Maraknya penelusuran kontekstual dan semantik telah membuat bisnis e-niaga dan ritel melakukan penelusuran dengan mudah bagi konsumennya. Mesin pencari dan sistem rekomendasi yang didukung oleh AI generatif dapat meningkatkan pengalaman pencarian produk secara eksponensial dengan memahami kueri bahasa alami dan memberikan hasil yang lebih akurat. Hal ini meningkatkan pengalaman pengguna secara keseluruhan, membantu pelanggan menemukan apa yang mereka cari.
Layanan Pencarian Terbuka Amazon sekarang mendukung kesamaan cosinus metrik untuk indeks k-NN. Kesamaan cosinus mengukur cosinus sudut antara dua vektor, di mana sudut cosinus yang lebih kecil menunjukkan kesamaan yang lebih tinggi antara vektor. Dengan kesamaan cosinus, Anda dapat mengukur orientasi antara dua vektor, yang menjadikannya pilihan yang baik untuk beberapa aplikasi pencarian semantik tertentu.
Dalam postingan ini, kami menunjukkan cara membuat mesin pencari teks dan gambar kontekstual untuk rekomendasi produk menggunakan Model Penyematan Multimodal Amazon Titan, tersedia di Batuan Dasar Amazon, dengan Amazon OpenSearch Tanpa Server.
Model penyematan multimodal dirancang untuk mempelajari representasi gabungan dari berbagai modalitas seperti teks, gambar, dan audio. Dengan melatih kumpulan data berskala besar yang berisi gambar dan keterangan terkait, model penyematan multimodal belajar menyematkan gambar dan teks ke dalam ruang laten bersama. Berikut ini adalah ikhtisar tingkat tinggi tentang cara kerjanya secara konseptual:
- Pembuat enkode terpisah – Model ini memiliki encoder terpisah untuk setiap modalitas—encoder teks untuk teks (misalnya, BERT atau RoBERTa), encoder gambar untuk gambar (misalnya, CNN untuk gambar), dan encoder audio untuk audio (misalnya, model seperti Wav2Vec) . Setiap pembuat enkode menghasilkan penyematan yang menangkap fitur semantik dari modalitasnya masing-masing
- Penggabungan modalitas – Penyematan dari pembuat enkode uni-modal digabungkan menggunakan lapisan jaringan saraf tambahan. Tujuannya adalah untuk mempelajari interaksi dan korelasi antar modalitas. Pendekatan fusi yang umum mencakup penggabungan, operasi berdasarkan elemen, penyatuan, dan mekanisme perhatian.
- Ruang representasi bersama – Lapisan fusi membantu memproyeksikan modalitas individu ke dalam ruang representasi bersama. Dengan melatih kumpulan data multimodal, model mempelajari ruang penyematan umum di mana penyematan dari setiap modalitas yang mewakili konten semantik dasar yang sama ditempatkan lebih berdekatan.
- Tugas hilir – Penyematan multimodal gabungan yang dihasilkan kemudian dapat digunakan untuk berbagai tugas hilir seperti pengambilan multimodal, klasifikasi, atau penerjemahan. Model ini menggunakan korelasi antar modalitas untuk meningkatkan performa pada tugas-tugas ini dibandingkan dengan penyematan modal individual. Keuntungan utamanya adalah kemampuan untuk memahami interaksi dan semantik antara modalitas seperti teks, gambar, dan audio melalui pemodelan bersama.
Ikhtisar solusi
Solusi ini menyediakan implementasi untuk membangun prototipe mesin pencari bertenaga model bahasa besar (LLM) untuk mengambil dan merekomendasikan produk berdasarkan kueri teks atau gambar. Kami merinci langkah-langkah untuk menggunakan Penyematan Multimodal Amazon Titan model untuk menyandikan gambar dan teks ke dalam penyematan, menyerap penyematan ke dalam indeks Layanan OpenSearch, dan menanyakan indeks menggunakan Layanan OpenSearch fungsionalitas k-tetangga terdekat (k-NN)..
Solusi ini mencakup komponen berikut:
- Model Penyematan Multimodal Amazon Titan – Model dasar (FM) ini menghasilkan penyematan gambar produk yang digunakan dalam postingan ini. Dengan Amazon Titan Multimodal Embeddings, Anda dapat membuat embeddings untuk konten Anda dan menyimpannya dalam database vektor. Saat pengguna akhir mengirimkan kombinasi teks dan gambar apa pun sebagai kueri penelusuran, model akan menghasilkan penyematan untuk kueri penelusuran tersebut dan mencocokkannya dengan penyematan yang disimpan untuk memberikan hasil penelusuran dan rekomendasi yang relevan kepada pengguna akhir. Anda dapat menyesuaikan model lebih lanjut untuk meningkatkan pemahamannya tentang konten unik Anda dan memberikan hasil yang lebih bermakna menggunakan pasangan gambar-teks untuk penyesuaian. Secara default, model menghasilkan vektor (penyematan) sebanyak 1,024 dimensi, dan diakses melalui Amazon Bedrock. Anda juga dapat membuat dimensi yang lebih kecil untuk mengoptimalkan kecepatan dan kinerja
- Amazon OpenSearch Tanpa Server – Ini adalah konfigurasi tanpa server berdasarkan permintaan untuk Layanan OpenSearch. Kami menggunakan Amazon OpenSearch Tanpa Server sebagai database vektor untuk menyimpan embeddings yang dihasilkan oleh model Amazon Titan Multimodal Embeddings. Indeks yang dibuat dalam koleksi Amazon OpenSearch Serverless berfungsi sebagai penyimpanan vektor untuk solusi Retrieval Augmented Generation (RAG) kami.
- Studio Amazon SageMaker – Ini adalah lingkungan pengembangan terintegrasi (IDE) untuk pembelajaran mesin (ML). Praktisi ML dapat melakukan semua langkah pengembangan ML—mulai dari menyiapkan data hingga membangun, melatih, dan menerapkan model ML.
Desain solusi terdiri dari dua bagian: pengindeksan data dan pencarian kontekstual. Selama pengindeksan data, Anda memproses gambar produk untuk menghasilkan penyematan untuk gambar tersebut dan kemudian mengisi penyimpanan data vektor. Langkah-langkah ini diselesaikan sebelum langkah-langkah interaksi pengguna.
Pada fase pencarian kontekstual, permintaan pencarian (teks atau gambar) dari pengguna diubah menjadi embeddings dan pencarian kesamaan dijalankan pada database vektor untuk menemukan gambar produk serupa berdasarkan pencarian kesamaan. Anda kemudian menampilkan hasil serupa teratas. Semua kode untuk posting ini tersedia di GitHub repo.
Diagram berikut menggambarkan arsitektur solusi.

Berikut ini adalah langkah-langkah alur kerja solusi:
- Unduh teks deskripsi produk dan gambar dari publik Layanan Penyimpanan Sederhana Amazon (Amazon S3).
- Tinjau dan siapkan kumpulan data.
- Hasilkan penyematan untuk gambar produk menggunakan model Amazon Titan Multimodal Embeddings (amazon.titan-embed-image-v1). Jika Anda memiliki banyak gambar dan deskripsi, Anda dapat menggunakan Inferensi batch untuk Amazon Bedrock.
- Simpan penyematan ke dalam Amazon OpenSearch Tanpa Server sebagai mesin pencari.
- Terakhir, ambil kueri pengguna dalam bahasa alami, ubah menjadi embeddings menggunakan model Amazon Titan Multimodal Embeddings, dan lakukan pencarian k-NN untuk mendapatkan hasil pencarian yang relevan.
Kami menggunakan SageMaker Studio (tidak ditampilkan dalam diagram) sebagai IDE untuk mengembangkan solusinya.
Langkah-langkah ini dibahas secara rinci di bagian berikut. Kami juga menyertakan tangkapan layar dan detail keluarannya.
Prasyarat
Untuk menerapkan solusi yang disediakan dalam postingan ini, Anda harus memiliki yang berikut:
- An Akun AWS dan keakraban dengan FM, Amazon Bedrock, Amazon SageMaker, dan Layanan OpenSearch.
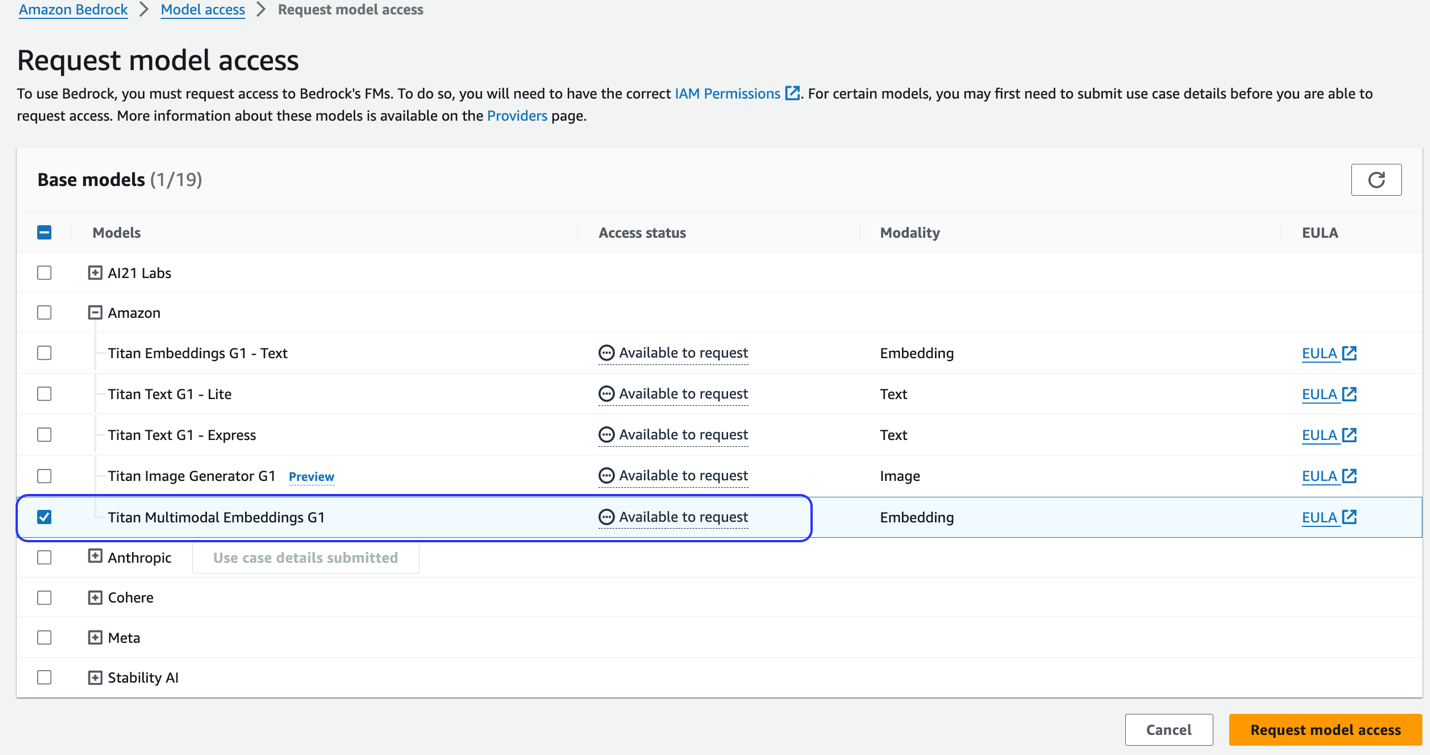
- Model Amazon Titan Multimodal Embeddings diaktifkan di Amazon Bedrock. Anda dapat mengonfirmasi bahwa ini diaktifkan di Akses model halaman konsol Amazon Bedrock. Jika Amazon Titan Multimodal Embeddings diaktifkan, status akses akan ditampilkan sebagai Akses diberikan, seperti yang ditunjukkan pada tangkapan layar berikut.

Jika model tidak tersedia, aktifkan akses ke model dengan memilih Kelola akses model, memilih Penyematan Multimodal Amazon Titan G1, dan memilih Minta akses model. Model ini segera diaktifkan untuk digunakan.
Siapkan solusinya
Ketika langkah-langkah prasyarat selesai, Anda siap menyiapkan solusinya:
- Di akun AWS Anda, buka konsol SageMaker dan pilih studio di panel navigasi.
- Pilih domain dan profil pengguna Anda, lalu pilih Buka Studio.
Nama domain dan profil pengguna Anda mungkin berbeda.

- Pilih Terminal sistem bawah Utilitas dan file.
- Jalankan perintah berikut untuk mengkloning GitHub repo ke instance SageMaker Studio:
- Arahkan ke folder
multimodal/Titan/titan-multimodal-embeddings/amazon-bedrock-multimodal-oss-searchengine-e2efolder. - Buka
titan_mm_embed_search_blog.ipynbbuku catatan.
Jalankan solusinya
Buka file titan_mm_embed_search_blog.ipynb dan gunakan kernel Data Science Python 3. Di Run menu, pilih Jalankan Semua Sel untuk menjalankan kode di buku catatan ini.
Buku catatan ini melakukan langkah-langkah berikut:
- Instal paket dan perpustakaan yang diperlukan untuk solusi ini.
- Muat yang tersedia untuk umum Kumpulan Data Objek Amazon Berkeley dan metadata dalam bingkai data pandas.
Kumpulan datanya adalah kumpulan 147,702 daftar produk dengan metadata multibahasa dan 398,212 gambar katalog unik. Untuk postingan ini, Anda hanya menggunakan gambar item dan nama item dalam bahasa Inggris AS. Anda menggunakan sekitar 1,600 produk.

- Hasilkan penyematan untuk gambar item menggunakan model Amazon Titan Multimodal Embeddings menggunakan
get_titan_multomodal_embedding()fungsi. Demi abstraksi, kami telah mendefinisikan semua fungsi penting yang digunakan dalam buku catatan ini diutils.pyfile.

Selanjutnya, Anda membuat dan menyiapkan penyimpanan vektor Amazon OpenSearch Tanpa Server (koleksi dan indeks).
- Sebelum Anda membuat koleksi dan indeks pencarian vektor baru, Anda harus terlebih dahulu membuat tiga kebijakan Layanan OpenSearch terkait: kebijakan keamanan enkripsi, kebijakan keamanan jaringan, dan kebijakan akses data.


- Terakhir, serap gambar yang disematkan ke dalam indeks vektor.

Sekarang Anda dapat melakukan pencarian multimoda secara real-time.
Jalankan pencarian kontekstual
Di bagian ini, kami menampilkan hasil pencarian kontekstual berdasarkan kueri teks atau gambar.
Pertama, mari kita lakukan pencarian gambar berdasarkan input teks. Pada contoh berikut, kami menggunakan input teks “gelas perlengkapan minum” dan mengirimkannya ke mesin pencari untuk menemukan item serupa.

Tangkapan layar berikut menunjukkan hasilnya.

Sekarang mari kita lihat hasilnya berdasarkan gambar sederhana. Gambar masukan diubah menjadi penyematan vektor dan, berdasarkan penelusuran kesamaan, model mengembalikan hasilnya.
Anda dapat menggunakan gambar apa pun, tetapi untuk contoh berikut, kami menggunakan gambar acak dari kumpulan data berdasarkan ID item (misalnya, item_id = “B07JCDQWM6”), lalu kirimkan gambar ini ke mesin pencari untuk menemukan item serupa.

Tangkapan layar berikut menunjukkan hasilnya.

Membersihkan
Untuk menghindari timbulnya biaya di masa mendatang, hapus sumber daya yang digunakan dalam solusi ini. Anda dapat melakukan ini dengan menjalankan bagian pembersihan buku catatan.

Kesimpulan
Postingan ini menyajikan panduan penggunaan model Amazon Titan Multimodal Embeddings di Amazon Bedrock untuk membangun aplikasi pencarian kontekstual yang kuat. Secara khusus, kami mendemonstrasikan contoh aplikasi pencarian daftar produk. Kami melihat bagaimana model penyematan memungkinkan penemuan informasi yang efisien dan akurat dari gambar dan data tekstual, sehingga meningkatkan pengalaman pengguna saat mencari item yang relevan.
Amazon Titan Multimodal Embeddings membantu Anda mendukung pengalaman pencarian, rekomendasi, dan personalisasi multimodal yang lebih akurat dan relevan secara kontekstual bagi pengguna akhir. Misalnya, sebuah perusahaan fotografi stok dengan ratusan juta gambar dapat menggunakan model tersebut untuk memperkuat fungsi penelusurannya, sehingga pengguna dapat menelusuri gambar menggunakan frasa, gambar, atau kombinasi gambar dan teks.
Model Amazon Titan Multimodal Embeddings di Amazon Bedrock kini tersedia di Wilayah AWS AS Timur (Virginia Utara) dan AS Barat (Oregon). Untuk mempelajari lebih lanjut, lihat Amazon Titan Image Generator, Multimodal Embeddings, dan model Teks kini tersedia di Amazon Bedrock, yang Halaman produk Amazon Titan, Dan Panduan Pengguna Batuan Dasar Amazon. Untuk memulai Amazon Titan Multimodal Embeddings di Amazon Bedrock, kunjungi Konsol Amazon Bedrock.
Mulai membangun dengan model Amazon Titan Multimodal Embeddings di Batuan Dasar Amazon hari ini.
Tentang Penulis
 Sandeep Singh adalah Ilmuwan Data AI Generatif Senior di Amazon Web Services, yang membantu bisnis berinovasi dengan AI generatif. Ia berspesialisasi dalam AI Generatif, Kecerdasan Buatan, Pembelajaran Mesin, dan Desain Sistem. Dia bersemangat mengembangkan solusi canggih yang didukung AI/ML untuk memecahkan masalah bisnis yang kompleks untuk beragam industri, mengoptimalkan efisiensi dan skalabilitas.
Sandeep Singh adalah Ilmuwan Data AI Generatif Senior di Amazon Web Services, yang membantu bisnis berinovasi dengan AI generatif. Ia berspesialisasi dalam AI Generatif, Kecerdasan Buatan, Pembelajaran Mesin, dan Desain Sistem. Dia bersemangat mengembangkan solusi canggih yang didukung AI/ML untuk memecahkan masalah bisnis yang kompleks untuk beragam industri, mengoptimalkan efisiensi dan skalabilitas.
 Mani Khanuja adalah Pimpinan Teknologi – Spesialis AI Generatif, penulis buku Applied Machine Learning and High Performance Computing on AWS, dan anggota Dewan Direksi Women in Manufacturing Education Foundation Board. Dia memimpin proyek pembelajaran mesin di berbagai domain seperti visi komputer, pemrosesan bahasa alami, dan AI generatif. Dia berbicara di konferensi internal dan eksternal seperti AWS re:Invent, Women in Manufacturing West, webinar YouTube, dan GHC 23. Di waktu luangnya, dia suka berjalan-jalan di sepanjang pantai.
Mani Khanuja adalah Pimpinan Teknologi – Spesialis AI Generatif, penulis buku Applied Machine Learning and High Performance Computing on AWS, dan anggota Dewan Direksi Women in Manufacturing Education Foundation Board. Dia memimpin proyek pembelajaran mesin di berbagai domain seperti visi komputer, pemrosesan bahasa alami, dan AI generatif. Dia berbicara di konferensi internal dan eksternal seperti AWS re:Invent, Women in Manufacturing West, webinar YouTube, dan GHC 23. Di waktu luangnya, dia suka berjalan-jalan di sepanjang pantai.
 Rupinder Grewal adalah Arsitek Solusi Spesialis AI/ML Senior di AWS. Saat ini dia berfokus pada penyajian model dan MLOps di Amazon SageMaker. Sebelumnya, dia bekerja sebagai Machine Learning Engineer yang membuat dan menghosting model. Di luar pekerjaan, dia menikmati bermain tenis dan bersepeda di jalur pegunungan.
Rupinder Grewal adalah Arsitek Solusi Spesialis AI/ML Senior di AWS. Saat ini dia berfokus pada penyajian model dan MLOps di Amazon SageMaker. Sebelumnya, dia bekerja sebagai Machine Learning Engineer yang membuat dan menghosting model. Di luar pekerjaan, dia menikmati bermain tenis dan bersepeda di jalur pegunungan.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/build-a-contextual-text-and-image-search-engine-for-product-recommendations-using-amazon-bedrock-and-amazon-opensearch-serverless/

