Pada intinya, LangChain adalah kerangka kerja inovatif yang dirancang untuk membuat aplikasi yang memanfaatkan kemampuan model bahasa. Ini adalah perangkat yang dirancang bagi pengembang untuk membuat aplikasi yang sadar konteks dan mampu memberikan alasan yang canggih.
Ini berarti aplikasi LangChain dapat memahami konteksnya, seperti instruksi cepat atau respons berdasarkan konten dan menggunakan model bahasa untuk tugas penalaran yang kompleks, seperti memutuskan bagaimana merespons atau tindakan apa yang harus diambil. LangChain mewakili pendekatan terpadu untuk mengembangkan aplikasi cerdas, menyederhanakan perjalanan dari konsep hingga eksekusi dengan beragam komponennya.
Memahami LangChain
LangChain lebih dari sekedar kerangka kerja; ini adalah ekosistem lengkap yang terdiri dari beberapa bagian integral.
- Pertama, ada Perpustakaan LangChain, tersedia dalam Python dan JavaScript. Pustaka ini adalah tulang punggung LangChain, menawarkan antarmuka dan integrasi untuk berbagai komponen. Mereka menyediakan runtime dasar untuk menggabungkan komponen-komponen ini ke dalam rantai dan agen yang kohesif, bersama dengan implementasi siap pakai untuk segera digunakan.
- Selanjutnya, kita memiliki Template LangChain. Ini adalah kumpulan arsitektur referensi yang dapat diterapkan dan disesuaikan untuk beragam tugas. Baik Anda membuat chatbot atau alat analisis yang kompleks, templat ini menawarkan titik awal yang kuat.
- LangServe berperan sebagai perpustakaan serbaguna untuk menerapkan rantai LangChain sebagai REST API. Alat ini penting untuk mengubah proyek LangChain Anda menjadi layanan web yang dapat diakses dan terukur.
- Terakhir, LangSmith berfungsi sebagai platform pengembang. Ini dirancang untuk melakukan debug, menguji, mengevaluasi, dan memantau rantai yang dibangun pada kerangka LLM apa pun. Integrasi yang mulus dengan LangChain menjadikannya alat yang sangat diperlukan bagi pengembang yang ingin menyempurnakan dan menyempurnakan aplikasi mereka.
Bersama-sama, komponen-komponen ini memberdayakan Anda untuk mengembangkan, memproduksi, dan menerapkan aplikasi dengan mudah. Dengan LangChain, Anda mulai dengan menulis aplikasi Anda menggunakan perpustakaan, merujuk template untuk panduan. LangSmith kemudian membantu Anda dalam memeriksa, menguji, dan memantau rantai Anda, memastikan bahwa aplikasi Anda terus meningkat dan siap untuk diterapkan. Terakhir, dengan LangServe, Anda dapat dengan mudah mengubah rantai apa pun menjadi API, sehingga penerapannya menjadi mudah.
Di bagian selanjutnya, kita akan mempelajari lebih dalam tentang cara menyiapkan LangChain dan memulai perjalanan Anda dalam menciptakan aplikasi cerdas yang didukung model bahasa.
Otomatiskan tugas dan alur kerja manual dengan pembuat alur kerja berbasis AI kami, yang dirancang oleh Nanonets untuk Anda dan tim Anda.
Instalasi dan Pengaturan
Apakah Anda siap untuk terjun ke dunia LangChain? Menyiapkannya sangatlah mudah, dan panduan ini akan memandu Anda melalui prosesnya langkah demi langkah.
Langkah pertama dalam perjalanan LangChain Anda adalah menginstalnya. Anda dapat melakukannya dengan mudah menggunakan pip atau conda. Jalankan perintah berikut di terminal Anda:
pip install langchain
Bagi mereka yang lebih menyukai fitur-fitur terbaru dan merasa nyaman dengan lebih banyak petualangan, Anda dapat menginstal LangChain langsung dari sumbernya. Kloning repositori dan navigasikan ke langchain/libs/langchain direktori. Lalu lari:
pip install -e .
Untuk fitur eksperimental, pertimbangkan untuk menginstal langchain-experimental. Ini adalah paket yang berisi kode mutakhir dan ditujukan untuk tujuan penelitian dan eksperimental. Instal menggunakan:
pip install langchain-experimental
LangChain CLI adalah alat praktis untuk bekerja dengan templat LangChain dan proyek LangServe. Untuk menginstal LangChain CLI, gunakan:
pip install langchain-cli
LangServe sangat penting untuk menerapkan rantai LangChain Anda sebagai REST API. Itu diinstal bersama LangChain CLI.
LangChain sering kali memerlukan integrasi dengan penyedia model, penyimpanan data, API, dll. Untuk contoh ini, kita akan menggunakan API model OpenAI. Instal paket OpenAI Python menggunakan:
pip install openai
Untuk mengakses API, atur kunci OpenAI API Anda sebagai variabel lingkungan:
export OPENAI_API_KEY="your_api_key"
Alternatifnya, teruskan kunci langsung di lingkungan python Anda:
import os
os.environ['OPENAI_API_KEY'] = 'your_api_key'
LangChain memungkinkan pembuatan aplikasi model bahasa melalui modul. Modul-modul ini dapat berdiri sendiri atau disusun untuk kasus penggunaan yang kompleks. Modul-modul ini adalah –
- Model I / O: Memfasilitasi interaksi dengan berbagai model bahasa, menangani masukan dan keluarannya secara efisien.
- Pengambilan: Memungkinkan akses dan interaksi dengan data spesifik aplikasi, yang penting untuk pemanfaatan data dinamis.
- Agen: Memberdayakan aplikasi untuk memilih alat yang sesuai berdasarkan arahan tingkat tinggi, sehingga meningkatkan kemampuan pengambilan keputusan.
- Rantai: Menawarkan komposisi yang telah ditentukan sebelumnya dan dapat digunakan kembali yang berfungsi sebagai landasan pengembangan aplikasi.
- Memori: Mempertahankan status aplikasi di beberapa eksekusi rantai, penting untuk interaksi sadar konteks.
Setiap modul menargetkan kebutuhan pengembangan spesifik, menjadikan LangChain sebagai perangkat komprehensif untuk membuat aplikasi model bahasa tingkat lanjut.
Selain komponen di atas, kami juga punya Bahasa Ekspresi LangChain (LCEL), yang merupakan cara deklaratif untuk menyusun modul dengan mudah, dan ini memungkinkan rangkaian komponen menggunakan antarmuka Runnable universal.
LCEL terlihat seperti ini –
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import BaseOutputParser # Example chain
chain = ChatPromptTemplate() | ChatOpenAI() | CustomOutputParser()
Sekarang setelah kita membahas dasar-dasarnya, kita akan melanjutkan ke:
- Gali lebih dalam setiap modul Langchain secara detail.
- Pelajari cara menggunakan Bahasa Ekspresi LangChain.
- Jelajahi kasus penggunaan umum dan terapkan.
- Terapkan aplikasi end-to-end dengan LangServe.
- Lihat LangSmith untuk debugging, pengujian, dan pemantauan.
Mari kita mulai!
Modul I : Model I/O
Di LangChain, elemen inti aplikasi apa pun berkisar pada model bahasa. Modul ini menyediakan landasan penting untuk berinteraksi secara efektif dengan model bahasa apa pun, memastikan integrasi dan komunikasi yang lancar.
Komponen Utama Model I/O
- LLM dan Model Obrolan (digunakan secara bergantian):
- LLM:
- Definisi: Model penyelesaian teks murni.
- Input / Output: Ambil string teks sebagai masukan dan kembalikan string teks sebagai keluaran.
- Model Obrolan
- LLM:
- Definisi: Model yang menggunakan model bahasa sebagai basisnya tetapi berbeda dalam format input dan output.
- Input / Output: Menerima daftar pesan obrolan sebagai masukan dan mengembalikan Pesan Obrolan.
- Anjuran: Membuat template, memilih secara dinamis, dan mengelola input model. Memungkinkan pembuatan perintah yang fleksibel dan spesifik konteks yang memandu respons model bahasa.
- Parser Keluaran: Mengekstrak dan memformat informasi dari keluaran model. Berguna untuk mengubah keluaran mentah model bahasa menjadi data terstruktur atau format tertentu yang dibutuhkan oleh aplikasi.
LLM
Integrasi LangChain dengan Large Language Model (LLM) seperti OpenAI, Cohere, dan Hugging Face merupakan aspek mendasar dari fungsinya. LangChain sendiri tidak menghosting LLM tetapi menawarkan antarmuka yang seragam untuk berinteraksi dengan berbagai LLM.
Bagian ini memberikan gambaran umum tentang penggunaan wrapper OpenAI LLM di LangChain, yang juga berlaku untuk jenis LLM lainnya. Kami telah menginstalnya di bagian “Memulai”. Mari kita inisialisasi LLM.
from langchain.llms import OpenAI
llm = OpenAI()
- LLM menerapkan Antarmuka yang dapat dijalankan, blok bangunan dasar Bahasa Ekspresi LangChain (LCEL). Artinya mereka mendukung
invoke,ainvoke,stream,astream,batch,abatch,astream_logpanggilan. - LLM menerima string sebagai masukan, atau objek yang dapat dipaksakan ke perintah string, termasuk
List[BaseMessage]danPromptValue. (lebih lanjut tentang ini nanti)
Mari kita lihat beberapa contoh.
response = llm.invoke("List the seven wonders of the world.")
print(response)

Sebagai alternatif, Anda dapat memanggil metode streaming untuk mengalirkan respons teks.
for chunk in llm.stream("Where were the 2012 Olympics held?"): print(chunk, end="", flush=True)

Model Obrolan
Integrasi LangChain dengan model obrolan, variasi khusus model bahasa, sangat penting untuk membuat aplikasi obrolan interaktif. Meskipun mereka menggunakan model bahasa secara internal, model obrolan menghadirkan antarmuka berbeda yang berpusat di sekitar pesan obrolan sebagai masukan dan keluaran. Bagian ini memberikan gambaran rinci tentang penggunaan model obrolan OpenAI di LangChain.
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
Model obrolan di LangChain berfungsi dengan berbagai jenis pesan seperti AIMessage, HumanMessage, SystemMessage, FunctionMessage, dan ChatMessage (dengan parameter peran yang berubah-ubah). Umumnya, HumanMessage, AIMessage, dan SystemMessage adalah yang paling sering digunakan.
Model obrolan pada dasarnya menerima List[BaseMessage] sebagai masukan. String dapat dikonversi menjadi HumanMessage, dan PromptValue juga didukung.
from langchain.schema.messages import HumanMessage, SystemMessage
messages = [ SystemMessage(content="You are Micheal Jordan."), HumanMessage(content="Which shoe manufacturer are you associated with?"),
]
response = chat.invoke(messages)
print(response.content)
Anjuran
Anjuran sangat penting dalam memandu model bahasa untuk menghasilkan keluaran yang relevan dan koheren. Mulai dari instruksi sederhana hingga contoh beberapa contoh yang rumit. Di LangChain, penanganan perintah bisa menjadi proses yang sangat efisien, berkat beberapa kelas dan fungsi khusus.
milik LangChain PromptTemplate class adalah alat serbaguna untuk membuat prompt string. Ini menggunakan Python str.format sintaksis, memungkinkan pembuatan prompt dinamis. Anda dapat menentukan templat dengan placeholder dan mengisinya dengan nilai spesifik sesuai kebutuhan.
from langchain.prompts import PromptTemplate # Simple prompt with placeholders
prompt_template = PromptTemplate.from_template( "Tell me a {adjective} joke about {content}."
) # Filling placeholders to create a prompt
filled_prompt = prompt_template.format(adjective="funny", content="robots")
print(filled_prompt)Untuk model obrolan, perintahnya lebih terstruktur, melibatkan pesan dengan peran tertentu. Penawaran LangChain ChatPromptTemplate untuk tujuan ini.
from langchain.prompts import ChatPromptTemplate # Defining a chat prompt with various roles
chat_template = ChatPromptTemplate.from_messages( [ ("system", "You are a helpful AI bot. Your name is {name}."), ("human", "Hello, how are you doing?"), ("ai", "I'm doing well, thanks!"), ("human", "{user_input}"), ]
) # Formatting the chat prompt
formatted_messages = chat_template.format_messages(name="Bob", user_input="What is your name?")
for message in formatted_messages: print(message)
Pendekatan ini memungkinkan terciptanya chatbot yang interaktif dan menarik dengan respons yang dinamis.
Kedua PromptTemplate dan ChatPromptTemplate terintegrasi secara mulus dengan LangChain Expression Language (LCEL), memungkinkan mereka menjadi bagian dari alur kerja yang lebih besar dan kompleks. Kami akan membahas lebih lanjut tentang ini nanti.
Templat prompt khusus terkadang penting untuk tugas yang memerlukan pemformatan unik atau instruksi khusus. Membuat templat prompt khusus melibatkan penentuan variabel masukan dan metode pemformatan khusus. Fleksibilitas ini memungkinkan LangChain untuk memenuhi beragam kebutuhan spesifik aplikasi. Baca lebih lanjut di sini.
LangChain juga mendukung beberapa langkah, memungkinkan model untuk belajar dari contoh. Fitur ini sangat penting untuk tugas yang memerlukan pemahaman kontekstual atau pola tertentu. Templat prompt beberapa gambar dapat dibuat dari serangkaian contoh atau dengan memanfaatkan objek Pemilih Contoh. Baca lebih lanjut di sini.
Parser Keluaran
Pengurai keluaran memainkan peran penting dalam Langchain, memungkinkan pengguna menyusun respons yang dihasilkan oleh model bahasa. Di bagian ini, kita akan mengeksplorasi konsep parser keluaran dan memberikan contoh kode menggunakan PydanticOutputParser Langchain, SimpleJsonOutputParser, CommaSeparatedListOutputParser, DatetimeOutputParser, dan XMLOutputParser.
Parser Keluaran Pydantic
Langchain menyediakan PydanticOutputParser untuk mengurai respons ke dalam struktur data Pydantic. Di bawah ini adalah contoh langkah demi langkah cara menggunakannya:
from typing import List
from langchain.llms import OpenAI
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import PromptTemplate
from langchain.pydantic_v1 import BaseModel, Field, validator # Initialize the language model
model = OpenAI(model_name="text-davinci-003", temperature=0.0) # Define your desired data structure using Pydantic
class Joke(BaseModel): setup: str = Field(description="question to set up a joke") punchline: str = Field(description="answer to resolve the joke") @validator("setup") def question_ends_with_question_mark(cls, field): if field[-1] != "?": raise ValueError("Badly formed question!") return field # Set up a PydanticOutputParser
parser = PydanticOutputParser(pydantic_object=Joke) # Create a prompt with format instructions
prompt = PromptTemplate( template="Answer the user query.n{format_instructions}n{query}n", input_variables=["query"], partial_variables={"format_instructions": parser.get_format_instructions()},
) # Define a query to prompt the language model
query = "Tell me a joke." # Combine prompt, model, and parser to get structured output
prompt_and_model = prompt | model
output = prompt_and_model.invoke({"query": query}) # Parse the output using the parser
parsed_result = parser.invoke(output) # The result is a structured object
print(parsed_result)
output akan:

SimpleJsonOutputParser
SimpleJsonOutputParser Langchain digunakan saat Anda ingin mengurai keluaran seperti JSON. Berikut ini contohnya:
from langchain.output_parsers.json import SimpleJsonOutputParser # Create a JSON prompt
json_prompt = PromptTemplate.from_template( "Return a JSON object with `birthdate` and `birthplace` key that answers the following question: {question}"
) # Initialize the JSON parser
json_parser = SimpleJsonOutputParser() # Create a chain with the prompt, model, and parser
json_chain = json_prompt | model | json_parser # Stream through the results
result_list = list(json_chain.stream({"question": "When and where was Elon Musk born?"})) # The result is a list of JSON-like dictionaries
print(result_list)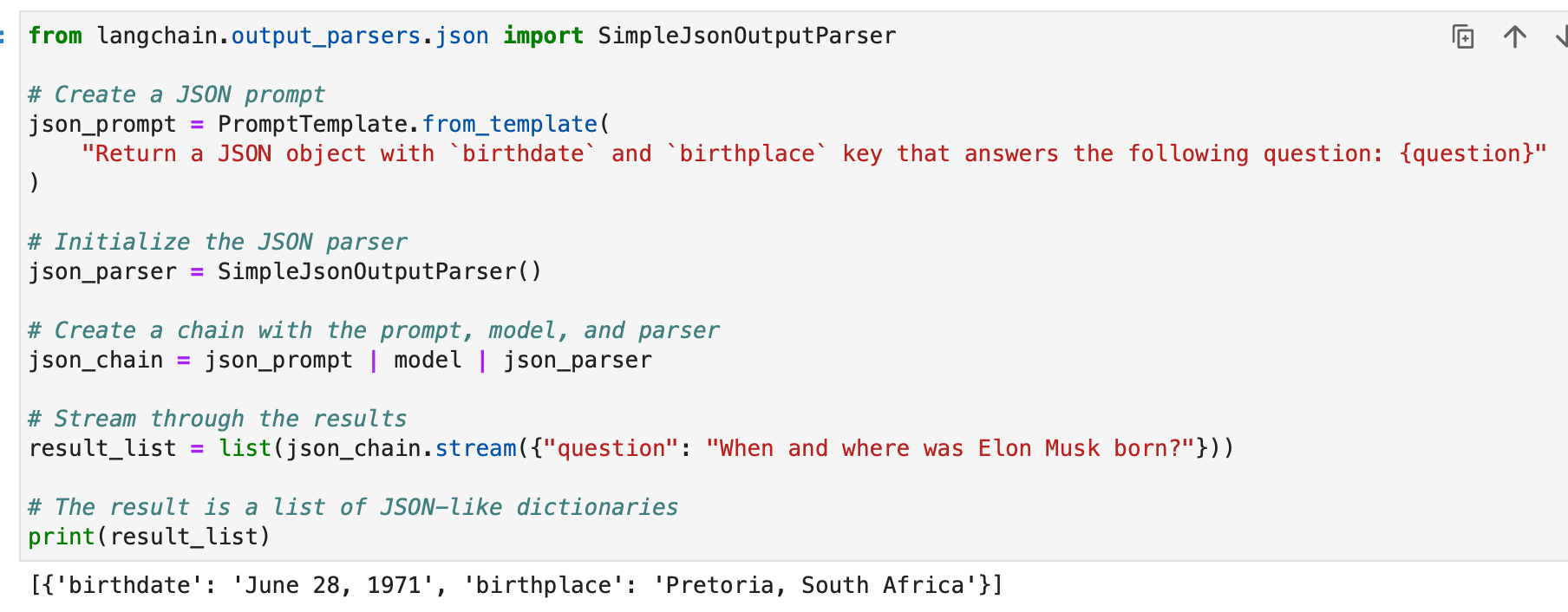
CommaSeparatedListOutputParser
CommaSeparatedListOutputParser berguna saat Anda ingin mengekstrak daftar yang dipisahkan koma dari respons model. Berikut ini contohnya:
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI # Initialize the parser
output_parser = CommaSeparatedListOutputParser() # Create format instructions
format_instructions = output_parser.get_format_instructions() # Create a prompt to request a list
prompt = PromptTemplate( template="List five {subject}.n{format_instructions}", input_variables=["subject"], partial_variables={"format_instructions": format_instructions}
) # Define a query to prompt the model
query = "English Premier League Teams" # Generate the output
output = model(prompt.format(subject=query)) # Parse the output using the parser
parsed_result = output_parser.parse(output) # The result is a list of items
print(parsed_result)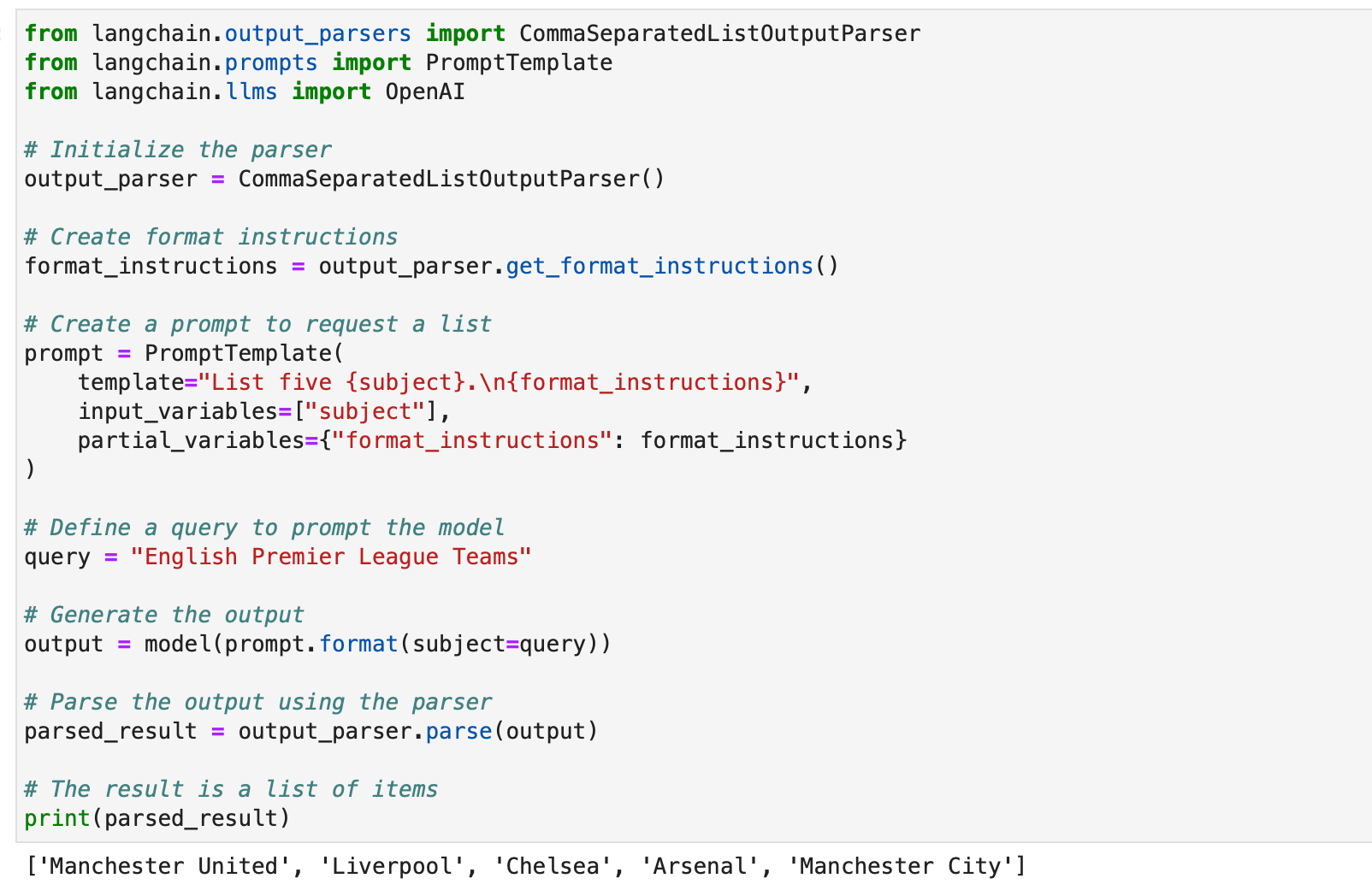
DatetimeOutputParser
DatetimeOutputParser Langchain dirancang untuk mengurai informasi datetime. Berikut cara menggunakannya:
from langchain.prompts import PromptTemplate
from langchain.output_parsers import DatetimeOutputParser
from langchain.chains import LLMChain
from langchain.llms import OpenAI # Initialize the DatetimeOutputParser
output_parser = DatetimeOutputParser() # Create a prompt with format instructions
template = """
Answer the user's question:
{question}
{format_instructions} """ prompt = PromptTemplate.from_template( template, partial_variables={"format_instructions": output_parser.get_format_instructions()},
) # Create a chain with the prompt and language model
chain = LLMChain(prompt=prompt, llm=OpenAI()) # Define a query to prompt the model
query = "when did Neil Armstrong land on the moon in terms of GMT?" # Run the chain
output = chain.run(query) # Parse the output using the datetime parser
parsed_result = output_parser.parse(output) # The result is a datetime object
print(parsed_result)
Contoh-contoh ini menunjukkan bagaimana parser keluaran Langchain dapat digunakan untuk menyusun berbagai jenis respons model, sehingga cocok untuk berbagai aplikasi dan format. Pengurai keluaran adalah alat yang berharga untuk meningkatkan kegunaan dan kemampuan interpretasi keluaran model bahasa di Langchain.
Otomatiskan tugas dan alur kerja manual dengan pembuat alur kerja berbasis AI kami, yang dirancang oleh Nanonets untuk Anda dan tim Anda.
Modul II : Pengambilan
Pengambilan di LangChain memainkan peran penting dalam aplikasi yang memerlukan data spesifik pengguna, tidak termasuk dalam set pelatihan model. Proses ini, dikenal sebagai Retrieval Augmented Generation (RAG), melibatkan pengambilan data eksternal dan mengintegrasikannya ke dalam proses pembuatan model bahasa. LangChain menyediakan seperangkat alat dan fungsi yang komprehensif untuk memfasilitasi proses ini, melayani aplikasi sederhana dan kompleks.
LangChain mencapai pengambilan melalui serangkaian komponen yang akan kita bahas satu per satu.
Pemuat Dokumen
Pemuat dokumen di LangChain memungkinkan ekstraksi data dari berbagai sumber. Dengan lebih dari 100 loader yang tersedia, mereka mendukung berbagai jenis dokumen, aplikasi, dan sumber (bucket s3 pribadi, situs web publik, database).
Anda dapat memilih pemuat dokumen berdasarkan kebutuhan Anda di sini.
Semua pemuat ini menyerap data ke dalamnya Dokumen kelas. Kita akan mempelajari cara menggunakan data yang diserap ke dalam kelas Dokumen nanti.
Pemuat File Teks: Muat yang sederhana .txt file ke dalam dokumen.
from langchain.document_loaders import TextLoader loader = TextLoader("./sample.txt")
document = loader.load()
Pemuat CSV: Muat file CSV ke dalam dokumen.
from langchain.document_loaders.csv_loader import CSVLoader loader = CSVLoader(file_path='./example_data/sample.csv')
documents = loader.load()
Kita dapat memilih untuk menyesuaikan penguraian dengan menentukan nama bidang –
loader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv', csv_args={ 'delimiter': ',', 'quotechar': '"', 'fieldnames': ['MLB Team', 'Payroll in millions', 'Wins']
})
documents = loader.load()
Pemuat PDF: PDF Loader di LangChain menawarkan berbagai metode untuk menguraikan dan mengekstraksi konten dari file PDF. Setiap pemuat memenuhi kebutuhan yang berbeda dan menggunakan perpustakaan dasar yang berbeda. Di bawah ini adalah contoh detail untuk setiap loader.
PyPDFLoader digunakan untuk penguraian PDF dasar.
from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
MathPixLoader sangat ideal untuk mengekstraksi konten dan diagram matematika.
from langchain.document_loaders import MathpixPDFLoader loader = MathpixPDFLoader("example_data/math-content.pdf")
data = loader.load()
PyMuPDFLoader cepat dan mencakup ekstraksi metadata terperinci.
from langchain.document_loaders import PyMuPDFLoader loader = PyMuPDFLoader("example_data/layout-parser-paper.pdf")
data = loader.load() # Optionally pass additional arguments for PyMuPDF's get_text() call
data = loader.load(option="text")
PDFMiner Loader digunakan untuk kontrol yang lebih terperinci atas ekstraksi teks.
from langchain.document_loaders import PDFMinerLoader loader = PDFMinerLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
AmazonTextractPDFParser menggunakan AWS Textract untuk OCR dan fitur penguraian PDF lanjutan lainnya.
from langchain.document_loaders import AmazonTextractPDFLoader # Requires AWS account and configuration
loader = AmazonTextractPDFLoader("example_data/complex-layout.pdf")
documents = loader.load()
PDFMinerPDFasHTMLLoader menghasilkan HTML dari PDF untuk penguraian semantik.
from langchain.document_loaders import PDFMinerPDFasHTMLLoader loader = PDFMinerPDFasHTMLLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
PDFPlumberLoader menyediakan metadata terperinci dan mendukung satu dokumen per halaman.
from langchain.document_loaders import PDFPlumberLoader loader = PDFPlumberLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
Loader Terintegrasi: LangChain menawarkan beragam pemuat khusus untuk memuat data secara langsung dari aplikasi Anda (seperti Slack, Sigma, Notion, Confluence, Google Drive, dan banyak lagi) dan database serta menggunakannya dalam aplikasi LLM.
Daftar lengkapnya adalah di sini.
Di bawah ini adalah beberapa contoh untuk menggambarkan hal ini –
Contoh I – Kendur
Slack, platform pesan instan yang banyak digunakan, dapat diintegrasikan ke dalam alur kerja dan aplikasi LLM.
- Buka halaman Manajemen Ruang Kerja Slack Anda.
- Navigasi ke
{your_slack_domain}.slack.com/services/export. - Pilih rentang tanggal yang diinginkan dan mulai ekspor.
- Slack memberi tahu melalui email dan DM setelah ekspor siap.
- Ekspor tersebut menghasilkan a
.zipfile yang terletak di folder Unduhan Anda atau jalur unduhan yang Anda tentukan. - Tetapkan jalur unduhan
.zipfile untukLOCAL_ZIPFILE. - Gunakan
SlackDirectoryLoaderdarilangchain.document_loaderspaket.
from langchain.document_loaders import SlackDirectoryLoader SLACK_WORKSPACE_URL = "https://xxx.slack.com" # Replace with your Slack URL
LOCAL_ZIPFILE = "" # Path to the Slack zip file loader = SlackDirectoryLoader(LOCAL_ZIPFILE, SLACK_WORKSPACE_URL)
docs = loader.load()
print(docs)
Contoh II – Gambar
Figma, alat populer untuk desain antarmuka, menawarkan REST API untuk integrasi data.
- Dapatkan kunci file Figma dari format URL:
https://www.figma.com/file/{filekey}/sampleFilename. - ID Node ditemukan di parameter URL
?node-id={node_id}. - Hasilkan token akses dengan mengikuti instruksi di Pusat Bantuan Figma.
- Grafik
FigmaFileLoaderkelas darilangchain.document_loaders.figmadigunakan untuk memuat data Figma. - Berbagai modul LangChain seperti
CharacterTextSplitter,ChatOpenAI, dll., digunakan untuk pemrosesan.
import os
from langchain.document_loaders.figma import FigmaFileLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.indexes import VectorstoreIndexCreator
from langchain.chains import ConversationChain, LLMChain
from langchain.memory import ConversationBufferWindowMemory
from langchain.prompts.chat import ChatPromptTemplate, SystemMessagePromptTemplate, AIMessagePromptTemplate, HumanMessagePromptTemplate figma_loader = FigmaFileLoader( os.environ.get("ACCESS_TOKEN"), os.environ.get("NODE_IDS"), os.environ.get("FILE_KEY"),
) index = VectorstoreIndexCreator().from_loaders([figma_loader])
figma_doc_retriever = index.vectorstore.as_retriever()
- Grafik
generate_codefungsi menggunakan data Figma untuk membuat kode HTML/CSS. - Ini menggunakan percakapan bertemplat dengan model berbasis GPT.
def generate_code(human_input): # Template for system and human prompts system_prompt_template = "Your coding instructions..." human_prompt_template = "Code the {text}. Ensure it's mobile responsive" # Creating prompt templates system_message_prompt = SystemMessagePromptTemplate.from_template(system_prompt_template) human_message_prompt = HumanMessagePromptTemplate.from_template(human_prompt_template) # Setting up the AI model gpt_4 = ChatOpenAI(temperature=0.02, model_name="gpt-4") # Retrieving relevant documents relevant_nodes = figma_doc_retriever.get_relevant_documents(human_input) # Generating and formatting the prompt conversation = [system_message_prompt, human_message_prompt] chat_prompt = ChatPromptTemplate.from_messages(conversation) response = gpt_4(chat_prompt.format_prompt(context=relevant_nodes, text=human_input).to_messages()) return response # Example usage
response = generate_code("page top header")
print(response.content)
- Grafik
generate_codefungsi, ketika dijalankan, mengembalikan kode HTML/CSS berdasarkan input desain Figma.
Sekarang mari kita gunakan pengetahuan kita untuk membuat beberapa kumpulan dokumen.
Pertama-tama kami memuat PDF, laporan keberlanjutan tahunan BCG.
Kami menggunakan PyPDFLoader untuk ini.
from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("bcg-2022-annual-sustainability-report-apr-2023.pdf")
pdfpages = loader.load_and_split()
Kami akan menyerap data dari Airtable sekarang. Kami memiliki Airtable yang berisi informasi tentang berbagai OCR dan model ekstraksi data –
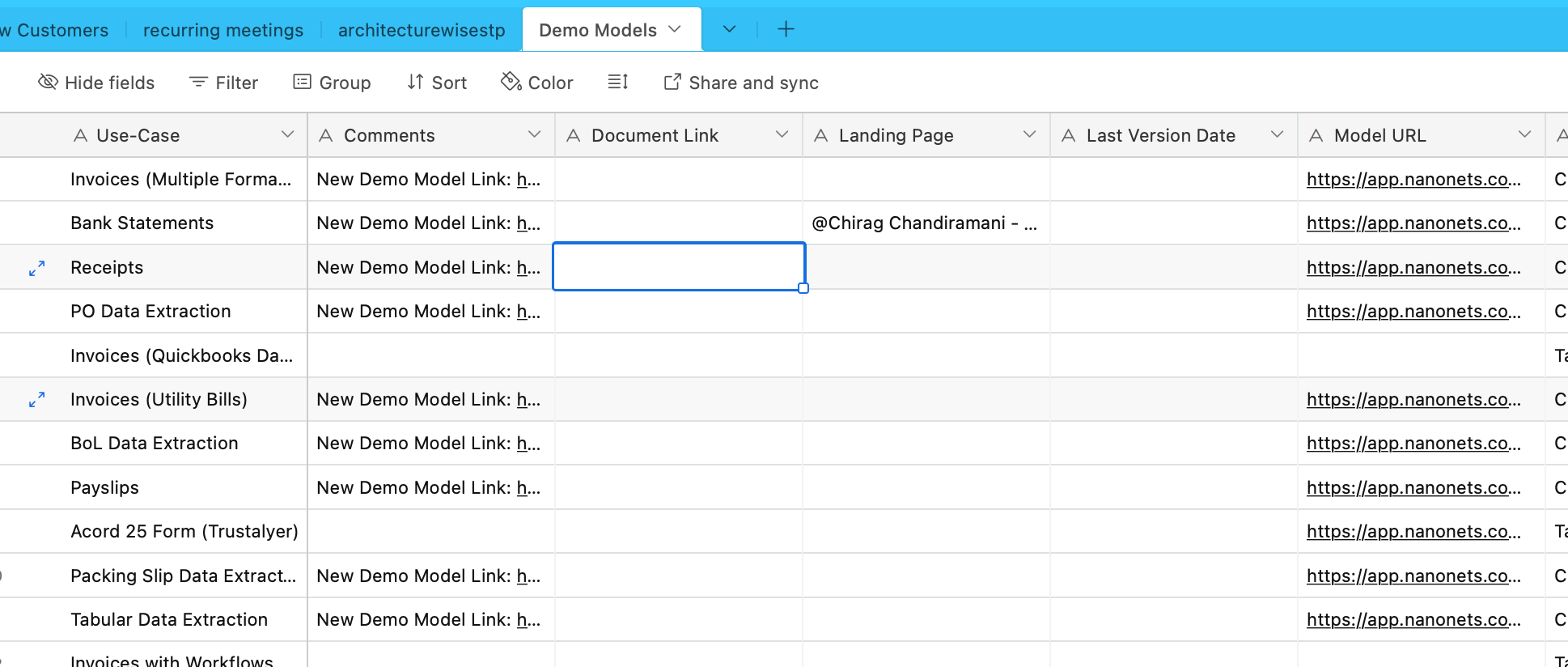
Mari kita gunakan AirtableLoader untuk ini, yang terdapat dalam daftar loader terintegrasi.
from langchain.document_loaders import AirtableLoader api_key = "XXXXX"
base_id = "XXXXX"
table_id = "XXXXX" loader = AirtableLoader(api_key, table_id, base_id)
airtabledocs = loader.load()
Sekarang mari kita lanjutkan dan pelajari cara menggunakan kelas dokumen ini.
Transformator Dokumen
Transformator dokumen di LangChain adalah alat penting yang dirancang untuk memanipulasi dokumen, yang kami buat di subbagian sebelumnya.
Mereka digunakan untuk tugas-tugas seperti membagi dokumen panjang menjadi potongan-potongan kecil, menggabungkan, dan memfilter, yang penting untuk mengadaptasi dokumen ke jendela konteks model atau memenuhi kebutuhan aplikasi tertentu.
Salah satu alat tersebut adalah RecursiveCharacterTextSplitter, pemisah teks serbaguna yang menggunakan daftar karakter untuk pemisahan. Ini memungkinkan parameter seperti ukuran potongan, tumpang tindih, dan indeks awal. Berikut ini contoh penggunaannya dalam Python:
from langchain.text_splitter import RecursiveCharacterTextSplitter state_of_the_union = "Your long text here..." text_splitter = RecursiveCharacterTextSplitter( chunk_size=100, chunk_overlap=20, length_function=len, add_start_index=True,
) texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
Alat lainnya adalah CharacterTextSplitter, yang membagi teks berdasarkan karakter tertentu dan menyertakan kontrol untuk ukuran potongan dan tumpang tindih:
from langchain.text_splitter import CharacterTextSplitter text_splitter = CharacterTextSplitter( separator="nn", chunk_size=1000, chunk_overlap=200, length_function=len, is_separator_regex=False,
) texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
HTMLHeaderTextSplitter dirancang untuk membagi konten HTML berdasarkan tag header, dengan mempertahankan struktur semantik:
from langchain.text_splitter import HTMLHeaderTextSplitter html_string = "Your HTML content here..."
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")] html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text(html_string)
print(html_header_splits[0])
Manipulasi yang lebih kompleks dapat dicapai dengan menggabungkan HTMLHeaderTextSplitter dengan splitter lain, seperti Pipelined Splitter:
from langchain.text_splitter import HTMLHeaderTextSplitter, RecursiveCharacterTextSplitter url = "https://example.com"
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url) chunk_size = 500
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size)
splits = text_splitter.split_documents(html_header_splits)
print(splits[0])
LangChain juga menawarkan pemisah khusus untuk bahasa pemrograman berbeda, seperti Pemisah Kode Python dan Pemisah Kode JavaScript:
from langchain.text_splitter import RecursiveCharacterTextSplitter, Language python_code = """
def hello_world(): print("Hello, World!")
hello_world() """ python_splitter = RecursiveCharacterTextSplitter.from_language( language=Language.PYTHON, chunk_size=50
)
python_docs = python_splitter.create_documents([python_code])
print(python_docs[0]) js_code = """
function helloWorld() { console.log("Hello, World!");
}
helloWorld(); """ js_splitter = RecursiveCharacterTextSplitter.from_language( language=Language.JS, chunk_size=60
)
js_docs = js_splitter.create_documents([js_code])
print(js_docs[0])
Untuk memisahkan teks berdasarkan jumlah token, yang berguna untuk model bahasa dengan batas token, TokenTextSplitter digunakan:
from langchain.text_splitter import TokenTextSplitter text_splitter = TokenTextSplitter(chunk_size=10)
texts = text_splitter.split_text(state_of_the_union)
print(texts[0])
Terakhir, LongContextReorder menyusun ulang dokumen untuk mencegah penurunan kinerja dalam model karena konteks yang panjang:
from langchain.document_transformers import LongContextReorder reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs)
print(reordered_docs[0])
Alat-alat ini menunjukkan berbagai cara untuk mengubah dokumen di LangChain, dari pemisahan teks sederhana hingga penyusunan ulang yang rumit dan pemisahan bahasa tertentu. Untuk kasus penggunaan yang lebih mendalam dan spesifik, bagian dokumentasi dan Integrasi LangChain harus dikonsultasikan.
Dalam contoh kami, pemuat telah membuat dokumen terpotong untuk kami, dan bagian ini sudah ditangani.
Model Penyematan Teks
Model penyematan teks di LangChain menyediakan antarmuka standar untuk berbagai penyedia model penyematan seperti OpenAI, Cohere, dan Hugging Face. Model ini mengubah teks menjadi representasi vektor, memungkinkan operasi seperti penelusuran semantik melalui kesamaan teks dalam ruang vektor.
Untuk memulai model penyematan teks, Anda biasanya perlu menginstal paket tertentu dan menyiapkan kunci API. Kami telah melakukan ini untuk OpenAI
Di LangChain, itu embed_documents metode ini digunakan untuk menyematkan banyak teks, menyediakan daftar representasi vektor. Contohnya:
from langchain.embeddings import OpenAIEmbeddings # Initialize the model
embeddings_model = OpenAIEmbeddings() # Embed a list of texts
embeddings = embeddings_model.embed_documents( ["Hi there!", "Oh, hello!", "What's your name?", "My friends call me World", "Hello World!"]
)
print("Number of documents embedded:", len(embeddings))
print("Dimension of each embedding:", len(embeddings[0]))
Untuk menyematkan satu teks, misalnya kueri penelusuran, embed_query metode digunakan. Ini berguna untuk membandingkan kueri dengan sekumpulan dokumen yang disematkan. Misalnya:
from langchain.embeddings import OpenAIEmbeddings # Initialize the model
embeddings_model = OpenAIEmbeddings() # Embed a single query
embedded_query = embeddings_model.embed_query("What was the name mentioned in the conversation?")
print("First five dimensions of the embedded query:", embedded_query[:5])
Memahami penyematan ini sangatlah penting. Setiap bagian teks diubah menjadi vektor, yang dimensinya bergantung pada model yang digunakan. Misalnya, model OpenAI biasanya menghasilkan vektor berdimensi 1536. Penyematan ini kemudian digunakan untuk mengambil informasi yang relevan.
Fungsi penyematan LangChain tidak terbatas pada OpenAI tetapi dirancang untuk bekerja dengan berbagai penyedia. Penyiapan dan penggunaannya mungkin sedikit berbeda tergantung pada penyedianya, namun konsep inti dalam menyematkan teks ke dalam ruang vektor tetap sama. Untuk penggunaan mendetail, termasuk konfigurasi lanjutan dan integrasi dengan penyedia model penyematan yang berbeda, dokumentasi LangChain di bagian Integrasi adalah sumber daya yang berharga.
Toko Vektor
Penyimpanan vektor di LangChain mendukung penyimpanan dan pencarian penyematan teks yang efisien. LangChain terintegrasi dengan lebih dari 50 toko vektor, menyediakan antarmuka standar untuk kemudahan penggunaan.
Contoh: Menyimpan dan Mencari Embeddings
Setelah menyematkan teks, kita dapat menyimpannya di toko vektor seperti Chroma dan melakukan pencarian kesamaan:
from langchain.vectorstores import Chroma db = Chroma.from_texts(embedded_texts)
similar_texts = db.similarity_search("search query")
Sebagai alternatif, mari kita gunakan penyimpanan vektor FAISS untuk membuat indeks untuk dokumen kita.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS pdfstore = FAISS.from_documents(pdfpages, embedding=OpenAIEmbeddings()) airtablestore = FAISS.from_documents(airtabledocs, embedding=OpenAIEmbeddings())

Retriever
Retriever di LangChain adalah antarmuka yang mengembalikan dokumen sebagai respons terhadap kueri tidak terstruktur. Penyimpanan ini lebih umum dibandingkan penyimpanan vektor, dengan fokus pada pengambilan dibandingkan penyimpanan. Meskipun penyimpanan vektor dapat digunakan sebagai tulang punggung retriever, ada juga jenis retriever lainnya.
Untuk menyiapkan Chroma retriever, Anda menginstalnya terlebih dahulu menggunakan pip install chromadb. Kemudian, Anda memuat, membagi, menyematkan, dan mengambil dokumen menggunakan serangkaian perintah Python. Berikut ini contoh kode untuk menyiapkan Chroma retriever:
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma full_text = open("state_of_the_union.txt", "r").read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
texts = text_splitter.split_text(full_text) embeddings = OpenAIEmbeddings()
db = Chroma.from_texts(texts, embeddings)
retriever = db.as_retriever() retrieved_docs = retriever.invoke("What did the president say about Ketanji Brown Jackson?")
print(retrieved_docs[0].page_content)
MultiQueryRetriever mengotomatiskan penyetelan cepat dengan menghasilkan beberapa kueri untuk kueri masukan pengguna dan menggabungkan hasilnya. Berikut ini contoh penggunaannya yang sederhana:
from langchain.chat_models import ChatOpenAI
from langchain.retrievers.multi_query import MultiQueryRetriever question = "What are the approaches to Task Decomposition?"
llm = ChatOpenAI(temperature=0)
retriever_from_llm = MultiQueryRetriever.from_llm( retriever=db.as_retriever(), llm=llm
) unique_docs = retriever_from_llm.get_relevant_documents(query=question)
print("Number of unique documents:", len(unique_docs))
Kompresi Kontekstual di LangChain memampatkan dokumen yang diambil menggunakan konteks kueri, memastikan hanya informasi relevan yang dikembalikan. Hal ini melibatkan pengurangan konten dan penyaringan dokumen yang kurang relevan. Contoh kode berikut menunjukkan cara menggunakan Contextual Compression Retriever:
from langchain.llms import OpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever) compressed_docs = compression_retriever.get_relevant_documents("What did the president say about Ketanji Jackson Brown")
print(compressed_docs[0].page_content)
EnsembleRetriever menggabungkan algoritma pengambilan yang berbeda untuk mencapai kinerja yang lebih baik. Contoh penggabungan BM25 dan FAISS Retriever ditunjukkan pada kode berikut:
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain.vectorstores import FAISS bm25_retriever = BM25Retriever.from_texts(doc_list).set_k(2)
faiss_vectorstore = FAISS.from_texts(doc_list, OpenAIEmbeddings())
faiss_retriever = faiss_vectorstore.as_retriever(search_kwargs={"k": 2}) ensemble_retriever = EnsembleRetriever( retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5]
) docs = ensemble_retriever.get_relevant_documents("apples")
print(docs[0].page_content)
MultiVector Retriever di LangChain memungkinkan kueri dokumen dengan banyak vektor per dokumen, yang berguna untuk menangkap aspek semantik berbeda dalam dokumen. Metode untuk membuat banyak vektor mencakup pemisahan menjadi bagian-bagian yang lebih kecil, meringkas, atau menghasilkan pertanyaan hipotetis. Untuk membagi dokumen menjadi beberapa bagian yang lebih kecil, kode Python berikut dapat digunakan:
python
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.storage import InMemoryStore
from langchain.document_loaders from TextLoader
import uuid loaders = [TextLoader("file1.txt"), TextLoader("file2.txt")]
docs = [doc for loader in loaders for doc in loader.load()]
text_splitter = RecursiveCharacterTextSplitter(chunk_size=10000)
docs = text_splitter.split_documents(docs) vectorstore = Chroma(collection_name="full_documents", embedding_function=OpenAIEmbeddings())
store = InMemoryStore()
id_key = "doc_id"
retriever = MultiVectorRetriever(vectorstore=vectorstore, docstore=store, id_key=id_key) doc_ids = [str(uuid.uuid4()) for _ in docs]
child_text_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
sub_docs = [sub_doc for doc in docs for sub_doc in child_text_splitter.split_documents([doc])]
for sub_doc in sub_docs: sub_doc.metadata[id_key] = doc_ids[sub_docs.index(sub_doc)] retriever.vectorstore.add_documents(sub_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
Menghasilkan ringkasan untuk pengambilan yang lebih baik karena representasi konten yang lebih fokus adalah metode lain. Berikut ini contoh pembuatan ringkasan:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.document import Document chain = (lambda x: x.page_content) | ChatPromptTemplate.from_template("Summarize the following document:nn{doc}") | ChatOpenAI(max_retries=0) | StrOutputParser()
summaries = chain.batch(docs, {"max_concurrency": 5}) summary_docs = [Document(page_content=s, metadata={id_key: doc_ids[i]}) for i, s in enumerate(summaries)]
retriever.vectorstore.add_documents(summary_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
Menghasilkan pertanyaan hipotetis yang relevan dengan setiap dokumen menggunakan LLM adalah pendekatan lain. Hal ini dapat dilakukan dengan kode berikut:
functions = [{"name": "hypothetical_questions", "parameters": {"questions": {"type": "array", "items": {"type": "string"}}}}]
from langchain.output_parsers.openai_functions import JsonKeyOutputFunctionsParser chain = (lambda x: x.page_content) | ChatPromptTemplate.from_template("Generate 3 hypothetical questions:nn{doc}") | ChatOpenAI(max_retries=0).bind(functions=functions, function_call={"name": "hypothetical_questions"}) | JsonKeyOutputFunctionsParser(key_name="questions")
hypothetical_questions = chain.batch(docs, {"max_concurrency": 5}) question_docs = [Document(page_content=q, metadata={id_key: doc_ids[i]}) for i, questions in enumerate(hypothetical_questions) for q in questions]
retriever.vectorstore.add_documents(question_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
Pengambil Dokumen Induk adalah pengambil dokumen lain yang memberikan keseimbangan antara akurasi penyematan dan retensi konteks dengan menyimpan potongan kecil dan mengambil dokumen induknya yang lebih besar. Implementasinya adalah sebagai berikut:
from langchain.retrievers import ParentDocumentRetriever loaders = [TextLoader("file1.txt"), TextLoader("file2.txt")]
docs = [doc for loader in loaders for doc in loader.load()] child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
vectorstore = Chroma(collection_name="full_documents", embedding_function=OpenAIEmbeddings())
store = InMemoryStore()
retriever = ParentDocumentRetriever(vectorstore=vectorstore, docstore=store, child_splitter=child_splitter) retriever.add_documents(docs, ids=None) retrieved_docs = retriever.get_relevant_documents("query")
Pengambil kueri mandiri membuat kueri terstruktur dari masukan bahasa alami dan menerapkannya ke VectorStore yang mendasarinya. Implementasinya ditunjukkan pada kode berikut:
from langchain.chat_models from ChatOpenAI
from langchain.chains.query_constructor.base from AttributeInfo
from langchain.retrievers.self_query.base from SelfQueryRetriever metadata_field_info = [AttributeInfo(name="genre", description="...", type="string"), ...]
document_content_description = "Brief summary of a movie"
llm = ChatOpenAI(temperature=0) retriever = SelfQueryRetriever.from_llm(llm, vectorstore, document_content_description, metadata_field_info) retrieved_docs = retriever.invoke("query")
WebResearchRetriever melakukan penelitian web berdasarkan kueri tertentu –
from langchain.retrievers.web_research import WebResearchRetriever # Initialize components
llm = ChatOpenAI(temperature=0)
search = GoogleSearchAPIWrapper()
vectorstore = Chroma(embedding_function=OpenAIEmbeddings()) # Instantiate WebResearchRetriever
web_research_retriever = WebResearchRetriever.from_llm(vectorstore=vectorstore, llm=llm, search=search) # Retrieve documents
docs = web_research_retriever.get_relevant_documents("query")
Sebagai contoh, kita juga dapat menggunakan retriever standar yang sudah diimplementasikan sebagai bagian dari objek penyimpanan vektor sebagai berikut –

Kami sekarang dapat menanyakan para retriever. Output dari kueri kita akan berupa objek dokumen yang relevan dengan kueri tersebut. Hal ini pada akhirnya akan digunakan untuk menciptakan tanggapan yang relevan di bagian selanjutnya.


Otomatiskan tugas dan alur kerja manual dengan pembuat alur kerja berbasis AI kami, yang dirancang oleh Nanonets untuk Anda dan tim Anda.
Modul III : Agen
LangChain memperkenalkan konsep kuat yang disebut “Agen” yang membawa gagasan rantai ke tingkat yang baru. Agen memanfaatkan model bahasa untuk secara dinamis menentukan urutan tindakan yang harus dilakukan, menjadikannya sangat fleksibel dan adaptif. Tidak seperti rantai tradisional, di mana tindakan dikodekan dalam kode, agen menggunakan model bahasa sebagai mesin penalaran untuk memutuskan tindakan mana yang harus diambil dan dalam urutan apa.
Agen merupakan komponen inti yang bertanggung jawab dalam pengambilan keputusan. Ini memanfaatkan kekuatan model bahasa dan petunjuk untuk menentukan langkah selanjutnya untuk mencapai tujuan tertentu. Masukan ke agen biasanya mencakup:
- Alat: Deskripsi alat yang tersedia (lebih lanjut tentang ini nanti).
- Masukan Pengguna: Tujuan atau permintaan tingkat tinggi dari pengguna.
- Langkah Menengah: Riwayat pasangan (tindakan, keluaran alat) yang dieksekusi untuk mencapai masukan pengguna saat ini.
Output dari suatu agen bisa menjadi yang berikutnya tindakan untuk mengambil tindakan (AgenAksi) atau final tanggapan untuk dikirim ke pengguna (Agen Selesai). Sebuah tindakan menentukan alat dan memasukkan untuk alat itu.
Tools
Alat adalah antarmuka yang dapat digunakan agen untuk berinteraksi dengan dunia. Mereka memungkinkan agen untuk melakukan berbagai tugas, seperti mencari web, menjalankan perintah shell, atau mengakses API eksternal. Di LangChain, alat sangat penting untuk memperluas kemampuan agen dan memungkinkan mereka menyelesaikan beragam tugas.
Untuk menggunakan alat di LangChain, Anda dapat memuatnya menggunakan cuplikan berikut:
from langchain.agents import load_tools tool_names = [...]
tools = load_tools(tool_names)
Beberapa alat mungkin memerlukan Model Bahasa dasar (LLM) untuk diinisialisasi. Dalam kasus seperti itu, Anda juga dapat lulus LLM:
from langchain.agents import load_tools tool_names = [...]
llm = ...
tools = load_tools(tool_names, llm=llm)
Penyiapan ini memungkinkan Anda mengakses berbagai alat dan mengintegrasikannya ke dalam alur kerja agen Anda. Daftar lengkap alat dengan dokumentasi penggunaan adalah di sini.
Mari kita lihat beberapa contoh Alat.
DuckDuckGo
Alat DuckDuckGo memungkinkan Anda melakukan pencarian web menggunakan mesin pencarinya. Berikut cara menggunakannya:
from langchain.tools import DuckDuckGoSearchRun
search = DuckDuckGoSearchRun()
search.run("manchester united vs luton town match summary")

DataUntukSeo
Toolkit DataForSeo memungkinkan Anda memperoleh hasil mesin pencari menggunakan API DataForSeo. Untuk menggunakan toolkit ini, Anda perlu menyiapkan kredensial API Anda. Berikut cara mengonfigurasi kredensial:
import os os.environ["DATAFORSEO_LOGIN"] = "<your_api_access_username>"
os.environ["DATAFORSEO_PASSWORD"] = "<your_api_access_password>"
Setelah kredensial Anda ditetapkan, Anda dapat membuat DataForSeoAPIWrapper alat untuk mengakses API:
from langchain.utilities.dataforseo_api_search import DataForSeoAPIWrapper wrapper = DataForSeoAPIWrapper() result = wrapper.run("Weather in Los Angeles")
Grafik DataForSeoAPIWrapper alat mengambil hasil mesin pencari dari berbagai sumber.
Anda dapat menyesuaikan jenis hasil dan bidang yang dikembalikan dalam respons JSON. Misalnya, Anda dapat menentukan jenis hasil, bidang, dan menetapkan jumlah maksimum jumlah hasil teratas yang akan ditampilkan:
json_wrapper = DataForSeoAPIWrapper( json_result_types=["organic", "knowledge_graph", "answer_box"], json_result_fields=["type", "title", "description", "text"], top_count=3,
) json_result = json_wrapper.results("Bill Gates")
Contoh ini mengkustomisasi respons JSON dengan menentukan jenis hasil, bidang, dan membatasi jumlah hasil.
Anda juga dapat menentukan lokasi dan bahasa untuk hasil penelusuran Anda dengan meneruskan parameter tambahan ke pembungkus API:
customized_wrapper = DataForSeoAPIWrapper( top_count=10, json_result_types=["organic", "local_pack"], json_result_fields=["title", "description", "type"], params={"location_name": "Germany", "language_code": "en"},
) customized_result = customized_wrapper.results("coffee near me")
Dengan menyediakan parameter lokasi dan bahasa, Anda dapat menyesuaikan hasil pencarian dengan wilayah dan bahasa tertentu.
Anda memiliki fleksibilitas untuk memilih mesin pencari yang ingin Anda gunakan. Cukup tentukan mesin pencari yang diinginkan:
customized_wrapper = DataForSeoAPIWrapper( top_count=10, json_result_types=["organic", "local_pack"], json_result_fields=["title", "description", "type"], params={"location_name": "Germany", "language_code": "en", "se_name": "bing"},
) customized_result = customized_wrapper.results("coffee near me")
Dalam contoh ini, pencarian disesuaikan untuk menggunakan Bing sebagai mesin pencari.
Pembungkus API juga memungkinkan Anda menentukan jenis pencarian yang ingin Anda lakukan. Misalnya, Anda dapat melakukan penelusuran peta:
maps_search = DataForSeoAPIWrapper( top_count=10, json_result_fields=["title", "value", "address", "rating", "type"], params={ "location_coordinate": "52.512,13.36,12z", "language_code": "en", "se_type": "maps", },
) maps_search_result = maps_search.results("coffee near me")
Ini menyesuaikan pencarian untuk mengambil informasi terkait peta.
Kerang (pesta)
Toolkit Shell memberi agen akses ke lingkungan shell, memungkinkan mereka menjalankan perintah shell. Fitur ini kuat namun harus digunakan dengan hati-hati, terutama di lingkungan sandbox. Berikut cara menggunakan alat Shell:
from langchain.tools import ShellTool shell_tool = ShellTool() result = shell_tool.run({"commands": ["echo 'Hello World!'", "time"]})
Dalam contoh ini, alat Shell menjalankan dua perintah shell: mengulangi “Hello World!” dan menampilkan waktu saat ini.

Anda dapat memberikan alat Shell kepada agen untuk melakukan tugas yang lebih kompleks. Berikut ini contoh agen yang mengambil link dari halaman web menggunakan alat Shell:
from langchain.agents import AgentType, initialize_agent
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(temperature=0.1) shell_tool.description = shell_tool.description + f"args {shell_tool.args}".replace( "{", "{{"
).replace("}", "}}")
self_ask_with_search = initialize_agent( [shell_tool], llm, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
self_ask_with_search.run( "Download the langchain.com webpage and grep for all urls. Return only a sorted list of them. Be sure to use double quotes."
)
Dalam skenario ini, agen menggunakan alat Shell untuk menjalankan serangkaian perintah untuk mengambil, memfilter, dan mengurutkan URL dari halaman web.
Contoh yang diberikan menunjukkan beberapa alat yang tersedia di LangChain. Alat-alat ini pada akhirnya memperluas kemampuan agen (dieksplorasi di subbagian berikutnya) dan memberdayakan mereka untuk melakukan berbagai tugas secara efisien. Bergantung pada kebutuhan Anda, Anda dapat memilih alat dan perangkat yang paling sesuai dengan kebutuhan proyek Anda dan mengintegrasikannya ke dalam alur kerja agen Anda.
Kembali ke Agen
Mari beralih ke agen sekarang.
AgentExecutor adalah lingkungan runtime untuk agen. Ia bertanggung jawab untuk memanggil agen, menjalankan tindakan yang dipilihnya, meneruskan keluaran tindakan kembali ke agen, dan mengulangi proses tersebut hingga agen selesai. Dalam kodesemu, AgentExecutor mungkin terlihat seperti ini:
next_action = agent.get_action(...)
while next_action != AgentFinish: observation = run(next_action) next_action = agent.get_action(..., next_action, observation)
return next_action
AgentExecutor menangani berbagai kompleksitas, seperti menangani kasus di mana agen memilih alat yang tidak ada, menangani kesalahan alat, mengelola keluaran yang dihasilkan agen, dan menyediakan pencatatan dan kemampuan observasi di semua tingkat.
Meskipun kelas AgentExecutor adalah runtime agen utama di LangChain, ada runtime eksperimental lain yang didukung, termasuk:
- Agen rencanakan dan laksanakan
- Bayi AGI
- GPT Otomatis
Untuk mendapatkan pemahaman yang lebih baik tentang kerangka agen, mari buat agen dasar dari awal, lalu lanjutkan menjelajahi agen yang sudah dibuat sebelumnya.
Sebelum kita mendalami pembuatan agen, penting untuk meninjau kembali beberapa terminologi dan skema utama:
- AgenAksi: Ini adalah kelas data yang mewakili tindakan yang harus diambil agen. Terdiri dari a
toolproperti (nama alat yang akan dipanggil) dan atool_inputproperti (input untuk alat itu). - Agen Selesai: Kelas data ini menunjukkan bahwa agen telah menyelesaikan tugasnya dan harus mengembalikan respons kepada pengguna. Biasanya mencakup kamus nilai yang dikembalikan, sering kali dengan “output” kunci yang berisi teks respons.
- Langkah Menengah: Ini adalah catatan tindakan agen sebelumnya dan keluaran terkait. Mereka sangat penting untuk meneruskan konteks ke iterasi agen di masa depan.
Dalam contoh kita, kita akan menggunakan Panggilan Fungsi OpenAI untuk membuat agen kita. Pendekatan ini dapat diandalkan untuk pembuatan agen. Kita akan mulai dengan membuat alat sederhana yang menghitung panjang sebuah kata. Alat ini berguna karena model bahasa terkadang membuat kesalahan akibat tokenisasi saat menghitung panjang kata.
Pertama, mari muat model bahasa yang akan kita gunakan untuk mengontrol agen:
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
Mari kita uji modelnya dengan perhitungan panjang kata:
llm.invoke("how many letters in the word educa?")
Responsnya harus menunjukkan jumlah huruf dalam kata “educa.”
Selanjutnya, kita akan mendefinisikan fungsi Python sederhana untuk menghitung panjang sebuah kata:
from langchain.agents import tool @tool
def get_word_length(word: str) -> int: """Returns the length of a word.""" return len(word)
Kami telah membuat alat bernama get_word_length yang mengambil sebuah kata sebagai masukan dan mengembalikan panjangnya.
Sekarang, mari buat prompt untuk agen. Prompt menginstruksikan agen tentang cara mempertimbangkan dan memformat output. Dalam kasus kami, kami menggunakan Panggilan Fungsi OpenAI, yang memerlukan instruksi minimal. Kami akan mendefinisikan prompt dengan placeholder untuk input pengguna dan scratchpad agen:
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a very powerful assistant but not great at calculating word lengths.", ), ("user", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"), ]
)
Sekarang, bagaimana agen mengetahui alat apa yang dapat digunakannya? Kami mengandalkan model bahasa pemanggilan fungsi OpenAI, yang mengharuskan fungsi diteruskan secara terpisah. Untuk menyediakan alat kami kepada agen, kami akan memformatnya sebagai panggilan fungsi OpenAI:
from langchain.tools.render import format_tool_to_openai_function llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools])
Sekarang, kita dapat membuat agen dengan mendefinisikan pemetaan input dan menghubungkan komponen-komponen:
Ini adalah bahasa LCEL. Kami akan membahas ini nanti secara rinci.
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai _function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
)
Kami telah membuat agen kami, yang memahami masukan pengguna, menggunakan alat yang tersedia, dan memformat keluaran. Sekarang, mari berinteraksi dengannya:
agent.invoke({"input": "how many letters in the word educa?", "intermediate_steps": []})
Agen harus merespons dengan AgentAction, yang menunjukkan tindakan selanjutnya yang harus diambil.
Kita telah membuat agennya, namun sekarang kita perlu menulis runtime untuk agen tersebut. Runtime yang paling sederhana adalah yang terus-menerus memanggil agen, menjalankan tindakan, dan mengulanginya hingga agen selesai. Berikut ini contohnya:
from langchain.schema.agent import AgentFinish user_input = "how many letters in the word educa?"
intermediate_steps = [] while True: output = agent.invoke( { "input": user_input, "intermediate_steps": intermediate_steps, } ) if isinstance(output, AgentFinish): final_result = output.return_values["output"] break else: print(f"TOOL NAME: {output.tool}") print(f"TOOL INPUT: {output.tool_input}") tool = {"get_word_length": get_word_length}[output.tool] observation = tool.run(output.tool_input) intermediate_steps.append((output, observation)) print(final_result)
Dalam perulangan ini, kami berulang kali memanggil agen, menjalankan tindakan, dan memperbarui langkah perantara hingga agen selesai. Kami juga menangani interaksi alat dalam loop.

Untuk menyederhanakan proses ini, LangChain menyediakan kelas AgentExecutor, yang merangkum eksekusi agen dan menawarkan penanganan kesalahan, penghentian awal, penelusuran, dan peningkatan lainnya. Mari gunakan AgentExecutor untuk berinteraksi dengan agen:
from langchain.agents import AgentExecutor agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True) agent_executor.invoke({"input": "how many letters in the word educa?"})
AgentExecutor menyederhanakan proses eksekusi dan menyediakan cara mudah untuk berinteraksi dengan agen.
Memori juga dibahas secara rinci nanti.
Agen yang kami buat sejauh ini tidak memiliki kewarganegaraan, artinya agen tersebut tidak mengingat interaksi sebelumnya. Untuk mengaktifkan pertanyaan dan percakapan lanjutan, kita perlu menambahkan memori ke agen. Ini melibatkan dua langkah:
- Tambahkan variabel memori di prompt untuk menyimpan riwayat obrolan.
- Pantau riwayat obrolan selama interaksi.
Mari kita mulai dengan menambahkan placeholder memori pada prompt:
from langchain.prompts import MessagesPlaceholder MEMORY_KEY = "chat_history"
prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a very powerful assistant but not great at calculating word lengths.", ), MessagesPlaceholder(variable_name=MEMORY_KEY), ("user", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"), ]
)
Sekarang, buat daftar untuk melacak riwayat obrolan:
from langchain.schema.messages import HumanMessage, AIMessage chat_history = []
Pada langkah pembuatan agen, kami juga akan menyertakan memori:
agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), "chat_history": lambda x: x["chat_history"], } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
)
Sekarang, saat menjalankan agen, pastikan untuk memperbarui riwayat obrolan:
input1 = "how many letters in the word educa?"
result = agent_executor.invoke({"input": input1, "chat_history": chat_history})
chat_history.extend([ HumanMessage(content=input1), AIMessage(content=result["output"]),
])
agent_executor.invoke({"input": "is that a real word?", "chat_history": chat_history})
Hal ini memungkinkan agen untuk menyimpan riwayat percakapan dan menjawab pertanyaan lanjutan berdasarkan interaksi sebelumnya.
Selamat! Anda telah berhasil membuat dan mengeksekusi agen end-to-end pertama Anda di LangChain. Untuk mempelajari lebih dalam kemampuan LangChain, Anda dapat menjelajahi:
- Jenis agen berbeda didukung.
- Agen yang sudah dibuat sebelumnya
- Cara bekerja dengan alat dan integrasi alat.
Jenis Agen
LangChain menawarkan berbagai jenis agen, masing-masing cocok untuk kasus penggunaan tertentu. Berikut beberapa agen yang tersedia:
- Reaksi Zero-shot: Agen ini menggunakan kerangka ReAct untuk memilih alat hanya berdasarkan deskripsinya. Ini memerlukan deskripsi untuk setiap alat dan sangat serbaguna.
- Masukan terstruktur Bereaksi: Agen ini menangani alat multi-input dan cocok untuk tugas kompleks seperti menavigasi browser web. Ini menggunakan skema argumen alat untuk input terstruktur.
- Fungsi OpenAI: Dirancang khusus untuk model yang disesuaikan untuk pemanggilan fungsi, agen ini kompatibel dengan model seperti gpt-3.5-turbo-0613 dan gpt-4-0613. Kami menggunakan ini untuk membuat agen pertama kami di atas.
- Percakapan: Dirancang untuk pengaturan percakapan, agen ini menggunakan ReAct untuk pemilihan alat dan menggunakan memori untuk mengingat interaksi sebelumnya.
- Tanyakan sendiri dengan pencarian: Agen ini mengandalkan satu alat, “Jawaban Menengah”, yang mencari jawaban faktual atas pertanyaan. Ini setara dengan bertanya pada diri sendiri dengan kertas pencarian.
- Penyimpanan dokumen ReAct: Agen ini berinteraksi dengan penyimpanan dokumen menggunakan kerangka ReAct. Ini memerlukan alat “Pencarian” dan “Pencarian” dan mirip dengan contoh asli makalah ReAct di Wikipedia.
Jelajahi jenis agen ini untuk menemukan agen yang paling sesuai dengan kebutuhan Anda di LangChain. Agen ini memungkinkan Anda untuk mengikat seperangkat alat di dalamnya untuk menangani tindakan dan menghasilkan respons. Pelajari lebih lanjut tentang cara membangun agen Anda sendiri dengan alat di sini.
Agen Bawaan
Mari lanjutkan eksplorasi agen, dengan fokus pada agen bawaan yang tersedia di LangChain.
Gmail
LangChain menawarkan perangkat Gmail yang memungkinkan Anda menghubungkan email LangChain Anda ke API Gmail. Untuk memulai, Anda perlu menyiapkan kredensial Anda, yang dijelaskan dalam dokumentasi API Gmail. Setelah Anda mengunduh credentials.json file, Anda dapat melanjutkan dengan menggunakan API Gmail. Selain itu, Anda harus menginstal beberapa perpustakaan yang diperlukan menggunakan perintah berikut:
pip install --upgrade google-api-python-client > /dev/null
pip install --upgrade google-auth-oauthlib > /dev/null
pip install --upgrade google-auth-httplib2 > /dev/null
pip install beautifulsoup4 > /dev/null # Optional for parsing HTML messages
Anda dapat membuat perangkat Gmail sebagai berikut:
from langchain.agents.agent_toolkits import GmailToolkit toolkit = GmailToolkit()
Anda juga dapat menyesuaikan otentikasi sesuai kebutuhan Anda. Di balik layar, sumber daya googleapi dibuat menggunakan metode berikut:
from langchain.tools.gmail.utils import build_resource_service, get_gmail_credentials credentials = get_gmail_credentials( token_file="token.json", scopes=["https://mail.google.com/"], client_secrets_file="credentials.json",
)
api_resource = build_resource_service(credentials=credentials)
toolkit = GmailToolkit(api_resource=api_resource)
Toolkit ini menawarkan berbagai alat yang dapat digunakan dalam agen, termasuk:
GmailCreateDraft: Membuat draf email dengan kolom pesan tertentu.GmailSendMessage: Mengirim pesan email.GmailSearch: Mencari pesan email atau thread.GmailGetMessage: Ambil email berdasarkan ID pesan.GmailGetThread: Mencari pesan email.
Untuk menggunakan alat ini dalam suatu agen, Anda dapat menginisialisasi agen sebagai berikut:
from langchain.llms import OpenAI
from langchain.agents import initialize_agent, AgentType llm = OpenAI(temperature=0)
agent = initialize_agent( tools=toolkit.get_tools(), llm=llm, agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
)
Berikut adalah beberapa contoh bagaimana alat ini dapat digunakan:
- Buat draf Gmail untuk diedit:
agent.run( "Create a gmail draft for me to edit of a letter from the perspective of a sentient parrot " "who is looking to collaborate on some research with her estranged friend, a cat. " "Under no circumstances may you send the message, however."
)
- Telusuri email terbaru di draf Anda:
agent.run("Could you search in my drafts for the latest email?")
Contoh berikut menunjukkan kemampuan perangkat Gmail LangChain dalam agen, memungkinkan Anda berinteraksi dengan Gmail secara terprogram.
Agen Basis Data SQL
Bagian ini memberikan gambaran umum tentang agen yang dirancang untuk berinteraksi dengan database SQL, khususnya database Chinook. Agen ini dapat menjawab pertanyaan umum tentang database dan memulihkan kesalahan. Harap dicatat bahwa ini masih dalam pengembangan aktif, dan tidak semua jawaban mungkin benar. Berhati-hatilah saat menjalankannya pada data sensitif, karena dapat menjalankan pernyataan DML pada database Anda.
Untuk menggunakan agen ini, Anda dapat menginisialisasinya sebagai berikut:
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.sql_database import SQLDatabase
from langchain.llms.openai import OpenAI
from langchain.agents import AgentExecutor
from langchain.agents.agent_types import AgentType
from langchain.chat_models import ChatOpenAI db = SQLDatabase.from_uri("sqlite:///../../../../../notebooks/Chinook.db")
toolkit = SQLDatabaseToolkit(db=db, llm=OpenAI(temperature=0)) agent_executor = create_sql_agent( llm=OpenAI(temperature=0), toolkit=toolkit, verbose=True, agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)
Agen ini dapat diinisialisasi menggunakan ZERO_SHOT_REACT_DESCRIPTION tipe agen. Ini dirancang untuk menjawab pertanyaan dan memberikan deskripsi. Alternatifnya, Anda dapat menginisialisasi agen menggunakan OPENAI_FUNCTIONS tipe agen dengan model turbo GPT-3.5 OpenAI, yang kami gunakan di klien sebelumnya.
Penolakan tanggung jawab
- Rantai kueri dapat menghasilkan kueri sisipkan/perbarui/hapus. Berhati-hatilah, dan gunakan perintah khusus atau buat pengguna SQL tanpa izin menulis jika diperlukan.
- Ketahuilah bahwa menjalankan kueri tertentu, seperti “jalankan kueri sebesar mungkin”, dapat membebani database SQL Anda secara berlebihan, terutama jika database tersebut berisi jutaan baris.
- Basis data berorientasi gudang data sering kali mendukung kuota tingkat pengguna untuk membatasi penggunaan sumber daya.
Anda dapat meminta agen untuk menjelaskan sebuah tabel, seperti tabel “playlisttrack”. Berikut ini contoh cara melakukannya:
agent_executor.run("Describe the playlisttrack table")
Agen akan memberikan informasi tentang skema tabel dan baris sampel.
Jika Anda salah bertanya tentang tabel yang tidak ada, agen dapat memulihkan dan memberikan informasi tentang tabel yang paling cocok. Misalnya:
agent_executor.run("Describe the playlistsong table")
Agen akan mencari tabel kecocokan terdekat dan memberikan informasi mengenainya.
Anda juga dapat meminta agen untuk menjalankan kueri pada database. Contohnya:
agent_executor.run("List the total sales per country. Which country's customers spent the most?")
Agen akan mengeksekusi query dan memberikan hasilnya, seperti negara dengan total penjualan tertinggi.
Untuk mendapatkan jumlah total lagu di setiap playlist, Anda dapat menggunakan kueri berikut:
agent_executor.run("Show the total number of tracks in each playlist. The Playlist name should be included in the result.")
Agen akan mengembalikan nama playlist beserta jumlah total lagu yang sesuai.
Jika agen mengalami kesalahan, agen dapat memulihkan dan memberikan respons yang akurat. Contohnya:
agent_executor.run("Who are the top 3 best selling artists?")
Bahkan setelah mengalami kesalahan awal, agen akan menyesuaikan dan memberikan jawaban yang benar, yang dalam hal ini adalah 3 artis terlaris.
Agen DataFrame Pandas
Bagian ini memperkenalkan agen yang dirancang untuk berinteraksi dengan Pandas DataFrames untuk tujuan menjawab pertanyaan. Harap dicatat bahwa agen ini menggunakan agen Python di bawah tenda untuk mengeksekusi kode Python yang dihasilkan oleh model bahasa (LLM). Berhati-hatilah saat menggunakan agen ini untuk mencegah potensi bahaya dari kode Python berbahaya yang dihasilkan oleh LLM.
Anda dapat menginisialisasi agen Pandas DataFrame sebagai berikut:
from langchain_experimental.agents.agent_toolkits import create_pandas_dataframe_agent
from langchain.chat_models import ChatOpenAI
from langchain.agents.agent_types import AgentType from langchain.llms import OpenAI
import pandas as pd df = pd.read_csv("titanic.csv") # Using ZERO_SHOT_REACT_DESCRIPTION agent type
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), df, verbose=True) # Alternatively, using OPENAI_FUNCTIONS agent type
# agent = create_pandas_dataframe_agent(
# ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613"),
# df,
# verbose=True,
# agent_type=AgentType.OPENAI_FUNCTIONS,
# )
Anda dapat meminta agen untuk menghitung jumlah baris di DataFrame:
agent.run("how many rows are there?")
Agen akan mengeksekusi kode tersebut df.shape[0] dan berikan jawabannya, seperti “Ada 891 baris dalam kerangka data.”
Anda juga dapat meminta agen untuk memfilter baris berdasarkan kriteria tertentu, seperti menemukan jumlah orang yang memiliki lebih dari 3 saudara kandung:
agent.run("how many people have more than 3 siblings")
Agen akan mengeksekusi kode tersebut df[df['SibSp'] > 3].shape[0] dan berikan jawabannya, misalnya “30 orang mempunyai lebih dari 3 saudara kandung”.
Jika Anda ingin menghitung akar kuadrat dari rata-rata usia, Anda dapat bertanya kepada agen:
agent.run("whats the square root of the average age?")
Agen akan menghitung usia rata-rata menggunakan df['Age'].mean() lalu hitung akar kuadratnya menggunakan math.sqrt(). Ini akan memberikan jawabannya, seperti “Akar kuadrat dari usia rata-rata adalah 5.449689683556195.”
Mari kita buat salinan DataFrame, dan nilai usia yang hilang diisi dengan usia rata-rata:
df1 = df.copy()
df1["Age"] = df1["Age"].fillna(df1["Age"].mean())
Kemudian, Anda dapat menginisialisasi agen dengan kedua DataFrames dan mengajukan pertanyaan:
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), [df, df1], verbose=True)
agent.run("how many rows in the age column are different?")
Agen akan membandingkan kolom usia di kedua DataFrames dan memberikan jawabannya, seperti “177 baris di kolom usia berbeda.”
Perangkat Jira
Bagian ini menjelaskan cara menggunakan toolkit Jira, yang memungkinkan agen berinteraksi dengan instance Jira. Anda dapat melakukan berbagai tindakan seperti mencari masalah dan membuat masalah menggunakan toolkit ini. Ini menggunakan perpustakaan atlassian-python-api. Untuk menggunakan toolkit ini, Anda perlu mengatur variabel lingkungan untuk instance Jira Anda, termasuk JIRA_API_TOKEN, JIRA_USERNAME, dan JIRA_INSTANCE_URL. Selain itu, Anda mungkin perlu menyetel kunci API OpenAI sebagai variabel lingkungan.
Untuk memulai, instal perpustakaan atlassian-python-api dan atur variabel lingkungan yang diperlukan:
%pip install atlassian-python-api import os
from langchain.agents import AgentType
from langchain.agents import initialize_agent
from langchain.agents.agent_toolkits.jira.toolkit import JiraToolkit
from langchain.llms import OpenAI
from langchain.utilities.jira import JiraAPIWrapper os.environ["JIRA_API_TOKEN"] = "abc"
os.environ["JIRA_USERNAME"] = "123"
os.environ["JIRA_INSTANCE_URL"] = "https://jira.atlassian.com"
os.environ["OPENAI_API_KEY"] = "xyz" llm = OpenAI(temperature=0)
jira = JiraAPIWrapper()
toolkit = JiraToolkit.from_jira_api_wrapper(jira)
agent = initialize_agent( toolkit.get_tools(), llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
Anda dapat menginstruksikan agen untuk membuat terbitan baru di proyek tertentu dengan ringkasan dan deskripsi:
agent.run("make a new issue in project PW to remind me to make more fried rice")
Agen akan menjalankan tindakan yang diperlukan untuk membuat masalah dan memberikan respons, seperti “Masalah baru telah dibuat di proyek PW dengan ringkasan 'Buat lebih banyak nasi goreng' dan deskripsi 'Pengingat untuk membuat lebih banyak nasi goreng'.”
Hal ini memungkinkan Anda berinteraksi dengan instance Jira menggunakan instruksi bahasa alami dan toolkit Jira.
Otomatiskan tugas dan alur kerja manual dengan pembuat alur kerja berbasis AI kami, yang dirancang oleh Nanonets untuk Anda dan tim Anda.
Modul IV : Rantai
LangChain adalah alat yang dirancang untuk memanfaatkan Model Bahasa Besar (LLM) dalam aplikasi yang kompleks. Ini memberikan kerangka kerja untuk membuat rantai komponen, termasuk LLM dan jenis komponen lainnya. Dua kerangka utama
- Bahasa Ekspresi LangChain (LCEL)
- Antarmuka Rantai Warisan
LangChain Expression Language (LCEL) adalah sintaksis yang memungkinkan komposisi rantai secara intuitif. Ini mendukung fitur-fitur canggih seperti streaming, panggilan asinkron, batching, paralelisasi, percobaan ulang, fallback, dan penelusuran. Misalnya, Anda dapat membuat parser prompt, model, dan output di LCEL seperti yang ditunjukkan dalam kode berikut:
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
prompt = ChatPromptTemplate.from_messages([ ("system", "You're a very knowledgeable historian who provides accurate and eloquent answers to historical questions."), ("human", "{question}")
])
runnable = prompt | model | StrOutputParser() for chunk in runnable.stream({"question": "What are the seven wonders of the world"}): print(chunk, end="", flush=True)
Alternatifnya, LLMChain adalah opsi yang mirip dengan LCEL untuk menyusun komponen. Contoh LLMChainnya adalah sebagai berikut:
from langchain.chains import LLMChain chain = LLMChain(llm=model, prompt=prompt, output_parser=StrOutputParser())
chain.run(question="What are the seven wonders of the world")
Rantai di LangChain juga dapat dibuat stateful dengan memasukkan objek Memori. Hal ini memungkinkan persistensi data di seluruh panggilan, seperti yang ditunjukkan dalam contoh ini:
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory conversation = ConversationChain(llm=chat, memory=ConversationBufferMemory())
conversation.run("Answer briefly. What are the first 3 colors of a rainbow?")
conversation.run("And the next 4?")
LangChain juga mendukung integrasi dengan API pemanggil fungsi OpenAI, yang berguna untuk memperoleh keluaran terstruktur dan menjalankan fungsi dalam suatu rantai. Untuk mendapatkan keluaran terstruktur, Anda dapat menentukannya menggunakan kelas Pydantic atau JsonSchema, seperti yang diilustrasikan di bawah ini:
from langchain.pydantic_v1 import BaseModel, Field
from langchain.chains.openai_functions import create_structured_output_runnable
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate class Person(BaseModel): name: str = Field(..., description="The person's name") age: int = Field(..., description="The person's age") fav_food: Optional[str] = Field(None, description="The person's favorite food") llm = ChatOpenAI(model="gpt-4", temperature=0)
prompt = ChatPromptTemplate.from_messages([ # Prompt messages here
]) runnable = create_structured_output_runnable(Person, llm, prompt)
runnable.invoke({"input": "Sally is 13"})
Untuk keluaran terstruktur, pendekatan lama menggunakan LLMChain juga tersedia:
from langchain.chains.openai_functions import create_structured_output_chain class Person(BaseModel): name: str = Field(..., description="The person's name") age: int = Field(..., description="The person's age") chain = create_structured_output_chain(Person, llm, prompt, verbose=True)
chain.run("Sally is 13")
LangChain memanfaatkan fungsi OpenAI untuk membuat berbagai rantai spesifik untuk tujuan berbeda. Ini termasuk rantai untuk ekstraksi, penandaan, OpenAPI, dan QA dengan kutipan.
Dalam konteks ekstraksi, prosesnya mirip dengan rantai keluaran terstruktur tetapi berfokus pada ekstraksi informasi atau entitas. Untuk penandaan, idenya adalah memberi label pada dokumen dengan kelas seperti sentimen, bahasa, gaya, topik yang dibahas, atau kecenderungan politik.
Contoh cara kerja penandaan di LangChain dapat ditunjukkan dengan kode Python. Prosesnya dimulai dengan menginstal paket yang diperlukan dan menyiapkan lingkungan:
pip install langchain openai
# Set env var OPENAI_API_KEY or load from a .env file:
# import dotenv
# dotenv.load_dotenv() from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import create_tagging_chain, create_tagging_chain_pydantic
Skema untuk penandaan ditentukan, menentukan properti dan tipe yang diharapkan:
schema = { "properties": { "sentiment": {"type": "string"}, "aggressiveness": {"type": "integer"}, "language": {"type": "string"}, }
} llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
chain = create_tagging_chain(schema, llm)
Contoh menjalankan rantai penandaan dengan masukan berbeda menunjukkan kemampuan model dalam menafsirkan sentimen, bahasa, dan agresivitas:
inp = "Estoy increiblemente contento de haberte conocido! Creo que seremos muy buenos amigos!"
chain.run(inp)
# {'sentiment': 'positive', 'language': 'Spanish'} inp = "Estoy muy enojado con vos! Te voy a dar tu merecido!"
chain.run(inp)
# {'sentiment': 'enojado', 'aggressiveness': 1, 'language': 'es'}
Untuk kontrol yang lebih baik, skema dapat didefinisikan secara lebih spesifik, termasuk kemungkinan nilai, deskripsi, dan properti yang diperlukan. Contoh dari kontrol yang ditingkatkan ini ditunjukkan di bawah ini:
schema = { "properties": { # Schema definitions here }, "required": ["language", "sentiment", "aggressiveness"],
} chain = create_tagging_chain(schema, llm)
Skema Pydantic juga dapat digunakan untuk menentukan kriteria penandaan, menyediakan cara Pythonic untuk menentukan properti dan tipe yang diperlukan:
from enum import Enum
from pydantic import BaseModel, Field class Tags(BaseModel): # Class fields here chain = create_tagging_chain_pydantic(Tags, llm)
Selain itu, transformator dokumen penanda metadata LangChain dapat digunakan untuk mengekstrak metadata dari Dokumen LangChain, menawarkan fungsionalitas serupa dengan rantai penandaan tetapi diterapkan pada Dokumen LangChain.
Mengutip sumber pengambilan adalah fitur lain dari LangChain, menggunakan fungsi OpenAI untuk mengekstraksi kutipan dari teks. Hal ini ditunjukkan dalam kode berikut:
from langchain.chains import create_citation_fuzzy_match_chain
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
chain = create_citation_fuzzy_match_chain(llm)
# Further code for running the chain and displaying results
Di LangChain, rangkaian aplikasi Model Bahasa Besar (LLM) biasanya melibatkan penggabungan template prompt dengan LLM dan opsional parser keluaran. Cara yang disarankan untuk melakukan hal ini adalah melalui LangChain Expression Language (LCEL), meskipun pendekatan LLMChain lama juga didukung.
Dengan menggunakan LCEL, BasePromptTemplate, BaseLanguageModel, dan BaseOutputParser semuanya mengimplementasikan antarmuka Runnable dan dapat dengan mudah disalurkan satu sama lain. Berikut ini contoh yang menunjukkan hal ini:
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema import StrOutputParser prompt = PromptTemplate.from_template( "What is a good name for a company that makes {product}?"
)
runnable = prompt | ChatOpenAI() | StrOutputParser()
runnable.invoke({"product": "colorful socks"})
# Output: 'VibrantSocks'
Perutean di LangChain memungkinkan pembuatan rantai non-deterministik di mana keluaran dari langkah sebelumnya menentukan langkah berikutnya. Hal ini membantu dalam menyusun dan menjaga konsistensi dalam interaksi dengan LLM. Misalnya, jika Anda memiliki dua templat yang dioptimalkan untuk jenis pertanyaan berbeda, Anda dapat memilih templat berdasarkan masukan pengguna.
Inilah cara Anda dapat mencapai hal ini menggunakan LCEL dengan RunnableBranch, yang diinisialisasi dengan daftar pasangan (kondisi, runnable) dan runnable default:
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableBranch
# Code for defining physics_prompt and math_prompt general_prompt = PromptTemplate.from_template( "You are a helpful assistant. Answer the question as accurately as you can.nn{input}"
)
prompt_branch = RunnableBranch( (lambda x: x["topic"] == "math", math_prompt), (lambda x: x["topic"] == "physics", physics_prompt), general_prompt,
) # More code for setting up the classifier and final chain
Rantai terakhir kemudian dibangun menggunakan berbagai komponen, seperti pengklasifikasi topik, cabang prompt, dan parser keluaran, untuk menentukan aliran berdasarkan topik masukan:
from operator import itemgetter
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough final_chain = ( RunnablePassthrough.assign(topic=itemgetter("input") | classifier_chain) | prompt_branch | ChatOpenAI() | StrOutputParser()
) final_chain.invoke( { "input": "What is the first prime number greater than 40 such that one plus the prime number is divisible by 3?" }
)
# Output: Detailed answer to the math question
Pendekatan ini menunjukkan fleksibilitas dan kekuatan LangChain dalam menangani pertanyaan kompleks dan merutekannya dengan tepat berdasarkan masukan.
Dalam bidang model bahasa, praktik umum adalah menindaklanjuti panggilan awal dengan serangkaian panggilan berikutnya, menggunakan keluaran dari satu panggilan sebagai masukan untuk panggilan berikutnya. Pendekatan sekuensial ini sangat bermanfaat ketika Anda ingin memanfaatkan informasi yang dihasilkan dalam interaksi sebelumnya. Meskipun LangChain Expression Language (LCEL) adalah metode yang direkomendasikan untuk membuat rangkaian ini, metode SequentialChain masih didokumentasikan karena kompatibilitasnya ke belakang.
Untuk mengilustrasikannya, mari kita pertimbangkan sebuah skenario di mana pertama-tama kita membuat sinopsis drama dan kemudian ulasan berdasarkan sinopsis tersebut. Menggunakan Python langchain.prompts, kami membuat dua PromptTemplate contoh: satu untuk sinopsis dan satu lagi untuk review. Berikut kode untuk menyiapkan template ini:
from langchain.prompts import PromptTemplate synopsis_prompt = PromptTemplate.from_template( "You are a playwright. Given the title of play, it is your job to write a synopsis for that title.nnTitle: {title}nPlaywright: This is a synopsis for the above play:"
) review_prompt = PromptTemplate.from_template( "You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:"
)
Dalam pendekatan LCEL, kami merangkai petunjuk ini dengan ChatOpenAI dan StrOutputParser untuk membuat urutan yang pertama menghasilkan sinopsis dan kemudian review. Cuplikan kodenya seperti berikut:
from langchain.chat_models import ChatOpenAI
from langchain.schema import StrOutputParser llm = ChatOpenAI()
chain = ( {"synopsis": synopsis_prompt | llm | StrOutputParser()} | review_prompt | llm | StrOutputParser()
)
chain.invoke({"title": "Tragedy at sunset on the beach"})
Jika kita membutuhkan sinopsis dan reviewnya, kita bisa menggunakannya RunnablePassthrough untuk membuat rantai terpisah untuk masing-masing dan kemudian menggabungkannya:
from langchain.schema.runnable import RunnablePassthrough synopsis_chain = synopsis_prompt | llm | StrOutputParser()
review_chain = review_prompt | llm | StrOutputParser()
chain = {"synopsis": synopsis_chain} | RunnablePassthrough.assign(review=review_chain)
chain.invoke({"title": "Tragedy at sunset on the beach"})
Untuk skenario yang melibatkan rangkaian yang lebih kompleks, SequentialChain metode ikut berperan. Hal ini memungkinkan banyak input dan output. Pertimbangkan kasus di mana kita memerlukan sinopsis berdasarkan judul dan era sebuah drama. Berikut cara kami menyiapkannya:
from langchain.llms import OpenAI
from langchain.chains import LLMChain, SequentialChain
from langchain.prompts import PromptTemplate llm = OpenAI(temperature=0.7) synopsis_template = "You are a playwright. Given the title of play and the era it is set in, it is your job to write a synopsis for that title.nnTitle: {title}nEra: {era}nPlaywright: This is a synopsis for the above play:"
synopsis_prompt_template = PromptTemplate(input_variables=["title", "era"], template=synopsis_template)
synopsis_chain = LLMChain(llm=llm, prompt=synopsis_prompt_template, output_key="synopsis") review_template = "You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:"
prompt_template = PromptTemplate(input_variables=["synopsis"], template=review_template)
review_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="review") overall_chain = SequentialChain( chains=[synopsis_chain, review_chain], input_variables=["era", "title"], output_variables=["synopsis", "review"], verbose=True,
) overall_chain({"title": "Tragedy at sunset on the beach", "era": "Victorian England"})
Dalam skenario ketika Anda ingin mempertahankan konteks di seluruh rantai atau di bagian selanjutnya dari rantai, SimpleMemory dapat digunakan. Hal ini sangat berguna untuk mengelola hubungan input/output yang kompleks. Misalnya, dalam skenario di mana kita ingin membuat postingan media sosial berdasarkan judul, era, sinopsis, dan ulasan drama, SimpleMemory dapat membantu mengelola variabel berikut:
from langchain.memory import SimpleMemory
from langchain.chains import SequentialChain template = "You are a social media manager for a theater company. Given the title of play, the era it is set in, the date, time and location, the synopsis of the play, and the review of the play, it is your job to write a social media post for that play.nnHere is some context about the time and location of the play:nDate and Time: {time}nLocation: {location}nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:n{review}nnSocial Media Post:"
prompt_template = PromptTemplate(input_variables=["synopsis", "review", "time", "location"], template=template)
social_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="social_post_text") overall_chain = SequentialChain( memory=SimpleMemory(memories={"time": "December 25th, 8pm PST", "location": "Theater in the Park"}), chains=[synopsis_chain, review_chain, social_chain], input_variables=["era", "title"], output_variables=["social_post_text"], verbose=True,
) overall_chain({"title": "Tragedy at sunset on the beach", "era": "Victorian England"})
Selain rantai berurutan, ada rantai khusus untuk bekerja dengan dokumen. Masing-masing rantai ini memiliki tujuan berbeda, mulai dari menggabungkan dokumen hingga menyempurnakan jawaban berdasarkan analisis dokumen berulang, hingga memetakan dan mengurangi konten dokumen untuk diringkas atau diurutkan ulang berdasarkan skor tanggapan. Rantai ini dapat dibuat ulang dengan LCEL untuk fleksibilitas dan penyesuaian tambahan.
-
StuffDocumentsChainmenggabungkan daftar dokumen menjadi satu prompt yang diteruskan ke LLM. -
RefineDocumentsChainmemperbarui jawabannya secara berulang untuk setiap dokumen, cocok untuk tugas yang dokumennya melebihi kapasitas konteks model. -
MapReduceDocumentsChainmenerapkan rantai ke setiap dokumen satu per satu dan kemudian menggabungkan hasilnya. -
MapRerankDocumentsChainmemberi skor pada setiap respons berbasis dokumen dan memilih respons dengan skor tertinggi.
Berikut ini contoh bagaimana Anda dapat menyiapkan a MapReduceDocumentsChain menggunakan LCEL:
from functools import partial
from langchain.chains.combine_documents import collapse_docs, split_list_of_docs
from langchain.schema import Document, StrOutputParser
from langchain.schema.prompt_template import format_document
from langchain.schema.runnable import RunnableParallel, RunnablePassthrough llm = ChatAnthropic()
document_prompt = PromptTemplate.from_template("{page_content}")
partial_format_document = partial(format_document, prompt=document_prompt) map_chain = ( {"context": partial_format_document} | PromptTemplate.from_template("Summarize this content:nn{context}") | llm | StrOutputParser()
) map_as_doc_chain = ( RunnableParallel({"doc": RunnablePassthrough(), "content": map_chain}) | (lambda x: Document(page_content=x["content"], metadata=x["doc"].metadata))
).with_config(run_name="Summarize (return doc)") def format_docs(docs): return "nn".join(partial_format_document(doc) for doc in docs) collapse_chain = ( {"context": format_docs} | PromptTemplate.from_template("Collapse this content:nn{context}") | llm | StrOutputParser()
) reduce_chain = ( {"context": format_docs} | PromptTemplate.from_template("Combine these summaries:nn{context}") | llm | StrOutputParser()
).with_config(run_name="Reduce") map_reduce = (map_as_doc_chain.map() | collapse | reduce_chain).with_config(run_name="Map reduce")
Konfigurasi ini memungkinkan analisis konten dokumen secara mendetail dan komprehensif, memanfaatkan kekuatan LCEL dan model bahasa yang mendasarinya.
Otomatiskan tugas dan alur kerja manual dengan pembuat alur kerja berbasis AI kami, yang dirancang oleh Nanonets untuk Anda dan tim Anda.
Modul V : Memori
Di LangChain, memori adalah aspek mendasar dari antarmuka percakapan, yang memungkinkan sistem untuk mereferensikan interaksi masa lalu. Hal ini dicapai melalui penyimpanan dan permintaan informasi, dengan dua tindakan utama: membaca dan menulis. Sistem memori berinteraksi dengan rantai dua kali selama proses, menambah input pengguna dan menyimpan input dan output untuk referensi di masa mendatang.
Membangun Memori ke dalam Sistem
- Menyimpan Pesan Obrolan: Modul memori LangChain mengintegrasikan berbagai metode untuk menyimpan pesan obrolan, mulai dari daftar dalam memori hingga database. Hal ini memastikan bahwa semua interaksi obrolan dicatat untuk referensi di masa mendatang.
- Meminta Pesan Obrolan: Selain menyimpan pesan obrolan, LangChain menggunakan struktur data dan algoritma untuk membuat tampilan yang berguna dari pesan-pesan ini. Sistem memori sederhana mungkin mengembalikan pesan terkini, sementara sistem yang lebih canggih dapat meringkas interaksi masa lalu atau fokus pada entitas yang disebutkan dalam interaksi saat ini.
Untuk mendemonstrasikan penggunaan memori di LangChain, pertimbangkan ConversationBufferMemory kelas, bentuk memori sederhana yang menyimpan pesan obrolan dalam buffer. Berikut ini contohnya:
from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("Hello!")
memory.chat_memory.add_ai_message("How can I assist you?")
Saat mengintegrasikan memori ke dalam rantai, penting untuk memahami variabel yang dikembalikan dari memori dan cara penggunaannya dalam rantai. Misalnya saja load_memory_variables Metode ini membantu menyelaraskan variabel yang dibaca dari memori dengan ekspektasi rantai.
Contoh Ujung-ke-Ujung dengan LangChain
Pertimbangkan untuk menggunakan ConversationBufferMemory di LLMChain. Rantai tersebut, dikombinasikan dengan template prompt yang sesuai dan memori, memberikan pengalaman percakapan yang lancar. Berikut ini contoh yang disederhanakan:
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory llm = OpenAI(temperature=0)
template = "Your conversation template here..."
prompt = PromptTemplate.from_template(template)
memory = ConversationBufferMemory(memory_key="chat_history")
conversation = LLMChain(llm=llm, prompt=prompt, memory=memory) response = conversation({"question": "What's the weather like?"})
Contoh ini menggambarkan bagaimana sistem memori LangChain berintegrasi dengan rantainya untuk memberikan pengalaman percakapan yang koheren dan sadar konteks.
Jenis Memori di Langchain
Langchain menawarkan berbagai jenis memori yang dapat digunakan untuk meningkatkan interaksi dengan model AI. Setiap jenis memori memiliki parameter dan tipe pengembaliannya sendiri, sehingga cocok untuk skenario yang berbeda. Mari jelajahi beberapa tipe memori yang tersedia di Langchain beserta contoh kodenya.
1. Memori Penyangga Percakapan
Jenis memori ini memungkinkan Anda menyimpan dan mengekstrak pesan dari percakapan. Anda dapat mengekstrak riwayat sebagai string atau daftar pesan.
from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory()
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({}) # Extract history as a string
{'history': 'Human: hinAI: whats up'} # Extract history as a list of messages
{'history': [HumanMessage(content='hi', additional_kwargs={}), AIMessage(content='whats up', additional_kwargs={})]}
Anda juga dapat menggunakan Memori Buffer Percakapan secara berantai untuk interaksi seperti obrolan.
2. Memori Jendela Penyangga Percakapan
Tipe memori ini menyimpan daftar interaksi terkini dan menggunakan K interaksi terakhir, mencegah buffer menjadi terlalu besar.
from langchain.memory import ConversationBufferWindowMemory memory = ConversationBufferWindowMemory(k=1)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
memory.load_memory_variables({}) {'history': 'Human: not much younAI: not much'}
Seperti Memori Buffer Percakapan, Anda juga dapat menggunakan jenis memori ini secara berantai untuk interaksi seperti obrolan.
3. Memori Entitas Percakapan
Jenis memori ini mengingat fakta tentang entitas tertentu dalam percakapan dan mengekstrak informasi menggunakan LLM.
from langchain.memory import ConversationEntityMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationEntityMemory(llm=llm)
_input = {"input": "Deven & Sam are working on a hackathon project"}
memory.load_memory_variables(_input)
memory.save_context( _input, {"output": " That sounds like a great project! What kind of project are they working on?"}
)
memory.load_memory_variables({"input": 'who is Sam'}) {'history': 'Human: Deven & Sam are working on a hackathon projectnAI: That sounds like a great project! What kind of project are they working on?', 'entities': {'Sam': 'Sam is working on a hackathon project with Deven.'}}
4. Memori Grafik Pengetahuan Percakapan
Jenis memori ini menggunakan grafik pengetahuan untuk membuat ulang memori. Anda dapat mengekstrak entitas terkini dan pengetahuan kembar tiga dari pesan.
from langchain.memory import ConversationKGMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationKGMemory(llm=llm)
memory.save_context({"input": "say hi to sam"}, {"output": "who is sam"})
memory.save_context({"input": "sam is a friend"}, {"output": "okay"})
memory.load_memory_variables({"input": "who is sam"}) {'history': 'On Sam: Sam is friend.'}
Anda juga dapat menggunakan tipe memori ini dalam rantai untuk pengambilan pengetahuan berbasis percakapan.
5. Memori Ringkasan Percakapan
Jenis memori ini membuat ringkasan percakapan dari waktu ke waktu, berguna untuk memadatkan informasi dari percakapan yang lebih panjang.
from langchain.memory import ConversationSummaryMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationSummaryMemory(llm=llm)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({}) {'history': 'nThe human greets the AI, to which the AI responds.'}
6. Memori Penyangga Ringkasan Percakapan
Jenis memori ini menggabungkan ringkasan percakapan dan buffer, menjaga keseimbangan antara interaksi terkini dan ringkasan. Ia menggunakan panjang token untuk menentukan kapan harus menghapus interaksi.
from langchain.memory import ConversationSummaryBufferMemory
from langchain.llms import OpenAI llm = OpenAI()
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
memory.load_memory_variables({}) {'history': 'System: nThe human says "hi", and the AI responds with "whats up".nHuman: not much younAI: not much'}
Anda dapat menggunakan jenis memori ini untuk meningkatkan interaksi Anda dengan model AI di Langchain. Setiap jenis memori memiliki tujuan tertentu dan dapat dipilih berdasarkan kebutuhan Anda.
7. Memori Penyangga Token Percakapan
ConversationTokenBufferMemory adalah jenis memori lain yang menyimpan buffer interaksi terkini di memori. Berbeda dengan jenis memori sebelumnya yang berfokus pada jumlah interaksi, jenis memori ini menggunakan panjang token untuk menentukan kapan harus menghapus interaksi.
Menggunakan memori dengan LLM:
from langchain.memory import ConversationTokenBufferMemory
from langchain.llms import OpenAI llm = OpenAI() memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"}) memory.load_memory_variables({}) {'history': 'Human: not much younAI: not much'}
Dalam contoh ini, memori diatur untuk membatasi interaksi berdasarkan panjang token, bukan jumlah interaksi.
Anda juga bisa mendapatkan riwayat sebagai daftar pesan saat menggunakan jenis memori ini.
memory = ConversationTokenBufferMemory( llm=llm, max_token_limit=10, return_messages=True
)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
Menggunakan dalam rantai:
Anda dapat menggunakan ConversationTokenBufferMemory dalam sebuah rantai untuk meningkatkan interaksi dengan model AI.
from langchain.chains import ConversationChain conversation_with_summary = ConversationChain( llm=llm, # We set a very low max_token_limit for the purposes of testing. memory=ConversationTokenBufferMemory(llm=OpenAI(), max_token_limit=60), verbose=True,
)
conversation_with_summary.predict(input="Hi, what's up?")
Dalam contoh ini, ConversationTokenBufferMemory digunakan dalam ConversationChain untuk mengelola percakapan dan membatasi interaksi berdasarkan panjang token.
8. Memori VectorStoreRetriever
VectorStoreRetrieverMemory menyimpan kenangan di penyimpanan vektor dan menanyakan K dokumen paling “menonjol” teratas setiap kali dipanggil. Tipe memori ini tidak secara eksplisit melacak urutan interaksi tetapi menggunakan pengambilan vektor untuk mengambil memori yang relevan.
from datetime import datetime
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.memory import VectorStoreRetrieverMemory
from langchain.chains import ConversationChain
from langchain.prompts import PromptTemplate # Initialize your vector store (specifics depend on the chosen vector store)
import faiss
from langchain.docstore import InMemoryDocstore
from langchain.vectorstores import FAISS embedding_size = 1536 # Dimensions of the OpenAIEmbeddings
index = faiss.IndexFlatL2(embedding_size)
embedding_fn = OpenAIEmbeddings().embed_query
vectorstore = FAISS(embedding_fn, index, InMemoryDocstore({}), {}) # Create your VectorStoreRetrieverMemory
retriever = vectorstore.as_retriever(search_kwargs=dict(k=1))
memory = VectorStoreRetrieverMemory(retriever=retriever) # Save context and relevant information to the memory
memory.save_context({"input": "My favorite food is pizza"}, {"output": "that's good to know"})
memory.save_context({"input": "My favorite sport is soccer"}, {"output": "..."})
memory.save_context({"input": "I don't like the Celtics"}, {"output": "ok"}) # Retrieve relevant information from memory based on a query
print(memory.load_memory_variables({"prompt": "what sport should i watch?"})["history"])
Dalam contoh ini, VectorStoreRetrieverMemory digunakan untuk menyimpan dan mengambil informasi relevan dari percakapan berdasarkan pengambilan vektor.
Anda juga dapat menggunakan VectorStoreRetrieverMemory dalam rantai untuk pengambilan pengetahuan berbasis percakapan, seperti yang ditunjukkan dalam contoh sebelumnya.
Berbagai jenis memori di Langchain ini menyediakan berbagai cara untuk mengelola dan mengambil informasi dari percakapan, meningkatkan kemampuan model AI dalam memahami dan merespons pertanyaan dan konteks pengguna. Setiap jenis memori dapat dipilih berdasarkan kebutuhan spesifik aplikasi Anda.
Sekarang kita akan belajar cara menggunakan memori dengan LLMChain. Memori dalam LLMChain memungkinkan model mengingat interaksi dan konteks sebelumnya untuk memberikan respons yang lebih koheren dan sadar konteks.
Untuk menyiapkan memori di LLMChain, Anda perlu membuat kelas memori, seperti ConversationBufferMemory. Inilah cara Anda mengaturnya:
from langchain.chains import LLMChain
from langchain.llms import OpenAI
from langchain.memory import ConversationBufferMemory
from langchain.prompts import PromptTemplate template = """You are a chatbot having a conversation with a human. {chat_history}
Human: {human_input}
Chatbot:""" prompt = PromptTemplate( input_variables=["chat_history", "human_input"], template=template
)
memory = ConversationBufferMemory(memory_key="chat_history") llm = OpenAI()
llm_chain = LLMChain( llm=llm, prompt=prompt, verbose=True, memory=memory,
) llm_chain.predict(human_input="Hi there my friend")
Dalam contoh ini, ConversationBufferMemory digunakan untuk menyimpan riwayat percakapan. Itu memory_key parameter menentukan kunci yang digunakan untuk menyimpan riwayat percakapan.
Jika Anda menggunakan model obrolan dan bukan model gaya penyelesaian, Anda dapat menyusun perintah secara berbeda untuk memanfaatkan memori dengan lebih baik. Berikut ini contoh cara menyiapkan LLMChain berbasis model obrolan dengan memori:
from langchain.chat_models import ChatOpenAI
from langchain.schema import SystemMessage
from langchain.prompts import ( ChatPromptTemplate, HumanMessagePromptTemplate, MessagesPlaceholder,
) # Create a ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages( [ SystemMessage( content="You are a chatbot having a conversation with a human." ), # The persistent system prompt MessagesPlaceholder( variable_name="chat_history" ), # Where the memory will be stored. HumanMessagePromptTemplate.from_template( "{human_input}" ), # Where the human input will be injected ]
) memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True) llm = ChatOpenAI() chat_llm_chain = LLMChain( llm=llm, prompt=prompt, verbose=True, memory=memory,
) chat_llm_chain.predict(human_input="Hi there my friend")
Dalam contoh ini, ChatPromptTemplate digunakan untuk menyusun perintah, dan ConversationBufferMemory digunakan untuk menyimpan dan mengambil riwayat percakapan. Pendekatan ini sangat berguna untuk percakapan bergaya obrolan yang konteks dan sejarahnya memainkan peran penting.
Memori juga dapat ditambahkan ke rantai dengan banyak masukan, seperti rantai tanya jawab. Berikut ini contoh cara mengatur memori dalam rantai tanya jawab:
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.embeddings.cohere import CohereEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
from langchain.vectorstores import Chroma
from langchain.docstore.document import Document
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.memory import ConversationBufferMemory # Split a long document into smaller chunks
with open("../../state_of_the_union.txt") as f: state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union) # Create an ElasticVectorSearch instance to index and search the document chunks
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_texts( texts, embeddings, metadatas=[{"source": i} for i in range(len(texts))]
) # Perform a question about the document
query = "What did the president say about Justice Breyer"
docs = docsearch.similarity_search(query) # Set up a prompt for the question-answering chain with memory
template = """You are a chatbot having a conversation with a human. Given the following extracted parts of a long document and a question, create a final answer. {context} {chat_history}
Human: {human_input}
Chatbot:""" prompt = PromptTemplate( input_variables=["chat_history", "human_input", "context"], template=template
)
memory = ConversationBufferMemory(memory_key="chat_history", input_key="human_input")
chain = load_qa_chain( OpenAI(temperature=0), chain_type="stuff", memory=memory, prompt=prompt
) # Ask the question and retrieve the answer
query = "What did the president say about Justice Breyer"
result = chain({"input_documents": docs, "human_input": query}, return_only_outputs=True) print(result)
print(chain.memory.buffer)
Dalam contoh ini, sebuah pertanyaan dijawab menggunakan dokumen yang dipecah menjadi beberapa bagian yang lebih kecil. ConversationBufferMemory digunakan untuk menyimpan dan mengambil riwayat percakapan, memungkinkan model memberikan jawaban yang peka konteks.
Menambahkan memori ke agen memungkinkannya mengingat dan menggunakan interaksi sebelumnya untuk menjawab pertanyaan dan memberikan respons sadar konteks. Berikut cara menyiapkan memori di agen:
from langchain.agents import ZeroShotAgent, Tool, AgentExecutor
from langchain.memory import ConversationBufferMemory
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.utilities import GoogleSearchAPIWrapper # Create a tool for searching
search = GoogleSearchAPIWrapper()
tools = [ Tool( name="Search", func=search.run, description="useful for when you need to answer questions about current events", )
] # Create a prompt with memory
prefix = """Have a conversation with a human, answering the following questions as best you can. You have access to the following tools:"""
suffix = """Begin!" {chat_history}
Question: {input}
{agent_scratchpad}""" prompt = ZeroShotAgent.create_prompt( tools, prefix=prefix, suffix=suffix, input_variables=["input", "chat_history", "agent_scratchpad"],
)
memory = ConversationBufferMemory(memory_key="chat_history") # Create an LLMChain with memory
llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=prompt)
agent = ZeroShotAgent(llm_chain=llm_chain, tools=tools, verbose=True)
agent_chain = AgentExecutor.from_agent_and_tools( agent=agent, tools=tools, verbose=True, memory=memory
) # Ask a question and retrieve the answer
response = agent_chain.run(input="How many people live in Canada?")
print(response) # Ask a follow-up question
response = agent_chain.run(input="What is their national anthem called?")
print(response)
Dalam contoh ini, memori ditambahkan ke agen, memungkinkannya mengingat riwayat percakapan sebelumnya dan memberikan jawaban sesuai konteks. Hal ini memungkinkan agen untuk menjawab pertanyaan lanjutan secara akurat berdasarkan informasi yang tersimpan dalam memori.
Bahasa Ekspresi LangChain
Dalam dunia pemrosesan bahasa alami dan pembelajaran mesin, menyusun rantai operasi yang kompleks dapat menjadi tugas yang berat. Untungnya, LangChain Expression Language (LCEL) hadir untuk menyelamatkan, menyediakan cara deklaratif dan efisien untuk membangun dan menerapkan jalur pemrosesan bahasa yang canggih. LCEL dirancang untuk menyederhanakan proses penyusunan rantai, sehingga memungkinkan peralihan dari pembuatan prototipe hingga produksi dengan mudah. Di blog ini, kita akan menjelajahi apa itu LCEL dan mengapa Anda ingin menggunakannya, bersama dengan contoh kode praktis untuk mengilustrasikan kemampuannya.
LCEL, atau LangChain Expression Language, adalah alat yang ampuh untuk menyusun rantai pemrosesan bahasa. Ini dibuat khusus untuk mendukung transisi dari pembuatan prototipe ke produksi dengan lancar, tanpa memerlukan perubahan kode yang ekstensif. Baik Anda sedang membangun rantai “prompt + LLM” sederhana atau saluran kompleks dengan ratusan langkah, LCEL siap membantu Anda.
Berikut beberapa alasan untuk menggunakan LCEL dalam proyek pemrosesan bahasa Anda:
- Streaming Token Cepat: LCEL mengirimkan token dari Model Bahasa ke parser keluaran secara real-time, meningkatkan daya tanggap dan efisiensi.
- API Serbaguna: LCEL mendukung API sinkron dan asinkron untuk pembuatan prototipe dan penggunaan produksi, menangani banyak permintaan secara efisien.
- Paralelisasi Otomatis: LCEL mengoptimalkan eksekusi paralel bila memungkinkan, mengurangi latensi pada antarmuka sinkronisasi dan asinkron.
- Konfigurasi yang Andal: Konfigurasikan percobaan ulang dan fallback untuk meningkatkan keandalan rantai dalam skala besar, dengan dukungan streaming dalam pengembangan.
- Streaming Hasil Antara: Akses hasil antara selama pemrosesan untuk pembaruan pengguna atau tujuan debugging.
- Pembuatan Skema: LCEL menghasilkan skema Pydantic dan JSONSchema untuk validasi input dan output.
- Pelacakan Komprehensif: LangSmith secara otomatis melacak semua langkah dalam rantai kompleks untuk observasi dan debugging.
- Penerapan Mudah: Terapkan rantai yang dibuat LCEL dengan mudah menggunakan LangServe.
Sekarang, mari selami contoh kode praktis yang menunjukkan kekuatan LCEL. Kami akan mengeksplorasi tugas dan skenario umum di mana LCEL unggul.
Cepat + LLM
Komposisi yang paling mendasar melibatkan penggabungan prompt dan model bahasa untuk membuat rantai yang mengambil masukan pengguna, menambahkannya ke prompt, meneruskannya ke model, dan mengembalikan keluaran model mentah. Berikut ini contohnya:
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI prompt = ChatPromptTemplate.from_template("tell me a joke about {foo}")
model = ChatOpenAI()
chain = prompt | model result = chain.invoke({"foo": "bears"})
print(result)
Dalam contoh ini, rantai menghasilkan lelucon tentang beruang.
Anda dapat melampirkan urutan penghentian ke rantai Anda untuk mengontrol cara rantai memproses teks. Misalnya:
chain = prompt | model.bind(stop=["n"])
result = chain.invoke({"foo": "bears"})
print(result)
Konfigurasi ini menghentikan pembuatan teks ketika karakter baris baru ditemukan.
LCEL mendukung melampirkan informasi panggilan fungsi ke rantai Anda. Berikut ini contohnya:
functions = [ { "name": "joke", "description": "A joke", "parameters": { "type": "object", "properties": { "setup": {"type": "string", "description": "The setup for the joke"}, "punchline": { "type": "string", "description": "The punchline for the joke", }, }, "required": ["setup", "punchline"], }, }
]
chain = prompt | model.bind(function_call={"name": "joke"}, functions=functions)
result = chain.invoke({"foo": "bears"}, config={})
print(result)
Contoh ini melampirkan informasi pemanggilan fungsi untuk menghasilkan lelucon.
Prompt + LLM + OutputParser
Anda dapat menambahkan parser keluaran untuk mengubah keluaran model mentah menjadi format yang lebih bisa diterapkan. Inilah cara Anda melakukannya:
from langchain.schema.output_parser import StrOutputParser chain = prompt | model | StrOutputParser()
result = chain.invoke({"foo": "bears"})
print(result)
Outputnya sekarang dalam format string, yang lebih nyaman untuk tugas hilir.
Saat menentukan fungsi yang akan dikembalikan, Anda dapat menguraikannya secara langsung menggunakan LCEL. Misalnya:
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser chain = ( prompt | model.bind(function_call={"name": "joke"}, functions=functions) | JsonOutputFunctionsParser()
)
result = chain.invoke({"foo": "bears"})
print(result)
Contoh ini mem-parsing output dari fungsi “lelucon” secara langsung.
Ini hanyalah beberapa contoh bagaimana LCEL menyederhanakan tugas pemrosesan bahasa yang kompleks. Baik Anda membuat chatbot, membuat konten, atau melakukan transformasi teks yang kompleks, LCEL dapat menyederhanakan alur kerja Anda dan membuat kode Anda lebih mudah dikelola.
RAG (Generasi Pengambilan Augmented)
LCEL dapat digunakan untuk membuat rantai pengambilan-augmentasi pengambilan, yang menggabungkan langkah-langkah pengambilan dan pembuatan bahasa. Berikut ini contohnya:
from operator import itemgetter from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.vectorstores import FAISS # Create a vector store and retriever
vectorstore = FAISS.from_texts( ["harrison worked at kensho"], embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever() # Define templates for prompts
template = """Answer the question based only on the following context:
{context} Question: {question} """
prompt = ChatPromptTemplate.from_template(template) model = ChatOpenAI() # Create a retrieval-augmented generation chain
chain = ( {"context": retriever, "question": RunnablePassthrough()} | prompt | model | StrOutputParser()
) result = chain.invoke("where did harrison work?")
print(result)
Dalam contoh ini, rantai mengambil informasi yang relevan dari konteks dan menghasilkan respons terhadap pertanyaan tersebut.
Rantai Pengambilan Percakapan
Anda dapat dengan mudah menambahkan riwayat percakapan ke rantai Anda. Berikut ini contoh rantai pengambilan percakapan:
from langchain.schema.runnable import RunnableMap
from langchain.schema import format_document from langchain.prompts.prompt import PromptTemplate # Define templates for prompts
_template = """Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question, in its original language. Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:"""
CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template(_template) template = """Answer the question based only on the following context:
{context} Question: {question} """
ANSWER_PROMPT = ChatPromptTemplate.from_template(template) # Define input map and context
_inputs = RunnableMap( standalone_question=RunnablePassthrough.assign( chat_history=lambda x: _format_chat_history(x["chat_history"]) ) | CONDENSE_QUESTION_PROMPT | ChatOpenAI(temperature=0) | StrOutputParser(),
)
_context = { "context": itemgetter("standalone_question") | retriever | _combine_documents, "question": lambda x: x["standalone_question"],
}
conversational_qa_chain = _inputs | _context | ANSWER_PROMPT | ChatOpenAI() result = conversational_qa_chain.invoke( { "question": "where did harrison work?", "chat_history": [], }
)
print(result)
Dalam contoh ini, rantai menangani pertanyaan lanjutan dalam konteks percakapan.
Dengan Memori dan Dokumen Sumber Pengembalian
LCEL juga mendukung memori dan pengembalian dokumen sumber. Inilah cara Anda dapat menggunakan memori dalam sebuah rantai:
from operator import itemgetter
from langchain.memory import ConversationBufferMemory # Create a memory instance
memory = ConversationBufferMemory( return_messages=True, output_key="answer", input_key="question"
) # Define steps for the chain
loaded_memory = RunnablePassthrough.assign( chat_history=RunnableLambda(memory.load_memory_variables) | itemgetter("history"),
) standalone_question = { "standalone_question": { "question": lambda x: x["question"], "chat_history": lambda x: _format_chat_history(x["chat_history"]), } | CONDENSE_QUESTION_PROMPT | ChatOpenAI(temperature=0) | StrOutputParser(),
} retrieved_documents = { "docs": itemgetter("standalone_question") | retriever, "question": lambda x: x["standalone_question"],
} final_inputs = { "context": lambda x: _combine_documents(x["docs"]), "question": itemgetter("question"),
} answer = { "answer": final_inputs | ANSWER_PROMPT | ChatOpenAI(), "docs": itemgetter("docs"),
} # Create the final chain by combining the steps
final_chain = loaded_memory | standalone_question | retrieved_documents | answer inputs = {"question": "where did harrison work?"}
result = final_chain.invoke(inputs)
print(result)
Dalam contoh ini, memori digunakan untuk menyimpan dan mengambil riwayat percakapan dan dokumen sumber.
Banyak Rantai
Anda dapat merangkai beberapa rantai menggunakan Runnables. Berikut ini contohnya:
from operator import itemgetter from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser prompt1 = ChatPromptTemplate.from_template("what is the city {person} is from?")
prompt2 = ChatPromptTemplate.from_template( "what country is the city {city} in? respond in {language}"
) model = ChatOpenAI() chain1 = prompt1 | model | StrOutputParser() chain2 = ( {"city": chain1, "language": itemgetter("language")} | prompt2 | model | StrOutputParser()
) result = chain2.invoke({"person": "obama", "language": "spanish"})
print(result)
Dalam contoh ini, dua rantai digabungkan untuk menghasilkan informasi tentang kota dan negaranya dalam bahasa tertentu.
Percabangan dan Penggabungan
LCEL memungkinkan Anda membagi dan menggabungkan rantai menggunakan RunnableMaps. Berikut contoh percabangan dan penggabungan:
from operator import itemgetter from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser planner = ( ChatPromptTemplate.from_template("Generate an argument about: {input}") | ChatOpenAI() | StrOutputParser() | {"base_response": RunnablePassthrough()}
) arguments_for = ( ChatPromptTemplate.from_template( "List the pros or positive aspects of {base_response}" ) | ChatOpenAI() | StrOutputParser()
)
arguments_against = ( ChatPromptTemplate.from_template( "List the cons or negative aspects of {base_response}" ) | ChatOpenAI() | StrOutputParser()
) final_responder = ( ChatPromptTemplate.from_messages( [ ("ai", "{original_response}"), ("human", "Pros:n{results_1}nnCons:n{results_2}"), ("system", "Generate a final response given the critique"), ] ) | ChatOpenAI() | StrOutputParser()
) chain = ( planner | { "results_1": arguments_for, "results_2": arguments_against, "original_response": itemgetter("base_response"), } | final_responder
) result = chain.invoke({"input": "scrum"})
print(result)
Dalam contoh ini, rantai percabangan dan penggabungan digunakan untuk menghasilkan argumen dan mengevaluasi pro dan kontra sebelum menghasilkan respons akhir.
Menulis Kode Python dengan LCEL
Salah satu aplikasi canggih LangChain Expression Language (LCEL) adalah menulis kode Python untuk memecahkan masalah pengguna. Di bawah ini adalah contoh cara menggunakan LCEL untuk menulis kode Python:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain_experimental.utilities import PythonREPL template = """Write some python code to solve the user's problem. Return only python code in Markdown format, e.g.: ```python
....
```"""
prompt = ChatPromptTemplate.from_messages([("system", template), ("human", "{input}")]) model = ChatOpenAI() def _sanitize_output(text: str): _, after = text.split("```python") return after.split("```")[0] chain = prompt | model | StrOutputParser() | _sanitize_output | PythonREPL().run result = chain.invoke({"input": "what's 2 plus 2"})
print(result)
Dalam contoh ini, pengguna memberikan masukan, dan LCEL menghasilkan kode Python untuk memecahkan masalah. Kode tersebut kemudian dieksekusi menggunakan Python REPL, dan kode Python yang dihasilkan dikembalikan dalam format Markdown.
Harap dicatat bahwa menggunakan Python REPL dapat mengeksekusi kode arbitrer, jadi gunakanlah dengan hati-hati.
Menambahkan Memori ke Rantai
Memori sangat penting dalam banyak aplikasi AI percakapan. Berikut cara menambahkan memori ke rantai arbitrer:
from operator import itemgetter
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder model = ChatOpenAI()
prompt = ChatPromptTemplate.from_messages( [ ("system", "You are a helpful chatbot"), MessagesPlaceholder(variable_name="history"), ("human", "{input}"), ]
) memory = ConversationBufferMemory(return_messages=True) # Initialize memory
memory.load_memory_variables({}) chain = ( RunnablePassthrough.assign( history=RunnableLambda(memory.load_memory_variables) | itemgetter("history") ) | prompt | model
) inputs = {"input": "hi, I'm Bob"}
response = chain.invoke(inputs)
response # Save the conversation in memory
memory.save_context(inputs, {"output": response.content}) # Load memory to see the conversation history
memory.load_memory_variables({})
Dalam contoh ini, memori digunakan untuk menyimpan dan mengambil riwayat percakapan, memungkinkan chatbot mempertahankan konteks dan merespons dengan tepat.
Menggunakan Alat Eksternal dengan Runnables
LCEL memungkinkan Anda mengintegrasikan alat eksternal dengan Runnables secara mulus. Berikut ini contoh penggunaan alat Pencarian DuckDuckGo:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.tools import DuckDuckGoSearchRun search = DuckDuckGoSearchRun() template = """Turn the following user input into a search query for a search engine: {input}"""
prompt = ChatPromptTemplate.from_template(template) model = ChatOpenAI() chain = prompt | model | StrOutputParser() | search search_result = chain.invoke({"input": "I'd like to figure out what games are tonight"})
print(search_result)
Dalam contoh ini, LCEL mengintegrasikan alat Pencarian DuckDuckGo ke dalam rantai, memungkinkannya menghasilkan permintaan pencarian dari input pengguna dan mengambil hasil pencarian.
Fleksibilitas LCEL memudahkan penggabungan berbagai alat dan layanan eksternal ke dalam saluran pemrosesan bahasa Anda, sehingga meningkatkan kemampuan dan fungsionalitasnya.
Menambahkan Moderasi ke Aplikasi LLM
Untuk memastikan bahwa aplikasi LLM Anda mematuhi kebijakan konten dan mencakup perlindungan moderasi, Anda dapat mengintegrasikan pemeriksaan moderasi ke dalam rantai Anda. Berikut cara menambahkan moderasi menggunakan LangChain:
from langchain.chains import OpenAIModerationChain
from langchain.llms import OpenAI
from langchain.prompts import ChatPromptTemplate moderate = OpenAIModerationChain() model = OpenAI()
prompt = ChatPromptTemplate.from_messages([("system", "repeat after me: {input}")]) chain = prompt | model # Original response without moderation
response_without_moderation = chain.invoke({"input": "you are stupid"})
print(response_without_moderation) moderated_chain = chain | moderate # Response after moderation
response_after_moderation = moderated_chain.invoke({"input": "you are stupid"})
print(response_after_moderation)
Dalam contoh ini, the OpenAIModerationChain digunakan untuk menambahkan moderasi pada respons yang dihasilkan oleh LLM. Rantai moderasi memeriksa respons terhadap konten yang melanggar kebijakan konten OpenAI. Jika ada pelanggaran yang ditemukan, pihaknya akan menandai respons yang sesuai.
Perutean berdasarkan Kesamaan Semantik
LCEL memungkinkan Anda menerapkan logika perutean khusus berdasarkan kesamaan semantik input pengguna. Berikut ini contoh cara menentukan logika rantai secara dinamis berdasarkan masukan pengguna:
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import PromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableLambda, RunnablePassthrough
from langchain.utils.math import cosine_similarity physics_template = """You are a very smart physics professor. You are great at answering questions about physics in a concise and easy to understand manner. When you don't know the answer to a question you admit that you don't know. Here is a question:
{query}""" math_template = """You are a very good mathematician. You are great at answering math questions. You are so good because you are able to break down hard problems into their component parts, answer the component parts, and then put them together to answer the broader question. Here is a question:
{query}""" embeddings = OpenAIEmbeddings()
prompt_templates = [physics_template, math_template]
prompt_embeddings = embeddings.embed_documents(prompt_templates) def prompt_router(input): query_embedding = embeddings.embed_query(input["query"]) similarity = cosine_similarity([query_embedding], prompt_embeddings)[0] most_similar = prompt_templates[similarity.argmax()] print("Using MATH" if most_similar == math_template else "Using PHYSICS") return PromptTemplate.from_template(most_similar) chain = ( {"query": RunnablePassthrough()} | RunnableLambda(prompt_router) | ChatOpenAI() | StrOutputParser()
) print(chain.invoke({"query": "What's a black hole"}))
print(chain.invoke({"query": "What's a path integral"}))
Dalam contoh ini, the prompt_router fungsi menghitung kesamaan kosinus antara masukan pengguna dan templat cepat yang telah ditentukan sebelumnya untuk pertanyaan fisika dan matematika. Berdasarkan skor kesamaan, rantai secara dinamis memilih templat perintah yang paling relevan, memastikan bahwa chatbot merespons pertanyaan pengguna dengan tepat.
Menggunakan Agen dan Runnables
LangChain memungkinkan Anda membuat agen dengan menggabungkan Runnables, prompt, model, dan alat. Berikut ini contoh membangun agen dan menggunakannya:
from langchain.agents import XMLAgent, tool, AgentExecutor
from langchain.chat_models import ChatAnthropic model = ChatAnthropic(model="claude-2") @tool
def search(query: str) -> str: """Search things about current events.""" return "32 degrees" tool_list = [search] # Get prompt to use
prompt = XMLAgent.get_default_prompt() # Logic for going from intermediate steps to a string to pass into the model
def convert_intermediate_steps(intermediate_steps): log = "" for action, observation in intermediate_steps: log += ( f"<tool>{action.tool}</tool><tool_input>{action.tool_input}" f"</tool_input><observation>{observation}</observation>" ) return log # Logic for converting tools to a string to go in the prompt
def convert_tools(tools): return "n".join([f"{tool.name}: {tool.description}" for tool in tools]) agent = ( { "question": lambda x: x["question"], "intermediate_steps": lambda x: convert_intermediate_steps( x["intermediate_steps"] ), } | prompt.partial(tools=convert_tools(tool_list)) | model.bind(stop=["</tool_input>", "</final_answer>"]) | XMLAgent.get_default_output_parser()
) agent_executor = AgentExecutor(agent=agent, tools=tool_list, verbose=True) result = agent_executor.invoke({"question": "What's the weather in New York?"})
print(result)
Dalam contoh ini, agen dibuat dengan menggabungkan model, alat, perintah, dan logika kustom untuk langkah perantara dan konversi alat. Agen kemudian dieksekusi, memberikan respons terhadap permintaan pengguna.
Membuat Kueri Database SQL
Anda dapat menggunakan LangChain untuk menanyakan database SQL dan menghasilkan kueri SQL berdasarkan pertanyaan pengguna. Berikut ini contohnya:
from langchain.prompts import ChatPromptTemplate template = """Based on the table schema below, write a SQL query that would answer the user's question:
{schema} Question: {question}
SQL Query:"""
prompt = ChatPromptTemplate.from_template(template) from langchain.utilities import SQLDatabase # Initialize the database (you'll need the Chinook sample DB for this example)
db = SQLDatabase.from_uri("sqlite:///./Chinook.db") def get_schema(_): return db.get_table_info() def run_query(query): return db.run(query) from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough model = ChatOpenAI() sql_response = ( RunnablePassthrough.assign(schema=get_schema) | prompt | model.bind(stop=["nSQLResult:"]) | StrOutputParser()
) result = sql_response.invoke({"question": "How many employees are there?"})
print(result) template = """Based on the table schema below, question, SQL query, and SQL response, write a natural language response:
{schema} Question: {question}
SQL Query: {query}
SQL Response: {response}"""
prompt_response = ChatPromptTemplate.from_template(template) full_chain = ( RunnablePassthrough.assign(query=sql_response) | RunnablePassthrough.assign( schema=get_schema, response=lambda x: db.run(x["query"]), ) | prompt_response | model
) response = full_chain.invoke({"question": "How many employees are there?"})
print(response)
Dalam contoh ini, LangChain digunakan untuk menghasilkan kueri SQL berdasarkan pertanyaan pengguna dan mengambil respons dari database SQL. Perintah dan respons diformat untuk menyediakan interaksi bahasa alami dengan database.
Otomatiskan tugas dan alur kerja manual dengan pembuat alur kerja berbasis AI kami, yang dirancang oleh Nanonets untuk Anda dan tim Anda.
LangServe & LangSmith
LangServe membantu pengembang menerapkan runnable dan rantai LangChain sebagai REST API. Library ini terintegrasi dengan FastAPI dan menggunakan pydantic untuk validasi data. Selain itu, ia menyediakan klien yang dapat digunakan untuk memanggil runnable yang diterapkan di server, dan klien JavaScript tersedia di LangChainJS.
Fitur
- Skema Input dan Output secara otomatis disimpulkan dari objek LangChain Anda dan diterapkan pada setiap panggilan API, dengan banyak pesan kesalahan.
- Halaman dokumen API dengan JSONSchema dan Swagger tersedia.
- Titik akhir /invoke, /batch, dan /stream yang efisien dengan dukungan untuk banyak permintaan bersamaan di satu server.
- /stream_log endpoint untuk streaming semua (atau beberapa) langkah perantara dari rantai/agen Anda.
- Halaman taman bermain di /playground dengan keluaran streaming dan langkah perantara.
- Pelacakan bawaan (opsional) ke LangSmith; cukup tambahkan kunci API Anda (lihat Petunjuk).
- Semua dibangun dengan pustaka Python sumber terbuka yang telah teruji pertempuran seperti FastAPI, Pydantic, uvloop, dan asyncio.
keterbatasan
- Callback klien belum didukung untuk kejadian yang berasal dari server.
- Dokumen OpenAPI tidak akan dibuat saat menggunakan Pydantic V2. FastAPI tidak mendukung pencampuran namespace pydantic v1 dan v2. Lihat bagian di bawah untuk lebih jelasnya.
Gunakan LangChain CLI untuk mem-bootstrap proyek LangServe dengan cepat. Untuk menggunakan langchain CLI, pastikan Anda menginstal langchain-cli versi terbaru. Anda dapat menginstalnya dengan pip install -U langchain-cli.
langchain app new ../path/to/directory
Mulai instans LangServe Anda dengan cepat menggunakan Templat LangChain. Untuk contoh lainnya, lihat indeks templat atau direktori contoh.
Berikut adalah server yang menerapkan model obrolan OpenAI, model obrolan Antropik, dan rantai yang menggunakan model Antropik untuk menceritakan lelucon tentang suatu topik.
#!/usr/bin/env python
from fastapi import FastAPI
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatAnthropic, ChatOpenAI
from langserve import add_routes app = FastAPI( title="LangChain Server", version="1.0", description="A simple api server using Langchain's Runnable interfaces",
) add_routes( app, ChatOpenAI(), path="/openai",
) add_routes( app, ChatAnthropic(), path="/anthropic",
) model = ChatAnthropic()
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
add_routes( app, prompt | model, path="/chain",
) if __name__ == "__main__": import uvicorn uvicorn.run(app, host="localhost", port=8000)
Setelah Anda menerapkan server di atas, Anda dapat melihat dokumen OpenAPI yang dihasilkan menggunakan:
curl localhost:8000/docs
Pastikan untuk menambahkan akhiran /docs.
from langchain.schema import SystemMessage, HumanMessage
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnableMap
from langserve import RemoteRunnable openai = RemoteRunnable("https://localhost:8000/openai/")
anthropic = RemoteRunnable("https://localhost:8000/anthropic/")
joke_chain = RemoteRunnable("https://localhost:8000/chain/") joke_chain.invoke({"topic": "parrots"}) # or async
await joke_chain.ainvoke({"topic": "parrots"}) prompt = [ SystemMessage(content='Act like either a cat or a parrot.'), HumanMessage(content='Hello!')
] # Supports astream
async for msg in anthropic.astream(prompt): print(msg, end="", flush=True) prompt = ChatPromptTemplate.from_messages( [("system", "Tell me a long story about {topic}")]
) # Can define custom chains
chain = prompt | RunnableMap({ "openai": openai, "anthropic": anthropic,
}) chain.batch([{ "topic": "parrots" }, { "topic": "cats" }])
Dalam TypeScript (memerlukan LangChain.js versi 0.0.166 atau lebih baru):
import { RemoteRunnable } from "langchain/runnables/remote"; const chain = new RemoteRunnable({ url: `https://localhost:8000/chain/invoke/`,
});
const result = await chain.invoke({ topic: "cats",
});
Python menggunakan permintaan:
import requests
response = requests.post( "https://localhost:8000/chain/invoke/", json={'input': {'topic': 'cats'}}
)
response.json()
Anda juga dapat menggunakan ikal:
curl --location --request POST 'https://localhost:8000/chain/invoke/' --header 'Content-Type: application/json' --data-raw '{ "input": { "topic": "cats" } }'
Kode berikut:
...
add_routes( app, runnable, path="/my_runnable",
)
menambahkan titik akhir ini ke server:
- POST /my_runnable/invoke – memanggil runnable dengan satu input
- POST /my_runnable/batch – memanggil runnable pada sejumlah input
- POST /my_runnable/stream – memanggil satu input dan mengalirkan output
- POST /my_runnable/stream_log – memanggil satu input dan mengalirkan output, termasuk output dari langkah-langkah perantara saat dihasilkan
- GET /my_runnable/input_schema – skema json untuk input ke runnable
- GET /my_runnable/output_schema – skema json untuk output dari runnable
- DAPATKAN /my_runnable/config_schema – skema json untuk konfigurasi runnable
Anda dapat menemukan halaman taman bermain untuk runnable Anda di /my_runnable/playground. Ini memperlihatkan UI sederhana untuk mengonfigurasi dan memanggil runnable Anda dengan keluaran streaming dan langkah-langkah perantara.
Untuk klien dan server:
pip install "langserve[all]"
atau pip install “langserve[client]” untuk kode klien, dan pip install “langserve[server]” untuk kode server.
Jika Anda perlu menambahkan autentikasi ke server Anda, harap rujuk dokumentasi keamanan FastAPI dan dokumentasi middleware.
Anda dapat men-deploy ke GCP Cloud Run menggunakan perintah berikut:
gcloud run deploy [your-service-name] --source . --port 8001 --allow-unauthenticated --region us-central1 --set-env-vars=OPENAI_API_KEY=your_key
LangServe memberikan dukungan untuk Pydantic 2 dengan beberapa keterbatasan. Dokumen OpenAPI tidak akan dibuat untuk pemanggilan/batch/stream/stream_log saat menggunakan Pydantic V2. Fast API tidak mendukung pencampuran namespace pydantic v1 dan v2. LangChain menggunakan namespace v1 di Pydantic v2. Silakan baca panduan berikut untuk memastikan kompatibilitas dengan LangChain. Kecuali batasan ini, kami berharap titik akhir API, taman bermain, dan fitur lainnya berfungsi sesuai harapan.
Aplikasi LLM sering kali menangani file. Ada berbagai arsitektur yang dapat dibuat untuk mengimplementasikan pemrosesan file; pada tingkat tinggi:
- File dapat diunggah ke server melalui titik akhir khusus dan diproses menggunakan titik akhir terpisah.
- File dapat diunggah berdasarkan nilai (byte file) atau referensi (misalnya, url s3 ke konten file).
- Titik akhir pemrosesan mungkin memblokir atau non-pemblokiran.
- Jika diperlukan pemrosesan yang signifikan, pemrosesan dapat dipindahkan ke kumpulan proses khusus.
Anda harus menentukan arsitektur apa yang sesuai untuk aplikasi Anda. Saat ini, untuk mengunggah file berdasarkan nilai ke runnable, gunakan pengkodean base64 untuk file tersebut (multipart/form-data belum didukung).
Ini sebuah contoh yang menunjukkan cara menggunakan pengkodean base64 untuk mengirim file ke runnable jarak jauh. Ingat, Anda selalu dapat mengunggah file dengan referensi (misalnya, url s3) atau mengunggahnya sebagai data multibagian/formulir ke titik akhir khusus.
Tipe Input dan Output ditentukan pada semua runnable. Anda dapat mengaksesnya melalui properti input_schema dan output_schema. LangServe menggunakan tipe ini untuk validasi dan dokumentasi. Jika Anda ingin mengganti tipe inferensi default, Anda dapat menggunakan metode with_types.
Berikut ini contoh mainan untuk mengilustrasikan ide tersebut:
from typing import Any
from fastapi import FastAPI
from langchain.schema.runnable import RunnableLambda app = FastAPI() def func(x: Any) -> int: """Mistyped function that should accept an int but accepts anything.""" return x + 1 runnable = RunnableLambda(func).with_types( input_schema=int,
) add_routes(app, runnable)
Mewarisi dari CustomUserType jika Anda ingin data dideserialisasi menjadi model pydantic daripada representasi dict yang setara. Saat ini, tipe ini hanya berfungsi di sisi server dan digunakan untuk menentukan perilaku decoding yang diinginkan. Jika mewarisi dari tipe ini, server akan menyimpan tipe yang didekodekan sebagai model pydantic alih-alih mengubahnya menjadi dict.
from fastapi import FastAPI
from langchain.schema.runnable import RunnableLambda
from langserve import add_routes
from langserve.schema import CustomUserType app = FastAPI() class Foo(CustomUserType): bar: int def func(foo: Foo) -> int: """Sample function that expects a Foo type which is a pydantic model""" assert isinstance(foo, Foo) return foo.bar add_routes(app, RunnableLambda(func), path="/foo")
Taman bermain memungkinkan Anda menentukan widget khusus untuk runnable Anda dari backend. Widget ditentukan di tingkat bidang dan dikirimkan sebagai bagian dari skema JSON dari jenis input. Widget harus berisi kunci yang disebut tipe dengan nilai yang merupakan salah satu daftar widget yang terkenal. Kunci widget lainnya akan dikaitkan dengan nilai yang menjelaskan jalur dalam objek JSON.
Skema umum:
type JsonPath = number | string | (number | string)[];
type NameSpacedPath = { title: string; path: JsonPath }; // Using title to mimic json schema, but can use namespace
type OneOfPath = { oneOf: JsonPath[] }; type Widget = { type: string // Some well-known type (e.g., base64file, chat, etc.) [key: string]: JsonPath | NameSpacedPath | OneOfPath;
};
Mengizinkan pembuatan input unggahan file di taman bermain UI untuk file yang diunggah sebagai string yang dikodekan base64. Berikut contoh lengkapnya.
try: from pydantic.v1 import Field
except ImportError: from pydantic import Field from langserve import CustomUserType # ATTENTION: Inherit from CustomUserType instead of BaseModel otherwise
# the server will decode it into a dict instead of a pydantic model.
class FileProcessingRequest(CustomUserType): """Request including a base64 encoded file.""" # The extra field is used to specify a widget for the playground UI. file: str = Field(..., extra={"widget": {"type": "base64file"}}) num_chars: int = 100
Otomatiskan tugas dan alur kerja manual dengan pembuat alur kerja berbasis AI kami, yang dirancang oleh Nanonets untuk Anda dan tim Anda.
Pengantar LangSmith
LangChain memudahkan pembuatan prototipe aplikasi dan Agen LLM. Namun, mengirimkan aplikasi LLM ke produksi bisa jadi sulit dilakukan. Anda mungkin harus banyak menyesuaikan dan mengulangi perintah, rantai, dan komponen lainnya untuk menciptakan produk berkualitas tinggi.
Untuk membantu proses ini, LangSmith diperkenalkan, sebuah platform terpadu untuk debugging, pengujian, dan pemantauan aplikasi LLM Anda.
Kapan ini berguna? Anda mungkin merasakan manfaatnya ketika Anda ingin dengan cepat men-debug rantai, agen, atau seperangkat alat baru, memvisualisasikan bagaimana komponen (rantai, llms, retriever, dll.) berhubungan dan digunakan, mengevaluasi perintah dan LLM yang berbeda untuk satu komponen, menjalankan rantai tertentu beberapa kali pada kumpulan data untuk memastikan rantai tersebut secara konsisten memenuhi standar kualitas, atau menangkap jejak penggunaan dan menggunakan LLM atau saluran analitik untuk menghasilkan wawasan.
Prasyarat:
- Buat akun LangSmith dan buat kunci API (lihat pojok kiri bawah).
- Biasakan diri Anda dengan platform ini dengan melihat dokumennya.
Sekarang, mari kita mulai!
Pertama, konfigurasikan variabel lingkungan Anda untuk memberi tahu LangChain untuk mencatat jejak. Hal ini dilakukan dengan menyetel variabel lingkungan LANGCHAIN_TRACING_V2 ke true. Anda dapat memberi tahu LangChain proyek mana yang harus dilog dengan mengatur variabel lingkungan LANGCHAIN_PROJECT (jika ini tidak disetel, proses yang berjalan akan dicatat ke proyek default). Ini secara otomatis akan membuat proyek untuk Anda jika tidak ada. Anda juga harus menyetel variabel lingkungan LANGCHAIN_ENDPOINT dan LANGCHAIN_API_KEY.
CATATAN: Anda juga dapat menggunakan manajer konteks dengan python untuk mencatat jejak menggunakan:
from langchain.callbacks.manager import tracing_v2_enabled with tracing_v2_enabled(project_name="My Project"): agent.run("How many people live in canada as of 2023?")
Namun, dalam contoh ini, kita akan menggunakan variabel lingkungan.
%pip install openai tiktoken pandas duckduckgo-search --quiet import os
from uuid import uuid4 unique_id = uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"Tracing Walkthrough - {unique_id}"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "<YOUR-API-KEY>" # Update to your API key # Used by the agent in this tutorial
os.environ["OPENAI_API_KEY"] = "<YOUR-OPENAI-API-KEY>"
Buat klien LangSmith untuk berinteraksi dengan API:
from langsmith import Client client = Client()
Buat komponen LangChain dan log run ke platform. Dalam contoh ini, kita akan membuat agen bergaya ReAct dengan akses ke alat pencarian umum (DuckDuckGo). Perintah agen dapat dilihat di Hub di sini:
from langchain import hub
from langchain.agents import AgentExecutor
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.chat_models import ChatOpenAI
from langchain.tools import DuckDuckGoSearchResults
from langchain.tools.render import format_tool_to_openai_function # Fetches the latest version of this prompt
prompt = hub.pull("wfh/langsmith-agent-prompt:latest") llm = ChatOpenAI( model="gpt-3.5-turbo-16k", temperature=0,
) tools = [ DuckDuckGoSearchResults( name="duck_duck_go" ), # General internet search using DuckDuckGo
] llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools]) runnable_agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
) agent_executor = AgentExecutor( agent=runnable_agent, tools=tools, handle_parsing_errors=True
)
Kami menjalankan agen secara bersamaan pada beberapa input untuk mengurangi latensi. Proses akan dicatat ke LangSmith di latar belakang, sehingga latensi eksekusi tidak terpengaruh:
inputs = [ "What is LangChain?", "What's LangSmith?", "When was Llama-v2 released?", "What is the langsmith cookbook?", "When did langchain first announce the hub?",
] results = agent_executor.batch([{"input": x} for x in inputs], return_exceptions=True) results[:2]
Dengan asumsi Anda telah berhasil menyiapkan lingkungan, jejak agen Anda akan muncul di bagian Proyek di aplikasi. Selamat!
Tampaknya agen tersebut tidak menggunakan alat tersebut secara efektif. Mari kita evaluasi sehingga kita mempunyai dasar.
Selain logging berjalan, LangSmith juga memungkinkan Anda menguji dan mengevaluasi aplikasi LLM Anda.
Di bagian ini, Anda akan memanfaatkan LangSmith untuk membuat kumpulan data benchmark dan menjalankan evaluator berbantuan AI pada agen. Anda akan melakukannya dalam beberapa langkah:
- Buat kumpulan data LangSmith:
Di bawah ini, kami menggunakan klien LangSmith untuk membuat kumpulan data dari pertanyaan masukan di atas dan label daftar. Anda akan menggunakannya nanti untuk mengukur kinerja agen baru. Kumpulan data adalah kumpulan contoh, yang tidak lebih dari pasangan input-output yang dapat Anda gunakan sebagai kasus uji pada aplikasi Anda:
outputs = [ "LangChain is an open-source framework for building applications using large language models. It is also the name of the company building LangSmith.", "LangSmith is a unified platform for debugging, testing, and monitoring language model applications and agents powered by LangChain", "July 18, 2023", "The langsmith cookbook is a github repository containing detailed examples of how to use LangSmith to debug, evaluate, and monitor large language model-powered applications.", "September 5, 2023",
] dataset_name = f"agent-qa-{unique_id}" dataset = client.create_dataset( dataset_name, description="An example dataset of questions over the LangSmith documentation.",
) for query, answer in zip(inputs, outputs): client.create_example( inputs={"input": query}, outputs={"output": answer}, dataset_id=dataset.id )
- Inisialisasi agen baru untuk melakukan benchmark:
LangSmith memungkinkan Anda mengevaluasi LLM, rantai, agen, atau bahkan fungsi khusus apa pun. Agen percakapan bersifat stateful (memiliki memori); untuk memastikan bahwa status ini tidak dibagikan di antara kumpulan data yang dijalankan, kami akan meneruskan chain_factory (
alias konstruktor) berfungsi untuk menginisialisasi setiap panggilan:
# Since chains can be stateful (e.g. they can have memory), we provide
# a way to initialize a new chain for each row in the dataset. This is done
# by passing in a factory function that returns a new chain for each row.
def agent_factory(prompt): llm_with_tools = llm.bind( functions=[format_tool_to_openai_function(t) for t in tools] ) runnable_agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser() ) return AgentExecutor(agent=runnable_agent, tools=tools, handle_parsing_errors=True)
- Konfigurasikan evaluasi:
Membandingkan hasil rantai di UI secara manual memang efektif, namun dapat memakan waktu. Akan sangat membantu jika menggunakan metrik otomatis dan masukan yang dibantu AI untuk mengevaluasi kinerja komponen Anda:
from langchain.evaluation import EvaluatorType
from langchain.smith import RunEvalConfig evaluation_config = RunEvalConfig( evaluators=[ EvaluatorType.QA, EvaluatorType.EMBEDDING_DISTANCE, RunEvalConfig.LabeledCriteria("helpfulness"), RunEvalConfig.LabeledScoreString( { "accuracy": """
Score 1: The answer is completely unrelated to the reference.
Score 3: The answer has minor relevance but does not align with the reference.
Score 5: The answer has moderate relevance but contains inaccuracies.
Score 7: The answer aligns with the reference but has minor errors or omissions.
Score 10: The answer is completely accurate and aligns perfectly with the reference.""" }, normalize_by=10, ), ], custom_evaluators=[],
)
- Jalankan agen dan evaluator:
Gunakan fungsi run_on_dataset (atau arun_on_dataset asinkron) untuk mengevaluasi model Anda. Ini akan:
- Ambil contoh baris dari kumpulan data yang ditentukan.
- Jalankan agen Anda (atau fungsi khusus apa pun) pada setiap contoh.
- Terapkan evaluator pada jejak proses yang dihasilkan dan contoh referensi terkait untuk menghasilkan umpan balik otomatis.
Hasilnya akan terlihat di aplikasi LangSmith:
chain_results = run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=functools.partial(agent_factory, prompt=prompt), evaluation=evaluation_config, verbose=True, client=client, project_name=f"runnable-agent-test-5d466cbc-{unique_id}", tags=[ "testing-notebook", "prompt:5d466cbc", ],
)
Sekarang setelah kami mendapatkan hasil uji coba, kami dapat membuat perubahan pada agen kami dan melakukan benchmark terhadapnya. Mari kita coba lagi dengan prompt yang berbeda dan lihat hasilnya:
candidate_prompt = hub.pull("wfh/langsmith-agent-prompt:39f3bbd0") chain_results = run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=functools.partial(agent_factory, prompt=candidate_prompt), evaluation=evaluation_config, verbose=True, client=client, project_name=f"runnable-agent-test-39f3bbd0-{unique_id}", tags=[ "testing-notebook", "prompt:39f3bbd0", ],
)
LangSmith memungkinkan Anda mengekspor data ke format umum seperti CSV atau JSONL langsung di aplikasi web. Anda juga dapat menggunakan klien untuk mengambil proses untuk analisis lebih lanjut, untuk menyimpannya di database Anda sendiri, atau untuk berbagi dengan orang lain. Mari kita ambil jejak proses dari proses evaluasi:
runs = client.list_runs(project_name=chain_results["project_name"], execution_order=1) # After some time, these will be populated.
client.read_project(project_name=chain_results["project_name"]).feedback_stats
Ini adalah panduan singkat untuk memulai, namun masih banyak cara lain untuk menggunakan LangSmith untuk mempercepat alur pengembang Anda dan memberikan hasil yang lebih baik.
Untuk informasi lebih lanjut tentang bagaimana Anda bisa mendapatkan hasil maksimal dari LangSmith, lihat dokumentasi LangSmith.
Naik level dengan Nanonet
Meskipun LangChain adalah alat yang berharga untuk mengintegrasikan model bahasa (LLM) dengan aplikasi Anda, LangChain mungkin menghadapi keterbatasan dalam kasus penggunaan perusahaan. Mari kita jelajahi bagaimana Nanonets melampaui LangChain untuk mengatasi tantangan-tantangan ini:
1. Konektivitas Data Komprehensif:
LangChain menawarkan konektor, namun mungkin tidak mencakup semua aplikasi ruang kerja dan format data yang diandalkan oleh bisnis. Nanonets menyediakan konektor data untuk lebih dari 100 aplikasi ruang kerja yang banyak digunakan, termasuk Slack, Notion, Google Suite, Salesforce, Zendesk, dan banyak lagi. Ini juga mendukung semua tipe data tidak terstruktur seperti PDF, TXT, gambar, file audio, dan file video, serta tipe data terstruktur seperti CSV, spreadsheet, MongoDB, dan database SQL.

2. Otomatisasi Tugas untuk Aplikasi Ruang Kerja:
Meskipun pembuatan teks/respons berfungsi dengan baik, kemampuan LangChain terbatas dalam penggunaan bahasa alami untuk melakukan tugas di berbagai aplikasi. Nanonets menawarkan agen pemicu/tindakan untuk aplikasi ruang kerja paling populer, memungkinkan Anda menyiapkan alur kerja yang mendengarkan peristiwa dan melakukan tindakan. Misalnya, Anda dapat mengotomatiskan respons email, entri CRM, kueri SQL, dan lainnya, semuanya melalui perintah bahasa alami.

3. Sinkronisasi Data Waktu Nyata:
LangChain mengambil data statis dengan konektor data, yang mungkin tidak mengikuti perubahan data di database sumber. Sebaliknya, Nanonets memastikan sinkronisasi real-time dengan sumber data, memastikan bahwa Anda selalu bekerja dengan informasi terbaru.

3. Konfigurasi Sederhana:
Mengonfigurasi elemen pipeline LangChain, seperti retriever dan synthesizer, bisa menjadi proses yang rumit dan memakan waktu. Nanonet menyederhanakan hal ini dengan menyediakan penyerapan dan pengindeksan data yang dioptimalkan untuk setiap jenis data, semuanya ditangani di latar belakang oleh Asisten AI. Hal ini mengurangi beban penyesuaian dan membuatnya lebih mudah untuk diatur dan digunakan.
4. Solusi Terpadu:
Tidak seperti LangChain, yang mungkin memerlukan implementasi unik untuk setiap tugas, Nanonets berfungsi sebagai solusi terpadu untuk menghubungkan data Anda dengan LLM. Baik Anda perlu membuat aplikasi LLM atau alur kerja AI, Nanonets menawarkan platform terpadu untuk beragam kebutuhan Anda.
Alur Kerja AI Nanonet
Alur Kerja Nanonets adalah Asisten AI multiguna yang aman yang menyederhanakan integrasi pengetahuan dan data Anda dengan LLM dan memfasilitasi pembuatan aplikasi dan alur kerja tanpa kode. Ini menawarkan antarmuka pengguna yang mudah digunakan, sehingga dapat diakses oleh individu dan organisasi.
Untuk memulai, Anda dapat menjadwalkan panggilan dengan salah satu pakar AI kami, yang dapat memberikan demo dan uji coba Alur Kerja Nanonets yang dipersonalisasi dan disesuaikan dengan kasus penggunaan spesifik Anda.
Setelah disiapkan, Anda dapat menggunakan bahasa alami untuk merancang dan menjalankan aplikasi dan alur kerja kompleks yang didukung oleh LLM, berintegrasi secara lancar dengan aplikasi dan data Anda.

Tingkatkan tim Anda dengan Nanonets AI untuk membuat aplikasi dan mengintegrasikan data Anda dengan aplikasi dan alur kerja berbasis AI, memungkinkan tim Anda fokus pada hal yang benar-benar penting.
Otomatiskan tugas dan alur kerja manual dengan pembuat alur kerja berbasis AI kami, yang dirancang oleh Nanonets untuk Anda dan tim Anda.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://nanonets.com/blog/langchain/

