שפת שאילתות מובנית (SQL) היא שפה מורכבת הדורשת הבנה של מסדי נתונים ומטא נתונים. היום, AI ייצור יכול לאפשר לאנשים ללא ידע ב-SQL. משימת בינה מלאכותית זו נקראת טקסט ל-SQL, אשר מייצרת שאילתות SQL מעיבוד שפה טבעית (NLP) וממירה טקסט ל-SQL נכון סמנטי. הפתרון בפוסט זה נועד להביא את פעולות הניתוח הארגוניות לשלב הבא על ידי קיצור הדרך לנתונים שלך באמצעות שפה טבעית.
עם הופעתם של מודלים גדולים של שפה (LLMs), דור SQL מבוסס NLP עבר מהפך משמעותי. מפגינים ביצועים יוצאי דופן, LLMs מסוגלים כעת ליצור שאילתות SQL מדויקות מתיאורי שפה טבעית. עם זאת, עדיין נותרו אתגרים. ראשית, השפה האנושית היא מטבעה מעורפלת ותלויה בהקשר, בעוד ש-SQL הוא מדויק, מתמטי ומובנה. פער זה עלול לגרום להמרה לא מדויקת של צרכי המשתמש ל-SQL שנוצר. שנית, ייתכן שיהיה עליך לבנות תכונות טקסט ל-SQL עבור כל מסד נתונים, מכיוון שלעתים קרובות הנתונים אינם מאוחסנים במטרה אחת. ייתכן שיהיה עליך ליצור מחדש את היכולת עבור כל מסד נתונים כדי לאפשר למשתמשים ליצור SQL מבוסס NLP. שלישית, למרות האימוץ הגדול יותר של פתרונות ניתוח מרכזיים כמו אגמי נתונים ומחסנים, המורכבות עולה עם שמות טבלאות שונים ומטא נתונים אחרים הנדרשים ליצירת ה-SQL עבור המקורות הרצויים. לכן, גם איסוף מטא נתונים מקיפים ואיכותיים נותר אתגר. למידע נוסף על שיטות עבודה מומלצות של טקסט ל-SQL ודפוסי עיצוב, ראה הפקת ערך מנתונים ארגוניים: שיטות עבודה מומלצות עבור Text2SQL ובינה מלאכותית יצירתית.
הפתרון שלנו נועד להתמודד עם אתגרים אלה באמצעות סלע אמזון ו שירותי AWS Analytics. אנו משתמשים קלוד האנתרופי v2.1 על Amazon Bedrock בתור ה-LLM שלנו. כדי להתמודד עם האתגרים, הפתרון שלנו משלב תחילה את המטא נתונים של מקורות הנתונים בתוך קטלוג נתוני דבק של AWS כדי להגביר את הדיוק של שאילתת SQL שנוצרה. זרימת העבודה כוללת גם לולאת הערכה ותיקון סופית, למקרה שבעיות SQL מזוהות על ידי אמזונה אתנה, המשמש במורד הזרם כמנוע ה-SQL. אתנה גם מאפשרת לנו להשתמש בהמון נקודות קצה ומחברים נתמכים כדי לכסות קבוצה גדולה של מקורות נתונים.
לאחר שנעבור על השלבים לבניית הפתרון, אנו מציגים את התוצאות של כמה תרחישי בדיקה עם רמות מורכבות SQL משתנות. לבסוף, אנו דנים כיצד קל לשלב מקורות נתונים שונים בשאילתות ה-SQL שלך.
סקירת פתרונות
ישנם שלושה מרכיבים קריטיים בארכיטקטורה שלנו: Retrieval Augmented Generation (RAG) עם מטא נתונים של מסד נתונים, לולאת תיקון עצמי רב-שלבית, ואתנה כמנוע ה-SQL שלנו.
אנו משתמשים בשיטת RAG כדי לאחזר את תיאורי הטבלה ותיאורי הסכימה (עמודות) מ-AWS Glue metastore כדי להבטיח שהבקשה קשורה לטבלה ולמערכי הנתונים הנכונים. בפתרון שלנו, בנינו את השלבים הבודדים להפעלת מסגרת RAG עם קטלוג הנתונים של דבק AWS למטרות הדגמה. עם זאת, אתה יכול גם להשתמש בסיסי ידע ב- Amazon Bedrock כדי לבנות פתרונות RAG במהירות.
הרכיב הרב-שלבי מאפשר ל-LLM לתקן את שאילתת ה-SQL שנוצרה לצורך דיוק. כאן, ה-SQL שנוצר נשלח עבור שגיאות תחביר. אנו משתמשים בהודעות שגיאה של Athena כדי להעשיר את ההנחיה שלנו ל-LLM לתיקונים מדויקים ויעילים יותר ב-SQL שנוצר.
אתה יכול לשקול את הודעות השגיאה שמגיעות מדי פעם מאתנה כמו משוב. השלכות העלות של שלב תיקון שגיאות הן זניחות בהשוואה לערך שנמסר. אתה יכול אפילו לכלול את השלבים המתקנים האלה כדוגמאות למידה מחוזקת מפוקחת כדי לכוונן עדין את ה-LLM שלך. עם זאת, לא כיסינו את הזרימה הזו בפוסט שלנו למטרות פשטות.
שימו לב שתמיד קיים סיכון מובנה לאי דיוקים, שמגיע באופן טבעי עם פתרונות AI גנרטיביים. גם אם הודעות השגיאה של Athena יעילות מאוד כדי להפחית את הסיכון הזה, תוכל להוסיף עוד בקרה ותצוגות, כגון משוב אנושי או שאילתות לדוגמה לכוונון עדין, כדי למזער עוד יותר סיכונים כאלה.
Athena לא רק מאפשרת לנו לתקן את שאילתות ה-SQL, אלא היא גם מפשטת עבורנו את הבעיה הכוללת מכיוון שהיא משמשת כרכזת, שבה החישורים הם מקורות נתונים מרובים. ניהול גישה, תחביר SQL ועוד מטופלים כולם באמצעות Athena.
התרשים הבא ממחיש את ארכיטקטורת הפתרונות.
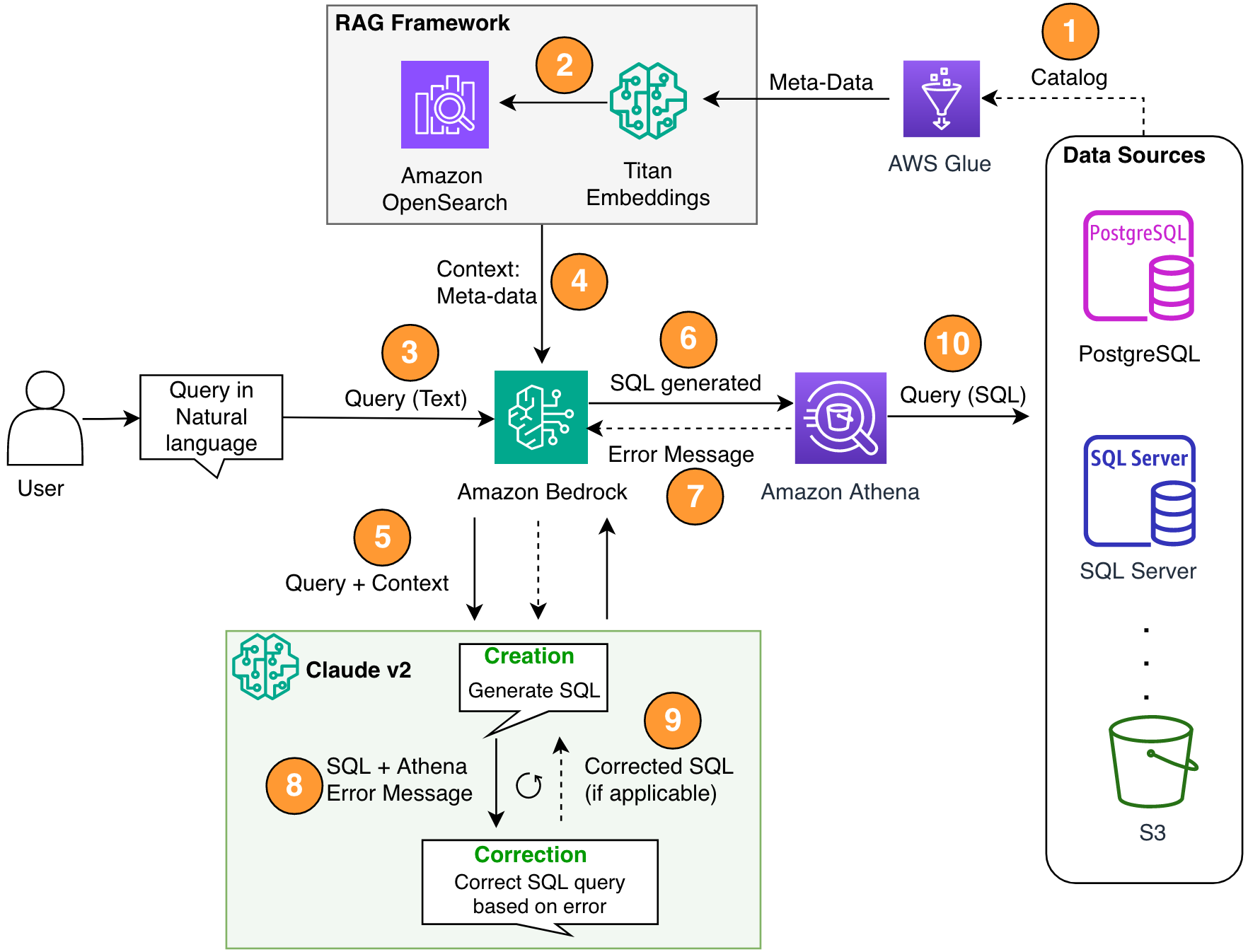
איור 1. ארכיטקטורת הפתרון וזרימת התהליך.
זרימת התהליך כוללת את השלבים הבאים:
- צור את קטלוג הנתונים של AWS Glue Data באמצעות סורק AWS Glue (או בשיטה אחרת).
- משתמש ב Titan-Text-Embeddings דגם על Amazon Bedrock, המר את המטא נתונים להטמעות ואחסן אותם ב- Amazon OpenSearch ללא שרתים חנות וקטור, המשמש כבסיס הידע שלנו במסגרת RAG שלנו.
בשלב זה התהליך מוכן לקבל את השאילתה בשפה טבעית. שלבים 7-9 מייצגים לולאת תיקון, אם ישים.
- המשתמש מזין את השאילתה שלו בשפה טבעית. אתה יכול להשתמש בכל יישום אינטרנט כדי לספק את ממשק המשתמש של הצ'אט. לכן, לא כיסינו את פרטי ממשק המשתמש בפוסט שלנו.
- הפתרון מיישם מסגרת RAG באמצעות חיפוש דמיון, שמוסיף את ההקשר הנוסף מהמטא נתונים ממסד הנתונים הווקטוריים. טבלה זו משמשת למציאת הטבלה, מסד הנתונים והתכונות הנכונות.
- השאילתה מתמזגת עם ההקשר ונשלחת אל קלוד האנתרופי v2.1 ב- Amazon Bedrock.
- המודל מקבל את שאילתת SQL שנוצרת ומתחבר לאטהנה כדי לאמת את התחביר.
- אם אתנה מספקת הודעת שגיאה שמזכירה שהתחביר שגוי, המודל משתמש בטקסט השגיאה מהתגובה של אתנה.
- ההנחיה החדשה מוסיפה את תגובתה של אתנה.
- המודל יוצר את ה-SQL המתוקן וממשיך בתהליך. איטרציה זו יכולה להתבצע מספר פעמים.
- לבסוף, אנו מריצים את ה-SQL באמצעות Athena ומייצרים פלט. כאן, הפלט מוצג למשתמש. למען הפשטות האדריכלית, לא הצגנו את השלב הזה.
תנאים מוקדמים
עבור פוסט זה, עליך להשלים את התנאים המוקדמים הבאים:
- יש חשבון AWS.
- התקן מה היא ממשק שורת הפקודה של AWS (AWS CLI).
- הגדר את SDK עבור Python (Boto3).
- צור את קטלוג הנתונים של AWS Glue Data באמצעות סורק AWS Glue (או בשיטה אחרת).
- משתמש ב Titan-Text-Embeddings דגם על Amazon Bedrock, המר את המטא נתונים להטמעות ואחסן אותם ב-OpenSearch Serverless חנות וקטור.
מיישמים את הפתרון
אתה יכול להשתמש בפעולות הבאות מחברת צדק, הכולל את כל קטעי הקוד שסופקו בסעיף זה, לבניית הפתרון. אנו ממליצים להשתמש סטודיו SageMaker של אמזון כדי לפתוח את המחברת הזו עם מופע ml.t3.medium עם ליבת Python 3 (Data Science). להנחיות, עיין ב אימון מודל למידת מכונה. בצע את השלבים הבאים כדי להגדיר את הפתרון:
- צור את בסיס הידע ב-OpenSearch Service עבור מסגרת RAG:
- בנה את ההנחיה (
final_question) על ידי שילוב קלט המשתמש בשפה טבעית (user_query), המטא נתונים הרלוונטיים מחנות הווקטור (vector_search_match), וההוראות שלנו (details): - הפעל את Amazon Bedrock עבור ה-LLM (Claude v2) ובקש ממנו ליצור את שאילתת SQL. בקוד הבא, הוא עושה מספר ניסיונות על מנת להמחיש את שלב התיקון העצמי:x
- אם מתקבלות בעיות כלשהן עם שאילתת SQL שנוצרה (
{sqlgenerated}) מתגובת אתנה ({syntaxcheckmsg}), ההודעה החדשה (prompt) נוצר על סמך התגובה והמודל מנסה שוב ליצור את ה-SQL החדש: - לאחר יצירת ה-SQL, לקוח Athena מופעל כדי להפעיל ולהפיק את הפלט:
בדוק את הפתרון
בחלק זה, אנו מריצים את הפתרון שלנו עם תרחישים שונים לדוגמה כדי לבדוק רמות מורכבות שונות של שאילתות SQL.
כדי לבדוק את הטקסט ל-SQL שלנו, אנו משתמשים בשניים מערכי נתונים זמינים מ-IMDB. קבוצות משנה של נתוני IMDb זמינות לשימוש אישי ולא מסחרי. אתה יכול להוריד את מערכי הנתונים ולאחסן אותם שירות אחסון פשוט של אמזון (אמזון S3). אתה יכול להשתמש בקטע Spark SQL הבא כדי ליצור טבלאות ב-AWS Glue. עבור דוגמה זו, אנו משתמשים title_ratings ו title:
אחסן נתונים באמזון S3 ומטא נתונים ב-AWS Glue
בתרחיש זה, מערך הנתונים שלנו מאוחסן בדלי S3. לאתנה יש מחבר S3 המאפשר לך להשתמש ב-Amazon S3 כמקור נתונים שניתן לבצע שאילתה.
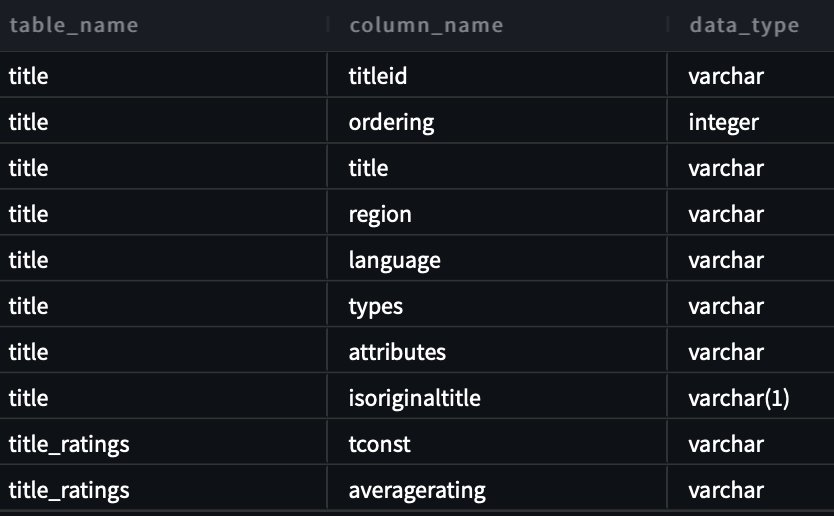
עבור השאילתה הראשונה שלנו, אנו מספקים את הקלט "אני חדש בזה. האם אתה יכול לעזור לי לראות את כל הטבלאות והעמודות בסכימת imdb?"
להלן השאילתה שנוצרה:
צילום המסך והקוד הבאים מציגים את הפלט שלנו.
עבור השאילתה השנייה שלנו, אנו מבקשים "הראה לי את כל הכותרת והפרטים באזור ארה"ב שהדירוג שלהם הוא יותר מ-9.5."
להלן השאילתה שנוצרה:
התגובה היא כדלקמן.

עבור השאילתה השלישית שלנו, אנו מזינים "תגובה נהדרת! עכשיו תראה לי את כל הכותרים המקוריים עם דירוגים של יותר מ-7.5 ולא באזור ארה"ב."
השאילתה הבאה נוצרת:
אנו מקבלים את התוצאות הבאות.

צור SQL מתוקן בעצמו
תרחיש זה מדמה שאילתת SQL שיש לה בעיות תחביר. כאן, ה-SQL שנוצר יתוקן בעצמו על סמך התגובה מאתנה. בתגובה הבאה נתנה אתנה א COLUMN_NOT_FOUND טעות והזכיר את זה table_description לא ניתן לפתור:
שימוש בפתרון עם מקורות נתונים אחרים
כדי להשתמש בפתרון עם מקורות נתונים אחרים, Athena מטפלת במשימה עבורך. לשם כך, אתנה משתמשת מחברי מקור נתונים שאפשר להשתמש איתו שאילתות מאוחדות. אתה יכול לשקול מחבר כהרחבה של מנוע השאילתות של Athena. מחברי מקורות נתונים מובנים מראש של Athena קיימים עבור מקורות נתונים כמו יומני CloudWatch של אמזון, אמזון דינמו, Amazon DocumentDB (עם תאימות MongoDB), ו שירות מסדי נתונים יחסי של אמזון (Amazon RDS), ומקורות נתונים יחסיים תואמי JDBC כגון MySQL ו-PostgreSQL תחת רישיון Apache 2.0. לאחר שתגדיר חיבור למקור נתונים כלשהו, תוכל להשתמש בבסיס הקוד הקודם כדי להרחיב את הפתרון. למידע נוסף, עיין ב שאל כל מקור נתונים עם השאילתה המאוחדת החדשה של אמזון אתנה.
לנקות את
כדי לנקות את המשאבים, אתה יכול להתחיל ב מנקה את דלי ה-S3 שלך היכן נמצאים הנתונים. אלא אם האפליקציה שלך תפעיל את Amazon Bedrock, היא לא תיגרם בעלות כלשהי. למען שיטות העבודה המומלצות לניהול תשתית, אנו ממליצים למחוק את המשאבים שנוצרו בהדגמה זו.
סיכום
בפוסט זה הצגנו פתרון המאפשר לך להשתמש ב-NLP ליצירת שאילתות SQL מורכבות עם מגוון משאבים המופעלים על ידי Athena. הגדלנו גם את הדיוק של שאילתות SQL שנוצרו באמצעות לולאת הערכה רב-שלבית המבוססת על הודעות שגיאה מתהליכים במורד הזרם. בנוסף, השתמשנו במטא-נתונים ב-AWS Glue Data Catalog כדי לשקול את שמות הטבלאות שנשאלו בשאילתה דרך מסגרת RAG. לאחר מכן בדקנו את הפתרון בתרחישים מציאותיים שונים עם רמות מורכבות שונות של שאילתות. לבסוף, דנו כיצד ליישם פתרון זה על מקורות נתונים שונים הנתמכים על ידי Athena.
Amazon Bedrock הוא במרכז הפתרון הזה. Amazon Bedrock יכולה לעזור לך לבנות יישומי AI גנרטיביים רבים. כדי להתחיל עם Amazon Bedrock, אנו ממליצים לעקוב אחר ההתחלה המהירה בהמשך GitHub ריפו והיכרות עם בניית יישומי AI גנרטיביים. אתה יכול גם לנסות בסיסי ידע ב- Amazon Bedrock כדי לבנות פתרונות RAG כאלה במהירות.
על הכותבים
 סנג'יב פנדה הוא מהנדס נתונים ו-ML באמזון. עם הרקע ב-AI/ML, Data Science וביג דאטה, Sanjeeb מעצב ומפתח פתרונות נתונים ו-ML חדשניים הפותרים אתגרים טכניים מורכבים ומשיגים יעדים אסטרטגיים עבור מוכרי 3P גלובליים המנהלים את העסקים שלהם באמזון. מעבר לעבודתו כמהנדס נתונים ו-ML באמזון, סנג'יב פנדה הוא חובב אוכל ומוזיקה נלהב.
סנג'יב פנדה הוא מהנדס נתונים ו-ML באמזון. עם הרקע ב-AI/ML, Data Science וביג דאטה, Sanjeeb מעצב ומפתח פתרונות נתונים ו-ML חדשניים הפותרים אתגרים טכניים מורכבים ומשיגים יעדים אסטרטגיים עבור מוכרי 3P גלובליים המנהלים את העסקים שלהם באמזון. מעבר לעבודתו כמהנדס נתונים ו-ML באמזון, סנג'יב פנדה הוא חובב אוכל ומוזיקה נלהב.
 בורק גוזלוקלו הוא אדריכל ראשי בינה מלאכותית/ML מומחה לפתרונות הממוקם בבוסטון, MA. הוא עוזר ללקוחות אסטרטגיים לאמץ טכנולוגיות AWS ובמיוחד פתרונות AI Generative כדי להשיג את היעדים העסקיים שלהם. לבוראק יש תואר דוקטור בהנדסת אווירונאוטיקה וחלל מ- METU, תואר שני בהנדסת מערכות ופוסט-דוקטורט בדינמיקת מערכת מ-MIT בקיימברידג', MA. בורק הוא עדיין שותף מחקר ב-MIT. בורק נלהב מיוגה ומדיטציה.
בורק גוזלוקלו הוא אדריכל ראשי בינה מלאכותית/ML מומחה לפתרונות הממוקם בבוסטון, MA. הוא עוזר ללקוחות אסטרטגיים לאמץ טכנולוגיות AWS ובמיוחד פתרונות AI Generative כדי להשיג את היעדים העסקיים שלהם. לבוראק יש תואר דוקטור בהנדסת אווירונאוטיקה וחלל מ- METU, תואר שני בהנדסת מערכות ופוסט-דוקטורט בדינמיקת מערכת מ-MIT בקיימברידג', MA. בורק הוא עדיין שותף מחקר ב-MIT. בורק נלהב מיוגה ומדיטציה.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://aws.amazon.com/blogs/machine-learning/build-a-robust-text-to-sql-solution-generating-complex-queries-self-correcting-and-querying-diverse-data-sources/

