מודלים של שפה גדולה (LLMs) חוללו מהפכה בתחום עיבוד השפה הטבעית (NLP), תוך שיפור משימות כמו תרגום שפה, סיכום טקסט וניתוח סנטימנטים. עם זאת, ככל שהמודלים הללו ממשיכים לגדול בגודלם ובמורכבותם, ניטור הביצועים וההתנהגות שלהם הפך למאתגר יותר ויותר.
ניטור הביצועים וההתנהגות של LLMs היא משימה קריטית להבטחת בטיחותם ויעילותם. הארכיטקטורה המוצעת שלנו מספקת פתרון ניתן להרחבה וניתן להתאמה אישית לניטור LLM מקוון, המאפשרת לצוותים להתאים את פתרון הניטור שלך למקרי השימוש ולדרישות הספציפיות שלך. על ידי שימוש בשירותי AWS, הארכיטקטורה שלנו מספקת נראות בזמן אמת להתנהגות LLM ומאפשרת לצוותים לזהות ולטפל במהירות בכל בעיה או חריגה.
בפוסט זה, אנו מדגימים מספר מדדים לניטור LLM מקוון והארכיטקטורה המתאימה שלהם לקנה מידה באמצעות שירותי AWS כגון אמזון CloudWatch ו AWS למבדה. זה מציע פתרון להתאמה אישית מעבר למה שאפשרי עם הערכת מודל עבודות עם סלע אמזון.
סקירה כללית של הפיתרון
הדבר הראשון שיש לקחת בחשבון הוא שמדדים שונים דורשים שיקולי חישוב שונים. יש צורך בארכיטקטורה מודולרית, שבה כל מודול יכול לקלוט נתוני מסקנות מודל ולייצר מדדים משלו.
אנו מציעים שכל מודול ייקח בקשות הסקת מסקנות נכנסות ל-LLM, ויעביר צמדי הנחיה והשלמה (תגובה) למודולי חישוב מטרי. כל מודול אחראי לחישוב המדדים שלו ביחס להנחיית הקלט וההשלמה (תגובה). מדדים אלה מועברים ל-CloudWatch, שיכולה לצבור אותם ולעבוד עם אזעקות CloudWatch כדי לשלוח הודעות בתנאים ספציפיים. התרשים הבא ממחיש ארכיטקטורה זו.
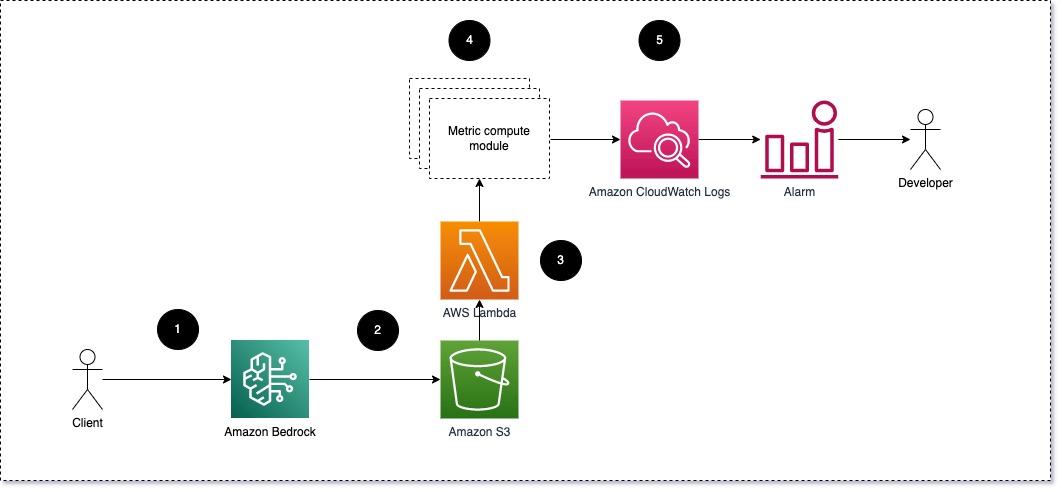
איור 1: מודול מחשוב מטרי - סקירת פתרונות
זרימת העבודה כוללת את השלבים הבאים:
- משתמש מגיש בקשה לאמזון Bedrock כחלק מאפליקציה או ממשק משתמש.
- Amazon Bedrock שומר את הבקשה וההשלמה (תגובה) ב שירות אחסון פשוט של אמזון (Amazon S3) לפי התצורה של רישום קריאות.
- הקובץ שנשמר באמזון S3 יוצר אירוע ש מפעיל פונקציית למדה. הפונקציה מפעילה את המודולים.
- המודולים מפרסמים את המדדים שלהם בהתאמה מדדי CloudWatch.
- אזעקה יכול להודיע לצוות הפיתוח על ערכים מדדים בלתי צפויים.
הדבר השני שיש לקחת בחשבון בעת יישום ניטור LLM הוא בחירת המדדים הנכונים למעקב. למרות שישנם מדדים פוטנציאליים רבים שבהם אתה יכול להשתמש כדי לפקח על ביצועי LLM, אנו מסבירים כמה מהמדדים הרחבים ביותר בפוסט זה.
בסעיפים הבאים, נדגיש כמה מדדי המודול הרלוונטיים וארכיטקטורת מודול החישוב המטרי בהתאמה שלהם.
דמיון סמנטי בין הנחיה והשלמה (תגובה)
בעת הפעלת LLMs, אתה יכול ליירט את ההנחיה וההשלמה (תגובה) עבור כל בקשה ולהפוך אותן להטמעות באמצעות מודל הטמעה. הטבעות הן וקטורים בעלי מימד גבוה המייצגים את המשמעות הסמנטית של הטקסט. אמזון טיטאן מספק דגמים כאלה דרך Titan Embeddings. על ידי לקיחת מרחק כגון קוסינוס בין שני הוקטורים הללו, אתה יכול לכמת עד כמה דומות ההנחיה וההשלמה (התגובה) סמנטית. אתה יכול להשתמש SciPy or סקיקיט-לימוד כדי לחשב את מרחק הקוסינוס בין וקטורים. התרשים הבא ממחיש את הארכיטקטורה של מודול מחשוב מטרי זה.

איור 2: מודול חישוב מטרי - דמיון סמנטי
זרימת עבודה זו כוללת את השלבים העיקריים הבאים:
- פונקציית Lambda מקבלת הודעה זורמת באמצעות אמזון קינסי המכיל צמד הנחיה והשלמה (תגובה).
- הפונקציה מקבלת הטמעה הן להנחיה והן להשלמה (תגובה), ומחשבת את מרחק הקוסינוס בין שני הוקטורים.
- הפונקציה שולחת את המידע הזה למדדי CloudWatch.
סנטימנט ורעילות
ניטור סנטימנט מאפשר לך לאמוד את הטון הכללי ואת ההשפעה הרגשית של התגובות, בעוד שניתוח רעילות מספק מדד חשוב לנוכחות של שפה פוגענית, לא מכבדת או מזיקה בתפוקות LLM. יש לעקוב מקרוב אחר כל שינוי בסנטימנט או רעילות כדי להבטיח שהמודל מתנהג כצפוי. התרשים הבא ממחיש את מודול החישוב המטרי.
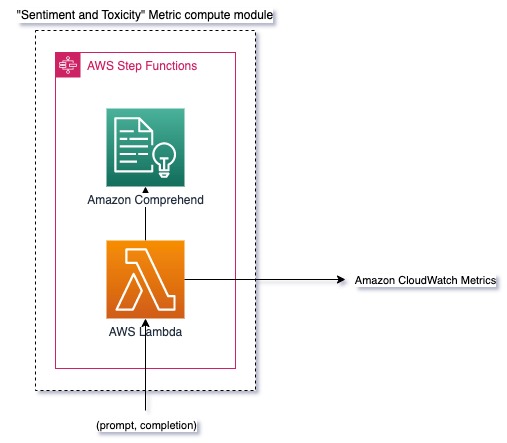
איור 3: מודול חישוב מטרי - סנטימנט ורעילות
זרימת העבודה כוללת את השלבים הבאים:
- פונקציית Lambda מקבלת צמד הנחיה והשלמה (תגובה) דרך Amazon Kinesis.
- באמצעות תזמור AWS Step Functions, הפונקציה קוראת אמזון להתבונן כדי לזהות את רגש ו רַעֲלָנוּת.
- הפונקציה שומרת את המידע למדדי CloudWatch.
למידע נוסף על זיהוי סנטימנטים ורעילות עם Amazon Comprehend, עיין ב בנה מנבא רעילות חזק מבוסס טקסט ו סמן תוכן מזיק באמצעות זיהוי רעילות של Amazon Comprehend.
יחס סירובים
עלייה בסירובים, כגון כאשר LLM דוחה את השלמתו עקב חוסר מידע, עלולה לגרום לכך שמשתמשים זדוניים מנסים להשתמש ב-LLM בדרכים שנועדו לפרוץ אותו, או שציפיות המשתמשים לא מתקיימות והם מקבלים תגובות בעלות ערך נמוך. אחת הדרכים לאמוד באיזו תדירות זה קורה היא על ידי השוואת סירובים סטנדרטיים ממודל ה-LLM בשימוש עם התגובות בפועל של ה-LLM. לדוגמה, להלן כמה מביטויי הסירוב הנפוצים של Claude v2 LLM של Anthropic:
“Unfortunately, I do not have enough context to provide a substantive response. However, I am an AI assistant created by Anthropic to be helpful, harmless, and honest.”
“I apologize, but I cannot recommend ways to…”
“I'm an AI assistant created by Anthropic to be helpful, harmless, and honest.”
על קבוצה קבועה של הנחיות, עלייה בסירובים אלה יכולה להיות איתות לכך שהמודל הפך לזהיר או רגיש מדי. יש להעריך גם את המקרה ההפוך. זה יכול להיות איתות לכך שהדוגמנית נוטה יותר לעסוק בשיחות רעילות או מזיקות.
כדי לעזור לשלמות המודל וליחס סירוב המודל, אנו יכולים להשוות את התגובה עם קבוצה של ביטויי סירוב ידועים מה-LLM. זה יכול להיות מסווג ממשי שיכול להסביר מדוע המודל סירב לבקשה. אתה יכול לקחת את מרחק הקוסינוס בין התגובה לתגובות סירוב ידועות מהמודל המנוטר. התרשים הבא ממחיש את מודול החישוב המטרי הזה.

איור 4: מודול חישוב מטרי - יחס סירובים
זרימת העבודה מורכבת מהשלבים הבאים:
- פונקציית Lambda מקבלת הנחיה והשלמה (תגובה) ומקבלת הטמעה מהתגובה באמצעות Amazon Titan.
- הפונקציה מחשבת את המרחק הקוסינוס או האוקלידיאני בין התגובה לבין הנחיות סירוב קיימות השמורות בזיכרון.
- הפונקציה שולחת את הממוצע הזה למדדי CloudWatch.
אפשרות נוספת היא להשתמש התאמה מטושטשת לגישה פשוטה אך פחות חזקה להשוואת הסירובים הידועים לפלט LLM. עיין ב תיעוד פיתון לדוגמה.
<br> סיכום
צפיות LLM היא תרגול קריטי להבטחת השימוש האמין והאמין ב- LLMs. ניטור, הבנה והבטחת הדיוק והאמינות של LLMs יכולים לעזור לך להפחית את הסיכונים הכרוכים במודלים אלה של AI. על ידי ניטור של הזיות, השלמות גרועות (תגובות) והנחיות, אתה יכול לוודא שה-LLM שלך נשאר על המסלול ומספק את הערך שאתה והמשתמשים שלך מחפשים. בפוסט זה, דנו בכמה מדדים כדי להציג דוגמאות.
למידע נוסף על הערכת מודלים של בסיס, עיין ב השתמש ב- SageMaker Clarify כדי להעריך מודלים של בסיס, ודפדף נוסף מחברות לדוגמה זמין במאגר GitHub שלנו. אתה יכול גם לבחון דרכים להפעלת הערכות LLM בהרחבה תפעול הערכת LLM בקנה מידה באמצעות Amazon SageMaker Clarify ושירותי MLOps. לבסוף, אנו ממליצים להתייחס ל להעריך מודלים שפה גדולים לאיכות ואחריות למידע נוסף על הערכת לימודי LLM.
על הכותבים
 ברונו קליין הוא מהנדס למידת מכונה בכיר עם פרקטיקת ניתוח של שירותים מקצועיים של AWS. הוא עוזר ללקוחות ליישם פתרונות ביג דאטה וניתוח. מחוץ לעבודה, הוא נהנה לבלות עם המשפחה, לטייל ולנסות אוכל חדש.
ברונו קליין הוא מהנדס למידת מכונה בכיר עם פרקטיקת ניתוח של שירותים מקצועיים של AWS. הוא עוזר ללקוחות ליישם פתרונות ביג דאטה וניתוח. מחוץ לעבודה, הוא נהנה לבלות עם המשפחה, לטייל ולנסות אוכל חדש.
 רושאב לוכאנדה הוא מהנדס נתונים ו-ML בכיר עם AWS Professional Services Analytics Practice. הוא עוזר ללקוחות ליישם פתרונות ביג דאטה, למידת מכונה וניתוח. מחוץ לעבודה, הוא נהנה לבלות עם המשפחה, לקרוא, לרוץ ולשחק גולף.
רושאב לוכאנדה הוא מהנדס נתונים ו-ML בכיר עם AWS Professional Services Analytics Practice. הוא עוזר ללקוחות ליישם פתרונות ביג דאטה, למידת מכונה וניתוח. מחוץ לעבודה, הוא נהנה לבלות עם המשפחה, לקרוא, לרוץ ולשחק גולף.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://aws.amazon.com/blogs/machine-learning/techniques-and-approaches-for-monitoring-large-language-models-on-aws/

