Les agents d'IA générative sont capables de produire des réponses de type humain et de s'engager dans des conversations en langage naturel en orchestrant une chaîne d'appels à des modèles de base (FM) et à d'autres outils d'augmentation basés sur les entrées de l'utilisateur. Au lieu de se contenter de remplir des intentions prédéfinies via un arbre de décision statique, les agents sont autonomes dans le contexte de leur suite d'outils disponibles. Socle amazonien est un service entièrement géré qui met à disposition les principaux FM des sociétés d'IA via une API ainsi que des outils de développement pour aider à créer et à faire évoluer des applications d'IA génératives.
Dans cet article, nous montrons comment créer un agent de services financiers génératif basé sur l'IA optimisé par Amazon Bedrock. L'agent peut aider les utilisateurs à trouver les informations de leur compte, à remplir une demande de prêt ou à répondre à des questions en langage naturel tout en citant également les sources des réponses fournies. Cette solution est destinée à servir de rampe de lancement permettant aux développeurs de créer leurs propres agents conversationnels personnalisés pour diverses applications, telles que les travailleurs virtuels et les systèmes de support client. Le code de la solution et les ressources de déploiement se trouvent dans le GitHub référentiel.
Amazon Lex fournit l'interface de compréhension du langage naturel (NLU) et de traitement du langage naturel (NLP) pour l'open source Agent conversationnel LangChain intégré dans un AWS Amplifier site web. L'agent est équipé d'outils qui incluent un Anthropic Claude 2.1 FM hébergé sur Amazon Bedrock et des données clients synthétiques stockées sur Amazon DynamoDB ainsi que Amazone Kendra pour offrir les fonctionnalités suivantes :
- Apporter des réponses personnalisées – Interrogez DynamoDB pour obtenir des informations sur le compte client, telles que les détails du résumé de l'hypothèque, le solde dû et la prochaine date de paiement.
- Accéder aux connaissances générales – Exploitez la logique de raisonnement de l'agent en tandem avec les grandes quantités de données utilisées pour pré-entraîner les différents FM fournis via Amazon Bedrock afin de produire des réponses à toute invite client.
- Organisez des réponses avisées – Informer les réponses des agents à l'aide d'un index Amazon Kendra configuré avec des sources de données faisant autorité : documents clients stockés dans Service de stockage simple Amazon (Amazon S3) et Robot d'exploration Web Amazon Kendra configuré pour le site Web du client
Vue d'ensemble de la solution
Enregistrement de démonstration
L'enregistrement de démonstration suivant met en évidence les fonctionnalités de l'agent et les détails techniques de mise en œuvre.
Architecture de la solution
Le diagramme suivant illustre l'architecture de la solution.
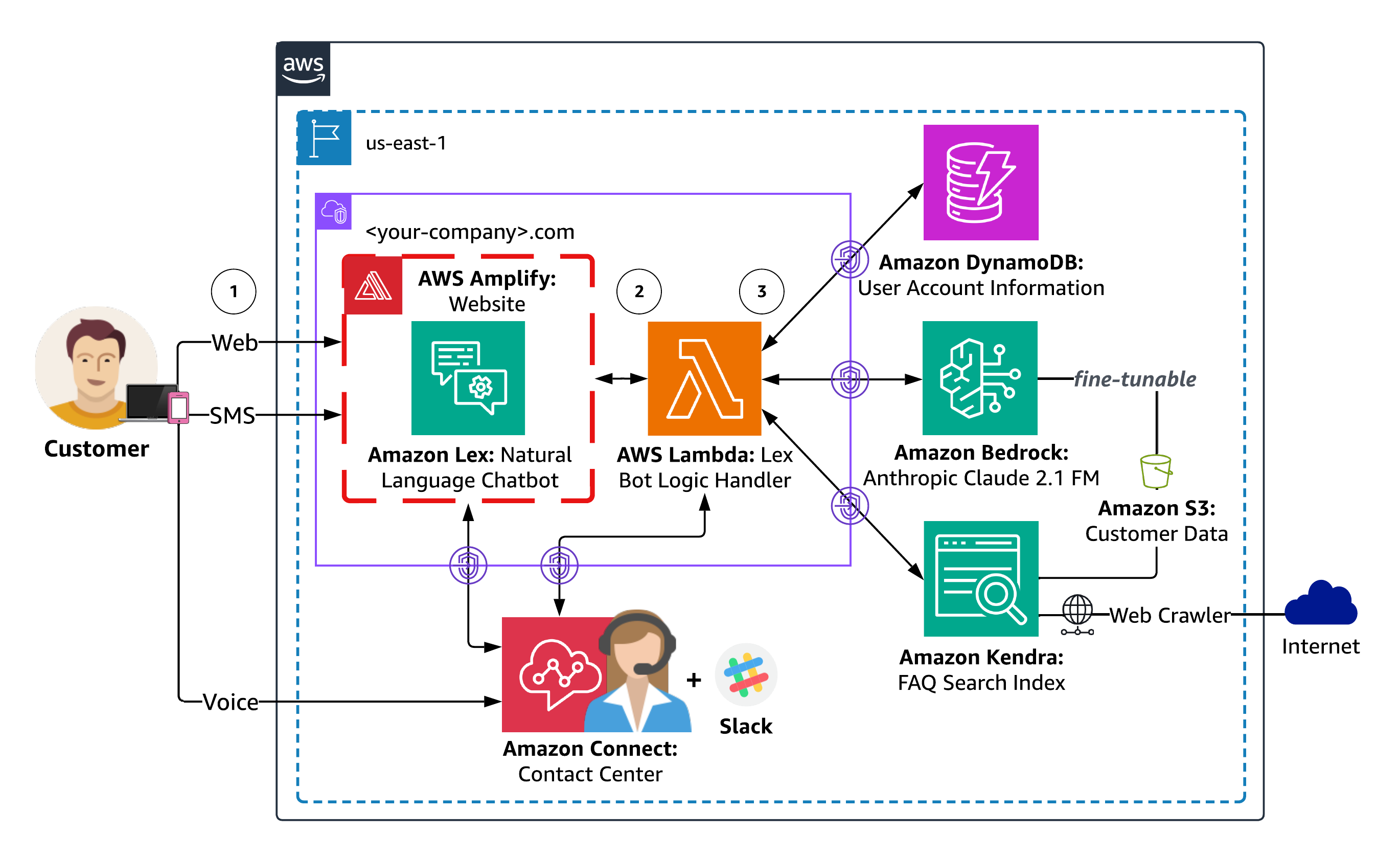
Diagramme 1 : Présentation de l'architecture de la solution
Le workflow de réponse de l'agent comprend les étapes suivantes :
- Les utilisateurs dialoguent en langage naturel avec l'agent via leur choix de canaux Web, SMS ou vocaux. Le canal Web comprend un site Web hébergé par Amplify avec un chatbot intégré Amazon Lex pour un client fictif. Les canaux SMS et vocaux peuvent être configurés en option à l'aide de Connexion Amazon ainsi que intégrations de messagerie pour Amazon Lex. Chaque demande d'utilisateur est traitée par Amazon Lex pour déterminer l'intention de l'utilisateur via un processus appelé reconnaissance d'intention, qui implique l'analyse et l'interprétation de la saisie de l'utilisateur (texte ou parole) pour comprendre l'action ou l'objectif prévu de l'utilisateur.
- Amazon Lex invoque alors un AWS Lambda gestionnaire pour la réalisation de l’intention de l’utilisateur. La fonction Lambda associée au chatbot Amazon Lex contient la logique et les règles métier nécessaires pour traiter l'intention de l'utilisateur. Lambda effectue des actions spécifiques ou récupère des informations en fonction des entrées de l'utilisateur, prend des décisions et génère des réponses appropriées.
- Lambda instrumente la logique de l'agent de services financiers en tant qu'agent conversationnel LangChain qui peut accéder aux données spécifiques au client stockées sur DynamoDB, organiser des réponses avisées à l'aide de vos documents et pages Web indexés par Amazon Kendra et fournir des réponses de connaissances générales via FM sur Amazon Bedrock. Les réponses générées par Amazon Kendra incluent l'attribution de la source, démontrant comment vous pouvez fournir des informations contextuelles supplémentaires à l'agent via Récupération Génération Augmentée (CHIFFON). RAG vous permet d’améliorer la capacité de votre agent à générer des réponses plus précises et contextuellement pertinentes en utilisant vos propres données.
Architecture des agents
Le diagramme suivant illustre l'architecture de l'agent.
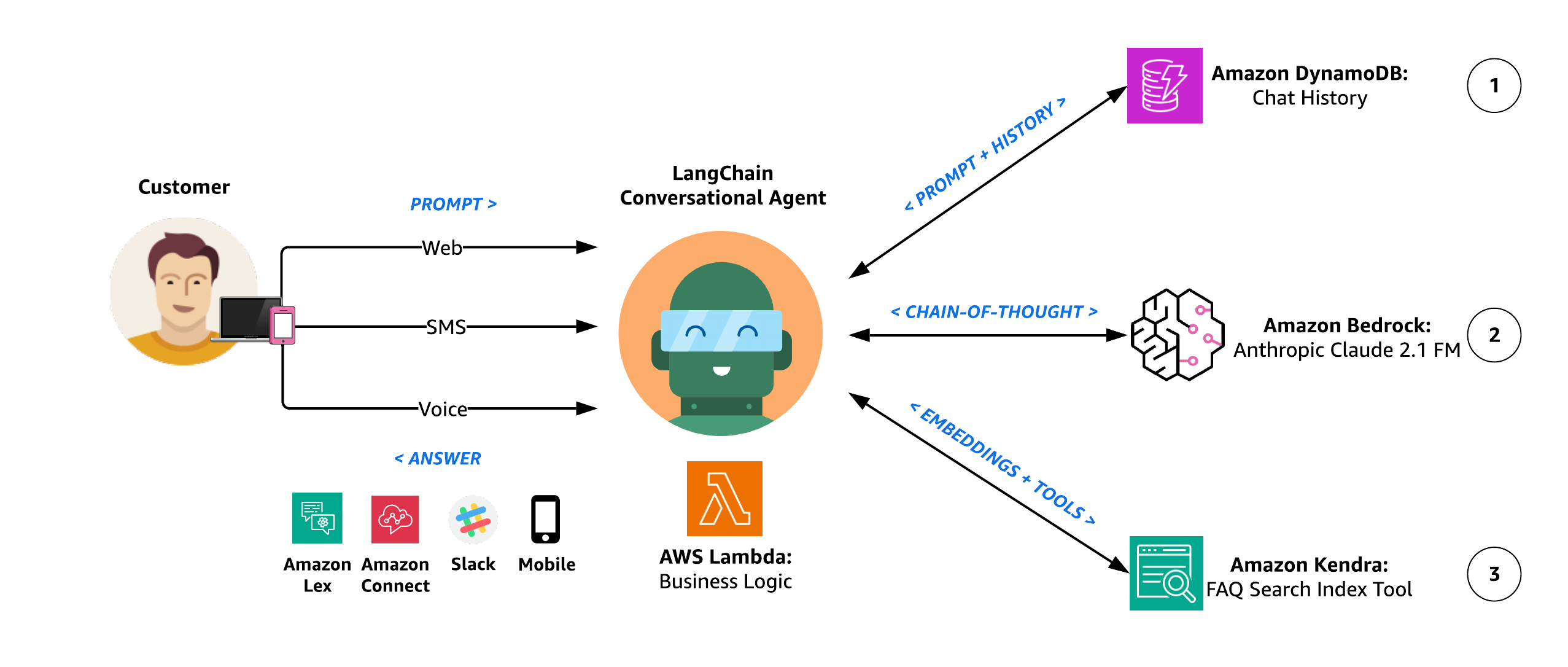
Diagramme 2 : Architecture de l'agent conversationnel LangChain
Le workflow de raisonnement de l’agent comprend les étapes suivantes :
- L'agent conversationnel LangChain intègre une mémoire de conversation afin de pouvoir répondre à plusieurs requêtes avec génération contextuelle. Cette mémoire permet à l'agent de fournir des réponses qui tiennent compte du contexte de la conversation en cours. Ceci est réalisé grâce à la génération contextuelle, où l'agent génère des réponses pertinentes et contextuellement appropriées en fonction des informations dont il s'est souvenu lors de la conversation. En termes plus simples, l'agent se souvient de ce qui a été dit précédemment et utilise ces informations pour répondre à plusieurs questions d'une manière qui a du sens dans la discussion en cours. Notre agent utilise Classe d'historique des messages de discussion DynamoDB de LangChain comme tampon de mémoire de conversation afin de pouvoir rappeler les interactions passées et améliorer l'expérience utilisateur avec des réponses plus significatives et contextuelles.
- L'agent utilise Anthropic Claude 2.1 sur Amazon Bedrock pour effectuer la tâche souhaitée via une série de saisies de texte soigneusement auto-générées appelées instructions. L’objectif principal de l’ingénierie rapide est d’obtenir des réponses spécifiques et précises de la part du FM. Différentes techniques d’ingénierie rapide incluent :
- Coup zéro – Une seule question est présentée au modèle sans aucun indice supplémentaire. Le modèle est censé générer une réponse basée uniquement sur la question posée.
- Peu de coups – Un ensemble d’exemples de questions et leurs réponses correspondantes sont inclus avant la question proprement dite. En exposant le modèle à ces exemples, il apprend à réagir de la même manière.
- Chaîne de pensée – Un style spécifique d'invite en quelques étapes où l'invite est conçue pour contenir une série d'étapes de raisonnement intermédiaires, guidant le modèle à travers un processus de réflexion logique, conduisant finalement à la réponse souhaitée.
Notre agent utilise un raisonnement en chaîne de pensée en exécutant un ensemble d'actions dès réception d'une demande. Suite à chaque action, l’agent entre dans l’étape d’observation, où il exprime une pensée. Si une réponse finale n’est pas encore obtenue, l’agent itère, sélectionnant différentes actions pour progresser vers la réponse finale. Voir l'exemple de code suivant :
Pensée : Dois-je utiliser un outil ? Oui
Action : L'action à entreprendre
Entrée d'action : l'entrée de l'action
Observation : Le résultat de l'action
Pensée : Dois-je utiliser un outil ? Non
Agent FSI : [réponse et documents sources]
- Dans le cadre des différents cheminements de raisonnement et des choix d'auto-évaluation de l'agent pour décider du prochain plan d'action, il a la capacité d'accéder à des sources de données synthétiques sur les clients via un Outil de récupération d'index Amazon Kendra. À l'aide d'Amazon Kendra, l'agent effectue une recherche contextuelle sur un large éventail de types de contenu, notamment des documents, des FAQ, des bases de connaissances, des manuels et des sites Web. Pour plus de détails sur les sources de données prises en charge, reportez-vous à Les sources de données. L'agent a le pouvoir d'utiliser cet outil pour fournir des réponses avisées aux invites des utilisateurs qui doivent être répondues à l'aide d'une bibliothèque de connaissances faisant autorité et fournie par le client, au lieu du corpus de connaissances plus générales utilisé pour pré-entraîner Amazon Bedrock FM.
Guide de déploiement
Dans les sections suivantes, nous discutons des étapes clés du déploiement de la solution, y compris le pré-déploiement et le post-déploiement.
Pré-déploiement
Avant de déployer la solution, vous devez créer votre propre version forkée du référentiel de solution avec un webhook sécurisé par jeton pour automatiser le déploiement continu de votre site Web Amplify. La configuration d'Amplify pointe vers un référentiel source GitHub à partir duquel l'interface de notre site Web est construite.
Fork et clone exemple-d'agent-ai-amazon-bedrock-langchain-generative dépôt
- Pour contrôler le code source qui crée votre site Web Amplify, suivez les instructions dans Forker un dépôt pour créer le référentiel generative-ai-amazon-bedrock-langchain-agent-example. Cela crée une copie du référentiel déconnectée de la base de code d'origine, afin que vous puissiez apporter les modifications appropriées.
- Veuillez noter l'URL de votre référentiel forké à utiliser pour cloner le référentiel à l'étape suivante et pour configurer la variable d'environnement GITHUB_PAT utilisée dans le script d'automatisation du déploiement de la solution.
- Clonez votre dépôt forké à l'aide de la commande git clone :
Créer un jeton d'accès personnel GitHub
Le site Web hébergé par Amplify utilise un Jeton d'accès personnel GitHub (PAT) comme jeton OAuth pour le contrôle de source tiers. Le jeton OAuth est utilisé pour créer un webhook et une clé de déploiement en lecture seule à l'aide du clonage SSH.
- Pour créer votre PAT, suivez les instructions dans Création d'un jeton d'accès personnel (classique). Vous préférerez peut-être utiliser un Application GitHub pour accéder à des ressources au nom d’une organisation ou pour des intégrations de longue durée.
- Prenez note de votre PAT avant de fermer votre navigateur : vous l'utiliserez pour configurer la variable d'environnement GITHUB_PAT utilisée dans le script d'automatisation du déploiement de la solution. Le script publiera votre PAT sur AWS Secrets Manager en utilisant Interface de ligne de commande AWS (AWS CLI) et le nom secret seront utilisés comme GitHubTokenSecretName AWS CloudFormation paramètre.
Déploiement
Le script d'automatisation du déploiement de la solution utilise le modèle CloudFormation paramétré, GenAI-FSI-Agent.yml, pour automatiser le provisionnement des ressources de solution suivantes :
- Un site Web Amplify pour simuler votre environnement front-end.
- Un bot Amazon Lex configuré via un package de déploiement d'importation de bot.
- Quatre tables DynamoDB :
- Table des comptes utilisateur en attente – Enregistre les transactions en attente (par exemple, les demandes de prêt).
- Table de comptes utilisateur existants – Contient des informations sur le compte utilisateur (par exemple, un résumé du compte hypothécaire).
- ConversationIndexTable – Suit l’état de la conversation.
- Table de conversation – Stocke l’historique des conversations.
- Un compartiment S3 qui contient le gestionnaire d'agent Lambda, le chargeur de données Lambda et les packages de déploiement Amazon Lex, ainsi qu'une FAQ client et des exemples de documents de demande de prêt hypothécaire.
- Deux fonctions Lambda :
- Gestionnaire d'agents – Contient la logique de l’agent conversationnel LangChain qui peut utiliser intelligemment une variété d’outils basés sur les entrées de l’utilisateur.
- Chargeur de données – Charge des exemples de données de compte client dans UserExistingAccountsTable et est invoqué en tant que ressource CloudFormation personnalisée lors de la création de la pile.
- Une couche Lambda pour les bibliothèques Amazon Bedrock Boto3, LangChain et pdfrw. La couche fournit à la bibliothèque FM de LangChain un modèle Amazon Bedrock comme FM sous-jacent et fournit pdfrw comme bibliothèque PDF open source pour créer et modifier des fichiers PDF.
- Un index Amazon Kendra qui fournit un index consultable d'informations faisant autorité sur les clients, notamment des documents, des FAQ, des bases de connaissances, des manuels, des sites Web, etc.
- Deux sources de données Amazon Kendra :
- Amazon S3 – Héberge un exemple de document FAQ client.
- Robot d'exploration Web Amazon Kendra – Configuré avec un domaine racine qui émule le site Web spécifique au client (par exemple, .com).
- Gestion des identités et des accès AWS (IAM) pour les ressources précédentes.
AWS CloudFormation préremplit les paramètres de pile avec les valeurs par défaut fournies dans le modèle. Pour fournir des valeurs d'entrée alternatives, vous pouvez spécifier des paramètres en tant que variables d'environnement référencées dans les paires `ParameterKey=,ParameterValue=` dans la commande `aws cloudformation create-stack` du script shell suivant.
- Avant d'exécuter le script shell, accédez à votre version forkée du référentiel generative-ai-amazon-bedrock-langchain-agent-example comme répertoire de travail et modifiez les autorisations du script shell en exécutable :
- Définissez votre référentiel Amplify et les variables d'environnement GitHub PAT créées lors des étapes de pré-déploiement :
- Enfin, exécutez le script d'automatisation du déploiement de la solution pour déployer les ressources de la solution, y compris les GenAI-FSI-Agent.yml Pile CloudFormation :
source ./create-stack.sh
Script d'automatisation du déploiement de solutions
Le précédent source ./create-stack.sh shell La commande exécute les commandes AWS CLI suivantes pour déployer la pile de solutions :
Post-déploiement
Dans cette section, nous discutons des étapes post-déploiement pour le lancement d’une application frontale destinée à émuler l’application de production du client. L'agent de services financiers fonctionnera comme un assistant intégré dans l'exemple d'interface utilisateur Web.
Lancez une interface Web pour votre chatbot
La Interface utilisateur Web d'Amazon Lex, également connu sous le nom d'interface utilisateur du chatbot, vous permet de provisionner rapidement un client Web complet pour les chatbots Amazon Lex. L'interface utilisateur s'intègre à Amazon Lex pour produire un plug-in JavaScript qui intégrera un widget de discussion alimenté par Amazon Lex dans votre application Web existante. Dans ce cas, nous utilisons l'interface utilisateur Web pour émuler une application Web client existante avec un chatbot Amazon Lex intégré. Effectuez les étapes suivantes :
- Suivez les instructions pour déployer la pile CloudFormation de l'interface utilisateur Web Amazon Lex.
- Sur la console AWS CloudFormation, accédez au dossier de la pile. Sortie et localisez la valeur de
SnippetUrl.

Figure 1 : Amazon CloudFormation génère l'URL de l'extrait de l'interface utilisateur Web Lex
- Copiez l'extrait Iframe de l'interface utilisateur Web, qui ressemblera au format ci-dessous Ajout de l'interface utilisateur ChatBot à votre site Web en tant qu'Iframe.

Figure 2 : Extrait Iframe de l'interface utilisateur Web Lex
- Modifiez votre version forkée du référentiel source Amplify GitHub en ajoutant le plugin JavaScript de votre interface utilisateur Web à la section intitulée
<-- Paste your Lex Web UI JavaScript plugin here -->pour chacun des fichiers HTML sous le répertoire frontal:index.html,contact.htmlet uneabout.html.

Figure 3 : Interface d'extrait d'extrait de l'interface utilisateur Web Lex
Amplify fournit un pipeline de création et de publication automatisé qui se déclenche en fonction des nouvelles validations dans votre référentiel forké et publie la nouvelle version de votre site Web sur votre domaine Amplify. Vous pouvez afficher l'état du déploiement sur la console Amplify.

Figure 4 : État du pipeline AWS Amplify
Accéder au site Amplify
Une fois le plug-in JavaScript de votre interface utilisateur Web Amazon Lex en place, vous êtes maintenant prêt à lancer votre site Web de démonstration Amplify.
- Pour accéder au domaine de votre site Web, accédez à la pile CloudFormation. Sortie et localisez l'URL du domaine Amplify. Vous pouvez également utiliser la commande suivante :
- Après avoir accédé à l'URL de votre domaine Amplify, vous pouvez procéder aux tests et à la validation.

Figure 5 : Frontend AWS Amplify
Test et validation
La procédure de test suivante vise à vérifier que l'agent identifie et comprend correctement les intentions des utilisateurs pour accéder aux données client (telles que les informations de compte), exécuter les flux de travail de l'entreprise via des intentions prédéfinies (telles que remplir une demande de prêt) et répondre aux requêtes générales, telles que le Exemples d'invites suivants :
- Pourquoi devrais-je utiliser ?
- Dans quelle mesure leurs tarifs sont-ils compétitifs ?
- Quel type de crédit immobilier dois-je utiliser ?
- Quelles sont les tendances actuelles en matière de crédit immobilier ?
- De combien ai-je besoin d’économiser pour un acompte ?
- Quels autres frais vais-je payer à la clôture ?
L'exactitude des réponses est déterminée en évaluant la pertinence, la cohérence et la nature humaine des réponses générées par le substrat rocheux amazonien fourni par Anthropic Claude 2.1 FM. Les liens sources fournis avec chaque réponse (par exemple, .com basé sur la configuration d'Amazon Kendra Web Crawler) doivent également être confirmés comme étant crédibles.
Apporter des réponses personnalisées
Vérifiez que l'agent accède et utilise avec succès les informations client pertinentes dans DynamoDB pour adapter les réponses spécifiques à l'utilisateur.

Figure 6 : Réponse personnalisée
Notez que l'utilisation de l'authentification par code PIN au sein de l'agent est uniquement à des fins de démonstration et ne doit être utilisée dans aucune implémentation de production.
Organisez des réponses avisées
Vérifiez que les questions d'opinion reçoivent des réponses crédibles de la part de l'agent qui recherche correctement des réponses basées sur des documents clients faisant autorité et des pages Web indexées par Amazon Kendra.
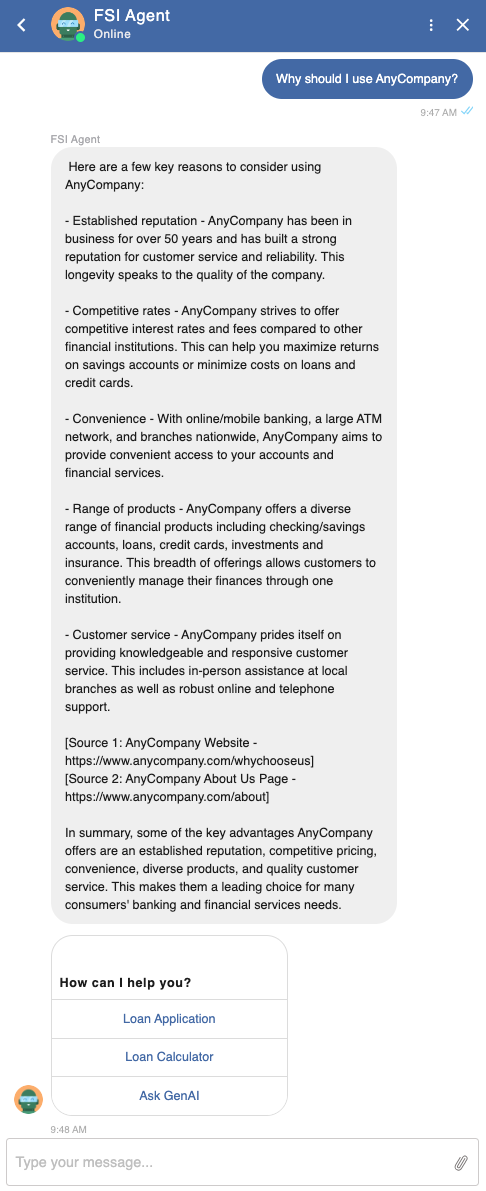
Figure 7 : Réponse avisée du RAG
Générer du contexte
Déterminez la capacité de l’agent à fournir des réponses contextuellement pertinentes en fonction de l’historique des discussions précédentes.

Figure 8 : Réponse de génération contextuelle
Accéder aux connaissances générales
Confirmez l'accès de l'agent aux informations de connaissances générales pour les requêtes non spécifiques au client et sans opinion qui nécessitent des réponses précises et cohérentes basées sur les données de formation Amazon Bedrock FM et RAG.

Figure 9 : Réponse des connaissances générales
Exécuter des intentions prédéfinies
Assurez-vous que l'agent interprète correctement et répond de manière conversationnelle aux invites des utilisateurs qui sont destinées à être acheminées vers des intentions prédéfinies, telles que remplir une demande de prêt dans le cadre d'un flux de travail commercial.

Figure 10 : Réponse intentionnelle prédéfinie
Ce qui suit est le document de demande de prêt résultant, complété via le flux conversationnel.

Figure 11 : Demande de prêt résultante
La fonctionnalité de support multicanal peut être testée en conjonction avec les mesures d'évaluation précédentes sur les canaux Web, SMS et vocaux. Pour plus d'informations sur l'intégration du chatbot avec d'autres services, reportez-vous à Intégration d'un bot Amazon Lex V2 avec Twilio SMS ainsi que Ajouter un robot Amazon Lex à Amazon Connect.
Nettoyer
Pour éviter des frais sur votre compte AWS, nettoyez les ressources provisionnées par la solution.
- Révoquez le jeton d'accès personnel GitHub. Les PAT GitHub sont configurés avec une valeur d'expiration. Si vous voulez vous assurer que votre PAT ne peut pas être utilisé pour un accès par programme à votre référentiel Amplify GitHub avant qu'il n'atteigne son expiration, vous pouvez révoquer le PAT en suivant les instructions Instructions du dépôt GitHub.
- Supprimez la pile GenAI-FSI-Agent.yml CloudFormation et les autres ressources de solution à l'aide du script d'automatisation de suppression de solution. Les commandes suivantes utilisent le nom de pile par défaut. Si vous avez personnalisé le nom de la pile, ajustez les commandes en conséquence.
# export STACK_NAME=<YOUR-STACK-NAME>./delete-stack.sh
Script d'automatisation de la suppression de solution
La
delete-stack.sh shellLe script supprime les ressources initialement provisionnées à l'aide du script d'automatisation du déploiement de la solution, y compris la pile GenAI-FSI-Agent.yml CloudFormation.
Considérations
Bien que la solution présentée dans cet article présente les capacités d'un agent de services financiers génératif alimenté par Amazon Bedrock, il est essentiel de reconnaître que cette solution n'est pas prête pour la production. Il s'agit plutôt d'un exemple illustratif pour les développeurs souhaitant créer des agents conversationnels personnalisés pour diverses applications telles que les travailleurs virtuels et les systèmes de support client. Le cheminement d’un développeur vers la production serait itératif sur cet exemple de solution avec les considérations suivantes.
Sécurité et confidentialité
Garantissez la sécurité des données et la confidentialité des utilisateurs tout au long du processus de mise en œuvre. Mettez en œuvre des contrôles d’accès et des mécanismes de cryptage appropriés pour protéger les informations sensibles. Des solutions telles que l'agent de services financiers à IA générative bénéficieront de données qui ne sont pas encore disponibles pour le FM sous-jacent, ce qui signifie souvent que vous souhaiterez utiliser vos propres données privées pour une plus grande avancée en matière de capacités. Tenez compte des bonnes pratiques suivantes :
- Gardez-le secret, gardez-le en sécurité – Vous souhaiterez que ces données restent entièrement protégées, sécurisées et privées pendant le processus de génération, et vous souhaiterez contrôler la manière dont ces données sont partagées et utilisées.
- Établir des garde-fous d’utilisation – Comprendre comment les données sont utilisées par un service avant de les mettre à disposition de vos équipes. Créez et distribuez les règles indiquant quelles données peuvent être utilisées avec quel service. Expliquez-les clairement à vos équipes afin qu'elles puissent agir rapidement et prototyper en toute sécurité.
- Impliquez le service juridique, le plus tôt possible – Demandez à vos équipes juridiques d’examiner les conditions générales et les fiches de service des services que vous envisagez d’utiliser avant de commencer à transmettre des données sensibles par leur intermédiaire. Vos partenaires juridiques n’ont jamais été aussi importants qu’aujourd’hui.
À titre d'exemple de la façon dont nous envisageons cela chez AWS avec Amazon Bedrock : toutes les données sont cryptées et ne quittent pas votre VPC, et Amazon Bedrock crée une copie séparée du FM de base qui n'est accessible qu'au client, et ajuste ou entraîne cette copie privée du modèle.
Test d'acceptation des utilisateurs
Effectuez des tests d'acceptation des utilisateurs (UAT) avec de vrais utilisateurs pour évaluer les performances, la convivialité et la satisfaction de l'agent de services financiers génératif d'IA. Recueillez les commentaires et apportez les améliorations nécessaires en fonction des commentaires des utilisateurs.
Déploiement et surveillance
Déployez l'agent entièrement testé sur AWS et mettez en œuvre la surveillance et la journalisation pour suivre ses performances, identifier les problèmes et optimiser le système si nécessaire. Fonctionnalités de surveillance et de dépannage Lambda sont activés par défaut pour le gestionnaire Lambda de l'agent.
Maintenance et mises à jour
Mettez régulièrement à jour l'agent avec les dernières versions et données FM pour améliorer sa précision et son efficacité. Surveillez les données spécifiques au client dans DynamoDB et synchronisez l'indexation de votre source de données Amazon Kendra si nécessaire.
Conclusion
Dans cet article, nous avons plongé dans le monde passionnant des agents d’IA générative et dans leur capacité à faciliter des interactions de type humain grâce à l’orchestration d’appels aux FM et à d’autres outils complémentaires. En suivant ce guide, vous pouvez utiliser Bedrock, LangChain et les ressources clients existantes pour mettre en œuvre, tester et valider avec succès un agent fiable qui fournit aux utilisateurs une assistance financière précise et personnalisée via des conversations en langage naturel.
Dans un prochain article, nous démontrerons comment la même fonctionnalité peut être fournie en utilisant une approche alternative avec Agents pour le substrat rocheux d’Amazonie ainsi que Base de connaissances pour Amazon Bedrock. Cette implémentation entièrement gérée par AWS explorera plus en détail comment offrir des capacités intelligentes d'automatisation et de recherche de données via des agents personnalisés qui transforment la façon dont les utilisateurs interagissent avec vos applications, rendant les interactions plus naturelles, efficaces et efficientes.
A propos de l'auteure
 Kyle T. Blocksom est un architecte de solutions senior chez AWS basé en Californie du Sud. La passion de Kyle est de rassembler les gens et de tirer parti de la technologie pour proposer des solutions que les clients adorent. En dehors du travail, il aime surfer, manger, lutter avec son chien et gâter sa nièce et son neveu.
Kyle T. Blocksom est un architecte de solutions senior chez AWS basé en Californie du Sud. La passion de Kyle est de rassembler les gens et de tirer parti de la technologie pour proposer des solutions que les clients adorent. En dehors du travail, il aime surfer, manger, lutter avec son chien et gâter sa nièce et son neveu.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/build-generative-ai-agents-with-amazon-bedrock-amazon-dynamodb-amazon-kendra-amazon-lex-and-langchain/

