Ez egy vendégbejegyzés, amelyet az Iambic Therapeutics vezetői csapatával közösen írtunk.
Iambic Therapeutics egy gyógyszerkutató startup, amelynek küldetése, hogy innovatív, mesterséges intelligencia által vezérelt technológiákat hozzon létre, hogy jobb gyógyszereket szállítson a rákos betegeknek, gyorsabban.
Fejlett generatív és prediktív mesterséges intelligencia (AI) eszközeink lehetővé teszik, hogy gyorsabban és hatékonyabban kutassunk a lehetséges gyógyszermolekulák hatalmas terében. Technológiáink sokoldalúak és alkalmazhatók terápiás területeken, fehérjeosztályokon és hatásmechanizmusokon keresztül. A differenciált mesterségesintelligencia-eszközök létrehozásán túl integrált platformot hoztunk létre, amely egyesíti az AI-szoftvert, a felhőalapú adatokat, a méretezhető számítási infrastruktúrát, valamint a nagy áteresztőképességű kémiai és biológiai képességeket. A platform lehetővé teszi mesterséges intelligenciánkat – azáltal, hogy adatokat szolgáltat a modelljeink finomításához – és lehetővé teszi, hogy kihasználja az automatizált döntéshozatal és adatfeldolgozás lehetőségeit.
A sikert azon képességünkön mérjük, hogy kiváló klinikai jelölteket tudunk előállítani a sürgős betegek szükségleteinek kielégítésére, példátlan sebességgel: a programindításból mindössze 24 hónap alatt klinikai jelöltekké fejlődtünk, ami lényegesen gyorsabb, mint versenytársaink.
Ebben a bejegyzésben arra összpontosítunk, hogyan használtuk Ács on Amazon Elastic Kubernetes szolgáltatás (Amazon EKS) a mesterséges intelligencia oktatásának és következtetésének skálázása érdekében, amelyek az Iambic felfedezési platform alapvető elemei.
A méretezhető AI-tanítás és következtetések szükségessége
Az Iambic minden héten mesterséges intelligencia-következtetést hajt végre több tucat modellen és több millió molekulán keresztül, két elsődleges felhasználási esetet kiszolgálva:
- Orvoskémikusok és más tudósok az Insight nevű webalkalmazásunkat használják a kémiai tér felfedezésére, a kísérleti adatok elérésére és értelmezésére, valamint az újonnan tervezett molekulák tulajdonságainak előrejelzésére. Mindezt a munka interaktívan, valós időben történik, így alacsony késleltetéssel és közepes átviteli sebességgel kell következtetéseket levonni.
- Ugyanakkor generatív AI modelljeink automatikusan olyan molekulákat terveznek, amelyek számos tulajdonság javítását célozzák, több millió jelöltet keresnek, és óriási átviteli sebességet és közepes késleltetést igényelnek.
Kísérleti platformunk mesterséges intelligencia-technológiák és szakértő gyógyszervadászok irányításával hetente több ezer egyedi molekulát állít elő, és mindegyiket többszörös biológiai vizsgálatnak vetik alá. A generált adatpontokat minden héten automatikusan feldolgozzuk és felhasználjuk mesterséges intelligencia modelljeink finomhangolására. Kezdetben a modell finomhangolása több órát vett igénybe a CPU-időben, ezért elengedhetetlen volt egy keretrendszer a modell finomhangolásához a GPU-kon.
Mélytanulási modelljeink nem triviális követelményeket támasztanak: gigabájt méretűek, számosak és heterogének, és GPU-t igényelnek a gyors következtetéshez és a finomhangoláshoz. A felhő-infrastruktúrát tekintve olyan rendszerre volt szükségünk, amely lehetővé teszi a GPU-k elérését, a gyors fel- és leskálázást a tüskés, heterogén munkaterhelések kezelésére, és nagy Docker-képek futtatását.
Olyan méretezhető rendszert akartunk építeni, amely támogatja a mesterséges intelligencia képzését és következtetéseit. Amazon EKS-t használunk, és a legjobb megoldást kerestük dolgozói csomópontjaink automatikus méretezésére. Számos okból a Karpentert választottuk a Kubernetes csomópontok automatikus skálázásához:
- Könnyű integráció a Kubernetes-szel, a Kubernetes szemantika használatával csomóponti követelmények és pod specifikációk a méretezéshez
- Alacsony késleltetésű csomópontok kiosztása
- Könnyű integráció az infrastruktúránkkal kódszerszámként (Terraform)
A csomópont-szolgáltatók támogatják az egyszerű integrációt az Amazon EKS-sel és más AWS-erőforrásokkal, mint pl Amazon rugalmas számítási felhő (Amazon EC2) példányok és Amazon Elastic Block Store kötetek. A szolgáltatók által használt Kubernetes szemantika támogatja az irányított ütemezést Kubernetes-konstrukciók, például szennyeződések vagy tűréshatárok, valamint affinitási vagy antiaffinitás-specifikációk használatával; megkönnyítik a Karpenter által ütemezhető GPU-példányok számának és típusának szabályozását is.
Megoldás áttekintése
Ebben a részben egy olyan általános architektúrát mutatunk be, amely hasonló ahhoz, amelyet saját munkaterheléseinkhez használunk, és amely lehetővé teszi a modellek rugalmas telepítését az egyéni metrikákon alapuló hatékony automatikus skálázással.
A következő ábra a megoldás architektúráját mutatja be.

Az architektúra telepíti a egyszerű szolgáltatás egy Kubernetes podban egy EKS klaszter. Ez lehet modellkövetkeztetés, adatszimuláció vagy bármely más konténeres szolgáltatás, amely HTTP-kéréssel érhető el. A szolgáltatás egy fordított proxy mögött található Traefik. A fordított proxy összegyűjti a mérőszámokat a szolgáltatás hívásairól, és egy szabványos metrics API-n keresztül megjeleníti azokat a Prométheusz. A Kubernetes eseményvezérelt automatikus skálázó (KEDA) úgy van konfigurálva, hogy a Prometheusban elérhető egyéni mérőszámok alapján automatikusan skálázza a szervizpadok számát. Itt a másodpercenkénti kérések számát használjuk egyéni mérőszámként. Ugyanez az építészeti megközelítés érvényes, ha más mérőszámot választ a munkaterheléséhez.
A Karpenter figyeli a függőben lévő pod-okat, amelyek a fürtben lévő elegendő erőforrás hiánya miatt nem futhatnak. Ha ilyen podokat észlel, a Karpenter további csomópontokat ad a fürthöz, hogy biztosítsa a szükséges erőforrásokat. Ezzel szemben, ha a fürtben több csomópont van, mint amennyire az ütemezett sorba rendezéseknek szüksége van, a Karpenter eltávolít néhány munkavégző csomópontot, és a sorba rendezések átütemeződnek, így kevesebb példányon konszolidálják őket. A másodpercenkénti HTTP kérések száma és a csomópontok száma a segítségével megjeleníthető grafana Irányítópult. Az automatikus méretezés bemutatásához futtatunk egyet vagy többet egyszerű terhelést generáló hüvelyek, amelyek HTTP kéréseket küldenek a szolgáltatásnak a használatával becsavar.
Megoldás bevezetése
A lépésről lépésre végigvezeti, használjuk AWS Cloud9 mint környezet az architektúra telepítéséhez. Ez lehetővé teszi, hogy minden lépést webböngészőből hajtson végre. A megoldást helyi számítógépről vagy EC2-példányról is telepítheti.
Az üzembe helyezés egyszerűsítése és a reprodukálhatóság javítása érdekében követjük a do-keretet és a depend-on-docker sablon. klónozzuk a aws-do-eks projekt és felhasználásával Dokkmunkás, olyan konténerképet készítünk, amely fel van szerelve a szükséges eszközökkel és szkriptekkel. A tárolón belül végigfutjuk a végpontok közötti áttekintés minden lépését, az EKS-klaszter létrehozásától a Karpenterrel a méretezésig. EC2 példányok.
A bejegyzésben szereplő példához a következőket használjuk EKS-fürt jegyzék:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: do-eks-yaml-karpenter
version: '1.28'
region: us-west-2
tags:
karpenter.sh/discovery: do-eks-yaml-karpenter
iam:
withOIDC: true
addons:
- name: aws-ebs-csi-driver
version: v1.26.0-eksbuild.1
wellKnownPolicies:
ebsCSIController: true
managedNodeGroups:
- name: c5-xl-do-eks-karpenter-ng
instanceType: c5.xlarge
instancePrefix: c5-xl
privateNetworking: true
minSize: 0
desiredCapacity: 2
maxSize: 10
volumeSize: 300
iam:
withAddonPolicies:
cloudWatch: true
ebs: trueEz a jegyzék egy nevű fürtöt határoz meg do-eks-yaml-karpenter kiegészítőként telepített EBS CSI-illesztőprogrammal. Kezelt csomópontcsoport kettővel c5.xlarge csomópontokat tartalmaz a fürt számára szükséges rendszerpodák futtatásához. A dolgozó csomópontok privát alhálózatokban vannak tárolva, és a fürt API-végpontja alapértelmezés szerint nyilvános.
Használhat egy meglévő EKS-fürtöt is egy létrehozása helyett. A Karpentert a következőképpen telepítjük utasítás a Karpenter dokumentációjában, vagy a következő futtatásával forgatókönyv, amely automatizálja a telepítési utasításokat.
A következő kód az ebben a példában használt Karpenter konfigurációt mutatja:
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
metadata: null
labels:
cluster-name: do-eks-yaml-karpenter
annotations:
purpose: karpenter-example
spec:
nodeClassRef:
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
name: default
requirements:
- key: karpenter.sh/capacity-type
operator: In
values:
- spot
- on-demand
- key: karpenter.k8s.aws/instance-category
operator: In
values:
- c
- m
- r
- g
- p
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values:
- '2'
disruption:
consolidationPolicy: WhenUnderutilized
#consolidationPolicy: WhenEmpty
#consolidateAfter: 30s
expireAfter: 720h
---
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default
spec:
amiFamily: AL2
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "do-eks-yaml-karpenter"
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "do-eks-yaml-karpenter"
role: "KarpenterNodeRole-do-eks-yaml-karpenter"
tags:
app: autoscaling-test
blockDeviceMappings:
- deviceName: /dev/xvda
ebs:
volumeSize: 80Gi
volumeType: gp3
iops: 10000
deleteOnTermination: true
throughput: 125
detailedMonitoring: trueMeghatározunk egy alapértelmezett Karpenter NodePool-t a következő követelményekkel:
- A Karpenter mindkettőből indíthat példányokat
spotés aon-demandkapacitású medencék - A példányoknak a "
c" (számításra optimalizálva), "m" (Általános rendeltetésű), "r” (memória optimalizálva), vagy „g"És"p” (GPU-gyorsított) számítástechnikai családok - A példánygenerálásnak nagyobbnak kell lennie 2-nél; például,
g3elfogadható, deg2nem
Az alapértelmezett NodePool megszakítási házirendeket is meghatároz. Az alulhasznált csomópontokat eltávolítjuk, így a pod-ok konszolidálhatók, hogy kevesebb vagy kisebb csomóponton fussanak. Alternatív megoldásként beállíthatjuk az üres csomópontok eltávolítását a megadott időtartam után. A expireAfter A beállítás meghatározza bármely csomópont maximális élettartamát, mielőtt leállítják és szükség esetén cserélik. Ez segít csökkenteni a biztonsági réseket, valamint elkerülni a hosszú üzemidővel rendelkező csomópontokra jellemző problémákat, például a fájlok töredezettségét vagy a memóriaszivárgást.
Alapértelmezés szerint a Karpenter kis gyökérkötetű csomópontokat biztosít, ami nem lehet elegendő az AI vagy a gépi tanulási (ML) munkaterhelések futtatásához. A mélytanulási tárolóképek némelyike több tíz GB méretű is lehet, és meg kell győződnünk arról, hogy elegendő tárhely van a csomópontokon ahhoz, hogy ezeket a képeket használó pod-ok futtassák. Ennek érdekében meghatározzuk EC2NodeClass val vel blockDeviceMappings, ahogy az az előző kódban is látható.
A Karpenter felelős az automatikus skálázásért a fürt szintjén. Az automatikus skálázás pod szintjén történő konfigurálásához a KEDA segítségével definiálunk egy egyéni erőforrást ScaledObject, ahogy az a következő kódban látható:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: keda-prometheus-hpa
namespace: hpa-example
spec:
scaleTargetRef:
name: php-apache
minReplicaCount: 1
cooldownPeriod: 30
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus- server.prometheus.svc.cluster.local:80
metricName: http_requests_total
threshold: '1'
query: rate(traefik_service_requests_total{service="hpa-example-php-apache-80@kubernetes",code="200"}[2m])Az előző jegyzék meghatározza a ScaledObject nevezett keda-prometheus-hpa, amely a php-apache telepítés skálázásáért felelős, és mindig fut legalább egy replikát. A mérőszám alapján méretezi ennek a telepítésnek a podjait http_requests_total a Prometheusban elérhető a megadott lekérdezéssel, és a sorba rendezések méretezését célozza meg úgy, hogy minden pod legfeljebb egy kérést szolgáltasson ki másodpercenként. Lekicsinyíti a replikákat, miután a kérés terhelése több mint 30 másodpercig a küszöb alatt van.
A telepítési spec példaszolgáltatásunk a következőket tartalmazza erőforrásigények és korlátok:
resources:
limits:
cpu: 500m
nvidia.com/gpu: 1
requests:
cpu: 200m
nvidia.com/gpu: 1Ezzel a konfigurációval mindegyik szervizegység pontosan egy NVIDIA GPU-t fog használni. Amikor új sorba rendezések jönnek létre, azok Függő állapotban lesznek, amíg elérhetővé nem válik a GPU. A Karpenter szükség szerint GPU-csomópontokat ad a fürthöz a függőben lévő pod-ok elhelyezéséhez.
A terhelést generáló pod előre beállított gyakorisággal küld HTTP kéréseket a szolgáltatásnak. Növeljük a kérések számát a replikák számának növelésével a terhelés-generátor telepítése.
A teljes skálázási ciklus kihasználtság alapú csomópont-konszolidációval egy Grafana műszerfalon látható. A következő irányítópult a fürt csomópontjainak számát mutatja példánytípusonként (fent), a másodpercenkénti kérések számát (bal lent) és a sorba rendezések számát (jobbra lent).
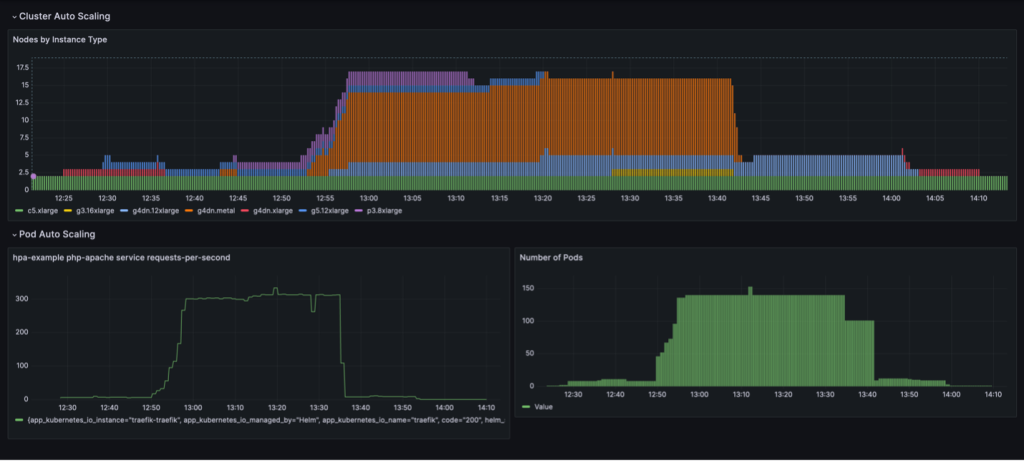
Csak a két c5.xlarge CPU-példánnyal kezdjük, amelyekkel a fürt létrejött. Ezután telepítünk egy szolgáltatáspéldányt, amelyhez egyetlen GPU szükséges. A Karpenter egy g4dn.xlarge példányt ad hozzá ennek az igénynek a kielégítésére. Ezután üzembe helyezzük a terhelésgenerátort, amelynek eredményeként a KEDA további szervizcsomagokat, a Karpenter pedig több GPU-példányt ad hozzá. Az optimalizálás után az állapot beáll egy p3.8xlarge példányra 8 GPU-val és egy g5.12xlarge példányra 4 GPU-val.
Amikor a terhelést generáló üzembe helyezést 40 replikára méretezzük, a KEDA további szolgáltatássorokat hoz létre, hogy fenntartsa a szükséges kérésterhelést podonként. A Karpenter g4dn.metal és g4dn.12xlarge csomópontokat ad a fürthöz, hogy biztosítsa a szükséges GPU-kat a további podokhoz. Méretezett állapotban a fürt 16 GPU-csomópontot tartalmaz, és körülbelül 300 kérést szolgál ki másodpercenként. Ha a terhelésgenerátort 1 replikára kicsinyítjük, fordított folyamat megy végbe. A lehűlési időszak után a KEDA csökkenti a szervizdobozok számát. Aztán ahogy kevesebb pod fut, a Karpenter eltávolítja az alulhasználatos csomópontokat a fürtből, és a szolgáltatási podok konszolidálódnak, hogy kevesebb csomóponton fussanak. Ha a terhelésgenerátort eltávolítják, egyetlen, 4 GPU-val rendelkező g1dn.xlarge-példányon lévő egyetlen szervizpod marad tovább. Ha eltávolítjuk a szervizcsomagot is, a fürt a kezdeti állapotban marad, mindössze két CPU-csomóponttal.
Ezt a viselkedést akkor figyelhetjük meg, amikor a NodePool rendelkezik a beállítással consolidationPolicy: WhenUnderutilized.
Ezzel a beállítással a Karpenter dinamikusan konfigurálja a fürtöt a lehető legkevesebb csomóponttal, miközben elegendő erőforrást biztosít az összes pod futtatásához, és minimálisra csökkenti a költségeket.
A következő műszerfalon látható skálázási viselkedés figyelhető meg, amikor a NodePool a konszolidációs politika be van állítva WhenEmpty, együtt consolidateAfter: 30s.
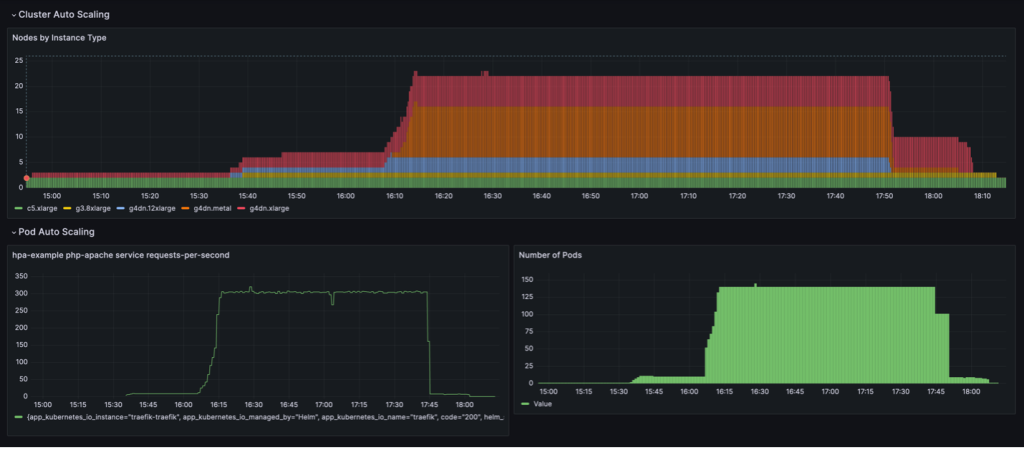
Ebben a forgatókönyvben a csomópontok csak akkor állnak le, ha a lehűlési időszak után nem fut rajtuk pod. A skálázási görbe simának tűnik a felhasználás alapú konszolidációs politikához képest; azonban látható, hogy a skálázott állapotban több csomópontot használnak (22 vs. 16).
Összességében a pod és a fürt automatikus skálázás kombinálása biztosítja, hogy a fürt dinamikusan skálázódik a munkaterheléssel, szükség esetén lefoglalja az erőforrásokat, és eltávolítja azokat, amikor nincs használatban, ezáltal maximalizálja a kihasználtságot és minimalizálja a költségeket.
Eredmények
Az Iambic ezt az architektúrát arra használta, hogy lehetővé tegye a GPU-k hatékony használatát AWS-en, és a munkaterheléseket CPU-ról GPU-ra migrálja. Az EC2 GPU-val hajtott példányok, az Amazon EKS és a Karpenter használatával gyorsabb következtetéseket tudtunk levonni fizika alapú modelljeinkből, és gyors kísérleti iterációs időt tudtunk végezni azon alkalmazott tudósok számára, akik szolgáltatásként támaszkodnak a képzésre.
A következő táblázat összefoglalja ennek az áttelepítésnek az időbeli mutatóit.
| Feladat | CPU | GPU |
| Következtetés diffúziós modellek segítségével fizika alapú ML modellekhez | 3,600 másodperc |
100 másodperc (a GPU-k inherens kötegelése miatt) |
| Az ML modell képzés, mint szolgáltatás | 180 perc | 4 perc |
Az alábbi táblázat összefoglalja néhány idő- és költségmutatónkat.
| Feladat | Teljesítmény/költség | |
| CPU | GPU | |
| ML modell képzés |
240 perc átlagosan 0.70 dollár edzési feladatonként |
20 perc átlagosan 0.38 dollár edzési feladatonként |
Összegzésként
Ebben a bejegyzésben bemutattuk, hogy az Iambic hogyan használta a Karpentert és a KEDA-t Amazon EKS infrastruktúránk méretezéséhez, hogy megfeleljen a mesterséges intelligencia következtetései és a képzési munkaterheléseink késleltetési követelményeinek. A Karpenter és a KEDA hatékony nyílt forráskódú eszközök, amelyek segítik az EKS-fürtök és a rajtuk futó munkaterhelések automatikus méretezését. Ez segít optimalizálni a számítási költségeket, miközben megfelel a teljesítménykövetelményeknek. Megtekintheti a kódot, és ugyanazt az architektúrát telepítheti saját környezetében, ha követi a teljes útmutatót GitHub repo.
A szerzőkről
 Matthew Welborn az Iambic Therapeutics gépi tanulási részlegének igazgatója. Ő és csapata kihasználja az MI-t, hogy felgyorsítsa az új terápiák azonosítását és fejlesztését, így gyorsabban juttassák el az életmentő gyógyszereket a betegekhez.
Matthew Welborn az Iambic Therapeutics gépi tanulási részlegének igazgatója. Ő és csapata kihasználja az MI-t, hogy felgyorsítsa az új terápiák azonosítását és fejlesztését, így gyorsabban juttassák el az életmentő gyógyszereket a betegekhez.
 Paul Whittemore az Iambic Therapeutics vezető mérnöke. Támogatja az Iambic AI által vezérelt gyógyszerkutatási platform infrastruktúrájának szállítását.
Paul Whittemore az Iambic Therapeutics vezető mérnöke. Támogatja az Iambic AI által vezérelt gyógyszerkutatási platform infrastruktúrájának szállítását.
 Alex Iankoulski az ML/AI Frameworks egyik fő megoldástervezője, aki arra összpontosít, hogy segítse az ügyfeleket mesterséges intelligencia-terheléseik összehangolásában konténerek és gyorsított számítási infrastruktúra segítségével az AWS-en.
Alex Iankoulski az ML/AI Frameworks egyik fő megoldástervezője, aki arra összpontosít, hogy segítse az ügyfeleket mesterséges intelligencia-terheléseik összehangolásában konténerek és gyorsított számítási infrastruktúra segítségével az AWS-en.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/machine-learning/scale-ai-training-and-inference-for-drug-discovery-through-amazon-eks-and-karpenter/

