Large language models (or LLMs) have become a topic of daily conversations. Their quick adoption is evident by the amount of time required to reach a 100 million users, which has gone from “4.5yrs by facebook” to an all-time low of mere “2 months by ChatGPT.” A generative pre-trained transformer (GPT) uses causal autoregressive updates to make prediction. Variety of tasks such as speech recognition, text generation, and question answering are demonstrated to have stupendous performance by these model architectures. Several recent models such as NeoX, Falcon, Llama use the GPT architecture as a backbone. Training LLMs requires colossal amount of compute time, which costs millions of dollars. In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium, a purpose-built machine learning (ML) accelerator optimized for deep learning training. We’ll outline how we cost-effectively (3.2 M tokens/$) trained such models with AWS Trainium without losing any model quality.
Solution overview
GPT NeoX and Pythia models
GPT NeoX and Pythia are the open-source causal language models by Eleuther-AI with approximately 20 billion parameters in NeoX and 6.9 billion in Pythia. Both are decoder models following similar architectural design as Chat GPT3. However, they also have several additions, which are also widely adopted in the recent models such as Llama. Particularly, they have rotational positional embedding (ROPE) with partial rotation across head dimensions. The original models (NeoX and Pythia 6.9B) are trained on openly available Pile dataset with deduplication and using Megatron and Deepspeed backend.
We demonstrate the pre-training and fine-tuning of these models on AWS Trainium-based Trn1 instances using Neuron NeMo library. To establish the proof-of-concept and quick reproduction, we’ll use a smaller Wikipedia dataset subset tokenized using GPT2 Byte-pair encoding (BPE) tokenizer.
Walkthrough
Download the pre-tokenized Wikipedia dataset as shown:
Both NeoX 20B and Pythia 6.9B uses ROPE with partial rotation, for example, rotating 25% of the head dimensions and keeping the rest unrotated. To efficiently implement the partial rotation on AWS Trainium accelerator, instead of concatenating the rotating and non-rotating dimensions, we append zero frequencies for non-rotating dimensions and then rotate the complete set of head dimensions. This simple trick helped us improve the throughput (sequences processed per sec) on AWS Trainium.
Training steps
To run the training, we use SLURM managed multi-node Amazon Elastic Compute Cloud (Amazon EC2) Trn1 cluster, with each node containing a trn1.32xl instance. Each trn1.32xl has 16 accelerators with two workers per accelerator. After downloading the latest Neuron NeMo package, use the provided neox and pythia pre-training and fine-tuning scripts with optimized hyper-parameters and execute the following for a four node training.
- Compile: Pre-compile the model with three train iterations to generate and save the graphs:
- Run: Execute the training by loading the cached graphs from first steps
- Monitor results
Same steps needs to be followed for running Pythia 6.9B model with replacing neox_20B_slurm.sh by pythia_6.9B_slurm.sh.
Pre-training and fine-tuning experiments
We demonstrate the pre-training of GPT-NeoX and Pythia models on AWS Trainium using Neuron NeMo library for 10k iterations, and also show fine-tuning of these models for 1k steps. For pre-training, we use the GPT2 BPE tokenizer inside the NeMo and follow same config as used in the original model. Fine-tuning on AWS Trainium requires change of few parameters (such as vocab size division factor), which are provided in the fine-tuning scripts to accommodate for Megatron versus NeMo differences and GPU versus AWS Trainium changes. The multi-node distributed training throughput with varying number of nodes is shown in the Table-1.
| Model | Tensor Parallel | Pipeline Parallel | Number of instances | Cost ($/hour) | Sequence length | Global batch size | Throughput (seq/sec) | Cost-throughput ratio (tokens/$) |
| Pythia 6.9B | 8 | 1 | 1 | 7.59 | 2048 | 256 | 10.4 | 10,102,387 |
| 8 | 1 | 4 | 30.36 | 2048 | 256 | 35.8 | 8,693,881 | |
| NeoX 20B | 8 | 4 | 4 | 30.36 | 2048 | 16384 | 13.60 | 3,302,704 |
| 8 | 4 | 8 | 60.72 | 2048 | 16384 | 26.80 | 3,254,134 | |
| 8 | 4 | 16 | 121.44 | 2048 | 16384 | 54.30 | 3,296,632 | |
| 8 | 4 | 32 | 242.88 | 2048 | 16384 | 107.50 | 3,263,241 | |
| 8 | 4 | 64 | 485.76 | 2048 | 16384 | 212.00 | 3,217,708 |
Table 1. Comparing mean throughput of GPT NeoX and Pythia models for training up to 500 steps with changing number of nodes. The pricing of trn1.32xl is based on the 3-year reserved effective per hour rate.
Next, we also evaluate the loss trajectory of the model training on AWS Trainium and compare it with the corresponding run on a P4d (Nvidia A100 GPU cores) cluster. Along with the training loss, we also compare useful indicator such as gradient norm, which is 2-norm of the model gradients computed at each training iteration to monitor the training progress. The training results are shown in Figure-1, 2 and fine-tuning of NeoX 20B in Figure-3.

Figure-1. Training loss averaged across all workers (left) and gradient norm (right) at training each step. NeoX 20B is trained on 4 nodes with small wiki dataset on GPU and Trainium with same training hyper-parameters (global batch size=256). GPU is using BF16 and default mixed-precision while AWS Trainium is using full BF16 with stochastic rounding. The loss and gradient norm trajectories match for GPU and AWS Trainium.
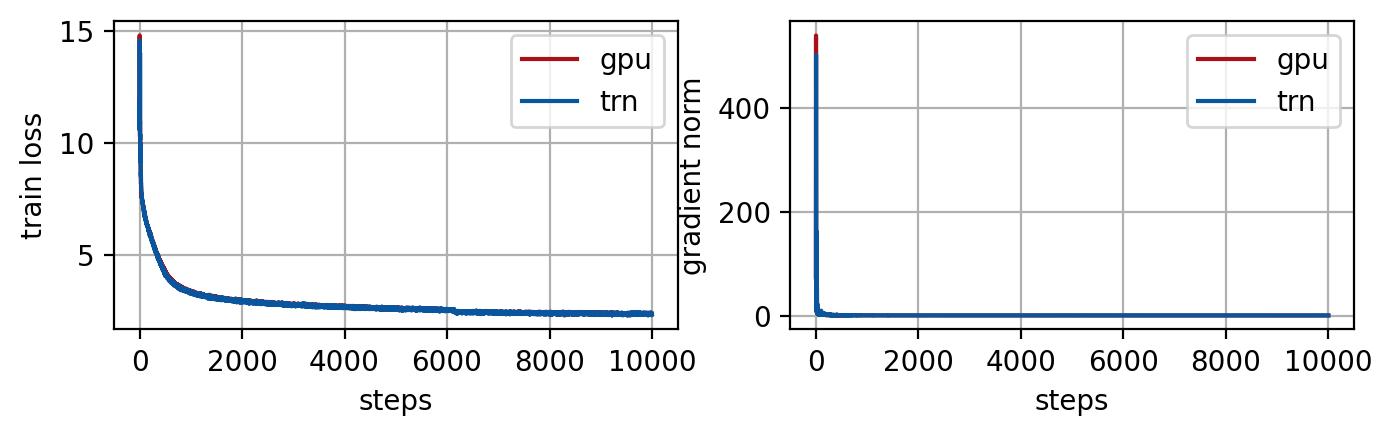
Figure-2. Training loss averaged across all workers (left) and gradient norm (right) at training each step. Similar to GPT NeoX in Figure-1, Pythia 6.9B is trained on 4 nodes with small wiki dataset on GPU and Trainium with same training hyper-parameters (global batch size=256). The loss and gradient norm trajectories match for GPU and Trainium.
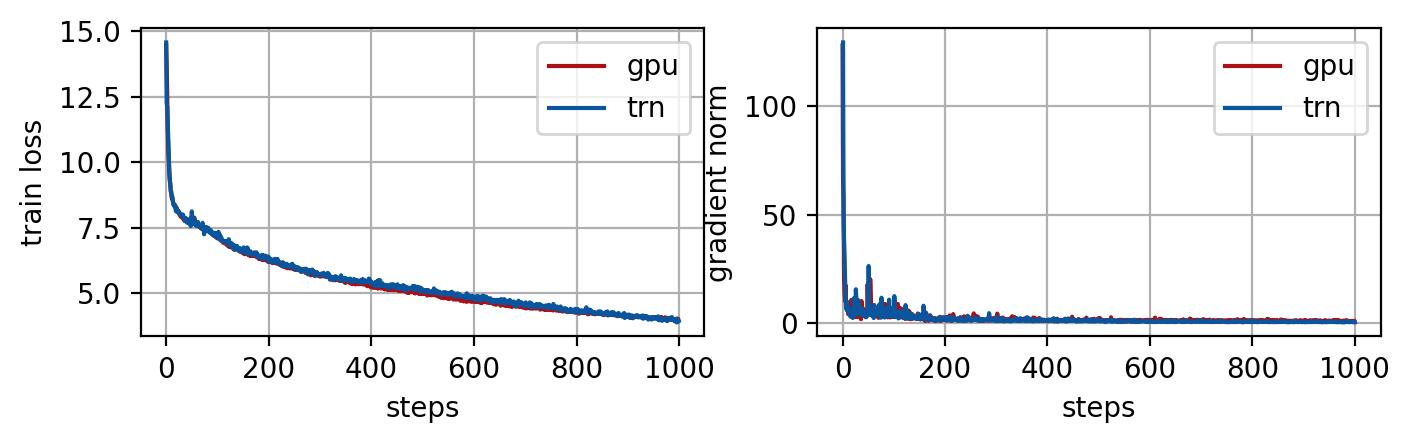
Figure-3. Fine-tuning GPT NeoX 20B model on GPU and AWS Trainium with training loss averaged across all workers (left) and gradient norm (right). A small wiki dataset is used for fine-tuning demonstration. The loss and gradient norm trajectories match for GPU and AWS Trainium.
In this post, we showed cost-efficient training of LLMs on AWS deep learning hardware. We trained GPT NeoX 20B and Pythia 6.9B models on AWS Trn1 with Neuron NeMo library. The cost normalized throughput for 20 billion models with AWS Trainium is around approximately 3.2M tokens/$ spent. Along with cost-efficient training on AWS Trainium, we obtain similar model accuracy, which is evident from training step loss and gradient norm trajectory. We also fine-tuned the available checkpoints for NeoX 20B model on AWS Trainium. For additional information on the distributed training with NeMo Megatron on AWS Trainium, see AWS Neuron Reference for NeMo Megatron. A good resource to start fine-tuning of Llama model could be found here, Llama2 fine-tuning. To get started with managed AWS Trainium on Amazon SageMaker, see Train your ML Models with AWS Trainium and Amazon SageMaker.
About the Authors
 Gaurav Gupta is currently an Applied Scientist at Amazon Web Services (AWS) AI labs. Dr. Gupta completed his PhD from USC Viterbi. His research interests span the domain of sequential data modeling, learning partial differential equations, information theory for machine learning, fractional dynamical models, and complex networks. He is currently working on applied and mathematical problems on LLMs training behavior, vision models with PDEs, information-theoretic multi-modality models. Dr. Gupta has publications in top journals/conferences such as Neurips, ICLR, ICML, Nature, IEEE Control Society, ACM cyber-physical society.
Gaurav Gupta is currently an Applied Scientist at Amazon Web Services (AWS) AI labs. Dr. Gupta completed his PhD from USC Viterbi. His research interests span the domain of sequential data modeling, learning partial differential equations, information theory for machine learning, fractional dynamical models, and complex networks. He is currently working on applied and mathematical problems on LLMs training behavior, vision models with PDEs, information-theoretic multi-modality models. Dr. Gupta has publications in top journals/conferences such as Neurips, ICLR, ICML, Nature, IEEE Control Society, ACM cyber-physical society.
 Ben Snyder is an applied scientist with AWS Deep Learning. His research interests include foundational models, reinforcement learning, and asynchronous optimization. Outside of work, he enjoys cycling and backcountry camping.
Ben Snyder is an applied scientist with AWS Deep Learning. His research interests include foundational models, reinforcement learning, and asynchronous optimization. Outside of work, he enjoys cycling and backcountry camping.
 Amith (R) Mamidala is the senior machine learning application engineering at AWS Annapurna Labs. Dr. Mamidala completed his PhD at the Ohio State University in high performance computing and communication. During his tenure at IBM research, Dr. Mamidala contributed towards the BlueGene class of computers which often led the Top500 ranking of the most powerful and power-efficient supercomputers. The project was awarded 2009 National medal of Technology and Innovation. After a brief stint as an AI engineer at a financial hedge fund, Dr. Mamidala joined the Annapurna labs focusing on Large Language model training.
Amith (R) Mamidala is the senior machine learning application engineering at AWS Annapurna Labs. Dr. Mamidala completed his PhD at the Ohio State University in high performance computing and communication. During his tenure at IBM research, Dr. Mamidala contributed towards the BlueGene class of computers which often led the Top500 ranking of the most powerful and power-efficient supercomputers. The project was awarded 2009 National medal of Technology and Innovation. After a brief stint as an AI engineer at a financial hedge fund, Dr. Mamidala joined the Annapurna labs focusing on Large Language model training.
 Jun (Luke) Huan is a principal scientist at AWS AI Labs. Dr. Huan works on AI and Data Science. He has published more than 180 peer-reviewed papers in leading conferences and journals. He was a recipient of the NSF Faculty Early Career Development Award in 2009. Before joining AWS, he worked at Baidu research as a distinguished scientist and the head of Baidu Big Data Laboratory. He founded StylingAI Inc., an AI start-up, and worked as the CEO and Chief Scientist in 2019-2021. Before joining industry, he was the Charles E. and Mary Jane Spahr Professor in the EECS Department at the University of Kansas.
Jun (Luke) Huan is a principal scientist at AWS AI Labs. Dr. Huan works on AI and Data Science. He has published more than 180 peer-reviewed papers in leading conferences and journals. He was a recipient of the NSF Faculty Early Career Development Award in 2009. Before joining AWS, he worked at Baidu research as a distinguished scientist and the head of Baidu Big Data Laboratory. He founded StylingAI Inc., an AI start-up, and worked as the CEO and Chief Scientist in 2019-2021. Before joining industry, he was the Charles E. and Mary Jane Spahr Professor in the EECS Department at the University of Kansas.
 Shruti Koparkar is a Senior Product Marketing Manager at AWS. She helps customers explore, evaluate, and adopt Amazon EC2 accelerated computing infrastructure for their machine learning needs.
Shruti Koparkar is a Senior Product Marketing Manager at AWS. She helps customers explore, evaluate, and adopt Amazon EC2 accelerated computing infrastructure for their machine learning needs.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/frugality-meets-accuracy-cost-efficient-training-of-gpt-neox-and-pythia-models-with-aws-trainium/

