ABBYY adalah perusahaan teknologi global yang menyediakan solusi untuk pemrosesan dokumen, pengambilan data, dan teknologi berbasis bahasa. Didirikan pada tahun 1989 oleh sekelompok ahli bahasa dan insinyur dari Moscow State University. Nama perusahaan adalah singkatan dari "Advanced Business Computer Systems."
Produk pertama ABBYY adalah kamus dan perangkat lunak linguistik untuk pasar yang berbeda. Pada tahun 1990-an, ABBYY memperluas lini produknya dengan menyertakan aplikasi optical character recognition (OCR) dan pemindaian dokumen. Produk PDF ABBYY adalah beberapa yang paling populer di pasaran. Lebih dari 100 juta orang menggunakan produk ABBYY PDF setiap hari. Perusahaan berusaha untuk memberikan solusi yang akurat, andal, dan ramah pengguna yang dapat digunakan semua orang, dari individu hingga organisasi besar.
Posting blog ini akan meninjau lini produk mereka dan beberapa pro/kontra bekerja sama. Kami juga akan membandingkan beberapa produk mereka dengan yang ditawarkan oleh perusahaan terkemuka lainnya di industri ini sehingga Anda dapat memutuskan apakah produk tersebut cocok untuk kebutuhan Anda.
Mari kita selami.
Solusi apa yang ditawarkan ABBYY?
ABBYY menawarkan rangkaian lengkap perangkat lunak konversi dan pengeditan OCR dan PDF yang mudah digunakan dan andal. Produk mereka memungkinkan pengguna mengonversi dokumen menjadi PDF yang dapat dicari, mengedit PDF, dan mengekstrak data dari formulir dan tabel. Perusahaan juga menawarkan aplikasi seluler untuk perangkat iOS dan Android yang memungkinkan pengguna memindai dan mengubah dokumen kertas menjadi format digital. Di bagian ini, kita akan menjelajahi berbagai layanan yang mereka sediakan.
ABBYY Vantage
ABBYY Vantage adalah solusi manajemen dokumen yang memungkinkan Anda mengotomatiskan proses bisnis Anda dengan bantuan algoritme cerdas dan kecerdasan buatan. Anda dapat meningkatkan efisiensi alur kerja Anda dengan menggunakan alat ini untuk mengonversi, menganotasi, memproses, dan mengekstrak data dari berbagai dokumen. Alat ini juga memungkinkan Anda menggunakan teknologi OCR untuk berbagai keperluan seperti klasifikasi dokumen, pengindeksan, dan pencarian. ABBYY Vantage juga menawarkan kemampuan analitik data untuk membantu perusahaan melacak tren dan mendapatkan wawasan baru tentang bisnis mereka.
Garis Waktu ABBYY
ABBYY Timeline adalah aplikasi untuk memvisualisasikan peristiwa sejarah dari dokumen teks yang tidak terstruktur seperti artikel berita atau email. Alat ini memungkinkan pengguna untuk melihat bagaimana konsep berkembang dan mengidentifikasi pola tren dari waktu ke waktu. Terutama, aplikasi ini menggunakan teknik pemrosesan bahasa alami untuk mengidentifikasi kejadian dari dokumen teks dan kemudian mengelompokkan kejadian tersebut ke dalam garis waktu berdasarkan jenis kejadian.
ABBYY FlexiCapture
ABBYY FlexiCapture adalah rangkaian perangkat lunak yang membantu organisasi secara otomatis menangkap bidang kunci dari formulir kertas ke dalam basis data atau sistem CRM mereka. Alat ini dapat dengan mudah mengekstrak data dari berbagai bentuk, termasuk faktur, pesanan pembelian, laporan bank, klaim asuransi, dll.
ABBYY FlexiCapture untuk Faktur
ABBYY FlexiCapture untuk Faktur dirancang untuk membantu bisnis merampingkan proses manajemen faktur mereka dengan mengotomatisasi tugas pemrosesan faktur. Solusi ini memungkinkan Anda menghemat waktu dengan secara otomatis mengekstraksi, menstandarkan, dan memperkaya data dari faktur dengan informasi tambahan dari database internal Anda dan membuat laporan yang disesuaikan berdasarkan kebutuhan Anda.
Server ABBYY FineReader
ABBYY FineReader Server adalah solusi untuk konversi, pengindeksan, dan pengambilan dokumen otomatis di sisi server. Itu mengubah dokumen yang dipindai menjadi format yang dapat diedit secara real-time menggunakan teknologi OCR (pengenalan karakter optik), sehingga memungkinkan pengguna untuk mengedit dan menggunakannya kembali sesuai kebutuhan. Solusinya juga menawarkan fitur-fitur canggih seperti pengindeksan halus untuk kemudahan pencarian dan analisis dokumen yang disempurnakan untuk pemahaman yang lebih baik tentang struktur konten.
Solusi perusahaan dari ABBYY tersedia untuk diintegrasikan dengan sistem yang berbeda melalui SDK dan alat pengembang.
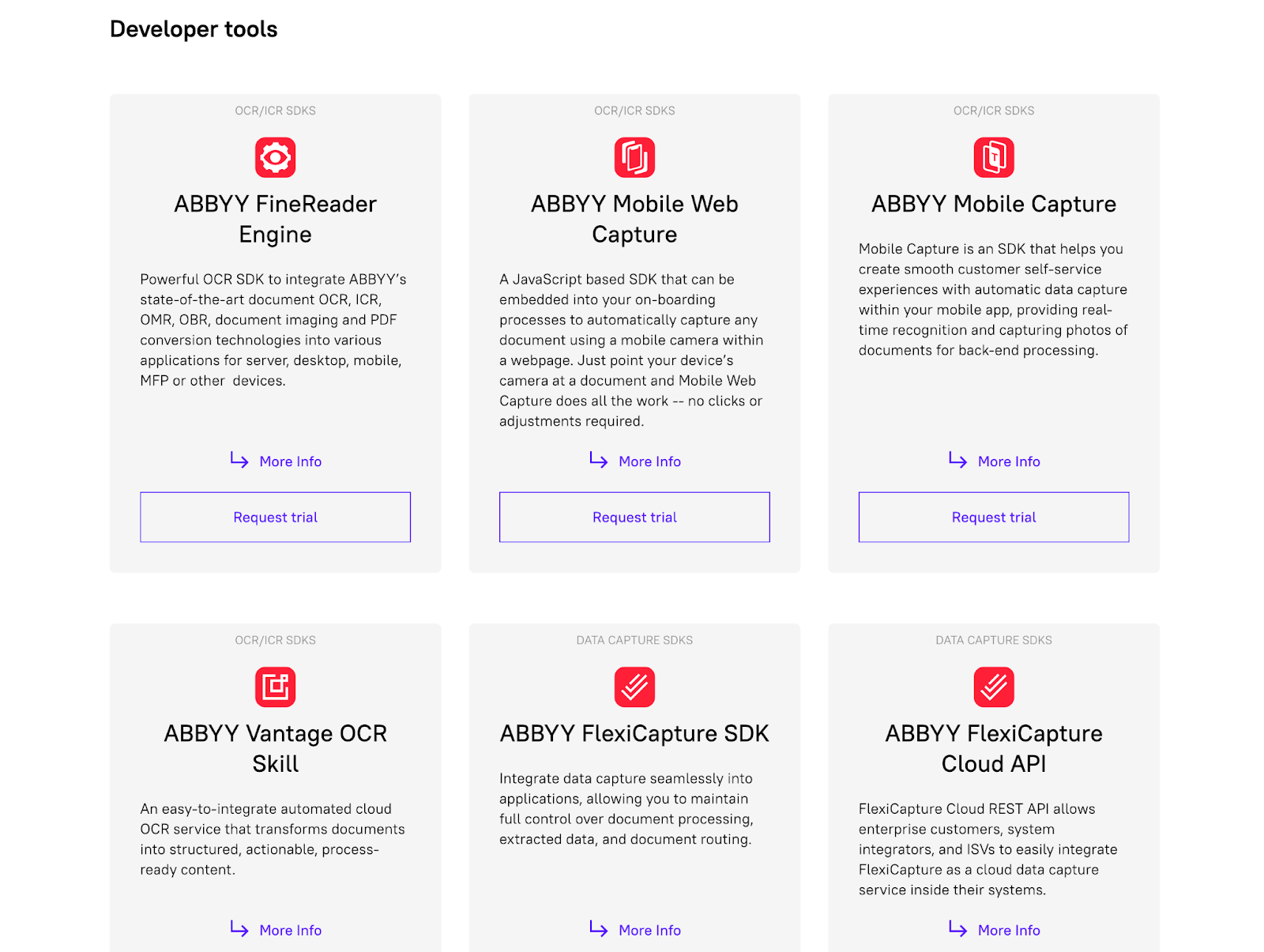
ABBYY FlexiCapture dan ABBYY FineReader adalah dua layanan terpopuler yang ditawarkan oleh ABBYY. Mari kita lihat lebih dekat.
ABBYY FlexiCapture memiliki banyak fungsi yang sama dengan ABBYY FineReader Server (sebelumnya dicap sebagai Recognition Server). Namun, setiap produk dirancang dengan fungsi unik, yang harus dipertimbangkan perusahaan saat mengevaluasi solusi untuk pengambilan dokumen dan persyaratan OCR mereka. Untuk membantu Anda membandingkan produk dengan lebih mudah, kami telah menyusun daftar kasus penggunaan yang memungkinkan Anda menilai antara ABBYY FlexiCapture dan Server FineReader.
Mencari solusi Pengenalan Teks yang cerdas? Pergilah ke Nanonet dan gunakan solusi dengan akurasi di atas 95%.
Apa kasus penggunaan bisnis ABBYY Finereader OCR?
ABBYY FineReader Server adalah program konversi dokumen yang digunakan untuk mengonversi dokumen dan gambar ke dalam format yang dapat dicari. Program ini beroperasi di server, memungkinkan konversi dokumen berskala besar dalam kerangka waktu pemrosesan perusahaan. Ini juga dapat menyediakan cara yang hemat biaya bagi perusahaan untuk menangkap dan mengindeks dokumen secara manual di seluruh perusahaan, baik melalui pemindaian dokumen kertas atau pemrosesan file dan gambar elektronik. Namun, satu kelemahannya adalah tidak menyediakan konversi nilai tulisan tangan atau tanda centang [1].
Pada gambar di bawah ini, Anda dapat melihat hubungan antar komponen Server FineReader.
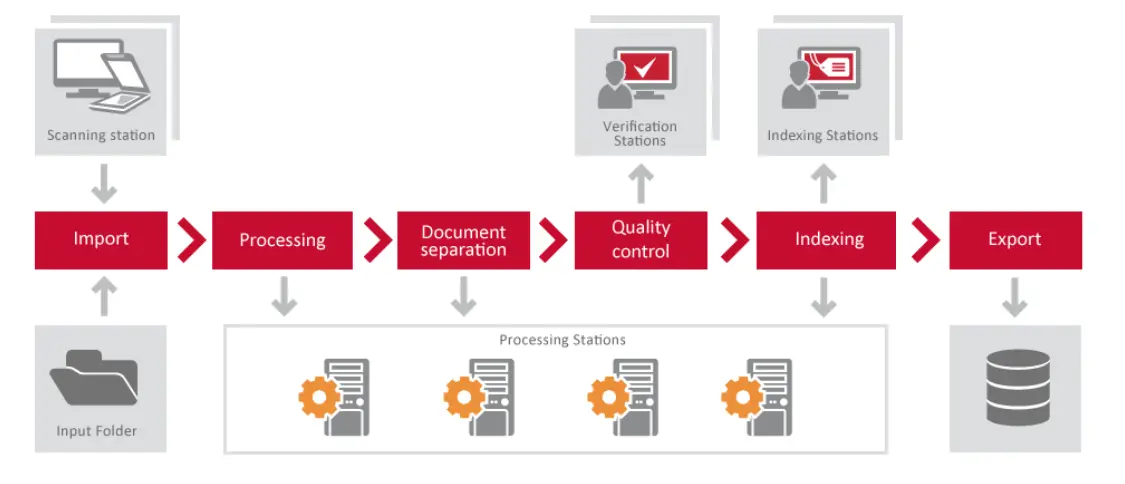
Beberapa kasus penggunaan umum
Pemrosesan Massal
Pantau folder bersama di jaringan dan buat konversi PDF gambar ke teks dari gambar atau dokumen. Ketika file baru ditambahkan ke folder, itu diubah menjadi versi yang dapat dicari teks dan kemudian dipindahkan ke folder ekspor yang sesuai dengan tetap mempertahankan penunjukan sub-folder asli. File ekspor akan menjaga integritas hukum file gambar asli sambil menambahkan lapisan teks yang dapat dicari di belakang gambar dalam file PDF di folder ekspor.
Pemindaian Dokumen
Saat Anda memindai dokumen ke dalam format digital, Anda mendapatkan manfaat tambahan karena dapat menyalin dan menempelkan teks dari dokumen tersebut ke dokumen lain. Namun, Anda harus mengetik ulang teks secara manual jika tidak ada perangkat lunak OCR yang tersedia. Waktu yang diperlukan untuk melakukan ini bisa sangat signifikan. FineReader OCR memungkinkan pengguna dengan cepat mengubah gambar yang dipindai menjadi file teks yang dapat diedit yang dapat dengan mudah diakses dan dimanipulasi di aplikasi lain, seperti Word atau Excel. Hal yang sama berlaku untuk faks, yang sering diterima dalam format TIFF dan tidak mendukung pengeditan atau manipulasi. Menggunakan OCR FineReader, faks ini dapat diubah menjadi file PDF yang dapat diedit atau bahkan dokumen kata dengan beberapa klik.
Digitalisasi Dokumen (Gambar ke Teks)
ABBYY menawarkan solusi ekstraksi data yang dapat digunakan untuk mengonversi gambar teks cetak atau tulisan tangan menjadi format yang dapat diedit. Ini adalah alat penting untuk bisnis dan organisasi yang perlu mendigitalkan dokumen dalam jumlah besar, seperti keuangan, hukum, atau medis. Proses ekstraksi data dapat secara otomatis mengekstrak teks dari gambar, yang kemudian dapat disimpan dalam database atau diubah menjadi PDF yang dapat dicari atau format dokumen lainnya. Solusi ini dapat menghemat waktu dan uang bisnis dan organisasi secara signifikan dengan mengurangi kebutuhan entri data manual. Selain itu, proses ekstraksi data dapat digunakan untuk meningkatkan keakuratan entri data dengan menyediakan metode yang konsisten dan akurat untuk mengubah dokumen kertas menjadi format digital.
Mesin penerjemah
ABBYY FineReader OCR dapat digunakan sebagai alat terjemahan mesin dengan mengubah gambar menjadi teks dalam bahasa lain (terjemahan mesin). Ini dapat berguna jika Anda ingin menyediakan layanan terjemahan tanpa harus mempertahankan penerjemah manusia di lokasi Anda, tetapi tetap ingin memberikan terjemahan berkualitas kepada pelanggan Anda (atau hanya tidak ingin membuang waktu untuk menerjemahkan sesuatu sendiri).
Ekstraksi tabel adalah proses mengekstraksi data dari PDF atau gambar dokumen tabel melalui penggunaan pengenalan karakter optik (OCR). Biasanya digunakan untuk mengubah dokumen kertas yang dipindai, seperti kwitansi, menjadi format digital sehingga data dapat diproses, dianalisis, dan disimpan dengan lebih efisien. Berbagai perangkat lunak OCR tersedia di pasaran, tetapi ABBYY FineReader adalah salah satu pilihan yang paling populer. Teknologi tersebut dapat mengenali garis dan sel, dan juga dapat mendeteksi header dan footer. Dimungkinkan untuk memproses dokumen multi-halaman sekaligus, yang menghemat waktu. Selain itu, ABBYY FineReader mendukung berbagai bahasa, menjadikannya ideal untuk mengekstraksi data dari dokumen dalam berbagai bahasa.
Ingin mengotomatiskan entri data dari dokumen? Solusi OCR berbasis AI Nanonets dapat membantu mengekstrak informasi penting dari dokumen terstruktur / tidak terstruktur dan menjadikan prosesnya otomatis!
Apa kasus penggunaan bisnis Flexicapture OCR?
ABBYY FlexiCapture pada dasarnya adalah aplikasi perangkat lunak ekstraksi data tingkat perusahaan yang menyediakan fungsi optical character recognition (OCR). FlexiCapture menyediakan sarana untuk mengekstrak informasi secara otomatis dari dokumen berdasarkan aturan yang ditetapkan, termasuk kata kunci dan lokasi data pada halaman. FlexiCapture saat ini tersedia dalam paket solusi khusus yang siap dijalankan seperti FlexiCapture untuk Faktur dan FlexiCapture untuk Ruang Surat. Meskipun solusinya sangat bergantung pada penggunaan teknologi OCR yang sama yang ditemukan dalam FineReader Server, dan dapat mengekspor versi teks yang dapat dicari dari dokumen jika diperlukan, fungsi intinya adalah sebagai berikut:
- Klasifikasi dokumen (menentukan jenisnya)
- Mencocokkan kelas dokumen ini dengan aturan ekstraksi data yang sesuai
- Mengekspor data di suatu tempat seperti database, file XML atau Microsoft Excel.
Kemampuan klasifikasi dokumen FlexiCapture dapat digunakan untuk mengekstrak lalu membandingkan nilai bidang dari kumpulan dokumen. Misalnya, aplikasi pinjaman mungkin berisi setengah lusin dokumen, beberapa di antaranya berisi SSN. Sebuah aturan dapat dengan mudah dikonfigurasikan untuk membandingkan SSN dari setiap dokumen yang berisi nilai untuk bidang ini dan kemudian menampilkan kesalahan apa pun kepada operator selama fase verifikasi dokumen.
Pada gambar di bawah ini, Anda dapat melihat hubungan antar komponen Server FlexiCapture.
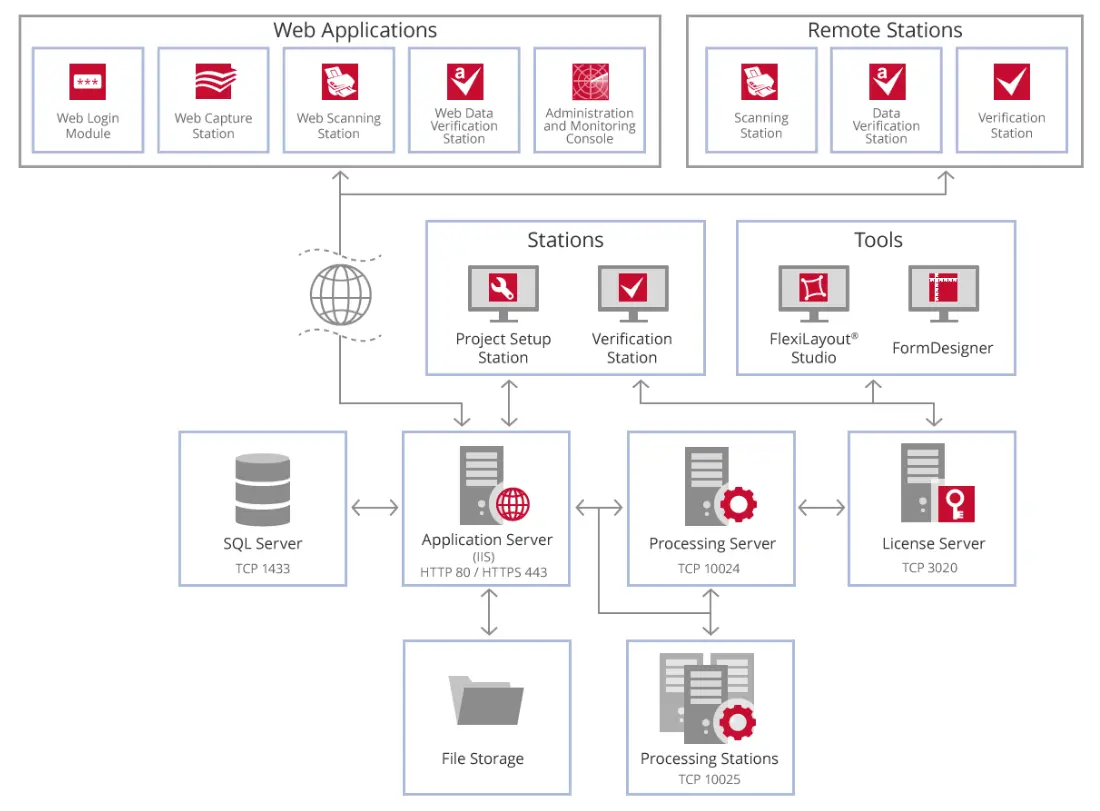
Beberapa kasus penggunaan umum
Pencocokan 2 Arah
ABBYY FineReader memiliki fitur yang dapat membantu departemen hutang Anda berjalan lebih lancar. Ini termasuk:
- Ekstraksi otomatis data faktur dari kertas dan dokumen elektronik
- Pencocokan 2 arah item baris faktur terhadap pembelian yang sesuai dalam sistem ERP
- Mencari melalui faktur yang dapat dicari teks
- Menyetujui pembayaran dengan jumlah dolar atau aturan lainnya
- Pemrosesan pesanan pembelian yang masuk secara otomatis
Klasifikasi Dokumen
- Mengklasifikasikan dokumen yang masuk berdasarkan jenis dan mengekstrak data dari dokumen menggunakan aturan yang telah dikonfigurasi sebelumnya.
- Ekspor dokumen versi PDF teks yang dapat dicari ke sistem manajemen konten dan isi bidang dengan data yang diekstraksi dari dokumen.
- Memberi pengguna sarana untuk mengoreksi data yang diekstrak bersama dengan antrean untuk mengelola pengecualian terhadap aturan yang telah diprogram sebelumnya dalam proses alur kerja dokumen.
Alternatif Teratas untuk Solusi ABBYY

Amazon Texttract adalah layanan yang secara otomatis mengekstrak teks dan data dari dokumen yang dipindai. Ini melampaui pengenalan karakter optik sederhana (OCR) untuk juga mengidentifikasi konten bidang dalam formulir dan informasi yang disimpan dalam tabel.
Amazon AWS Textract adalah alat baru yang semakin populer, berkat biaya rendah dan kemudahan penggunaannya. Ini sangat ideal untuk memindai dokumen dalam jumlah besar, meskipun tingkat akurasinya tidak setinggi ABBYY [2].
Perbedaan utama antara ABBYY dan Amazon Textract adalah bahwa sementara ABBYY menyediakan solusi mandiri untuk mengekstraksi teks dari gambar menggunakan Pengenalan Karakter Optik (OCR), Amazon menyediakan API kepada pelanggannya yang dapat mereka integrasikan ke dalam aplikasi mereka sendiri. Mereka bahkan menyediakan SDK yang berbeda, sehingga memudahkan pengembang untuk mengintegrasikan fitur ini ke dalam produk mereka; namun, ini membutuhkan pengetahuan tambahan tentang bahasa pemrograman seperti Java atau Python.
Selain itu, tidak seperti AWS Textract, ABBYY memberikan kontrol mutlak atas setiap aspek proses OCR Anda (misalnya, memungkinkan Anda menyesuaikan segmentasi kata).
ABBYY dan AWS Textract bekerja sangat baik dalam hal akurasi dan kecepatan dalam banyak kasus.
Kelebihan Teks
- Anda dapat menggunakan AWS Textract dengan aplikasi pemrosesan teks apa pun dengan SDK.
- AWS Texttract mendukung lebih dari 25 bahasa di 200 negara dan wilayah. Anda dapat menggunakannya untuk menerjemahkan file gambar Anda secara real-time dan membuat pipeline pemrosesan multibahasa.
- Alat ini hemat biaya. Harganya hanya $0.0025 per 100,000 karakter yang diproses—kurang dari separuh biaya solusi lain!
- AWS Textract dapat diskalakan, artinya Anda dapat menggunakannya dalam skala besar atau kecil, tergantung kebutuhan Anda.
Kekurangan Teks
- AWS Textract memerlukan banyak waktu dan sumber daya untuk berlatih dengan data Anda sebelum Anda dapat menggunakannya dalam produksi.
- Perangkat lunak pengenalan karakter optis (OCR) modern dapat mengidentifikasi apakah dokumen yang diunggah asli atau palsu dengan memvalidasi tanggal, menemukan wilayah berpiksel, dan metode lainnya. AWS Texttract tidak memiliki kemampuan ini; itu hanya dapat mengekstraksi teks dari dokumen yang diunggah.
- Texttract tidak memungkinkan integrasi dengan penyedia hulu dan hilir dengan mudah. Misalnya, kami mungkin harus membuat pipeline RPA dengan layanan pihak ketiga. Akan sulit untuk menemukan plugin yang sesuai dengan Textract.
ABBYY vs Tesseract

Tesseract OCR dirancang untuk mengenali berbagai bahasa yang ditulis dalam kode C++ murni. Itu juga dapat dikompilasi untuk digunakan pada perangkat seluler seperti platform Android dan iOS. Perangkat lunak ini menggunakan fitur canggih seperti deteksi tata letak teks vertikal, yang memungkinkan pengguna membaca teks dari berbagai sudut tanpa kehilangan akurasi.
ABBYY dan Tesseract memberikan solusi OCR dan membanggakan tingkat akurasi yang tinggi dan mendukung berbagai bahasa. Namun, ada beberapa perbedaan kritis antara keduanya. ABBYY menawarkan antarmuka yang lebih ramah pengguna, menjadikannya ideal bagi mereka yang baru mengenal OCR. Ini juga menyediakan lebih banyak fitur, seperti mengekspor berbagai format dan melakukan pengeditan gambar. Di sisi lain, Tesseract adalah open source dan karenanya gratis untuk digunakan. Ini juga memiliki mesin yang lebih akurat, menjadikannya pilihan yang lebih baik bagi mereka yang membutuhkan tingkat akurasi setinggi mungkin.
Kelebihan Tesseract
- Ia bekerja dengan berbagai bahasa dalam berbagai font, termasuk Romawi, Cyrillic, Han ideographic script, Hebrew, Arabic, dan Thai.
- Kode sumber tersedia di bawah lisensi Apache, sehingga bebas digunakan dan dimodifikasi. Ini juga memiliki jejak memori yang rendah dibandingkan dengan mesin OCR lainnya, sehingga tidak memakan terlalu banyak ruang di komputer atau ponsel cerdas Anda.
- Tesseract serbaguna dan dapat digunakan untuk berbagai tugas, mulai dari Optical Character Recognition (OCR) sederhana hingga tugas yang lebih kompleks seperti Machine Learning (ML).
Kekurangan Tesseract
- Tesseract tidak selalu memberikan hasil yang sempurna, terutama dengan teks yang kompleks atau tulisan tangan.
- Pemrosesan gambar Tesseract belum sempurna; oleh karena itu, Anda perlu menggunakan preprocessor atau gambar yang sudah diproses untuk mendapatkan hasil terbaik [8].
ABBYY vs.Ephesoft

Ephesoft adalah alat pengenalan dokumen lain yang menggunakan teknologi pengenalan karakter optik (OCR) untuk mengubah gambar menjadi file teks. Perangkat lunak ini dirancang khusus untuk bisnis yang membutuhkan solusi untuk mengelola dokumen kertas dalam jumlah besar seperti faktur atau kuitansi. Seperti produk ABBYY, Ephesoft dapat digunakan di berbagai industri, termasuk perawatan kesehatan, pemerintahan, keuangan, dan manufaktur.
Kedua rangkaian perangkat lunak menawarkan serangkaian fitur dan manfaat yang komprehensif, tetapi ada beberapa perbedaan penting di antara keduanya. Misalnya, ABBYY secara umum dianggap lebih akurat daripada Ephesoft [6]t, terutama saat mengenali teks dalam dokumen dengan tata letak yang rumit. Namun, Ephesoft biasanya lebih cepat daripada ABBYY, menjadikannya pilihan yang baik untuk organisasi yang harus memproses dokumen dalam jumlah besar setiap hari. Dari segi harga, ABBYY biasanya lebih mahal daripada Ephesoft, meskipun kedua perusahaan menawarkan diskon untuk lisensi volume. Pada akhirnya, perangkat lunak OCR terbaik untuk bisnis Anda akan bergantung pada kebutuhan dan anggaran spesifik Anda.
Kelebihan Ephesoft
- Sistem memiliki fungsi pelacakan yang membantu melacak perubahan dokumen pengguna. Ini berguna untuk mencegah penipuan dan mengawasi siapa yang membuat perubahan saat banyak pengguna mengerjakan dokumen.
- Ephesoft menggunakan teknik peningkatan kualitas gambar untuk mengekstrak data dari gambar, seperti OCR (Pengenalan Karakter Optik), pengenalan barcode, dan pengenalan karakter. Ini meningkatkan akurasi ekstraksi data secara signifikan dibandingkan dengan metode manual, di mana data mungkin tidak sepenuhnya akurat atau lengkap karena kualitas gambar yang buruk atau faktor lainnya.
- Mendukung dokumen dalam berbagai bahasa, seperti Inggris, Spanyol, Prancis, dll., sehingga cocok di seluruh industri dengan beragam basis pelanggan yang menggunakan bahasa berbeda sebagai mode komunikasi/dokumentasi utama mereka.
Kontra dari Ephesoft
- Perlu pelatihan yang tepat sebelum menggunakannya. Jika Anda tidak memiliki pengalaman sebelumnya bekerja dengan perangkat lunak jenis ini, Anda mungkin kesulitan menggunakannya secara efektif. Namun, begitu Anda terbiasa, akan sangat mudah bagi Anda untuk menggunakan produk ini secara efektif dalam pengaturan bisnis Anda.
- Perangkat lunak Ephesoft harganya lebih mahal daripada produk serupa lainnya di pasar. Investasi awal yang diperlukan untuk membeli Ephesoft mungkin tinggi, tetapi biayanya dapat dikurangi dengan memilih versi cloud [7].
ABBYY vs. Hipersains

Model pembelajaran mesin milik Hyperscience dan teknologi pengenalan karakter optik (OCR) yang kuat menghadirkan kemampuan ekstraksi data yang tak tertandingi untuk formulir tulisan tangan, bersama dengan dokumen terstruktur dan semi terstruktur lainnya. Platform ini menawarkan pelaporan kinerja yang unggul, jaminan kualitas bawaan, dan ekstraksi tingkat tinggi untuk pengambilan dan analisis dokumen yang akurat – dan cepat.
ABBYY dan Hyperscience menawarkan solusi OCR berbasis desktop dan cloud. Jika Anda memerlukan OCR dokumen dalam jumlah besar, ABBYY mungkin merupakan opsi yang lebih baik, karena Anda dapat memprosesnya secara berkelompok menggunakan aplikasi desktop.
Mesin OCR ABBYY didasarkan pada kecerdasan buatan (AI), sedangkan mesin OCR Hyperscience didasarkan pada pembelajaran mesin (ML). Ini berarti bahwa ABBYY dapat belajar dan berkembang dari waktu ke waktu, sedangkan Hyperscience akan selalu memberikan hasil yang konsisten dengan data pelatihannya. Jadi jika Anda memerlukan alat OCR yang dapat beradaptasi dengan perubahan kondisi (mis., font yang berbeda, kualitas gambar yang buruk, dll.), ABBYY mungkin merupakan pilihan yang lebih baik. Namun, jika Anda memerlukan alat OCR yang akan selalu menghasilkan tingkat akurasi tinggi yang sama, apa pun dokumen masukannya, Hyperscience mungkin merupakan pilihan yang lebih baik.
ABBYY vs. Bacairis

Readiris adalah mesin OCR yang kuat dan akurat yang dapat digunakan untuk mengonversi dokumen dan gambar yang dipindai menjadi teks yang dapat diedit dan dicari. Ini menawarkan berbagai fitur dan opsi, menjadikannya solusi OCR yang serbaguna dan kuat untuk berbagai kebutuhan.
Readiris adalah salah satu alternatif populer untuk ABBYY FineReader. Ini juga merupakan program OCR dengan berbagai fitur dan banyak pengguna.
Kelebihan Readiris
- Pemrosesan dokumen 20% lebih cepat
- Edit teks yang disematkan di gambar Anda dengan OCR
- Konversikan dokumen Microsoft Office ke PDF
- Anotasi dan beri komentar
- Lindungi dan tandatangani PDF
- Integrasi dengan printer (Twain scanner) [3]
Kontra Readiris
- Harga bisa mahal saat bekerja dengan data besar.
- Akurasi bisa rendah saat bekerja dengan data tidak terstruktur dibandingkan dengan alat lain [4]
ABBYY vs. Google Cloud Vision

Google Cloud Vision OCR adalah solusi pengenalan teks dan analisis gambar berbasis cloud. Layanan ini menggunakan algoritme pembelajaran mendalam untuk memproses gambar dan video, mengenali objek, pemandangan, dan wajah, serta mendeteksi teks dalam lebih dari 100 bahasa.
Kelebihan Google Cloud Vision
- Hasilnya akurat dan andal—Google menggunakan model pembelajaran mendalam untuk layanan OCR-nya, yang berarti Google mempelajari lebih lanjut tentang bagaimana dokumen spesifik Anda diformat seiring berjalannya waktu, meningkatkan akurasinya dari waktu ke waktu.
- Ini kompatibel dengan sebagian besar jenis file—Google Cloud Vision OCR berfungsi dengan file JPEG, PNG, BMP, TIFF, PDF, dan GIF animasi! Anda bahkan dapat mengonversi halaman HTML menjadi teks biasa menggunakan Google Cloud Vision OCR (walaupun tidak semua pemformatan akan dipertahankan).
- Mudah digunakan—Anda hanya perlu mengunggah gambar yang berisi teks yang ingin dikonversi dan mengeklik "Buat Teks" di konsol Google Cloud Vision. Anda tidak perlu menginstal perangkat lunak apa pun atau mengunduh pustaka perangkat lunak apa pun.
- Menyediakan antarmuka API untuk diintegrasikan dengan perangkat lunak khusus.
Kontra dari Google Cloud Vision
- Ini membutuhkan koneksi internet (yang berarti Anda tidak dapat menggunakannya secara offline).
- Lambat untuk memproses volume data yang besar. Anda dapat menggunakannya untuk jumlah teks kecil hingga sedang, tetapi jika Anda ingin melakukan pemrosesan teks dalam jumlah besar dalam mode batch, solusi ini mungkin tidak cukup cepat untuk kebutuhan Anda.
- Dalam beberapa kasus seperti ekstraksi tabel, keakuratan Google Cloud Vision OCR tidak setinggi alat lainnya [5].
Ingin mengotomatiskan entri data dari dokumen? Solusi OCR berbasis AI Nanonets dapat membantu mengekstrak informasi penting dari dokumen terstruktur / tidak terstruktur dan menjadikan prosesnya otomatis!
ABBYY vs. Nanonet

Nanonets adalah perangkat lunak OCR berbasis AI yang mengotomatiskan data capture untuk pemrosesan dokumen faktur yang cerdas, kwitansi, KTP, dan lainnya. Nanonet menggunakan OCR tingkat lanjut, pemrosesan gambar pembelajaran mesin, dan Deep Learning untuk mengekstrak informasi yang relevan dari data yang tidak terstruktur. Ini cepat, akurat, mudah digunakan, memungkinkan pengguna membuat model OCR khusus dari awal, dan memiliki beberapa integrasi Zapier yang rapi. Digitalkan dokumen, ekstrak bidang data, dan integrasikan dengan aplikasi sehari-hari Anda melalui API dalam antarmuka yang sederhana dan intuitif.
Kelebihan Nanonet
- UI yang modern
- Menangani dokumen dalam jumlah besar
- Dihargai dengan masuk akal
- Mudah digunakan
- Pengambilan data secara kognitif – menghasilkan intervensi minimal
- Tidak membutuhkan tim pengembang in-house
- Algoritma / model dapat dilatih / dilatih ulang
- Dokumentasi & dukungan hebat
- Banyak opsi penyesuaian
- Berbagai pilihan opsi integrasi
- Bekerja dengan non-Inggris atau beberapa bahasa
- Hampir tidak diperlukan pemrosesan pasca
- Integrasi 2 arah yang mulus dengan beberapa perangkat lunak akuntansi
- API OCR yang bagus untuk pengembang
Kekurangan Nanonet
- Tidak dapat menangani lonjakan volume yang sangat tinggi
- UI tangkapan tabel bisa lebih baik.
Bandingkan dan Tinjau Harga ABBYY
|
Alat Bantu |
Dukungan Bahasa |
Demo |
Harga |
|
|
Adobe Acrobat Pro DC |
100+ bahasa |
7-hari |
Mulai $14.99/bulan |
awan |
|
BacaIRIS |
130+ bahasa |
30-hari |
Mulai $129/bulan |
Windows dan Mac |
|
ABBY Pembaca Halus |
198+ bahasa |
7-hari |
$ 117 / tahun |
Windows, iOS, Android, dan Mac. |
|
Visi Google Cloud |
130+ bahasa |
Gratis |
Versi gratis $1.5 per 1000 unit |
Awan, API |
|
Nanonet |
100+ bahasa |
KONSULTASI |
Versi gratis Pro: $499 / bulan |
Awan, Windows, dan Mac |
|
tesseract |
120+ bahasa |
KONSULTASI |
KONSULTASI |
Windows |
Mengapa memilih Nanonet daripada ABBYY?
Nanonets adalah perangkat lunak OCR yang menggunakan kecerdasan buatan untuk mengotomatiskan ekstraksi tabel dari dokumen PDF, gambar, dan file yang dipindai. Tidak seperti solusi lain, tidak memerlukan aturan dan template terpisah untuk setiap jenis dokumen baru. Sebaliknya, itu bergantung pada kecerdasan kognitif untuk menangani dokumen semi-terstruktur dan tak terlihat sambil meningkatkan dari waktu ke waktu. Anda juga dapat menyesuaikan output untuk hanya mengekstrak tabel atau entri data yang Anda minati.
Ini cepat, akurat, mudah digunakan, memungkinkan pengguna untuk membuat model OCR khusus dari awal, dan memiliki beberapa integrasi Zapier yang rapi. Digitasi dokumen, ekstrak tabel atau bidang data, dan integrasikan dengan aplikasi sehari-hari Anda melalui API dalam antarmuka yang sederhana dan intuitif.
Mengapa Nanonet adalah OCR Terbaik?
- Nanonet dapat mengekstrak data pada halaman sementara parser PDF baris perintah hanya mengekstrak objek, header & metadata seperti (judul, halaman, status enkripsi, dll.)
- Teknologi penguraian PDF Nanonets tidak berbasis template. Selain menawarkan model terlatih untuk kasus penggunaan populer, algoritma penguraian Nanonets PDF juga dapat menangani jenis dokumen yang tidak terlihat!
- Selain menangani dokumen PDF asli, kemampuan OCR bawaan Nanonet memungkinkannya menangani dokumen dan gambar yang dipindai juga!
- Fitur otomatisasi yang kuat dengan kemampuan AI dan ML.
- Nanonets menangani data tidak terstruktur, kendala data umum, dokumen PDF multi-halaman, tabel, dan item multi-baris dengan mudah.
- Nanonets adalah alat tanpa kode yang dapat terus belajar dan melatih kembali dirinya sendiri pada data khusus untuk memberikan output yang tidak memerlukan pasca-pemrosesan.
Penguraian faktur otomatis dengan Nanonets – membuat alur kerja pemrosesan faktur tanpa sentuhan sama sekali.
Integrasikan alat Anda yang ada dengan Nanonets dan otomatisasi pengumpulan data, penyimpanan ekspor, dan pembukuan.
Nanonets juga dapat membantu dalam mengotomatisasi alur kerja penguraian faktur dengan:
- Mengimpor dan menggabungkan data faktur dari berbagai sumber – email, dokumen yang dipindai, file/gambar digital, penyimpanan cloud, ERP, API, dll.
- Menangkap dan mengekstrak data faktur secara cerdas dari faktur, kwitansi, tagihan, dan dokumen keuangan lainnya.
- Mengkategorikan dan mengkodekan transaksi berdasarkan aturan bisnis.
- Menyiapkan alur kerja persetujuan otomatis untuk mendapatkan persetujuan internal dan mengelola pengecualian.
- Rekonsiliasi semua transaksi.
- Mengintegrasikan secara mulus dengan ERP atau perangkat lunak akuntansi seperti Quickbooks, Sage, Xero, Netsuite, dan banyak lagi.
Referensi
[1] Bisakah saya mengenali teks tulisan tangan di ABBYY FineReader? - Pusat Bantuan
[2] ABBYY FineReader VS Amazon Textract – bandingkan perbedaan & ulasan?
[3] 7 Software OCR Terbaik 2022 (Gratis dan BERBAYAR)
[4] 10 perangkat lunak OCR teratas pada tahun 2022 | Solusi OCR terbaik
[6] Ephesoft vs. FineReader PDF untuk Windows dan Mac 2022 | G2
[7] 21 Software OCR Terbaik di tahun 2022
[8] Tesseract OCR dengan Python dengan Pytesseract & OpenCV
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://nanonets.com/blog/abbyy-reviews-compare-competitors-alternatives/

