Sama seperti spesies biologis, bahasa menyebar, berevolusi, bersaing, dan bahkan punah. Untuk memahami mekanisme ini, fisikawan menerapkan metode mereka pada linguistik, menciptakan bidang dinamika bahasa interdisipliner, seperti Marco Patriarca, Els Heinsalu dan David sanchez menjelaskan

Jika dunia penelitian adalah sebuah ekosistem, dengan ilmuwan dari berbagai disiplin ilmu mewakili spesies yang berbeda, maka fisikawan akan diklasifikasikan sebagai penyerbu. Lagi pula, mereka telah menyebarkan metode dan alat mereka ke banyak bidang lain selama bertahun-tahun, tidak hanya menyusup ke ilmu alam lain tetapi juga ilmu sosial.
Lahir dari invasi ini, bidang interdisipliner seperti sosiofisika dan ekonofisika telah dikembangkan, di mana model matematika dari fisika diterapkan pada konteks sosial, termasuk lalu lintas, banyak dan pasar keuangan. Area baru ini – dan model yang terlibat – adalah bagian dari apa yang dikenal sebagai teori sistem kompleks. Ini menyangkut sistem yang terdiri dari banyak elemen yang berinteraksi satu sama lain, menghasilkan perilaku kolektif yang tidak dapat dipahami jika sifat komponen individu dipertimbangkan secara terpisah.
Tetapi sementara sosiofisika dan ekonofisika sekarang diakui sebagai disiplin ilmu, penerapan fisika pada linguistik – yang dikenal sebagai dinamika bahasa – kurang dikenal. Faktanya, kami telah menemukan laporan wasit yang mempertanyakan keseriusan makalah penelitian oleh fisikawan tentang topik ini. Jadi jika Anda adalah salah satu fisikawan aneh yang mempelajari masalah yang secara tradisional merupakan bagian dari linguistik, bagaimana reaksi Anda? Nah, bersumpah adalah salah satu pilihan.
Menyebarkan berita
Kata-kata makian sebenarnya adalah contoh yang bagus tentang bagaimana fisika dapat diterapkan pada linguistik. Pada tahun 2011 sekelompok fisikawan dari Institut Niels Bohr di Denmark dan Universitas Kyushu di Jepang mempelajari bagaimana kata-kata makian Jepang tersebar di seluruh negeri (Phys Pdt. E 83 066116). Ini adalah skenario yang relatif sederhana karena tidak melibatkan kerumitan linguistik – tidak ada tata bahasa, sintaksis, atau fonetik untuk memperumit gambar. Ini hanya pertanyaan tentang bagaimana kata-kata tersebar, yang sangat mirip dengan difusi standar. Selain itu, pulau-pulau utama Jepang yang tipis dan panjang memberikan geografi semu satu dimensi, sangat menyederhanakan proses difusi.
Studi tersebut menganalisis peta linguistik (dibangun dari survei sebelumnya) untuk 21 kata makian, mengungkapkan bahwa mayoritas telah menyebar dari kota Kyoto, yang sering dianggap sebagai ibu kota budaya Jepang. Faktanya, sebagian besar kata yang dipelajari ditemukan di utara dan selatan Kyoto di sepanjang muka gelombang yang terletak pada jarak yang sebanding (gambar 1). Menggunakan model difusi budaya sederhana – di mana inovasi linguistik berkembang secara acak ke segala arah hingga bertemu dan mungkin menggantikan (dengan probabilitas tertentu) inovasi yang lebih tua – tim mampu mereproduksi tidak hanya distribusi spasial dari 21 kata makian tetapi juga variabel jarak antara muka gelombang berurutan.
Misalnya, gambar 1 menunjukkan bahwa kata umpatan “aho” (bodoh) lebih banyak digunakan di Kyoto, sedangkan “baka” (orang bodoh) lebih banyak digunakan di ibu kota, Tokyo. Perbedaan ini merupakan konsekuensi dari penyebaran inovasi linguistik yang muncul di wilayah Kyoto pada waktu yang berbeda, bukan karena kompetisi budaya antara dua kota besar. Dengan kata lain, "baka" dulu ada di Kyoto tetapi di beberapa titik dikuasai oleh "aho" baru, yang belum sampai ke Toyko.
1 Cincin kata-kata umpatan
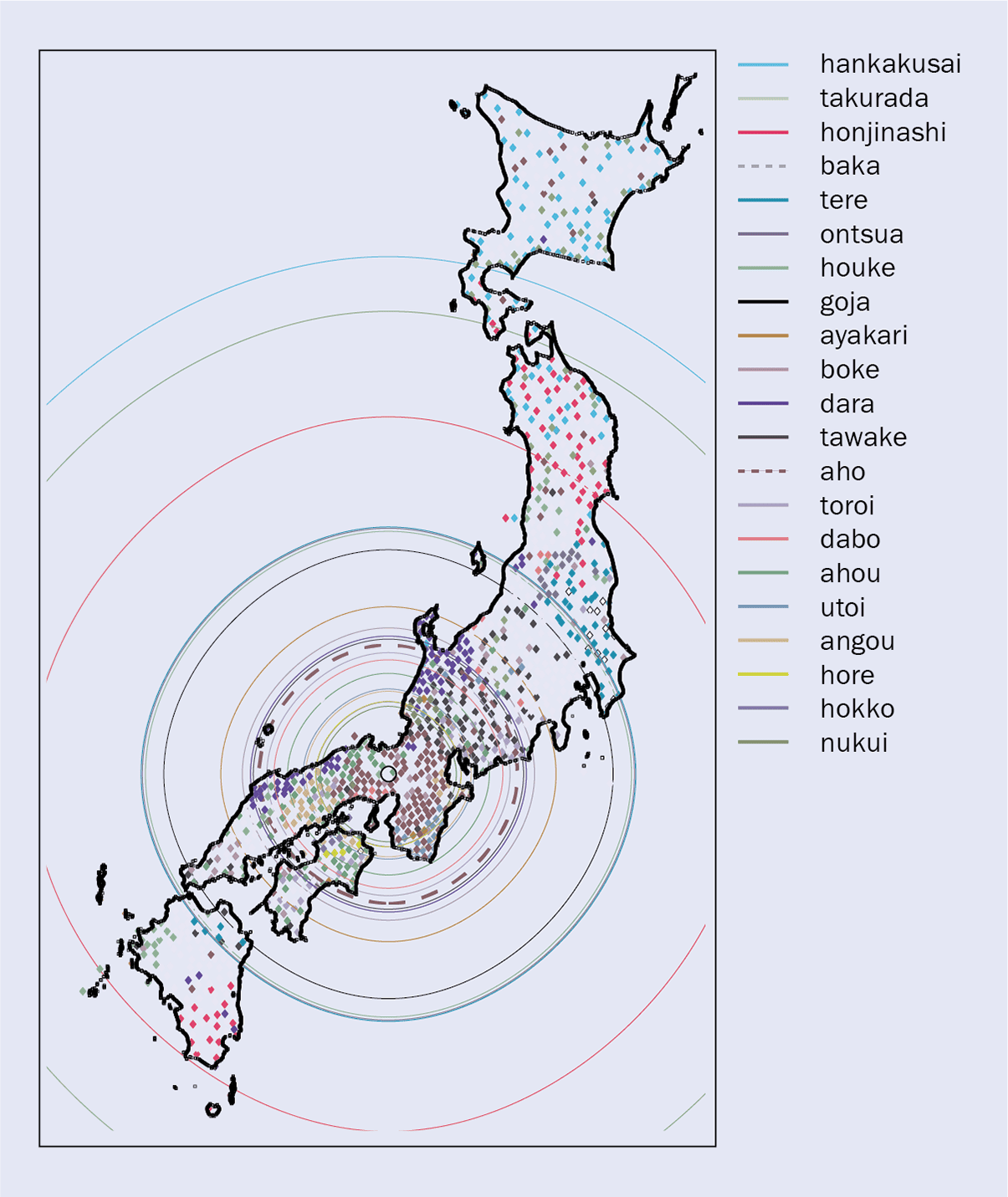
Peta yang menunjukkan penyebaran kata-kata umpatan Jepang (lihat kunci). Setiap kata diwakili oleh gelombang depan (lingkaran) yang berpusat di kota Kyoto (ditandai dengan cincin kecil). Terlihat bagaimana setiap kata menyebar dengan kecepatan yang sama ke segala arah dan semakin baru kata tersebut, semakin kecil penyebaran dari Kyoto. Area penggunaan kata, sementara itu, tumbuh dengan bertambahnya jarak dari Kyoto. Studi ini juga mengungkapkan bagaimana kata-kata baru menggantikan yang lama daripada yang ada di sampingnya. “Baka”, misalnya, pernah ada di Kyoto tetapi telah dikuasai oleh “aho” yang lebih baru, yang belum sampai ke Toyko. Kata “aho” dan “baka” ditunjukkan dengan garis putus-putus.
Skenario yang menyerupai muka gelombang difusi-reaksi tipikal seperti yang terlihat pada Gambar 1 juga ditemukan dalam ekologi yang mewakili, misalnya, spesies yang mengkolonisasi wilayah baru atau menyerang area yang sudah ditempati oleh spesies lain. Faktanya, ada banyak kesamaan matematis antara dinamika bahasa dan ekologi.
Penyebaran dan evolusi
Selain kata dan ekspresi idiomatis, fitur bahasa – seperti ciri fonetik dan struktur sintaksis yang berbeda – dapat menyebar juga. Proses ini dapat berlangsung lintas populasi, ketika inovasi linguistik muncul dalam komunitas bahasa, atau melalui kontak antar komunitas dengan bahasa yang berbeda. Itu belum tentu terhubung dengan migrasi manusia. Sebaliknya, penyebaran bahasa secara keseluruhan biasanya terjadi di samping migrasi komunitas bahasa, yaitu ketika orang yang berbicara bahasa yang tinggal di satu tempat pindah ke lokasi lain di mana bahasa yang berbeda digunakan. Akibatnya, wilayah ini kemudian dapat memiliki komunitas dwibahasa, atau bahkan bahasa aslinya dapat punah.
Selanjutnya, penyebaran bahasa biasanya terjadi secara paralel dengan evolusi bahasa, mungkin menyebabkannya terpecah menjadi dialek. Ini mirip dengan apa yang terjadi dalam biologi ketika suatu kelompok dalam suatu spesies terpisah dari anggota lainnya, mengembangkan karakteristiknya sendiri dan menjadi spesies baru.
Ambil, misalnya, bahasa Mazatec – sekelompok bahasa pribumi yang terkait erat yang dituturkan oleh sekitar 240,000 orang di wilayah Oaxaca utara di Meksiko tenggara. Ini adalah studi kasus yang penting karena bahasa Mazatec dalam skala kecil menunjukkan tingkat keragaman dan kompleksitas yang sebanding dengan kelompok yang lebih besar, seperti bahasa Roman di Eropa (yang mencakup Prancis, Spanyol, dan Italia).

Matematika bertemu mitos
Ketika orang Mazatec bermigrasi dari tanah air mereka, mereka pertama kali menyebar melalui dataran rendah sebelum bergerak melintasi pegunungan di wilayah Sierra Mazateca. Yang aneh adalah bahwa beberapa bahasa yang digunakan di dataran rendah lebih mirip dengan bahasa lain di pegunungan daripada dengan bahasa dataran rendah lain yang secara geografis lebih dekat.
Untuk mengetahui mengapa demikian, sebuah penelitian pada tahun 2019 (melibatkan penulis Marco Patriarca dan Els Heinsalu) menggunakan model evolusi penyebaran sederhana (Aplikasi Kompleksitas dalam Ilmu Bahasa dan Komunikasi 10.1007/978-3-030-04598-2_9). Pekerjaan tersebut menunjukkan bahwa sifat dua dimensi dari geografi dataran rendah membuat bahasa menyebar lebih lambat, dan oleh karena itu keragaman yang lebih besar diamati karena ada lebih banyak waktu untuk mutasi muncul dan menyebar. Sebaliknya, sifat kuasi-satu dimensi dari lembah yang menghubungkan dataran rendah ke pegunungan memaksa penyebaran yang lebih cepat, mencegah mutasi.
Contoh lain yang menarik dari penyebaran dan evolusi bahasa melibatkan Bahasa numerik – sekelompok tujuh bahasa yang digunakan oleh penduduk asli Amerika di AS bagian barat. Dalam hal ini, diyakini bahwa bahasa proto-Numik berkembang menjadi banyak varietas di dalam tanah air Numik (bagian selatan pegunungan Sierra Nevada dan Death Valley). Kemudian, ketika para pembicara mulai menyebar dengan cepat melintasi Great Basin, itu menciptakan distribusi seperti kipas dari berbagai bahasa (gambar 2a).
2 Mengipasi
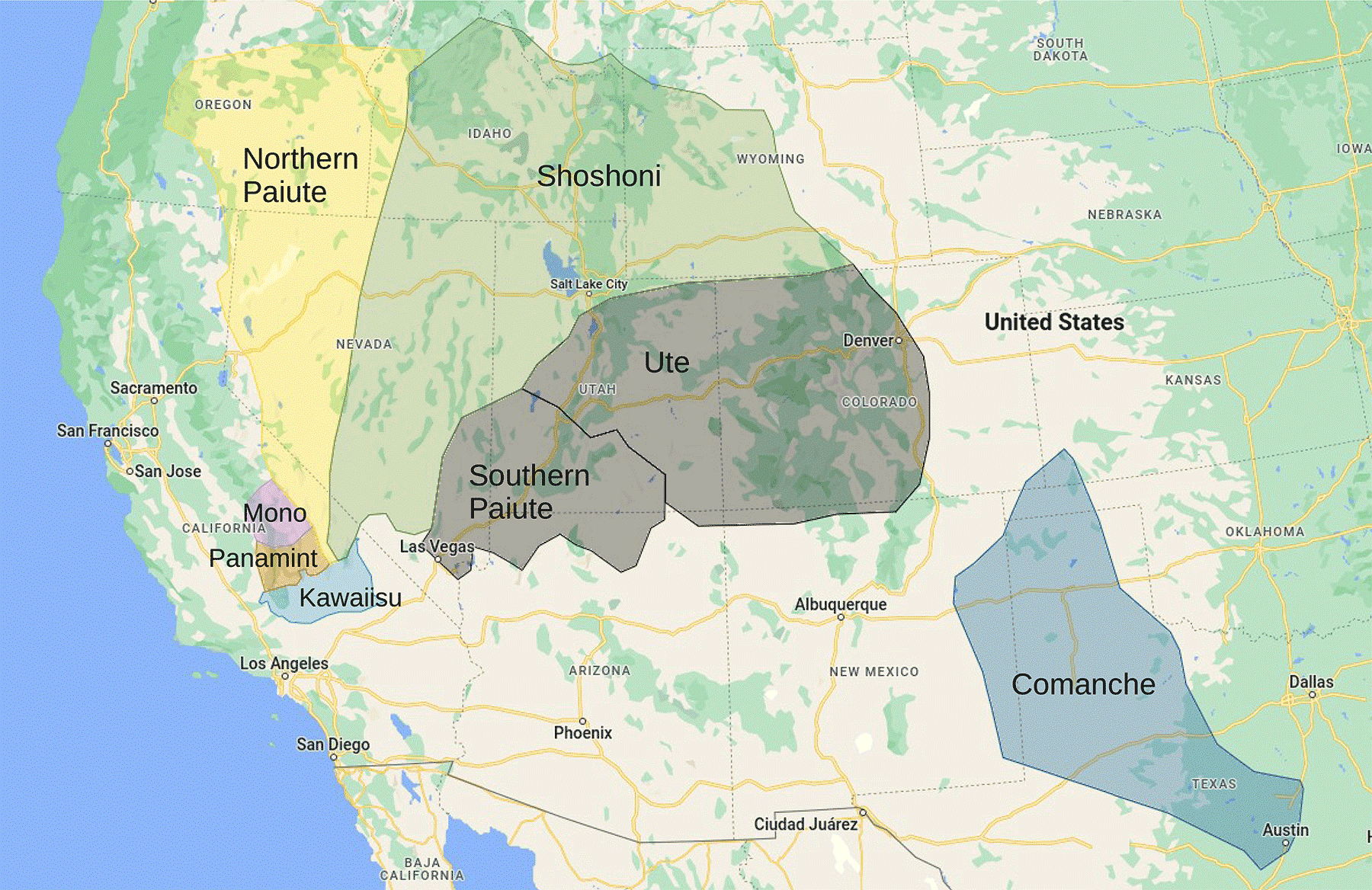

Tujuh bahasa Numic, yang diucapkan oleh penduduk asli Amerika di AS bagian barat, tersebar dari tanah air Numic dan melintasi Great Basin dalam distribusi seperti kipas, seperti yang ditunjukkan di (a), peta yang dibuat dari data lapangan. Sebuah tim di Universidade Federal de Pernambuco di Brazil mereproduksi struktur ini menggunakan model minimal yang secara bersamaan menggambarkan difusi dan evolusi bahasa (b).
Pada tahun 2006 peneliti dari Universidade Federal de Pernambuco di Brazil mampu mereproduksi pola ini menggunakan simulasi komputer (Fisika A 361 361). Menggunakan model minimal populasi yang bereproduksi dan berkembang di suatu wilayah, mereka menunjukkan bahwa bahasanya berubah dan terbagi menjadi bahasa yang berbeda, yang mengarah ke distribusi spasial bahasa yang mirip dengan yang diamati untuk studi kasus Numic (gambar 2b).
Evolusi versus persaingan
Evolusi bahasa merupakan sisi penting dan kompleks dari dinamika bahasa. Deskripsi matematis yang sesuai sebagian besar terinspirasi oleh model evolusi ekologis dan genetik, tetapi juga yang digunakan dalam ilmu sosial, seperti teori permainan. Beberapa model evolusi bahasa bersifat abstrak dan berfokus pada statistik proses evolusi, sedangkan yang lain memperhitungkan aturan yang diketahui dari linguistik, seperti hukum fonetik yang menjelaskan evolusi suara.
Namun, dalam rentang waktu yang singkat, kita dapat mengabaikan evolusi, dan menganggap bahasa sebagai spesies tetap yang bersaing untuk mendapatkan penutur. Dalam kompetisi bahasa, yang merupakan salah satu topik pertama yang dibahas dalam dinamika bahasa, kita tidak hanya memiliki dua spesies yang bersaing – yaitu monolingual yang berbicara bahasa A atau B. Sebaliknya, ada juga bilingual yang berbicara kedua bahasa. Jadi, dapatkah suatu bahasa disamakan dengan parasit yang dapat hidup berdampingan dengan bahasa lain di dalam suatu inang?
Interpretasi lain bisa jadi bahwa penutur adalah simpul dari jaringan sementara, dan bahasa yang digunakan oleh penutur untuk berkomunikasi adalah penghubung antara dua simpul. Sekarang, jika kita memiliki komunitas multibahasa, penutur harus memutuskan bahasa mana yang akan digunakan di mana, dengan siapa dan untuk apa. Untuk memahami bagaimana bahasa minoritas bertahan atau punah tergantung pada pilihan pembicara, seseorang dapat menggunakan model penggunaan bahasa, mungkin juga menggabungkan informasi dari situasi nyata (PLoS ONE 16 e0252453).
Kompleksitas bahasa dan tingkat deskripsi
Dalam kasus bahasa dan analisis linguistik, ada dua jenis kompleksitas. Salah satunya terkait dengan fitur struktural dari bahasa itu sendiri, seperti fonem, morfem dan batang leksikal, sedangkan yang lain terkait dengan interaksi sosial, seperti percakapan secara langsung atau komunikasi melalui jejaring sosial. Aspek-aspek kompleksitas yang berbeda ini dapat dijelaskan dalam hal interaksi jaringan yang kompleks. Menyatukan dua dimensi kompleksitas bahasa – struktural dan sosial – merupakan tantangan utama untuk pemodelan matematika bahasa.
Selain itu, pemodelan dapat dilakukan pada berbagai tingkat detail. Dalam hal kompleksitas struktural, seseorang dapat mempelajari satuan bunyi (fonologi), kata (morfologi), kalimat (sintaksis), dan makna global (semantik). Adapun kompleksitas sosial, seseorang dapat mempertimbangkannya pada tingkat makroskopis dalam hal ukuran populasi komunitas bahasa; pada tingkat mesoscopic di mana kebisingan dan gangguan ditambahkan ke deskripsi matematis; atau pada tingkat mikroskopis individu yang terperinci, di mana pembicara tunggal disimulasikan dengan mempertimbangkan keragaman dan fluktuasi acaknya.
Mengumpulkan informasi tentang bahasa
Secara tradisional, informasi tentang bahasa alami – yang dikembangkan hanya oleh manusia yang berbicara – dikumpulkan melalui kerja lapangan, yang merupakan kasus untuk studi bahasa Mazatec dan Numic. Ini melibatkan wawancara pembicara untuk mendokumentasikan bahasa, dengan fokus pada bahasa lisan bukan teks tertulis. Data kemudian dapat dianalisis secara statistik menggunakan metode dan alat matematika yang berbeda untuk memperkirakan jarak linguistik antar bahasa dan untuk mengungkap kelompok bahasa.
Namun, teks tertulis menawarkan pandangan lain tentang bahasa, dan merupakan bagian lain dari linguistik yang dapat melibatkan fisikawan. Dengan menerapkan fisika statistik, seseorang dapat mengungkap keteraturan dan hukum statistik, seperti Hukum singkatan Zipf, yang menyatakan bahwa kata yang lebih sering digunakan cenderung lebih pendek. Saat ini jenis studi ini dapat dilakukan dengan menggunakan alat numerik dan komputer yang cepat, memungkinkan analisis database digital yang besar dengan mudah. Melakukan ini, hukum singkat telah ditunjukkan menampung sekitar 1000 bahasa dari 80 rumpun bahasa yang berbeda.
Munculnya media sosial juga telah membuka cara baru untuk mengumpulkan data linguistik. Orang-orang di Twitter, misalnya, berkomunikasi secara real time, menyediakan banyak data dalam bentuk jutaan postingan geotag dari seluruh dunia dan dalam banyak bahasa. Data tersebut mungkin agak bias – pengguna sebagian besar masih muda (12-34) dan laki-laki – tetapi mereka memang mengandung banyak informasi menarik dan menggelitik.
Dalam satu studi baru-baru ini, fisikawan dari Institut Fisika Lintas Disiplin dan Sistem Kompleks (IFISC) di Spanyol (termasuk penulis David Sánchez) membangun gambaran linguistik beresolusi tinggi dari berbagai wilayah multibahasa untuk menangkap keragaman masyarakat ini dan memahami apa yang mendorong kepunahan bahasa (fisik. Penelitian Pdt 3 043146). Untuk melakukannya, mereka menggunakan kumpulan data 100 juta Tweet, yang dikumpulkan antara tahun 2015 dan 2019 di 16 negara dan wilayah. Atribusi bahasa dan lokasi dilakukan secara otomatis – dengan Twitter menyediakan lokasi dan peneliti menggunakan alat otomatis untuk menentukan bahasa – memungkinkan tim menghitung proporsi penutur dalam bahasa dan lokasi geografis tertentu.
3 Pencampuran monolingual

Belgia (atas) dan Catalonia (bawah) adalah wilayah multibahasa yang memiliki komunitas satu bahasa. Dengan menganalisis Tweet yang dikumpulkan antara tahun 2015 dan 2019, peneliti dapat menghitung proporsi penutur bahasa tertentu dalam jarak 100 km2 daerah (persegi) untuk kedua negara. Peta-peta ini menunjukkan proporsi (a) Prancis, (b) Belanda, (c) Katalan dan (d) Penutur bahasa Spanyol, di mana ungu tua berarti tidak ada penutur bahasa tersebut, dan kuning menunjukkan wilayah yang hanya menggunakan bahasa tersebut. Hitam berarti tidak ada cukup Tweet dari area tersebut untuk membentuk kumpulan data.
Di Belgia, ada pembagian bahasa yang jelas antara wilayah Flanders di utara yang didominasi oleh bahasa Belanda, dan Wallonia di selatan yang sebagian besar menggunakan bahasa Prancis. Pencampuran bahasa paling banyak terjadi di perbatasan (ditunjukkan dengan garis hitam). Brussel juga ditandai di peta dan menunjukkan konsentrasi penutur bahasa Prancis. Sebaliknya, peta Catalonia menunjukkan percampuran yang jauh lebih luas, dengan sedikit perbedaan antara pedesaan tengah dan kota pesisir besar di timur.
Negara-negara termasuk Belgia atau Swiss ditemukan memiliki komunitas satu bahasa yang dipisahkan oleh batas-batas yang jelas, sedangkan di wilayah seperti Catalonia penutur berbagai bahasa tampak bercampur (gambar 3). Alasan di balik perbedaan distribusi ini terutama bersifat historis, tetapi juga terkait dengan kesamaan bahasa dan prestise.
Tweet juga dapat memberikan informasi berharga tentang variasi leksikal geografis – ketika kata dan frasa yang berbeda digunakan di wilayah yang berbeda untuk merujuk pada hal yang sama. Salah satu pendekatannya adalah membuat daftar variasi kata untuk definisi yang sama dan mempelajari kejadian spasialnya menggunakan algoritma pengelompokan. Dengan mencari persamaan di antara unsur-unsur dengan ciri-ciri leksikal tertentu dan melihat bagaimana mereka membentuk kelompok-kelompok, dimungkinkan untuk menemukan wilayah dialeknya. Sebagai alternatif, seseorang dapat mempertimbangkan semua kata dalam kumpulan data Tweet, tidak hanya yang menunjukkan bentuk alternatif.
Dalam penelitian terbaru, kelompok di IFISC menggunakan metode kedua ini untuk memetakan wilayah budaya di AS (Komunikasi Humaniora dan Ilmu Sosial 10 133). Berdasarkan gagasan bahwa afiliasi budaya dapat disimpulkan dari topik yang didiskusikan orang, para peneliti melihat distribusi frekuensi kata-kata di Tweet yang diberi geotag untuk menemukan hotspot regional bagi mereka. Dari sana, mereka dapat memperoleh kelompok utama variasi topikal (gambar 4).
4 budaya kata
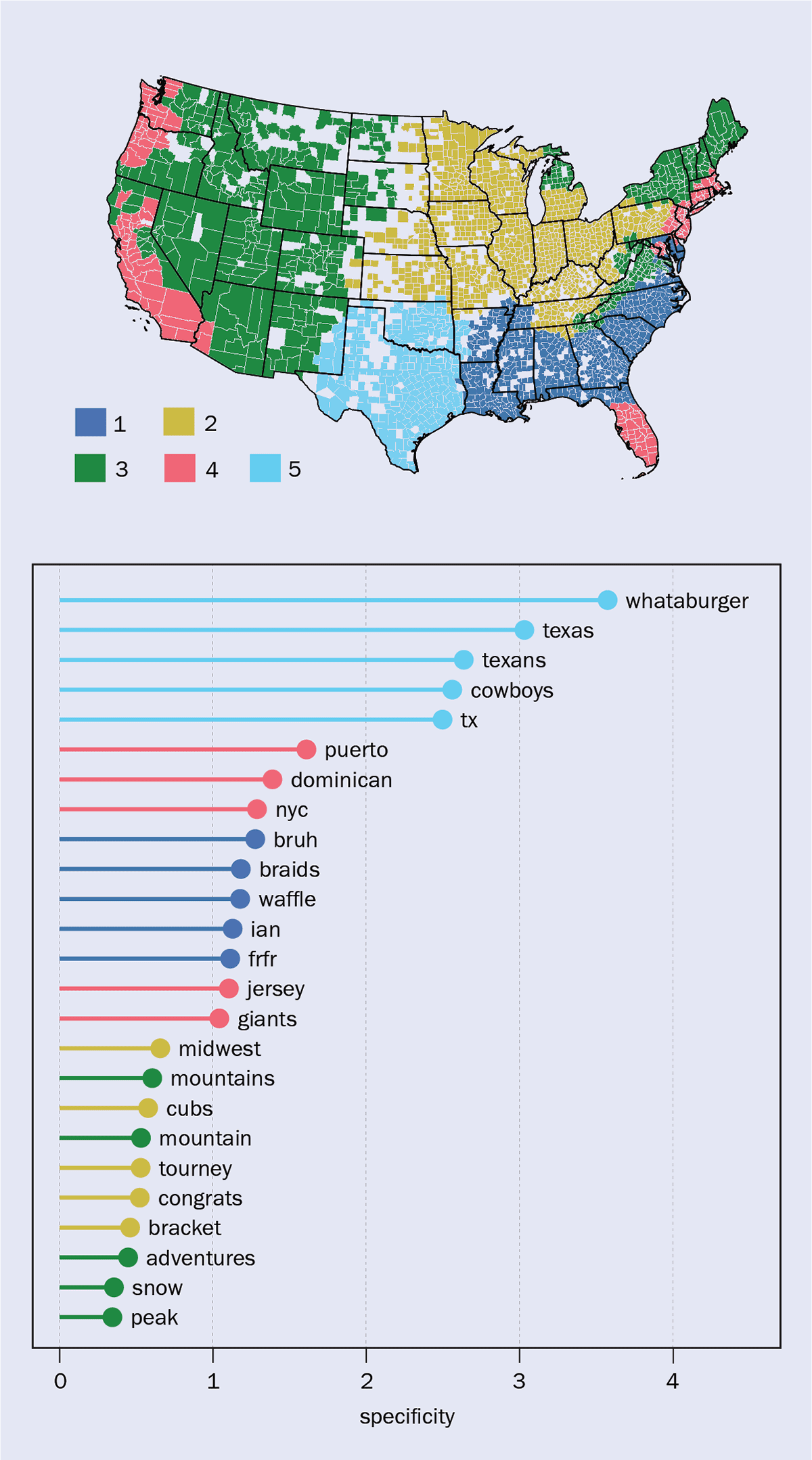
Dengan melihat konten sembilan miliar Tweet dengan geotag yang diposting di AS dari tahun 2015 hingga 2021, peneliti dapat membuat distribusi frekuensi kata untuk menemukan hotspot regional yang sesuai dengan penggunaannya. Dari kata-kata ini, dan topik yang didiskusikan orang, tim dapat memetakan wilayah budaya (a). Setiap segmen adalah kabupaten, dan yang berwarna putih tidak memiliki cukup data. Topik yang paling sering dibicarakan di berbagai daerah adalah: masakan, mode, musik (biru); olahraga, sekolah (kuning); alam, cuaca, aktivitas luar ruangan (hijau); kehidupan perkotaan, imigrasi, kekerasan (merah); referensi diri, budaya Hispanik (cyan). Kata yang paling spesifik untuk setiap wilayah ditampilkan di (b).
Meskipun studi data media sosial semacam itu dapat memberikan gambaran linguistik dalam periode waktu yang singkat, tantangan di masa depan adalah melacak bagaimana bahasa, dan persaingan di antara mereka, berkembang dalam waktu. Namun demikian, perlu diingat bahwa cara bahasa digunakan dalam kehidupan nyata dan online bisa berbeda. Sebagian besar informasi online dalam bahasa Inggris, tetapi offline hanya bahasa ketiga yang paling banyak digunakan, dengan Cina jauh lebih umum (walaupun menyumbang kurang dari 2% dari bahasa online). Selain itu, banyak bahasa yang ada sama sekali tidak terwakili dalam platform komunikasi online.
Keragaman bahasa
Ketika kami memberikan ceramah kepada non-fisikawan tentang dinamika bahasa, kami telah memperhatikan bahwa hubungan antara fisika dan linguistik selalu memicu diskusi yang hidup. Bahasa, tentu saja, menjadi perhatian kita semua. Sayangnya, bagaimanapun, banyak bahasa yang sekarat. Diperkirakan bahwa 50–90% dari sekitar 6000 bahasa yang digunakan di dunia saat ini akan hilang pada akhir abad ini. Dengan kata lain, rata-rata setiap dua minggu sebuah bahasa mati. Menariknya, daerah dengan keanekaragaman hayati tinggi juga memiliki keanekaragaman linguistik yang tinggi, dan hilangnya keduanya terjadi secara paralel.
Kembali ke pengertian dunia penelitian sebagai ekosistem, kita berharap fisika yang menyebar ke linguistik tidak berdampak negatif, seperti yang biasanya terjadi ketika satu spesies menginvasi spesies lain. Sebaliknya, kami melihat simbiosis yang bermanfaat, di mana alat dan model teori sistem kompleks memungkinkan kita memahami mekanisme yang mendorong bagaimana bahasa berkembang dan menyebar. Pengetahuan ini tidak hanya menarik secara ilmiah tetapi juga memiliki dampak sosial yang jelas yang dapat membantu membentuk dan mendukung masyarakat yang secara linguistik lebih inklusif.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Keuangan EVM. Antarmuka Terpadu untuk Keuangan Terdesentralisasi. Akses Di Sini.
- Grup Media Kuantum. IR/PR Diperkuat. Akses Di Sini.
- PlatoAiStream. Kecerdasan Data Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://physicsworld.com/a/the-physics-of-languages/

