Les clients souhaitent de plus en plus utiliser des approches d'apprentissage profond telles que grands modèles de langage (LLM) pour automatiser l’extraction de données et d’informations. Pour de nombreux secteurs, les données utiles pour l'apprentissage automatique (ML) peuvent contenir des informations personnelles identifiables (PII). Pour garantir la confidentialité des clients et maintenir la conformité réglementaire lors de la formation, du réglage fin et de l'utilisation de modèles d'apprentissage profond, il est souvent nécessaire de d'abord supprimer les informations personnelles à partir des données sources.
Cet article montre comment utiliser Gestionnaire de données Amazon SageMaker ainsi que le Amazon comprendre pour supprimer automatiquement les informations personnelles à partir des données tabulaires dans le cadre de votre opérations d'apprentissage automatique (ML Ops).
Problème : données ML contenant des informations personnelles
Les informations personnelles sont définies comme toute représentation d'informations permettant de déduire raisonnablement l'identité d'une personne à laquelle les informations s'appliquent, par des moyens directs ou indirects. Les PII sont des informations qui identifient directement une personne (nom, adresse, numéro de sécurité sociale ou autre numéro ou code d'identification, numéro de téléphone, adresse e-mail, etc.) ou des informations qu'une agence a l'intention d'utiliser pour identifier des personnes spécifiques en conjonction avec d'autres éléments de données, nommément identification indirecte.
Les clients des domaines d'activité tels que la finance, la vente au détail, le droit et le gouvernement traitent régulièrement des données PII. En raison de diverses réglementations et règles gouvernementales, les clients doivent trouver un mécanisme pour gérer ces données sensibles avec des mesures de sécurité appropriées pour éviter les amendes réglementaires, une éventuelle fraude et diffamation. La rédaction des informations personnelles est le processus de masquage ou de suppression des informations sensibles d'un document afin qu'elles puissent être utilisées et distribuées, tout en protégeant les informations confidentielles.
Les entreprises doivent offrir des expériences client agréables et de meilleurs résultats commerciaux en utilisant le ML. La rédaction des données PII est souvent une première étape clé pour débloquer les flux de données plus volumineux et plus riches nécessaires à l'utilisation ou au réglage fin. modèles d'IA génératifs, sans se soucier de savoir si les données de leur entreprise (ou celles de leurs clients) seront compromises.
Vue d'ensemble de la solution
Cette solution utilise Amazon Comprehend et SageMaker Data Wrangler pour rédiger automatiquement les données PII à partir d'un exemple d'ensemble de données.
Amazon Comprehend est un service de traitement du langage naturel (NLP) qui utilise le ML pour découvrir des informations et des relations dans des données non structurées, sans qu'aucune infrastructure de gestion ou expérience en ML ne soit requise. Il fournit des fonctionnalités pour localiser divers types d'entités PII dans le texte, par exemple des noms ou des numéros de carte de crédit. Bien que les derniers modèles d'IA générative aient démontré une certaine capacité de rédaction de PII, ils ne fournissent généralement pas de score de confiance pour l'identification de PII ou de données structurées décrivant ce qui a été rédigé. La fonctionnalité PII d'Amazon Comprehend renvoie les deux, vous permettant de créer des flux de travail de rédaction entièrement vérifiables à grande échelle. De plus, en utilisant Amazon Comprehend avec Lien privé AWS signifie que les données client ne quittent jamais le réseau AWS et sont continuellement sécurisées avec les mêmes contrôles d'accès aux données et de confidentialité que le reste de vos applications.
Semblable à Amazon Comprehend, Amazone Macie utilise un moteur basé sur des règles pour identifier les données sensibles (y compris les informations personnelles) stockées dans Service de stockage simple Amazon (Amazon S3). Cependant, son approche basée sur des règles repose sur des mots-clés spécifiques indiquant des données sensibles situées à proximité de ces données (dans les 30 caractères). En revanche, l'approche ML basée sur le NLP d'Amazon Comprehend utilise la compréhension sématique de morceaux de texte plus longs pour identifier les informations personnelles, ce qui la rend plus utile pour rechercher des informations personnelles dans des données non structurées.
De plus, pour les données tabulaires telles que les fichiers CSV ou texte brut, Macie renvoie des informations de localisation moins détaillées qu'Amazon Comprehend (soit un indicateur de ligne/colonne, soit un numéro de ligne, respectivement, mais pas les décalages des caractères de début et de fin). Cela rend Amazon Comprehend particulièrement utile pour rédiger des PII à partir de texte non structuré pouvant contenir un mélange de mots PII et non PII (par exemple, des tickets d'assistance ou des invites LLM) stockés sous forme de tableau.
Amazon Sage Maker fournit des outils spécialement conçus pour les équipes ML afin d'automatiser et de standardiser les processus tout au long du cycle de vie du ML. Avec les outils SageMaker MLOps, les équipes peuvent facilement préparer, former, tester, dépanner, déployer et gouverner des modèles ML à grande échelle, augmentant ainsi la productivité des data scientists et des ingénieurs ML tout en maintenant les performances des modèles en production. Le diagramme suivant illustre le flux de travail SageMaker MLOps.
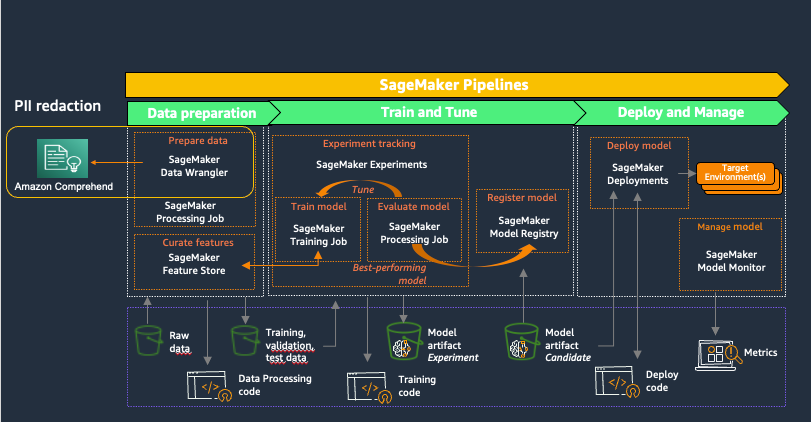
SageMaker Data Wrangler est une fonctionnalité de Amazon SageMakerStudio qui fournit une solution de bout en bout pour importer, préparer, transformer, présenter et analyser des ensembles de données stockés dans des emplacements tels qu'Amazon S3 ou Amazone Athéna, une première étape courante dans le cycle de vie du ML. Vous pouvez utiliser SageMaker Data Wrangler pour simplifier et rationaliser le prétraitement des ensembles de données et l'ingénierie des fonctionnalités, soit en utilisant des transformations intégrées sans code, soit en les personnalisant avec vos propres scripts Python.
L'utilisation d'Amazon Comprehend pour rédiger des informations personnelles dans le cadre d'un flux de travail de préparation de données SageMaker Data Wrangler permet de maintenir toutes les utilisations en aval des données, telles que la formation de modèles ou l'inférence, en conformité avec les exigences PII de votre organisation. Vous pouvez intégrer SageMaker Data Wrangler avec Pipelines Amazon SageMaker pour automatiser les opérations ML de bout en bout, y compris la préparation des données et la rédaction des informations personnelles. Pour plus de détails, reportez-vous à Intégration de SageMaker Data Wrangler avec SageMaker Pipelines. Le reste de cet article présente un flux SageMaker Data Wrangler qui utilise Amazon Comprehend pour rédiger des informations personnelles à partir du texte stocké au format de données tabulaires.
Cette solution utilise un public jeu de données synthétique ainsi qu'un flux SageMaker Data Wrangler personnalisé, disponible sous forme de fichier dans GitHub. Les étapes à suivre pour utiliser le flux SageMaker Data Wrangler pour rédiger des informations personnelles sont les suivantes :
- Ouvrez SageMaker Studio.
- Téléchargez le flux SageMaker Data Wrangler.
- Passez en revue le flux SageMaker Data Wrangler.
- Ajoutez un nœud de destination.
- Créez une tâche d'exportation SageMaker Data Wrangler.
Cette procédure pas à pas, y compris l'exécution de la tâche d'exportation, devrait prendre 20 à 25 minutes.
Pré-requis
Pour cette procédure pas à pas, vous devez disposer des éléments suivants :
Ouvrir SageMaker Studio
Pour ouvrir SageMaker Studio, procédez comme suit :
- Sur la console SageMaker, choisissez Studio dans le volet de navigation.
- Choisissez le domaine et le profil utilisateur
- Selectionnez Open Studio.
Pour démarrer avec les nouvelles fonctionnalités de SageMaker Data Wrangler, il est recommandé de mise à niveau vers la dernière version.
Téléchargez le flux SageMaker Data Wrangler
Vous devez d'abord récupérer le fichier de flux SageMaker Data Wrangler depuis GitHub et le télécharger sur SageMaker Studio. Effectuez les étapes suivantes :
- Accédez au SageMaker Data Wrangler
redact-pii.flowfichier sur GitHub. - Sur GitHub, choisissez l'icône de téléchargement pour télécharger le fichier de flux sur votre ordinateur local.
- Dans SageMaker Studio, choisissez l'icône de fichier dans le volet de navigation.
- Choisissez l'icône de téléchargement, puis choisissez
redact-pii.flow.
Examiner le flux SageMaker Data Wrangler
Dans SageMaker Studio, ouvrez redact-pii.flow. Après quelques minutes, le flux terminera son chargement et affichera l'organigramme (voir la capture d'écran suivante). Le flux contient six étapes : un Source S3 étape suivie de cinq étapes de transformation.

Sur l'organigramme, choisissez la dernière étape, Réduire les informations personnellesL’ Toutes les étapes Le volet s'ouvre sur la droite et affiche une liste des étapes du flux. Vous pouvez développer chaque étape pour afficher les détails, modifier les paramètres et éventuellement ajouter du code personnalisé.
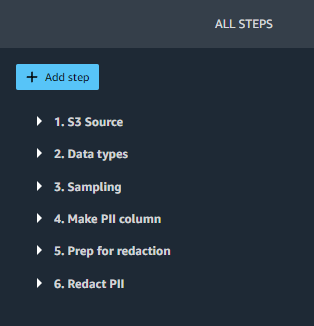
Passons en revue chaque étape du flux.
Étapes 1 (Source S3) et 2 (Types de données) sont ajoutés par SageMaker Data Wrangler chaque fois que des données sont importées pour un nouveau flux. Dans Source S3, URI S3 Le champ pointe vers l'exemple d'ensemble de données, qui est un fichier CSV stocké dans Amazon S3. Le fichier contient environ 116,000 XNUMX lignes et le flux définit la valeur de Échantillonnage champ à 1,000 1,000, ce qui signifie que SageMaker Data Wrangler échantillonnera XNUMX XNUMX lignes à afficher dans l’interface utilisateur. Types de données définit le type de données pour chaque colonne de données importées.
Étape 3 (Échantillonnage) définit le nombre de lignes que SageMaker Data Wrangler échantillonnera pour une tâche d'exportation sur 5,000 XNUMX, via le Taille approximative de l'échantillon champ. Notez que cela est différent du nombre de lignes échantillonnées à afficher dans l'interface utilisateur (étape 1). Pour exporter des données comportant plus de lignes, vous pouvez augmenter ce nombre ou supprimer l'étape 3.
Les étapes 4, 5 et 6 utilisent Transformations personnalisées SageMaker Data Wrangler. Les transformations personnalisées vous permettent d'exécuter votre propre code Python ou SQL dans un flux Data Wrangler. Le code personnalisé peut être écrit de quatre manières :
- En SQL, utiliser PySpark SQL pour modifier l'ensemble de données
- En Python, utiliser un bloc de données et des bibliothèques PySpark pour modifier l'ensemble de données
- En Python, en utilisant un pandas bloc de données et bibliothèques pour modifier l'ensemble de données
- En Python, utiliser une fonction définie par l'utilisateur pour modifier une colonne de l'ensemble de données
L'approche Python (pandas) nécessite que votre ensemble de données tienne dans la mémoire et ne peut être exécuté que sur une seule instance, ce qui limite sa capacité à évoluer efficacement. Lorsque vous travaillez en Python avec des ensembles de données plus volumineux, nous vous recommandons d'utiliser l'approche Python (PySpark) ou Python (fonction définie par l'utilisateur). SageMaker Data Wrangler optimise les fonctions Python définies par l'utilisateur pour fournir des performances similaires à un plugin Apache Spark, sans avoir besoin de connaître PySpark ou Pandas. Pour rendre cette solution aussi accessible que possible, cet article utilise une fonction Python définie par l'utilisateur écrite en Python pur.
Développez l'étape 4 (Créer une colonne PII) pour voir ses détails. Cette étape combine différents types de données PII provenant de plusieurs colonnes en une seule phrase enregistrée dans une nouvelle colonne. pii_col. Le tableau suivant montre un exemple de ligne contenant des données.
| nom_client | client_emploi | Adresse de facturation | email client |
| Katie | Journaliste | 19009 Places Vang Suite 805 | [email protected] |
Ceci est combiné dans la phrase « Katie est une journaliste qui vit au 19009 Vang Squares Suite 805 et peut être envoyée par courrier électronique à [email protected]». La phrase est enregistrée dans pii_col, que cet article utilise comme colonne cible à rédiger.
Étape 5 (Préparation à la rédaction) prend une colonne à rédiger (pii_col) et crée une nouvelle colonne (pii_col_prep) prêt à être rédigé efficacement à l'aide d'Amazon Comprehend. Pour supprimer les informations personnelles d'une autre colonne, vous pouvez modifier le Colonne d'entrée domaine de cette étape.
Il y a deux facteurs à prendre en compte pour rédiger efficacement des données à l'aide d'Amazon Comprehend :
- La coût pour détecter les informations personnelles est défini sur une base unitaire, où 1 unité = 100 caractères, avec un tarif minimum de 3 unités pour chaque document. Étant donné que les données tabulaires contiennent souvent de petites quantités de texte par cellule, il est généralement plus rapide et plus rentable de combiner le texte de plusieurs cellules en un seul document à envoyer à Amazon Comprehend. Cela évite l'accumulation de surcharge due à de nombreux appels de fonction répétés et garantit que les données envoyées sont toujours supérieures au minimum de 3 unités.
- Étant donné que nous effectuons la rédaction comme une étape d'un flux SageMaker Data Wrangler, nous appellerons Amazon Comprehend de manière synchrone. Amazon Comprehend définit un Limite de 100 Ko (100,000 XNUMX caractères) par appel de fonction synchrone, nous devons donc nous assurer que tout texte que nous envoyons est inférieur à cette limite.
Compte tenu de ces facteurs, l'étape 5 prépare les données à envoyer à Amazon Comprehend en ajoutant une chaîne de délimitation à la fin du texte dans chaque cellule. Pour le délimiteur, vous pouvez utiliser n'importe quelle chaîne qui n'apparaît pas dans la colonne en cours de rédaction (idéalement, une chaîne contenant le moins de caractères possible, car elles sont incluses dans le total de caractères Amazon Comprehend). L'ajout de ce délimiteur de cellule nous permet d'optimiser l'appel à Amazon Comprehend, et sera abordé plus en détail à l'étape 6.
Notez que si le texte d'une cellule individuelle est plus long que la limite Amazon Comprehend, le code de cette étape le tronque à 100,000 15,000 caractères (environ l'équivalent de 30 XNUMX mots ou XNUMX pages à simple interligne). Bien qu'il soit peu probable que cette quantité de texte soit stockée dans une seule cellule, vous pouvez modifier le code de transformation pour gérer ce cas extrême d'une autre manière si nécessaire.
Étape 6 (Réduire les informations personnelles) prend un nom de colonne à rédiger en entrée (pii_col_prep) et enregistre le texte rédigé dans une nouvelle colonne (pii_redacted). Lorsque vous utilisez une transformation de fonction personnalisée Python, SageMaker Data Wrangler définit un champ vide custom_func ça prend un pandas Series (une colonne de texte) en entrée et renvoie une série de pandas modifiée de même longueur. La capture d'écran suivante montre une partie du Réduire les informations personnelles étape.
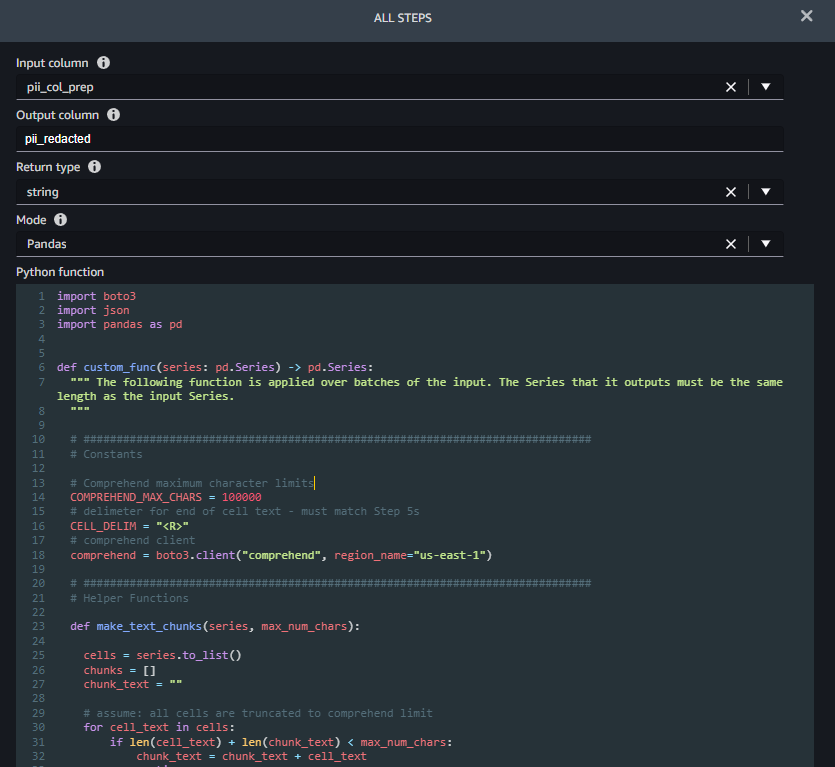
La fonction custom_func contient deux fonctions d'assistance (internes) :
make_text_chunks– Cette fonction effectue le travail de concaténation du texte des cellules individuelles de la série (y compris leurs délimiteurs) en chaînes plus longues (morceaux) à envoyer à Amazon Comprehend.redact_pii– Cette fonction prend le texte en entrée, appelle Amazon Comprehend pour détecter les informations personnelles, supprime celles trouvées et renvoie le texte rédigé. La rédaction est effectuée en remplaçant tout texte PII par le type de PII trouvé entre crochets, par exemple John Smith serait remplacé par [NOM]. Vous pouvez modifier cette fonction pour remplacer les PII par n'importe quelle chaîne, y compris la chaîne vide (« ») pour la supprimer. Vous pouvez également modifier la fonction pour vérifier le score de confiance de chaque entité PII et n'expurger que s'il est supérieur à un seuil spécifique.
Une fois les fonctions internes définies, custom_func les utilise pour effectuer la rédaction, comme indiqué dans l'extrait de code suivant. Une fois la rédaction terminée, il reconvertit les morceaux en cellules d'origine, qu'il enregistre dans le pii_redacted colonne.
Ajouter un nœud de destination
Pour voir le résultat de vos transformations, SageMaker Data Wrangler prend en charge l'exportation vers Amazon S3, SageMaker Pipelines, Magasin de fonctionnalités Amazon SageMakeret le code Python. Pour exporter les données rédigées vers Amazon S3, nous devons d'abord créer un nœud de destination :
- Dans le diagramme de flux SageMaker Data Wrangler, choisissez le signe plus à côté du Réduire les informations personnelles étape.
- Selectionnez Ajouter destination, Puis choisissez Amazon S3.
- Fournissez un nom de sortie pour votre ensemble de données transformé.
- Parcourez ou entrez l'emplacement S3 pour stocker le fichier de données expurgé.
- Selectionnez Ajouter destination.
Vous devriez maintenant voir le nœud de destination à la fin de votre flux de données.
Créer une tâche d'exportation SageMaker Data Wrangler
Maintenant que le nœud de destination a été ajouté, nous pouvons créer la tâche d'exportation pour traiter l'ensemble de données :
- Dans SageMaker Data Wrangler, choisissez Créer un emploi.
- Le nœud de destination que vous venez d'ajouter devrait déjà être sélectionné. Choisir Suivant.
- Acceptez les valeurs par défaut pour toutes les autres options, puis choisissez Courir.
Cela crée un Travail de traitement SageMaker. Pour afficher l'état de la tâche, accédez à la console SageMaker. Dans le volet de navigation, développez le En cours section et choisissez Tâches de traitement. La suppression des 116,000 5.4 cellules de la colonne cible à l’aide des paramètres de tâche d’exportation par défaut (deux instances ml.m8xlarge) prend environ 0.25 minutes et coûte environ 3 USD. Une fois la tâche terminée, téléchargez le fichier de sortie avec la colonne expurgée depuis Amazon SXNUMX.
Nettoyer
L'application SageMaker Data Wrangler s'exécute sur une instance ml.m5.4xlarge. Pour l'arrêter, dans SageMaker Studio, choisissez Exécution de terminaux et de noyaux dans le volet de navigation. Dans le INSTANCES D'EXÉCUTION section, recherchez l'instance étiquetée Traqueur de données et choisissez l'icône d'arrêt à côté. Cela ferme l'application SageMaker Data Wrangler exécutée sur l'instance.
Conclusion
Dans cet article, nous avons expliqué comment utiliser des transformations personnalisées dans SageMaker Data Wrangler et Amazon Comprehend pour supprimer les données PII de votre ensemble de données ML. Tu peux download le flux SageMaker Data Wrangler et commencez dès aujourd'hui à rédiger les informations personnelles à partir de vos données tabulaires.
Pour d'autres façons d'améliorer votre flux de travail MLOps à l'aide des transformations personnalisées SageMaker Data Wrangler, consultez Création de transformations personnalisées dans Amazon SageMaker Data Wrangler à l'aide de NLTK et SciPy. Pour plus d'options de préparation des données, consultez la série d'articles de blog qui explique comment utiliser Amazon Comprehend pour réagir, traduire et analyser du texte depuis l'un ou l'autre. Amazone Athéna or Redshift d'Amazon.
À propos des auteurs
 Tricia Jamison est architecte de prototypage senior au sein de l'équipe AWS Prototyping and Cloud Acceleration (PACE), où elle aide les clients AWS à mettre en œuvre des solutions innovantes aux problèmes difficiles liés à l'apprentissage automatique, à l'Internet des objets (IoT) et aux technologies sans serveur. Elle vit à New York et aime le basket-ball, les randonnées longue distance et avoir une longueur d'avance sur ses enfants.
Tricia Jamison est architecte de prototypage senior au sein de l'équipe AWS Prototyping and Cloud Acceleration (PACE), où elle aide les clients AWS à mettre en œuvre des solutions innovantes aux problèmes difficiles liés à l'apprentissage automatique, à l'Internet des objets (IoT) et aux technologies sans serveur. Elle vit à New York et aime le basket-ball, les randonnées longue distance et avoir une longueur d'avance sur ses enfants.
 Neelam Koshiya est architecte de solutions d'entreprise chez AWS. Avec une formation en génie logiciel, elle est naturellement passée à un rôle d'architecture. Son objectif actuel est d'aider les entreprises clientes dans leur parcours d'adoption du cloud pour des résultats commerciaux stratégiques, le domaine de profondeur étant l'IA/ML. Elle est passionnée par l'innovation et l'inclusion. Dans ses temps libres, elle aime lire et être à l'extérieur.
Neelam Koshiya est architecte de solutions d'entreprise chez AWS. Avec une formation en génie logiciel, elle est naturellement passée à un rôle d'architecture. Son objectif actuel est d'aider les entreprises clientes dans leur parcours d'adoption du cloud pour des résultats commerciaux stratégiques, le domaine de profondeur étant l'IA/ML. Elle est passionnée par l'innovation et l'inclusion. Dans ses temps libres, elle aime lire et être à l'extérieur.
 Adèleke Coker est un architecte de solutions globales avec AWS. Il travaille avec des clients du monde entier pour fournir des conseils et une assistance technique dans le déploiement de charges de travail de production à grande échelle sur AWS. Dans ses temps libres, il aime apprendre, lire, jouer et regarder des événements sportifs.
Adèleke Coker est un architecte de solutions globales avec AWS. Il travaille avec des clients du monde entier pour fournir des conseils et une assistance technique dans le déploiement de charges de travail de production à grande échelle sur AWS. Dans ses temps libres, il aime apprendre, lire, jouer et regarder des événements sportifs.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/automatically-redact-pii-for-machine-learning-using-amazon-sagemaker-data-wrangler/

