Keskustelevan tekoälyn (AI) avustajat on suunniteltu tarjoamaan tarkkoja, reaaliaikaisia vastauksia reitittämällä kyselyt älykkäästi sopivimpiin tekoälytoimintoihin. AWS:n luovilla tekoälypalveluilla, kuten Amazonin kallioperä, kehittäjät voivat luoda järjestelmiä, jotka hallitsevat asiantuntevasti käyttäjien pyyntöjä ja vastaavat niihin. Amazon Bedrock on täysin hallittu palvelu, joka tarjoaa valikoiman tehokkaita perusmalleja (FM) johtavilta tekoälyyrityksiltä, kuten AI21 Labs, Anthropic, Cohere, Meta, Stability AI ja Amazon käyttämällä yhtä API-sovellusliittymää sekä laajan valikoiman ominaisuudet, joita tarvitset luodaksesi luovia tekoälysovelluksia turvallisuuden, yksityisyyden ja vastuullisen tekoälyn avulla.
Tässä viestissä arvioidaan kahta ensisijaista lähestymistapaa tekoälyassistenttien kehittämiseen: käyttämällä hallittuja palveluita, kuten Amazon Bedrockin edustajatja käyttää avoimen lähdekoodin teknologioita, kuten LangChain. Tutkimme jokaisen edut ja haasteet, jotta voit valita tarpeisiisi sopivimman tien.
Mikä on AI-avustaja?
Tekoälyassistentti on älykäs järjestelmä, joka ymmärtää luonnollisen kielen kyselyt ja on vuorovaikutuksessa erilaisten työkalujen, tietolähteiden ja API:iden kanssa suorittaakseen tehtäviä tai hakeakseen tietoja käyttäjän puolesta. Tehokkailla tekoälyavustajilla on seuraavat keskeiset ominaisuudet:
- Luonnollisen kielen käsittely (NLP) ja keskustelun kulku
- Tietokannan integrointi ja semanttiset haut merkityksellisten tietojen ymmärtämiseksi ja hakemiseksi keskustelukontekstin vivahteiden perusteella
- Suoritetaan tehtäviä, kuten tietokantakyselyitä ja mukautettuja AWS Lambda tehtävät
- Erikoiskeskustelujen ja käyttäjien pyyntöjen käsittely
Esittelemme tekoälyassistenttien edut esimerkiksi Internet of Things (IoT) -laitehallinnan avulla. Tässä käyttötapauksessa tekoäly voi auttaa teknikoita hallitsemaan koneita tehokkaasti komennoilla, jotka hakevat tietoja tai automatisoivat tehtäviä, mikä virtaviivaistaa tuotantoa.
Agents for Amazon Bedrock -lähestymistapa
Amazon Bedrockin edustajat avulla voit rakentaa generatiivisia tekoälysovelluksia, jotka voivat suorittaa monivaiheisia tehtäviä yrityksen järjestelmissä ja tietolähteissä. Se tarjoaa seuraavat keskeiset ominaisuudet:
- Automaattinen pikaluonti ohjeista, API-tiedoista ja tietolähdetiedoista, mikä säästää viikkojen nopeaa suunnittelutyötä
- Retrieval Augmented Generation (RAG), jonka avulla agentit voidaan yhdistää turvallisesti yrityksen tietolähteisiin ja tarjota asiaankuuluvia vastauksia
- Monivaiheisten tehtävien organisointi ja suorittaminen jakamalla pyynnöt loogisiin sarjoihin ja kutsumalla tarvittavia sovellusliittymiä
- Näkyvyys agentin päättelyyn ajatusketjun (CoT) jäljityksen avulla, mikä mahdollistaa vianetsinnän ja mallin käyttäytymisen ohjauksen
- Kehotuskehityskyky muokata automaattisesti luotua kehotemallia agenttien hallinnan tehostamiseksi
Voit käyttää Agents for Amazon Bedrock ja Amazon Bedrockin tietokannat rakentaa ja ottaa käyttöön tekoälyapureita monimutkaisiin reitityskäyttötapauksiin. Ne tarjoavat strategisen edun kehittäjille ja organisaatioille yksinkertaistamalla infrastruktuurin hallintaa, parantamalla skaalautuvuutta, parantamalla turvallisuutta ja vähentämällä eriyttämätöntä raskasta nostoa. Ne mahdollistavat myös yksinkertaisemman sovelluskerroksen koodin, koska reitityslogiikka, vektorointi ja muisti ovat täysin hallittuja.
Ratkaisun yleiskatsaus
Tämä ratkaisu esittelee keskusteluapulaisen tekoälyavustajan, joka on räätälöity IoT-laitteiden hallintaan ja toimintoihin käytettäessä Anthropicin Claude v2.1:tä Amazon Bedrockissa. AI-assistentin ydintoimintoja ohjaa kattava ohjesarja, joka tunnetaan nimellä a järjestelmäkehote, jossa määritellään sen valmiudet ja osaamisalueet. Nämä ohjeet varmistavat, että AI-avustaja pystyy käsittelemään monenlaisia tehtäviä laitetietojen hallinnasta käyttökomentojen suorittamiseen.
Näillä ominaisuuksilla varustettuna, kuten järjestelmäkehotteessa kerrotaan, AI-avustaja seuraa jäsenneltyä työnkulkua käyttäjien kysymyksiin vastaamiseksi. Seuraavassa kuvassa on visuaalinen esitys tästä työnkulusta, joka havainnollistaa jokaista vaihetta käyttäjän ensimmäisestä vuorovaikutuksesta lopulliseen vastaukseen.

Työnkulku koostuu seuraavista vaiheista:
- Prosessi alkaa, kun käyttäjä pyytää avustajaa suorittamaan tehtävän; esimerkiksi kysymällä tietyn IoT-laitteen enimmäisdatapisteitä
device_xxx. Tämä tekstinsyöttö kaapataan ja lähetetään AI-avustajalle. - AI-avustaja tulkitsee käyttäjän tekstinsyötön. Se käyttää tarjottua keskusteluhistoriaa, toimintaryhmiä ja tietopohjaa ymmärtääkseen kontekstin ja määrittääkseen tarvittavat tehtävät.
- Kun käyttäjän tarkoitus on jäsennetty ja ymmärretty, AI-avustaja määrittelee tehtävät. Tämä perustuu ohjeisiin, jotka avustaja tulkitsee järjestelmän kehotteen ja käyttäjän syötteen mukaisesti.
- Tehtävät suoritetaan sitten sarjan API-kutsujen kautta. Tämä tehdään käyttämällä suhtautua kehote, joka jakaa tehtävän sarjaan vaiheita, jotka käsitellään peräkkäin:
- Laitteen mittareiden tarkistuksiin käytämme
check-device-metricstoimintaryhmä, joka sisältää API-kutsun Lambda-funktioille, jotka sitten tekevät kyselyn Amazon Athena pyydettyjä tietoja varten. - Käytämme suoria laitetoimintoja, kuten käynnistystä, pysäytystä tai uudelleenkäynnistystä, varten
action-on-devicetoimintaryhmä, joka kutsuu Lambda-funktion. Tämä toiminto käynnistää prosessin, joka lähettää komentoja IoT-laitteelle. Tässä viestissä Lambda-toiminto lähettää ilmoituksia käyttämällä Amazonin yksinkertainen sähköpostipalvelu (Amazon SES). - Käytämme Amazon Bedrockin Knowledge Bases -tietokantoja hakeaksemme historiallisia tietoja, jotka on tallennettu upotettuina Amazon OpenSearch-palvelu vektoritietokanta.
- Laitteen mittareiden tarkistuksiin käytämme
- Kun tehtävät on suoritettu, Amazon Bedrock FM luo lopullisen vastauksen ja välittää sen takaisin käyttäjälle.
- Agents for Amazon Bedrock tallentaa tiedot automaattisesti tilallisen istunnon avulla ylläpitääkseen samaa keskustelua. Tila poistetaan, kun määritettävä joutokäynnin aikakatkaisu on kulunut.
Tekninen yleiskatsaus
Seuraava kaavio havainnollistaa arkkitehtuuria AI-avustajan käyttöönottamiseksi Agents for Amazon Bedrockin kanssa.
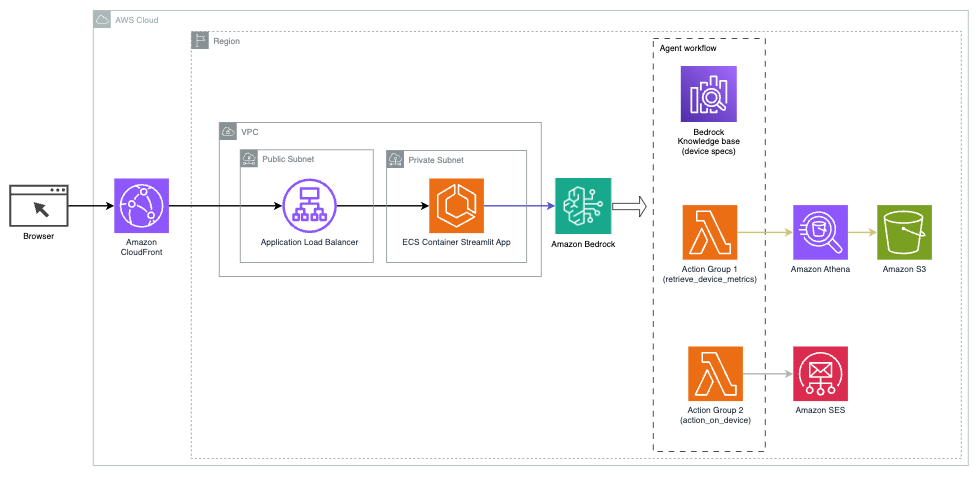
Se koostuu seuraavista avainkomponenteista:
- Keskustelukäyttöliittymä – Keskustelukäyttöliittymä käyttää Streamlitiä, avoimen lähdekoodin Python-kirjastoa, joka yksinkertaistaa mukautettujen, visuaalisesti houkuttelevien verkkosovellusten luomista koneoppimiseen (ML) ja datatieteeseen. Sitä isännöidään Amazonin elastisten säiliöiden palvelu (Amazon ECS) kanssa AWS-veljeskunta, ja sitä käytetään Application Load Balancer -sovelluksella. Voit käyttää Fargatea Amazon ECS:n kanssa säiliöt tarvitsematta hallita palvelimia, klustereita tai virtuaalikoneita.
- Amazon Bedrockin edustajat – Agents for Amazon Bedrock täydentää käyttäjien kyselyt useiden päättelyvaiheiden ja vastaavien toimien avulla, jotka perustuvat ReAct kehotus:
- Amazon Bedrockin tietokannat – Knowledge Bases for Amazon Bedrock tarjoaa täysin hallitun RÄTTI antaa AI-avustajalle pääsyn tietoihisi. Käyttötapauksessamme latasimme laitteen tekniset tiedot tiedostoon Amazonin yksinkertainen tallennuspalvelu (Amazon S3) ämpäri. Se toimii tietokannan tietolähteenä.
- Toimintaryhmät – Nämä ovat määriteltyjä API-skeemoja, jotka kutsuvat tiettyjä Lambda-toimintoja ollakseen vuorovaikutuksessa IoT-laitteiden ja muiden AWS-palvelujen kanssa.
- Anthropic Claude v2.1 Amazon Bedrockissa – Tämä malli tulkitsee käyttäjien kyselyitä ja organisoi tehtävien kulun.
- Amazon Titan Embeddings – Tämä malli toimii tekstin upotusmallina, joka muuttaa luonnollisen kielen tekstin – yksittäisistä sanoista monimutkaisiin asiakirjoihin – numeerisiksi vektoreiksi. Tämä mahdollistaa vektorihakuominaisuudet, jolloin järjestelmä voi semanttisesti kohdistaa käyttäjien kyselyt osuvimpiin tietokannan merkintöihin tehokkaan haun saavuttamiseksi.
Ratkaisu on integroitu AWS-palveluihin, kuten Lambda koodin suorittamiseen vastauksena API-kutsuihin, Athena tietojoukkojen kyselyyn, OpenSearch-palvelu tietokannoista etsimiseen ja Amazon S3 tallennusta varten. Nämä palvelut toimivat yhdessä tarjotakseen saumattoman kokemuksen IoT-laitteiden toimintojen hallintaan luonnollisen kielen komentojen avulla.
Hyödyt
Tämä ratkaisu tarjoaa seuraavat edut:
- Toteutuksen monimutkaisuus:
- Tarvitaan vähemmän koodirivejä, koska Agents for Amazon Bedrock poistaa suuren osan taustalla olevasta monimutkaisuudesta, mikä vähentää kehitysponnisteluja.
- Vektoritietokantojen, kuten OpenSearch Servicen, hallinta on yksinkertaista, koska Knowledge Bases for Amazon Bedrock käsittelee vektorointia ja tallennusta
- Integrointi eri AWS-palveluihin on virtaviivaisempaa ennalta määritettyjen toimintaryhmien avulla
- Kehittäjäkokemus:
- Amazon Bedrock -konsoli tarjoaa käyttäjäystävällisen käyttöliittymän nopeaan kehittämiseen, testaukseen ja perussyyanalyysiin (RCA), mikä parantaa yleistä kehittäjäkokemusta.
- Ketteryys ja joustavuus:
- Agents for Amazon Bedrock mahdollistaa saumattoman päivityksen uudempiin FM-laitteisiin (kuten Claude 3.0), kun ne tulevat saataville, joten ratkaisusi pysyy ajan tasalla uusimpien edistysten kanssa
- AWS hallitsee palvelukiintiöitä ja rajoituksia, mikä vähentää valvonta- ja skaalausinfrastruktuurin kustannuksia
- Turvallisuus:
- Amazon Bedrock on täysin hallittu palvelu, joka noudattaa AWS:n tiukkoja turvallisuus- ja vaatimustenmukaisuusstandardeja, mikä mahdollisesti yksinkertaistaa organisaation tietoturvatarkastuksia.
Vaikka Agents for Amazon Bedrock tarjoaa virtaviivaisen ja hallitun ratkaisun keskustelupohjaisten tekoälysovellusten rakentamiseen, jotkut organisaatiot saattavat suosia avoimen lähdekoodin lähestymistapaa. Tällaisissa tapauksissa voit käyttää kehyksiä, kuten LangChain, jota käsittelemme seuraavassa osiossa.
LangChainin dynaaminen reititystapa
LangChain on avoimen lähdekoodin kehys, joka yksinkertaistaa keskustelun tekoälyn rakentamista mahdollistamalla suurten kielimallien (LLM) integroinnin ja dynaamisten reititysominaisuuksien. LangChain Expression Language (LCEL) -kielen avulla kehittäjät voivat määritellä reititys, jonka avulla voit luoda ei-deterministisiä ketjuja, joissa edellisen vaiheen tulos määrittää seuraavan vaiheen. Reititys auttaa tarjoamaan rakennetta ja johdonmukaisuutta vuorovaikutuksessa LLM:ien kanssa.
Tässä viestissä käytämme samaa esimerkkiä kuin AI-avustaja IoT-laitteiden hallintaan. Suurin ero on kuitenkin siinä, että meidän täytyy käsitellä järjestelmäkehotteita erikseen ja käsitellä jokaista ketjua erillisenä kokonaisuutena. Reititysketju päättää kohdeketjun käyttäjän syötteen perusteella. Päätös tehdään LLM:n tuella välittämällä järjestelmäkehote, chat-historia ja käyttäjän kysymys.
Ratkaisun yleiskatsaus
Seuraava kaavio havainnollistaa dynaamisen reititysratkaisun työnkulkua.

Työnkulku koostuu seuraavista vaiheista:
- Käyttäjä esittää kysymyksen tekoälyavustajalle. Esimerkiksi "Mitä ovat laitteen 1009 enimmäismittaukset?"
- LLM arvioi jokaisen kysymyksen yhdessä keskusteluhistorian kanssa samasta istunnosta määrittääkseen sen luonteen ja sen, mihin aihealueeseen se kuuluu (kuten SQL, toiminta, haku tai pk-yritys). LLM luokittelee syötteen ja LCEL-reititysketju ottaa sen syötteen.
- Reititinketju valitsee kohdeketjun syötteen perusteella, ja LLM:lle toimitetaan seuraava järjestelmäkehote:
LLM arvioi käyttäjän kysymyksen yhdessä keskusteluhistorian kanssa määrittääkseen kyselyn luonteen ja sen, mihin aihealueeseen se kuuluu. LLM luokittelee sitten syötteen ja tulostaa JSON-vastauksen seuraavassa muodossa:
Reititinketju käyttää tätä JSON-vastausta vastaavan kohdeketjun kutsumiseen. On neljä aihekohtaista kohdeketjua, joista jokaisella on oma järjestelmäkehote:
- SQL:ään liittyvät kyselyt lähetetään SQL-kohdeketjuun tietokantavuorovaikutuksia varten. Voit käyttää LCEL:ää rakentaaksesi SQL-ketju.
- Toimintakeskeiset kysymykset kutsuvat mukautetun Lambda-kohdeketjun toimintojen suorittamiseen. LCEL:n avulla voit määrittää omasi mukautettu toiminto; meidän tapauksessamme se on toiminto, joka suorittaa ennalta määritellyn Lambda-toiminnon lähettääkseen sähköpostin, jossa laitetunnus on jäsennetty. Esimerkki käyttäjän syötteestä voi olla "Sammuta laite 1009".
- Hakuun keskittyvät tiedustelut jatkavat RÄTTI kohdeketju tiedonhakuun.
- Pk-yrityksiin liittyvät kysymykset siirtyvät pk-yritysten/asiantuntijoiden kohdeketjuun erikoistuneiden näkemysten saamiseksi.
- Jokainen kohdeketju ottaa syötteen ja suorittaa tarvittavat mallit tai toiminnot:
- SQL-ketju käyttää Athenaa kyselyjen suorittamiseen.
- RAG-ketju käyttää semanttiseen hakuun OpenSearch-palvelua.
- Mukautettu Lambda-ketju suorittaa toimintoja varten Lambda-toimintoja.
- Pk-/asiantuntijaketju tarjoaa oivalluksia Amazon Bedrock -mallin avulla.
- LLM muotoilee vastaukset kunkin kohdeketjun johdonmukaisiksi oivalluksiksi. Nämä tiedot toimitetaan sitten käyttäjälle, jolloin kyselysykli on valmis.
- Käyttäjän syötteet ja vastaukset tallennetaan Amazon DynamoDB tarjota kontekstin LLM:lle nykyiselle istunnolle ja aiemmille vuorovaikutuksille. Sovellus hallitsee DynamoDB:ssä säilytettyjen tietojen kestoa.
Tekninen yleiskatsaus
Seuraava kaavio havainnollistaa LangChainin dynaamisen reititysratkaisun arkkitehtuuria.
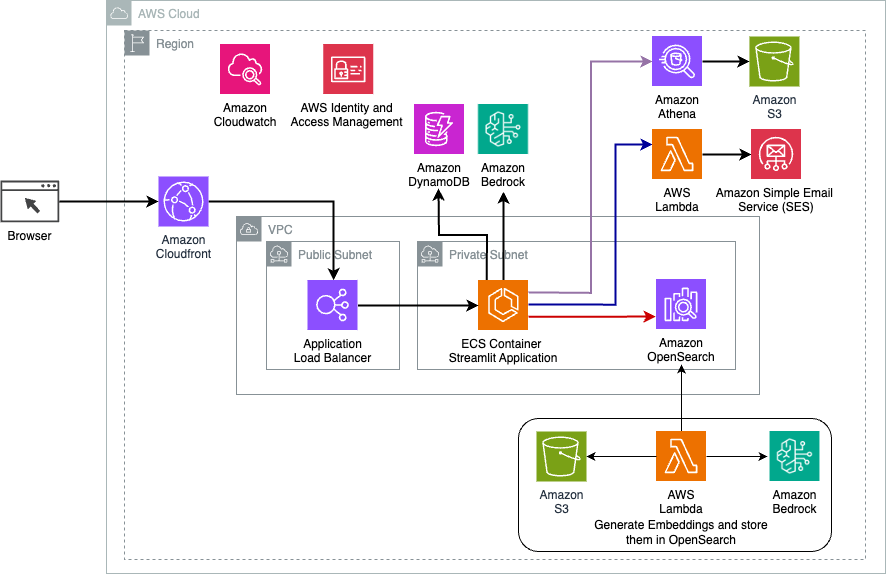
Verkkosovellus on rakennettu Streamlitille, jota isännöidään Amazon ECS:ssä Fargaten kanssa, ja sitä käytetään Application Load Balancer -sovelluksella. Käytämme LLM:nä Anthropicin Claude v2.1:tä Amazon Bedrockissa. Verkkosovellus on vuorovaikutuksessa mallin kanssa LangChain-kirjastojen avulla. Se toimii myös vuorovaikutuksessa useiden muiden AWS-palvelujen, kuten OpenSearch Servicen, Athenan ja DynamoDB:n, kanssa loppukäyttäjien tarpeiden täyttämiseksi.
Hyödyt
Tämä ratkaisu tarjoaa seuraavat edut:
- Toteutuksen monimutkaisuus:
- Vaikka LangChain vaatii enemmän koodia ja mukautettua kehitystä, se tarjoaa enemmän joustavuutta ja hallintaa reitityslogiikassa ja integraatiossa eri komponenttien kanssa.
- Vektoritietokantojen, kuten OpenSearch Servicen, hallinta vaatii lisäasennus- ja määritysponnisteluja. Vektorisointiprosessi toteutetaan koodilla.
- Integrointi AWS-palveluihin voi sisältää enemmän mukautettua koodia ja konfigurointia.
- Kehittäjäkokemus:
- LangChainin Python-pohjainen lähestymistapa ja kattava dokumentaatio voivat houkutella kehittäjiä, jotka ovat jo tunteneet Pythonin ja avoimen lähdekoodin työkalut.
- Nopea kehitys ja virheenkorjaus saattavat vaatia enemmän manuaalista työtä kuin Amazon Bedrock -konsolin käyttäminen.
- Ketteryys ja joustavuus:
- LangChain tukee laajaa valikoimaa LLM:itä, jolloin voit vaihtaa eri mallien tai palveluntarjoajien välillä, mikä lisää joustavuutta.
- LangChainin avoimen lähdekoodin luonne mahdollistaa yhteisölähtöiset parannukset ja mukautukset.
- Turvallisuus:
- Avoimen lähdekoodin kehyksenä LangChain saattaa vaatia tiukempia tietoturvatarkastuksia ja -selvityksiä organisaatioissa, mikä saattaa lisätä yleiskustannuksia.
Yhteenveto
Keskustelevat tekoälyassistentit ovat muuntavia työkaluja toimintojen virtaviivaistamiseen ja käyttökokemusten parantamiseen. Tässä viestissä tutkittiin kahta tehokasta lähestymistapaa AWS-palveluiden avulla: Amazon Bedrockin hallitut agentit ja joustava, avoimen lähdekoodin LangChain dynaaminen reititys. Valinta näiden lähestymistapojen välillä riippuu organisaatiosi vaatimuksista, kehitystarpeista ja halutusta räätälöintitasosta. Valitusta tiestä riippumatta AWS antaa sinulle mahdollisuuden luoda älykkäitä tekoälyavustajia, jotka mullistavat yritysten ja asiakkaiden vuorovaikutuksen
Löydä ratkaisukoodi ja käyttöönottoresurssit sivuiltamme GitHub-arkisto, jossa voit seurata kunkin keskustelun tekoälyn yksityiskohtaisia vaiheita.
Tietoja Tekijät
 Ameer Hakme on AWS Solutions -arkkitehti Pennsylvaniassa. Hän tekee yhteistyötä riippumattomien ohjelmistotoimittajien (ISV) kanssa Koillisalueella ja auttaa heitä suunnittelemaan ja rakentamaan skaalautuvia ja moderneja alustoja AWS-pilveen. AI/ML:n ja generatiivisen tekoälyn asiantuntija Ameer auttaa asiakkaita hyödyntämään näiden huipputeknologioiden potentiaalia. Vapaa-ajallaan hän ajaa moottoripyörällä ja viettää laatuaikaa perheensä kanssa.
Ameer Hakme on AWS Solutions -arkkitehti Pennsylvaniassa. Hän tekee yhteistyötä riippumattomien ohjelmistotoimittajien (ISV) kanssa Koillisalueella ja auttaa heitä suunnittelemaan ja rakentamaan skaalautuvia ja moderneja alustoja AWS-pilveen. AI/ML:n ja generatiivisen tekoälyn asiantuntija Ameer auttaa asiakkaita hyödyntämään näiden huipputeknologioiden potentiaalia. Vapaa-ajallaan hän ajaa moottoripyörällä ja viettää laatuaikaa perheensä kanssa.
 Sharon Li on AI/ML Solutions -arkkitehti Amazon Web Servicesissä Bostonissa, ja hänen intohimonsa on suunnitella ja rakentaa generatiivisia tekoälysovelluksia AWS:llä. Hän tekee yhteistyötä asiakkaiden kanssa hyödyntääkseen AWS AI/ML -palveluita innovatiivisiin ratkaisuihin.
Sharon Li on AI/ML Solutions -arkkitehti Amazon Web Servicesissä Bostonissa, ja hänen intohimonsa on suunnitella ja rakentaa generatiivisia tekoälysovelluksia AWS:llä. Hän tekee yhteistyötä asiakkaiden kanssa hyödyntääkseen AWS AI/ML -palveluita innovatiivisiin ratkaisuihin.
 Kawsar Kamal on Amazon Web Servicesin vanhempi ratkaisuarkkitehti, jolla on yli 15 vuoden kokemus infrastruktuurin automaatio- ja turvallisuusalalta. Hän auttaa asiakkaita suunnittelemaan ja rakentamaan skaalautuvia DevSecOps- ja AI/ML-ratkaisuja pilveen.
Kawsar Kamal on Amazon Web Servicesin vanhempi ratkaisuarkkitehti, jolla on yli 15 vuoden kokemus infrastruktuurin automaatio- ja turvallisuusalalta. Hän auttaa asiakkaita suunnittelemaan ja rakentamaan skaalautuvia DevSecOps- ja AI/ML-ratkaisuja pilveen.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/machine-learning/enhance-conversational-ai-with-advanced-routing-techniques-with-amazon-bedrock/

