Dans le paysage actuel des interactions individuelles avec les clients pour passer des commandes, la pratique dominante continue de s'appuyer sur des agents humains, même dans des contextes tels que les cafés avec service au volant et les établissements de restauration rapide. Cette approche traditionnelle pose plusieurs défis : elle dépend fortement de processus manuels, a du mal à s'adapter efficacement aux demandes croissantes des clients, introduit un risque d'erreurs humaines et fonctionne dans des heures spécifiques de disponibilité. De plus, sur des marchés concurrentiels, les entreprises qui adhèrent uniquement à des processus manuels peuvent avoir du mal à fournir un service efficace et compétitif. Malgré les progrès technologiques, le modèle centré sur l’humain reste profondément ancré dans le traitement des commandes, ce qui entraîne ces limites.
La perspective d’utiliser la technologie pour une assistance individuelle au traitement des commandes existe depuis un certain temps. Cependant, les solutions existantes peuvent souvent se diviser en deux catégories : les systèmes basés sur des règles qui nécessitent beaucoup de temps et d'efforts pour la configuration et la maintenance, ou les systèmes rigides qui n'ont pas la flexibilité requise pour des interactions humaines avec les clients. En conséquence, les entreprises et les organisations sont confrontées à des difficultés pour mettre en œuvre de telles solutions de manière rapide et efficace. Heureusement, avec l'avènement de IA générative ainsi que grands modèles de langage (LLM), il est désormais possible de créer des systèmes automatisés capables de gérer efficacement le langage naturel et avec un calendrier de montée en puissance accéléré.
Socle amazonien est un service entièrement géré qui offre un choix de modèles de base (FM) hautes performances provenant de grandes sociétés d'IA telles que AI21 Labs, Anthropic, Cohere, Meta, Stability AI et Amazon via une seule API, ainsi qu'un large ensemble de fonctionnalités dont vous avez besoin. Nous devons créer des applications d’IA génératives offrant sécurité, confidentialité et IA responsable. En plus d'Amazon Bedrock, vous pouvez utiliser d'autres services AWS comme Amazon SageMaker JumpStart ainsi que Amazon Lex pour créer des agents de traitement des commandes génératifs d’IA entièrement automatisés et facilement adaptables.
Dans cet article, nous vous montrons comment créer un agent de traitement des commandes vocal à l'aide d'Amazon Lex, Amazon Bedrock et AWS Lambda.
Vue d'ensemble de la solution
Le diagramme suivant illustre notre architecture de solution.
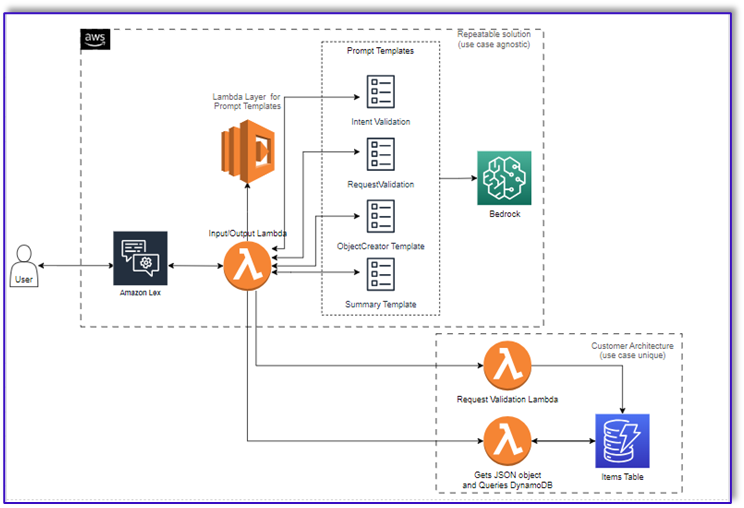
Le flux de travail comprend les étapes suivantes :
- Un client passe la commande via Amazon Lex.
- Le bot Amazon Lex interprète les intentions du client et déclenche une
DialogCodeHook.
- Une fonction Lambda extrait le modèle d'invite approprié de la couche Lambda et formate les invites du modèle en ajoutant l'entrée du client dans le modèle d'invite associé.
- La
RequestValidation L'invite vérifie la commande avec l'élément de menu et informe le client via Amazon Lex s'il souhaite commander quelque chose qui ne fait pas partie du menu et fournira des recommandations. L'invite effectue également une validation préliminaire de l'intégralité de la commande.
- La
ObjectCreator L'invite convertit les requêtes en langage naturel en une structure de données (format JSON).
- La fonction Lambda du validateur client vérifie les attributs requis pour la commande et confirme si toutes les informations nécessaires sont présentes pour traiter la commande.
- Une fonction Lambda client prend la structure de données comme entrée pour le traitement de la commande et renvoie le total de la commande à la fonction Lambda d'orchestration.
- La fonction Lambda d'orchestration appelle le point de terminaison Amazon Bedrock LLM pour générer un récapitulatif final de la commande incluant le total de la commande à partir du système de base de données client (par exemple, Amazon DynamoDB).
- Le récapitulatif de la commande est communiqué au client via Amazon Lex. Une fois que le client aura confirmé la commande, la commande sera traitée.
Pré-requis
Cet article suppose que vous disposez d'un compte AWS actif et que vous êtes familier avec les concepts et services suivants :
De plus, pour accéder à Amazon Bedrock à partir des fonctions Lambda, vous devez vous assurer que le runtime Lambda dispose des bibliothèques suivantes :
- boto3>=1.28.57
- awscli>=1.29.57
- botocore>=1.31.57
Cela peut être fait avec un Couche lambda ou en utilisant une AMI spécifique avec les bibliothèques requises.
De plus, ces bibliothèques sont requises lors de l'appel de l'API Amazon Bedrock depuis Amazon SageMakerStudio. Cela peut être fait en exécutant une cellule avec le code suivant :
%pip install --no-build-isolation --force-reinstall
"boto3>=1.28.57"
"awscli>=1.29.57"
"botocore>=1.31.57"
Enfin, vous créez la stratégie suivante et l'attachez ultérieurement à n'importe quel rôle accédant à Amazon Bedrock :
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Action": "bedrock:*",
"Resource": "*"
}
]
}
Créer une table DynamoDB
Dans notre scénario spécifique, nous avons créé une table DynamoDB comme système de base de données client, mais vous pouvez également utiliser Service de base de données relationnelle Amazon (AmazonRDS). Effectuez les étapes suivantes pour provisionner votre table DynamoDB (ou personnaliser les paramètres selon les besoins de votre cas d'utilisation) :
- Sur la console DynamoDB, choisissez Tables dans le volet de navigation.
- Selectionnez Créer une table.

- Pour Nom de la table, entrez un nom (par exemple,
ItemDetails).
- Pour Clé de partition, entrez une clé (pour ce post, nous utilisons
Item).
- Pour Clé de tri, entrez une clé (pour ce post, nous utilisons
Size).
- Selectionnez Créer une table.

Vous pouvez maintenant charger les données dans la table DynamoDB. Pour cet article, nous utilisons un fichier CSV. Vous pouvez charger les données dans la table DynamoDB à l'aide du code Python dans un notebook SageMaker.
Tout d’abord, nous devons créer un profil nommé dev.
- Ouvrez un nouveau terminal dans SageMaker Studio et exécutez la commande suivante :
aws configure --profile dev
Cette commande vous invitera à saisir votre ID de clé d'accès AWS, votre clé d'accès secrète, votre région AWS par défaut et votre format de sortie.

- Revenez au notebook SageMaker et écrivez un code Python pour configurer une connexion à DynamoDB à l'aide de la bibliothèque Boto3 en Python. Cet extrait de code crée une session à l'aide d'un profil AWS spécifique nommé dev, puis crée un client DynamoDB à l'aide de cette session. Voici l'exemple de code pour charger les données :
%pip install boto3
import boto3
import csv
# Create a session using a profile named 'dev'
session = boto3.Session(profile_name='dev')
# Create a DynamoDB resource using the session
dynamodb = session.resource('dynamodb')
# Specify your DynamoDB table name
table_name = 'your_table_name'
table = dynamodb.Table(table_name)
# Specify the path to your CSV file
csv_file_path = 'path/to/your/file.csv'
# Read CSV file and put items into DynamoDB
with open(csv_file_path, 'r', encoding='utf-8-sig') as csvfile:
csvreader = csv.reader(csvfile)
# Skip the header row
next(csvreader, None)
for row in csvreader:
# Extract values from the CSV row
item = {
'Item': row[0], # Adjust the index based on your CSV structure
'Size': row[1],
'Price': row[2]
}
# Put item into DynamoDB
response = table.put_item(Item=item)
print(f"Item added: {response}")
print(f"CSV data has been loaded into the DynamoDB table: {table_name}")
Alternativement, vous pouvez utiliser Établi NoSQL ou d'autres outils pour charger rapidement les données dans votre table DynamoDB.
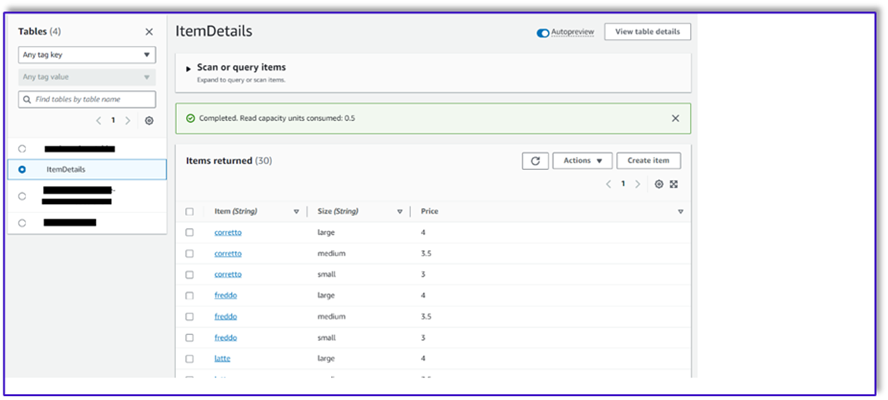
Ce qui suit est une capture d'écran une fois les exemples de données insérés dans le tableau.
Créez des modèles dans un bloc-notes SageMaker à l'aide de l'API d'appel Amazon Bedrock
Pour créer notre modèle d'invite pour ce cas d'utilisation, nous utilisons Amazon Bedrock. Vous pouvez accéder à Amazon Bedrock à partir du Console de gestion AWS et via des invocations d'API. Dans notre cas, nous accédons à Amazon Bedrock via l'API à partir du confort d'un bloc-notes SageMaker Studio pour créer non seulement notre modèle d'invite, mais également notre code d'invocation API complet que nous pourrons ensuite utiliser sur notre fonction Lambda.
- Sur la console SageMaker, accédez à un domaine SageMaker Studio existant ou créez-en un nouveau pour accéder à Amazon Bedrock à partir d'un bloc-notes SageMaker.

- Après avoir créé le domaine et l'utilisateur SageMaker, choisissez l'utilisateur et choisissez Lancement ainsi que Studio. Cela ouvrira un environnement JupyterLab.
- Lorsque l'environnement JupyterLab est prêt, ouvrez un nouveau bloc-notes et commencez à importer les bibliothèques nécessaires.

De nombreux FM sont disponibles via le SDK Amazon Bedrock Python. Dans ce cas, nous utilisons Claude V2, un puissant modèle fondateur développé par Anthropic.
L’agent de traitement des commandes a besoin de quelques modèles différents. Cela peut changer en fonction du cas d'utilisation, mais nous avons conçu un flux de travail général qui peut s'appliquer à plusieurs paramètres. Pour ce cas d'utilisation, le modèle Amazon Bedrock LLM accomplira les tâches suivantes :
- Valider l'intention du client
- Valider la demande
- Créer la structure des données de commande
- Transmettre un récapitulatif de la commande au client
- Pour appeler le modèle, créez un objet d'exécution de base à partir de Boto3.

#Model api request parameters
modelId = 'anthropic.claude-v2' # change this to use a different version from the model provider
accept = 'application/json'
contentType = 'application/json'
import boto3
import json
bedrock = boto3.client(service_name='bedrock-runtime')
Commençons par travailler sur le modèle d'invite du validateur d'intention. Il s'agit d'un processus itératif, mais grâce au guide d'ingénierie des invites d'Anthropic, vous pouvez rapidement créer une invite capable d'accomplir la tâche.
- Créez le premier modèle d'invite avec une fonction utilitaire qui aidera à préparer le corps pour les invocations d'API.
Voici le code de prompt_template_intent_validator.txt :
"{"prompt": "Human: I will give you some instructions to complete my request.n<instructions>Given the Conversation between Human and Assistant, you need to identify the intent that the human wants to accomplish and respond appropriately. The valid intents are: Greeting,Place Order, Complain, Speak to Someone. Always put your response to the Human within the Response tags. Also add an XML tag to your output identifying the human intent.nHere are some examples:n<example><Conversation> H: hi there.nnA: Hi, how can I help you today?nnH: Yes. I would like a medium mocha please</Conversation>nnA:<intent>Place Order</intent><Response>nGot it.</Response></example>n<example><Conversation> H: hellonnA: Hi, how can I help you today?nnH: my coffee does not taste well can you please re-make it?</Conversation>nnA:<intent>Complain</intent><Response>nOh, I am sorry to hear that. Let me get someone to help you.</Response></example>n<example><Conversation> H: hinnA: Hi, how can I help you today?nnH: I would like to speak to someone else please</Conversation>nnA:<intent>Speak to Someone</intent><Response>nSure, let me get someone to help you.</Response></example>n<example><Conversation> H: howdynnA: Hi, how can I help you today?nnH:can I get a large americano with sugar and 2 mochas with no whipped cream</Conversation>nnA:<intent>Place Order</intent><Response>nSure thing! Please give me a moment.</Response></example>n<example><Conversation> H: hinn</Conversation>nnA:<intent>Greeting</intent><Response>nHi there, how can I help you today?</Response></example>n</instructions>nnPlease complete this request according to the instructions and examples provided above:<request><Conversation>REPLACEME</Conversation></request>nnAssistant:n", "max_tokens_to_sample": 250, "temperature": 1, "top_k": 250, "top_p": 0.75, "stop_sequences": ["nnHuman:", "nnhuman:", "nnCustomer:", "nncustomer:"]}"


- Enregistrez ce modèle dans un fichier afin de le télécharger sur Amazon S3 et de l'appeler depuis la fonction Lambda si nécessaire. Enregistrez les modèles sous forme de chaînes sérialisées JSON dans un fichier texte. La capture d'écran précédente montre également l'exemple de code permettant d'accomplir cela.
- Répétez les mêmes étapes avec les autres modèles.
Voici quelques captures d'écran des autres modèles et les résultats lors de l'appel d'Amazon Bedrock avec certains d'entre eux.
Voici le code de prompt_template_request_validator.txt :
"{"prompt": "Human: I will give you some instructions to complete my request.n<instructions>Given the context do the following steps: 1. verify that the items in the input are valid. If customer provided an invalid item, recommend replacing it with a valid one. 2. verify that the customer has provided all the information marked as required. If the customer missed a required information, ask the customer for that information. 3. When the order is complete, provide a summary of the order and ask for confirmation always using this phrase: 'is this correct?' 4. If the customer confirms the order, Do not ask for confirmation again, just say the phrase inside the brackets [Great, Give me a moment while I try to process your order]</instructions>n<context>nThe VALID MENU ITEMS are: [latte, frappe, mocha, espresso, cappuccino, romano, americano].nThe VALID OPTIONS are: [splenda, stevia, raw sugar, honey, whipped cream, sugar, oat milk, soy milk, regular milk, skimmed milk, whole milk, 2 percent milk, almond milk].nThe required information is: size. Size can be: small, medium, large.nHere are some examples: <example>H: I would like a medium latte with 1 Splenda and a small romano with no sugar please.nnA: <Validation>:nThe Human is ordering a medium latte with one splenda. Latte is a valid menu item and splenda is a valid option. The Human is also ordering a small romano with no sugar. Romano is a valid menu item.</Validation>n<Response>nOk, I got: nt-Medium Latte with 1 Splenda and.nt-Small Romano with no Sugar.nIs this correct?</Response>nnH: yep.nnA:n<Response>nGreat, Give me a moment while I try to process your order</example>nn<example>H: I would like a cappuccino and a mocha please.nnA: <Validation>:nThe Human is ordering a cappuccino and a mocha. Both are valid menu items. The Human did not provide the size for the cappuccino. The human did not provide the size for the mocha. I will ask the Human for the required missing information.</Validation>n<Response>nSure thing, but can you please let me know the size for the Cappuccino and the size for the Mocha? We have Small, Medium, or Large.</Response></example>nn<example>H: I would like a small cappuccino and a large lemonade please.nnA: <Validation>:nThe Human is ordering a small cappuccino and a large lemonade. Cappuccino is a valid menu item. Lemonade is not a valid menu item. I will suggest the Human a replacement from our valid menu items.</Validation>n<Response>nSorry, we don't have Lemonades, would you like to order something else instead? Perhaps a Frappe or a Latte?</Response></example>nn<example>H: Can I get a medium frappuccino with sugar please?nnA: <Validation>:n The Human is ordering a Frappuccino. Frappuccino is not a valid menu item. I will suggest a replacement from the valid menu items in my context.</Validation>n<Response>nI am so sorry, but Frappuccino is not in our menu, do you want a frappe or a cappuccino instead? perhaps something else?</Response></example>nn<example>H: I want two large americanos and a small latte please.nnA: <Validation>:n The Human is ordering 2 Large Americanos, and a Small Latte. Americano is a valid menu item. Latte is a valid menu item.</Validation>n<Response>nOk, I got: nt-2 Large Americanos and.nt-Small Latte.nIs this correct?</Response>nnH: looks correct, yes.nnA:n<Response>nGreat, Give me a moment while I try to process your order.</Response></example>nn</Context>nnPlease complete this request according to the instructions and examples provided above:<request>REPLACEME</request>nnAssistant:n", "max_tokens_to_sample": 250, "temperature": 0.3, "top_k": 250, "top_p": 0.75, "stop_sequences": ["nnHuman:", "nnhuman:", "nnCustomer:", "nncustomer:"]}"

Voici notre réponse d'Amazon Bedrock utilisant ce modèle.

Voici le code pour prompt_template_object_creator.txt:
"{"prompt": "Human: I will give you some instructions to complete my request.n<instructions>Given the Conversation between Human and Assistant, you need to create a json object in Response with the appropriate attributes.nHere are some examples:n<example><Conversation> H: I want a latte.nnA:nCan I have the size?nnH: Medium.nnA: So, a medium latte.nIs this Correct?nnH: Yes.</Conversation>nnA:<Response>{"1":{"item":"latte","size":"medium","addOns":[]}}</Response></example>n<example><Conversation> H: I want a large frappe and 2 small americanos with sugar.nnA: Okay, let me confirm:nn1 large frappenn2 small americanos with sugarnnIs this correct?nnH: Yes.</Conversation>nnA:<Response>{"1":{"item":"frappe","size":"large","addOns":[]},"2":{"item":"americano","size":"small","addOns":["sugar"]},"3":{"item":"americano","size":"small","addOns":["sugar"]}}</Response>n</example>n<example><Conversation> H: I want a medium americano.nnA: Okay, let me confirm:nn1 medium americanonnIs this correct?nnH: Yes.</Conversation>nnA:<Response>{"1":{"item":"americano","size":"medium","addOns":[]}}</Response></example>n<example><Conversation> H: I want a large latte with oatmilk.nnA: Okay, let me confirm:nnLarge latte with oatmilknnIs this correct?nnH: Yes.</Conversation>nnA:<Response>{"1":{"item":"latte","size":"large","addOns":["oatmilk"]}}</Response></example>n<example><Conversation> H: I want a small mocha with no whipped cream please.nnA: Okay, let me confirm:nnSmall mocha with no whipped creamnnIs this correct?nnH: Yes.</Conversation>nnA:<Response>{"1":{"item":"mocha","size":"small","addOns":["no whipped cream"]}}</Response>nn</example></instructions>nnPlease complete this request according to the instructions and examples provided above:<request><Conversation>REPLACEME</Conversation></request>nnAssistant:n", "max_tokens_to_sample": 250, "temperature": 0.3, "top_k": 250, "top_p": 0.75, "stop_sequences": ["nnHuman:", "nnhuman:", "nnCustomer:", "nncustomer:"]}"


Voici le code de prompt_template_order_summary.txt :
"{"prompt": "Human: I will give you some instructions to complete my request.n<instructions>Given the Conversation between Human and Assistant, you need to create a summary of the order with bullet points and include the order total.nHere are some examples:n<example><Conversation> H: I want a large frappe and 2 small americanos with sugar.nnA: Okay, let me confirm:nn1 large frappenn2 small americanos with sugarnnIs this correct?nnH: Yes.</Conversation>nn<OrderTotal>10.50</OrderTotal>nnA:<Response>nHere is a summary of your order along with the total:nn1 large frappenn2 small americanos with sugar.nYour Order total is $10.50</Response></example>n<example><Conversation> H: I want a medium americano.nnA: Okay, let me confirm:nn1 medium americanonnIs this correct?nnH: Yes.</Conversation>nn<OrderTotal>3.50</OrderTotal>nnA:<Response>nHere is a summary of your order along with the total:nn1 medium americano.nYour Order total is $3.50</Response></example>n<example><Conversation> H: I want a large latte with oat milk.nnA: Okay, let me confirm:nnLarge latte with oat milknnIs this correct?nnH: Yes.</Conversation>nn<OrderTotal>6.75</OrderTotal>nnA:<Response>nHere is a summary of your order along with the total:nnLarge latte with oat milk.nYour Order total is $6.75</Response></example>n<example><Conversation> H: I want a small mocha with no whipped cream please.nnA: Okay, let me confirm:nnSmall mocha with no whipped creamnnIs this correct?nnH: Yes.</Conversation>nn<OrderTotal>4.25</OrderTotal>nnA:<Response>nHere is a summary of your order along with the total:nnSmall mocha with no whipped cream.nYour Order total is $6.75</Response>nn</example>n</instructions>nnPlease complete this request according to the instructions and examples provided above:<request><Conversation>REPLACEME</Conversation>nn<OrderTotal>REPLACETOTAL</OrderTotal></request>nnAssistant:n", "max_tokens_to_sample": 250, "temperature": 0.3, "top_k": 250, "top_p": 0.75, "stop_sequences": ["nnHuman:", "nnhuman:", "nnCustomer:", "nncustomer:", "[Conversation]"]}"


Comme vous pouvez le constater, nous avons utilisé nos modèles d'invite pour valider les éléments de menu, identifier les informations requises manquantes, créer une structure de données et résumer la commande. Les modèles fondamentaux disponibles sur Amazon Bedrock sont très puissants, vous pouvez donc accomplir encore plus de tâches via ces modèles.
Vous avez terminé l'ingénierie des invites et enregistré les modèles dans des fichiers texte. Vous pouvez maintenant commencer à créer le bot Amazon Lex et les fonctions Lambda associées.
Créer une couche Lambda avec les modèles d'invite
Effectuez les étapes suivantes pour créer votre couche Lambda :
- Dans SageMaker Studio, créez un nouveau dossier avec un sous-dossier nommé
python.
- Copiez vos fichiers d'invite dans le
python dossier.

- Vous pouvez ajouter la bibliothèque ZIP à votre instance de notebook en exécutant la commande suivante.
!conda install -y -c conda-forge zip

- Maintenant, exécutez la commande suivante pour créer le fichier ZIP à télécharger sur la couche Lambda.
!zip -r prompt_templates_layer.zip prompt_templates_layer/.

- Après avoir créé le fichier ZIP, vous pouvez télécharger le fichier. Accédez à Lambda, créez une nouvelle couche en téléchargeant le fichier directement ou en le téléchargeant d'abord sur Amazon S3.
- Attachez ensuite cette nouvelle couche à la fonction Lambda d'orchestration.
Vos fichiers de modèles d'invite sont désormais stockés localement dans votre environnement d'exécution Lambda. Cela accélérera le processus lors des exécutions de votre bot.
Créez une couche Lambda avec les bibliothèques requises
Effectuez les étapes suivantes pour créer votre couche Lambda avec les bibliothèques requises :
- Ouvrez un AWSCloud9 environnement d'instance, créez un dossier avec un sous-dossier appelé
python.
- Ouvrez un terminal à l'intérieur du
python dossier.
- Exécutez les commandes suivantes depuis le terminal :
pip install “boto3>=1.28.57” -t .
pip install “awscli>=1.29.57" -t .
pip install “botocore>=1.31.57” -t .
- Courir
cd .. et positionnez-vous dans votre nouveau dossier où vous avez également le python sous-dossier.
- Exécutez la commande suivante:
- Après avoir créé le fichier ZIP, vous pouvez télécharger le fichier. Accédez à Lambda, créez une nouvelle couche en téléchargeant le fichier directement ou en le téléchargeant d'abord sur Amazon S3.
- Attachez ensuite cette nouvelle couche à la fonction Lambda d'orchestration.
Créer le bot dans Amazon Lex v2
Pour ce cas d'utilisation, nous construisons un bot Amazon Lex qui peut fournir une interface d'entrée/sortie pour l'architecture afin d'appeler Amazon Bedrock en utilisant la voix ou le texte depuis n'importe quelle interface. Étant donné que le LLM gérera l'élément de conversation de cet agent de traitement des commandes et que Lambda orchestrera le flux de travail, vous pouvez créer un bot avec trois intentions et aucun emplacement.
- Sur la console Amazon Lex, créez un nouveau bot avec la méthode Créer un bot vierge.

Vous pouvez désormais ajouter une intention avec n'importe quel énoncé initial approprié pour que les utilisateurs finaux puissent démarrer la conversation avec le bot. Nous utilisons des salutations simples et ajoutons une réponse initiale du robot afin que les utilisateurs finaux puissent répondre à leurs demandes. Lors de la création du bot, assurez-vous d'utiliser un hook de code Lambda avec les intentions ; cela déclenchera une fonction Lambda qui orchestrera le flux de travail entre le client, Amazon Lex et le LLM.
- Ajoutez votre première intention, qui déclenche le flux de travail et utilise le modèle d'invite de validation d'intention pour appeler Amazon Bedrock et identifier ce que le client essaie d'accomplir. Ajoutez quelques énoncés simples pour que les utilisateurs finaux puissent démarrer la conversation.
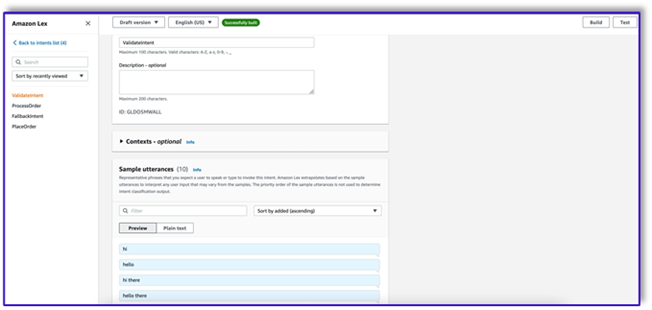
Vous n'avez pas besoin d'utiliser d'emplacements ou de lecture initiale dans aucune des intentions du bot. En fait, vous n'avez pas besoin d'ajouter des énoncés à la deuxième ou à la troisième intention. En effet, le LLM guidera Lambda tout au long du processus.
- Ajoutez une invite de confirmation. Vous pourrez personnaliser ce message dans la fonction Lambda ultérieurement.

- Sous Crochets de code, sélectionnez Utiliser une fonction Lambda pour l'initialisation et la validation.

- Créez une seconde intention sans énoncé ni réponse initiale. C'est le
PlaceOrder intention.
Lorsque le LLM identifie que le client essaie de passer une commande, la fonction Lambda déclenchera cette intention et validera la demande du client par rapport au menu, et s'assurera qu'aucune information requise ne manque. N'oubliez pas que tout cela figure dans les modèles d'invite. Vous pouvez donc adapter ce flux de travail à n'importe quel cas d'utilisation en modifiant les modèles d'invite.

- N'ajoutez aucun créneau, mais ajoutez une invite de confirmation et refusez la réponse.

- Sélectionnez Utiliser une fonction Lambda pour l'initialisation et la validation.

- Créez une troisième intention nommée
ProcessOrder sans exemples d'énoncés et sans créneaux.
- Ajoutez une réponse initiale, une invite de confirmation et une réponse de refus.
Une fois que le LLM a validé la demande du client, la fonction Lambda déclenche la troisième et dernière intention de traitement de la commande. Ici, Lambda utilisera le modèle de créateur d'objet pour générer la structure de données JSON de commande afin d'interroger la table DynamoDB, puis utilisera le modèle de résumé de commande pour résumer l'intégralité de la commande ainsi que le total afin qu'Amazon Lex puisse la transmettre au client.

- Sélectionnez Utiliser une fonction Lambda pour l'initialisation et la validation. Celui-ci peut utiliser n'importe quelle fonction Lambda pour traiter la commande une fois que le client a donné la confirmation finale.

- Après avoir créé les trois intents, accédez au générateur visuel pour le
ValidateIntent, ajoutez une étape d'intention de référence et connectez la sortie de la confirmation positive à cette étape.
- Après avoir ajouté l'intention de référence, modifiez-la et choisissez l'intention PlaceOrder comme nom de l'intention.

- De même, pour accéder au générateur visuel pour le
PlaceOrder intention et connectez la sortie de la confirmation positive au ProcessOrder aller à l'intention. Aucune modification n'est requise pour le ProcessOrder intention.
- Vous devez maintenant créer la fonction Lambda qui orchestre Amazon Lex et appelle la table DynamoDB, comme détaillé dans la section suivante.
Créer une fonction Lambda pour orchestrer le bot Amazon Lex
Vous pouvez désormais créer la fonction Lambda qui orchestre le bot et le flux de travail Amazon Lex. Effectuez les étapes suivantes :
- Créez une fonction Lambda avec la stratégie d'exécution standard et laissez Lambda créer un rôle pour vous.
- Dans la fenêtre de code de votre fonction, ajoutez quelques fonctions utilitaires qui vous aideront : formatez les invites en ajoutant le contexte lex au modèle, appelez l'API Amazon Bedrock LLM, extrayez le texte souhaité des réponses, et plus encore. Voir le code suivant :
import json
import re
import boto3
import logging
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
bedrock = boto3.client(service_name='bedrock-runtime')
def CreatingCustomPromptFromLambdaLayer(object_key,replace_items):
folder_path = '/opt/order_processing_agent_prompt_templates/python/'
try:
file_path = folder_path + object_key
with open(file_path, "r") as file1:
raw_template = file1.read()
# Modify the template with the custom input prompt
#template['inputs'][0].insert(1, {"role": "user", "content": '### Input:n' + user_request})
for key,value in replace_items.items():
value = json.dumps(json.dumps(value).replace('"','')).replace('"','')
raw_template = raw_template.replace(key,value)
modified_prompt = raw_template
return modified_prompt
except Exception as e:
return {
'statusCode': 500,
'body': f'An error occurred: {str(e)}'
}
def CreatingCustomPrompt(object_key,replace_items):
logger.debug('replace_items is: {}'.format(replace_items))
#retrieve user request from intent_request
#we first propmt the model with current order
bucket_name = 'your-bucket-name'
#object_key = 'prompt_template_order_processing.txt'
try:
s3 = boto3.client('s3')
# Retrieve the existing template from S3
response = s3.get_object(Bucket=bucket_name, Key=object_key)
raw_template = response['Body'].read().decode('utf-8')
raw_template = json.loads(raw_template)
logger.debug('raw template is {}'.format(raw_template))
#template_json = json.loads(raw_template)
#logger.debug('template_json is {}'.format(template_json))
#template = json.dumps(template_json)
#logger.debug('template is {}'.format(template))
# Modify the template with the custom input prompt
#template['inputs'][0].insert(1, {"role": "user", "content": '### Input:n' + user_request})
for key,value in replace_items.items():
raw_template = raw_template.replace(key,value)
logger.debug("Replacing: {} nwith: {}".format(key,value))
modified_prompt = json.dumps(raw_template)
logger.debug("Modified template: {}".format(modified_prompt))
logger.debug("Modified template type is: {}".format(print(type(modified_prompt))))
#modified_template_json = json.loads(modified_prompt)
#logger.debug("Modified template json: {}".format(modified_template_json))
return modified_prompt
except Exception as e:
return {
'statusCode': 500,
'body': f'An error occurred: {str(e)}'
}
def validate_intent(intent_request):
logger.debug('starting validate_intent: {}'.format(intent_request))
#retrieve user request from intent_request
user_request = 'Human: ' + intent_request['inputTranscript'].lower()
#getting current context variable
current_session_attributes = intent_request['sessionState']['sessionAttributes']
if len(current_session_attributes) > 0:
full_context = current_session_attributes['fullContext'] + 'nn' + user_request
dialog_context = current_session_attributes['dialogContext'] + 'nn' + user_request
else:
full_context = user_request
dialog_context = user_request
#Preparing validation prompt by adding context to prompt template
object_key = 'prompt_template_intent_validator.txt'
#replace_items = {"REPLACEME":full_context}
#replace_items = {"REPLACEME":dialog_context}
replace_items = {"REPLACEME":dialog_context}
#validation_prompt = CreatingCustomPrompt(object_key,replace_items)
validation_prompt = CreatingCustomPromptFromLambdaLayer(object_key,replace_items)
#Prompting model for request validation
intent_validation_completion = prompt_bedrock(validation_prompt)
intent_validation_completion = re.sub(r'["]','',intent_validation_completion)
#extracting response from response completion and removing some special characters
validation_response = extract_response(intent_validation_completion)
validation_intent = extract_intent(intent_validation_completion)
#business logic depending on intents
if validation_intent == 'Place Order':
return validate_request(intent_request)
elif validation_intent in ['Complain','Speak to Someone']:
##adding session attributes to keep current context
full_context = full_context + 'nn' + intent_validation_completion
dialog_context = dialog_context + 'nnAssistant: ' + validation_response
intent_request['sessionState']['sessionAttributes']['fullContext'] = full_context
intent_request['sessionState']['sessionAttributes']['dialogContext'] = dialog_context
intent_request['sessionState']['sessionAttributes']['customerIntent'] = validation_intent
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close',validation_response)
if validation_intent == 'Greeting':
##adding session attributes to keep current context
full_context = full_context + 'nn' + intent_validation_completion
dialog_context = dialog_context + 'nnAssistant: ' + validation_response
intent_request['sessionState']['sessionAttributes']['fullContext'] = full_context
intent_request['sessionState']['sessionAttributes']['dialogContext'] = dialog_context
intent_request['sessionState']['sessionAttributes']['customerIntent'] = validation_intent
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'InProgress','ConfirmIntent',validation_response)
def validate_request(intent_request):
logger.debug('starting validate_request: {}'.format(intent_request))
#retrieve user request from intent_request
user_request = 'Human: ' + intent_request['inputTranscript'].lower()
#getting current context variable
current_session_attributes = intent_request['sessionState']['sessionAttributes']
if len(current_session_attributes) > 0:
full_context = current_session_attributes['fullContext'] + 'nn' + user_request
dialog_context = current_session_attributes['dialogContext'] + 'nn' + user_request
else:
full_context = user_request
dialog_context = user_request
#Preparing validation prompt by adding context to prompt template
object_key = 'prompt_template_request_validator.txt'
replace_items = {"REPLACEME":dialog_context}
#validation_prompt = CreatingCustomPrompt(object_key,replace_items)
validation_prompt = CreatingCustomPromptFromLambdaLayer(object_key,replace_items)
#Prompting model for request validation
request_validation_completion = prompt_bedrock(validation_prompt)
request_validation_completion = re.sub(r'["]','',request_validation_completion)
#extracting response from response completion and removing some special characters
validation_response = extract_response(request_validation_completion)
##adding session attributes to keep current context
full_context = full_context + 'nn' + request_validation_completion
dialog_context = dialog_context + 'nnAssistant: ' + validation_response
intent_request['sessionState']['sessionAttributes']['fullContext'] = full_context
intent_request['sessionState']['sessionAttributes']['dialogContext'] = dialog_context
return close(intent_request['sessionState']['sessionAttributes'],'PlaceOrder','InProgress','ConfirmIntent',validation_response)
def process_order(intent_request):
logger.debug('starting process_order: {}'.format(intent_request))
#retrieve user request from intent_request
user_request = 'Human: ' + intent_request['inputTranscript'].lower()
#getting current context variable
current_session_attributes = intent_request['sessionState']['sessionAttributes']
if len(current_session_attributes) > 0:
full_context = current_session_attributes['fullContext'] + 'nn' + user_request
dialog_context = current_session_attributes['dialogContext'] + 'nn' + user_request
else:
full_context = user_request
dialog_context = user_request
# Preparing object creator prompt by adding context to prompt template
object_key = 'prompt_template_object_creator.txt'
replace_items = {"REPLACEME":dialog_context}
#object_creator_prompt = CreatingCustomPrompt(object_key,replace_items)
object_creator_prompt = CreatingCustomPromptFromLambdaLayer(object_key,replace_items)
#Prompting model for object creation
object_creation_completion = prompt_bedrock(object_creator_prompt)
#extracting response from response completion
object_creation_response = extract_response(object_creation_completion)
inputParams = json.loads(object_creation_response)
inputParams = json.dumps(json.dumps(inputParams))
logger.debug('inputParams is: {}'.format(inputParams))
client = boto3.client('lambda')
response = client.invoke(FunctionName = 'arn:aws:lambda:us-east-1:<AccountNumber>:function:aws-blog-order-validator',InvocationType = 'RequestResponse',Payload = inputParams)
responseFromChild = json.load(response['Payload'])
validationResult = responseFromChild['statusCode']
if validationResult == 205:
order_validation_error = responseFromChild['validator_response']
return close(intent_request['sessionState']['sessionAttributes'],'PlaceOrder','InProgress','ConfirmIntent',order_validation_error)
#invokes Order Processing lambda to query DynamoDB table and returns order total
response = client.invoke(FunctionName = 'arn:aws:lambda:us-east-1: <AccountNumber>:function:aws-blog-order-processing',InvocationType = 'RequestResponse',Payload = inputParams)
responseFromChild = json.load(response['Payload'])
orderTotal = responseFromChild['body']
###Prompting the model to summarize the order along with order total
object_key = 'prompt_template_order_summary.txt'
replace_items = {"REPLACEME":dialog_context,"REPLACETOTAL":orderTotal}
#order_summary_prompt = CreatingCustomPrompt(object_key,replace_items)
order_summary_prompt = CreatingCustomPromptFromLambdaLayer(object_key,replace_items)
order_summary_completion = prompt_bedrock(order_summary_prompt)
#extracting response from response completion
order_summary_response = extract_response(order_summary_completion)
order_summary_response = order_summary_response + '. Shall I finalize processing your order?'
##adding session attributes to keep current context
full_context = full_context + 'nn' + order_summary_completion
dialog_context = dialog_context + 'nnAssistant: ' + order_summary_response
intent_request['sessionState']['sessionAttributes']['fullContext'] = full_context
intent_request['sessionState']['sessionAttributes']['dialogContext'] = dialog_context
return close(intent_request['sessionState']['sessionAttributes'],'ProcessOrder','InProgress','ConfirmIntent',order_summary_response)
""" --- Main handler and Workflow functions --- """
def lambda_handler(event, context):
"""
Route the incoming request based on intent.
The JSON body of the request is provided in the event slot.
"""
logger.debug('event is: {}'.format(event))
return dispatch(event)
def dispatch(intent_request):
"""
Called when the user specifies an intent for this bot. If intent is not valid then returns error name
"""
logger.debug('intent_request is: {}'.format(intent_request))
intent_name = intent_request['sessionState']['intent']['name']
confirmation_state = intent_request['sessionState']['intent']['confirmationState']
# Dispatch to your bot's intent handlers
if intent_name == 'ValidateIntent' and confirmation_state == 'None':
return validate_intent(intent_request)
if intent_name == 'PlaceOrder' and confirmation_state == 'None':
return validate_request(intent_request)
elif intent_name == 'PlaceOrder' and confirmation_state == 'Confirmed':
return process_order(intent_request)
elif intent_name == 'PlaceOrder' and confirmation_state == 'Denied':
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close','Got it. Let me know if I can help you with something else.')
elif intent_name == 'PlaceOrder' and confirmation_state not in ['Denied','Confirmed','None']:
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close','Sorry. I am having trouble completing the request. Let me get someone to help you.')
logger.debug('exiting intent {} here'.format(intent_request['sessionState']['intent']['name']))
elif intent_name == 'ProcessOrder' and confirmation_state == 'None':
return validate_request(intent_request)
elif intent_name == 'ProcessOrder' and confirmation_state == 'Confirmed':
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close','Perfect! Your order has been processed. Please proceed to payment.')
elif intent_name == 'ProcessOrder' and confirmation_state == 'Denied':
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close','Got it. Let me know if I can help you with something else.')
elif intent_name == 'ProcessOrder' and confirmation_state not in ['Denied','Confirmed','None']:
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close','Sorry. I am having trouble completing the request. Let me get someone to help you.')
logger.debug('exiting intent {} here'.format(intent_request['sessionState']['intent']['name']))
raise Exception('Intent with name ' + intent_name + ' not supported')
def prompt_bedrock(formatted_template):
logger.debug('prompt bedrock input is:'.format(formatted_template))
body = json.loads(formatted_template)
modelId = 'anthropic.claude-v2' # change this to use a different version from the model provider
accept = 'application/json'
contentType = 'application/json'
response = bedrock.invoke_model(body=body, modelId=modelId, accept=accept, contentType=contentType)
response_body = json.loads(response.get('body').read())
response_completion = response_body.get('completion')
logger.debug('response is: {}'.format(response_completion))
#print_ww(response_body.get('completion'))
#print(response_body.get('results')[0].get('outputText'))
return response_completion
#function to extract text between the <Response> and </Response> tags within model completion
def extract_response(response_completion):
if '<Response>' in response_completion:
customer_response = response_completion.replace('<Response>','||').replace('</Response>','').split('||')[1]
logger.debug('modified response is: {}'.format(response_completion))
return customer_response
else:
logger.debug('modified response is: {}'.format(response_completion))
return response_completion
#function to extract text between the <Response> and </Response> tags within model completion
def extract_intent(response_completion):
if '<intent>' in response_completion:
customer_intent = response_completion.replace('<intent>','||').replace('</intent>','||').split('||')[1]
return customer_intent
else:
return customer_intent
def close(session_attributes, intent, fulfillment_state, action_type, message):
#This function prepares the response in the appropiate format for Lex V2
response = {
"sessionState": {
"sessionAttributes":session_attributes,
"dialogAction": {
"type": action_type
},
"intent": {
"name":intent,
"state":fulfillment_state
},
},
"messages":
[{
"contentType":"PlainText",
"content":message,
}]
,
}
return response
- Attachez la couche Lambda que vous avez créée précédemment à cette fonction.
- De plus, attachez le calque aux modèles d'invite que vous avez créés.
- Dans le rôle d'exécution Lambda, attachez la stratégie pour accéder à Amazon Bedrock, qui a été créée précédemment.

Le rôle d'exécution Lambda doit disposer des autorisations suivantes.

Attachez la fonction Orchestration Lambda au bot Amazon Lex
- Après avoir créé la fonction dans la section précédente, revenez à la console Amazon Lex et accédez à votre bot.
- Sous Langues dans le volet de navigation, choisissez Anglais.
- Pour Identifier, choisissez votre robot de traitement des commandes.
- Pour Version ou alias de la fonction Lambda, choisissez $DERNIER.
- Selectionnez Épargnez.

Créer des fonctions Lambda d'assistance
Effectuez les étapes suivantes pour créer des fonctions Lambda supplémentaires :
- Créez une fonction Lambda pour interroger la table DynamoDB que vous avez créée précédemment :
import json
import boto3
import logging
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
# Initialize the DynamoDB client
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('your-table-name')
def calculate_grand_total(input_data):
# Initialize the total price
total_price = 0
try:
# Loop through each item in the input JSON
for item_id, item_data in input_data.items():
item_name = item_data['item'].lower() # Convert item name to lowercase
item_size = item_data['size'].lower() # Convert item size to lowercase
# Query the DynamoDB table for the item based on Item and Size
response = table.get_item(
Key={'Item': item_name,
'Size': item_size}
)
# Check if the item was found in the table
if 'Item' in response:
item = response['Item']
price = float(item['Price'])
total_price += price # Add the item's price to the total
return total_price
except Exception as e:
raise Exception('An error occurred: {}'.format(str(e)))
def lambda_handler(event, context):
try:
# Parse the input JSON from the Lambda event
input_json = json.loads(event)
# Calculate the grand total
grand_total = calculate_grand_total(input_json)
# Return the grand total in the response
return {'statusCode': 200,'body': json.dumps(grand_total)}
except Exception as e:
return {
'statusCode': 500,
'body': json.dumps('An error occurred: {}'.format(str(e)))
- Accédez à la configuration dans la fonction Lambda et choisissez Permissions.
- Joignez une déclaration de stratégie basée sur les ressources permettant à la fonction Lambda de traitement des commandes d'appeler cette fonction.

- Accédez au rôle d'exécution IAM pour cette fonction Lambda et ajoutez une stratégie pour accéder à la table DynamoDB.

- Créez une autre fonction Lambda pour vérifier si tous les attributs requis ont été transmis par le client. Dans l'exemple suivant, nous vérifions si l'attribut size est capturé pour une commande :
import json
import logging
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
def lambda_handler(event, context):
# Define customer orders from the input event
customer_orders = json.loads(event)
# Initialize a list to collect error messages
order_errors = {}
missing_size = []
error_messages = []
# Iterate through each order in customer_orders
for order_id, order in customer_orders.items():
if "size" not in order or order["size"] == "":
missing_size.append(order['item'])
order_errors['size'] = missing_size
if order_errors:
items_missing_size = order_errors['size']
error_message = f"could you please provide the size for the following items: {', '.join(items_missing_size)}?"
error_messages.append(error_message)
# Prepare the response message
if error_messages:
response_message = "n".join(error_messages)
return {
'statusCode': 205,
'validator_response': response_message
}
else:
response_message = "Order is validated successfully"
return {
'statusCode': 200,
'validator_response': response_message
}
- Accédez à la configuration dans la fonction Lambda et choisissez Permissions.
- Joignez une déclaration de stratégie basée sur les ressources permettant à la fonction Lambda de traitement des commandes d'appeler cette fonction.

Testez la solution
Nous pouvons désormais tester la solution avec des exemples de commandes que les clients passent via Amazon Lex.
Pour notre premier exemple, le client a demandé un frappuccino, qui ne figure pas au menu. Le modèle valide à l'aide du modèle de validateur de commande et suggère quelques recommandations basées sur le menu. Une fois que le client a confirmé sa commande, il est informé du total de la commande et du récapitulatif de la commande. La commande sera traitée sur la base de la confirmation finale du client.

Dans notre exemple suivant, le client commande un grand cappuccino, puis modifie la taille de grand à moyen. Le modèle capture toutes les modifications nécessaires et demande au client de confirmer la commande. Le modèle présente le total de la commande et le récapitulatif de la commande, et traite la commande en fonction de la confirmation finale du client.
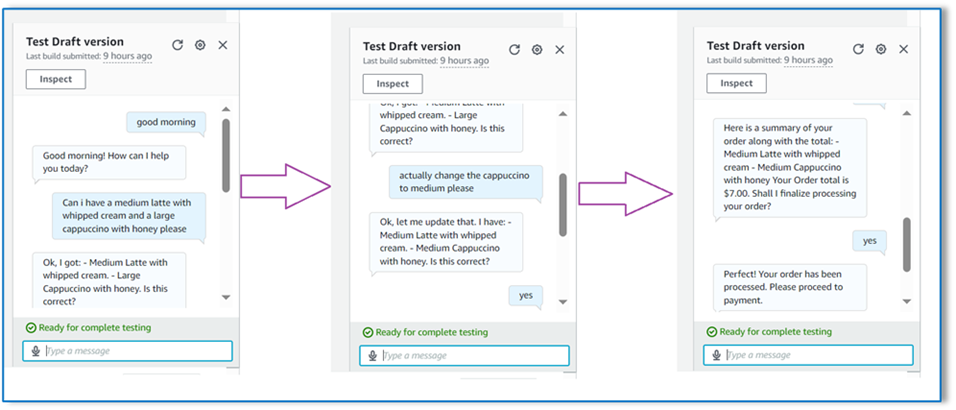
Pour notre dernier exemple, le client a passé une commande pour plusieurs articles et la taille manque pour quelques articles. Le modèle et la fonction Lambda vérifieront si tous les attributs requis sont présents pour traiter la commande, puis demanderont au client de fournir les informations manquantes. Une fois que le client a fourni les informations manquantes (dans ce cas, la taille du café), le total et le récapitulatif de la commande lui sont présentés. La commande sera traitée sur la base de la confirmation finale du client.
Limites du LLM
Les résultats du LLM sont par nature stochastiques, ce qui signifie que les résultats de notre LLM peuvent varier en format, voire sous la forme de contenu mensonger (hallucinations). Par conséquent, les développeurs doivent s'appuyer sur une bonne logique de gestion des erreurs dans tout leur code afin de gérer ces scénarios et d'éviter une expérience utilisateur finale dégradée.
Nettoyer
Si vous n'avez plus besoin de cette solution, vous pouvez supprimer les ressources suivantes :
- Fonctions Lambda
- Boîte Amazon Lex
- Table DynamoDB
- Seau S3
De plus, arrêtez l'instance de SageMaker Studio si l'application n'est plus requise.
Évaluation des coûts
Pour obtenir des informations sur les tarifs des principaux services utilisés par cette solution, consultez les informations suivantes :
Notez que vous pouvez utiliser Claude v2 sans avoir besoin de provisionnement, les coûts globaux restent donc au minimum. Pour réduire davantage les coûts, vous pouvez configurer la table DynamoDB avec le paramètre à la demande.
Conclusion
Cet article a montré comment créer un agent de traitement des commandes doté d'une IA vocale à l'aide d'Amazon Lex, d'Amazon Bedrock et d'autres services AWS. Nous avons montré comment une ingénierie rapide avec un puissant modèle d'IA générative comme Claude peut permettre une compréhension robuste du langage naturel et des flux de conversation pour le traitement des commandes sans avoir besoin de données de formation approfondies.
L'architecture de la solution utilise des composants sans serveur tels que Lambda, Amazon S3 et DynamoDB pour permettre une mise en œuvre flexible et évolutive. Le stockage des modèles d'invite dans Amazon S3 vous permet de personnaliser la solution pour différents cas d'utilisation.
Les prochaines étapes pourraient inclure l'extension des capacités de l'agent pour gérer un plus large éventail de demandes des clients et de cas extrêmes. Les modèles d'invites permettent d'améliorer de manière itérative les compétences de l'agent. Des personnalisations supplémentaires pourraient impliquer l'intégration des données de commande avec des systèmes backend tels que l'inventaire, le CRM ou le point de vente. Enfin, l'agent pourrait être mis à disposition sur divers points de contact client tels que les applications mobiles, le service au volant, les kiosques, etc. en utilisant les capacités multicanaux d'Amazon Lex.
Pour en savoir plus, reportez-vous aux ressources connexes suivantes :
- Déployer et gérer des bots multicanaux :
- Ingénierie rapide pour Claude et autres modèles :
- Modèles architecturaux sans serveur pour les assistants IA évolutifs :
À propos des auteurs
 Moumita Dutta est architecte de solutions partenaire chez Amazon Web Services. Dans son rôle, elle collabore étroitement avec des partenaires pour développer des actifs évolutifs et réutilisables qui rationalisent les déploiements cloud et améliorent l'efficacité opérationnelle. Elle est membre de la communauté AI/ML et experte en IA générative chez AWS. Dans ses loisirs, elle aime jardiner et faire du vélo.
Moumita Dutta est architecte de solutions partenaire chez Amazon Web Services. Dans son rôle, elle collabore étroitement avec des partenaires pour développer des actifs évolutifs et réutilisables qui rationalisent les déploiements cloud et améliorent l'efficacité opérationnelle. Elle est membre de la communauté AI/ML et experte en IA générative chez AWS. Dans ses loisirs, elle aime jardiner et faire du vélo.
 Fernando Lammoglia est un architecte de solutions partenaires chez Amazon Web Services, travaillant en étroite collaboration avec les partenaires AWS pour diriger le développement et l'adoption de solutions d'IA de pointe dans toutes les unités commerciales. Un leader stratégique possédant une expertise en architecture cloud, en IA générative, en apprentissage automatique et en analyse de données. Il se spécialise dans l’exécution de stratégies de commercialisation et dans la fourniture de solutions d’IA percutantes alignées sur les objectifs organisationnels. Pendant son temps libre, il aime passer du temps avec sa famille et voyager dans d'autres pays.
Fernando Lammoglia est un architecte de solutions partenaires chez Amazon Web Services, travaillant en étroite collaboration avec les partenaires AWS pour diriger le développement et l'adoption de solutions d'IA de pointe dans toutes les unités commerciales. Un leader stratégique possédant une expertise en architecture cloud, en IA générative, en apprentissage automatique et en analyse de données. Il se spécialise dans l’exécution de stratégies de commercialisation et dans la fourniture de solutions d’IA percutantes alignées sur les objectifs organisationnels. Pendant son temps libre, il aime passer du temps avec sa famille et voyager dans d'autres pays.
 Mitul Patel est architecte de solutions senior chez Amazon Web Services. Dans son rôle de facilitateur de technologie cloud, il travaille avec les clients pour comprendre leurs objectifs et leurs défis, et fournit des conseils prescriptifs pour atteindre leur objectif avec les offres AWS. Il est membre de la communauté AI/ML et ambassadeur de l'IA générative chez AWS. Pendant son temps libre, il aime faire de la randonnée et jouer au football.
Mitul Patel est architecte de solutions senior chez Amazon Web Services. Dans son rôle de facilitateur de technologie cloud, il travaille avec les clients pour comprendre leurs objectifs et leurs défis, et fournit des conseils prescriptifs pour atteindre leur objectif avec les offres AWS. Il est membre de la communauté AI/ML et ambassadeur de l'IA générative chez AWS. Pendant son temps libre, il aime faire de la randonnée et jouer au football.

