Les assistants conversationnels d’intelligence artificielle (IA) sont conçus pour fournir des réponses précises en temps réel grâce à un routage intelligent des requêtes vers les fonctions d’IA les plus appropriées. Avec les services d'IA générative AWS comme Socle amazonien, les développeurs peuvent créer des systèmes qui gèrent et répondent de manière experte aux demandes des utilisateurs. Amazon Bedrock est un service entièrement géré qui offre un choix de modèles de base (FM) hautes performances provenant de grandes sociétés d'IA telles que AI21 Labs, Anthropic, Cohere, Meta, Stability AI et Amazon, à l'aide d'une seule API, ainsi qu'un large ensemble de capacités dont vous avez besoin pour créer des applications d’IA générative avec sécurité, confidentialité et IA responsable.
Cet article évalue deux approches principales pour développer des assistants IA : utiliser des services gérés tels que Agents pour le substrat rocheux d’Amazonie, et en utilisant des technologies open source comme LangChaîne. Nous explorons les avantages et les défis de chacun, afin que vous puissiez choisir la voie la plus adaptée à vos besoins.
Qu'est-ce qu'un assistant IA ?
Un assistant IA est un système intelligent qui comprend les requêtes en langage naturel et interagit avec divers outils, sources de données et API pour effectuer des tâches ou récupérer des informations au nom de l'utilisateur. Les assistants IA efficaces possèdent les capacités clés suivantes :
- Traitement du langage naturel (NLP) et flux conversationnel
- Intégration de la base de connaissances et recherches sémantiques pour comprendre et récupérer des informations pertinentes en fonction des nuances du contexte de la conversation
- Exécuter des tâches, telles que des requêtes de base de données et des tâches personnalisées AWS Lambda fonctions
- Gérer les conversations spécialisées et les demandes des utilisateurs
Nous démontrons les avantages des assistants IA en utilisant comme exemple la gestion des appareils Internet des objets (IoT). Dans ce cas d’utilisation, l’IA peut aider les techniciens à gérer efficacement les machines grâce à des commandes qui récupèrent des données ou automatisent des tâches, rationalisant ainsi les opérations de fabrication.
Approche des agents pour Amazon Bedrock
Agents pour le substrat rocheux d’Amazonie vous permet de créer des applications d'IA génératives capables d'exécuter des tâches en plusieurs étapes sur les systèmes et les sources de données d'une entreprise. Il offre les fonctionnalités clés suivantes :
- Création automatique d'invites à partir d'instructions, de détails d'API et d'informations sur la source de données, ce qui permet d'économiser des semaines d'efforts d'ingénierie rapides
- Retrieval Augmented Generation (RAG) pour connecter en toute sécurité les agents aux sources de données d'une entreprise et fournir des réponses pertinentes
- Orchestration et exécution de tâches en plusieurs étapes en décomposant les requêtes en séquences logiques et en appelant les API nécessaires
- Visibilité sur le raisonnement de l'agent grâce à une trace de chaîne de pensée (CoT), permettant le dépannage et le pilotage du comportement du modèle
- Capacités d'ingénierie d'invite pour modifier le modèle d'invite généré automatiquement pour un contrôle amélioré sur les agents
Vous pouvez utiliser des agents pour Amazon Bedrock et Bases de connaissances pour Amazon Bedrock pour créer et déployer des assistants IA pour des cas d'utilisation de routage complexes. Ils offrent un avantage stratégique aux développeurs et aux organisations en simplifiant la gestion de l’infrastructure, en améliorant l’évolutivité, en améliorant la sécurité et en réduisant les tâches lourdes indifférenciées. Ils permettent également un code de couche application plus simple car la logique de routage, la vectorisation et la mémoire sont entièrement gérées.
Vue d'ensemble de la solution
Cette solution introduit un assistant d'IA conversationnel adapté à la gestion et aux opérations des appareils IoT lors de l'utilisation de Claude v2.1 d'Anthropic sur Amazon Bedrock. La fonctionnalité principale de l'assistant IA est régie par un ensemble complet d'instructions, appelé invite du système, qui délimite ses capacités et ses domaines d’expertise. Ces conseils garantissent que l'assistant IA peut gérer un large éventail de tâches, de la gestion des informations sur les appareils à l'exécution de commandes opérationnelles.
Doté de ces capacités, comme détaillé dans l'invite du système, l'assistant IA suit un flux de travail structuré pour répondre aux questions des utilisateurs. La figure suivante fournit une représentation visuelle de ce flux de travail, illustrant chaque étape depuis l'interaction initiale de l'utilisateur jusqu'à la réponse finale.

Le workflow est composé des étapes suivantes :
- Le processus commence lorsqu'un utilisateur demande à l'assistant d'effectuer une tâche ; par exemple, demander le maximum de points de données pour un appareil IoT spécifique
device_xxx. Cette saisie de texte est capturée et envoyée à l'assistant IA. - L'assistant IA interprète la saisie de texte de l'utilisateur. Il utilise l'historique des conversations fourni, les groupes d'action et les bases de connaissances pour comprendre le contexte et déterminer les tâches nécessaires.
- Une fois l'intention de l'utilisateur analysée et comprise, l'assistant IA définit les tâches. Ceci est basé sur les instructions qui sont interprétées par l'assistant selon l'invite du système et la saisie de l'utilisateur.
- Les tâches sont ensuite exécutées via une série d’appels API. Cela se fait en utilisant Réagir des invites, qui décomposent la tâche en une série d'étapes traitées séquentiellement :
- Pour les vérifications des métriques des appareils, nous utilisons le
check-device-metricsgroupe d'action, qui implique un appel d'API aux fonctions Lambda qui interrogent ensuite Amazone Athéna pour les données demandées. - Pour les actions directes sur l'appareil telles que démarrer, arrêter ou redémarrer, nous utilisons le
action-on-devicegroupe d'action, qui appelle une fonction Lambda. Cette fonction lance un processus qui envoie des commandes au périphérique IoT. Pour cet article, la fonction Lambda envoie des notifications en utilisant Service de messagerie simple Amazon (Amazon SES). - Nous utilisons les bases de connaissances pour Amazon Bedrock pour extraire des données historiques stockées sous forme d'intégrations dans le Service Amazon OpenSearch base de données vectorielles.
- Pour les vérifications des métriques des appareils, nous utilisons le
- Une fois les tâches terminées, la réponse finale est générée par Amazon Bedrock FM et renvoyée à l'utilisateur.
- Les agents pour Amazon Bedrock stockent automatiquement les informations à l'aide d'une session avec état pour maintenir la même conversation. L'état est supprimé après l'écoulement d'un délai d'inactivité configurable.
Aperçu technique
Le diagramme suivant illustre l'architecture permettant de déployer un assistant IA avec des agents pour Amazon Bedrock.
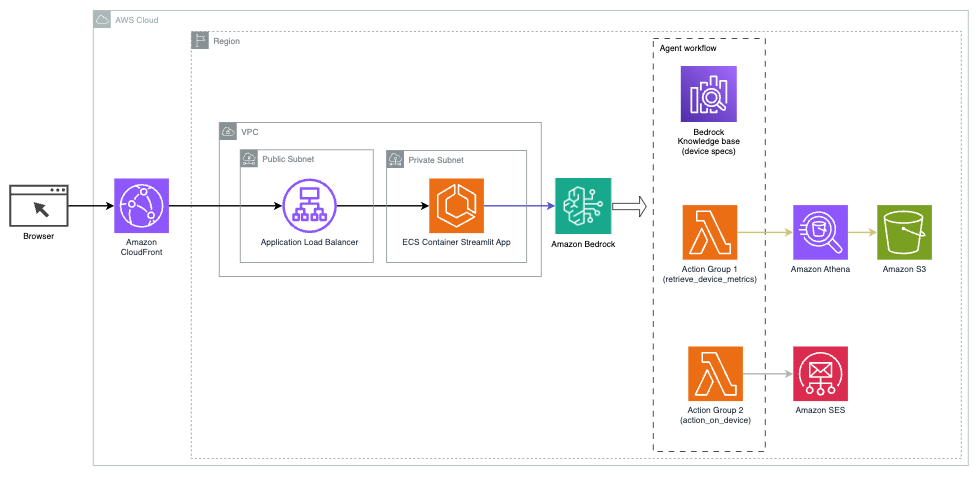
Il se compose des éléments clés suivants :
- Interface conversationnelle – L'interface conversationnelle utilise Streamlit, une bibliothèque Python open source qui simplifie la création d'applications Web personnalisées et visuellement attrayantes pour l'apprentissage automatique (ML) et la science des données. Il est hébergé sur Service de conteneur élastique Amazon (Amazon ECS) avec AWSFargate, et on y accède à l'aide d'un Application Load Balancer. Vous pouvez utiliser Fargate avec Amazon ECS pour exécuter conteneurs sans avoir à gérer des serveurs, des clusters ou des machines virtuelles.
- Agents pour le substrat rocheux d’Amazonie – Les agents pour Amazon Bedrock répondent aux requêtes des utilisateurs via une série d'étapes de raisonnement et d'actions correspondantes basées sur Invite Réagir:
- Bases de connaissances pour Amazon Bedrock – Les bases de connaissances pour Amazon Bedrock fournissent des informations entièrement gérées CHIFFON pour permettre à l'assistant IA d'accéder à vos données. Dans notre cas d'utilisation, nous avons téléchargé les spécifications de l'appareil dans un Service de stockage simple Amazon (Amazon S3). Il sert de source de données à la base de connaissances.
- Groupes d'action – Il s'agit de schémas API définis qui appellent des fonctions Lambda spécifiques pour interagir avec les appareils IoT et d'autres services AWS.
- Anthropic Claude v2.1 sur Amazon Bedrock – Ce modèle interprète les requêtes des utilisateurs et orchestre le flux des tâches.
- Intégrations Amazon Titan – Ce modèle sert de modèle d'intégration de texte, transformant le texte en langage naturel (des mots simples aux documents complexes) en vecteurs numériques. Cela active les capacités de recherche vectorielle, permettant au système de faire correspondre sémantiquement les requêtes des utilisateurs avec les entrées de la base de connaissances les plus pertinentes pour une recherche efficace.
La solution est intégrée aux services AWS tels que Lambda pour exécuter du code en réponse aux appels d'API, Athena pour interroger des ensembles de données, OpenSearch Service pour rechercher dans les bases de connaissances et Amazon S3 pour le stockage. Ces services fonctionnent ensemble pour offrir une expérience transparente pour la gestion des opérations des appareils IoT via des commandes en langage naturel.
Avantages
Cette solution offre les avantages suivants :
- Complexité de mise en œuvre :
- Moins de lignes de code sont nécessaires, car les agents pour Amazon Bedrock éliminent une grande partie de la complexité sous-jacente, réduisant ainsi les efforts de développement.
- La gestion des bases de données vectorielles comme OpenSearch Service est simplifiée, car les bases de connaissances pour Amazon Bedrock gèrent la vectorisation et le stockage.
- L'intégration avec divers services AWS est plus rationalisée grâce à des groupes d'actions prédéfinis
- Expérience développeur :
- La console Amazon Bedrock fournit une interface conviviale pour un développement, des tests et une analyse des causes profondes (RCA) rapides, améliorant ainsi l'expérience globale des développeurs.
- Agilité et flexibilité :
- Les agents pour Amazon Bedrock permettent des mises à niveau transparentes vers les FM les plus récents (tels que Claude 3.0) lorsqu'ils sont disponibles, afin que votre solution reste à jour avec les dernières avancées.
- Les quotas et limitations de service sont gérés par AWS, réduisant ainsi les frais de surveillance et de mise à l'échelle de l'infrastructure.
- Sécurité :
- Amazon Bedrock est un service entièrement géré, adhérant aux normes strictes de sécurité et de conformité d'AWS, simplifiant potentiellement les examens de sécurité de l'organisation.
Bien que les agents pour Amazon Bedrock offrent une solution rationalisée et gérée pour créer des applications d'IA conversationnelle, certaines organisations peuvent préférer une approche open source. Dans de tels cas, vous pouvez utiliser des frameworks comme LangChain, dont nous parlerons dans la section suivante.
Approche de routage dynamique LangChain
LangChain est un framework open source qui simplifie la création d'IA conversationnelle en permettant l'intégration de grands modèles de langage (LLM) et de capacités de routage dynamique. Avec LangChain Expression Language (LCEL), les développeurs peuvent définir le routage, qui vous permet de créer des chaînes non déterministes où la sortie d'une étape précédente définit l'étape suivante. Le routage contribue à fournir une structure et une cohérence dans les interactions avec les LLM.
Pour cet article, nous utilisons le même exemple que l'assistant IA pour la gestion des appareils IoT. Cependant, la principale différence est que nous devons gérer les invites du système séparément et traiter chaque chaîne comme une entité distincte. La chaîne de routage décide de la chaîne de destination en fonction des entrées de l'utilisateur. La décision est prise avec l'aide d'un LLM en transmettant l'invite du système, l'historique des discussions et la question de l'utilisateur.
Vue d'ensemble de la solution
Le diagramme suivant illustre le flux de travail de la solution de routage dynamique.

Le flux de travail comprend les étapes suivantes :
- L'utilisateur présente une question à l'assistant IA. Par exemple, « Quelles sont les métriques maximales pour l'appareil 1009 ? »
- Un LLM évalue chaque question ainsi que l'historique des discussions de la même session pour déterminer sa nature et à quel domaine elle relève (comme SQL, action, recherche ou SME). Le LLM classe l'entrée et la chaîne de routage LCEL prend cette entrée.
- La chaîne de routeurs sélectionne la chaîne de destination en fonction de l'entrée, et le LLM reçoit l'invite système suivante :
Le LLM évalue la question de l'utilisateur ainsi que l'historique des discussions pour déterminer la nature de la requête et le domaine auquel elle appartient. Le LLM classe ensuite l'entrée et génère une réponse JSON au format suivant :
La chaîne de routeurs utilise cette réponse JSON pour appeler la chaîne de destination correspondante. Il existe quatre chaînes de destination spécifiques à un sujet, chacune avec sa propre invite système :
- Les requêtes liées à SQL sont envoyées à la chaîne de destination SQL pour les interactions avec la base de données. Vous pouvez utiliser LCEL pour créer le Chaîne SQL.
- Les questions orientées vers l'action appellent la chaîne de destination Lambda personnalisée pour l'exécution des opérations. Avec LCEL, vous pouvez définir le vôtre fonction personnalisée; dans notre cas, il s'agit d'une fonction permettant d'exécuter une fonction Lambda prédéfinie pour envoyer un e-mail avec un ID d'appareil analysé. Un exemple de saisie utilisateur pourrait être « Arrêter le périphérique 1009 ».
- Les demandes axées sur la recherche sont transmises au CHIFFON chaîne de destination pour la recherche d’informations.
- Les questions liées aux PME sont adressées à la chaîne de destination PME/experts pour obtenir des informations spécialisées.
- Chaque chaîne de destination prend l'entrée et exécute les modèles ou fonctions nécessaires :
- La chaîne SQL utilise Athena pour exécuter des requêtes.
- La chaîne RAG utilise OpenSearch Service pour la recherche sémantique.
- La chaîne Lambda personnalisée exécute les fonctions Lambda pour les actions.
- La chaîne PME/experts fournit des informations en utilisant le modèle Amazon Bedrock.
- Les réponses de chaque chaîne de destination sont formulées en informations cohérentes par le LLM. Ces informations sont ensuite fournies à l'utilisateur, complétant ainsi le cycle de requête.
- Les entrées et les réponses de l'utilisateur sont stockées dans Amazon DynamoDB pour fournir un contexte au LLM pour la session en cours et à partir des interactions passées. La durée des informations persistantes dans DynamoDB est contrôlée par l'application.
Aperçu technique
Le schéma suivant illustre l'architecture de la solution de routage dynamique LangChain.
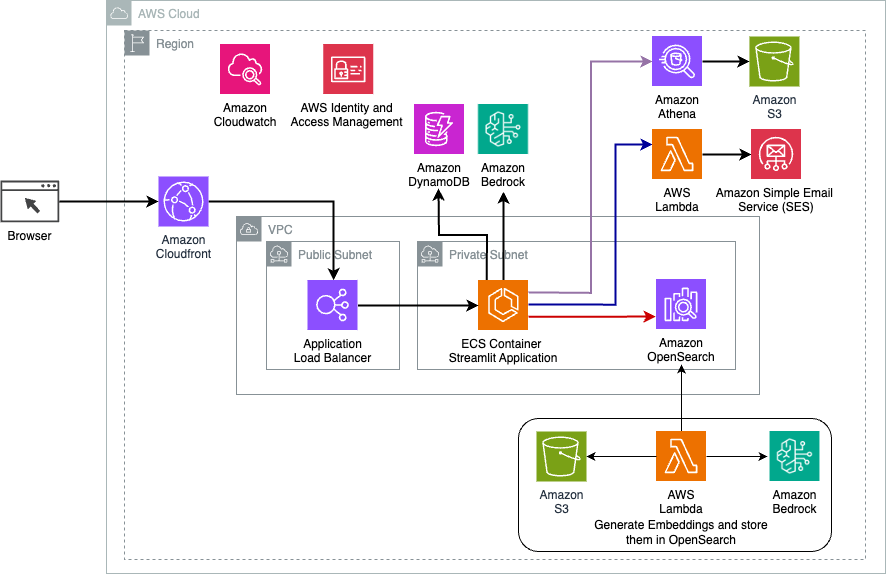
L'application Web est construite sur Streamlit hébergé sur Amazon ECS avec Fargate et est accessible à l'aide d'un Application Load Balancer. Nous utilisons Claude v2.1 d'Anthropic sur Amazon Bedrock comme LLM. L'application Web interagit avec le modèle à l'aide des bibliothèques LangChain. Il interagit également avec divers autres services AWS, tels qu'OpenSearch Service, Athena et DynamoDB, pour répondre aux besoins des utilisateurs finaux.
Avantages
Cette solution offre les avantages suivants :
- Complexité de mise en œuvre :
- Bien qu'il nécessite plus de code et de développement personnalisé, LangChain offre une plus grande flexibilité et un plus grand contrôle sur la logique de routage et l'intégration avec divers composants.
- La gestion de bases de données vectorielles comme OpenSearch Service nécessite des efforts d'installation et de configuration supplémentaires. Le processus de vectorisation est implémenté dans le code.
- L'intégration aux services AWS peut impliquer davantage de code et de configuration personnalisés.
- Expérience développeur :
- L'approche basée sur Python de LangChain et sa documentation complète peuvent intéresser les développeurs déjà familiers avec Python et les outils open source.
- Le développement et le débogage rapides peuvent nécessiter plus d'efforts manuels que l'utilisation de la console Amazon Bedrock.
- Agilité et flexibilité :
- LangChain prend en charge une large gamme de LLM, vous permettant de basculer entre différents modèles ou fournisseurs, favorisant ainsi la flexibilité.
- La nature open source de LangChain permet des améliorations et des personnalisations pilotées par la communauté.
- Sécurité :
- En tant que framework open source, LangChain peut nécessiter des examens de sécurité et des contrôles plus rigoureux au sein des organisations, ce qui pourrait potentiellement ajouter des frais généraux.
Conclusion
Les assistants d’IA conversationnelle sont des outils transformateurs permettant de rationaliser les opérations et d’améliorer l’expérience utilisateur. Cet article a exploré deux approches puissantes utilisant les services AWS : les agents gérés pour Amazon Bedrock et le routage dynamique flexible et open source LangChain. Le choix entre ces approches dépend des exigences de votre organisation, des préférences de développement et du niveau de personnalisation souhaité. Quel que soit le chemin emprunté, AWS vous permet de créer des assistants IA intelligents qui révolutionnent les interactions commerciales et clients.
Trouvez le code de la solution et les ressources de déploiement dans notre GitHub référentiel, où vous pouvez suivre les étapes détaillées de chaque approche d'IA conversationnelle.
À propos des auteurs
 Ameer Hakmé est un architecte de solutions AWS basé en Pennsylvanie. Il collabore avec des fournisseurs de logiciels indépendants (ISV) de la région du Nord-Est, les aidant à concevoir et à créer des plates-formes évolutives et modernes sur le cloud AWS. Expert en IA/ML et en IA générative, Ameer aide ses clients à libérer le potentiel de ces technologies de pointe. Dans ses temps libres, il aime conduire sa moto et passer du temps de qualité avec sa famille.
Ameer Hakmé est un architecte de solutions AWS basé en Pennsylvanie. Il collabore avec des fournisseurs de logiciels indépendants (ISV) de la région du Nord-Est, les aidant à concevoir et à créer des plates-formes évolutives et modernes sur le cloud AWS. Expert en IA/ML et en IA générative, Ameer aide ses clients à libérer le potentiel de ces technologies de pointe. Dans ses temps libres, il aime conduire sa moto et passer du temps de qualité avec sa famille.
 Sharon Lic est un architecte de solutions IA/ML chez Amazon Web Services basé à Boston, passionné par la conception et la création d'applications d'IA générative sur AWS. Elle collabore avec les clients pour tirer parti des services AWS AI/ML pour des solutions innovantes.
Sharon Lic est un architecte de solutions IA/ML chez Amazon Web Services basé à Boston, passionné par la conception et la création d'applications d'IA générative sur AWS. Elle collabore avec les clients pour tirer parti des services AWS AI/ML pour des solutions innovantes.
 Kawsar Kamal est un architecte de solutions senior chez Amazon Web Services avec plus de 15 ans d'expérience dans le domaine de l'automatisation et de la sécurité des infrastructures. Il aide les clients à concevoir et à créer des solutions DevSecOps et AI/ML évolutives dans le Cloud.
Kawsar Kamal est un architecte de solutions senior chez Amazon Web Services avec plus de 15 ans d'expérience dans le domaine de l'automatisation et de la sécurité des infrastructures. Il aide les clients à concevoir et à créer des solutions DevSecOps et AI/ML évolutives dans le Cloud.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/enhance-conversational-ai-with-advanced-routing-techniques-with-amazon-bedrock/

