Malgré l’adoption apparemment imparable des LLM dans tous les secteurs, ils constituent un élément d’un écosystème technologique plus large qui alimente la nouvelle vague de l’IA. De nombreux cas d'utilisation de l'IA conversationnelle nécessitent des LLM comme Llama 2, Flan T5 et Bloom pour répondre aux requêtes des utilisateurs. Ces modèles s'appuient sur des connaissances paramétriques pour répondre aux questions. Le modèle apprend ces connaissances pendant la formation et les code dans les paramètres du modèle. Afin de mettre à jour ces connaissances, nous devons recycler le LLM, ce qui prend beaucoup de temps et d'argent.
Heureusement, nous pouvons également utiliser les connaissances sources pour éclairer nos LLM. Les connaissances sources sont des informations introduites dans le LLM via une invite de saisie. Une approche populaire pour fournir des connaissances sources est la génération augmentée de récupération (RAG). À l'aide de RAG, nous récupérons les informations pertinentes à partir d'une source de données externe et introduisons ces informations dans le LLM.
Dans cet article de blog, nous explorerons comment déployer des LLM tels que Llama-2 à l'aide d'Amazon Sagemaker JumpStart et maintenir nos LLM à jour avec des informations pertinentes via la génération augmentée de récupération (RAG) à l'aide de la base de données vectorielles Pinecone afin d'empêcher l'hallucination de l'IA. .
Génération augmentée de récupération (RAG) dans Amazon SageMaker
Pinecone gérera le composant de récupération de RAG, mais vous avez besoin de deux composants supplémentaires critiques : quelque part pour exécuter l'inférence LLM et quelque part pour exécuter le modèle d'intégration.
Amazon SageMaker Studio est un environnement de développement intégré (IDE) qui fournit une interface visuelle Web unique dans laquelle vous pouvez accéder à des outils spécialement conçus pour effectuer tous les développements d'apprentissage automatique (ML). Il fournit SageMaker JumpStart, un hub de modèles où les utilisateurs peuvent localiser, prévisualiser et lancer un modèle particulier dans leur propre compte SageMaker. Il fournit des modèles propriétaires pré-entraînés, accessibles au public pour un large éventail de types de problèmes, y compris les modèles de base.
Amazon SageMaker Studio fournit l'environnement idéal pour développer des pipelines LLM compatibles RAG. Tout d'abord, à l'aide de la console AWS, accédez à Amazon SageMaker, créez un domaine SageMaker Studio et ouvrez un bloc-notes Jupyter Studio.
Pré-requis
Effectuez les étapes préalables suivantes :
- Configurez Amazon SageMaker Studio.
- Intégrez un domaine Amazon SageMaker.
- Inscrivez-vous à une base de données vectorielle Pinecone gratuite.
- Bibliothèques prérequises : SDK SageMaker Python, client Pinecone
Présentation de la solution
À l'aide du notebook SageMaker Studio, nous devons d'abord installer les bibliothèques prérequises :
Déployer un LLM
Dans cet article, nous discutons de deux approches pour déployer un LLM. La première passe par le HuggingFaceModel objet. Vous pouvez l'utiliser lors du déploiement de LLM (et de l'intégration de modèles) directement à partir du hub de modèles Hugging Face.
Par exemple, vous pouvez créer une configuration déployable pour le google/flan-t5-xl modèle comme indiqué dans la capture d'écran suivante :
Lors du déploiement de modèles directement depuis Hugging Face, initialisez le my_model_configuration avec ce qui suit:
- An
envconfig nous indique quel modèle nous voulons utiliser et pour quelle tâche. - Notre exécution SageMaker
rolenous donne les autorisations pour déployer notre modèle. - An
image_uriest une configuration d'image spécifiquement pour le déploiement de LLM à partir de Hugging Face.
Alternativement, SageMaker propose un ensemble de modèles directement compatibles avec un modèle plus simple. JumpStartModel objet. De nombreux LLM populaires comme Llama 2 sont pris en charge par ce modèle, qui peut être initialisé comme indiqué dans la capture d'écran suivante :
Pour les deux versions de my_model, déployez-les comme indiqué dans la capture d'écran suivante :
Avec notre point de terminaison LLM initialisé, vous pouvez commencer à interroger. Le format de nos requêtes peut varier (notamment entre les LLM conversationnels et non conversationnels), mais le processus est généralement le même. Pour le modèle Hugging Face, procédez comme suit :
Vous pouvez trouver la solution dans le GitHub référentiel.
La réponse générée que nous recevons ici n’a pas beaucoup de sens – c’est une hallucination.
Fournir un contexte supplémentaire au LLM
Llama 2 tente de répondre à notre question en se basant uniquement sur des connaissances paramétriques internes. De toute évidence, les paramètres du modèle ne stockent pas la connaissance des instances que nous pouvons utiliser avec une formation ponctuelle gérée dans SageMaker.
Pour répondre correctement à cette question, nous devons utiliser la connaissance source. Autrement dit, nous donnons des informations supplémentaires au LLM via l'invite. Ajoutons ces informations directement comme contexte supplémentaire pour le modèle.
Nous voyons maintenant la bonne réponse à la question ; c'était facile! Cependant, il est peu probable qu'un utilisateur insère des contextes dans ses invites, il connaîtrait déjà la réponse à sa question.
Plutôt que d'insérer manuellement un seul contexte, identifiez automatiquement les informations pertinentes à partir d'une base de données d'informations plus complète. Pour cela, vous aurez besoin de Retrieval Augmented Generation.
Récupération Génération Augmentée
Avec Retrieval Augmented Generation, vous pouvez encoder une base de données d'informations dans un espace vectoriel où la proximité entre les vecteurs représente leur pertinence/similitude sémantique. Avec cet espace vectoriel comme base de connaissances, vous pouvez convertir une nouvelle requête utilisateur, l'encoder dans le même espace vectoriel et récupérer les enregistrements les plus pertinents précédemment indexés.
Après avoir récupéré ces enregistrements pertinents, sélectionnez-en quelques-uns et incluez-les dans l'invite LLM comme contexte supplémentaire, fournissant ainsi au LLM des connaissances sources très pertinentes. Il s'agit d'un processus en deux étapes où :
- L'indexation remplit l'index vectoriel avec les informations d'un ensemble de données.
- La récupération a lieu lors d'une requête et c'est là que nous récupérons les informations pertinentes de l'index vectoriel.
Les deux étapes nécessitent un modèle d'intégration pour traduire notre texte brut lisible par l'homme en espace vectoriel sémantique. Utilisez le transformateur de phrases MiniLM très efficace de Hugging Face, comme indiqué dans la capture d'écran suivante. Ce modèle n'est pas un LLM et n'est donc pas initialisé de la même manière que notre modèle Llama 2.
Dans le hub_config, spécifiez l'ID du modèle comme indiqué dans la capture d'écran ci-dessus, mais pour la tâche, utilisez l'extraction de fonctionnalités car nous générons des intégrations vectorielles et non du texte comme notre LLM. Ensuite, initialisez la configuration du modèle avec HuggingFaceModel comme avant, mais cette fois sans l'image LLM et avec quelques paramètres de version.
Vous pouvez déployer à nouveau le modèle avec deploy, en utilisant la plus petite instance (CPU uniquement) de ml.t2.large. Le modèle MiniLM est petit, il ne nécessite donc pas beaucoup de mémoire et n'a pas besoin de GPU car il peut créer rapidement des intégrations même sur un CPU. Si vous préférez, vous pouvez exécuter le modèle plus rapidement sur GPU.
Pour créer des intégrations, utilisez le predict et transmettez une liste de contextes à encoder via la méthode inputs clé comme indiqué :
Deux contextes d'entrée sont transmis, renvoyant deux incorporations de vecteurs de contexte comme indiqué :
len(out)
2
La dimensionnalité d'intégration du modèle MiniLM est 384 ce qui signifie que chaque vecteur intégrant les sorties MiniLM doit avoir une dimensionnalité de 384. Cependant, en regardant la longueur de nos intégrations, vous verrez ce qui suit :
len(out[0]), len(out[1])
(8, 8)
Deux listes contiennent chacune huit éléments. MiniLM traite d'abord le texte lors d'une étape de tokenisation. Cette tokenisation transforme notre texte brut lisible par l'homme en une liste d'ID de jetons lisibles par modèle. Dans les fonctionnalités de sortie du modèle, vous pouvez voir les intégrations au niveau du jeton. l'un de ces plongements montre la dimensionnalité attendue de 384 comme montré:
len(out[0][0])
384
Transformez ces intégrations au niveau du jeton en intégrations au niveau du document en utilisant les valeurs moyennes pour chaque dimension vectorielle, comme indiqué dans l'illustration suivante.
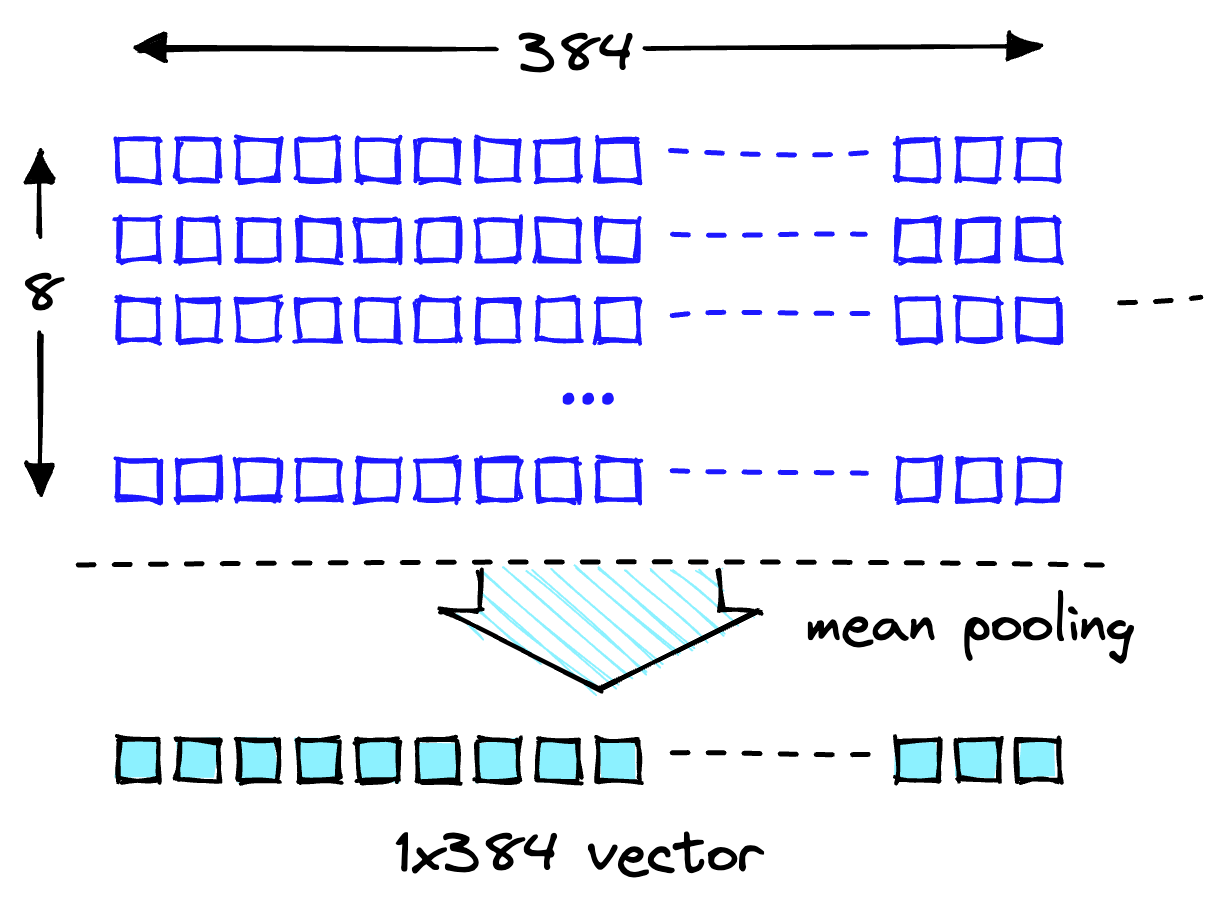
Opération de pooling moyen pour obtenir un seul vecteur de 384 dimensions.
Avec deux intégrations vectorielles à 384 dimensions, une pour chaque texte saisi. Pour nous faciliter la vie, regroupez le processus d'encodage dans une seule fonction, comme le montre la capture d'écran suivante :
Téléchargement de l'ensemble de données
Téléchargez la FAQ Amazon SageMaker comme base de connaissances pour obtenir les données contenant à la fois des colonnes de questions et de réponses.

Téléchargez la FAQ Amazon SageMaker
Lorsque vous effectuez la recherche, recherchez uniquement les réponses afin de pouvoir supprimer la colonne Question. Voir le carnet pour plus de détails.
Notre ensemble de données et le pipeline d'intégration sont prêts. Il ne nous manque plus qu’un endroit pour stocker ces intégrations.
Indexage
La base de données vectorielles Pinecone stocke les intégrations vectorielles et les recherche efficacement à grande échelle. Pour créer une base de données, vous aurez besoin d'une clé API gratuite de Pinecone.
Après vous être connecté à la base de données vectorielles Pinecone, créez un index vectoriel unique (similaire à une table dans les bases de données traditionnelles). Nommer l'index retrieval-augmentation-aws et aligner l'index dimension ainsi que metric paramètres avec ceux requis par le modèle d’intégration (MiniLM dans ce cas).
Pour commencer à insérer des données, exécutez ce qui suit :
Vous pouvez commencer à interroger l'index avec la question posée plus tôt dans cet article.
Le résultat ci-dessus montre que nous renvoyons des contextes pertinents pour nous aider à répondre à notre question. Depuis que nous top_k = 1, index.query a renvoyé le meilleur résultat à côté des métadonnées qui se lisent Managed Spot Training can be used with all instances supported in Amazon.
Augmenter l'invite
Utilisez les contextes récupérés pour augmenter l'invite et décider d'une quantité maximale de contexte à alimenter dans le LLM. Utilisez le 1000 caractères pour ajouter de manière itérative chaque contexte renvoyé à l'invite jusqu'à ce que vous dépassiez la longueur du contenu.
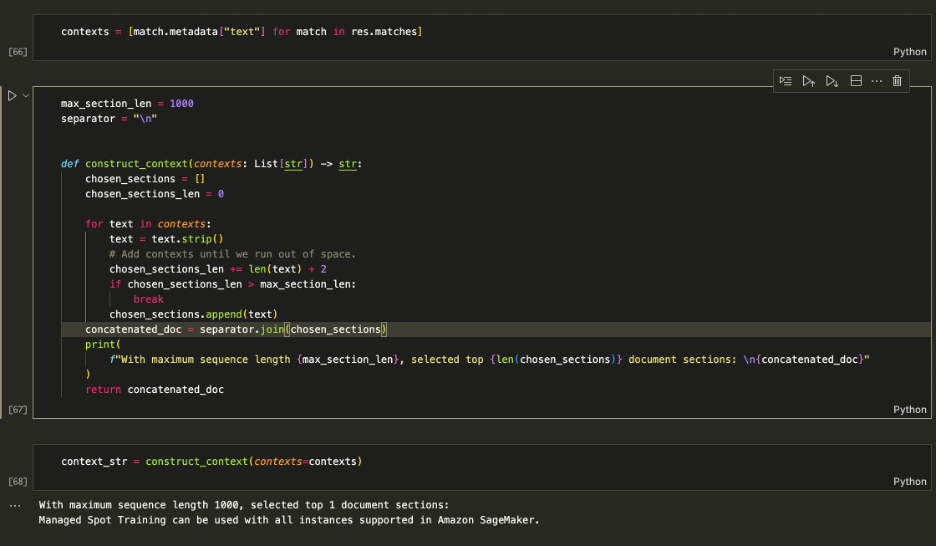
Augmenter l'invite
Nourrissez le context_str dans l'invite LLM, comme indiqué dans la capture d'écran suivante :
[Entrée] : Quelles instances puis-je utiliser avec la formation Spot gérée dans SageMaker ? [Sortie] : en fonction du contexte fourni, vous pouvez utiliser la formation Spot gérée avec toutes les instances prises en charge dans Amazon SageMaker. Par conséquent, la réponse est : Toutes les instances prises en charge dans Amazon SageMaker.
La logique fonctionne, alors regroupez-la dans une seule fonction pour garder les choses propres.
Vous pouvez désormais poser des questions comme celles présentées ci-dessous :
Nettoyer
Pour ne plus encourir de frais indésirables, supprimez le modèle et le point de terminaison.
Conclusion
Dans cet article, nous vous avons présenté RAG avec des LLM en libre accès sur SageMaker. Nous avons également montré comment déployer des modèles Amazon SageMaker Jumpstart avec Llama 2, des LLM Hugging Face avec Flan T5 et intégrer des modèles avec MiniLM.
Nous avons mis en œuvre un pipeline RAG complet de bout en bout en utilisant nos modèles en libre accès et un index vectoriel Pinecone. Grâce à cela, nous avons montré comment minimiser les hallucinations, maintenir les connaissances LLM à jour et, finalement, améliorer l'expérience utilisateur et la confiance dans nos systèmes.
Pour exécuter cet exemple par vous-même, clonez ce référentiel GitHub et suivez les étapes précédentes à l'aide du Carnet de questions-réponses sur GitHub.
À propos des auteurs
 Vedant Jaïn est un spécialiste senior de l'IA/ML, travaillant sur des initiatives stratégiques d'IA générative. Avant de rejoindre AWS, Vedant a occupé des postes spécialisés en ML/Data Science dans diverses sociétés telles que Databricks, Hortonworks (maintenant Cloudera) et JP Morgan Chase. En dehors de son travail, Vedant est passionné par la musique, l'escalade, l'utilisation de la science pour mener une vie pleine de sens et l'exploration des cuisines du monde entier.
Vedant Jaïn est un spécialiste senior de l'IA/ML, travaillant sur des initiatives stratégiques d'IA générative. Avant de rejoindre AWS, Vedant a occupé des postes spécialisés en ML/Data Science dans diverses sociétés telles que Databricks, Hortonworks (maintenant Cloudera) et JP Morgan Chase. En dehors de son travail, Vedant est passionné par la musique, l'escalade, l'utilisation de la science pour mener une vie pleine de sens et l'exploration des cuisines du monde entier.
 James Briggs est Staff Developer Advocate chez Pinecone, spécialisé dans la recherche de vecteurs et l'IA/ML. Il guide les développeurs et les entreprises dans le développement de leurs propres solutions GenAI grâce à la formation en ligne. Avant de rejoindre Pinecone, James a travaillé sur l'IA pour de petites startups technologiques et des sociétés financières établies. En dehors du travail, James a une passion pour les voyages et pour de nouvelles aventures, allant du surf et de la plongée sous-marine au Muay Thai et au BJJ.
James Briggs est Staff Developer Advocate chez Pinecone, spécialisé dans la recherche de vecteurs et l'IA/ML. Il guide les développeurs et les entreprises dans le développement de leurs propres solutions GenAI grâce à la formation en ligne. Avant de rejoindre Pinecone, James a travaillé sur l'IA pour de petites startups technologiques et des sociétés financières établies. En dehors du travail, James a une passion pour les voyages et pour de nouvelles aventures, allant du surf et de la plongée sous-marine au Muay Thai et au BJJ.
 Xin Huang est un scientifique appliqué senior pour Amazon SageMaker JumpStart et les algorithmes intégrés d'Amazon SageMaker. Il se concentre sur le développement d'algorithmes d'apprentissage automatique évolutifs. Ses intérêts de recherche portent sur le traitement du langage naturel, l'apprentissage en profondeur explicable sur des données tabulaires et l'analyse robuste du clustering spatio-temporel non paramétrique. Il a publié de nombreux articles dans les conférences ACL, ICDM, KDD et Royal Statistical Society: Series A.
Xin Huang est un scientifique appliqué senior pour Amazon SageMaker JumpStart et les algorithmes intégrés d'Amazon SageMaker. Il se concentre sur le développement d'algorithmes d'apprentissage automatique évolutifs. Ses intérêts de recherche portent sur le traitement du langage naturel, l'apprentissage en profondeur explicable sur des données tabulaires et l'analyse robuste du clustering spatio-temporel non paramétrique. Il a publié de nombreux articles dans les conférences ACL, ICDM, KDD et Royal Statistical Society: Series A.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/mitigate-hallucinations-through-retrieval-augmented-generation-using-pinecone-vector-database-llama-2-from-amazon-sagemaker-jumpstart/

