Retrieval Augmented Generation (RAG) memungkinkan Anda menyediakan model bahasa besar (LLM) dengan akses ke data dari sumber pengetahuan eksternal seperti repositori, database, dan API tanpa perlu menyempurnakannya. Saat menggunakan AI generatif untuk menjawab pertanyaan, RAG memungkinkan LLM menjawab pertanyaan dengan informasi paling relevan dan terkini dan secara opsional mengutip sumber data mereka untuk verifikasi.
Solusi RAG yang umum untuk pengambilan pengetahuan dari dokumen menggunakan model penyematan untuk mengonversi data dari sumber data menjadi penyematan dan menyimpan penyematan ini dalam database vektor. Saat pengguna mengajukan pertanyaan, ia mencari database vektor dan mengambil dokumen yang paling mirip dengan kueri pengguna. Selanjutnya, menggabungkan dokumen yang diambil dan permintaan pengguna dalam prompt tambahan yang dikirim ke LLM untuk pembuatan teks. Ada dua model dalam implementasi ini: model embeddings dan LLM yang menghasilkan respon akhir.
Dalam posting ini, kami menunjukkan cara menggunakan Studio Amazon SageMaker untuk membangun solusi menjawab pertanyaan RAG.
Menggunakan buku catatan untuk menjawab pertanyaan berbasis RAG
Menerapkan RAG biasanya memerlukan eksperimen dengan berbagai model penyematan, database vektor, model pembuatan teks, dan perintah, sekaligus melakukan debug pada kode hingga Anda mencapai prototipe yang berfungsi. Amazon SageMaker menawarkan notebook Jupyter terkelola yang dilengkapi dengan instans GPU, memungkinkan Anda bereksperimen dengan cepat selama fase awal ini tanpa menambah infrastruktur tambahan. Ada dua opsi untuk menggunakan notebook di SageMaker. Opsi pertama adalah peluncuran cepat laptop tersedia melalui SageMaker Studio. Di SageMaker Studio, lingkungan pengembangan terintegrasi (IDE) yang dibuat khusus untuk ML, Anda dapat meluncurkan notebook yang berjalan pada jenis instans berbeda dan dengan konfigurasi berbeda, berkolaborasi dengan kolega, dan mengakses fitur tambahan yang dibuat khusus untuk pembelajaran mesin (ML). Opsi kedua adalah menggunakan a Instance notebook SageMaker, yang merupakan instance komputasi ML terkelola sepenuhnya yang menjalankan aplikasi Jupyter Notebook.
Dalam postingan ini, kami menyajikan solusi RAG yang menambah pengetahuan model dengan data tambahan dari sumber pengetahuan eksternal untuk memberikan respons yang lebih akurat dan spesifik pada domain kustom. Kami menggunakan satu notebook SageMaker Studio yang berjalan pada ml.g5.2xlarge contoh (1 GPU A10G) dan Llama 2 7b ngobrol hf, versi Llama 2 7b yang disempurnakan, yang dioptimalkan untuk kasus penggunaan dialog dari Hugging Face Hub. Kami menggunakan dua postingan Blog Media & Hiburan AWS sebagai sampel data eksternal, yang kami konversi menjadi penyematan dengan BAAI/bge-kecil-en-v1.5 penyematan. Kami menyimpan embeddings di dalamnya biji pinus, database berbasis vektor yang menawarkan pencarian performa tinggi dan pencocokan kesamaan. Kami juga membahas cara melakukan transisi dari bereksperimen di notebook ke menerapkan model Anda ke titik akhir SageMaker untuk inferensi waktu nyata saat Anda menyelesaikan pembuatan prototipe. Pendekatan yang sama dapat digunakan dengan model dan database vektor yang berbeda.
Ikhtisar solusi
Diagram berikut menggambarkan arsitektur solusi.

Penerapan solusi terdiri dari dua langkah tingkat tinggi: mengembangkan solusi menggunakan notebook SageMaker Studio, dan menerapkan model untuk inferensi.
Kembangkan solusi menggunakan notebook SageMaker Studio
Selesaikan langkah-langkah berikut untuk mulai mengembangkan solusi:
- Muat model obrolan Llama-2 7b dari Hugging Face Hub di notebook.
- Buat PromptTemplate dengan LangChain dan menggunakannya untuk membuat perintah untuk kasus penggunaan Anda.
- Untuk 1–2 contoh perintah, tambahkan teks statis yang relevan dari dokumen eksternal sebagai konteks cepat dan nilai apakah kualitas responsnya meningkat.
- Dengan asumsi kualitasnya meningkat, terapkan alur kerja menjawab pertanyaan RAG:
- Kumpulkan dokumen eksternal yang dapat membantu model menjawab pertanyaan dalam kasus penggunaan Anda dengan lebih baik.
- Muat model penyematan BGE dan gunakan model tersebut untuk menghasilkan penyematan dokumen-dokumen ini.
- Simpan penyematan ini dalam indeks Pinecone.
- Saat pengguna mengajukan pertanyaan, lakukan pencarian kesamaan di Pinecone dan tambahkan konten dari dokumen yang paling mirip ke konteks perintah.
Terapkan model ke SageMaker untuk inferensi dalam skala besar
Ketika Anda mencapai sasaran kinerja, Anda dapat menerapkan model ke SageMaker untuk digunakan oleh aplikasi AI generatif:
- Terapkan model obrolan Llama-2 7b ke titik akhir real-time SageMaker.
- Terapkan BAAI/bge-kecil-en-v1.5 menyematkan model ke titik akhir real-time SageMaker.
- Gunakan model yang diterapkan dalam pertanyaan Anda untuk menjawab aplikasi AI generatif.
Di bagian berikut, kami memandu Anda melalui langkah-langkah penerapan solusi ini di notebook SageMaker Studio.
Prasyarat
Untuk mengikuti langkah-langkah dalam postingan ini, Anda harus memiliki akun AWS dan Identitas AWS dan Manajemen Akses (IAM) peran dengan izin untuk membuat dan mengakses sumber daya solusi. Jika Anda baru mengenal AWS, lihat Buat akun AWS mandiri.
Untuk menggunakan notebook SageMaker Studio di akun AWS Anda, Anda memerlukan a Domain SageMaker dengan profil pengguna yang memiliki izin untuk meluncurkan aplikasi SageMaker Studio. Jika Anda baru mengenal SageMaker Studio, Pengaturan Studio Cepat adalah cara tercepat untuk memulai. Dengan satu klik, SageMaker menyediakan domain SageMaker dengan preset default, termasuk mengatur profil pengguna, peran IAM, autentikasi IAM, dan akses internet publik. Buku catatan untuk posting ini mengasumsikan ml.g5.2xlarge tipe instans. Untuk meninjau atau menambah kuota Anda, buka konsol AWS Service Quotas, pilih Layanan AWS di panel navigasi, pilih Amazon SageMaker, dan lihat nilai untuk aplikasi Studio KernelGateway yang sedang berjalan ml.g5.2xlarge contoh.

Setelah mengonfirmasi batas kuota, Anda harus menyelesaikan dependensi untuk menggunakan obrolan Llama 2 7b.
Obrolan Llama 2 7b tersedia di bawah Lisensi Llama 2. Untuk mengakses Llama 2 di Hugging Face, Anda perlu menyelesaikan beberapa langkah terlebih dahulu:
- Buat akun Hugging Face jika Anda belum memilikinya.
- Lengkapi formulir “Minta akses ke versi Llama berikutnya” di Meta situs web.
- Minta akses ke Lama 2 7b ngobrol di Memeluk Wajah.
Setelah Anda diberikan akses, Anda dapat membuat token akses baru untuk mengakses model. Untuk membuat token akses, navigasikan ke Settings halaman di situs web Hugging Face.
Anda harus memiliki akun Pinecone untuk menggunakannya sebagai database vektor. Biji pinus tersedia di AWS melalui Pasar AWS. Situs web Pinecone juga menawarkan opsi untuk membuat akun gratis yang dilengkapi dengan izin untuk membuat indeks tunggal, yang cukup untuk keperluan posting ini. Untuk mengambil kunci Pinecone Anda, buka Konsol biji pinus Dan pilihlah Keys API.

Siapkan buku catatan dan lingkungan
Untuk mengikuti kode di postingan ini, buka SageMaker Studio dan clone yang berikut ini Repositori GitHub. Selanjutnya, buka buku catatan studio-local-gen-ai/rag/RAG-dengan-Llama-2-on-Studio.ipynb dan pilih gambar PyTorch 2.0.0 Python 3.10 GPU Optimized, kernel Python 3, dan ml.g5.2xlarge sebagai tipe instans. Jika ini pertama kalinya Anda menggunakan buku catatan SageMaker Studio, lihat Buat atau Buka Notebook Amazon SageMaker Studio.
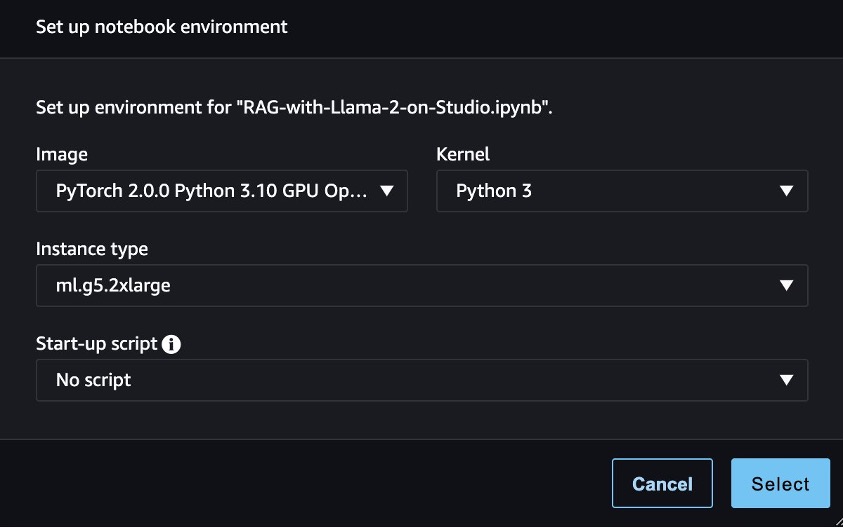
Untuk menyiapkan lingkungan pengembangan, Anda perlu menginstal pustaka Python yang diperlukan, seperti yang ditunjukkan dalam kode berikut:
%%writefile requirements.txt
sagemaker>=2.175.0
transformers==4.33.0
accelerate==0.21.0
datasets==2.13.0
langchain==0.0.297
pypdf>=3.16.3
pinecone-client
sentence_transformers
safetensors>=0.3.3!pip install -U -r requirements.txtMuat model dan tokenizer terlatih
Setelah Anda mengimpor perpustakaan yang diperlukan, Anda dapat memuat Obrolan Llama-2 7b model bersama dengan tokenizer yang sesuai dari Hugging Face. Artefak model yang dimuat ini disimpan di direktori lokal dalam SageMaker Studio. Hal ini memungkinkan Anda dengan cepat memuatnya kembali ke dalam memori kapan pun Anda perlu melanjutkan pekerjaan di waktu yang berbeda.
import torch from transformers import ( AutoTokenizer, LlamaTokenizer, LlamaForCausalLM, GenerationConfig, AutoModelForCausalLM
)
import transformers tg_model_id = "meta-llama/Llama-2-7b-chat-hf" #the model id in Hugging Face
tg_model_path = f"./tg_model/{tg_model_id}" #the local directory where the model will be saved tg_model = AutoModelForCausalLM.from_pretrained(tg_model_id, token=hf_access_token,do_sample=True, use_safetensors=True, device_map="auto", torch_dtype=torch.float16
tg_tokenizer = AutoTokenizer.from_pretrained(tg_model_id, token=hf_access_token) tg_model.save_pretrained(save_directory=tg_model_path, from_pt=True)
tg_tokenizer.save_pretrained(save_directory=tg_model_path, from_pt=True)Ajukan pertanyaan yang memerlukan informasi terkini
Anda sekarang dapat mulai menggunakan model dan mengajukan pertanyaan. Model obrolan Llama-2 mengharapkan perintah untuk mematuhi format berikut:
<s>[INST] <<SYS>>
system_prompt
<<SYS>>
{{ user_message }} [/INST]Anda dapat menggunakan Templat Prompt dari LangChain untuk membuat resep berdasarkan format prompt, sehingga Anda dapat dengan mudah membuat prompt selanjutnya:
from langchain import PromptTemplate template = """<s>[INST] <<SYS>>nYou are an assistant for question-answering tasks. You are helpful and friendly. Use the following pieces of retrieved context to answer the query. If you don't know the answer, you just say I don't know. Use three sentences maximum and keep the answer concise.
<<SYS>>n
{context}n
{question} [/INST] """
prompt_template = PromptTemplate( template=template, input_variables=['context','question'] )Mari kita ajukan pertanyaan kepada model yang memerlukan informasi terkini mulai tahun 2023. Anda dapat menggunakan LangChain dan khususnya rantai LLM jenis rantai dan berikan sebagai parameter LLM, templat prompt yang Anda buat sebelumnya, dan pertanyaannya:
question = "When can I visit the AWS M&E Customer Experience Center in New York City?" tg_tokenizer.add_special_tokens( {"pad_token": "[PAD]"} )
tg_tokenizer.padding_side = "left" tg_pipe = transformers.pipeline(task='text-generation', model=tg_model, tokenizer=tg_tokenizer, num_return_sequences=1, eos_token_id=tg_tokenizer.eos_token_id, pad_token_id=tg_tokenizer.eos_token_id, max_new_tokens=400, temperature=0.7) from langchain.chains import LLMChain
from langchain.llms import HuggingFacePipeline llm=HuggingFacePipeline(pipeline=tg_pipe, model_kwargs={'temperature':0.7})
llm_chain = LLMChain(llm=llm, prompt=prompt_template)
no_context_response = llm_chain.predict(context="", question=question)
print(no_context_response)Kami mendapatkan jawaban yang dihasilkan berikut:
Terima kasih telah menghubungi kami! Pusat Pengalaman Pelanggan AWS M&E di New York City saat ini ditutup untuk kunjungan karena pandemi COVID-19. Namun, Anda dapat memeriksa situs web resmi atau akun media sosial mereka untuk mengetahui informasi terbaru kapan pusat tersebut akan dibuka kembali. Sementara itu, Anda dapat menjelajahi tur virtual dan sumber daya yang tersedia secara online.
Tingkatkan jawaban dengan menambahkan konteks pada perintah
Jawaban yang kami hasilkan tidak sepenuhnya benar. Mari kita lihat apakah kita dapat memperbaikinya dengan memberikan konteks. Anda dapat menambahkan ekstrak dari postingan AWS mengumumkan Pusat Pengalaman Pelanggan M&E baru di New York, yang mencakup pembaruan topik mulai tahun 2023:
context = """Media and entertainment (M&E) customers continue to face challenges in creating more content, more quickly, and distributing it to more endpoints than ever before in their quest to delight viewers globally. Amazon Web Services (AWS), along with AWS Partners, have showcased the rapid evolution of M&E solutions for years at industry events like the National Association of Broadcasters (NAB) Show and the International Broadcast Convention (IBC). Until now, AWS for M&E technology demonstrations were accessible in this way just a few weeks out of the year. Customers are more engaged than ever before; they want to have higher quality conversations regarding user experience and media tooling. These conversations are best supported by having an interconnected solution architecture for reference. Scheduling a visit of the M&E Customer Experience Center will be available starting November 13th, please send an email to [email protected]."""Gunakan LLMChain lagi dan berikan teks sebelumnya sebagai konteks:
context_response = llm_chain.predict(context=context, question=question)
print(context_response)Respons baru menjawab pertanyaan dengan informasi terkini:
Anda dapat mengunjungi Pusat Pengalaman Pelanggan AWS M&E di New York City mulai tanggal 13 November. Silakan kirim email ke [email dilindungi] untuk menjadwalkan kunjungan.
Kami telah mengonfirmasi bahwa dengan menambahkan konteks yang tepat, performa model akan meningkat. Sekarang Anda dapat memfokuskan upaya Anda untuk menemukan dan menambahkan konteks yang tepat untuk pertanyaan yang diajukan. Dengan kata lain, terapkan RAG.
Terapkan jawaban pertanyaan RAG dengan penyematan BGE dan Pinecone
Pada saat ini, Anda harus memutuskan sumber informasi untuk meningkatkan pengetahuan model. Sumber ini dapat berupa halaman web internal atau dokumen dalam organisasi Anda, atau sumber data yang tersedia untuk umum. Untuk tujuan postingan ini dan demi kesederhanaan, kami telah memilih dua postingan Blog AWS yang diterbitkan pada tahun 2023:
Postingan ini sudah tersedia sebagai dokumen PDF di direktori proyek data di SageMaker Studio untuk akses cepat. Untuk membagi dokumen menjadi beberapa bagian yang dapat dikelola, Anda dapat menggunakan Pemisah TeksKarakter Rekursif metode dari LangChain:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFDirectoryLoader loader = PyPDFDirectoryLoader("./data/") documents = loader.load() text_splitter=RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=5
)
docs = text_splitter.split_documents(documents)Selanjutnya, gunakan model penyematan BGE bge-kecil-en diciptakan oleh Akademi Kecerdasan Buatan Beijing (BAAI) yang tersedia di Hugging Face untuk menghasilkan penyematan potongan ini. Unduh dan simpan model di direktori lokal di Studio. Kami menggunakan fp32 agar dapat berjalan di CPU instance.
em_model_name = "BAAI/bge-small-en"
em_model_path = f"./em-model" from transformers import AutoModel
# Load model from HuggingFace Hub
em_model = AutoModel.from_pretrained(em_model_name,torch_dtype=torch.float32)
em_tokenizer = AutoTokenizer.from_pretrained(em_model_name,device="cuda") # save model to disk
em_tokenizer.save_pretrained(save_directory=f"{em_model_path}/model",from_pt=True)
em_model.save_pretrained(save_directory=f"{em_model_path}/model",from_pt=True)
em_model.eval()Gunakan kode berikut untuk membuat fungsi embedding_generator, yang mengambil potongan dokumen sebagai masukan dan menghasilkan penyematan menggunakan model BGE:
# Tokenize sentences
def tokenize_text(_input, device): return em_tokenizer( [_input], padding=True, truncation=True, return_tensors='pt' ).to(device) # Run embedding task as a function with model and text sentences as input
def embedding_generator(_input, normalize=True): # Compute token embeddings with torch.no_grad(): embedded_output = em_model( **tokenize_text( _input, em_model.device ) ) sentence_embeddings = embedded_output[0][:, 0] # normalize embeddings if normalize: sentence_embeddings = torch.nn.functional.normalize( sentence_embeddings, p=2, dim=1 ) return sentence_embeddings[0, :].tolist() sample_sentence_embedding = embedding_generator(docs[0].page_content)
print(f"Embedding size of the document --->", len(sample_sentence_embedding))Dalam postingan ini, kami mendemonstrasikan alur kerja RAG menggunakan Pinecone, cloud-native yang terkelola basis data vektor yang juga menawarkan API untuk pencarian kesamaan. Anda bebas menulis ulang kode berikut untuk menggunakan database vektor pilihan Anda.
Kami menginisialisasi a Klien python biji pinus dan buat indeks pencarian vektor baru menggunakan panjang keluaran model penyematan. Kami menggunakan kelas Pinecone bawaan LangChain untuk menyerap embeddings yang kami buat pada langkah sebelumnya. Dibutuhkan tiga parameter: dokumen yang akan diserap, fungsi generator embeddings, dan nama indeks Pinecone.
import pinecone
pinecone.init( api_key = os.environ["PINECONE_API_KEY"], environment = os.environ["PINECONE_ENV"]
)
#check if index already exists, if not we create it
index_name = "rag-index"
if index_name not in pinecone.list_indexes(): pinecone.create_index( name=index_name, dimension=len(sample_sentence_embedding), ## 384 for bge-small-en metric='cosine' ) #insert the embeddings
from langchain.vectorstores import Pinecone
vector_store = Pinecone.from_documents( docs, embedding_generator, index_name=index_name
)Dengan model obrolan Llama-2 7B dimuat ke dalam memori dan penyematannya terintegrasi ke dalam indeks Pinecone, kini Anda dapat menggabungkan elemen-elemen ini untuk meningkatkan respons Llama 2 untuk kasus penggunaan tanya jawab kami. Untuk mencapai hal ini, Anda dapat menggunakan LangChain PengambilanQA, yang menambah prompt awal dengan dokumen paling mirip dari penyimpanan vektor. Dengan mengatur return_source_documents=True, Anda mendapatkan visibilitas ke dalam dokumen persis yang digunakan untuk menghasilkan jawaban sebagai bagian dari respons, sehingga memungkinkan Anda memverifikasi keakuratan jawaban.
from langchain.chains import RetrievalQA
import textwrap #helper method to improve the readability of the response
def print_response(llm_response): temp = [textwrap.fill(line, width=100) for line in llm_response['result'].split('n')] response = 'n'.join(temp) print(f"{llm_response['query']}n n{response}'n n Source Documents:") for source in llm_response["source_documents"]: print(source.metadata) llm_qa_chain = RetrievalQA.from_chain_type( llm=llm, #the Llama-2 7b chat model chain_type='stuff', retriever=vector_store.as_retriever(search_kwargs={"k": 2}), # perform similarity search in Pinecone return_source_documents=True, #show the documents that were used to answer the question chain_type_kwargs={"prompt": prompt_template}
)
print_response(llm_qa_chain(question))Kami mendapatkan jawaban berikut:
T: Kapan saya dapat mengunjungi Pusat Pengalaman Pelanggan AWS M&E di New York City?
A: Saya dengan senang hati membantu! Sesuai konteksnya, Pusat Pengalaman Pelanggan AWS M&E di New York City akan tersedia untuk dikunjungi mulai tanggal 13 November. Anda dapat mengirim email ke [email dilindungi] untuk menjadwalkan kunjungan.'
Dokumen sumber:
{'page': 4.0, 'source': 'data/AWS mengumumkan Pusat Pengalaman Pelanggan M&E baru di New York City _ AWS untuk Blog M&E.pdf'}
{'page': 2.0, 'source': 'data/AWS mengumumkan Pusat Pengalaman Pelanggan M&E baru di New York City _ AWS untuk Blog M&E.pdf'}
Mari kita coba pertanyaan lain:
question2=" How many awards have AWS Media Services won in 2023?"
print_response(llm_qa_chain(question2))Kami mendapatkan jawaban berikut:
T: Berapa banyak penghargaan yang dimenangkan AWS Media Services pada tahun 2023?
J: Menurut postingan blog tersebut, AWS Media Services telah memenangkan lima penghargaan industri pada tahun 2023.'
Dokumen sumber:
{'page': 0.0, 'source': 'data/AWS Media Services mendapatkan penghargaan industri _ AWS untuk M&E Blog.pdf'}
{'page': 1.0, 'source': 'data/AWS Media Services mendapatkan penghargaan industri _ AWS untuk M&E Blog.pdf'}
Setelah Anda mencapai tingkat keyakinan yang memadai, Anda dapat menerapkan model tersebut Titik akhir SageMaker untuk inferensi waktu nyata. Titik akhir ini dikelola sepenuhnya dan menawarkan dukungan untuk penskalaan otomatis.
SageMaker menawarkan inferensi model besar menggunakan wadah Inferensi Model Besar (LMI), yang dapat kita manfaatkan untuk menerapkan model kita. Kontainer ini dilengkapi dengan pustaka sumber terbuka yang sudah diinstal sebelumnya seperti DeepSpeed, yang memfasilitasi penerapan teknik peningkatan kinerja seperti paralelisme tensor selama inferensi. Selain itu, mereka menggunakan DJLServing sebagai server model terintegrasi yang telah dibuat sebelumnya. DJL Melayani adalah solusi penyajian model universal berperforma tinggi yang menawarkan dukungan untuk batching dinamis dan penskalaan otomatis pekerja, sehingga meningkatkan throughput.
Dalam pendekatan kami, kami menggunakan LMI SageMaker dengan DJLServing dan DeepSpeed Inference untuk menerapkan model Llama-2-chat 7b dan BGE ke titik akhir SageMaker yang berjalan di ml.g5.2xlarge contoh, memungkinkan inferensi real-time. Jika Anda ingin mengikuti sendiri langkah-langkah ini, lihat langkah-langkah berikut buku catatan untuk petunjuk rinci.
Anda akan membutuhkan dua ml.g5.2xlarge contoh untuk penerapan. Untuk meninjau atau menambah kuota Anda, buka konsol AWS Service Quotas, pilih Layanan AWS di panel navigasi, pilih Amazon SageMaker, dan lihat nilai untuk ml.g5.2xlarge untuk penggunaan titik akhir.

Langkah-langkah berikut menguraikan proses penerapan model kustom untuk alur kerja RAG di titik akhir SageMaker:
- Terapkan Llama-2 7b model obrolan ke titik akhir real-time SageMaker yang berjalan pada
ml.g5.2xlargeMisalnya untuk pembuatan teks cepat. - Terapkan BAAI/bge-kecil-en-v1.5 menyematkan model ke titik akhir real-time SageMaker yang berjalan pada
ml.g5.2xlargecontoh. Alternatifnya, Anda dapat menerapkan model penyematan Anda sendiri. - Ajukan pertanyaan dan gunakan LangChain PengambilanQA untuk menambah permintaan dengan dokumen yang paling mirip dari Pinecone, kali ini menggunakan model yang diterapkan di titik akhir real-time SageMaker:
# convert your local LLM into SageMaker endpoint LLM
llm_sm_ep = SagemakerEndpoint( endpoint_name=tg_sm_model.endpoint_name, # <--- Your text-gen model endpoint name region_name=region, model_kwargs={ "temperature": 0.05, "max_new_tokens": 512 }, content_handler=content_handler,
) llm_qa_smep_chain = RetrievalQA.from_chain_type( llm=llm_sm_ep, # <--- This uses SageMaker Endpoint model for inference chain_type='stuff', retriever=vector_store.as_retriever(search_kwargs={"k": 2}), return_source_documents=True, chain_type_kwargs={"prompt": prompt_template}
)- Gunakan LangChain untuk memverifikasi bahwa titik akhir SageMaker dengan model penyematan berfungsi seperti yang diharapkan sehingga dapat digunakan untuk penyerapan dokumen di masa mendatang:
response_model = smr_client.invoke_endpoint( EndpointName=em_sm_model.endpoint_name, <--- Your embedding model endpoint name Body=json.dumps({ "text": "This is a sample text" }), ContentType="application/json",
) outputs = json.loads(response_model["Body"].read().decode("utf8"))['outputs']Membersihkan
Selesaikan langkah-langkah berikut untuk membersihkan sumber daya Anda:
- Setelah Anda selesai mengerjakan buku catatan SageMaker Studio Anda, pastikan Anda mematikannya
ml.g5.2xlargemisalnya untuk menghindari biaya apa pun dengan memilih ikon berhenti. Anda juga dapat mengaturnya skrip konfigurasi siklus hidup untuk secara otomatis mematikan sumber daya ketika tidak digunakan.

- Jika Anda menyebarkan model ke titik akhir SageMaker, jalankan kode berikut di akhir buku catatan untuk menghapus titik akhir:
#delete your text generation endpoint
sm_client.delete_endpoint( EndpointName=tg_sm_model.endpoint_name
)
# delete your text embedding endpoint
sm_client.delete_endpoint( EndpointName=em_sm_model.endpoint_name
)- Terakhir, jalankan baris berikut untuk menghapus indeks Pinecone:
pinecone.delete_index(index_name)Kesimpulan
Notebook SageMaker memberikan cara mudah untuk memulai perjalanan Anda dengan Retrieval Augmented Generation. Mereka memungkinkan Anda bereksperimen secara interaktif dengan berbagai model, konfigurasi, dan pertanyaan tanpa memerlukan infrastruktur tambahan. Dalam postingan ini, kami menunjukkan cara meningkatkan kinerja obrolan Llama 2 7b dalam kasus penggunaan menjawab pertanyaan menggunakan LangChain, model penyematan BGE, dan Pinecone. Untuk memulai, luncurkan SageMaker Studio dan jalankan buku catatan tersedia berikut ini GitHub repo. Silakan bagikan pemikiran Anda di bagian komentar!
Tentang penulis
 Anastasia Tzeveleka adalah Arsitek Solusi Spesialis Pembelajaran Mesin dan AI di AWS. Dia bekerja dengan pelanggan di EMEA dan membantu mereka merancang solusi pembelajaran mesin dalam skala besar menggunakan layanan AWS. Dia telah mengerjakan proyek di berbagai domain termasuk Natural Language Processing (NLP), MLOps, dan alat Low Code No Code.
Anastasia Tzeveleka adalah Arsitek Solusi Spesialis Pembelajaran Mesin dan AI di AWS. Dia bekerja dengan pelanggan di EMEA dan membantu mereka merancang solusi pembelajaran mesin dalam skala besar menggunakan layanan AWS. Dia telah mengerjakan proyek di berbagai domain termasuk Natural Language Processing (NLP), MLOps, dan alat Low Code No Code.
 Pranav Murthy adalah Arsitek Solusi Spesialis AI/ML di AWS. Dia berfokus membantu pelanggan membangun, melatih, menerapkan, dan memigrasikan beban kerja pembelajaran mesin (ML) ke SageMaker. Dia sebelumnya bekerja di industri semikonduktor yang mengembangkan model computer vision (CV) besar dan pemrosesan bahasa alami (NLP) untuk meningkatkan proses semikonduktor. Di waktu luangnya, ia menikmati bermain catur dan jalan-jalan.
Pranav Murthy adalah Arsitek Solusi Spesialis AI/ML di AWS. Dia berfokus membantu pelanggan membangun, melatih, menerapkan, dan memigrasikan beban kerja pembelajaran mesin (ML) ke SageMaker. Dia sebelumnya bekerja di industri semikonduktor yang mengembangkan model computer vision (CV) besar dan pemrosesan bahasa alami (NLP) untuk meningkatkan proses semikonduktor. Di waktu luangnya, ia menikmati bermain catur dan jalan-jalan.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/use-amazon-sagemaker-studio-to-build-a-rag-question-answering-solution-with-llama-2-langchain-and-pinecone-for-fast-experimentation/

