Gli assistenti conversazionali di intelligenza artificiale (AI) sono progettati per fornire risposte precise e in tempo reale attraverso l'instradamento intelligente delle query alle funzioni AI più adatte. Con i servizi di intelligenza artificiale generativa AWS come Roccia Amazzonica, gli sviluppatori possono creare sistemi in grado di gestire e rispondere in modo esperto alle richieste degli utenti. Amazon Bedrock è un servizio completamente gestito che offre una scelta di Foundation Model (FM) ad alte prestazioni di aziende leader nel settore dell'intelligenza artificiale come AI21 Labs, Anthropic, Cohere, Meta, Stability AI e Amazon utilizzando un'unica API, insieme a un'ampia serie di le funzionalità necessarie per creare applicazioni di intelligenza artificiale generativa con sicurezza, privacy e intelligenza artificiale responsabile.
Questo post valuta due approcci principali per lo sviluppo di assistenti IA: l'utilizzo di servizi gestiti come Agenti per Amazon Bedrocke utilizzando tecnologie open source come LangChain. Esploriamo i vantaggi e le sfide di ciascuno, così potrai scegliere il percorso più adatto alle tue esigenze.
Cos'è un assistente AI?
Un assistente AI è un sistema intelligente che comprende le query in linguaggio naturale e interagisce con vari strumenti, origini dati e API per eseguire attività o recuperare informazioni per conto dell'utente. Gli assistenti IA efficaci possiedono le seguenti capacità chiave:
- Elaborazione del linguaggio naturale (PNL) e flusso conversazionale
- Integrazione della base di conoscenza e ricerche semantiche per comprendere e recuperare informazioni rilevanti in base alle sfumature del contesto della conversazione
- Esecuzione di attività, come query di database e personalizzazioni AWS Lambda funzioni
- Gestione di conversazioni specializzate e richieste degli utenti
Dimostriamo i vantaggi degli assistenti IA utilizzando come esempio la gestione dei dispositivi Internet of Things (IoT). In questo caso d’uso, l’intelligenza artificiale può aiutare i tecnici a gestire i macchinari in modo efficiente con comandi che recuperano dati o automatizzano le attività, semplificando le operazioni di produzione.
Gli agenti per l'approccio Amazon Bedrock
Agenti per Amazon Bedrock ti consente di creare applicazioni di intelligenza artificiale generativa in grado di eseguire attività in più fasi sui sistemi e sulle origini dati di un'azienda. Offre le seguenti funzionalità chiave:
- Creazione automatica di prompt da istruzioni, dettagli API e informazioni sull'origine dati, risparmiando settimane di lavoro di progettazione tempestiva
- Retrieval Augmented Generation (RAG) per connettere in modo sicuro gli agenti alle origini dati di un'azienda e fornire risposte pertinenti
- Orchestrazione ed esecuzione di attività in più fasi suddividendo le richieste in sequenze logiche e chiamando le API necessarie
- Visibilità del ragionamento dell'agente attraverso una traccia della catena di pensiero (CoT), che consente la risoluzione dei problemi e la guida del comportamento del modello
- Capacità di ingegneria dei prompt per modificare il modello di prompt generato automaticamente per un maggiore controllo sugli agenti
Puoi utilizzare gli agenti per Amazon Bedrock e Basi di conoscenza per Amazon Bedrock per creare e distribuire assistenti IA per casi d'uso di routing complessi. Forniscono un vantaggio strategico per sviluppatori e organizzazioni semplificando la gestione dell'infrastruttura, migliorando la scalabilità, migliorando la sicurezza e riducendo il lavoro pesante indifferenziato. Consentono inoltre un codice a livello di applicazione più semplice perché la logica di routing, la vettorizzazione e la memoria sono completamente gestite.
Panoramica della soluzione
Questa soluzione introduce un assistente AI conversazionale su misura per la gestione e le operazioni dei dispositivi IoT quando si utilizza Claude v2.1 di Anthropic su Amazon Bedrock. Le funzionalità principali dell'assistente AI sono governate da una serie completa di istruzioni, note come a richiesta del sistema, che ne delinea le capacità e le aree di competenza. Questa guida garantisce che l'assistente AI possa gestire un'ampia gamma di attività, dalla gestione delle informazioni sul dispositivo all'esecuzione di comandi operativi.
Dotato di queste funzionalità, come dettagliato nel prompt del sistema, l'assistente AI segue un flusso di lavoro strutturato per rispondere alle domande degli utenti. La figura seguente fornisce una rappresentazione visiva di questo flusso di lavoro, illustrando ogni passaggio dall'interazione iniziale dell'utente alla risposta finale.

Il flusso di lavoro è composto dai seguenti passaggi:
- Il processo inizia quando un utente richiede all'assistente di eseguire un'attività; ad esempio, chiedendo i punti dati massimi per uno specifico dispositivo IoT
device_xxx. Questo input di testo viene catturato e inviato all'assistente AI. - L'assistente AI interpreta l'input di testo dell'utente. Utilizza la cronologia delle conversazioni, i gruppi di azioni e le basi di conoscenza forniti per comprendere il contesto e determinare le attività necessarie.
- Dopo che l'intento dell'utente è stato analizzato e compreso, l'assistente AI definisce le attività. Questo si basa sulle istruzioni interpretate dall'assistente secondo il prompt del sistema e l'input dell'utente.
- Le attività vengono quindi eseguite tramite una serie di chiamate API. Questo viene fatto utilizzando Reagire prompting, che suddivide l'attività in una serie di passaggi elaborati in sequenza:
- Per i controlli delle metriche del dispositivo, utilizziamo il file
check-device-metricsgruppo di azioni, che prevede una chiamata API alle funzioni Lambda che quindi eseguono query Amazzone Atena per i dati richiesti. - Per le azioni dirette del dispositivo come avvio, arresto o riavvio, utilizziamo il file
action-on-devicegruppo di azioni, che richiama una funzione Lambda. Questa funzione avvia un processo che invia comandi al dispositivo IoT. Per questo post, la funzione Lambda invia notifiche utilizzando Servizio di posta elettronica semplice Amazon (Amazon SES). - Utilizziamo le knowledge base per Amazon Bedrock per recuperare dati storici archiviati come incorporamenti nel file Servizio Amazon OpenSearch banca dati vettoriale.
- Per i controlli delle metriche del dispositivo, utilizziamo il file
- Una volta completate le attività, la risposta finale viene generata da Amazon Bedrock FM e trasmessa all'utente.
- Gli agenti per Amazon Bedrock archiviano automaticamente le informazioni utilizzando una sessione con stato per mantenere la stessa conversazione. Lo stato viene eliminato allo scadere di un timeout di inattività configurabile.
Panoramica tecnica
Il diagramma seguente illustra l'architettura per distribuire un assistente AI con agenti per Amazon Bedrock.
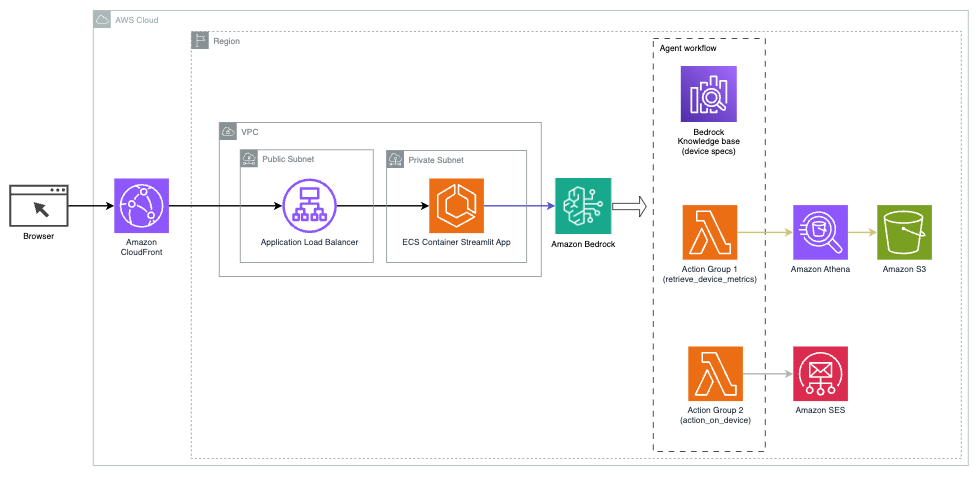
È costituito dai seguenti componenti chiave:
- Interfaccia conversazionale – L'interfaccia conversazionale utilizza Streamlit, una libreria Python open source che semplifica la creazione di app Web personalizzate e visivamente accattivanti per l'apprendimento automatico (ML) e la scienza dei dati. È ospitato su Servizio di container elastici Amazon (Amazon ECS) con AWS Fargate, ed è possibile accedervi utilizzando un Application Load Balancer. Puoi utilizzare Fargate con Amazon ECS per eseguire contenitori senza dover gestire server, cluster o macchine virtuali.
- Agenti per Amazon Bedrock – Gli agenti per Amazon Bedrock completano le query dell'utente attraverso una serie di passaggi di ragionamento e azioni corrispondenti basate su Richiesta di reazione:
- Basi di conoscenza per Amazon Bedrock – Le basi di conoscenza per Amazon Bedrock forniscono soluzioni completamente gestite RAG per fornire all'assistente AI l'accesso ai tuoi dati. Nel nostro caso d'uso, abbiamo caricato le specifiche del dispositivo in un file Servizio di archiviazione semplice Amazon (Amazon S3) secchio. Serve come origine dati per la knowledge base.
- Gruppi di azione – Si tratta di schemi API definiti che richiamano funzioni Lambda specifiche per interagire con dispositivi IoT e altri servizi AWS.
- Claude antropico v2.1 su Amazon Bedrock – Questo modello interpreta le query degli utenti e orchestra il flusso delle attività.
- Incorporamenti di Amazon Titan – Questo modello funge da modello di incorporamento del testo, trasformando il testo in linguaggio naturale, da singole parole a documenti complessi, in vettori numerici. Ciò abilita funzionalità di ricerca vettoriale, consentendo al sistema di abbinare semanticamente le query degli utenti con le voci della knowledge base più rilevanti per una ricerca efficace.
La soluzione è integrata con servizi AWS come Lambda per l'esecuzione di codice in risposta alle chiamate API, Athena per l'interrogazione di set di dati, OpenSearch Service per la ricerca nelle basi di conoscenza e Amazon S3 per lo storage. Questi servizi interagiscono per fornire un'esperienza fluida per la gestione delle operazioni dei dispositivi IoT tramite comandi in linguaggio naturale.
Benefici
Questa soluzione offre i seguenti vantaggi:
- Complessità di implementazione:
- Sono necessarie meno righe di codice perché Agents for Amazon Bedrock elimina gran parte della complessità sottostante, riducendo gli sforzi di sviluppo
- La gestione dei database vettoriali come OpenSearch Service è semplificata, poiché Knowledge Base per Amazon Bedrock gestisce la vettorizzazione e l'archiviazione
- L'integrazione con vari servizi AWS è più semplificata attraverso gruppi di azioni predefiniti
- Esperienza dello sviluppatore:
- La console Amazon Bedrock fornisce un'interfaccia intuitiva per sviluppo, test e analisi delle cause profonde (RCA) tempestivi, migliorando l'esperienza complessiva dello sviluppatore
- Agilità e flessibilità:
- Gli agenti per Amazon Bedrock consentono aggiornamenti senza interruzioni ai FM più recenti (come Claude 3.0) quando diventano disponibili, in modo che la tua soluzione rimanga aggiornata con gli ultimi progressi
- Le quote e le limitazioni del servizio sono gestite da AWS, riducendo il sovraccarico del monitoraggio e del dimensionamento dell'infrastruttura
- Sicurezza:
- Amazon Bedrock è un servizio completamente gestito, che aderisce ai rigorosi standard di sicurezza e conformità di AWS, semplificando potenzialmente le revisioni della sicurezza organizzativa
Sebbene Agents for Amazon Bedrock offra una soluzione semplificata e gestita per la creazione di applicazioni AI conversazionali, alcune organizzazioni potrebbero preferire un approccio open source. In questi casi, puoi utilizzare framework come LangChain, di cui parleremo nella sezione successiva.
Approccio di routing dinamico LangChain
LangChain è un framework open source che semplifica la creazione di un'intelligenza artificiale conversazionale consentendo l'integrazione di modelli linguistici di grandi dimensioni (LLM) e funzionalità di routing dinamico. Con LangChain Expression Language (LCEL), gli sviluppatori possono definire il file instradamento, che consente di creare catene non deterministiche in cui l'output di un passaggio precedente definisce il passaggio successivo. Il routing aiuta a fornire struttura e coerenza nelle interazioni con i LLM.
Per questo post utilizziamo lo stesso esempio dell'assistente AI per la gestione dei dispositivi IoT. Tuttavia, la differenza principale è che dobbiamo gestire i prompt del sistema separatamente e trattare ciascuna catena come un'entità separata. La catena di routing decide la catena di destinazione in base all'input dell'utente. La decisione viene presa con il supporto di un LLM passando il prompt del sistema, la cronologia della chat e la domanda dell'utente.
Panoramica della soluzione
Il diagramma seguente illustra il flusso di lavoro della soluzione di routing dinamico.

Il flusso di lavoro è costituito dai seguenti passaggi:
- L'utente presenta una domanda all'assistente AI. Ad esempio, "Quali sono le metriche massime per il dispositivo 1009?"
- Un LLM valuta ogni domanda insieme alla cronologia della chat della stessa sessione per determinarne la natura e l'area tematica in cui rientra (come SQL, azione, ricerca o SME). L'LLM classifica l'input e la catena di routing LCEL prende quell'input.
- La catena di router seleziona la catena di destinazione in base all'input e a LLM viene fornito il seguente prompt di sistema:
LLM valuta la domanda dell'utente insieme alla cronologia della chat per determinare la natura della query e in quale area rientra. LLM quindi classifica l'input e restituisce una risposta JSON nel seguente formato:
La catena di router utilizza questa risposta JSON per richiamare la catena di destinazione corrispondente. Esistono quattro catene di destinazione specifiche per argomento, ciascuna con il proprio prompt di sistema:
- Le query relative a SQL vengono inviate alla catena di destinazione SQL per le interazioni del database. È possibile utilizzare LCEL per creare il file catena SQL.
- Le domande orientate all'azione richiamano la catena di destinazione Lambda personalizzata per l'esecuzione delle operazioni. Con LCEL puoi definire il tuo funzione personalizzata; nel nostro caso, si tratta di una funzione per eseguire una funzione Lambda predefinita per inviare un'e-mail con un ID dispositivo analizzato. Un esempio di input utente potrebbe essere "Spegni dispositivo 1009".
- Le richieste mirate alla ricerca procedono al RAG catena di destinazione per il recupero delle informazioni.
- Le domande relative alle PMI vanno alla catena di destinazione delle PMI/esperti per approfondimenti specializzati.
- Ogni catena di destinazione prende l'input ed esegue i modelli o le funzioni necessarie:
- La catena SQL utilizza Athena per l'esecuzione delle query.
- La catena RAG utilizza OpenSearch Service per la ricerca semantica.
- La catena Lambda personalizzata esegue le funzioni Lambda per le azioni.
- La catena di PMI/esperti fornisce approfondimenti utilizzando il modello Amazon Bedrock.
- Le risposte di ciascuna catena di destinazione sono formulate in approfondimenti coerenti dal LLM. Queste informazioni vengono quindi fornite all'utente, completando il ciclo di query.
- Gli input e le risposte dell'utente vengono archiviati in Amazon DynamoDB per fornire contesto al LLM per la sessione corrente e dalle interazioni passate. La durata delle informazioni persistenti in DynamoDB è controllata dall'applicazione.
Panoramica tecnica
Il diagramma seguente illustra l'architettura della soluzione di routing dinamico LangChain.
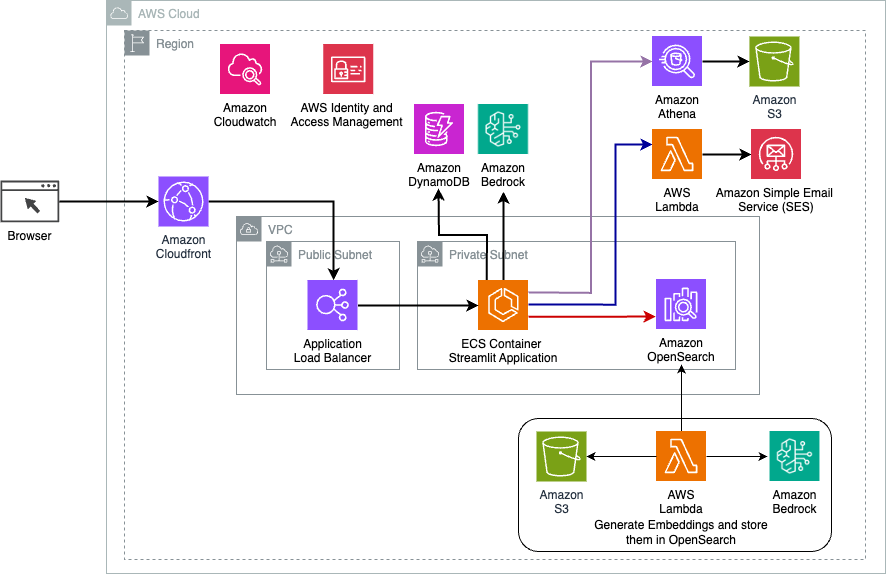
L'applicazione Web è basata su Streamlit ospitato su Amazon ECS con Fargate ed è accessibile tramite un sistema di bilanciamento del carico dell'applicazione. Usiamo Claude v2.1 di Anthropic su Amazon Bedrock come nostro LLM. L'applicazione web interagisce con il modello utilizzando le librerie LangChain. Interagisce inoltre con una varietà di altri servizi AWS, come OpenSearch Service, Athena e DynamoDB per soddisfare le esigenze degli utenti finali.
Benefici
Questa soluzione offre i seguenti vantaggi:
- Complessità di implementazione:
- Sebbene richieda più codice e sviluppo personalizzato, LangChain offre maggiore flessibilità e controllo sulla logica di routing e integrazione con vari componenti.
- La gestione di database vettoriali come OpenSearch Service richiede ulteriori attività di installazione e configurazione. Il processo di vettorizzazione è implementato nel codice.
- L'integrazione con i servizi AWS può comportare più codice e configurazione personalizzati.
- Esperienza dello sviluppatore:
- L'approccio basato su Python di LangChain e l'ampia documentazione possono risultare interessanti per gli sviluppatori che hanno già familiarità con Python e gli strumenti open source.
- Lo sviluppo e il debug tempestivi potrebbero richiedere uno sforzo manuale maggiore rispetto all'utilizzo della console Amazon Bedrock.
- Agilità e flessibilità:
- LangChain supporta un'ampia gamma di LLM, consentendoti di passare tra diversi modelli o fornitori, favorendo la flessibilità.
- La natura open source di LangChain consente miglioramenti e personalizzazioni guidati dalla comunità.
- Sicurezza:
- Essendo un framework open source, LangChain potrebbe richiedere revisioni e controlli di sicurezza più rigorosi all’interno delle organizzazioni, aggiungendo potenzialmente costi aggiuntivi.
Conclusione
Gli assistenti AI conversazionali sono strumenti trasformativi per semplificare le operazioni e migliorare le esperienze degli utenti. Questo post ha esplorato due potenti approcci che utilizzano i servizi AWS: gli agenti gestiti per Amazon Bedrock e il routing dinamico flessibile e open source LangChain. La scelta tra questi approcci dipende dai requisiti dell'organizzazione, dalle preferenze di sviluppo e dal livello di personalizzazione desiderato. Indipendentemente dal percorso intrapreso, AWS ti consente di creare assistenti IA intelligenti che rivoluzionano le interazioni aziendali e con i clienti
Trova il codice della soluzione e le risorse di distribuzione nel nostro Repository GitHub, dove puoi seguire i passaggi dettagliati per ciascun approccio basato sull'intelligenza artificiale conversazionale.
Informazioni sugli autori
 Ameer Hakme è un AWS Solutions Architect con sede in Pennsylvania. Collabora con fornitori di software indipendenti (ISV) nella regione nord-orientale, assistendoli nella progettazione e realizzazione di piattaforme scalabili e moderne sul cloud AWS. Esperto di AI/ML e IA generativa, Ameer aiuta i clienti a sbloccare il potenziale di queste tecnologie all'avanguardia. Nel tempo libero gli piace andare in moto e trascorrere del tempo di qualità con la sua famiglia.
Ameer Hakme è un AWS Solutions Architect con sede in Pennsylvania. Collabora con fornitori di software indipendenti (ISV) nella regione nord-orientale, assistendoli nella progettazione e realizzazione di piattaforme scalabili e moderne sul cloud AWS. Esperto di AI/ML e IA generativa, Ameer aiuta i clienti a sbloccare il potenziale di queste tecnologie all'avanguardia. Nel tempo libero gli piace andare in moto e trascorrere del tempo di qualità con la sua famiglia.
 Sharon Lic è un AI/ML Solutions Architect presso Amazon Web Services con sede a Boston, con una passione per la progettazione e la creazione di applicazioni di intelligenza artificiale generativa su AWS. Collabora con i clienti per sfruttare i servizi AI/ML di AWS per soluzioni innovative.
Sharon Lic è un AI/ML Solutions Architect presso Amazon Web Services con sede a Boston, con una passione per la progettazione e la creazione di applicazioni di intelligenza artificiale generativa su AWS. Collabora con i clienti per sfruttare i servizi AI/ML di AWS per soluzioni innovative.
 Kawsar Kamal è un Senior Solutions Architect presso Amazon Web Services con oltre 15 anni di esperienza nel settore dell'automazione e della sicurezza delle infrastrutture. Aiuta i clienti a progettare e costruire soluzioni DevSecOps e AI/ML scalabili nel cloud.
Kawsar Kamal è un Senior Solutions Architect presso Amazon Web Services con oltre 15 anni di esperienza nel settore dell'automazione e della sicurezza delle infrastrutture. Aiuta i clienti a progettare e costruire soluzioni DevSecOps e AI/ML scalabili nel cloud.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/enhance-conversational-ai-with-advanced-routing-techniques-with-amazon-bedrock/

