Membuat pipeline machine learning (ML) yang skalabel dan efisien sangat penting untuk menyederhanakan pengembangan, penerapan, dan pengelolaan model ML. Dalam postingan ini, kami menyajikan kerangka kerja untuk mengotomatiskan pembuatan grafik asiklik terarah (DAG) untuk Pipa Amazon SageMaker berdasarkan file konfigurasi sederhana. Itu kode kerangka kerja dan contohnya yang disajikan di sini hanya mencakup pipeline pelatihan model, namun dapat dengan mudah diperluas ke pipeline inferensi batch juga.
Kerangka kerja dinamis ini menggunakan file konfigurasi untuk mengatur langkah-langkah prapemrosesan, pelatihan, evaluasi, dan registrasi untuk kasus penggunaan model tunggal dan multi-model berdasarkan skrip Python yang ditentukan pengguna, kebutuhan infrastruktur (termasuk Cloud Pribadi Virtual Amazon Subnet dan grup keamanan (Amazon VPC), Identitas AWS dan Manajemen Akses (IAM) peran, Layanan Manajemen Kunci AWS (AWS KMS), registri kontainer, dan tipe instans), input dan output Layanan Penyimpanan Sederhana Amazon Jalur (Amazon S3), dan tag sumber daya. File konfigurasi (YAML dan JSON) memungkinkan praktisi ML menentukan kode yang tidak dapat dibedakan untuk mengatur pipeline pelatihan menggunakan sintaksis deklaratif. Hal ini memungkinkan ilmuwan data untuk dengan cepat membangun dan melakukan iterasi pada model ML, dan memberdayakan teknisi ML untuk menjalankan pipeline ML integrasi berkelanjutan dan pengiriman berkelanjutan (CI/CD) dengan lebih cepat, sehingga mengurangi waktu produksi model.
Ikhtisar solusi
Kode kerangka kerja yang diusulkan dimulai dengan membaca file konfigurasi. Kemudian secara dinamis membuat DAG SageMaker Pipelines berdasarkan langkah-langkah yang dinyatakan dalam file konfigurasi dan interaksi serta ketergantungan di antara langkah-langkah tersebut. Kerangka kerja orkestrasi ini melayani kasus penggunaan model tunggal dan multi-model, serta memberikan aliran data dan proses yang lancar. Berikut ini adalah manfaat utama dari solusi ini:
- Otomatisasi – Seluruh alur kerja ML, mulai dari prapemrosesan data hingga registri model, diatur tanpa intervensi manual. Hal ini mengurangi waktu dan upaya yang diperlukan untuk eksperimen dan operasionalisasi model.
- Reproduksibilitas – Dengan file konfigurasi yang telah ditentukan sebelumnya, data scientist dan teknisi ML dapat mereproduksi seluruh alur kerja, mencapai hasil yang konsisten di berbagai proses dan lingkungan.
- Skalabilitas - Amazon SageMaker digunakan di seluruh pipeline, memungkinkan praktisi ML memproses kumpulan data besar dan melatih model kompleks tanpa masalah infrastruktur.
- keluwesan – Framework ini fleksibel dan dapat mengakomodasi berbagai kasus penggunaan ML, framework ML (seperti XGBoost dan TensorFlow), pelatihan multi-model, dan pelatihan multi-langkah. Setiap langkah pelatihan DAG dapat dikustomisasi melalui file konfigurasi.
- Tata kelola model - The Registri Model Amazon SageMaker integrasi memungkinkan pelacakan versi model, dan karenanya mempromosikannya ke produksi dengan percaya diri.
Diagram arsitektur berikut menggambarkan bagaimana Anda dapat menggunakan kerangka kerja yang diusulkan selama eksperimen dan operasionalisasi model ML. Selama eksperimen, Anda dapat mengkloning repositori kode kerangka kerja yang disediakan dalam postingan ini dan repositori kode sumber khusus proyek Anda ke dalamnya Studio Amazon SageMaker, dan atur lingkungan virtual Anda (dirinci nanti di postingan ini). Anda kemudian dapat mengulangi skrip prapemrosesan, pelatihan, dan evaluasi, serta pilihan konfigurasi. Untuk membuat dan menjalankan DAG pelatihan SageMaker Pipelines, Anda dapat memanggil titik masuk kerangka kerja, yang akan membaca semua file konfigurasi, membuat langkah-langkah yang diperlukan, dan mengaturnya berdasarkan urutan langkah dan dependensi yang ditentukan.
Selama operasionalisasi, pipeline CI mengkloning repositori kode kerangka kerja dan repositori pelatihan khusus proyek ke dalam Pembuatan Kode AWS pekerjaan, di mana skrip titik masuk kerangka kerja dipanggil untuk membuat atau memperbarui DAG pelatihan SageMaker Pipelines, dan kemudian menjalankannya.

Struktur repositori
Grafik Repositori GitHub berisi direktori dan file berikut:
- /kerangka/konf/ – Direktori ini berisi file konfigurasi yang digunakan untuk mengatur variabel umum di semua unit pemodelan seperti subnet, grup keamanan, dan IAM role pada waktu proses. Unit pemodelan adalah rangkaian hingga enam langkah untuk melatih model ML.
- /framework/buatmodel/ – Direktori ini berisi skrip Python yang membuat a Model SageMaker objek berdasarkan model artefak dari a Langkah pelatihan SageMaker Pipelines. Objek model kemudian digunakan dalam a Transformasi batch SageMaker tugas untuk mengevaluasi kinerja model pada set pengujian.
- /kerangka kerja/modelmetrik/ – Direktori ini berisi skrip Python yang membuat Pemrosesan SageMaker Amazon tugas untuk menghasilkan laporan JSON metrik model untuk model terlatih berdasarkan hasil tugas transformasi batch SageMaker yang dilakukan pada data pengujian.
- /kerangka/saluran/ – Direktori ini berisi skrip Python yang menggunakan kelas Python yang ditentukan dalam direktori kerangka kerja lain untuk membuat atau memperbarui SageMaker Pipelines DAG berdasarkan konfigurasi yang ditentukan. Skrip model_unit.py digunakan oleh pipeline_service.py untuk membuat satu atau lebih unit pemodelan. Setiap unit pemodelan merupakan rangkaian hingga enam langkah untuk melatih model ML: memproses, melatih, membuat model, mengubah, metrik, dan mendaftarkan model. Konfigurasi untuk setiap unit pemodelan harus ditentukan dalam repositori masing-masing model. pipeline_service.py juga menetapkan ketergantungan di antara langkah-langkah SageMaker Pipelines (bagaimana langkah-langkah di dalam dan di seluruh unit pemodelan diurutkan atau dirantai) berdasarkan bagian sagemakerPipeline, yang harus ditentukan dalam file konfigurasi salah satu repositori model (model jangkar). Hal ini memungkinkan Anda untuk mengganti dependensi default yang disimpulkan oleh SageMaker Pipelines. Kami membahas struktur file konfigurasi nanti di posting ini.
- /kerangka/pemrosesan/ – Direktori ini berisi skrip Python yang membuat pekerjaan Pemrosesan SageMaker berdasarkan gambar Docker dan skrip titik masuk yang ditentukan.
- /framework/daftarmodel/ – Direktori ini berisi skrip Python untuk mendaftarkan model terlatih beserta metrik terhitungnya di SageMaker Model Registry.
- /kerangka/pelatihan/ – Direktori ini berisi skrip Python yang membuat tugas pelatihan SageMaker.
- /kerangka/transformasi/ – Direktori ini berisi skrip Python yang membuat pekerjaan transformasi batch SageMaker. Dalam konteks pelatihan model, ini digunakan untuk menghitung metrik performa model yang dilatih pada data pengujian.
- /kerangka/utilitas/ – Direktori ini berisi skrip utilitas untuk membaca dan menggabungkan file konfigurasi, serta logging.
- /framework_entrypoint.py – File ini adalah titik masuk kode kerangka kerja. Ia memanggil fungsi yang ditentukan dalam direktori /framework/pipeline/ untuk membuat atau memperbarui DAG Pipeline SageMaker dan menjalankannya.
- /contoh/ – Direktori ini berisi beberapa contoh bagaimana Anda dapat menggunakan kerangka otomatisasi ini untuk membuat DAG pelatihan yang sederhana dan kompleks.
- /env.env – File ini memungkinkan Anda mengatur variabel umum seperti subnet, grup keamanan, dan peran IAM sebagai variabel lingkungan.
- /persyaratan.txt – File ini menentukan pustaka Python yang diperlukan untuk kode kerangka kerja.
Prasyarat
Anda harus memiliki prasyarat berikut sebelum menerapkan solusi ini:
- Akun AWS
- Studio SageMaker
- Peran SageMaker dengan izin baca/tulis Amazon S3 dan izin enkripsi/dekripsi AWS KMS
- Bucket S3 untuk menyimpan data, skrip, dan artefak model
- Secara opsional, Antarmuka Baris Perintah AWS (AWS CLI)
- Python3 (Python 3.7 atau lebih tinggi) dan paket Python berikut:
- boto3
- pembuat bijak
- PyYAML
- Paket Python tambahan yang digunakan dalam skrip khusus Anda
Terapkan solusinya
Selesaikan langkah-langkah berikut untuk menyebarkan solusi:
- Atur repositori pelatihan model Anda sesuai dengan struktur berikut:
- Kloning kode kerangka kerja dan kode sumber model Anda dari repositori Git:
-
- Klon
dynamic-sagemaker-pipelines-frameworkrepo ke direktori pelatihan. Dalam kode berikut, kami menganggap direktori pelatihan dipanggilaws-train: - Kloning kode sumber model di bawah direktori yang sama. Untuk pelatihan multi-model, ulangi langkah ini untuk sebanyak mungkin model yang perlu Anda latih.
- Klon
Untuk pelatihan model tunggal, direktori Anda akan terlihat seperti berikut:
Untuk pelatihan multi-model, direktori Anda akan terlihat seperti berikut:
- Siapkan variabel lingkungan berikut. Tanda bintang menunjukkan variabel lingkungan yang diperlukan; sisanya adalah opsional.
| Variabel Lingkungan | Deskripsi Produk |
SMP_ACCOUNTID* |
Akun AWS tempat alur SageMaker dijalankan |
SMP_REGION* |
Wilayah AWS tempat alur SageMaker dijalankan |
SMP_S3BUCKETNAME* |
Nama ember S3 |
SMP_ROLE* |
Peran SageMaker |
SMP_MODEL_CONFIGPATH* |
Jalur relatif file konfigurasi model tunggal atau multi-model |
SMP_SUBNETS |
ID subnet untuk konfigurasi jaringan SageMaker |
SMP_SECURITYGROUPS |
ID grup keamanan untuk konfigurasi jaringan SageMaker |
Untuk kasus penggunaan model tunggal, SMP_MODEL_CONFIGPATH akan <MODEL-DIR>/conf/conf.yaml. Untuk kasus penggunaan multi-model, SMP_MODEL_CONFIGPATH akan */conf/conf.yaml, yang memungkinkan Anda menemukan semuanya conf.yaml file menggunakan modul glob Python dan menggabungkannya untuk membentuk file konfigurasi global. Selama eksperimen (pengujian lokal), Anda dapat menentukan variabel lingkungan di dalam file env.env dan kemudian mengekspornya dengan menjalankan perintah berikut di terminal Anda:
Perhatikan bahwa nilai variabel lingkungan di env.env harus ditempatkan di dalam tanda kutip (misalnya, SMP_REGION="us-east-1"). Selama operasionalisasi, variabel lingkungan ini harus ditetapkan oleh pipeline CI.
- Buat dan aktifkan lingkungan virtual dengan menjalankan perintah berikut:
- Instal paket Python yang diperlukan dengan menjalankan perintah berikut:
- Edit pelatihan model Anda
conf.yamlfile. Kami membahas struktur file konfigurasi di bagian selanjutnya. - Dari terminal, panggil titik masuk kerangka kerja untuk membuat atau memperbarui dan menjalankan DAG pelatihan Pipeline SageMaker:
- Lihat dan debug SageMaker Pipelines yang dijalankan di Jaringan pipa tab di UI SageMaker Studio.
Struktur file konfigurasi
Ada dua jenis file konfigurasi dalam solusi yang diusulkan: konfigurasi kerangka kerja dan konfigurasi model. Di bagian ini, kami menjelaskan masing-masing secara rinci.
Konfigurasi kerangka
Grafik /framework/conf/conf.yaml file menetapkan variabel yang umum di semua unit pemodelan. Ini termasuk SMP_S3BUCKETNAME, SMP_ROLE, SMP_MODEL_CONFIGPATH, SMP_SUBNETS, SMP_SECURITYGROUPS, dan SMP_MODELNAME. Lihat Langkah 3 petunjuk penerapan untuk deskripsi variabel ini dan cara mengaturnya melalui variabel lingkungan.
Konfigurasi model
Untuk setiap model dalam proyek, kita perlu menentukan hal berikut di <MODEL-DIR>/conf/conf.yaml file (tanda bintang menunjukkan bagian yang diperlukan; sisanya opsional):
- /conf/model* – Di bagian ini, Anda dapat mengonfigurasi satu atau lebih unit pemodelan. Ketika kode framework dijalankan, maka secara otomatis akan membaca semua file konfigurasi selama runtime dan menambahkannya ke pohon konfigurasi. Secara teoritis, Anda dapat menentukan semua unit pemodelan secara sama
conf.yamlfile, namun disarankan untuk menentukan setiap konfigurasi unit pemodelan di direktori masing-masing atau repositori Git untuk meminimalkan kesalahan. Satuannya adalah sebagai berikut:- {nama model}* – Nama modelnya.
- direktori_sumber* - Biasa
source_dirjalur yang digunakan untuk semua langkah dalam unit pemodelan. - praproses – Bagian ini menentukan parameter pra-pemrosesan.
- kereta* – Bagian ini menentukan parameter pekerjaan pelatihan.
- mengubah* – Bagian ini menentukan parameter tugas Transformasi SageMaker untuk membuat prediksi pada data pengujian.
- mengevaluasi – Bagian ini menentukan parameter pekerjaan Pemrosesan SageMaker untuk menghasilkan laporan JSON metrik model untuk model yang dilatih.
- pendaftaran* – Bagian ini menentukan parameter untuk mendaftarkan model terlatih di SageMaker Model Registry.
- /conf/sagemakerPipeline* – Bagian ini mendefinisikan aliran SageMaker Pipelines, termasuk ketergantungan antar langkah. Untuk kasus penggunaan model tunggal, bagian ini ditentukan di akhir file konfigurasi. Untuk kasus penggunaan multi-model, file
sagemakerPipelinebagian hanya perlu didefinisikan dalam file konfigurasi salah satu model (model mana pun). Kami menyebut model ini sebagai model jangkar. Parameternya adalah sebagai berikut:- Nama pipa* – Nama alur SageMaker.
- model* – Daftar unit pemodelan bersarang:
- {nama model}* – Pengidentifikasi model, yang harus cocok dengan pengidentifikasi {model-name} di bagian /conf/models.
- Langkah* -
- nama_langkah* – Nama langkah yang akan ditampilkan di SageMaker Pipelines DAG.
- kelas_langkah* – (Union[Pemrosesan, Pelatihan, CreateModel, Transform, Metrik, RegisterModel])
- tipe_langkah* – Parameter ini hanya diperlukan untuk langkah prapemrosesan, yang mana parameter ini harus disetel ke praproses. Hal ini diperlukan untuk membedakan langkah-langkah praproses dan evaluasi, yang keduanya memiliki a
step_classPengolahan. - aktifkan_cache – ([Persatuan[Benar, Salah]]). Ini menunjukkan apakah akan mengaktifkan Penyimpanan cache SageMaker Pipeline untuk langkah ini.
- rantai_input_sumber_langkah – ([daftar[nama_langkah]]). Anda dapat menggunakan ini untuk mengatur keluaran saluran dari langkah lain sebagai masukan untuk langkah ini.
- rantai_input_tambahan_awalan – Ini hanya diperbolehkan untuk langkah-langkah Transformasi
step_class, dan dapat digunakan bersama denganchain_input_source_stepparameter untuk menentukan file yang harus digunakan sebagai input pada langkah transformasi.
- Langkah* -
- {nama model}* – Pengidentifikasi model, yang harus cocok dengan pengidentifikasi {model-name} di bagian /conf/models.
- ketergantungan – Bagian ini menentukan urutan di mana langkah-langkah SageMaker Pipelines harus dijalankan. Kami telah mengadaptasi notasi Apache Airflow untuk bagian ini (misalnya,
{step_name} >> {step_name}). Jika bagian ini dibiarkan kosong, dependensi eksplisit ditentukan olehchain_input_source_stepparameter atau dependensi implisit menentukan aliran DAG SageMaker Pipelines.
Perhatikan bahwa kami merekomendasikan satu langkah pelatihan per unit pemodelan. Jika beberapa langkah pelatihan ditentukan untuk unit pemodelan, langkah berikutnya secara implisit mengambil langkah pelatihan terakhir untuk membuat objek model, menghitung metrik, dan mendaftarkan model. Jika Anda perlu melatih beberapa model, disarankan untuk membuat beberapa unit pemodelan.
contoh
Di bagian ini, kami mendemonstrasikan tiga contoh DAG pelatihan model ML yang dibuat menggunakan kerangka kerja yang disajikan.
Pelatihan model tunggal: LightGBM
Ini adalah contoh model tunggal untuk kasus penggunaan klasifikasi yang kami gunakan LightGBM dalam mode skrip di SageMaker. itu kumpulan data terdiri dari variabel kategori dan numerik untuk memprediksi pendapatan label biner (untuk memprediksi apakah subjek melakukan pembelian atau tidak). Itu skrip pra-pemrosesan digunakan untuk memodelkan data untuk pelatihan dan pengujian, lalu mementaskannya dalam ember S3. Jalur S3 kemudian disediakan ke langkah pelatihan dalam file konfigurasi.
Saat langkah pelatihan berjalan, SageMaker memuat file pada kontainer di /opt/ml/input/data/{channelName}/, dapat diakses melalui variabel lingkungan SM_CHANNEL_{channelName} pada wadah (channelName= 'kereta' atau 'tes').Itu naskah pelatihan melakukan hal berikut:
- Muat file secara lokal dari jalur kontainer lokal menggunakan Beban NumPy modul.
- Tetapkan hyperparameter untuk algoritma pelatihan.
- Simpan model yang dilatih di jalur kontainer lokal
/opt/ml/model/.
SageMaker mengambil konten di bawah /opt/ml/model/ untuk membuat tarball yang digunakan untuk menyebarkan model ke SageMaker untuk hosting.
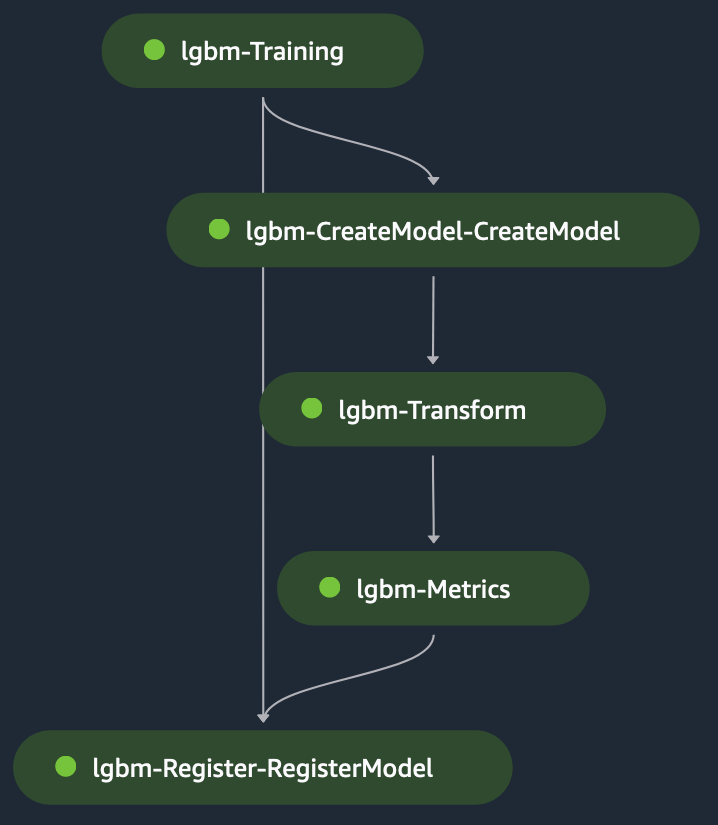
Langkah transformasi mengambil masukan dari tahapan file uji sebagai masukan dan model terlatih untuk membuat prediksi pada model terlatih. Output dari langkah transformasi adalah dirantai ke langkah metrik untuk mengevaluasi model terhadap kebenaran dasar, yang secara eksplisit diberikan ke langkah metrik. Terakhir, output dari langkah metrik secara implisit dirantai ke langkah register untuk mendaftarkan model di SageMaker Model Registry dengan informasi tentang performa model yang dihasilkan dalam langkah metrik. Gambar berikut menunjukkan representasi visual dari pelatihan DAG. Anda dapat merujuk ke skrip dan file konfigurasi untuk contoh ini di GitHub repo.
Pelatihan model tunggal: penyempurnaan LLM
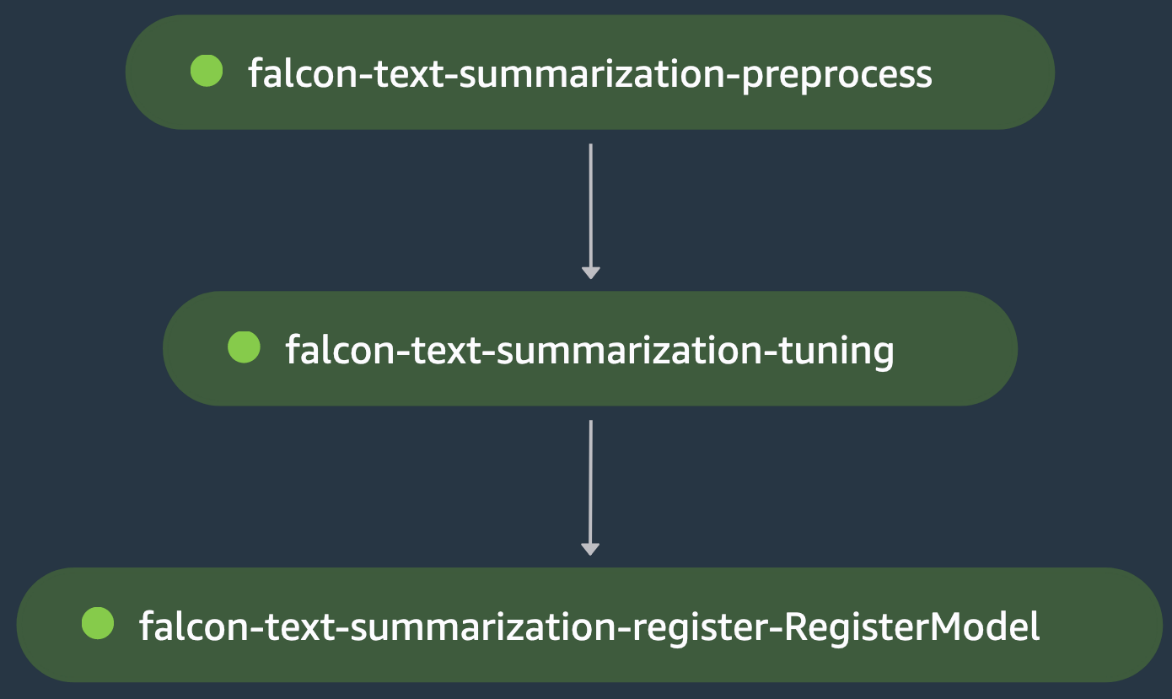
Ini adalah contoh pelatihan model tunggal lainnya, di mana kami mengatur penyempurnaan model bahasa besar (LLM) Falcon-40B dari Hugging Face Hub untuk kasus penggunaan peringkasan teks. Itu skrip pra-pemrosesan memuat samsum kumpulan data dari Hugging Face, memuat tokenizer untuk model, dan memproses pemisahan data pelatihan/pengujian untuk menyempurnakan model pada data domain ini dalam langkah praproses peringkasan teks-falcon.
Outputnya adalah dirantai ke langkah penyetelan ringkasan teks elang, di mana naskah pelatihan memuat Falcon-40B LLM dari Hugging Face Hub dan memulai penggunaan fine-tuning yang dipercepat LoRA di kereta terbelah. Model dievaluasi pada langkah yang sama setelah penyesuaian, yaitu penjaga gerbang kerugian evaluasi menggagalkan langkah penyetelan ringkasan teks elang, yang menyebabkan alur SageMaker berhenti sebelum dapat mendaftarkan model yang telah disempurnakan. Jika tidak, langkah penyetelan ringkasan teks elang berjalan dengan sukses dan model terdaftar di SageMaker Model Registry. Gambar berikut menunjukkan representasi visual DAG penyempurnaan LLM. Skrip dan file konfigurasi untuk contoh ini tersedia di GitHub repo.
Pelatihan multi-model
Ini adalah contoh pelatihan multi-model yang mana model analisis komponen utama (PCA) dilatih untuk pengurangan dimensi, dan model TensorFlow Multilayer Perceptron dilatih untuk Prediksi Harga Perumahan California. Langkah prapemrosesan model TensorFlow menggunakan model PCA terlatih untuk mengurangi dimensi data pelatihannya. Kami menambahkan ketergantungan dalam konfigurasi untuk memastikan model TensorFlow didaftarkan setelah pendaftaran model PCA. Gambar berikut menunjukkan representasi visual dari contoh DAG pelatihan multi-model. Skrip dan file konfigurasi untuk contoh ini tersedia di GitHub repo.

Membersihkan
Selesaikan langkah-langkah berikut untuk membersihkan sumber daya Anda:
- Gunakan AWS CLI untuk daftar dan menghapus semua saluran pipa yang tersisa yang dibuat oleh skrip Python.
- Secara opsional, hapus sumber daya AWS lainnya seperti bucket S3 atau IAM role yang dibuat di luar SageMaker Pipelines.
Kesimpulan
Dalam postingan ini, kami menyajikan kerangka kerja untuk mengotomatiskan pembuatan SageMaker Pipelines DAG berdasarkan file konfigurasi. Kerangka kerja yang diusulkan menawarkan solusi berwawasan ke depan terhadap tantangan mengatur beban kerja ML yang kompleks. Dengan menggunakan file konfigurasi, SageMaker Pipelines memberikan fleksibilitas untuk membangun orkestrasi dengan kode minimal, sehingga Anda dapat menyederhanakan proses pembuatan dan pengelolaan alur model tunggal dan multimodel. Pendekatan ini tidak hanya menghemat waktu dan sumber daya, namun juga mendorong praktik terbaik MLOps, sehingga berkontribusi terhadap keberhasilan inisiatif ML secara keseluruhan. Untuk informasi selengkapnya tentang detail penerapan, tinjau GitHub repo.
Tentang Penulis
 Luis Felipe Yepez Barrios, adalah Insinyur Pembelajaran Mesin dengan Layanan Profesional AWS, yang berfokus pada sistem terdistribusi yang dapat diskalakan dan alat otomatisasi untuk mempercepat inovasi ilmiah di bidang Pembelajaran Mesin (ML). Selain itu, ia membantu klien perusahaan dalam mengoptimalkan solusi pembelajaran mesin mereka melalui layanan AWS.
Luis Felipe Yepez Barrios, adalah Insinyur Pembelajaran Mesin dengan Layanan Profesional AWS, yang berfokus pada sistem terdistribusi yang dapat diskalakan dan alat otomatisasi untuk mempercepat inovasi ilmiah di bidang Pembelajaran Mesin (ML). Selain itu, ia membantu klien perusahaan dalam mengoptimalkan solusi pembelajaran mesin mereka melalui layanan AWS.
 Jinzhao Feng, adalah Insinyur Pembelajaran Mesin di AWS Professional Services. Dia berfokus pada perancangan dan penerapan AI Generatif skala besar dan solusi pipeline ML klasik. Dia berspesialisasi dalam FMOps, LLMOps, dan pelatihan terdistribusi.
Jinzhao Feng, adalah Insinyur Pembelajaran Mesin di AWS Professional Services. Dia berfokus pada perancangan dan penerapan AI Generatif skala besar dan solusi pipeline ML klasik. Dia berspesialisasi dalam FMOps, LLMOps, dan pelatihan terdistribusi.
 Asnani yang kejam, adalah Insinyur Pembelajaran Mesin di AWS. Latar belakangnya adalah Ilmu Data Terapan dengan fokus pada operasionalisasi beban kerja Machine Learning di cloud dalam skala besar.
Asnani yang kejam, adalah Insinyur Pembelajaran Mesin di AWS. Latar belakangnya adalah Ilmu Data Terapan dengan fokus pada operasionalisasi beban kerja Machine Learning di cloud dalam skala besar.
 Hasan Shojaei, adalah Ilmuwan Data Senior di Layanan Profesional AWS, yang membantu pelanggan di berbagai industri memecahkan tantangan bisnis mereka melalui penggunaan data besar, pembelajaran mesin, dan teknologi cloud. Sebelum menduduki jabatan ini, Hasan memimpin berbagai inisiatif untuk mengembangkan teknik pemodelan baru berbasis fisika dan berbasis data untuk perusahaan-perusahaan energi terkemuka. Di luar pekerjaan, Hasan sangat menyukai buku, hiking, fotografi, dan sejarah.
Hasan Shojaei, adalah Ilmuwan Data Senior di Layanan Profesional AWS, yang membantu pelanggan di berbagai industri memecahkan tantangan bisnis mereka melalui penggunaan data besar, pembelajaran mesin, dan teknologi cloud. Sebelum menduduki jabatan ini, Hasan memimpin berbagai inisiatif untuk mengembangkan teknik pemodelan baru berbasis fisika dan berbasis data untuk perusahaan-perusahaan energi terkemuka. Di luar pekerjaan, Hasan sangat menyukai buku, hiking, fotografi, dan sejarah.
 Alec Jenab, adalah Insinyur Pembelajaran Mesin yang berspesialisasi dalam pengembangan dan pengoperasian solusi pembelajaran mesin dalam skala besar untuk pelanggan perusahaan. Alec bersemangat untuk menghadirkan solusi inovatif ke pasar, terutama di area di mana pembelajaran mesin dapat meningkatkan pengalaman pengguna akhir secara signifikan. Di luar pekerjaan, dia menikmati bermain bola basket, seluncur salju, dan menemukan permata tersembunyi di San Francisco.
Alec Jenab, adalah Insinyur Pembelajaran Mesin yang berspesialisasi dalam pengembangan dan pengoperasian solusi pembelajaran mesin dalam skala besar untuk pelanggan perusahaan. Alec bersemangat untuk menghadirkan solusi inovatif ke pasar, terutama di area di mana pembelajaran mesin dapat meningkatkan pengalaman pengguna akhir secara signifikan. Di luar pekerjaan, dia menikmati bermain bola basket, seluncur salju, dan menemukan permata tersembunyi di San Francisco.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/automate-amazon-sagemaker-pipelines-dag-creation/

