Amazon Kendra is a highly accurate and simple-to-use intelligent search service powered by machine learning (ML). Amazon Kendra offers a suite of data source connectors to simplify the process of ingesting and indexing your content, wherever it resides.
Valuable data in organizations is stored in both structured and unstructured repositories. An enterprise search solution should be able to provide you with a fully managed experience and simplify the process of indexing your content from a variety of data sources in the enterprise.
One such unstructured data repository are internal and external websites. Sites may need to be crawled to create news feeds, analyze language use, or create bots to answer questions based on the website data.
We’re excited to announce that you can now use the new Amazon Kendra Web Crawler to search for answers from content stored in internal and external websites or create chatbots. In this post, we show how to index information stored in websites and use the intelligent search in Amazon Kendra to search for answers from content stored in internal and external websites. In addition, the ML-powered intelligent search can accurately get answers for your questions from unstructured documents with natural language narrative content, for which keyword search is not very effective.
The Web Crawler offers the following new features:
- Support for Basic, NTLM/Kerberos, Form, and SAML authentication
- The ability to specify 100 seed URLs and store connection configuration in Amazon Simple Storage Service (Amazon S3)
- Support for a web and internet proxy with the ability to provide proxy credentials
- Support for crawling dynamic content, such as a website containing JavaScript
- Field mapping and regex filtering features
Solution overview
With Amazon Kendra, you can configure multiple data sources to provide a central place to search across your document repository. For our solution, we demonstrate how to index a crawled website using the Amazon Kendra Web Crawler. The solution consists of the following steps:
- Choose an authentication mechanism for the website (if required) and store the details in AWS Secrets Manager.
- Create an Amazon Kendra index.
- Create a Web Crawler data source V2 via the Amazon Kendra console.
- Run a sample query to test the solution.
Prerequisites
To try out the Amazon Kendra Web Crawler, you need the following:
Gather authentication details
For protected and secure websites, the following authentication types and standards are supported:
- Basic
- NTLM/Kerberos
- Form authentication
- SAML
You need the authentication information when you set up the data source.
For basic or NTLM authentication, you need to provide your Secrets Manager secret, user name, and password.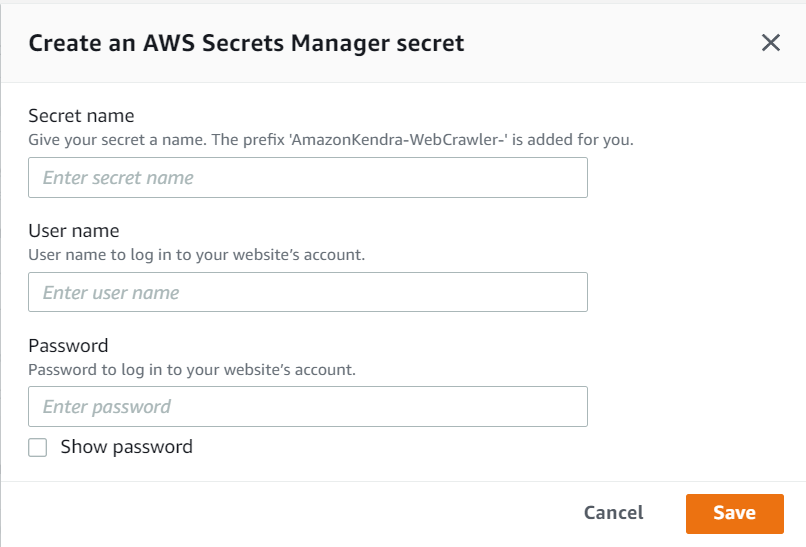
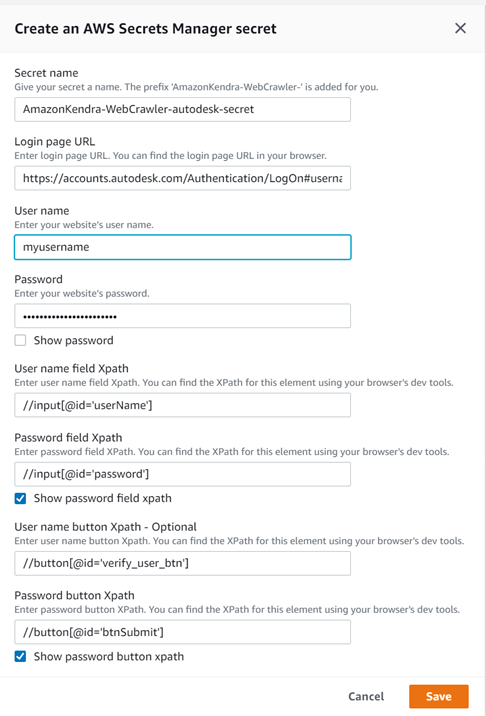
Form and SAML authentication require additional information, as shown in the following screenshot. Some of the fields like User name button Xpath are optional and will depend on whether the site you are crawling uses a button after entering the user name. Also note that you will need to know how to determine the Xpath of the user name and password field and the submit buttons.
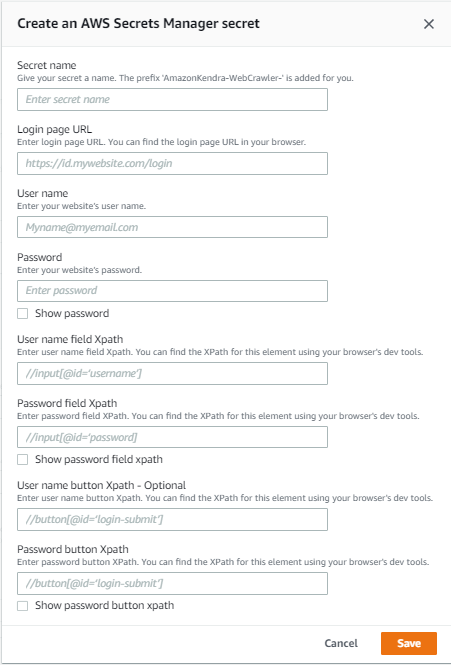
Create an Amazon Kendra index
To create an Amazon Kendra index, complete the following steps:
- On the Amazon Kendra console, choose Create an Index.
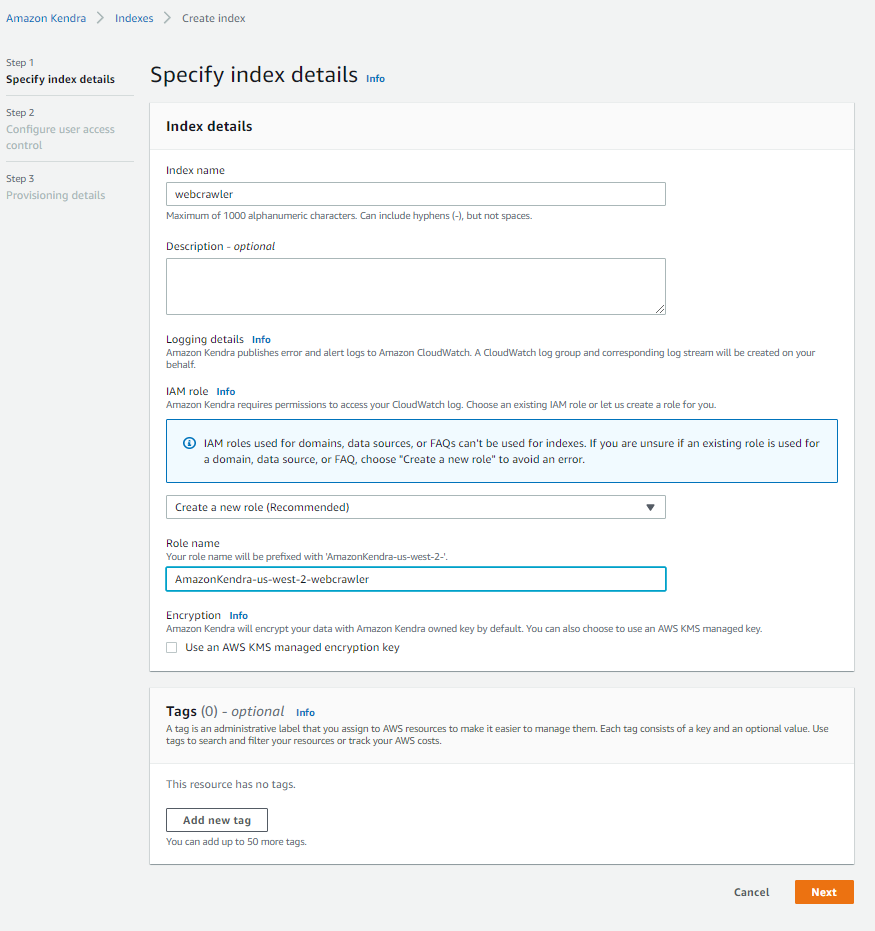
- For Index name, enter a name for the index (for example, Web Crawler).
- Enter an optional description.
- For Role name, enter an IAM role name.
- Configure optional encryption settings and tags.
- Choose Next.
- In the Configure user access control section, leave the settings at their defaults and choose Next.
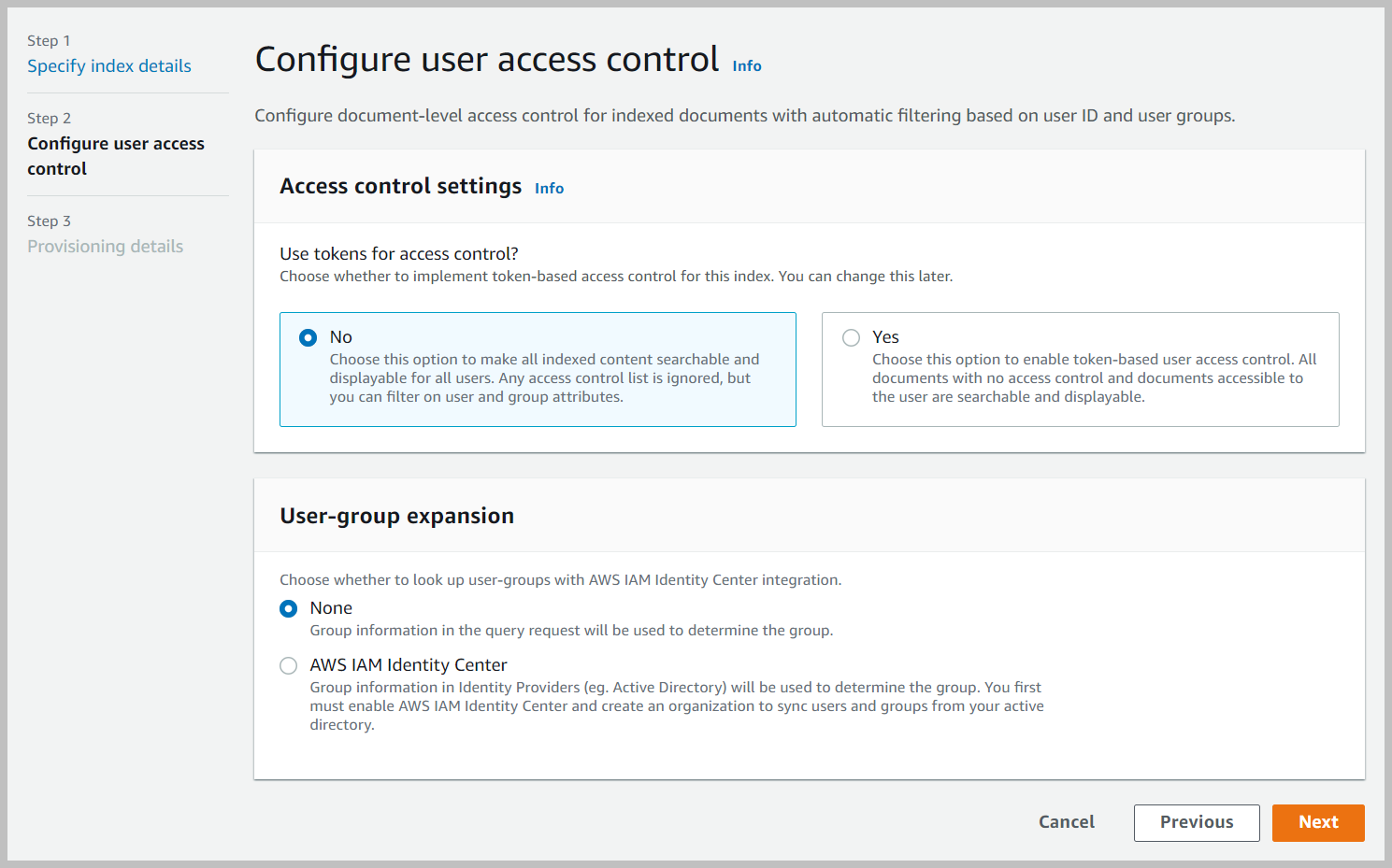
- For Provisioning editions, select Developer edition and choose Next.
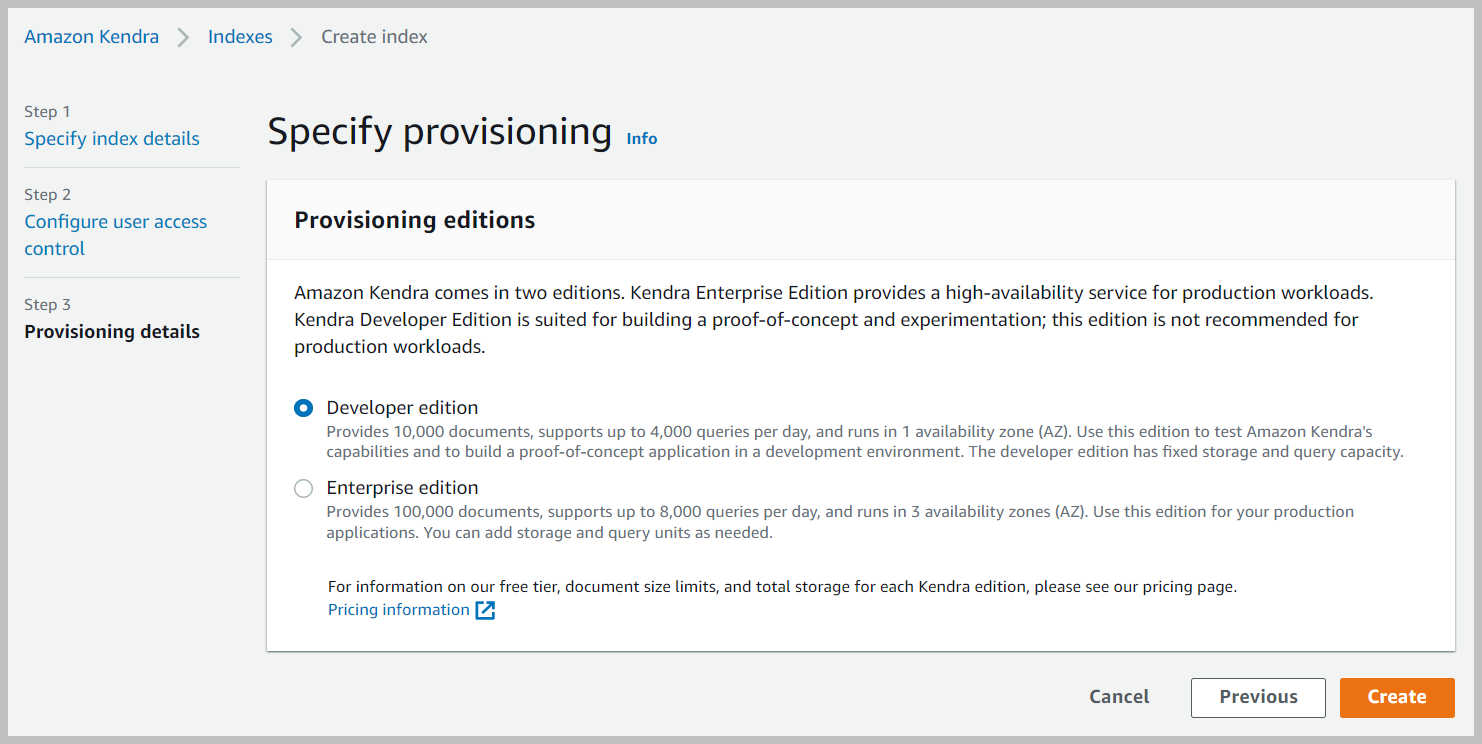
- On the review page, choose Create.
This creates and propagates the IAM role and then creates the Amazon Kendra index, which can take up to 30 minutes.
Create an Amazon Kendra Web Crawler data source
Complete the following steps to create your data source:
- On the Amazon Kendra console, choose Data sources in the navigation pane.
- Locate the WebCrawler connector V2.0 tile and choose Add connector.
- For Data source name, enter a name (for example, crawl-fda).
- Enter an optional description.
- Choose Next.
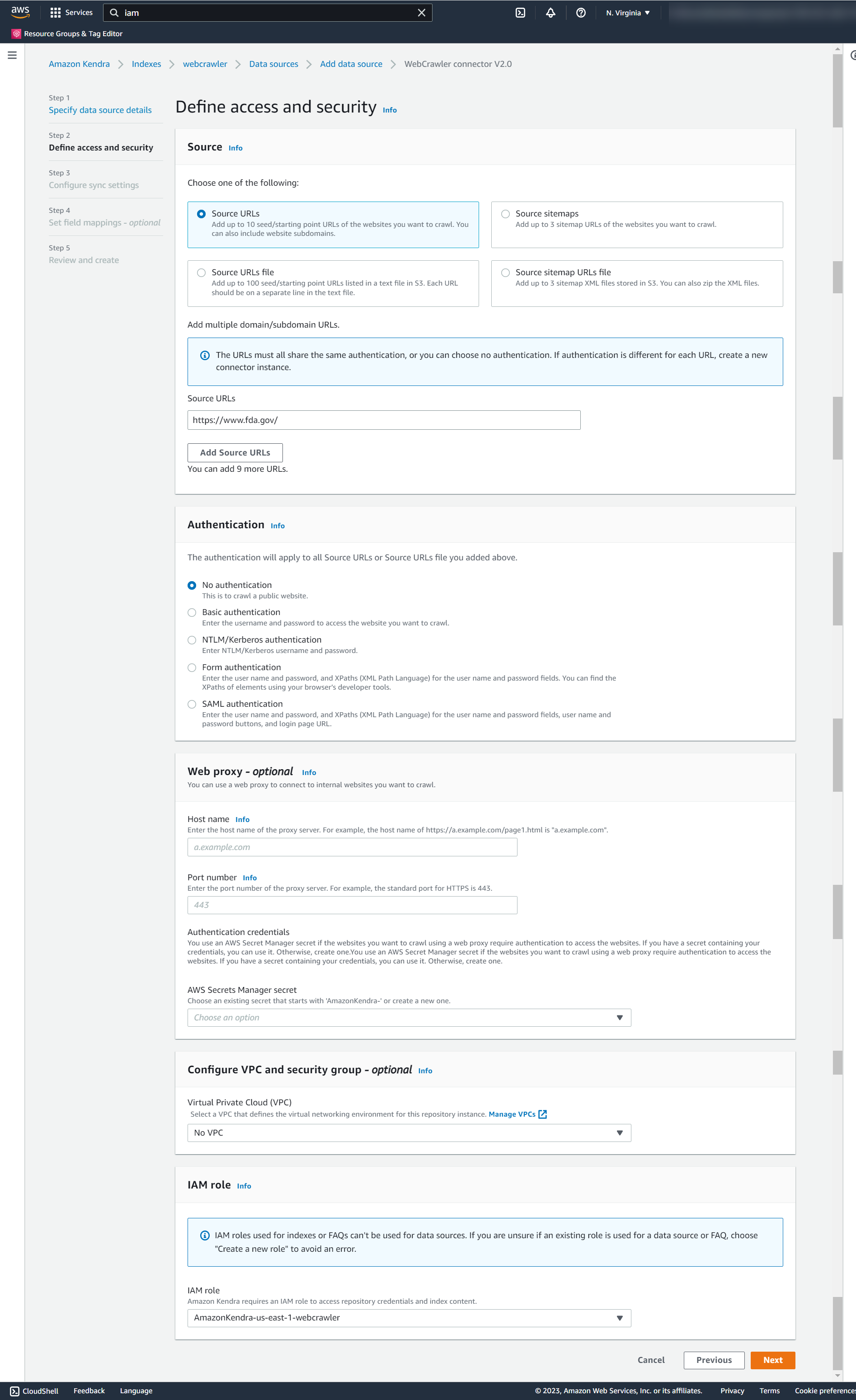
- In the Source section, select Source URL and enter a URL. For this post, we use https://www.fda.gov/ as an example source URL.
- In the Authentication section, chose the appropriate authentication based on the site that you want to crawl. For this post, we select No authentication because it’s a public site and doesn’t need authentication.
- In the Web proxy section, you can specify a Secrets Manager secret (if required).
- Choose Create and Add New Secret.
- Enter the authentication details that you gathered previously.
- Choose Save.
- In the IAM role section, choose Create a new role and enter a name (for example,
AmazonKendra-Web Crawler-datasource-role). - Choose Next.
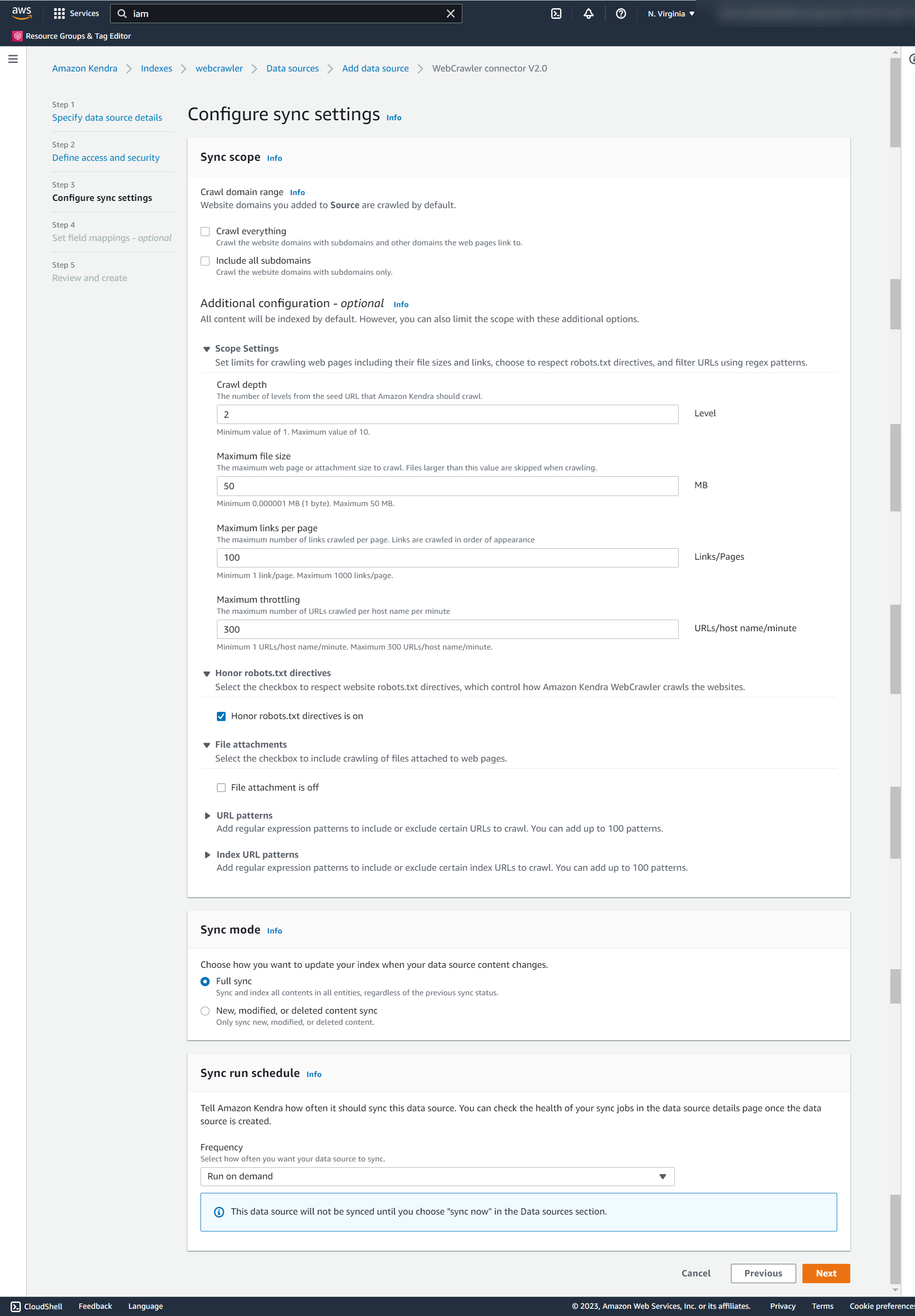
- In the Sync scope section, configure your sync settings based on the site you are crawling. For this post, we leave all the default settings.
- For Sync mode, choose how you want to update your index. For this post, we select Full sync.
- For Sync run schedule, choose Run on demand.
- Choose Next.
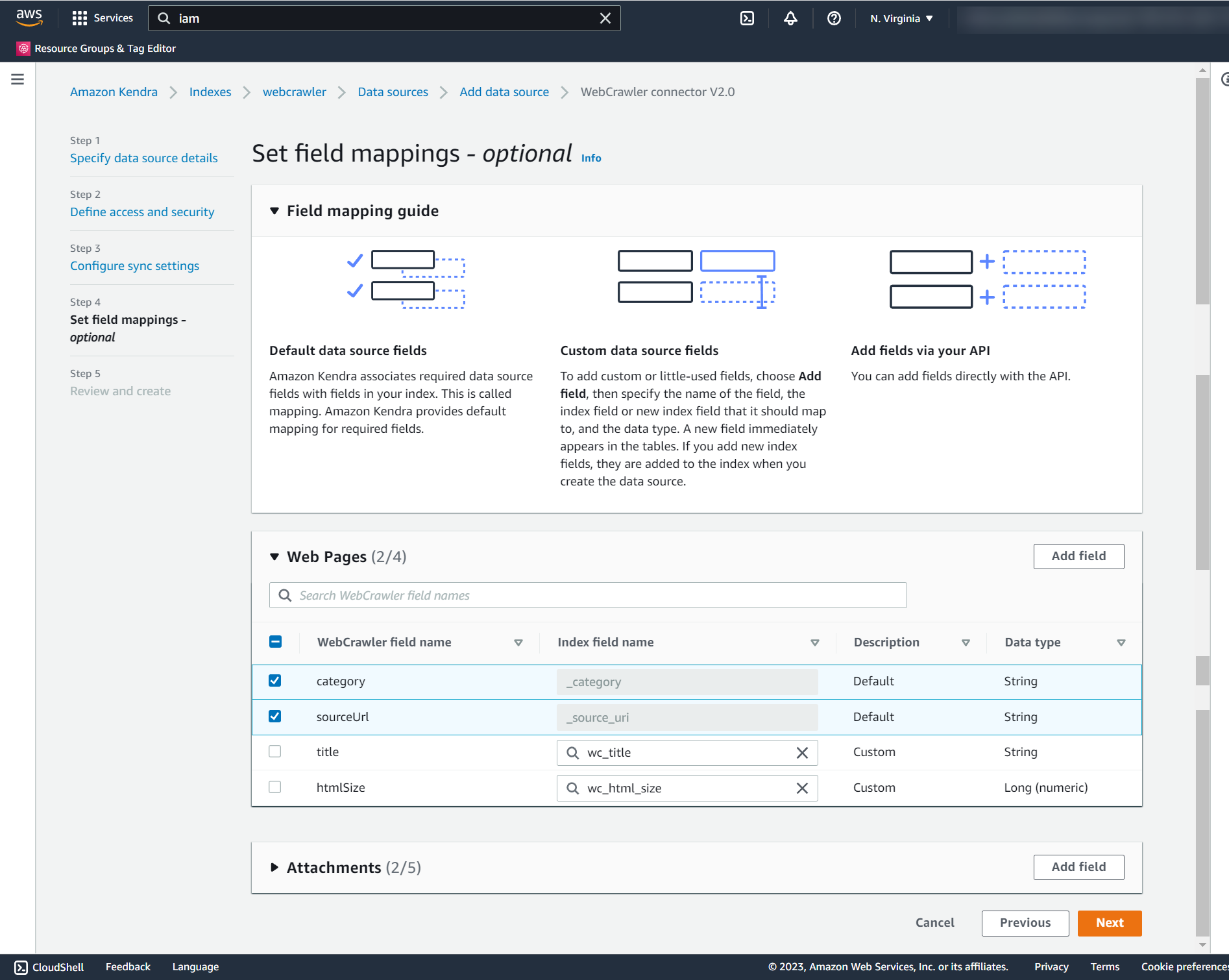
- Optionally, you can set field mappings. For this post, we keep the defaults for now.
Mapping fields is a useful exercise where you can substitute field names to values that are user-friendly and that fit in your organization’s vocabulary.
- Choose Next.
- Choose Add data source.

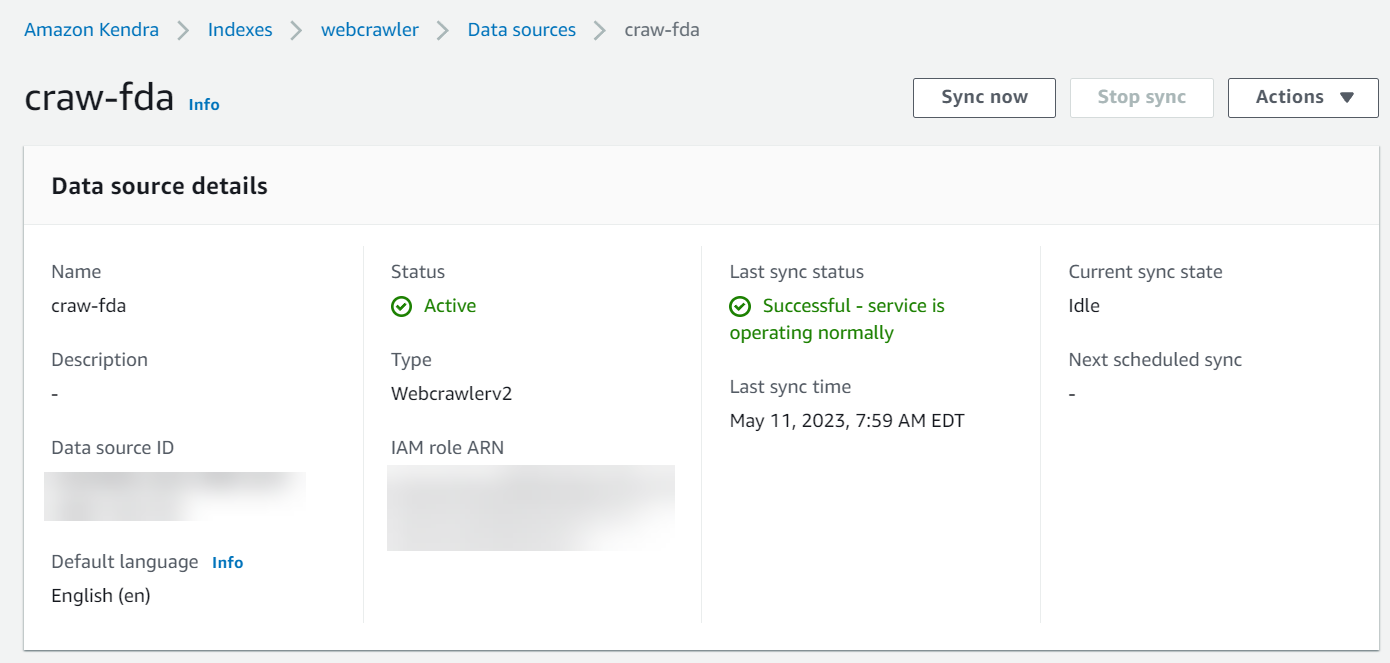
- To sync the data source, choose Sync now on the data source details page.
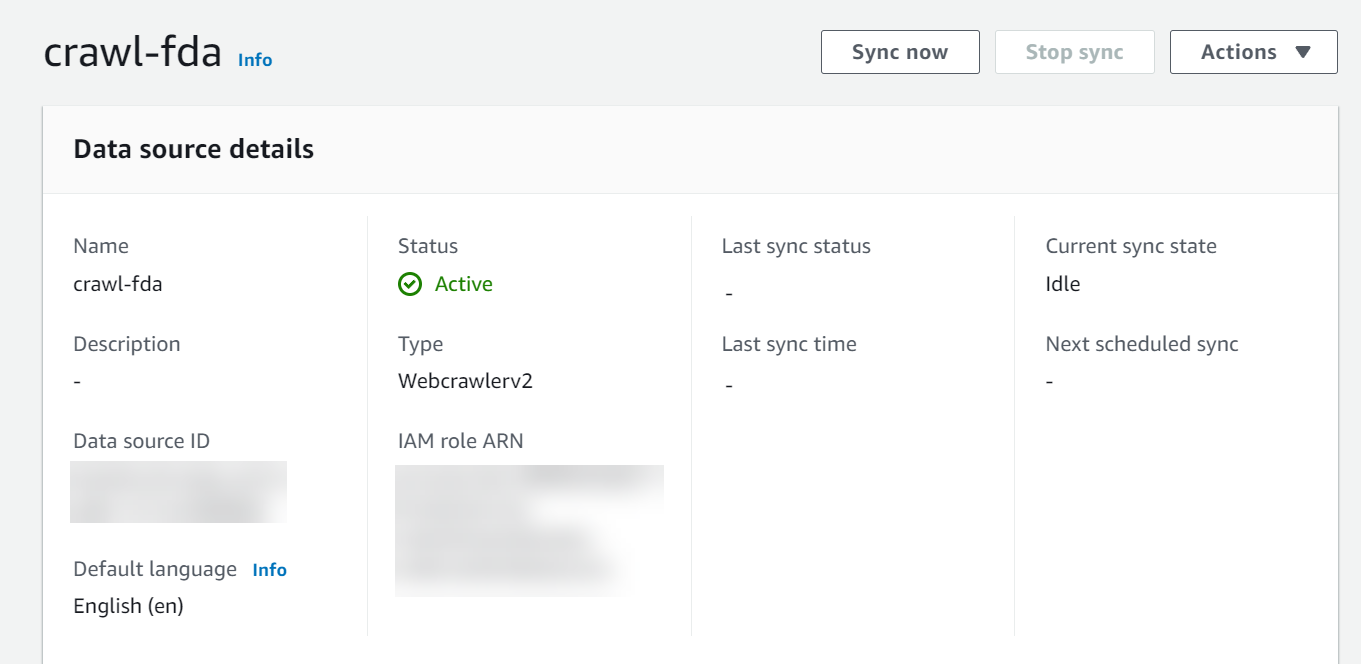
- Wait for the sync to complete.
Example of an authenticated website
If you want to crawl a site that has authentication, then in the Authentication section in the previous steps, you need to specify the authentication details. The following is an example if you selected Form authentication.
- In the Source section, select Source URL and enter a URL. For this example, we use https://accounts.autodesk.com.
- In the Authentication section, select Form authentication.
- In the Web proxy section, specify your Secrets Manager secret. This is required for any option other than No authentication.
- Choose Create and Add New Secret.
- Enter the authentication details that you gathered previously.
- Choose Save.
Test the solution
Now that you have ingested the content from the site into your Amazon Kendra index, you can test some queries.
- Go to your index and choose Search indexed content.
- Enter a sample search query and test out your search results (your query will vary based on the contents of site your crawled and the query entered).
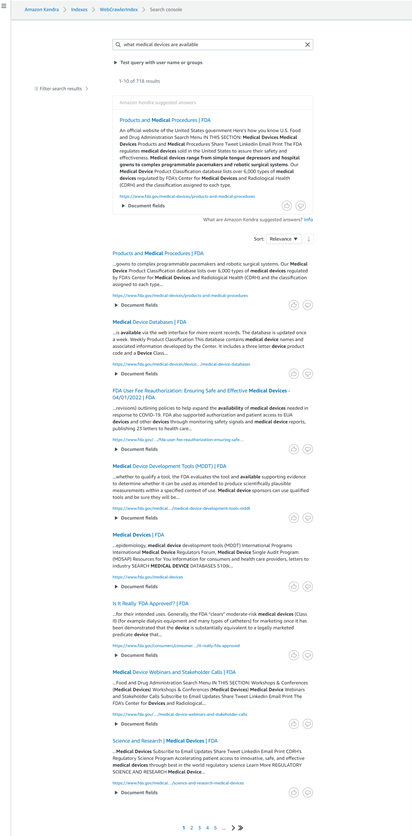
Congratulations! You have successfully used Amazon Kendra to surface answers and insights based on the content indexed from the site you crawled.
Clean up
To avoid incurring future costs, clean up the resources you created as part of this solution. If you created a new Amazon Kendra index while testing this solution, delete it. If you only added a new data source using the Amazon Kendra Web Crawler V2, delete that data source.
Conclusion
With the new Amazon Kendra Web Crawler V2, organizations can crawl any website that is public or behind authentication and use it for intelligent search powered by Amazon Kendra.
To learn about these possibilities and more, refer to the Amazon Kendra Developer Guide. For more information on how you can create, modify, or delete metadata and content when ingesting your data, refer to Enriching your documents during ingestion and Enrich your content and metadata to enhance your search experience with custom document enrichment in Amazon Kendra.
About the Authors
 Jiten Dedhia is a Sr. Solutions Architect with over 20 years of experience in the software industry. He has worked with global financial services clients, providing them advice on modernizing by using services provided by AWS.
Jiten Dedhia is a Sr. Solutions Architect with over 20 years of experience in the software industry. He has worked with global financial services clients, providing them advice on modernizing by using services provided by AWS.
 Gunwant Walbe is a Software Development Engineer at Amazon Web Services. He is an avid learner and keen to adopt new technologies. He develops complex business applications, and Java is his primary language of choice.
Gunwant Walbe is a Software Development Engineer at Amazon Web Services. He is an avid learner and keen to adopt new technologies. He develops complex business applications, and Java is his primary language of choice.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/index-your-web-crawled-content-using-the-new-web-crawler-for-amazon-kendra/

