A különböző iparágakban működő szervezetek kategorizálni akarnak, és betekintést szeretnének nyerni nagy mennyiségű, különböző formátumú dokumentumból. Ezen dokumentumok manuális feldolgozása az információk osztályozása és kinyerése érdekében továbbra is drága, hibás és nehezen méretezhető. Előrelépések generatív mesterséges intelligencia (AI) intelligens dokumentumfeldolgozó (IDP) megoldások születtek, amelyek automatizálhatják a dokumentumok osztályozását, és költséghatékony osztályozási réteget hozhatnak létre, amely képes kezelni a változatos, strukturálatlan vállalati dokumentumokat.
A dokumentumok kategorizálása az első fontos lépés az IDP-rendszerekben. Segít meghatározni a következő műveletsort a dokumentum típusától függően. Például a kárelbírálási folyamat során a szállítói csoport kapja meg a számlát, míg a kárrendezési osztály kezeli a szerződést vagy a kötvénydokumentumokat. A hagyományos szabálymotorok vagy az ML-alapú osztályozás besorolhatja a dokumentumokat, de gyakran eléri a határt a dokumentumformátumok típusai és az új dokumentumosztályok dinamikus hozzáadásának támogatása tekintetében. További információkért lásd Az Amazon Comprehend dokumentumosztályozója elrendezési támogatást ad a nagyobb pontosság érdekében.
Ebben a bejegyzésben a dokumentumok osztályozását tárgyaljuk a Amazon Titan Multimodal Embeddings modell bármilyen dokumentumtípus osztályozására képzés nélkül.
Amazon Titan multimodális beágyazások
Az Amazon nemrégiben mutatkozott be Titan multimodális beágyazások in Amazon alapkőzet. Ez a modell képes beágyazásokat létrehozni képek és szövegek számára, lehetővé téve az új dokumentumosztályozási munkafolyamatokban használható dokumentumbeágyazások létrehozását.
A képként beolvasott dokumentumok optimalizált vektoros ábrázolását állítja elő. Mind a vizuális, mind a szöveges összetevőket egységes numerikus vektorokba kódolva, amelyek szemantikai jelentést foglalnak magukba, lehetővé teszi a gyors indexelést, a hatékony kontextus szerinti keresést és a dokumentumok pontos osztályozását.
Ahogy új dokumentumsablonok és -típusok jelennek meg az üzleti munkafolyamatokban, egyszerűen előhívhatja a Amazon Bedrock API dinamikusan vektorizálni és hozzáfűzni IDP-rendszereikhez a dokumentumosztályozási képességek gyors javítása érdekében.
Megoldás áttekintése
Vizsgáljuk meg a következő dokumentumosztályozási megoldást az Amazon Titan Multimodal Embeddings modellel. Az optimális teljesítmény érdekében testre kell szabnia a megoldást az adott használati esethez és a meglévő IDP-folyamatbeállításokhoz.
Ez a megoldás vektorbeágyazású szemantikus kereséssel osztályozza a dokumentumokat úgy, hogy egy bemeneti dokumentumot egy már indexelt dokumentumgalériával egyeztet. A következő kulcsfontosságú összetevőket használjuk:
- embeddings - embeddings valós objektumok numerikus ábrázolásai, amelyeket a gépi tanulás (ML) és az AI-rendszerek az emberekhez hasonlóan összetett tudástartományok megértésére használnak.
- Vektoros adatbázisok - Vektoros adatbázisok beágyazások tárolására szolgálnak. A vektoradatbázisok hatékonyan indexelik és rendszerezik a beágyazásokat, lehetővé téve a hasonló vektorok gyors visszakeresését olyan távolságmérők alapján, mint az euklideszi távolság vagy a koszinusz hasonlóság.
- Szemantikus keresés – A szemantikus keresés a bemeneti lekérdezés kontextusának és jelentésének, valamint a keresett tartalom szempontjából való relevanciájának figyelembevételével működik. A vektoros beágyazás hatékony módja a szöveg és a képek kontextuális jelentésének rögzítésének és megőrzésének. Megoldásunkban, amikor egy alkalmazás szemantikai keresést kíván végrehajtani, a keresési dokumentumot először beágyazássá alakítjuk. Ezután lekérdezi a releváns tartalommal rendelkező vektoradatbázist, hogy megtalálja a leginkább hasonló beágyazásokat.
A címkézési folyamat során az üzleti dokumentumok, például a számlák, bankszámlakivonatok vagy vények mintakészletét az Amazon Titan Multimodal Embeddings modell segítségével beágyazásokká alakítják, és egy vektoros adatbázisban tárolják előre meghatározott címkékkel. Az Amazon Titan Multimodális beágyazási modellt az euklideszi L2 algoritmus segítségével képezték ki, ezért a legjobb eredmény érdekében a használt vektoradatbázisnak támogatnia kell ezt az algoritmust.
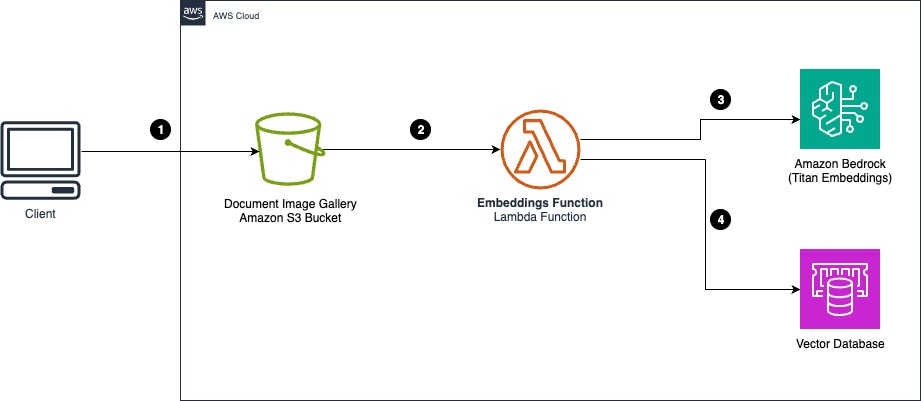
A következő architektúra diagram azt szemlélteti, hogyan használhatja az Amazon Titan Multimodal Embeddings modellt dokumentumokkal egy Amazon egyszerű tárolási szolgáltatás (Amazon S3) vödör képgaléria készítéséhez.
A munkafolyamat a következő lépésekből áll:
- Egy felhasználó vagy alkalmazás egy mintadokumentumképet tölt fel besorolási metaadatokkal egy dokumentumképgalériába. S3 előtag vagy S3 objektum metaadatok használhatók a galériaképek osztályozásához.
- Az Amazon S3 objektum értesítési eseménye meghívja a beágyazást AWS Lambda funkciót.
- A Lambda funkció beolvassa a dokumentum képét, és a képet beágyazásokká alakítja az Amazon Bedrock meghívásával és az Amazon Titan Multimodal Embeddings modell használatával.
- A képbeágyazásokat a dokumentumok osztályozásával együtt a vektoradatbázis tárolja.
Ha egy új dokumentumot osztályozni kell, ugyanazt a beágyazási modellt használja a rendszer a lekérdezési dokumentum beágyazássá alakításához. Ezután szemantikai hasonlóságkeresést hajtanak végre a vektoradatbázison a lekérdezés beágyazásával. A legfelső beágyazási egyezés alapján lekért címke lesz a lekérdezési dokumentum osztályozási címkéje.
A következő architektúra diagram bemutatja, hogyan használható az Amazon Titan Multimodal Embeddings modell egy S3-as tárolóban lévő dokumentumokkal a képosztályozáshoz.
A munkafolyamat a következő lépésekből áll:
- A besorolást igénylő dokumentumok egy bemeneti S3 tárolóba töltődnek fel.
- Az osztályozó lambda funkció megkapja az Amazon S3 objektumértesítést.
- A Lambda függvény az Amazon Bedrock API meghívásával a képet beágyazássá fordítja.
- A vektoradatbázisban szemantikus kereséssel keres egy megfelelő dokumentumot. Az egyező dokumentum osztályozása a bemeneti dokumentum osztályozására szolgál.
- A bemeneti dokumentum átkerül a cél S3 könyvtárba vagy előtagba a vektoradatbázis-keresésből leolvasott osztályozás használatával.

Annak érdekében, hogy a megoldást saját dokumentumaival tesztelhesse, létrehoztunk egy példa Python Jupyter notebookot, amely elérhető GitHub.
Előfeltételek
A notebook futtatásához szüksége van egy AWS-fiók megfelelővel AWS Identity and Access Management (IAM) engedélyek az Amazon Bedrock meghívására. Ezenkívül a Modell hozzáférés oldalon az Amazon Bedrock konzolon, győződjön meg arról, hogy a hozzáférés biztosított az Amazon Titan Multimodal Embeddings modellhez.
Implementáció
A következő lépésekben cserélje ki az egyes felhasználói beviteli helyőrzőket saját adataival:
- Hozza létre a vektoros adatbázist. Ebben a megoldásban egy memórián belüli FAISS adatbázist használunk, de használhat egy alternatív vektoradatbázist is. Az Amazon Titan alapértelmezett mérete 1024.
- A vektoradatbázis létrehozása után sorolja fel a mintadokumentumokat, mindegyikből hozzon létre beágyazást, és tárolja azokat a vektoradatbázisban
- Tesztelje a dokumentumokat. Cserélje ki a következő kódban található mappákat saját mappáira, amelyek ismert dokumentumtípusokat tartalmaznak:
- A Boto3 könyvtár használatával hívja fel az Amazon Bedrock-ot. A változó
inputImageB64egy base64 kódolású bájttömb, amely a dokumentumot reprezentálja. Az Amazon Bedrock válasza tartalmazza a beágyazásokat.
- Adja hozzá a beágyazásokat a vektoradatbázishoz egy ismert dokumentumtípust képviselő osztályazonosítóval:
- A képekkel feltöltött (galériánkat reprezentáló) vektoros adatbázissal új dokumentumokkal való hasonlóságokat fedezhet fel. Például a következő a kereséshez használt szintaxis. A k=1 azt jelzi, hogy a FAISS visszaadja a legjobb 1 meccset.
Ezen túlmenően, az euklideszi L2 távolság a kézben lévő kép és a talált kép között is visszakerül. Ha a kép pontosan egyezik, akkor ez az érték 0. Minél nagyobb ez az érték, annál távolabb vannak egymástól a képek hasonlósága.
További megfontolások
Ebben a részben a megoldás hatékony használatának további szempontjait tárgyaljuk. Ez magában foglalja az adatvédelmet, a biztonságot, a meglévő rendszerekkel való integrációt és a költségbecsléseket.
Adatvédelem és biztonság
Az AWS megosztott felelősségi modell vonatkozik adat védelem az Amazon Bedrockban. Ebben a modellben leírtak szerint az AWS felelős a teljes AWS-felhőt futtató globális infrastruktúra védelméért. Az ügyfelek felelősek az ezen az infrastruktúrán tárolt tartalmuk ellenőrzéséért. Ügyfélként Ön felelős az Ön által használt AWS-szolgáltatások biztonsági konfigurációs és kezelési feladataiért.
Adatvédelem az Amazon Bedrockban
Az Amazon Bedrock kerüli az ügyfelek felszólítását és folytatását az AWS-modellek betanításához vagy harmadik felekkel való megosztásához. Az Amazon Bedrock nem tárolja és nem naplózza az ügyfelek adatait szolgáltatási naplóiban. A modellszolgáltatók nem férhetnek hozzá az Amazon Bedrock naplóihoz, illetve nem férhetnek hozzá az ügyfelek értesítéseihez és folytatásaihoz. Ennek eredményeként az Amazon Titan Multimodal Embeddings modellen keresztül beágyazások generálásához használt képeket nem tárolják és nem használják fel az AWS-modellek betanításában vagy a külső terjesztésben. Ezenkívül az egyéb használati adatok, például az időbélyegek és a naplózott fiókazonosítók ki vannak zárva a modellképzésből.
Integráció meglévő rendszerekkel
Az Amazon Titan Multimodal Embeddings modellt az Euklideszi L2 algoritmussal képezték ki, így a használt vektoradatbázisnak kompatibilisnek kell lennie ezzel az algoritmussal.
Költségbecslés
A bejegyzés írásakor a Amazon Bedrock árképzés az Amazon Titan Multimodal Embeddings modell esetében a következő becsült költségek a megoldás igény szerinti árazása alapján:
- Egyszeri indexelési költség – 0.06 USD egyetlen indexelési futtatásért, 1,000 képgalériát feltételezve
- Osztályozási költség – 6 dollár 100,000 XNUMX bemeneti képért havonta
Tisztítsuk meg
A jövőbeni költségek elkerülése érdekében törölje a létrehozott erőforrásokat, például a Amazon SageMaker notebook példány, amikor nincs használatban.
Következtetés
Ebben a bejegyzésben azt vizsgáltuk, hogyan használhatja az Amazon Titan Multimodal Embeddings modellt egy olcsó megoldás létrehozására a dokumentumok osztályozására az IDP munkafolyamatban. Bemutattuk, hogyan hozhatunk létre képgalériát az ismert dokumentumokból, és hogyan végezzünk hasonlósági kereséseket az új dokumentumokkal azok osztályozása érdekében. Megvitattuk a multimodális képbeágyazások dokumentumosztályozási használatának előnyeit is, beleértve a különféle dokumentumtípusok kezelésére való képességüket, a méretezhetőséget és az alacsony késleltetést.
Ahogy új dokumentumsablonok és -típusok jelennek meg az üzleti munkafolyamatokban, a fejlesztők meghívhatják az Amazon Bedrock API-t, hogy dinamikusan vektorizálják azokat, és hozzáfűzzék IDP-rendszereiket, hogy gyorsan javítsák a dokumentumosztályozási képességeket. Ez egy olcsó, végtelenül skálázható osztályozási réteget hoz létre, amely a legkülönfélébb, strukturálatlan vállalati dokumentumokat is képes kezelni.
Összességében ez a bejegyzés útitervet ad egy olcsó megoldás kidolgozásához az IDP-munkafolyamatban az Amazon Titan Multimodal Embeddings használatával.
Következő lépésként ellenőrizze Mi az Amazon Bedrock a szolgáltatás használatának megkezdéséhez. És kövesse Amazon Bedrock az AWS Machine Learning Blogon hogy naprakész legyen az Amazon Bedrock új képességeivel és használati eseteivel.
A szerzőkről
 Sumit Bhati az AWS vezető ügyfélmegoldás-menedzsere, a felhőalapú utazás felgyorsítására specializálódott a vállalati ügyfelek számára. A Sumit célja, hogy segítse az ügyfeleket a felhő bevezetésének minden szakaszában, a migráció felgyorsításától a munkaterhelés korszerűsítéséig és az innovatív gyakorlatok integrációjának megkönnyítéséig.
Sumit Bhati az AWS vezető ügyfélmegoldás-menedzsere, a felhőalapú utazás felgyorsítására specializálódott a vállalati ügyfelek számára. A Sumit célja, hogy segítse az ügyfeleket a felhő bevezetésének minden szakaszában, a migráció felgyorsításától a munkaterhelés korszerűsítéséig és az innovatív gyakorlatok integrációjának megkönnyítéséig.
 David Girling Senior AI/ML Solutions Architect, aki több mint 20 éves tapasztalattal rendelkezik a vállalati rendszerek tervezésében, vezetésében és fejlesztésében. David egy olyan szakembercsapat tagja, amely arra összpontosít, hogy segítse az ügyfeleket a tanulásban, innovációban és ezeknek a nagy teljesítményű szolgáltatásoknak a felhasználásában az adataik felhasználásával.
David Girling Senior AI/ML Solutions Architect, aki több mint 20 éves tapasztalattal rendelkezik a vállalati rendszerek tervezésében, vezetésében és fejlesztésében. David egy olyan szakembercsapat tagja, amely arra összpontosít, hogy segítse az ügyfeleket a tanulásban, innovációban és ezeknek a nagy teljesítményű szolgáltatásoknak a felhasználásában az adataik felhasználásával.
 Ravi Avula az AWS vezető megoldások építésze, a vállalati architektúrára összpontosítva. Ravi 20 éves szoftvermérnöki tapasztalattal rendelkezik, és számos vezető szerepet töltött be a szoftverfejlesztés és a szoftverarchitektúra területén a fizetési ágazatban.
Ravi Avula az AWS vezető megoldások építésze, a vállalati architektúrára összpontosítva. Ravi 20 éves szoftvermérnöki tapasztalattal rendelkezik, és számos vezető szerepet töltött be a szoftverfejlesztés és a szoftverarchitektúra területén a fizetési ágazatban.
 George Belsian az AWS vezető felhőalkalmazás-építésze. Szenvedélyesen segíti ügyfeleit modernizációjuk és a felhőbe való áttérésük felgyorsításában. Jelenlegi szerepkörében George ügyfélcsapatokkal dolgozik együtt az innovatív, skálázható megoldások stratégiájának kidolgozásán, tervezésén és fejlesztésén.
George Belsian az AWS vezető felhőalkalmazás-építésze. Szenvedélyesen segíti ügyfeleit modernizációjuk és a felhőbe való áttérésük felgyorsításában. Jelenlegi szerepkörében George ügyfélcsapatokkal dolgozik együtt az innovatív, skálázható megoldások stratégiájának kidolgozásán, tervezésén és fejlesztésén.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/machine-learning/cost-effective-document-classification-using-the-amazon-titan-multimodal-embeddings-model/

