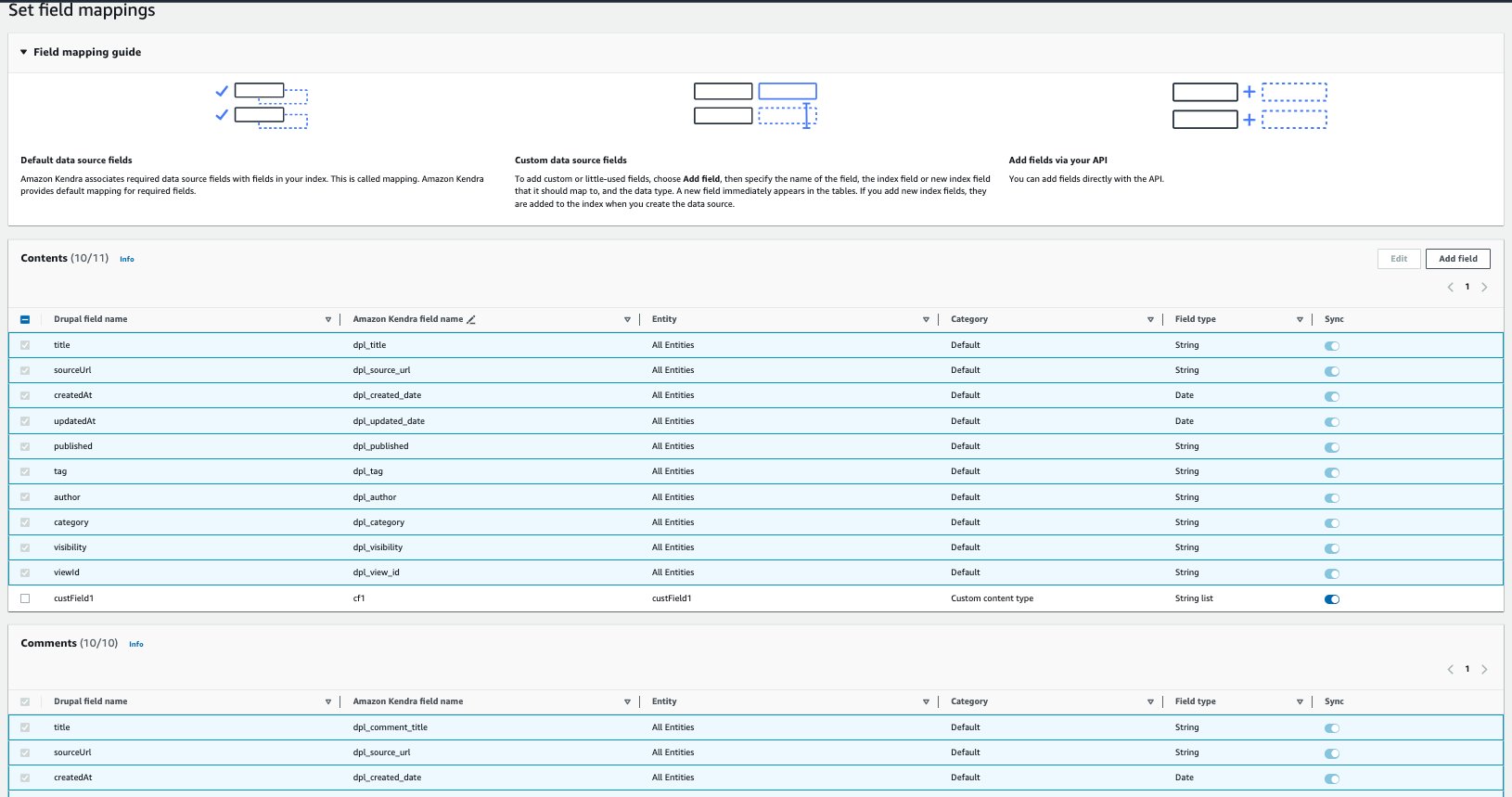
- 選択する Next.
- 構成設定を確認し、データ ソースを保存します。
- 選択する 今すぐ同期 作成されたデータソース上で Amazon Kendra Index とのデータ同期を開始します。
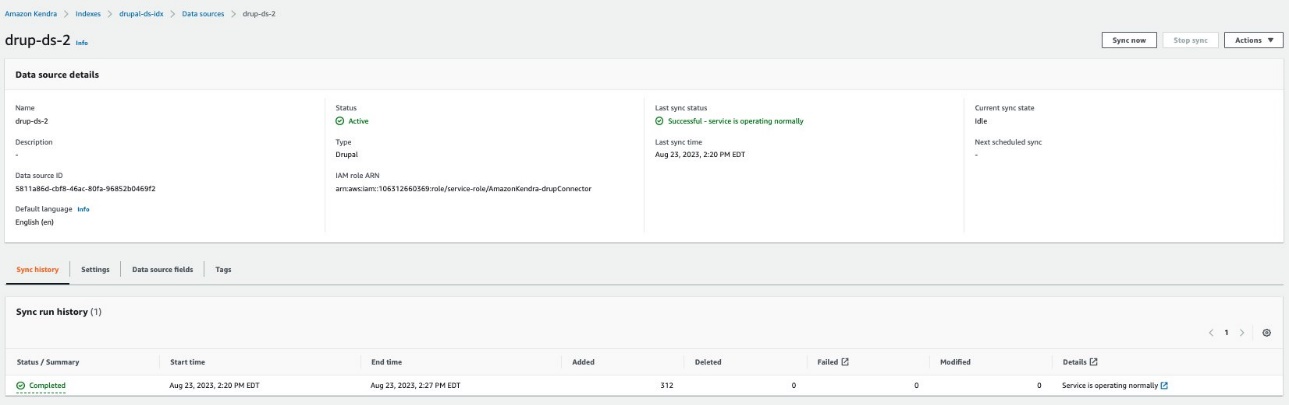
コンテンツをクロールして Amazon Kendra に同期するのに必要な時間は、コンテンツの量とスループットによって異なります。

Search Console または検索アプリケーションを使用して、インデックス付けされた Drupal コンテンツを検索できるようになりました。 必要に応じて、次の追加手順を使用して ACL を使用して検索できます。
- 作成したインデックス ページに移動し、 ユーザーアクセス制御lタブで選択します 編集の設定.

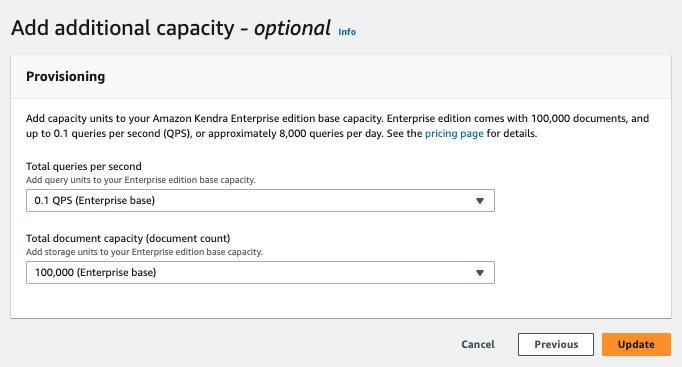
- アクセス制御設定選択 はい、デフォルト値をそのままにしておきます。 および グループ、選択する JSONの for トークンタイプ、ユーザーグループの展開を次のように維持します なし.
- 次のページで、デフォルト値を保持し (または容量要件に基づいて値を変更し)、 アップデイト.
AmazonKendraでインテリジェントな検索を実行する
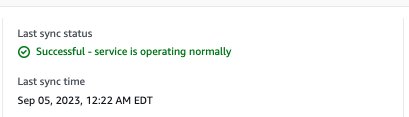
Amazon Kendraコンソールで検索するかAPIを使用する前に、データソースの同期が完了していることを確認してください。 確認するには、データソースを表示し、最後の同期が成功したかどうかを確認します。
- 検索を開始するには、AmazonKendraコンソールで次を選択します インデックス付きコンテンツを検索 ナビゲーションペインに表示されます。
Amazon Kendra 検索コンソールにリダイレクトされます。 Amazon Kendra を使用してインデックスを作成した Drupal ドキュメントから情報を検索できるようになりました。
- この投稿では、Drupal データ ソースに保存されているドキュメントを検索します。
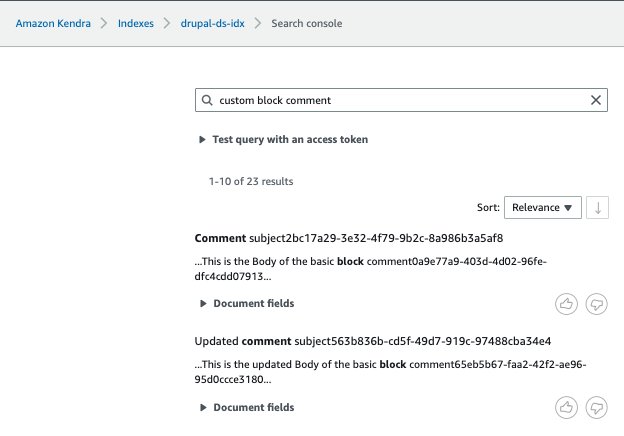
- 詳細 アクセストークンを使用してクエリをテストする 選択して トークンを適用する.
- 、Drupal アカウントに関連付けられているメール アドレスを入力します。
- 選択する 申し込む.
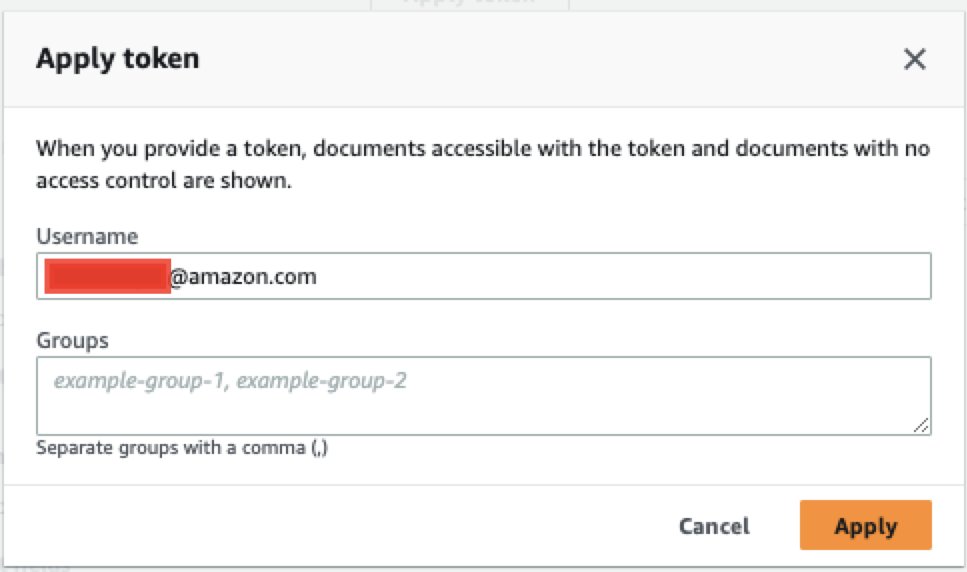
これで、ユーザーは、指定されたユーザー名またはグループに基づいてアクセス権のあるコンテンツのみを表示できるようになります。 この例では、Drupal ユーザーは、 [email protected] email は Drupal 上のどのドキュメントにもアクセスできないため、何も表示されません。

制限事項
このソリューションを使用する場合は、次の制限事項に注意してください。
- どのビューにも関連付けられていないコンテンツ タイプ (記事、基本ページなど) はクロールできません。
- 管理者がブロックにアクセスできない場合、ブロックからデータをクロールすることはできません。
- 記事、基本ページ、基本ブロック、ユーザー定義コンテンツタイプ、ユーザー定義ブロックタイプの文書本文がHTML形式で表示されます。 HTML コンテンツが整形式でない場合、HTML 関連のタグがドキュメント本文に表示されるため、Amazon Kendra の検索結果に表示されます。 記事のコメント、基本ページ、基本ブロック、ユーザー定義コンテンツタイプ、ユーザー定義ブロックタイプも同様です。
- Amazon Kendra SDK 側で検証があるため、説明や本文のないコンテンツ タイプまたはブロック タイプは Amazon Kendra インデックスに挿入されません。 ただし、Drupal では、説明や本文なしでコンテンツ タイプを作成できます。 それぞれのコンテンツタイプまたはブロックタイプ (存在する場合) のコメントと添付ファイルのみが Amazon Kendra インデックスに挿入されます。
クリーンアップ
将来のコストの発生を避けるために、このソリューションの一部として作成したリソースをクリーンアップしてください。 このソリューションのテスト中に新しい Amazon Kendra インデックスを作成した場合は、それを削除します。 Drupal 用の Amazon Kendra コネクタを使用して新しいデータ ソースを追加しただけの場合は、そのデータ ソースを削除します。 作成した IAM ユーザーをすべて削除します。
まとめ
Amazon Kendra Drupal コネクタを使用すると、組織は Amazon Kendra によるインテリジェントな検索を使用して、Drupal サイトに保存されているコンテンツを安全に検索できます。 この投稿では統合について紹介しましたが、次のような追加機能については説明しませんでした。
- 追加のフィールドを Amazon Kendra インデックス属性にマッピングし、それらをファセット、検索、および検索結果に表示できるようにすることができます
- Drupal データソースを Amazon Kendra の Custom Document Enrichment (CDE) 機能と統合して、追加の属性マッピング ロジックを実行したり、取り込み中にカスタム コンテンツ変換を実行したりできます。
Drupal の可能性について詳しくは、「 AmazonKendra開発者ガイド.
一般的なデータソース用の他の Amazon Kendra 組み込みコネクタの詳細については、を参照してください。 Amazon Kendra コネクタ ページで見やすくするために変数を解析したりすることができます。
著者について
 チャンナ・バシャバラジャ AWS のシニア ソリューション アーキテクトであり、分散ビジネス ソリューションの構築に 2 年以上の経験があります。 彼の専門分野は、機械学習、アプリ/モバイル開発、イベント駆動型アーキテクチャ、IoT/エッジ コンピューティングに及びます。
チャンナ・バシャバラジャ AWS のシニア ソリューション アーキテクトであり、分散ビジネス ソリューションの構築に 2 年以上の経験があります。 彼の専門分野は、機械学習、アプリ/モバイル開発、イベント駆動型アーキテクチャ、IoT/エッジ コンピューティングに及びます。
 王元華 は AWS のソフトウェア エンジニアであり、テクノロジー業界で 15 年以上の経験があります。 彼の興味はソフトウェア アーキテクチャとクラウド コンピューティング上のツールの構築です。
王元華 は AWS のソフトウェア エンジニアであり、テクノロジー業界で 15 年以上の経験があります。 彼の興味はソフトウェア アーキテクチャとクラウド コンピューティング上のツールの構築です。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/intelligently-search-drupal-content-using-amazon-kendra/

