טקסטורה באמזון הוא שירות למידת מכונה (ML) המחלץ אוטומטית טקסט, כתב יד ונתונים מכל מסמך או תמונה. נתח את המסמך פריסה היא תכונה חדשה המאפשרת ללקוחות לחלץ אוטומטית רכיבי פריסה כגון פסקאות, כותרות, כתוביות, כותרות עליונות, כותרות תחתונות ועוד ממסמכים. Layout מרחיב את זיהוי המילים והשורות של Amazon Textract על ידי קיבוץ אוטומטי של הטקסט לתוך רכיבי פריסה אלה ורצף אותם לפי דפוסי קריאה אנושיים. (כלומר סדר קריאה משמאל לימין ומלמעלה למטה).
בניית פתרונות עיבוד והבנת מסמכים עבור דוחות כספיים ומחקרים, תמלול רפואי, חוזים, מאמרים בתקשורת וכדומה מחייבת מיצוי מידע הקיים בכותרות, כותרות, פסקאות וכדומה. לדוגמה, בעת קטלוג דוחות כספיים במסד נתונים של מסמכים, חילוץ ואחסון הכותרת כאינדקס קטלוגי מאפשר שליפה קלה. לפני הצגת תכונה זו, הלקוחות היו צריכים לבנות את האלמנטים הללו באמצעות קוד שלאחר עיבוד ותגובת המילים והשורות מאמזון Textract.
המורכבות של יישום קוד זה מוגברת עם מסמכים עם מספר עמודות ופריסות מורכבות. עם הכרזה זו, חילוץ של רכיבי פריסה נפוצים ממסמכים הופכת קלה יותר ומאפשרת ללקוחות לבנות פתרונות יעילים לעיבוד מסמכים מהר יותר עם פחות קוד.
בספטמבר 2023, Amazon Textract השיקה את תכונת ה-Layout המחלצת אוטומטית רכיבי פריסה כגון פסקאות, כותרות, רשימות, כותרות עליונות ותחתונות ומסדרת את הטקסט והאלמנטים כפי שאדם יקרא. שחררנו גם את הגרסה המעודכנת של ערכת הכלים לפוסט-עיבוד בקוד פתוח, שנבנתה במיוחד עבור Amazon Textract, הידועה בשם Amazon Textract Textractor.
בפוסט זה, אנו דנים כיצד לקוחות יכולים לנצל את התכונה הזו לעומסי עבודה של עיבוד מסמכים. כמו כן, אנו דנים במחקר איכותי המדגים כיצד Layout משפר את דיוק המשימות של בינה מלאכותית (AI) עבור משימות מופשטות ומחלצות כאחד עבור עומסי עבודה של עיבוד מסמכים הכוללים מודלים של שפה גדולה (LLMs).
רכיבי פריסה
מרכזי בתכונת ה-Layout של Amazon Textract הם החדשים רכיבי פריסה. השמיים LAYOUT תכונה של נתח את המסמך API יכול כעת לזהות עד עשרה רכיבי פריסה שונים בעמוד של מסמך. רכיבי פריסה אלו מיוצגים כסוג בלוק ב-JSON התגובה ומכילים את הביטחון, הגיאומטריה (כלומר, מידע על התיבה התוחמת והמצולע), ו Relationships, שהיא רשימה של מזהים התואמים את LINE סוג בלוק.
- כותרת – הכותרת הראשית של המסמך. חזר בתור
LAYOUT_TITLEסוג בלוק. - כותרת – טקסט הממוקם בשוליים העליונים של המסמך. חזר בתור
LAYOUT_HEADERסוג בלוק. - תחתונה – טקסט הממוקם בשוליים התחתונים של המסמך. חזר בתור
LAYOUT_FOOTERסוג בלוק. - כותרת החלק – הכותרות מתחת לכותרת הראשית המייצגות סעיפים במסמך. חזר בתור
LAYOUT_SECTION_HEADERסוג בלוק. - מספר עמוד – מספר העמוד של המסמכים. חזר בתור
LAYOUT_PAGE_NUMBERסוג בלוק. - רשימה - כל מידע המקובץ יחד בטופס רשימה. חזר בתור
LAYOUT_LISTסוג בלוק. - תרשים – מציין את מיקום התמונה במסמך. חזר בתור
LAYOUT_FIGUREסוג בלוק. - טבלתי – מציין את מיקומה של טבלה במסמך. חזר בתור
LAYOUT_TABLEסוג בלוק. - ערך מפתח – מציין את המיקום של צמדי מפתח-ערך במסמך. חזר בתור
LAYOUT_KEY_VALUEסוג בלוק. - טקסט – טקסט שקיים בדרך כלל כחלק מפסקאות במסמכים. זה מלכוד הכל עבור טקסט שאינו קיים באלמנטים אחרים. חזר בתור
LAYOUT_TEXTסוג בלוק.
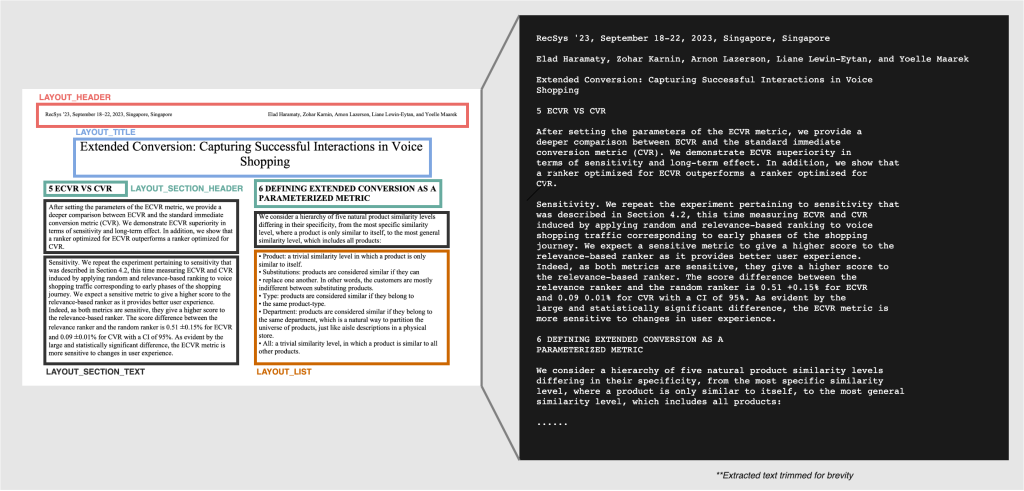
כל רכיב פריסה עשוי להכיל אחד או יותר LINE קשרים, והשורות הללו מהוות את התוכן הטקסטואלי בפועל של אלמנט הפריסה (לדוגמה, LAYOUT_TEXT הוא בדרך כלל פסקה של טקסט המכילה מספר רב LINEס). חשוב לציין שרכיבי פריסה מופיעים בסדר הקריאה הנכון בתגובת ה-API כסדר הקריאה במסמך, מה שמקל על בניית טקסט הפריסה מתגובת ה-JSON של ה-API.
השתמש במקרים של חילוץ מודע לפריסה
להלן כמה ממקרי השימוש הנפוצים ב-AnalyzeDocument החדש LAYOUT תכונה.
- חילוץ רכיבי פריסה למטרות אינדקס חיפוש וקטלוג. התוכן של
LAYOUT_TITLEorLAYOUT_SECTION_HEADER, יחד עם סדר הקריאה, ניתן להשתמש כדי לתייג או להעשיר מטא נתונים כראוי. זה משפר את ההקשר של מסמך במאגר מסמכים כדי לשפר את יכולות החיפוש או לארגן מסמכים. - סכם את המסמך כולו או חלקים ממנו על ידי חילוץ טקסט בסדר קריאה תקין ושימוש ברכיבי הפריסה.
- חילוץ חלקים ספציפיים של המסמך. לדוגמה, מסמך עשוי להכיל שילוב של תמונות עם טקסט בתוכו וקטעי טקסט רגיל או פסקאות אחרות. כעת תוכל לבודד את קטעי הטקסט באמצעות ה
LAYOUT_TEXTאלמנט. - ביצועים טובים יותר ותשובות מדויקות לשאלות ותשובות של מסמכים בתוך הקשר ולחילוצי ישויות באמצעות LLM.
ישנם מקרי שימוש אפשריים נוספים באוטומציה של מסמכים שבהם פריסה יכולה להיות שימושית. עם זאת, בפוסט זה אנו מסבירים כיצד לחלץ רכיבי פריסה על מנת לעזור להבין כיצד להשתמש בתכונה עבור פתרונות אוטומציה מסורתיים של תיעוד. אנו דנים ביתרונות של שימוש ב-Layout עבור מקרה שימוש בשאלות ותשובות של מסמך עם LLMs באמצעות שיטה נפוצה המכונה Retrieval Augmented Generation (RAG), ולמקרה שימוש בחילוץ ישות. עבור התוצאות של שני מקרי השימוש הללו, אנו מציגים ציונים השוואתיים שעוזרים להבדיל בין היתרונות של טקסט מודע לפריסה, בניגוד לטקסט פשוט.
כדי להדגיש את היתרונות, הרצנו בדיקות כדי להשוות את אופן החילוץ של טקסט רגיל באמצעות סריקות רסטר עם DetectDocumentText וטקסט ליניארי מודע לפריסה שחולץ באמצעות AnalyzeDocument עם LAYOUT תכונה משפיעה על התוצאה של פלטי שאלות ותשובות בתוך הקשר על ידי LLM. לבדיקה זו, השתמשנו בדגם קלוד אינסטנט של Anthropic עם Amazon Bedrock. עם זאת, עבור פריסות מסמכים מורכבות, יצירת טקסט בסדר קריאה תקין ולאחר מכן חלוקה המתאימה שלהם עשויה להיות מאתגרת, תלוי עד כמה מורכבת פריסת המסמך. בסעיפים הבאים, אנו דנים כיצד לחלץ רכיבי פריסה, ולניאריזציה של הטקסט כדי לבנות יישום מבוסס LLM. באופן ספציפי, אנו דנים בהערכה ההשוואתית של התגובות שנוצרו על ידי ה-LLM עבור יישום שאלות ותשובות למסמכים תוך שימוש בטקסט רגיל מבוסס סריקת רסטר וטקסט ליניארי המודע לפריסה.
חילוץ רכיבי פריסה מדף
ערכת הכלים של Amazon Textract Textractor יכולה לעבד מסמך באמצעות ה-API של AnalyzeDocument LAYOUT תכונה ובהמשך חושפת את רכיבי הפריסה שזוהו דרך העמודים PAGE_LAYOUT רכוש ותת נכס משלו TITLES, HEADERS, FOOTERS, TABLES, KEY_VALUES, PAGE_NUMBERS, LISTS, ו FIGURES. לכל אלמנט יש פונקציית הדמיה משלו, המאפשרת לך לראות בדיוק מה זוהה. כדי להתחיל, אתה מתחיל בהתקנת Textractor באמצעות
כפי שהודגם בקטע הקוד הבא, המסמך news_article.pdf מעובד עם AnalyzeDocument API עם LAYOUT תכונה. התגובה מביאה למסמך משתנה המכיל כל אחד מבושי ה-Layout שזוהו מהמאפיינים.

ראה דוגמה מעמיקה יותר ב התיעוד הרשמי של Textractor.
ליניאריזציה של טקסט מתגובת הפריסה
כדי להשתמש ביכולות הפריסה, Amazon Textract Textractor עבר עיבוד מקיף עבור המהדורה 1.4 כדי לספק ליניאריזציה עם למעלה מ-40 אפשרויות תצורה, המאפשרות לך להתאים את פלט הטקסט הליניארי למקרה השימוש שלך במורד הזרם עם מעט מאמץ. ה-linearizer החדש תומך בכל הזמינים כרגע AnalyzeDocument ממשקי API, כולל טפסים וחתימות, המאפשרים לך להוסיף פריטי בחירה לטקסט המתקבל מבלי לבצע שינויים בקוד.
ראה דוגמה זו ועוד ב התיעוד הרשמי של Textractor.
הוספנו גם א פריסה מדפסת יפה לספרייה שמאפשרת לקרוא לפונקציה בודדת על ידי העברת תגובת ה-API של layout בפורמט JSON ולקבל בתמורה את הטקסט הלינארי (לפי עמוד).
יש לך אפשרות לעצב את הטקסט בפורמט סימון, לא לכלול טקסט מתוך דמויות במסמך, ולא לכלול חילוצי כותרת עליונה, תחתונה ומספר עמודים מהפלט הלינאארי. אתה יכול גם לאחסן את הפלט הליניארי בפורמט טקסט רגיל במערכת הקבצים המקומית שלך או במיקום של Amazon S3 על ידי העברת save_txt_path פָּרָמֶטֶר. קטע הקוד הבא מדגים שימוש לדוגמה -
הערכת מדדי ביצוע LLM עבור משימות מופשטות וחילוץ
נמצא כי טקסט מודע לפריסה משפר את הביצועים והאיכות של טקסט שנוצר על ידי LLMs. בפרט, אנו מעריכים שני סוגים של משימות LLM - משימות מופשטות ומחלצות.
משימות מופשטות מתייחסות למשימות הדורשות מה-AI ליצור טקסט חדש שאינו נמצא ישירות בחומר המקור. כמה דוגמאות למשימה מופשטת כוללות סיכום ומענה על שאלות. עבור משימות אלו, אנו משתמשים במדד Recall-Oriented Understudy for Gisting Evaluation (ROUGE) כדי להעריך את הביצועים של LLM במשימות מענה לשאלות ביחס לקבוצה של נתוני אמת יסוד.
משימות חילוץ מתייחסות לפעילויות שבהן המודל מזהה ומחלץ חלקים ספציפיים מטקסט הקלט כדי לבנות תגובה. במשימות אלו, המודל מתמקד בבחירת פלחים רלוונטיים (כגון משפטים, ביטויים או מילות מפתח) מחומר המקור במקום ביצירת תוכן חדש. כמה דוגמאות נקראות זיהוי ישויות (NER) וחילוץ מילות מפתח. עבור משימות אלה, אנו משתמשים בדמיון Levenshtein Average Normalized (ANLS) על משימות זיהוי ישויות על בסיס טקסט ליניארי של פריסה שחולץ על ידי Amazon Textract.
ניתוח ציון ROUGE במשימת תשובות מופשטות לשאלות
הבדיקה שלנו מוגדרת לביצוע שאלות ותשובות בתוך הקשר במסמך מרובה עמודות על ידי חילוץ הטקסט ולאחר מכן ביצוע RAG כדי לקבל תשובות תשובות מה-LLM. אנו מבצעים שאלות ותשובות על קבוצת שאלות באמצעות טקסט גולמי מבוסס סריקת רסטר וטקסט ליניארי מודע לפריסה. לאחר מכן אנו מעריכים מדדי ROUGE עבור כל שאלה על ידי השוואת התגובה שנוצרה על ידי מכונה לתשובת האמת הבסיסית המתאימה. במקרה זה, האמת הבסיסית היא אותה מערכת שאלות עליה עונה אדם, הנחשבת כקבוצת ביקורת.
שאלות ותשובות בתוך הקשר עם RAG דורשות חילוץ טקסט מהמסמך, יצירת נתחים קטנים יותר של הטקסט, יצירת הטבעות וקטוריות של הנתחים, ולאחר מכן אחסונם במסד נתונים וקטורי. זה נעשה כדי שהמערכת תוכל לבצע חיפוש רלוונטיות עם השאלה במסד הנתונים הווקטוריים כדי להחזיר פיסות טקסט שהכי רלוונטיות לשאלה הנשאלת. הנתחים הרלוונטיים הללו משמשים לאחר מכן לבניית ההקשר הכולל ומסופקים ל-LLM כך שיוכל לענות במדויק על השאלה.
המסמך הבא, שנלקח מתוך DocUNet: ביטול עיוות של תמונת מסמך באמצעות U-Net מוערמים מערך הנתונים, משמש עבור הבדיקה. מסמך זה הוא מסמך מרובה עמודות עם כותרות, כותרות, פסקאות ותמונות. הגדרנו גם קבוצה של 20 שאלות עליהן ענה אדם כקבוצת ביקורת או כאמת קרקעית. אותה קבוצה של 20 שאלות שימשה לאחר מכן ליצירת תשובות מה-LLM.

בשלב הבא, אנו מחלצים את הטקסט ממסמך זה באמצעות DetectDocumentText API ו- AnalyzeDocument API עם LAYOUT תכונה. מכיוון שלרוב ה-LLMs יש חלון הקשר אסימון מוגבל, שמרנו על גודל הנתח קטן, כ-250 תווים עם חפיפה של נתח של 50 תווים, באמצעות של LangChain RecursiveCharacterTextSplitter. זה הביא לשתי קבוצות נפרדות של נתחי מסמכים - האחד נוצר באמצעות הטקסט הגולמי והשני באמצעות טקסט ליניארי המודע לפריסה. שתי קבוצות הנתחים אוחסנו במסד נתונים וקטור על ידי יצירת הטבעות וקטוריות באמצעות מודל הטבעת הטקסט של Amazon Titan Embeddings G1.

קטע הקוד הבא יוצר את הטקסט הגולמי מהמסמך.
הפלט (חתוך לקיצור) נראה כמו הבא. סדר קריאת הטקסט שגוי בגלל חוסר מודעות לפריסה של ה-API, והטקסט שחולץ משתרע על עמודות הטקסט.
הוויזואלי של סדר הקריאה עבור טקסט גולמי שחולץ על ידי DetectDocumentText ניתן לראות בתמונה הבאה.

קטע הקוד הבא יוצר מהמסמך את הטקסט בעל הפריסה ליניארית. אתה יכול להשתמש בכל אחת מהשיטות כדי ליצור את הטקסט ליניארי מהמסמך באמצעות הגרסה העדכנית ביותר של ספריית Amazon Textract Textractor Python.
הפלט (חתוך לקיצור) נראה כמו הבא. סדר קריאת הטקסט נשמר מאז שהשתמשנו בתכונת LAYOUT, והטקסט הגיוני יותר.
ניתן לראות את החזותית של סדר הקריאה עבור טקסט גולמי שחולץ על ידי AnalyzeDocument עם תכונת LAYOUT בתמונה הבאה.

ביצענו chunking בשני הטקסט שחולץ בנפרד, עם גודל chunk של 250 וחפיפה של 50.
לאחר מכן, אנו יוצרים הטמעות וקטוריות עבור הנתחים ומטעינים אותם למסד נתונים וקטורי בשני אוספים נפרדים. השתמשנו בקוד פתוח ב-ChromaDB כמסד הנתונים הוקטורים בזיכרון שלנו והשתמשנו בערך topK של 3 לחיפוש הרלוונטיות. המשמעות היא שלכל שאלה, שאילתת החיפוש הרלוונטית שלנו עם ChromaDB מחזירה 3 נתחי טקסט רלוונטיים בגודל 250 כל אחד. שלושת הנתחים הללו משמשים לאחר מכן לבניית הקשר עבור ה-LLM. בחרנו בכוונה גודל נתח קטן יותר ו-topK קטן יותר כדי לבנות את ההקשר מהסיבות הספציפיות הבאות.
- קצר את הגודל הכולל של ההקשר שלנו מכיוון שמחקרים מראים ש-LLM נוטים לכך ביצועים טובים יותר עם הקשר קצר יותר, למרות שהמודל תומך בהקשר ארוך יותר (באמצעות חלון הקשר אסימון גדול יותר).
- גודל הנחיות כללי קטן יותר מביא להשהיית מודל יצירת טקסט נמוכה יותר. ככל שגודל ההנחיות הכולל גדול יותר (הכולל את ההקשר), כך עשוי לקחת למודל זמן רב יותר ליצור תגובה.
- ציות לחלון ההקשר האסימון המוגבל של המודל, כפי שקורה ברוב ה-LLMs.
- יעילות עלות מכיוון ששימוש בפחות אסימונים פירושו עלות נמוכה יותר לכל שאלה עבור אסימוני קלט ופלט ביחד.
שימו לב ש-Anthropic Claude Instant v1 אכן תומך בחלון הקשר של 100,000 אסימונים דרך Amazon Bedrock. הגבלנו את עצמנו בכוונה לגודל נתח קטן יותר מכיוון שזה גם הופך את הבדיקה לרלוונטית לדגמים עם פחות פרמטרים וחלונות הקשר קצרים יותר.
השתמשנו במדדי ROUGE כדי להעריך טקסט שנוצר על ידי מכונה מול טקסט התייחסות (או אמת קרקע), תוך מדידת היבטים שונים כמו חפיפה של n-גרם, רצפי מילים וצמדי מילים בין שני הטקסטים. בחרנו שלושה מדדי ROUGE להערכה.
- ROUGE-1: משווה את החפיפה של אוניגרמות (מילים בודדות) בין הטקסט שנוצר לטקסט התייחסות.
- ROUGE-2: משווה את החפיפה של ביגרמות (רצפי שתי מילים) בין הטקסט שנוצר לטקסט התייחסות.
- ROUGE-L: מודד את רצף המשנה המשותף הארוך ביותר (LCS) בין הטקסט שנוצר לטקסט התייחסות, תוך התמקדות ברצף המילים הארוך ביותר המופיע בשני הטקסטים, אם כי לא בהכרח ברציפות.

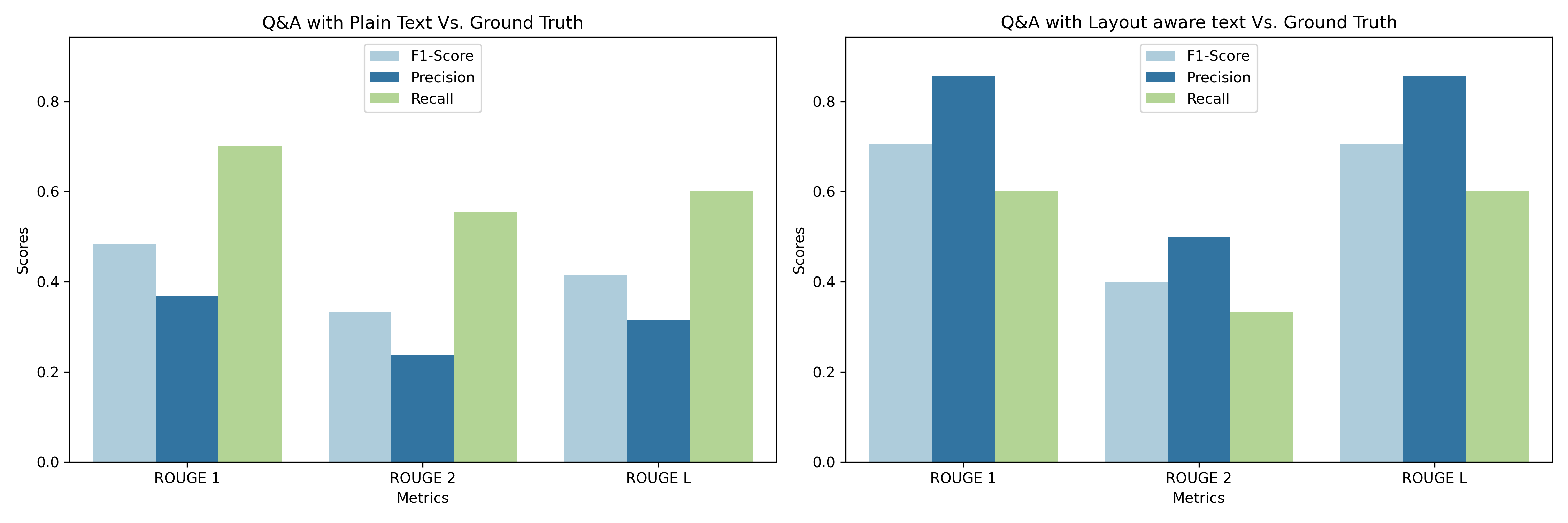
עבור 20 השאלות לדוגמה הרלוונטיות למסמך, הרצנו שאלות ותשובות עם הטקסט הגולמי והטקסט ליניארי, בהתאמה, ולאחר מכן הרצנו את ניתוח הציון ROUGE. שמנו לב לשיפור ממוצע של כמעט 50 אחוז בדייקנות הכוללת. והיה שיפור משמעותי בציוני F1 כאשר הושווה טקסט ליניארי של פריסה לאמת הקרקע לעומת כאשר הטקסט הגולמי הושווה לאמת הקרקע.
זה מצביע על כך שהמודל השתפר ביצירת תגובות נכונות בעזרת טקסט ליניארי וחתיכה קטנה יותר. זה הוביל לעלייה בדייקנות, והאיזון בין דיוק לזכירה עבר בצורה חיובית לכיוון דיוק, מה שהוביל לעלייה בציון F1. ציון F1 המוגבר, שמאזן בין דיוק וזיכרונות, מעיד על שיפור. חיוני לשקול את ההשלכות המעשיות של השינויים המטריים הללו. לדוגמה, בתרחיש שבו חיוביות כוזבות הן יקרות, העלייה בדייקנות מועילה מאוד.
ניתוח ציוני ANLS על משימות חילוץ על פני מערכי נתונים אקדמיים
אנו מודדים את ה-ANLS או את הדמיון הממוצע של Levenshtein, שהוא מדד מרחק עריכה שהוצג על ידי העיתון טקסט סצינה מענה על שאלה ויזואלית ומטרתה להעניש בעדינות פגמי OCR קלים תוך התחשבות ביכולות החשיבה של הדגם בו זמנית. מדד זה הוא גרסה נגזרת של מרחק לוונשטיין המסורתי, שהוא מדד להפרש בין שני רצפים (כגון מיתרים). הוא מוגדר כמספר המינימלי של עריכות של תו בודד (הוספות, מחיקות או החלפות) הנדרשות כדי לשנות מילה אחת לאחרת.
עבור מבחני ה-ANLS שלנו, ביצענו משימת NER שבה ה-LLM התבקש לחלץ את הערך המדויק מהטקסט שחולץ OCR. שני מערכי הנתונים האקדמיים המשמשים למבחנים הם DocVQA ו InfographicVQA. השתמשנו בהנחיה אפסית כדי לנסות לחלץ ישויות מפתח. ההנחיה המשמשת עבור ה-LLMs היא במבנה הבא.
שיפורי דיוק נצפו בכל מערכי הנתונים של תשובות לשאלות המסמכים שנבדקו במודל הקוד הפתוח FlanT5-XL בעת שימוש בטקסט ליניארי המודע לפריסה, בניגוד לטקסט גולמי (סריקת רסטר), בתגובה להנחיות של צילום אפס. במערך הנתונים של InfographicVQA, שימוש בטקסט ליניארי מודע לפריסה מאפשר למודל ה-3B הפרמטר FlanT5-XL להתאים את הביצועים של מודל ה-FlanT5-XXL הגדול יותר (על טקסט גולמי), שיש לו כמעט פי ארבעה פרמטרים רבים יותר (11B).
| מערך נתונים | ANLS* | |||||
| FlanT5-XL (3B) | FlanT5-XXL (11B) | |||||
| לא מודע לפריסה (ראסטר) | מודע לפריסה | Δ | לא מודע לפריסה (ראסטר) | מודע לפריסה | Δ | |
| DocVQA | 66.03% | 68.46% | 1.43% | 70.71% | 72.05% | 1.34% |
| אינפוגרפיקהVQA | 29.47% | 35.76% | 6.29% | 37.82% | 45.61% | 7.79% |
* ANLS נמדדת על טקסט שחולץ על ידי Amazon Textract, ולא על תמלול המסמך שסופק
סיכום
השקת Layout מסמנת התקדמות משמעותית בשימוש ב- Amazon Textract לבניית פתרונות אוטומציה של מסמכים. כפי שנדון בפוסט זה, Layout משתמש בשיטות AI מסורתיות ויצירתיות כדי לשפר את היעילות בעת בניית מגוון רחב של פתרונות אוטומציה של מסמכים כגון חיפוש מסמכים, שאלות ותשובות הקשריות, סיכום, חילוץ ישויות מפתח ועוד. ככל שאנו ממשיכים לאמץ את הכוח של AI בבניית מערכות עיבוד והבנת מסמכים, השיפורים הללו ללא ספק יסללו את הדרך לזרימות עבודה יעילות יותר, פרודוקטיביות גבוהה יותר וניתוח נתונים מעמיק יותר.
למידע נוסף על תכונת הפריסה וכיצד לנצל את התכונה עבור פתרונות אוטומציה של מסמכים, עיין ב נתח את המסמך, ניתוח פריסה, ו לינאריזציה של טקסט עבור תיעוד יישומי בינה מלאכותית.
על הכותבים
 אנג'אן ביזוואז הוא ארכיטקט בכיר בשירותי AI המתמקד בראייה ממוחשבת, NLP ובינה מלאכותית. אנג'אן היא חלק מצוות המומחים העולמי לשירותי AI ועובדת עם לקוחות כדי לעזור להם להבין ולפתח פתרונות לבעיות עסקיות עם שירותי AI של AWS ובינה מלאכותית גנרטיבית.
אנג'אן ביזוואז הוא ארכיטקט בכיר בשירותי AI המתמקד בראייה ממוחשבת, NLP ובינה מלאכותית. אנג'אן היא חלק מצוות המומחים העולמי לשירותי AI ועובדת עם לקוחות כדי לעזור להם להבין ולפתח פתרונות לבעיות עסקיות עם שירותי AI של AWS ובינה מלאכותית גנרטיבית.
 לליטה רדי הוא מנהל מוצר טכני בכיר בצוות Amazon Textract. היא מתמקדת בבניית שירותים מבוססי למידת מכונה עבור לקוחות AWS. בזמנה הפנוי, לליטה אוהבת לשחק משחקי לוח ולצאת לטיולים.
לליטה רדי הוא מנהל מוצר טכני בכיר בצוות Amazon Textract. היא מתמקדת בבניית שירותים מבוססי למידת מכונה עבור לקוחות AWS. בזמנה הפנוי, לליטה אוהבת לשחק משחקי לוח ולצאת לטיולים.
 אדוארד בלוואל הוא מהנדס מחקר בצוות הראייה הממוחשבת ב-AWS. הוא התורם העיקרי מאחורי ספריית Amazon Textract Textractor.
אדוארד בלוואל הוא מהנדס מחקר בצוות הראייה הממוחשבת ב-AWS. הוא התורם העיקרי מאחורי ספריית Amazon Textract Textractor.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://aws.amazon.com/blogs/machine-learning/amazon-textracts-new-layout-feature-introduces-efficiencies-in-general-purpose-and-generative-ai-document-processing-tasks/

