Sen ydin, LangChain on innovatiivinen kehys, joka on räätälöity kielimallien ominaisuuksia hyödyntävien sovellusten luomiseen. Se on työkalupakki, joka on suunniteltu kehittäjille, jotta he voivat luoda sovelluksia, jotka ovat kontekstitietoisia ja pystyvät kehittyneeseen päättelyyn.
Tämä tarkoittaa, että LangChain-sovellukset voivat ymmärtää kontekstin, kuten nopeat ohjeet tai sisällön perusvastaukset, ja käyttää kielimalleja monimutkaisiin päättelytehtäviin, kuten päättäessään, miten vastata tai mitä toimia. LangChain edustaa yhtenäistä lähestymistapaa älykkäiden sovellusten kehittämiseen, mikä yksinkertaistaa matkaa konseptista toteutukseen monien komponenttien avulla.
LangChainin ymmärtäminen
LangChain on paljon enemmän kuin pelkkä kehys; se on täysimittainen ekosysteemi, joka koostuu useista olennaisista osista.
- Ensinnäkin on LangChain-kirjastot, jotka ovat saatavilla sekä Pythonissa että JavaScriptissä. Nämä kirjastot ovat LangChainin selkäranka, ja ne tarjoavat käyttöliittymiä ja integraatioita eri komponenteille. Ne tarjoavat peruskäyttöajan näiden komponenttien yhdistämiseen yhtenäisiksi ketjuiksi ja agenteiksi sekä valmiit toteutukset välitöntä käyttöä varten.
- Seuraavaksi meillä on LangChain-malleja. Nämä ovat kokoelma käyttöönotettavia viitearkkitehtuureja, jotka on räätälöity monenlaisiin tehtäviin. Olitpa rakentamassa chatbotia tai monimutkaista analyyttistä työkalua, nämä mallit tarjoavat vankan lähtökohdan.
- LangServe toimii monipuolisena kirjastona LangChain-ketjujen käyttöönottamiseksi REST API:ina. Tämä työkalu on välttämätön, kun haluat muuttaa LangChain-projektisi saavutettaviksi ja skaalautuviksi verkkopalveluiksi.
- Lopuksi LangSmith toimii kehittäjäalustana. Se on suunniteltu virheenkorjaukseen, testaamiseen, arvioimiseen ja seuraamiseen mille tahansa LLM-kehykselle rakennettuja ketjuja. Saumaton integrointi LangChainin kanssa tekee siitä korvaamattoman työkalun kehittäjille, jotka haluavat jalostaa ja täydentää sovelluksiaan.
Yhdessä nämä komponentit antavat sinulle mahdollisuuden kehittää, tuottaa ja ottaa käyttöön sovelluksia helposti. LangChainilla aloitat kirjoittamalla sovelluksesi kirjastojen avulla ja viittaat mallipohjiin ohjeiden saamiseksi. LangSmith auttaa sinua sitten tarkastamaan, testaamaan ja valvomaan ketjujasi ja varmistamaan, että sovelluksesi kehittyvät jatkuvasti ja ovat valmiita käyttöönottoa varten. Lopuksi LangServen avulla voit helposti muuttaa minkä tahansa ketjun API:ksi, mikä tekee käyttöönotosta helppoa.
Seuraavissa osioissa perehdymme tarkemmin LangChainin määrittämiseen ja aloitamme matkasi älykkäiden, kielimallipohjaisten sovellusten luomiseen.
Automatisoi manuaalisia tehtäviä ja työnkulkuja tekoälypohjaisella työnkulun rakentajallamme, jonka Nanonets on suunnitellut sinulle ja ryhmillesi.
Asennus ja asennus
Oletko valmis sukeltamaan LangChainin maailmaan? Sen määrittäminen on yksinkertaista, ja tämä opas opastaa sinut prosessin läpi vaihe vaiheelta.
Ensimmäinen askel LangChain-matkallasi on sen asentaminen. Voit tehdä tämän helposti käyttämällä pip tai conda. Suorita seuraava komento terminaalissasi:
pip install langchain
Voit asentaa LangChainin suoraan lähteestä niille, jotka pitävät uusimmista ominaisuuksista ja nauttivat hieman enemmän seikkailusta. Kloonaa arkisto ja siirry kohtaan langchain/libs/langchain hakemistosta. Suorita sitten:
pip install -e .
Harkitse kokeellisten ominaisuuksien asentamista langchain-experimental. Se on paketti, joka sisältää huippuluokan koodia ja on tarkoitettu tutkimus- ja kokeellisiin tarkoituksiin. Asenna se käyttämällä:
pip install langchain-experimental
LangChain CLI on kätevä työkalu LangChain-mallien ja LangServe-projektien kanssa työskentelemiseen. LangChain CLI:n asentamiseksi käytä:
pip install langchain-cli
LangServe on välttämätön LangChain-ketjujesi käyttöönotossa REST API:na. Se asennetaan LangChain CLI:n rinnalle.
LangChain vaatii usein integraatioita mallintarjoajien, tietovarastojen, API:iden jne. kanssa. Tässä esimerkissä käytämme OpenAI:n mallisovellusliittymiä. Asenna OpenAI Python -paketti käyttämällä:
pip install openai
Voit käyttää sovellusliittymää asettamalla OpenAI API -avaimesi ympäristömuuttujaksi:
export OPENAI_API_KEY="your_api_key"
Vaihtoehtoisesti välitä avain suoraan python-ympäristössäsi:
import os
os.environ['OPENAI_API_KEY'] = 'your_api_key'
LangChain mahdollistaa kielimallisovellusten luomisen moduulien kautta. Nämä moduulit voivat olla joko itsenäisiä tai koottu monimutkaisia käyttötapauksia varten. Nämä moduulit ovat -
- Malli I/O: Helpottaa vuorovaikutusta eri kielimallien kanssa ja käsittelee niiden syötteitä ja lähtöjä tehokkaasti.
- haku: Mahdollistaa pääsyn ja vuorovaikutuksen sovelluskohtaisiin tietoihin, mikä on ratkaisevan tärkeää dynaamisen tiedonkäytön kannalta.
- Kiinteistönvälittäjät: Valtuuta sovellukset valitsemaan sopivat työkalut korkean tason ohjeiden perusteella, mikä parantaa päätöksentekokykyä.
- Kahleet: Tarjoaa ennalta määritettyjä, uudelleenkäytettäviä koostumuksia, jotka toimivat sovelluskehityksen rakennuspalikoina.
- Muisti: Säilyttää sovelluksen tilan useissa ketjun suorituksissa, mikä on välttämätöntä kontekstitietoisille vuorovaikutuksille.
Jokainen moduuli keskittyy tiettyihin kehitystarpeisiin, mikä tekee LangChainista kattavan työkalupakin kehittyneiden kielimallisovellusten luomiseen.
Yllä olevien komponenttien lisäksi meillä on myös LangChain Expression Language (LCEL), joka on deklaratiivinen tapa koota moduuleita helposti yhteen ja tämä mahdollistaa komponenttien ketjuttamisen yleisen Runnable-rajapinnan avulla.
LCEL näyttää suunnilleen tältä -
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import BaseOutputParser # Example chain
chain = ChatPromptTemplate() | ChatOpenAI() | CustomOutputParser()
Nyt kun olemme käsitelleet perusasiat, jatkamme:
- Tutustu tarkemmin jokaiseen Langchain-moduuliin.
- Opi käyttämään LangChain Expression Languagea.
- Tutustu yleisiin käyttötapauksiin ja toteuta ne.
- Ota käyttöön päästä päähän -sovellus LangServen avulla.
- Tarkista LangSmith virheenkorjausta, testausta ja valvontaa varten.
Aloitetaan!
Moduuli I: Malli I/O
LangChainissa minkä tahansa sovelluksen ydinelementti pyörii kielimallin ympärillä. Tämä moduuli tarjoaa olennaiset rakennuspalikot, joiden avulla voidaan liittää tehokkaasti minkä tahansa kielimallin kanssa, mikä varmistaa saumattoman integroinnin ja viestinnän.
Mallin I/O:n keskeiset osat
- LLM:t ja chat-mallit (käytetään vaihtokelpoisesti):
- LLM:t:
- Määritelmä: Puhtaat tekstin täydennysmallit.
- Input / Output: Ota syötteeksi tekstimerkkijono ja palauta tulosteeksi tekstimerkkijono.
- Chat-mallit
- LLM:t:
- Määritelmä: Mallit, jotka käyttävät kielimallia pohjana, mutta eroavat syöttö- ja tulostusmuodoissa.
- Input / Output: Hyväksy luettelo chat-viesteistä syötteeksi ja palauta chat-viesti.
- kysyy: Malli, valitse ja hallitse mallin syötteitä dynaamisesti. Mahdollistaa joustavien ja kontekstikohtaisten kehotteiden luomisen, jotka ohjaavat kielimallin vastauksia.
- Lähtöjäsentimet: Poimi ja muotoile tiedot mallin lähdöistä. Hyödyllinen kielimallien raakatulosteen muuntamiseksi strukturoiduksi dataksi tai sovelluksen tarvitsemiin erityismuotoihin.
LLM:t
LangChainin integrointi suurten kielimallien (LLM) kanssa, kuten OpenAI, Cohere ja Hugging Face, on sen toiminnallisuuden perustavanlaatuinen osa. LangChain itsessään ei isännöi LLM:itä, mutta tarjoaa yhtenäisen käyttöliittymän vuorovaikutukseen eri LLM:ien kanssa.
Tämä osio tarjoaa yleiskatsauksen OpenAI LLM -kääreen käytöstä LangChainissa, joka soveltuu myös muihin LLM-tyyppeihin. Olemme jo asentaneet tämän "Aloitus"-osioon. Alustetaanpa LLM.
from langchain.llms import OpenAI
llm = OpenAI()
- LLM:t toteuttavat Ajettava käyttöliittymä, sen perusrakennuspalikka LangChain Expression Language (LCEL). Tämä tarkoittaa, että he tukevat
invoke,ainvoke,stream,astream,batch,abatch,astream_logpuhelut. - LLM:t hyväksyvät jouset syötteinä tai objekteina, jotka voidaan pakottaa merkkijonokehotteiksi, mukaan lukien
List[BaseMessage]jaPromptValue. (näistä lisää myöhemmin)
Katsotaanpa joitain esimerkkejä.
response = llm.invoke("List the seven wonders of the world.")
print(response)

Voit vaihtoehtoisesti kutsua suoratoistomenetelmän suoratoistaaksesi tekstivastauksen.
for chunk in llm.stream("Where were the 2012 Olympics held?"): print(chunk, end="", flush=True)

Chat-mallit
LangChainin integrointi chat-malleihin, kielimallien erikoismuunnelmiin, on olennaista interaktiivisten chat-sovellusten luomisessa. Vaikka chat-mallit käyttävät kielimalleja sisäisesti, ne tarjoavat erillisen käyttöliittymän, joka keskittyy chat-viestien tuloihin ja lähtöihin. Tämä osio tarjoaa yksityiskohtaisen yleiskatsauksen OpenAI:n chat-mallin käytöstä LangChainissa.
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
LangChainin chat-mallit toimivat erilaisten viestityyppien kanssa, kuten AIMessage, HumanMessage, SystemMessage, FunctionMessageja ChatMessage (mielivaltaisella rooliparametrilla). Yleisesti, HumanMessage, AIMessageja SystemMessage ovat eniten käytettyjä.
Chat-mallit hyväksyvät ensisijaisesti List[BaseMessage] syötteinä. Merkkijonot voidaan muuntaa HumanMessageja PromptValue tuetaan myös.
from langchain.schema.messages import HumanMessage, SystemMessage
messages = [ SystemMessage(content="You are Micheal Jordan."), HumanMessage(content="Which shoe manufacturer are you associated with?"),
]
response = chat.invoke(messages)
print(response.content)
kysyy
Kehotteet ovat välttämättömiä ohjattaessa kielimalleja relevanttien ja yhtenäisten tulosten luomiseksi. Ne voivat vaihdella yksinkertaisista ohjeista monimutkaisiin muutaman otoksen esimerkkeihin. LangChainissa kehotteiden käsittely voi olla hyvin virtaviivainen prosessi useiden erillisten luokkien ja toimintojen ansiosta.
LangChainin PromptTemplate class on monipuolinen työkalu merkkijonokehotteiden luomiseen. Se käyttää Pythonia str.format syntaksi, joka mahdollistaa dynaamisen kehotteen luomisen. Voit määrittää mallin paikkamerkeillä ja täyttää ne tietyillä arvoilla tarpeen mukaan.
from langchain.prompts import PromptTemplate # Simple prompt with placeholders
prompt_template = PromptTemplate.from_template( "Tell me a {adjective} joke about {content}."
) # Filling placeholders to create a prompt
filled_prompt = prompt_template.format(adjective="funny", content="robots")
print(filled_prompt)Chat-malleissa kehotteet ovat jäsennellympiä, ja niissä on viestejä tietyillä rooleilla. LangChain tarjoaa ChatPromptTemplate tähän tarkoitukseen.
from langchain.prompts import ChatPromptTemplate # Defining a chat prompt with various roles
chat_template = ChatPromptTemplate.from_messages( [ ("system", "You are a helpful AI bot. Your name is {name}."), ("human", "Hello, how are you doing?"), ("ai", "I'm doing well, thanks!"), ("human", "{user_input}"), ]
) # Formatting the chat prompt
formatted_messages = chat_template.format_messages(name="Bob", user_input="What is your name?")
for message in formatted_messages: print(message)
Tämä lähestymistapa mahdollistaa interaktiivisten, mukaansatempaavien chatbottien luomisen dynaamisilla vastauksilla.
molemmat PromptTemplate ja ChatPromptTemplate integroituvat saumattomasti LangChain Expression Language (LCEL) -kieleen, jolloin ne voivat olla osa suurempia, monimutkaisia työnkulkuja. Keskustelemme tästä lisää myöhemmin.
Mukautetut kehotemallit ovat joskus välttämättömiä tehtävissä, jotka vaativat ainutlaatuista muotoilua tai erityisiä ohjeita. Mukautetun kehotemallin luomiseen kuuluu syöttömuuttujien ja mukautetun muotoilumenetelmän määrittäminen. Tämän joustavuuden ansiosta LangChain pystyy täyttämään laajan valikoiman sovelluskohtaisia vaatimuksia. Lue lisää täältä.
LangChain tukee myös muutaman laukauksen kehotusta, jolloin malli voi oppia esimerkeistä. Tämä ominaisuus on elintärkeä tehtävissä, jotka edellyttävät kontekstuaalista ymmärrystä tai erityisiä malleja. Muutaman kuvan kehotemalleja voidaan rakentaa esimerkkijoukosta tai käyttämällä esimerkkivalitsinobjektia. Lue lisää täältä.
Lähtöjäsentimet
Lähtöjäsentimillä on keskeinen rooli Langchainissa, jolloin käyttäjät voivat jäsentää kielimallien tuottamia vastauksia. Tässä osiossa tutkimme lähtöjäsenninten käsitettä ja annamme koodiesimerkkejä käyttämällä Langchainin PydanticOutputParser-, SimpleJsonOutputParser-, CommaSeparatedListOutputParser-, DatetimeOutputParser- ja XMLOutputParseria.
PydanticOutputParser
Langchain tarjoaa PydanticOutputParserin vastausten jäsentämiseksi Pydantic-tietorakenteiksi. Alla on vaiheittainen esimerkki sen käytöstä:
from typing import List
from langchain.llms import OpenAI
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import PromptTemplate
from langchain.pydantic_v1 import BaseModel, Field, validator # Initialize the language model
model = OpenAI(model_name="text-davinci-003", temperature=0.0) # Define your desired data structure using Pydantic
class Joke(BaseModel): setup: str = Field(description="question to set up a joke") punchline: str = Field(description="answer to resolve the joke") @validator("setup") def question_ends_with_question_mark(cls, field): if field[-1] != "?": raise ValueError("Badly formed question!") return field # Set up a PydanticOutputParser
parser = PydanticOutputParser(pydantic_object=Joke) # Create a prompt with format instructions
prompt = PromptTemplate( template="Answer the user query.n{format_instructions}n{query}n", input_variables=["query"], partial_variables={"format_instructions": parser.get_format_instructions()},
) # Define a query to prompt the language model
query = "Tell me a joke." # Combine prompt, model, and parser to get structured output
prompt_and_model = prompt | model
output = prompt_and_model.invoke({"query": query}) # Parse the output using the parser
parsed_result = parser.invoke(output) # The result is a structured object
print(parsed_result)
Tuotos on:

SimpleJsonOutputParser
Langchainin SimpleJsonOutputParseria käytetään, kun haluat jäsentää JSON-tyyppisiä tulosteita. Tässä on esimerkki:
from langchain.output_parsers.json import SimpleJsonOutputParser # Create a JSON prompt
json_prompt = PromptTemplate.from_template( "Return a JSON object with `birthdate` and `birthplace` key that answers the following question: {question}"
) # Initialize the JSON parser
json_parser = SimpleJsonOutputParser() # Create a chain with the prompt, model, and parser
json_chain = json_prompt | model | json_parser # Stream through the results
result_list = list(json_chain.stream({"question": "When and where was Elon Musk born?"})) # The result is a list of JSON-like dictionaries
print(result_list)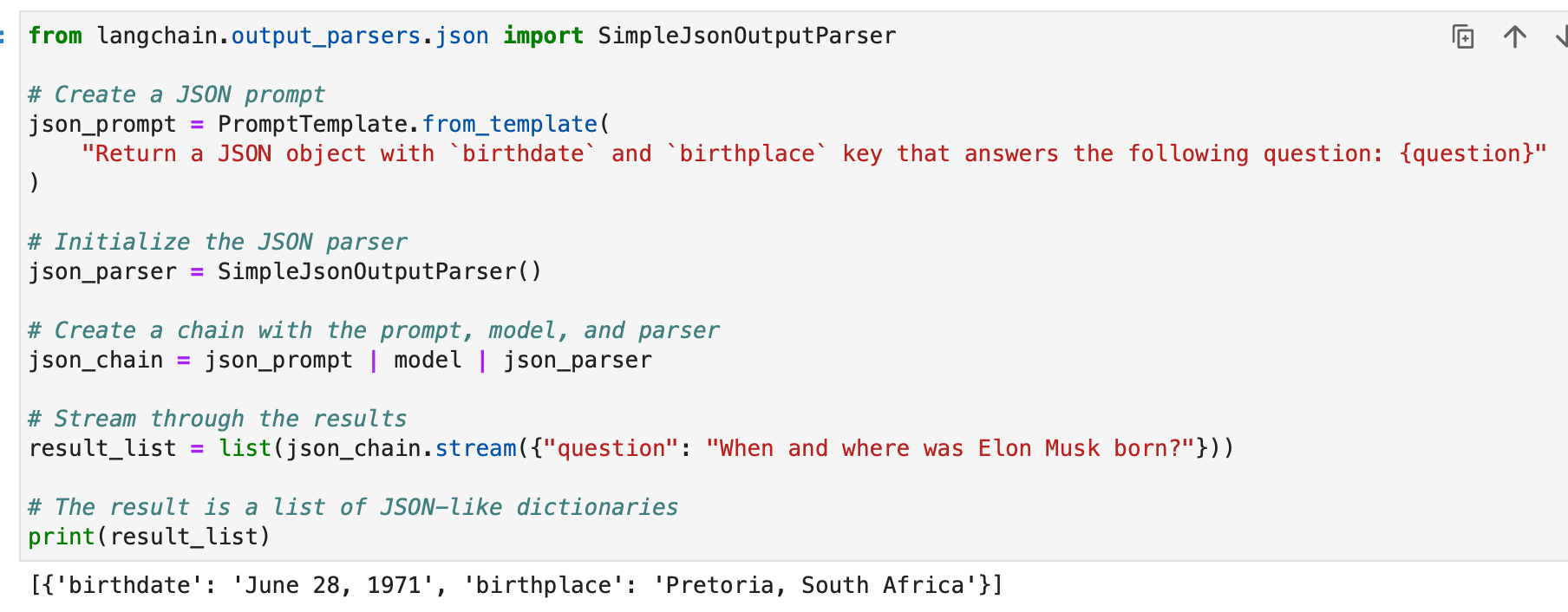
CommaSeparatedListOutputParser
CommaSeparatedListOutputParser on kätevä, kun haluat poimia pilkuilla eroteltuja luetteloita mallivastauksista. Tässä on esimerkki:
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI # Initialize the parser
output_parser = CommaSeparatedListOutputParser() # Create format instructions
format_instructions = output_parser.get_format_instructions() # Create a prompt to request a list
prompt = PromptTemplate( template="List five {subject}.n{format_instructions}", input_variables=["subject"], partial_variables={"format_instructions": format_instructions}
) # Define a query to prompt the model
query = "English Premier League Teams" # Generate the output
output = model(prompt.format(subject=query)) # Parse the output using the parser
parsed_result = output_parser.parse(output) # The result is a list of items
print(parsed_result)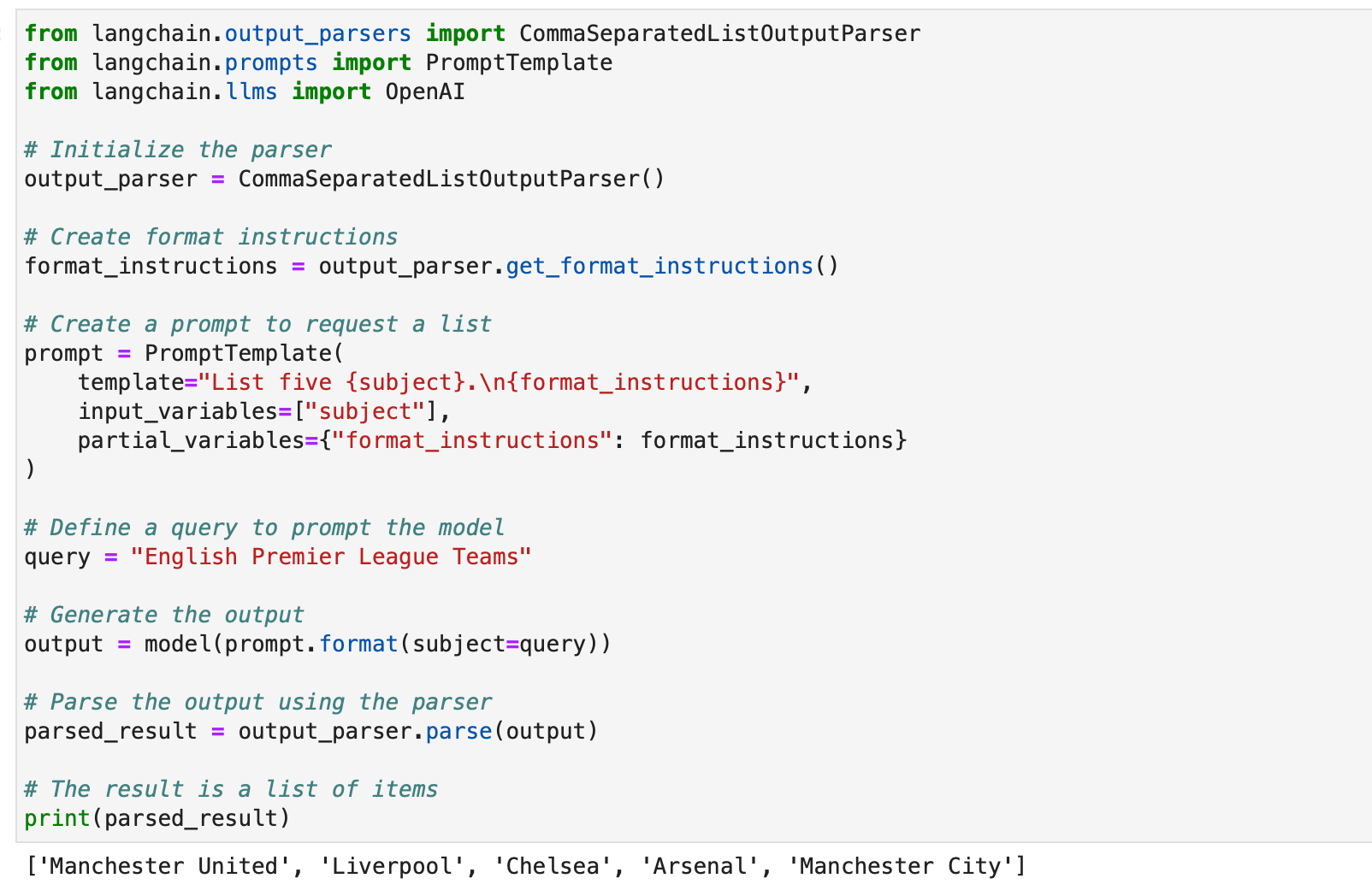
DatetimeOutputParser
Langchainin DatetimeOutputParser on suunniteltu jäsentämään päivämäärä-aikatietoja. Käytä sitä seuraavasti:
from langchain.prompts import PromptTemplate
from langchain.output_parsers import DatetimeOutputParser
from langchain.chains import LLMChain
from langchain.llms import OpenAI # Initialize the DatetimeOutputParser
output_parser = DatetimeOutputParser() # Create a prompt with format instructions
template = """
Answer the user's question:
{question}
{format_instructions} """ prompt = PromptTemplate.from_template( template, partial_variables={"format_instructions": output_parser.get_format_instructions()},
) # Create a chain with the prompt and language model
chain = LLMChain(prompt=prompt, llm=OpenAI()) # Define a query to prompt the model
query = "when did Neil Armstrong land on the moon in terms of GMT?" # Run the chain
output = chain.run(query) # Parse the output using the datetime parser
parsed_result = output_parser.parse(output) # The result is a datetime object
print(parsed_result)
Nämä esimerkit osoittavat, kuinka Langchainin lähtöjäsentimiä voidaan käyttää erityyppisten mallivastausten jäsentämiseen, mikä tekee niistä sopivia erilaisiin sovelluksiin ja formaatteihin. Tulosten jäsentimet ovat arvokas työkalu Langchainin kielimallin tulosteiden käytettävyyden ja tulkittavuuden parantamiseen.
Automatisoi manuaalisia tehtäviä ja työnkulkuja tekoälypohjaisella työnkulun rakentajallamme, jonka Nanonets on suunnitellut sinulle ja ryhmillesi.
Moduuli II: Haku
LangChain-haulla on ratkaiseva rooli sovelluksissa, jotka vaativat käyttäjäkohtaisia tietoja, jotka eivät sisälly mallin harjoitussarjaan. Tämä prosessi, joka tunnetaan nimellä Retrieval Augmented Generation (RAG), sisältää ulkoisten tietojen hakemisen ja integroinnin kielimallin luomisprosessiin. LangChain tarjoaa kattavan valikoiman työkaluja ja toimintoja, jotka helpottavat tätä prosessia, sekä yksinkertaisissa että monimutkaisissa sovelluksissa.
LangChain saavuttaa haun useiden komponenttien avulla, joista keskustelemme yksitellen.
Asiakirjojen latauslaitteet
LangChainin asiakirjalataajat mahdollistavat tietojen poimimisen eri lähteistä. Saatavilla on yli 100 latauslaitetta, joten ne tukevat erilaisia asiakirjatyyppejä, sovelluksia ja lähteitä (yksityiset s3-sämpöt, julkiset verkkosivustot, tietokannat).
Voit valita asiakirjalataimen tarpeidesi mukaan tätä.
Kaikki nämä lataajat nielevät tietoja Asiakirja luokat. Opimme käyttämään asiakirjaluokille syötettyä dataa myöhemmin.
Tekstitiedostojen latausohjelma: Lataa yksinkertainen .txt tiedosto asiakirjaksi.
from langchain.document_loaders import TextLoader loader = TextLoader("./sample.txt")
document = loader.load()
CSV-lataaja: Lataa CSV-tiedosto asiakirjaan.
from langchain.document_loaders.csv_loader import CSVLoader loader = CSVLoader(file_path='./example_data/sample.csv')
documents = loader.load()
Voimme mukauttaa jäsennystä määrittämällä kenttien nimet -
loader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv', csv_args={ 'delimiter': ',', 'quotechar': '"', 'fieldnames': ['MLB Team', 'Payroll in millions', 'Wins']
})
documents = loader.load()
PDF-lataajat: LangChainin PDF-lataajat tarjoavat erilaisia menetelmiä sisällön jäsentämiseen ja poimimiseen PDF-tiedostoista. Jokainen latauslaite täyttää erilaiset vaatimukset ja käyttää erilaisia taustalla olevia kirjastoja. Alla on yksityiskohtaisia esimerkkejä jokaisesta kuormaajasta.
PyPDFLoaderia käytetään perus PDF-jäsennykseen.
from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
MathPixLoader on ihanteellinen matemaattisen sisällön ja kaavioiden poimimiseen.
from langchain.document_loaders import MathpixPDFLoader loader = MathpixPDFLoader("example_data/math-content.pdf")
data = loader.load()
PyMuPDFLoader on nopea ja sisältää yksityiskohtaisen metatietojen purkamisen.
from langchain.document_loaders import PyMuPDFLoader loader = PyMuPDFLoader("example_data/layout-parser-paper.pdf")
data = loader.load() # Optionally pass additional arguments for PyMuPDF's get_text() call
data = loader.load(option="text")
PDFMiner Loader -ohjelmaa käytetään tekstin poimimisen tarkempaan hallintaan.
from langchain.document_loaders import PDFMinerLoader loader = PDFMinerLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
AmazonTextractPDFParser käyttää AWS Textractia tekstintunnistusta varten ja muita edistyneitä PDF-jäsennysominaisuuksia.
from langchain.document_loaders import AmazonTextractPDFLoader # Requires AWS account and configuration
loader = AmazonTextractPDFLoader("example_data/complex-layout.pdf")
documents = loader.load()
PDFMinerPDFasHTMLLoader luo HTML:n PDF:stä semanttista jäsentämistä varten.
from langchain.document_loaders import PDFMinerPDFasHTMLLoader loader = PDFMinerPDFasHTMLLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
PDFPlumberLoader tarjoaa yksityiskohtaisia metatietoja ja tukee yhtä asiakirjaa sivua kohden.
from langchain.document_loaders import PDFPlumberLoader loader = PDFPlumberLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
Integroidut kuormaajat: LangChain tarjoaa laajan valikoiman mukautettuja latauslaitteita, joilla voit ladata tietoja suoraan sovelluksistasi (kuten Slack, Sigma, Notion, Confluence, Google Drive ja monet muut) ja tietokannoista ja käyttää niitä LLM-sovelluksissa.
Täydellinen lista on tätä.
Alla on pari esimerkkiä tämän havainnollistamiseksi -
Esimerkki I – Slack
Slack, laajalti käytetty pikaviestintäalusta, voidaan integroida LLM:n työnkulkuihin ja sovelluksiin.
- Siirry Slack Workspace Management -sivullesi.
- Navigoida johonkin
{your_slack_domain}.slack.com/services/export. - Valitse haluamasi ajanjakso ja aloita vienti.
- Slack ilmoittaa sähköpostitse ja DM:llä, kun vienti on valmis.
- Vienti johtaa a
.ziptiedosto, joka sijaitsee Lataukset-kansiossasi tai määritetyssä latauspolussasi. - Määritä ladatun kohteen polku
.ziptiedostoLOCAL_ZIPFILE. - Käytä
SlackDirectoryLoadermistälangchain.document_loaderspaketti.
from langchain.document_loaders import SlackDirectoryLoader SLACK_WORKSPACE_URL = "https://xxx.slack.com" # Replace with your Slack URL
LOCAL_ZIPFILE = "" # Path to the Slack zip file loader = SlackDirectoryLoader(LOCAL_ZIPFILE, SLACK_WORKSPACE_URL)
docs = loader.load()
print(docs)
Esimerkki II – Figma
Figma, suosittu työkalu käyttöliittymäsuunnitteluun, tarjoaa REST API:n tietojen integrointiin.
- Hanki Figma-tiedostoavain URL-muodosta:
https://www.figma.com/file/{filekey}/sampleFilename. - Solmutunnukset löytyvät URL-parametrista
?node-id={node_id}. - Luo käyttöoikeustunnus noudattamalla osoitteessa olevia ohjeita Figma-ohjekeskus.
- -
FigmaFileLoaderluokasta alkaenlangchain.document_loaders.figmakäytetään Figma-tietojen lataamiseen. - Erilaisia LangChain-moduuleja, kuten
CharacterTextSplitter,ChatOpenAIjne., joita käytetään käsittelyyn.
import os
from langchain.document_loaders.figma import FigmaFileLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.indexes import VectorstoreIndexCreator
from langchain.chains import ConversationChain, LLMChain
from langchain.memory import ConversationBufferWindowMemory
from langchain.prompts.chat import ChatPromptTemplate, SystemMessagePromptTemplate, AIMessagePromptTemplate, HumanMessagePromptTemplate figma_loader = FigmaFileLoader( os.environ.get("ACCESS_TOKEN"), os.environ.get("NODE_IDS"), os.environ.get("FILE_KEY"),
) index = VectorstoreIndexCreator().from_loaders([figma_loader])
figma_doc_retriever = index.vectorstore.as_retriever()
- -
generate_codefunktio käyttää Figma-tietoja HTML/CSS-koodin luomiseen. - Se käyttää mallipohjaista keskustelua GPT-pohjaisen mallin kanssa.
def generate_code(human_input): # Template for system and human prompts system_prompt_template = "Your coding instructions..." human_prompt_template = "Code the {text}. Ensure it's mobile responsive" # Creating prompt templates system_message_prompt = SystemMessagePromptTemplate.from_template(system_prompt_template) human_message_prompt = HumanMessagePromptTemplate.from_template(human_prompt_template) # Setting up the AI model gpt_4 = ChatOpenAI(temperature=0.02, model_name="gpt-4") # Retrieving relevant documents relevant_nodes = figma_doc_retriever.get_relevant_documents(human_input) # Generating and formatting the prompt conversation = [system_message_prompt, human_message_prompt] chat_prompt = ChatPromptTemplate.from_messages(conversation) response = gpt_4(chat_prompt.format_prompt(context=relevant_nodes, text=human_input).to_messages()) return response # Example usage
response = generate_code("page top header")
print(response.content)
- -
generate_codefunktio, kun se suoritetaan, palauttaa HTML/CSS-koodin Figma-suunnittelusyötteen perusteella.
Käyttäkäämme nyt tietämystämme muutaman asiakirjajoukon luomiseen.
Lataamme ensin PDF-tiedoston, BCG:n vuosittaisen kestävän kehityksen raportin.
Käytämme tähän PyPDFLoaderia.
from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("bcg-2022-annual-sustainability-report-apr-2023.pdf")
pdfpages = loader.load_and_split()
Haemme nyt tietoja Airtablesta. Meillä on Airtable, joka sisältää tietoa erilaisista OCR- ja tiedonpoimintamalleista –
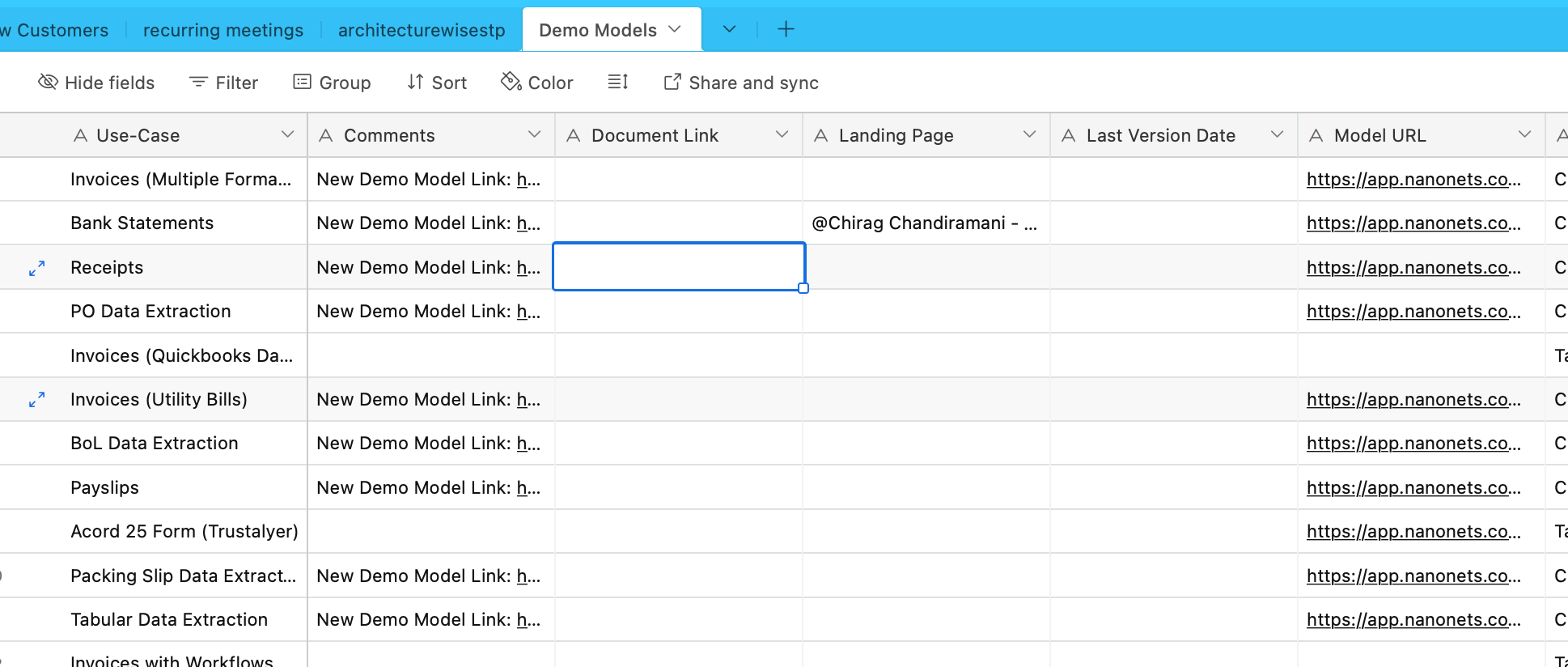
Käytämme tähän AirtableLoaderia, joka löytyy integroitujen kuormainten luettelosta.
from langchain.document_loaders import AirtableLoader api_key = "XXXXX"
base_id = "XXXXX"
table_id = "XXXXX" loader = AirtableLoader(api_key, table_id, base_id)
airtabledocs = loader.load()
Jatketaan nyt ja opitaan käyttämään näitä asiakirjaluokkia.
Asiakirjan muuntajat
Asiakirjamuuntajat LangChainissa ovat tärkeitä työkaluja, jotka on suunniteltu käsittelemään asiakirjoja, jotka loimme edellisessä alaosassa.
Niitä käytetään esimerkiksi pitkien asiakirjojen jakamiseen pienempiin osiin, yhdistämiseen ja suodattamiseen, jotka ovat ratkaisevan tärkeitä asiakirjojen mukauttamisessa mallin kontekstiikkunaan tai tiettyjen sovellustarpeiden täyttämiseen.
Yksi tällainen työkalu on RecursiveCharacterTextSplitter, monipuolinen tekstinjakaja, joka käyttää merkkiluetteloa jakamiseen. Se sallii parametrit, kuten palakoon, päällekkäisyyden ja aloitusindeksin. Tässä on esimerkki siitä, kuinka sitä käytetään Pythonissa:
from langchain.text_splitter import RecursiveCharacterTextSplitter state_of_the_union = "Your long text here..." text_splitter = RecursiveCharacterTextSplitter( chunk_size=100, chunk_overlap=20, length_function=len, add_start_index=True,
) texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
Toinen työkalu on CharacterTextSplitter, joka jakaa tekstin tietyn merkin perusteella ja sisältää osien koon ja päällekkäisyyden säätimet:
from langchain.text_splitter import CharacterTextSplitter text_splitter = CharacterTextSplitter( separator="nn", chunk_size=1000, chunk_overlap=200, length_function=len, is_separator_regex=False,
) texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
HTMLHeaderTextSplitter on suunniteltu jakamaan HTML-sisältö otsikkotunnisteiden perusteella säilyttäen semanttisen rakenteen:
from langchain.text_splitter import HTMLHeaderTextSplitter html_string = "Your HTML content here..."
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")] html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text(html_string)
print(html_header_splits[0])
Monimutkaisempi käsittely voidaan saavuttaa yhdistämällä HTMLHeaderTextSplitter toiseen jakajaan, kuten Pipelined Splitter:
from langchain.text_splitter import HTMLHeaderTextSplitter, RecursiveCharacterTextSplitter url = "https://example.com"
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url) chunk_size = 500
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size)
splits = text_splitter.split_documents(html_header_splits)
print(splits[0])
LangChain tarjoaa myös erityisiä jakajia eri ohjelmointikielille, kuten Python Code Splitter ja JavaScript Code Splitter:
from langchain.text_splitter import RecursiveCharacterTextSplitter, Language python_code = """
def hello_world(): print("Hello, World!")
hello_world() """ python_splitter = RecursiveCharacterTextSplitter.from_language( language=Language.PYTHON, chunk_size=50
)
python_docs = python_splitter.create_documents([python_code])
print(python_docs[0]) js_code = """
function helloWorld() { console.log("Hello, World!");
}
helloWorld(); """ js_splitter = RecursiveCharacterTextSplitter.from_language( language=Language.JS, chunk_size=60
)
js_docs = js_splitter.create_documents([js_code])
print(js_docs[0])
Tekstin jakamiseen merkkien määrän perusteella, mikä on hyödyllistä kielimalleissa, joissa on tunnusrajoituksia, käytetään TokenTextSplitteriä:
from langchain.text_splitter import TokenTextSplitter text_splitter = TokenTextSplitter(chunk_size=10)
texts = text_splitter.split_text(state_of_the_union)
print(texts[0])
Lopuksi LongContextReorder järjestää asiakirjoja uudelleen estääkseen mallien suorituskyvyn heikkenemisen pitkien kontekstien takia:
from langchain.document_transformers import LongContextReorder reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs)
print(reordered_docs[0])
Nämä työkalut esittelevät erilaisia tapoja muuttaa asiakirjoja LangChainissa yksinkertaisesta tekstin jakamisesta monimutkaiseen uudelleenjärjestelyyn ja kielikohtaiseen jakamiseen. Tarkempia ja tarkempia käyttötapauksia varten kannattaa tutustua LangChainin dokumentaatioon ja integraatioihin.
Esimerkeissämme kuormaajat ovat jo luoneet meille lohkottuja asiakirjoja, ja tämä osa on jo käsitelty.
Tekstin upotusmallit
LangChainin tekstin upotusmallit tarjoavat standardoidun käyttöliittymän useille upotusmallien tarjoajille, kuten OpenAI, Cohere ja Hugging Face. Nämä mallit muuntavat tekstin vektoriesitysiksi, mikä mahdollistaa toiminnot, kuten semanttisen haun tekstin samankaltaisuuden kautta vektoriavaruudessa.
Tekstin upotusmallien käytön aloittamiseksi sinun on yleensä asennettava tietyt paketit ja määritettävä API-avaimet. Olemme jo tehneet tämän OpenAI:lle
LangChainissa embed_documents -menetelmää käytetään useiden tekstien upottamiseen, mikä tarjoaa luettelon vektoriesitysistä. Esimerkiksi:
from langchain.embeddings import OpenAIEmbeddings # Initialize the model
embeddings_model = OpenAIEmbeddings() # Embed a list of texts
embeddings = embeddings_model.embed_documents( ["Hi there!", "Oh, hello!", "What's your name?", "My friends call me World", "Hello World!"]
)
print("Number of documents embedded:", len(embeddings))
print("Dimension of each embedding:", len(embeddings[0]))
Jos haluat upottaa yhden tekstin, kuten hakukyselyn, embed_query menetelmää käytetään. Tämä on hyödyllistä vertailtaessa kyselyä dokumenttien upotusjoukkoon. Esimerkiksi:
from langchain.embeddings import OpenAIEmbeddings # Initialize the model
embeddings_model = OpenAIEmbeddings() # Embed a single query
embedded_query = embeddings_model.embed_query("What was the name mentioned in the conversation?")
print("First five dimensions of the embedded query:", embedded_query[:5])
Näiden upotusten ymmärtäminen on ratkaisevan tärkeää. Jokainen teksti muunnetaan vektoriksi, jonka mitta riippuu käytetystä mallista. Esimerkiksi OpenAI-mallit tuottavat tyypillisesti 1536-ulotteisia vektoreita. Näitä upotuksia käytetään sitten asiaankuuluvien tietojen hakemiseen.
LangChainin upotustoiminto ei rajoitu OpenAI:han, vaan se on suunniteltu toimimaan useiden palveluntarjoajien kanssa. Asetukset ja käyttö voivat vaihdella hieman palveluntarjoajan mukaan, mutta tekstin vektoriavaruuteen upottamisen ydinkonsepti pysyy samana. LangChain-dokumentaatio Integraatiot-osiossa on arvokas resurssi yksityiskohtaista käyttöä varten, mukaan lukien edistyneet kokoonpanot ja integraatiot eri upotusmallien tarjoajien kanssa.
Vector kaupat
Vektorimyymälät LangChainissa tukevat tekstin upotuksen tehokasta tallennusta ja hakua. LangChain integroituu yli 50 vektorikauppaan, mikä tarjoaa standardoidun käyttöliittymän käytön helpottamiseksi.
Esimerkki: Upotusten tallentaminen ja etsiminen
Kun tekstit on upotettu, voimme tallentaa ne vektorikauppaan, kuten Chroma ja suorita samankaltaisuushakuja:
from langchain.vectorstores import Chroma db = Chroma.from_texts(embedded_texts)
similar_texts = db.similarity_search("search query")
Vaihtoehtoisesti voidaan käyttää FAISS-vektorivarastoa dokumenteillemme indeksien luomiseen.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS pdfstore = FAISS.from_documents(pdfpages, embedding=OpenAIEmbeddings()) airtablestore = FAISS.from_documents(airtabledocs, embedding=OpenAIEmbeddings())

Noutajat
LangChainin noutajat ovat rajapintoja, jotka palauttavat asiakirjoja vastauksena jäsentämättömään kyselyyn. Ne ovat yleisempiä kuin vektorivarastot ja keskittyvät noutoon varastoinnin sijaan. Vaikka vektorivarastoja voidaan käyttää noutajan selkärankana, on myös muita noutajien tyyppejä.
Voit määrittää Chroma-noutajan asentamalla sen ensin käyttämällä pip install chromadb. Sitten voit ladata, jakaa, upottaa ja noutaa asiakirjoja käyttämällä useita Python-komentoja. Tässä on koodiesimerkki Chroma-noutajan määrittämiseen:
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma full_text = open("state_of_the_union.txt", "r").read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
texts = text_splitter.split_text(full_text) embeddings = OpenAIEmbeddings()
db = Chroma.from_texts(texts, embeddings)
retriever = db.as_retriever() retrieved_docs = retriever.invoke("What did the president say about Ketanji Brown Jackson?")
print(retrieved_docs[0].page_content)
MultiQueryRetriever automatisoi kehotteen virityksen luomalla useita kyselyitä käyttäjän syöttämälle kyselylle ja yhdistää tulokset. Tässä on esimerkki sen yksinkertaisesta käytöstä:
from langchain.chat_models import ChatOpenAI
from langchain.retrievers.multi_query import MultiQueryRetriever question = "What are the approaches to Task Decomposition?"
llm = ChatOpenAI(temperature=0)
retriever_from_llm = MultiQueryRetriever.from_llm( retriever=db.as_retriever(), llm=llm
) unique_docs = retriever_from_llm.get_relevant_documents(query=question)
print("Number of unique documents:", len(unique_docs))
LangChainin kontekstuaalinen pakkaus pakkaa haetut asiakirjat kyselyn kontekstin avulla varmistaen, että vain asiaankuuluvat tiedot palautetaan. Tämä tarkoittaa sisällön vähentämistä ja vähemmän merkityksellisten asiakirjojen suodattamista. Seuraava koodiesimerkki näyttää, kuinka Contextual Compression Retrieveria käytetään:
from langchain.llms import OpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever) compressed_docs = compression_retriever.get_relevant_documents("What did the president say about Ketanji Jackson Brown")
print(compressed_docs[0].page_content)
EnsembleRetriever yhdistää erilaisia hakualgoritmeja paremman suorituskyvyn saavuttamiseksi. Esimerkki BM25- ja FAISS-noutajien yhdistämisestä näkyy seuraavassa koodissa:
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain.vectorstores import FAISS bm25_retriever = BM25Retriever.from_texts(doc_list).set_k(2)
faiss_vectorstore = FAISS.from_texts(doc_list, OpenAIEmbeddings())
faiss_retriever = faiss_vectorstore.as_retriever(search_kwargs={"k": 2}) ensemble_retriever = EnsembleRetriever( retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5]
) docs = ensemble_retriever.get_relevant_documents("apples")
print(docs[0].page_content)
LangChainin MultiVector Retriever mahdollistaa asiakirjojen kyselyn useilla vektoreilla asiakirjaa kohden, mikä on hyödyllistä dokumentin eri semanttisten näkökohtien sieppaamiseen. Menetelmiä useiden vektorien luomiseksi ovat jakaminen pienempiin osiin, yhteenveto tai hypoteettisten kysymysten luominen. Asiakirjojen jakamiseen pienempiin osiin voidaan käyttää seuraavaa Python-koodia:
python
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.storage import InMemoryStore
from langchain.document_loaders from TextLoader
import uuid loaders = [TextLoader("file1.txt"), TextLoader("file2.txt")]
docs = [doc for loader in loaders for doc in loader.load()]
text_splitter = RecursiveCharacterTextSplitter(chunk_size=10000)
docs = text_splitter.split_documents(docs) vectorstore = Chroma(collection_name="full_documents", embedding_function=OpenAIEmbeddings())
store = InMemoryStore()
id_key = "doc_id"
retriever = MultiVectorRetriever(vectorstore=vectorstore, docstore=store, id_key=id_key) doc_ids = [str(uuid.uuid4()) for _ in docs]
child_text_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
sub_docs = [sub_doc for doc in docs for sub_doc in child_text_splitter.split_documents([doc])]
for sub_doc in sub_docs: sub_doc.metadata[id_key] = doc_ids[sub_docs.index(sub_doc)] retriever.vectorstore.add_documents(sub_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
Toinen tapa on luoda yhteenvedot paremman haun vuoksi. Tässä on esimerkki yhteenvetojen luomisesta:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.document import Document chain = (lambda x: x.page_content) | ChatPromptTemplate.from_template("Summarize the following document:nn{doc}") | ChatOpenAI(max_retries=0) | StrOutputParser()
summaries = chain.batch(docs, {"max_concurrency": 5}) summary_docs = [Document(page_content=s, metadata={id_key: doc_ids[i]}) for i, s in enumerate(summaries)]
retriever.vectorstore.add_documents(summary_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
Kuhunkin asiakirjaan liittyvien hypoteettisten kysymysten luominen LLM:n avulla on toinen lähestymistapa. Tämä voidaan tehdä seuraavalla koodilla:
functions = [{"name": "hypothetical_questions", "parameters": {"questions": {"type": "array", "items": {"type": "string"}}}}]
from langchain.output_parsers.openai_functions import JsonKeyOutputFunctionsParser chain = (lambda x: x.page_content) | ChatPromptTemplate.from_template("Generate 3 hypothetical questions:nn{doc}") | ChatOpenAI(max_retries=0).bind(functions=functions, function_call={"name": "hypothetical_questions"}) | JsonKeyOutputFunctionsParser(key_name="questions")
hypothetical_questions = chain.batch(docs, {"max_concurrency": 5}) question_docs = [Document(page_content=q, metadata={id_key: doc_ids[i]}) for i, questions in enumerate(hypothetical_questions) for q in questions]
retriever.vectorstore.add_documents(question_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
Parent Document Retriever on toinen noutaja, joka löytää tasapainon upottamisen tarkkuuden ja kontekstin säilyttämisen välillä tallentamalla pieniä paloja ja hakemalla niiden suurempia pääasiakirjoja. Sen toteutus on seuraava:
from langchain.retrievers import ParentDocumentRetriever loaders = [TextLoader("file1.txt"), TextLoader("file2.txt")]
docs = [doc for loader in loaders for doc in loader.load()] child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
vectorstore = Chroma(collection_name="full_documents", embedding_function=OpenAIEmbeddings())
store = InMemoryStore()
retriever = ParentDocumentRetriever(vectorstore=vectorstore, docstore=store, child_splitter=child_splitter) retriever.add_documents(docs, ids=None) retrieved_docs = retriever.get_relevant_documents("query")
Itsekyselyinen noutaja rakentaa strukturoituja kyselyitä luonnollisen kielen syötteistä ja soveltaa niitä taustalla olevaan VectorStoreen. Sen toteutus näkyy seuraavassa koodissa:
from langchain.chat_models from ChatOpenAI
from langchain.chains.query_constructor.base from AttributeInfo
from langchain.retrievers.self_query.base from SelfQueryRetriever metadata_field_info = [AttributeInfo(name="genre", description="...", type="string"), ...]
document_content_description = "Brief summary of a movie"
llm = ChatOpenAI(temperature=0) retriever = SelfQueryRetriever.from_llm(llm, vectorstore, document_content_description, metadata_field_info) retrieved_docs = retriever.invoke("query")
WebResearchRetriever suorittaa verkkotutkimusta tietyn kyselyn perusteella -
from langchain.retrievers.web_research import WebResearchRetriever # Initialize components
llm = ChatOpenAI(temperature=0)
search = GoogleSearchAPIWrapper()
vectorstore = Chroma(embedding_function=OpenAIEmbeddings()) # Instantiate WebResearchRetriever
web_research_retriever = WebResearchRetriever.from_llm(vectorstore=vectorstore, llm=llm, search=search) # Retrieve documents
docs = web_research_retriever.get_relevant_documents("query")
Esimerkeissämme voimme myös käyttää vakionoutajaa, joka on jo toteutettu osana vektorivarastoobjektiamme seuraavasti:

Voimme nyt tiedustella noutajia. Kyselymme tulos on kyselyyn liittyviä dokumenttiobjekteja. Niitä käytetään viime kädessä asiaankuuluvien vastausten luomiseen muissa osioissa.


Automatisoi manuaalisia tehtäviä ja työnkulkuja tekoälypohjaisella työnkulun rakentajallamme, jonka Nanonets on suunnitellut sinulle ja ryhmillesi.
Moduuli III: Agentit
LangChain esittelee tehokkaan konseptin nimeltä "Agents", joka vie ketjujen idean aivan uudelle tasolle. Agentit hyödyntävät kielimalleja määrittääkseen dynaamisesti suoritettavia toimintosarjoja, mikä tekee niistä uskomattoman monipuolisia ja mukautuvia. Toisin kuin perinteiset ketjut, joissa toiminnot on koodattu koodiin, agentit käyttävät kielimalleja päättelymoottoreina päättääkseen, mitä toimia he tekevät ja missä järjestyksessä.
Agentti on keskeinen päätöksenteosta vastaava osa. Se hyödyntää kielimallin voimaa ja kehotteen määrittää seuraavat vaiheet tietyn tavoitteen saavuttamiseksi. Agentille syötetyt tiedot sisältävät tyypillisesti:
- Työkalut: Kuvaukset käytettävissä olevista työkaluista (lisää tästä myöhemmin).
- Käyttäjän syöte: Korkean tason tavoite tai kysely käyttäjältä.
- Välivaiheet: Historia (toiminto, työkalun tulos) pareista, jotka on suoritettu nykyisen käyttäjän syötteen saavuttamiseksi.
Agentin tulos voi olla seuraava toiminta ryhtyä toimiin (AgentActions) tai finaaliin vastaus lähettää käyttäjälle (AgentFinish). toiminta määrittelee a työkalu ja panos tuolle työkalulle.
Työkalut
Työkalut ovat rajapintoja, joita agentti voi käyttää vuorovaikutuksessa maailman kanssa. Niiden avulla agentit voivat suorittaa erilaisia tehtäviä, kuten etsiä verkosta, suorittaa komentotulkkikomentoja tai käyttää ulkoisia sovellusliittymiä. LangChainissa työkalut ovat välttämättömiä agenttien kykyjen laajentamiseen ja erilaisten tehtävien suorittamiseen.
Jos haluat käyttää työkaluja LangChainissa, voit ladata ne seuraavan katkelman avulla:
from langchain.agents import load_tools tool_names = [...]
tools = load_tools(tool_names)
Jotkin työkalut saattavat vaatia peruskielimallin (LLM) alustusta varten. Tällaisissa tapauksissa voit myös suorittaa LLM:n:
from langchain.agents import load_tools tool_names = [...]
llm = ...
tools = load_tools(tool_names, llm=llm)
Tämän asennuksen avulla voit käyttää erilaisia työkaluja ja integroida ne agenttisi työnkulkuihin. Täydellinen luettelo työkaluista käyttödokumentaatioineen on tätä.
Katsotaanpa joitain esimerkkejä työkaluista.
duckduckgo
DuckDuckGo-työkalun avulla voit tehdä verkkohakuja sen hakukoneen avulla. Käytä sitä seuraavasti:
from langchain.tools import DuckDuckGoSearchRun
search = DuckDuckGoSearchRun()
search.run("manchester united vs luton town match summary")

DataForSeo
DataForSeo-työkalupakin avulla voit saada hakukonetuloksia DataForSeo API:n avulla. Jotta voit käyttää tätä työkalupakkia, sinun on määritettävä API-kirjautumistietosi. Voit määrittää tunnistetiedot seuraavasti:
import os os.environ["DATAFORSEO_LOGIN"] = "<your_api_access_username>"
os.environ["DATAFORSEO_PASSWORD"] = "<your_api_access_password>"
Kun kirjautumistietosi on asetettu, voit luoda a DataForSeoAPIWrapper työkalu API:n käyttämiseen:
from langchain.utilities.dataforseo_api_search import DataForSeoAPIWrapper wrapper = DataForSeoAPIWrapper() result = wrapper.run("Weather in Los Angeles")
- DataForSeoAPIWrapper työkalu hakee hakukonetuloksia eri lähteistä.
Voit mukauttaa JSON-vastauksessa palautettujen tulosten ja kenttien tyyppiä. Voit esimerkiksi määrittää tulostyypit, kentät ja määrittää palautettavien parhaiden tulosten enimmäismäärän:
json_wrapper = DataForSeoAPIWrapper( json_result_types=["organic", "knowledge_graph", "answer_box"], json_result_fields=["type", "title", "description", "text"], top_count=3,
) json_result = json_wrapper.results("Bill Gates")
Tämä esimerkki mukauttaa JSON-vastausta määrittämällä tulostyypit, kentät ja rajoittamalla tulosten määrää.
Voit myös määrittää hakutulosten sijainnin ja kielen välittämällä lisäparametreja API-kääreeseen:
customized_wrapper = DataForSeoAPIWrapper( top_count=10, json_result_types=["organic", "local_pack"], json_result_fields=["title", "description", "type"], params={"location_name": "Germany", "language_code": "en"},
) customized_result = customized_wrapper.results("coffee near me")
Antamalla sijainti- ja kieliparametreja voit räätälöidä hakutuloksiasi tietyille alueille ja kielille.
Voit valita haluamasi hakukoneen joustavasti. Määritä vain haluamasi hakukone:
customized_wrapper = DataForSeoAPIWrapper( top_count=10, json_result_types=["organic", "local_pack"], json_result_fields=["title", "description", "type"], params={"location_name": "Germany", "language_code": "en", "se_name": "bing"},
) customized_result = customized_wrapper.results("coffee near me")
Tässä esimerkissä haku on mukautettu käyttämään Bingiä hakukoneena.
API-kääreen avulla voit myös määrittää suoritettavan haun tyypin. Voit esimerkiksi tehdä karttahaun:
maps_search = DataForSeoAPIWrapper( top_count=10, json_result_fields=["title", "value", "address", "rating", "type"], params={ "location_coordinate": "52.512,13.36,12z", "language_code": "en", "se_type": "maps", },
) maps_search_result = maps_search.results("coffee near me")
Tämä mukauttaa haun hakemaan karttoihin liittyviä tietoja.
Shell (bash)
Shell-työkalupakki tarjoaa agenteille pääsyn shell-ympäristöön, jolloin he voivat suorittaa komentotulkkikomentoja. Tämä ominaisuus on tehokas, mutta sitä tulee käyttää varoen, erityisesti hiekkalaatikkoympäristöissä. Voit käyttää Shell-työkalua seuraavasti:
from langchain.tools import ShellTool shell_tool = ShellTool() result = shell_tool.run({"commands": ["echo 'Hello World!'", "time"]})
Tässä esimerkissä Shell-työkalu suorittaa kaksi komentotulkkikomentoa: toistaen "Hello World!" ja näyttää nykyisen ajan.

Voit tarjota Shell-työkalun agentille monimutkaisempien tehtävien suorittamista varten. Tässä on esimerkki agentista, joka hakee linkkejä verkkosivulta Shell-työkalun avulla:
from langchain.agents import AgentType, initialize_agent
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(temperature=0.1) shell_tool.description = shell_tool.description + f"args {shell_tool.args}".replace( "{", "{{"
).replace("}", "}}")
self_ask_with_search = initialize_agent( [shell_tool], llm, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
self_ask_with_search.run( "Download the langchain.com webpage and grep for all urls. Return only a sorted list of them. Be sure to use double quotes."
)
Tässä skenaariossa agentti käyttää Shell-työkalua komentosarjan suorittamiseen URL-osoitteiden hakemiseksi, suodattamiseksi ja lajitteluksi verkkosivulta.
Annetut esimerkit osoittavat joitakin LangChainissa saatavilla olevista työkaluista. Nämä työkalut viime kädessä laajentavat agenttien kykyjä (tutkitaan seuraavassa alaosassa) ja antavat heille mahdollisuuden suorittaa erilaisia tehtäviä tehokkaasti. Riippuen tarpeistasi, voit valita työkalut ja työkalusarjat, jotka sopivat parhaiten projektisi tarpeisiin ja integroida ne agenttisi työnkulkuihin.
Takaisin agentteihin
Siirrytään nyt agentteihin.
AgentExecutor on agentin ajonaikainen ympäristö. Se vastaa agentin kutsumisesta, valitsemiensa toimien suorittamisesta, toimintotulosteiden välittämisestä takaisin agentille ja prosessin toistamisesta, kunnes agentti on valmis. Pseudokoodissa AgentExecutor saattaa näyttää tältä:
next_action = agent.get_action(...)
while next_action != AgentFinish: observation = run(next_action) next_action = agent.get_action(..., next_action, observation)
return next_action
AgentExecutor käsittelee useita monimutkaisia asioita, kuten sellaisten tapausten käsittelyä, joissa agentti valitsee olemattoman työkalun, työkaluvirheiden käsittelyn, agentin tuottamien tulosteiden hallinnan sekä kirjauksen ja havainnoinnin tarjoamisen kaikilla tasoilla.
Vaikka AgentExecutor-luokka on ensisijainen agentin ajonaika LangChainissa, tuetaan muita, kokeellisia ajonaikoja, kuten:
- Suunnittele ja toteuta agentti
- Vauva AGI
- Auto GPT
Saadaksemme paremman käsityksen agenttikehyksestä, rakennetaan perusagentti tyhjästä ja siirrytään sitten tutkimaan esivalmistettuja agentteja.
Ennen kuin sukeltaamme agentin rakentamiseen, on tärkeää käydä läpi joitakin keskeisiä termejä ja skeemoja:
- AgentAction: Tämä on tietoluokka, joka edustaa toimintoa, jonka edustajan tulee suorittaa. Se koostuu a
toolominaisuus (käytettävän työkalun nimi) ja atool_inputominaisuuden (työkalun syöte). - AgentFinish: Tämä tietoluokka osoittaa, että agentti on suorittanut tehtävänsä ja sen pitäisi palauttaa vastaus käyttäjälle. Se sisältää tyypillisesti sanakirjan palautusarvoista, usein avain "lähtö" sisältää vastaustekstin.
- Välivaiheet: Nämä ovat aiempien agenttitoimintojen ja vastaavien tulosteiden tietueita. Ne ovat ratkaisevan tärkeitä välitettäessä kontekstia agentin tuleviin iteraatioihin.
Esimerkissämme käytämme OpenAI Function Callingia agenttimme luomiseen. Tämä lähestymistapa on luotettava agenttien luomiseen. Aloitamme luomalla yksinkertaisen työkalun, joka laskee sanan pituuden. Tämä työkalu on hyödyllinen, koska kielimallit voivat joskus tehdä virheitä tokenisoinnin vuoksi sanojen pituuksia laskettaessa.
Ladataan ensin kielimalli, jota käytämme agentin ohjaamiseen:
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
Testataan mallia sananpituuslaskelmalla:
llm.invoke("how many letters in the word educa?")
Vastauksessa tulee ilmoittaa sanan "educa" kirjainten lukumäärä.
Seuraavaksi määrittelemme yksinkertaisen Python-funktion sanan pituuden laskemiseksi:
from langchain.agents import tool @tool
def get_word_length(word: str) -> int: """Returns the length of a word.""" return len(word)
Olemme luoneet työkalun nimeltä get_word_length joka ottaa sanan syötteeksi ja palauttaa sen pituuden.
Luodaan nyt kehote agentille. Kehote opastaa agenttia perustelemaan ja muotoilemaan tulosteen. Meidän tapauksessamme käytämme OpenAI Function Calling -toimintoa, joka vaatii vain vähän ohjeita. Määrittelemme kehotteen paikkamerkeillä käyttäjän syötteelle ja agentin luonnossivulle:
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a very powerful assistant but not great at calculating word lengths.", ), ("user", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"), ]
)
Kuinka agentti tietää, mitä työkaluja se voi käyttää? Luotamme OpenAI-funktiokutsukielimalleihin, jotka edellyttävät funktioiden välittämistä erikseen. Jotta voimme tarjota työkalumme agentille, muotoilemme ne OpenAI-funktiokutsuiksi:
from langchain.tools.render import format_tool_to_openai_function llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools])
Nyt voimme luoda agentin määrittämällä syötekartoitukset ja yhdistämällä komponentit:
Tämä on LCEL-kieli. Keskustelemme tästä myöhemmin yksityiskohtaisesti.
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai _function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
)
Olemme luoneet agenttimme, joka ymmärtää käyttäjän syötteen, käyttää käytettävissä olevia työkaluja ja muotoilee tulosteen. Ollaan nyt vuorovaikutuksessa sen kanssa:
agent.invoke({"input": "how many letters in the word educa?", "intermediate_steps": []})
Agentin tulee vastata AgentAction-toiminnolla, joka osoittaa seuraavan toimenpiteen.
Olemme luoneet agentin, mutta nyt meidän on kirjoitettava sille suoritusaika. Yksinkertaisin suoritusaika on sellainen, joka kutsuu jatkuvasti agenttia, suorittaa toimintoja ja toistaa, kunnes agentti lopettaa. Tässä on esimerkki:
from langchain.schema.agent import AgentFinish user_input = "how many letters in the word educa?"
intermediate_steps = [] while True: output = agent.invoke( { "input": user_input, "intermediate_steps": intermediate_steps, } ) if isinstance(output, AgentFinish): final_result = output.return_values["output"] break else: print(f"TOOL NAME: {output.tool}") print(f"TOOL INPUT: {output.tool_input}") tool = {"get_word_length": get_word_length}[output.tool] observation = tool.run(output.tool_input) intermediate_steps.append((output, observation)) print(final_result)
Tässä silmukassa kutsumme toistuvasti agenttia, suoritamme toimintoja ja päivitämme välivaiheita, kunnes agentti on valmis. Hoidamme myös työkaluvuorovaikutuksia silmukan sisällä.

Tämän prosessin yksinkertaistamiseksi LangChain tarjoaa AgentExecutor-luokan, joka kapseloi agentin suorittamisen ja tarjoaa virheiden käsittelyn, varhaisen pysäytyksen, jäljityksen ja muita parannuksia. Käytämme AgentExecutoria vuorovaikutukseen agentin kanssa:
from langchain.agents import AgentExecutor agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True) agent_executor.invoke({"input": "how many letters in the word educa?"})
AgentExecutor yksinkertaistaa suoritusprosessia ja tarjoaa kätevän tavan olla vuorovaikutuksessa agentin kanssa.
Myös muistia käsitellään yksityiskohtaisesti myöhemmin.
Tähän mennessä luomamme agentti on valtioton, eli se ei muista aikaisempia vuorovaikutuksia. Jotta voimme ottaa käyttöön jatkokysymykset ja keskustelut, meidän on lisättävä muistia agenttiin. Tämä sisältää kaksi vaihetta:
- Lisää kehotteeseen muistimuuttuja tallentaaksesi keskusteluhistorian.
- Pidä kirjaa chat-historiasta vuorovaikutuksen aikana.
Aloitetaan lisäämällä muistipaikkamerkki kehotteeseen:
from langchain.prompts import MessagesPlaceholder MEMORY_KEY = "chat_history"
prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a very powerful assistant but not great at calculating word lengths.", ), MessagesPlaceholder(variable_name=MEMORY_KEY), ("user", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"), ]
)
Luo nyt luettelo chat-historian seuraamiseksi:
from langchain.schema.messages import HumanMessage, AIMessage chat_history = []
Agentin luontivaiheessa sisällytämme myös muistin:
agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), "chat_history": lambda x: x["chat_history"], } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
)
Kun käytät agenttia, muista päivittää keskusteluhistoria:
input1 = "how many letters in the word educa?"
result = agent_executor.invoke({"input": input1, "chat_history": chat_history})
chat_history.extend([ HumanMessage(content=input1), AIMessage(content=result["output"]),
])
agent_executor.invoke({"input": "is that a real word?", "chat_history": chat_history})
Näin agentti voi ylläpitää keskusteluhistoriaa ja vastata jatkokysymyksiin aikaisempien vuorovaikutusten perusteella.
Onnittelut! Olet onnistuneesti luonut ja suorittanut ensimmäisen päästä päähän -agenttisi LangChainissa. Voit tutustua LangChainin ominaisuuksiin tarkemmin:
- Erilaisia agenttityyppejä tuetaan.
- Valmiiksi rakennetut agentit
- Kuinka työskennellä työkalujen ja työkaluintegraatioiden kanssa.
Agenttityypit
LangChain tarjoaa erilaisia agenttityyppejä, joista jokainen sopii tiettyihin käyttötapauksiin. Tässä on joitain käytettävissä olevia agentteja:
- Zero-shot ReAct: Tämä agentti käyttää ReAct-kehystä valitakseen työkalut pelkästään niiden kuvausten perusteella. Se vaatii kuvaukset jokaiselle työkalulle ja on erittäin monipuolinen.
- Strukturoitu syöttö ReAct: Tämä agentti käsittelee usean syöttötavan työkaluja ja sopii monimutkaisiin tehtäviin, kuten verkkoselaimessa liikkumiseen. Se käyttää työkalujen argumenttiskeemaa strukturoituun syötteeseen.
- OpenAI-toiminnot: Tämä agentti on suunniteltu erityisesti toimintokutsua varten hienosäädetyille malleille, ja se on yhteensopiva mallien, kuten gpt-3.5-turbo-0613 ja gpt-4-0613, kanssa. Käytimme tätä ensimmäisen edustajamme luomiseen yllä.
- Keskustelu: Tämä agentti on suunniteltu keskusteluasetuksiin, ja se käyttää ReActia työkalujen valintaan ja muistia aiempien vuorovaikutusten muistamiseen.
- Itse kysy haulla: Tämä agentti luottaa yhteen työkaluun, "Intermediate Answer", joka etsii asiallisia vastauksia kysymyksiin. Se vastaa alkuperäistä itsekyselyä hakupaperilla.
- ReActin dokumenttivarasto: Tämä agentti on vuorovaikutuksessa dokumenttivaraston kanssa ReAct-kehyksen avulla. Se vaatii "Haku"- ja "Haku"-työkalut ja on samanlainen kuin alkuperäisen ReAct-paperin Wikipedia-esimerkki.
Tutustu näihin agenttityyppeihin löytääksesi tarpeisiisi parhaiten sopivan LangChainissa. Näiden agenttien avulla voit sitoa työkaluja niihin toimintojen käsittelemiseksi ja vastausten luomiseksi. Lisätietoja aiheesta kuinka rakentaa oma agentti työkaluilla täällä.
Valmiiksi rakennetut agentit
Jatketaan agenttien tutkimista keskittyen LangChainissa saatavilla oleviin valmiisiin agentteihin.
gmail
LangChain tarjoaa Gmail-työkalupakin, jonka avulla voit yhdistää LangChain-sähköpostisi Gmail-sovellusliittymään. Aloittaaksesi sinun on määritettävä kirjautumistietosi, jotka on selitetty Gmail-sovellusliittymän dokumentaatiossa. Kun olet ladannut credentials.json tiedosto, voit jatkaa Gmail-sovellusliittymän käyttämistä. Lisäksi sinun on asennettava joitain vaadittuja kirjastoja käyttämällä seuraavia komentoja:
pip install --upgrade google-api-python-client > /dev/null
pip install --upgrade google-auth-oauthlib > /dev/null
pip install --upgrade google-auth-httplib2 > /dev/null
pip install beautifulsoup4 > /dev/null # Optional for parsing HTML messages
Voit luoda Gmail-työkalupakin seuraavasti:
from langchain.agents.agent_toolkits import GmailToolkit toolkit = GmailToolkit()
Voit myös muokata todennusta tarpeidesi mukaan. Kulissien takana googleapi-resurssi luodaan seuraavilla tavoilla:
from langchain.tools.gmail.utils import build_resource_service, get_gmail_credentials credentials = get_gmail_credentials( token_file="token.json", scopes=["https://mail.google.com/"], client_secrets_file="credentials.json",
)
api_resource = build_resource_service(credentials=credentials)
toolkit = GmailToolkit(api_resource=api_resource)
Työkalupakkaus tarjoaa erilaisia työkaluja, joita voidaan käyttää agentissa, mukaan lukien:
GmailCreateDraft: Luo sähköpostiluonnos määritetyillä viestikentillä.GmailSendMessage: Lähetä sähköpostiviestejä.GmailSearch: Etsi sähköpostiviestejä tai viestiketjuja.GmailGetMessage: Hae sähköpostiviestin tunnuksella.GmailGetThread: Etsi sähköpostiviestejä.
Jos haluat käyttää näitä työkaluja agentissa, voit alustaa agentin seuraavasti:
from langchain.llms import OpenAI
from langchain.agents import initialize_agent, AgentType llm = OpenAI(temperature=0)
agent = initialize_agent( tools=toolkit.get_tools(), llm=llm, agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
)
Tässä on pari esimerkkiä näiden työkalujen käytöstä:
- Luo Gmail-luonnos muokkausta varten:
agent.run( "Create a gmail draft for me to edit of a letter from the perspective of a sentient parrot " "who is looking to collaborate on some research with her estranged friend, a cat. " "Under no circumstances may you send the message, however."
)
- Etsi uusin sähköposti luonnoksistasi:
agent.run("Could you search in my drafts for the latest email?")
Nämä esimerkit osoittavat LangChainin Gmail-työkalupaketin ominaisuudet agentissa, jonka avulla voit olla vuorovaikutuksessa Gmailin kanssa ohjelmallisesti.
SQL-tietokantaagentti
Tämä osa tarjoaa yleiskatsauksen agentista, joka on suunniteltu vuorovaikutukseen SQL-tietokantojen, erityisesti Chinook-tietokannan, kanssa. Tämä agentti voi vastata yleisiin tietokantaa koskeviin kysymyksiin ja toipua virheistä. Huomaa, että se on edelleen aktiivisessa kehityksessä, eivätkä kaikki vastaukset välttämättä ole oikeita. Ole varovainen, kun käytät sitä arkaluontoisille tiedoille, koska se voi suorittaa DML-lauseita tietokannassasi.
Voit käyttää tätä agenttia alustamalla sen seuraavasti:
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.sql_database import SQLDatabase
from langchain.llms.openai import OpenAI
from langchain.agents import AgentExecutor
from langchain.agents.agent_types import AgentType
from langchain.chat_models import ChatOpenAI db = SQLDatabase.from_uri("sqlite:///../../../../../notebooks/Chinook.db")
toolkit = SQLDatabaseToolkit(db=db, llm=OpenAI(temperature=0)) agent_executor = create_sql_agent( llm=OpenAI(temperature=0), toolkit=toolkit, verbose=True, agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)
Tämä agentti voidaan alustaa käyttämällä ZERO_SHOT_REACT_DESCRIPTION agenttityyppi. Se on suunniteltu vastaamaan kysymyksiin ja tarjoamaan kuvauksia. Vaihtoehtoisesti voit alustaa agentin käyttämällä OPENAI_FUNCTIONS agenttityyppi OpenAI:n GPT-3.5-turbo-mallilla, jota käytimme aikaisemmassa asiakkaassamme.
Vastuun kieltäminen
- Kyselyketju voi luoda lisäys-/päivitys-/poistokyselyitä. Ole varovainen ja käytä mukautettua kehotetta tai luo tarvittaessa SQL-käyttäjä ilman kirjoitusoikeuksia.
- Huomaa, että tiettyjen kyselyiden suorittaminen, kuten "Suorita suurin mahdollinen kysely", voi ylikuormittaa SQL-tietokantaasi, varsinkin jos se sisältää miljoonia rivejä.
- Tietovarastopohjaiset tietokannat tukevat usein käyttäjätason kiintiöitä resurssien käytön rajoittamiseksi.
Voit pyytää agenttia kuvaamaan taulukkoa, kuten "soittolistaraita"-taulukkoa. Tässä on esimerkki kuinka se tehdään:
agent_executor.run("Describe the playlisttrack table")
Agentti antaa tietoja taulukon skeemasta ja esimerkkiriveistä.
Jos kysyt vahingossa taulukosta, jota ei ole olemassa, agentti voi palauttaa ja antaa tietoja lähimmästä vastaavasta taulukosta. Esimerkiksi:
agent_executor.run("Describe the playlistsong table")
Välittäjä löytää lähimmän hakutaulukon ja antaa siitä tiedot.
Voit myös pyytää agenttia suorittamaan kyselyitä tietokannassa. Esimerkiksi:
agent_executor.run("List the total sales per country. Which country's customers spent the most?")
Edustaja suorittaa kyselyn ja toimittaa tuloksen, kuten maan, jonka kokonaismyynti on suurin.
Voit käyttää seuraavaa kyselyä saadaksesi kunkin soittolistan kappaleiden kokonaismäärän:
agent_executor.run("Show the total number of tracks in each playlist. The Playlist name should be included in the result.")
Agentti palauttaa soittolistan nimet ja vastaavat kappaleiden kokonaismäärät.
Tapauksissa, joissa agentti kohtaa virheitä, se voi palautua ja antaa tarkkoja vastauksia. Esimerkiksi:
agent_executor.run("Who are the top 3 best selling artists?")
Jopa alkuperäisen virheen kohtaamisen jälkeen agentti säätää ja antaa oikean vastauksen, joka tässä tapauksessa on 3 myydyintä artistia.
Pandas DataFrame Agent
Tämä osio esittelee agentin, joka on suunniteltu vuorovaikutukseen Pandas DataFrame -kehyksien kanssa kysymyksiin vastaamista varten. Huomaa, että tämä agentti käyttää konepellin alla olevaa Python-agenttia kielimallin (LLM) luoman Python-koodin suorittamiseen. Ole varovainen käyttäessäsi tätä agenttia estääksesi LLM:n luoman haitallisen Python-koodin mahdolliset haitat.
Voit alustaa Pandas DataFrame -agentin seuraavasti:
from langchain_experimental.agents.agent_toolkits import create_pandas_dataframe_agent
from langchain.chat_models import ChatOpenAI
from langchain.agents.agent_types import AgentType from langchain.llms import OpenAI
import pandas as pd df = pd.read_csv("titanic.csv") # Using ZERO_SHOT_REACT_DESCRIPTION agent type
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), df, verbose=True) # Alternatively, using OPENAI_FUNCTIONS agent type
# agent = create_pandas_dataframe_agent(
# ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613"),
# df,
# verbose=True,
# agent_type=AgentType.OPENAI_FUNCTIONS,
# )
Voit pyytää agenttia laskemaan DataFramen rivien määrän:
agent.run("how many rows are there?")
Agentti suorittaa koodin df.shape[0] ja anna vastaus, kuten "Tietokehyksessä on 891 riviä".
Voit myös pyytää agenttia suodattamaan rivejä tiettyjen kriteerien perusteella, kuten sellaisten ihmisten määrän selvittämisessä, joilla on enemmän kuin kolme sisarusta:
agent.run("how many people have more than 3 siblings")
Agentti suorittaa koodin df[df['SibSp'] > 3].shape[0] ja anna vastaus, kuten "30 ihmisellä on enemmän kuin 3 sisarusta".
Jos haluat laskea keski-iän neliöjuuren, voit kysyä agentilta:
agent.run("whats the square root of the average age?")
Välittäjä laskee keski-iän käyttämällä df['Age'].mean() ja laske sitten neliöjuuri käyttämällä math.sqrt(). Se antaa vastauksen, kuten "Keski-iän neliöjuuri on 5.449689683556195."
Luodaan kopio DataFramesta, ja puuttuvat ikäarvot täytetään keski-iällä:
df1 = df.copy()
df1["Age"] = df1["Age"].fillna(df1["Age"].mean())
Sitten voit alustaa agentin molemmilla DataFrame-kehyksillä ja esittää sille kysymyksen:
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), [df, df1], verbose=True)
agent.run("how many rows in the age column are different?")
Agentti vertaa molempien DataFrame-kehysten ikäsarakkeita ja antaa vastauksen, kuten "Ikäsarakkeen 177 riviä ovat erilaisia."
Jira Toolkit
Tässä osiossa kerrotaan, kuinka käytetään Jira-työkalupakkia, jonka avulla agentit voivat olla vuorovaikutuksessa Jira-esiintymän kanssa. Tämän työkalupakin avulla voit suorittaa erilaisia toimintoja, kuten etsiä ongelmia ja luoda ongelmia. Se käyttää atlassian-python-api-kirjastoa. Jotta voit käyttää tätä työkalupakkia, sinun on asetettava ympäristömuuttujat Jira-instanssillesi, mukaan lukien JIRA_API_TOKEN, JIRA_USERNAME ja JIRA_INSTANCE_URL. Lisäksi saatat joutua asettamaan OpenAI API -avaimesi ympäristömuuttujaksi.
Aloita asentamalla atlassian-python-api-kirjasto ja määrittämällä tarvittavat ympäristömuuttujat:
%pip install atlassian-python-api import os
from langchain.agents import AgentType
from langchain.agents import initialize_agent
from langchain.agents.agent_toolkits.jira.toolkit import JiraToolkit
from langchain.llms import OpenAI
from langchain.utilities.jira import JiraAPIWrapper os.environ["JIRA_API_TOKEN"] = "abc"
os.environ["JIRA_USERNAME"] = "123"
os.environ["JIRA_INSTANCE_URL"] = "https://jira.atlassian.com"
os.environ["OPENAI_API_KEY"] = "xyz" llm = OpenAI(temperature=0)
jira = JiraAPIWrapper()
toolkit = JiraToolkit.from_jira_api_wrapper(jira)
agent = initialize_agent( toolkit.get_tools(), llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
Voit ohjeistaa agenttia luomaan uuden ongelman tiettyyn projektiin yhteenvedon ja kuvauksen avulla:
agent.run("make a new issue in project PW to remind me to make more fried rice")
Agentti suorittaa tarvittavat toimenpiteet ongelman luomiseksi ja vastauksen antamiseksi, kuten "Projektissa PW on luotu uusi numero, jossa on yhteenveto "Tee enemmän paistettua riisiä" ja kuvaus "Muistutus valmistaa enemmän paistettua riisiä".
Näin voit olla vuorovaikutuksessa Jira-esiintymän kanssa käyttämällä luonnollisen kielen ohjeita ja Jira-työkalupakkia.
Automatisoi manuaalisia tehtäviä ja työnkulkuja tekoälypohjaisella työnkulun rakentajallamme, jonka Nanonets on suunnitellut sinulle ja ryhmillesi.
Moduuli IV: Ketjut
LangChain on työkalu, joka on suunniteltu suurten kielimallien (LLM) hyödyntämiseen monimutkaisissa sovelluksissa. Se tarjoaa puitteet komponenttiketjujen luomiseen, mukaan lukien LLM:t ja muun tyyppiset komponentit. Kaksi ensisijaista kehystä
- LangChain Expression Language (LCEL)
- Legacy Chain käyttöliittymä
LangChain Expression Language (LCEL) on syntaksi, joka mahdollistaa ketjujen intuitiivisen kokoonpanon. Se tukee edistyneitä ominaisuuksia, kuten suoratoistoa, asynkronisia puheluita, eräajoa, rinnakkaistoimintoa, uudelleenyrityksiä, varatoimia ja jäljitystä. Voit esimerkiksi luoda kehotteen, mallin ja tulosteen jäsentimen LCEL:ssä seuraavan koodin mukaisesti:
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
prompt = ChatPromptTemplate.from_messages([ ("system", "You're a very knowledgeable historian who provides accurate and eloquent answers to historical questions."), ("human", "{question}")
])
runnable = prompt | model | StrOutputParser() for chunk in runnable.stream({"question": "What are the seven wonders of the world"}): print(chunk, end="", flush=True)
Vaihtoehtoisesti LLMChain on LCEL:n kaltainen vaihtoehto komponenttien muodostamiseen. LLMChain-esimerkki on seuraava:
from langchain.chains import LLMChain chain = LLMChain(llm=model, prompt=prompt, output_parser=StrOutputParser())
chain.run(question="What are the seven wonders of the world")
LangChainin ketjut voivat myös olla tilallisia sisällyttämällä niihin muistiobjektin. Tämä mahdollistaa tietojen pysyvyyden puheluissa, kuten tässä esimerkissä näkyy:
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory conversation = ConversationChain(llm=chat, memory=ConversationBufferMemory())
conversation.run("Answer briefly. What are the first 3 colors of a rainbow?")
conversation.run("And the next 4?")
LangChain tukee myös integraatiota OpenAI:n funktiokutsujen API:iden kanssa, mikä on hyödyllistä strukturoitujen tulosteiden hankkimisessa ja toimintojen suorittamisessa ketjussa. Strukturoitujen tulosteiden saamiseksi voit määrittää ne Pydantic-luokilla tai JsonSchemalla, kuten alla on kuvattu:
from langchain.pydantic_v1 import BaseModel, Field
from langchain.chains.openai_functions import create_structured_output_runnable
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate class Person(BaseModel): name: str = Field(..., description="The person's name") age: int = Field(..., description="The person's age") fav_food: Optional[str] = Field(None, description="The person's favorite food") llm = ChatOpenAI(model="gpt-4", temperature=0)
prompt = ChatPromptTemplate.from_messages([ # Prompt messages here
]) runnable = create_structured_output_runnable(Person, llm, prompt)
runnable.invoke({"input": "Sally is 13"})
Strukturoiduille ulostuloille on saatavilla myös vanha lähestymistapa LLMChainilla:
from langchain.chains.openai_functions import create_structured_output_chain class Person(BaseModel): name: str = Field(..., description="The person's name") age: int = Field(..., description="The person's age") chain = create_structured_output_chain(Person, llm, prompt, verbose=True)
chain.run("Sally is 13")
LangChain hyödyntää OpenAI-toimintoja luodakseen erilaisia erityisiä ketjuja eri tarkoituksiin. Näitä ovat poiminta-, koodaus-, OpenAPI- ja QA-ketjut viittauksilla.
Poiminnan yhteydessä prosessi on samanlainen kuin strukturoitu tuotantoketju, mutta keskittyy tiedon tai kokonaisuuden poimimiseen. Tunnisteita varten on ideana merkitä asiakirja luokilla, kuten tunne, kieli, tyyli, käsitellyt aiheet tai poliittinen suuntaus.
Esimerkki siitä, kuinka koodaus toimii LangChainissa, voidaan osoittaa Python-koodilla. Prosessi alkaa asentamalla tarvittavat paketit ja määrittämällä ympäristö:
pip install langchain openai
# Set env var OPENAI_API_KEY or load from a .env file:
# import dotenv
# dotenv.load_dotenv() from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import create_tagging_chain, create_tagging_chain_pydantic
Koodauksen skeema määritellään ja määritellään ominaisuudet ja niiden odotetut tyypit:
schema = { "properties": { "sentiment": {"type": "string"}, "aggressiveness": {"type": "integer"}, "language": {"type": "string"}, }
} llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
chain = create_tagging_chain(schema, llm)
Esimerkkejä merkintäketjun suorittamisesta eri syötteillä osoittavat mallin kyvyn tulkita tunteita, kieliä ja aggressiivisuutta:
inp = "Estoy increiblemente contento de haberte conocido! Creo que seremos muy buenos amigos!"
chain.run(inp)
# {'sentiment': 'positive', 'language': 'Spanish'} inp = "Estoy muy enojado con vos! Te voy a dar tu merecido!"
chain.run(inp)
# {'sentiment': 'enojado', 'aggressiveness': 1, 'language': 'es'}
Tarkempaa ohjausta varten skeema voidaan määritellä tarkemmin, mukaan lukien mahdolliset arvot, kuvaukset ja vaaditut ominaisuudet. Alla on esimerkki tästä parannetusta ohjauksesta:
schema = { "properties": { # Schema definitions here }, "required": ["language", "sentiment", "aggressiveness"],
} chain = create_tagging_chain(schema, llm)
Pydantisia skeemoja voidaan käyttää myös merkintäehtojen määrittämiseen, mikä tarjoaa Pythonic-tavan määrittää vaaditut ominaisuudet ja tyypit:
from enum import Enum
from pydantic import BaseModel, Field class Tags(BaseModel): # Class fields here chain = create_tagging_chain_pydantic(Tags, llm)
Lisäksi LangChainin metadatatunnistindokumenttimuuntajaa voidaan käyttää metatietojen poimimiseen LangChain Documentsista. Se tarjoaa samanlaisia toimintoja kuin merkintäketju, mutta sitä voidaan soveltaa LangChain-asiakirjaan.
Hakulähteiden lainaus on toinen LangChainin ominaisuus, joka käyttää OpenAI-funktioita lainausten poimimiseen tekstistä. Tämä näkyy seuraavassa koodissa:
from langchain.chains import create_citation_fuzzy_match_chain
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
chain = create_citation_fuzzy_match_chain(llm)
# Further code for running the chain and displaying results
LangChainissa ketjuttaminen Large Language Model (LLM) -sovelluksissa sisältää tyypillisesti kehotemallin yhdistämisen LLM:n ja valinnaisesti lähtöjäsennin kanssa. Suositeltu tapa tehdä tämä on LangChain Expression Language (LCEL) -kieli, vaikka myös vanhaa LLMChain-lähestymistapaa tuetaan.
Käyttämällä LCEL:ää BasePromptTemplate, BaseLanguageModel ja BaseOutputParser toteuttavat kaikki Runnable-rajapinnan, ja ne voidaan helposti yhdistää toisiinsa. Tässä on esimerkki tämän osoittamisesta:
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema import StrOutputParser prompt = PromptTemplate.from_template( "What is a good name for a company that makes {product}?"
)
runnable = prompt | ChatOpenAI() | StrOutputParser()
runnable.invoke({"product": "colorful socks"})
# Output: 'VibrantSocks'
LangChainin reititys mahdollistaa ei-determinististen ketjujen luomisen, joissa edellisen vaiheen tulos määrää seuraavan vaiheen. Tämä auttaa jäsentämään ja ylläpitämään johdonmukaisuutta vuorovaikutuksessa LLM:ien kanssa. Jos sinulla on esimerkiksi kaksi mallia, jotka on optimoitu erityyppisille kysymyksille, voit valita mallin käyttäjän syötteen perusteella.
Näin voit saavuttaa tämän käyttämällä LCEL:ää RunnableBranchin kanssa, joka alustetaan luettelolla (ehto, suoritettavissa olevista) pareista ja oletusajettavasta tiedostosta:
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableBranch
# Code for defining physics_prompt and math_prompt general_prompt = PromptTemplate.from_template( "You are a helpful assistant. Answer the question as accurately as you can.nn{input}"
)
prompt_branch = RunnableBranch( (lambda x: x["topic"] == "math", math_prompt), (lambda x: x["topic"] == "physics", physics_prompt), general_prompt,
) # More code for setting up the classifier and final chain
Lopullinen ketju muodostetaan sitten käyttämällä erilaisia komponentteja, kuten aiheluokittajaa, kehotteen haaraa ja lähtöjäsennintä, jotta voidaan määrittää kulku syötteen aiheen perusteella:
from operator import itemgetter
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough final_chain = ( RunnablePassthrough.assign(topic=itemgetter("input") | classifier_chain) | prompt_branch | ChatOpenAI() | StrOutputParser()
) final_chain.invoke( { "input": "What is the first prime number greater than 40 such that one plus the prime number is divisible by 3?" }
)
# Output: Detailed answer to the math question
Tämä lähestymistapa on esimerkki LangChainin joustavuudesta ja tehosta monimutkaisten kyselyjen käsittelyssä ja niiden reitittämisessä asianmukaisesti syötteen perusteella.
Kielimallien alueella yleinen käytäntö on seurata alkuperäistä kutsua sarjalla myöhempiä kutsuja käyttämällä yhden puhelun lähtöä seuraavan syötteenä. Tämä peräkkäinen lähestymistapa on erityisen hyödyllinen, kun haluat rakentaa aiemmissa vuorovaikutuksissa syntyneeseen tietoon. Vaikka LangChain Expression Language (LCEL) on suositeltu menetelmä näiden sekvenssien luomiseen, SequentialChain-menetelmä on edelleen dokumentoitu sen taaksepäin yhteensopivuuden vuoksi.
Tämän havainnollistamiseksi tarkastellaan skenaariota, jossa luomme ensin näytelmän synopsiksen ja sitten arvostelun sen perusteella. Pythonin käyttö langchain.prompts, luomme kaksi PromptTemplate tapaukset: yksi tiivistelmää ja toinen katsausta varten. Tässä on koodi näiden mallien määrittämiseksi:
from langchain.prompts import PromptTemplate synopsis_prompt = PromptTemplate.from_template( "You are a playwright. Given the title of play, it is your job to write a synopsis for that title.nnTitle: {title}nPlaywright: This is a synopsis for the above play:"
) review_prompt = PromptTemplate.from_template( "You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:"
)
LCEL-lähestymistavassa ketjutamme nämä kehotteet ChatOpenAI ja StrOutputParser luodaksesi sekvenssin, joka luo ensin yhteenvedon ja sitten katsauksen. Koodinpätkä on seuraava:
from langchain.chat_models import ChatOpenAI
from langchain.schema import StrOutputParser llm = ChatOpenAI()
chain = ( {"synopsis": synopsis_prompt | llm | StrOutputParser()} | review_prompt | llm | StrOutputParser()
)
chain.invoke({"title": "Tragedy at sunset on the beach"})
Jos tarvitsemme sekä yhteenvedon että arvostelun, voimme käyttää RunnablePassthrough luoda erillinen ketju jokaiselle ja yhdistää ne sitten:
from langchain.schema.runnable import RunnablePassthrough synopsis_chain = synopsis_prompt | llm | StrOutputParser()
review_chain = review_prompt | llm | StrOutputParser()
chain = {"synopsis": synopsis_chain} | RunnablePassthrough.assign(review=review_chain)
chain.invoke({"title": "Tragedy at sunset on the beach"})
Skenaarioissa, joissa on monimutkaisempia sarjoja, SequentialChain menetelmä tulee peliin. Tämä mahdollistaa useita tuloja ja lähtöjä. Harkitse tapausta, jossa tarvitsemme näytelmän nimeen ja aikakauteen perustuvan synopsiksen. Näin voimme määrittää sen:
from langchain.llms import OpenAI
from langchain.chains import LLMChain, SequentialChain
from langchain.prompts import PromptTemplate llm = OpenAI(temperature=0.7) synopsis_template = "You are a playwright. Given the title of play and the era it is set in, it is your job to write a synopsis for that title.nnTitle: {title}nEra: {era}nPlaywright: This is a synopsis for the above play:"
synopsis_prompt_template = PromptTemplate(input_variables=["title", "era"], template=synopsis_template)
synopsis_chain = LLMChain(llm=llm, prompt=synopsis_prompt_template, output_key="synopsis") review_template = "You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:"
prompt_template = PromptTemplate(input_variables=["synopsis"], template=review_template)
review_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="review") overall_chain = SequentialChain( chains=[synopsis_chain, review_chain], input_variables=["era", "title"], output_variables=["synopsis", "review"], verbose=True,
) overall_chain({"title": "Tragedy at sunset on the beach", "era": "Victorian England"})
Skenaarioissa, joissa haluat säilyttää kontekstin koko ketjussa tai ketjun myöhemmässä osassa, SimpleMemory voidaan käyttää. Tämä on erityisen hyödyllistä monimutkaisten syöttö-/lähtösuhteiden hallinnassa. Esimerkiksi tilanteessa, jossa haluamme luoda sosiaalisen median julkaisuja näytelmän nimen, aikakauden, tiivistelmän ja arvostelun perusteella, SimpleMemory voi auttaa hallitsemaan näitä muuttujia:
from langchain.memory import SimpleMemory
from langchain.chains import SequentialChain template = "You are a social media manager for a theater company. Given the title of play, the era it is set in, the date, time and location, the synopsis of the play, and the review of the play, it is your job to write a social media post for that play.nnHere is some context about the time and location of the play:nDate and Time: {time}nLocation: {location}nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:n{review}nnSocial Media Post:"
prompt_template = PromptTemplate(input_variables=["synopsis", "review", "time", "location"], template=template)
social_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="social_post_text") overall_chain = SequentialChain( memory=SimpleMemory(memories={"time": "December 25th, 8pm PST", "location": "Theater in the Park"}), chains=[synopsis_chain, review_chain, social_chain], input_variables=["era", "title"], output_variables=["social_post_text"], verbose=True,
) overall_chain({"title": "Tragedy at sunset on the beach", "era": "Victorian England"})
Peräkkäisten ketjujen lisäksi on olemassa erikoisketjuja asiakirjojen käsittelyyn. Kukin näistä ketjuista palvelee eri tarkoitusta asiakirjojen yhdistämisestä vastausten tarkentamiseen iteratiivisen asiakirja-analyysin perusteella, asiakirjan sisällön kartoittamiseen ja vähentämiseen yhteenvetoa tai uudelleenjärjestämistä varten pisteytettyjen vastausten perusteella. Nämä ketjut voidaan luoda uudelleen LCEL:n avulla lisäämään joustavuutta ja mukauttamista.
-
StuffDocumentsChainyhdistää asiakirjaluettelon yhdeksi LLM:lle lähetettäväksi kehotteeseen. -
RefineDocumentsChainpäivittää vastauksensa iteratiivisesti jokaiselle asiakirjalle, mikä sopii tehtäviin, joissa asiakirjat ylittävät mallin kontekstikapasiteetin. -
MapReduceDocumentsChainliittää ketjun jokaiseen asiakirjaan erikseen ja yhdistää sitten tulokset. -
MapRerankDocumentsChainpisteyttää jokaisen asiakirjapohjaisen vastauksen ja valitsee korkeimman pistemäärän.
Tässä on esimerkki siitä, kuinka voit määrittää a MapReduceDocumentsChain LCEL:llä:
from functools import partial
from langchain.chains.combine_documents import collapse_docs, split_list_of_docs
from langchain.schema import Document, StrOutputParser
from langchain.schema.prompt_template import format_document
from langchain.schema.runnable import RunnableParallel, RunnablePassthrough llm = ChatAnthropic()
document_prompt = PromptTemplate.from_template("{page_content}")
partial_format_document = partial(format_document, prompt=document_prompt) map_chain = ( {"context": partial_format_document} | PromptTemplate.from_template("Summarize this content:nn{context}") | llm | StrOutputParser()
) map_as_doc_chain = ( RunnableParallel({"doc": RunnablePassthrough(), "content": map_chain}) | (lambda x: Document(page_content=x["content"], metadata=x["doc"].metadata))
).with_config(run_name="Summarize (return doc)") def format_docs(docs): return "nn".join(partial_format_document(doc) for doc in docs) collapse_chain = ( {"context": format_docs} | PromptTemplate.from_template("Collapse this content:nn{context}") | llm | StrOutputParser()
) reduce_chain = ( {"context": format_docs} | PromptTemplate.from_template("Combine these summaries:nn{context}") | llm | StrOutputParser()
).with_config(run_name="Reduce") map_reduce = (map_as_doc_chain.map() | collapse | reduce_chain).with_config(run_name="Map reduce")
Tämä kokoonpano mahdollistaa asiakirjasisällön yksityiskohtaisen ja kattavan analyysin hyödyntäen LCEL:n ja sen taustalla olevan kielimallin vahvuuksia.
Automatisoi manuaalisia tehtäviä ja työnkulkuja tekoälypohjaisella työnkulun rakentajallamme, jonka Nanonets on suunnitellut sinulle ja ryhmillesi.
Moduuli V: Muisti
LangChainissa muisti on keskustelurajapintojen perustavanlaatuinen osa, jonka avulla järjestelmät voivat viitata menneisiin vuorovaikutuksiin. Tämä saavutetaan tallentamalla ja kyselemällä tietoja kahdella ensisijaisella toiminnolla: lukeminen ja kirjoittaminen. Muistijärjestelmä on vuorovaikutuksessa ketjun kanssa kahdesti ajon aikana, mikä lisää käyttäjän syötteitä ja tallentaa tulot ja lähdöt tulevaa tarvetta varten.
Muistin rakentaminen järjestelmäksi
- Chat-viestien tallentaminen: LangChain-muistimoduuli integroi erilaisia menetelmiä chat-viestien tallentamiseen, aina muistilistoista tietokantoihin. Tämä varmistaa, että kaikki chat-vuorovaikutukset tallennetaan myöhempää käyttöä varten.
- Chat-viestien kysely: Chat-viestien tallentamisen lisäksi LangChain käyttää tietorakenteita ja algoritmeja luodakseen hyödyllisen näkymän näistä viesteistä. Yksinkertaiset muistijärjestelmät saattavat palauttaa viimeaikaisia viestejä, kun taas edistyneemmät järjestelmät voivat tehdä yhteenvedon aiemmista vuorovaikutuksista tai keskittyä nykyisessä vuorovaikutuksessa mainittuihin entiteeteihin.
Jos haluat osoittaa muistin käytön LangChainissa, harkitse ConversationBufferMemory luokka, yksinkertainen muistilomake, joka tallentaa chat-viestit puskuriin. Tässä on esimerkki:
from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("Hello!")
memory.chat_memory.add_ai_message("How can I assist you?")
Muistia integroitaessa ketjuun on tärkeää ymmärtää muistista palautetut muuttujat ja kuinka niitä käytetään ketjussa. Esimerkiksi, load_memory_variables menetelmä auttaa kohdistamaan muistista luetut muuttujat ketjun odotuksiin.
Päästä päähän -esimerkki LangChainilla
Harkitse käyttöä ConversationBufferMemory vuonna LLMChain. Ketju yhdistettynä sopivaan kehotemalliin ja muistiin tarjoaa saumattoman keskustelukokemuksen. Tässä on yksinkertaistettu esimerkki:
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory llm = OpenAI(temperature=0)
template = "Your conversation template here..."
prompt = PromptTemplate.from_template(template)
memory = ConversationBufferMemory(memory_key="chat_history")
conversation = LLMChain(llm=llm, prompt=prompt, memory=memory) response = conversation({"question": "What's the weather like?"})
Tämä esimerkki havainnollistaa, kuinka LangChainin muistijärjestelmä integroituu ketjuihinsa tarjotakseen yhtenäisen ja kontekstuaalisesti tietoisen keskustelukokemuksen.
Muistityypit Langchainissa
Langchain tarjoaa erilaisia muistityyppejä, joita voidaan käyttää tehostamaan vuorovaikutusta tekoälymallien kanssa. Jokaisella muistityypillä on omat parametrinsa ja palautustyyppinsä, joten ne sopivat erilaisiin skenaarioihin. Tutkitaan joitain Langchainissa saatavilla olevia muistityyppejä koodiesimerkkien kanssa.
1. Keskustelupuskurimuisti
Tämän muistityypin avulla voit tallentaa ja poimia viestejä keskusteluista. Voit poimia historian merkkijonona tai viestiluettelona.
from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory()
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({}) # Extract history as a string
{'history': 'Human: hinAI: whats up'} # Extract history as a list of messages
{'history': [HumanMessage(content='hi', additional_kwargs={}), AIMessage(content='whats up', additional_kwargs={})]}
Voit myös käyttää keskustelupuskurimuistia ketjussa keskustelun kaltaiseen vuorovaikutukseen.
2. Keskustelupuskurin ikkunan muisti
Tämä muistityyppi pitää luettelon viimeaikaisista vuorovaikutuksista ja käyttää viimeisintä K vuorovaikutusta, mikä estää puskurin kasvamasta liian suureksi.
from langchain.memory import ConversationBufferWindowMemory memory = ConversationBufferWindowMemory(k=1)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
memory.load_memory_variables({}) {'history': 'Human: not much younAI: not much'}
Kuten keskustelupuskurimuisti, voit myös käyttää tätä muistityyppiä ketjussa keskustelun kaltaiseen vuorovaikutukseen.
3. Keskusteluyksikön muisti
Tämä muistityyppi muistaa tosiasiat tietyistä keskustelun kokonaisuuksista ja poimii tiedot LLM:n avulla.
from langchain.memory import ConversationEntityMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationEntityMemory(llm=llm)
_input = {"input": "Deven & Sam are working on a hackathon project"}
memory.load_memory_variables(_input)
memory.save_context( _input, {"output": " That sounds like a great project! What kind of project are they working on?"}
)
memory.load_memory_variables({"input": 'who is Sam'}) {'history': 'Human: Deven & Sam are working on a hackathon projectnAI: That sounds like a great project! What kind of project are they working on?', 'entities': {'Sam': 'Sam is working on a hackathon project with Deven.'}}
4. Keskustelutietokaavion muisti
Tämä muistityyppi käyttää tietokaaviota muistin luomiseen. Voit poimia viesteistä nykyiset entiteetit ja tietotriplet.
from langchain.memory import ConversationKGMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationKGMemory(llm=llm)
memory.save_context({"input": "say hi to sam"}, {"output": "who is sam"})
memory.save_context({"input": "sam is a friend"}, {"output": "okay"})
memory.load_memory_variables({"input": "who is sam"}) {'history': 'On Sam: Sam is friend.'}
Voit myös käyttää tätä muistityyppiä ketjussa keskustelupohjaiseen tiedonhakuun.
5. Keskustelun yhteenvetomuisti
Tämä muistityyppi luo keskustelusta ajan mittaan yhteenvedon, joka on hyödyllinen pitkien keskustelujen tietojen tiivistämiseen.
from langchain.memory import ConversationSummaryMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationSummaryMemory(llm=llm)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({}) {'history': 'nThe human greets the AI, to which the AI responds.'}
6. Keskustelun yhteenveto Puskurimuisti
Tämä muistityyppi yhdistää keskustelun yhteenvedon ja puskurin säilyttäen tasapainon viimeaikaisten vuorovaikutusten ja yhteenvedon välillä. Se käyttää tunnuksen pituutta määrittääkseen, milloin vuorovaikutukset on huuhdeltava.
from langchain.memory import ConversationSummaryBufferMemory
from langchain.llms import OpenAI llm = OpenAI()
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
memory.load_memory_variables({}) {'history': 'System: nThe human says "hi", and the AI responds with "whats up".nHuman: not much younAI: not much'}
Voit käyttää näitä muistityyppejä parantaaksesi vuorovaikutustasi Langchainin tekoälymallien kanssa. Jokainen muistityyppi palvelee tiettyä tarkoitusta ja voidaan valita tarpeidesi mukaan.
7. Keskustelumerkkipuskurimuisti
ConversationTokenBufferMemory on toinen muistityyppi, joka säilyttää puskurin viimeaikaisista vuorovaikutuksista muistissa. Toisin kuin aiemmat muistityypit, jotka keskittyvät vuorovaikutusten määrään, tämä käyttää tunnuksen pituutta määrittämään, milloin vuorovaikutukset on tyhjennettävä.
Muistin käyttö LLM:n kanssa:
from langchain.memory import ConversationTokenBufferMemory
from langchain.llms import OpenAI llm = OpenAI() memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"}) memory.load_memory_variables({}) {'history': 'Human: not much younAI: not much'}
Tässä esimerkissä muisti on asetettu rajoittamaan vuorovaikutuksia vuorovaikutusten lukumäärän sijaan tunnuksen pituuden perusteella.
Voit myös saada historian viestiluettelona, kun käytät tätä muistityyppiä.
memory = ConversationTokenBufferMemory( llm=llm, max_token_limit=10, return_messages=True
)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
Käyttö ketjussa:
Voit käyttää ConversationTokenBufferMemorya ketjussa tehostaaksesi vuorovaikutusta tekoälymallin kanssa.
from langchain.chains import ConversationChain conversation_with_summary = ConversationChain( llm=llm, # We set a very low max_token_limit for the purposes of testing. memory=ConversationTokenBufferMemory(llm=OpenAI(), max_token_limit=60), verbose=True,
)
conversation_with_summary.predict(input="Hi, what's up?")
Tässä esimerkissä ConversationTokenBufferMemorya käytetään ConversationChainissa keskustelun hallintaan ja vuorovaikutusten rajoittamiseen tunnuksen pituuden perusteella.
8. VectorStoreRetrieverMemory
VectorStoreRetrieverMemory tallentaa muistot vektorisäilöön ja kyselee K:n "merkittävintä" dokumenttia aina, kun sitä kutsutaan. Tämä muistityyppi ei nimenomaisesti seuraa vuorovaikutusten järjestystä, mutta käyttää vektorihakua relevanttien muistojen hakemiseen.
from datetime import datetime
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.memory import VectorStoreRetrieverMemory
from langchain.chains import ConversationChain
from langchain.prompts import PromptTemplate # Initialize your vector store (specifics depend on the chosen vector store)
import faiss
from langchain.docstore import InMemoryDocstore
from langchain.vectorstores import FAISS embedding_size = 1536 # Dimensions of the OpenAIEmbeddings
index = faiss.IndexFlatL2(embedding_size)
embedding_fn = OpenAIEmbeddings().embed_query
vectorstore = FAISS(embedding_fn, index, InMemoryDocstore({}), {}) # Create your VectorStoreRetrieverMemory
retriever = vectorstore.as_retriever(search_kwargs=dict(k=1))
memory = VectorStoreRetrieverMemory(retriever=retriever) # Save context and relevant information to the memory
memory.save_context({"input": "My favorite food is pizza"}, {"output": "that's good to know"})
memory.save_context({"input": "My favorite sport is soccer"}, {"output": "..."})
memory.save_context({"input": "I don't like the Celtics"}, {"output": "ok"}) # Retrieve relevant information from memory based on a query
print(memory.load_memory_variables({"prompt": "what sport should i watch?"})["history"])
Tässä esimerkissä VectorStoreRetrieverMemorya käytetään tallentamaan ja hakemaan oleellisia tietoja keskustelusta vektorihaun perusteella.
Voit myös käyttää VectorStoreRetrieverMemorya ketjussa keskustelupohjaiseen tiedonhakuun, kuten edellisissä esimerkeissä näkyy.
Nämä Langchainin erilaiset muistityypit tarjoavat erilaisia tapoja hallita ja hakea tietoja keskusteluista, mikä parantaa tekoälymallien kykyä ymmärtää käyttäjien kyselyitä ja kontekstia ja vastata niihin. Jokainen muistityyppi voidaan valita sovelluksesi erityisvaatimusten mukaan.
Nyt opimme käyttämään muistia LLMChainin kanssa. Muisti LLMC-ketjussa mahdollistaa mallin muistaa aikaisemmat vuorovaikutukset ja kontekstin tarjotakseen johdonmukaisempia ja kontekstitietoisempia vastauksia.
Muistin määrittämiseksi LLMChainissa sinun on luotava muistiluokka, kuten ConversationBufferMemory. Näin voit määrittää sen:
from langchain.chains import LLMChain
from langchain.llms import OpenAI
from langchain.memory import ConversationBufferMemory
from langchain.prompts import PromptTemplate template = """You are a chatbot having a conversation with a human. {chat_history}
Human: {human_input}
Chatbot:""" prompt = PromptTemplate( input_variables=["chat_history", "human_input"], template=template
)
memory = ConversationBufferMemory(memory_key="chat_history") llm = OpenAI()
llm_chain = LLMChain( llm=llm, prompt=prompt, verbose=True, memory=memory,
) llm_chain.predict(human_input="Hi there my friend")
Tässä esimerkissä ConversationBufferMemory-muistia käytetään keskusteluhistorian tallentamiseen. The memory_key parametri määrittää avaimen, jota käytetään keskusteluhistorian tallentamiseen.
Jos käytät chat-mallia valmistumismallin sijaan, voit jäsentää kehotteet eri tavalla hyödyntääksesi paremmin muistia. Tässä on esimerkki keskustelumallipohjaisen LLMChainin määrittämisestä muistilla:
from langchain.chat_models import ChatOpenAI
from langchain.schema import SystemMessage
from langchain.prompts import ( ChatPromptTemplate, HumanMessagePromptTemplate, MessagesPlaceholder,
) # Create a ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages( [ SystemMessage( content="You are a chatbot having a conversation with a human." ), # The persistent system prompt MessagesPlaceholder( variable_name="chat_history" ), # Where the memory will be stored. HumanMessagePromptTemplate.from_template( "{human_input}" ), # Where the human input will be injected ]
) memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True) llm = ChatOpenAI() chat_llm_chain = LLMChain( llm=llm, prompt=prompt, verbose=True, memory=memory,
) chat_llm_chain.predict(human_input="Hi there my friend")
Tässä esimerkissä ChatPromptTemplatea käytetään kehotteen jäsentämiseen ja ConversationBufferMemory-muistia keskusteluhistorian tallentamiseen ja hakemiseen. Tämä lähestymistapa on erityisen hyödyllinen chat-tyylisissä keskusteluissa, joissa kontekstilla ja historialla on ratkaiseva rooli.
Muistia voidaan myös lisätä ketjuun, jossa on useita syötteitä, kuten kysymys/vastausketju. Tässä on esimerkki muistin määrittämisestä kysymys/vastausketjussa:
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.embeddings.cohere import CohereEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
from langchain.vectorstores import Chroma
from langchain.docstore.document import Document
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.memory import ConversationBufferMemory # Split a long document into smaller chunks
with open("../../state_of_the_union.txt") as f: state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union) # Create an ElasticVectorSearch instance to index and search the document chunks
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_texts( texts, embeddings, metadatas=[{"source": i} for i in range(len(texts))]
) # Perform a question about the document
query = "What did the president say about Justice Breyer"
docs = docsearch.similarity_search(query) # Set up a prompt for the question-answering chain with memory
template = """You are a chatbot having a conversation with a human. Given the following extracted parts of a long document and a question, create a final answer. {context} {chat_history}
Human: {human_input}
Chatbot:""" prompt = PromptTemplate( input_variables=["chat_history", "human_input", "context"], template=template
)
memory = ConversationBufferMemory(memory_key="chat_history", input_key="human_input")
chain = load_qa_chain( OpenAI(temperature=0), chain_type="stuff", memory=memory, prompt=prompt
) # Ask the question and retrieve the answer
query = "What did the president say about Justice Breyer"
result = chain({"input_documents": docs, "human_input": query}, return_only_outputs=True) print(result)
print(chain.memory.buffer)
Tässä esimerkissä kysymykseen vastataan käyttämällä asiakirjaa, joka on jaettu pienempiin osiin. ConversationBufferMemory-muistia käytetään keskusteluhistorian tallentamiseen ja hakemiseen, jolloin malli voi tarjota kontekstitietoisia vastauksia.
Muistin lisääminen agenttiin antaa sen muistaa ja käyttää aikaisempia vuorovaikutuksia kysymyksiin vastaamiseen ja kontekstitietoisten vastausten antamiseen. Voit määrittää agentin muistin seuraavasti:
from langchain.agents import ZeroShotAgent, Tool, AgentExecutor
from langchain.memory import ConversationBufferMemory
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.utilities import GoogleSearchAPIWrapper # Create a tool for searching
search = GoogleSearchAPIWrapper()
tools = [ Tool( name="Search", func=search.run, description="useful for when you need to answer questions about current events", )
] # Create a prompt with memory
prefix = """Have a conversation with a human, answering the following questions as best you can. You have access to the following tools:"""
suffix = """Begin!" {chat_history}
Question: {input}
{agent_scratchpad}""" prompt = ZeroShotAgent.create_prompt( tools, prefix=prefix, suffix=suffix, input_variables=["input", "chat_history", "agent_scratchpad"],
)
memory = ConversationBufferMemory(memory_key="chat_history") # Create an LLMChain with memory
llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=prompt)
agent = ZeroShotAgent(llm_chain=llm_chain, tools=tools, verbose=True)
agent_chain = AgentExecutor.from_agent_and_tools( agent=agent, tools=tools, verbose=True, memory=memory
) # Ask a question and retrieve the answer
response = agent_chain.run(input="How many people live in Canada?")
print(response) # Ask a follow-up question
response = agent_chain.run(input="What is their national anthem called?")
print(response)
Tässä esimerkissä agenttiin lisätään muistia, jolloin se muistaa edellisen keskusteluhistorian ja antaa kontekstitietoisia vastauksia. Tämä antaa agentille mahdollisuuden vastata seurantakysymyksiin tarkasti muistiin tallennettujen tietojen perusteella.
LangChain Expression Language
Luonnollisen kielenkäsittelyn ja koneoppimisen maailmassa monimutkaisten toimintaketjujen muodostaminen voi olla pelottavaa. Onneksi LangChain Expression Language (LCEL) tulee apuun ja tarjoaa ilmoittavan ja tehokkaan tavan kehittää ja ottaa käyttöön kehittyneitä kielenkäsittelyputkia. LCEL on suunniteltu yksinkertaistamaan ketjujen muodostamisprosessia, mikä mahdollistaa helpon siirtymisen prototyypeistä tuotantoon. Tässä blogissa tutkimme, mitä LCEL on ja miksi saatat haluta käyttää sitä, sekä käytännön koodiesimerkkejä havainnollistamaan sen ominaisuuksia.
LCEL tai LangChain Expression Language on tehokas työkalu kieltenkäsittelyketjujen muodostamiseen. Se on suunniteltu tukemaan siirtymistä prototyyppien valmistuksesta tuotantoon saumattomasti ilman laajoja koodimuutoksia. Olitpa rakentamassa yksinkertaista "prompt + LLM" -ketjua tai monimutkaista satoja vaiheita sisältävää putkistoa, LCEL tarjoaa sinulle kaiken.
Tässä on joitain syitä käyttää LCEL:ää kieltenkäsittelyprojekteissasi:
- Nopea Token Streaming: LCEL toimittaa tunnuksia kielimallista lähtöjäsentäjään reaaliajassa, mikä parantaa reagointikykyä ja tehokkuutta.
- Monipuoliset API:t: LCEL tukee sekä synkronisia että asynkronisia API:ita prototyyppien luomiseen ja tuotantokäyttöön ja käsittelee useita pyyntöjä tehokkaasti.
- Automaattinen rinnakkaiskytkentä: LCEL optimoi rinnakkaissuorituksen mahdollisuuksien mukaan vähentäen latenssia sekä synkronoiduissa että asynkronisissa liitännöissä.
- Luotettavat kokoonpanot: Määritä uudelleenyritykset ja varakäynnit parantaaksesi ketjun luotettavuutta laajassa mittakaavassa, kun kehitetään suoratoistotukea.
- Stream Intermediate Results: Käytä välituloksia käsittelyn aikana käyttäjien päivityksiä tai virheenkorjausta varten.
- Kaavioiden luominen: LCEL luo Pydantic- ja JSONSchema-skeemoja syötteiden ja tulosten validointia varten.
- Kattava jäljitys: LangSmith jäljittää automaattisesti kaikki vaiheet monimutkaisissa ketjuissa havainnointia ja virheenkorjausta varten.
- Helppo käyttöönotto: Ota LCEL:n luomat ketjut käyttöön vaivattomasti LangServen avulla.
Sukellaan nyt käytännön koodiesimerkkeihin, jotka osoittavat LCEL:n tehon. Tutkimme yleisiä tehtäviä ja skenaarioita, joissa LCEL loistaa.
Kehote + LLM
Kaikkein perustavanlaatuisin kokoonpano sisältää kehotteen ja kielimallin yhdistämisen ketjun luomiseksi, joka ottaa käyttäjän syötteen, lisää sen kehotteeseen, välittää sen mallille ja palauttaa mallin raakatulosteen. Tässä on esimerkki:
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI prompt = ChatPromptTemplate.from_template("tell me a joke about {foo}")
model = ChatOpenAI()
chain = prompt | model result = chain.invoke({"foo": "bears"})
print(result)
Tässä esimerkissä ketju tuottaa vitsin karhuista.
Voit liittää ketjuun lopetussarjoja ohjataksesi tekstin käsittelyä. Esimerkiksi:
chain = prompt | model.bind(stop=["n"])
result = chain.invoke({"foo": "bears"})
print(result)
Tämä kokoonpano pysäyttää tekstin luomisen, kun rivinvaihtomerkki havaitaan.
LCEL tukee toimintokutsutietojen liittämistä ketjuun. Tässä on esimerkki:
functions = [ { "name": "joke", "description": "A joke", "parameters": { "type": "object", "properties": { "setup": {"type": "string", "description": "The setup for the joke"}, "punchline": { "type": "string", "description": "The punchline for the joke", }, }, "required": ["setup", "punchline"], }, }
]
chain = prompt | model.bind(function_call={"name": "joke"}, functions=functions)
result = chain.invoke({"foo": "bears"}, config={})
print(result)
Tämä esimerkki liittää funktiokutsutiedot vitsin luomiseksi.
Prompt + LLM + OutputParser
Voit lisätä tulosten jäsentimen muuntaaksesi raakamallin tulosteen toimivampaan muotoon. Näin voit tehdä sen:
from langchain.schema.output_parser import StrOutputParser chain = prompt | model | StrOutputParser()
result = chain.invoke({"foo": "bears"})
print(result)
Tulos on nyt merkkijonomuodossa, mikä on kätevämpää loppupään tehtäviin.
Kun määrität palautettavan funktion, voit jäsentää sen suoraan LCEL:llä. Esimerkiksi:
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser chain = ( prompt | model.bind(function_call={"name": "joke"}, functions=functions) | JsonOutputFunctionsParser()
)
result = chain.invoke({"foo": "bears"})
print(result)
Tämä esimerkki jäsentää "vitsi"-funktion tulostuksen suoraan.
Nämä ovat vain muutamia esimerkkejä siitä, kuinka LCEL yksinkertaistaa monimutkaisia kielenkäsittelytehtäviä. Rakennat sitten chatbotteja, luot sisältöä tai suoritat monimutkaisia tekstimuunnoksia, LCEL voi virtaviivaistaa työnkulkuasi ja tehdä koodistasi helpommin ylläpidettävän.
RAG (Retrieval-augmented Generation)
LCEL:n avulla voidaan luoda haulla lisättyjä sukupolviketjuja, joissa yhdistyvät haun ja kielen luontivaiheet. Tässä on esimerkki:
from operator import itemgetter from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.vectorstores import FAISS # Create a vector store and retriever
vectorstore = FAISS.from_texts( ["harrison worked at kensho"], embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever() # Define templates for prompts
template = """Answer the question based only on the following context:
{context} Question: {question} """
prompt = ChatPromptTemplate.from_template(template) model = ChatOpenAI() # Create a retrieval-augmented generation chain
chain = ( {"context": retriever, "question": RunnablePassthrough()} | prompt | model | StrOutputParser()
) result = chain.invoke("where did harrison work?")
print(result)
Tässä esimerkissä ketju hakee oleellista tietoa kontekstista ja luo vastauksen kysymykseen.
Keskustelujen hakuketju
Voit helposti lisätä keskusteluhistoriaa ketjuihisi. Tässä on esimerkki keskustelun hakuketjusta:
from langchain.schema.runnable import RunnableMap
from langchain.schema import format_document from langchain.prompts.prompt import PromptTemplate # Define templates for prompts
_template = """Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question, in its original language. Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:"""
CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template(_template) template = """Answer the question based only on the following context:
{context} Question: {question} """
ANSWER_PROMPT = ChatPromptTemplate.from_template(template) # Define input map and context
_inputs = RunnableMap( standalone_question=RunnablePassthrough.assign( chat_history=lambda x: _format_chat_history(x["chat_history"]) ) | CONDENSE_QUESTION_PROMPT | ChatOpenAI(temperature=0) | StrOutputParser(),
)
_context = { "context": itemgetter("standalone_question") | retriever | _combine_documents, "question": lambda x: x["standalone_question"],
}
conversational_qa_chain = _inputs | _context | ANSWER_PROMPT | ChatOpenAI() result = conversational_qa_chain.invoke( { "question": "where did harrison work?", "chat_history": [], }
)
print(result)
Tässä esimerkissä ketju käsittelee jatkokysymystä keskustelukontekstissa.
Muisti ja palautuslähdeasiakirjat
LCEL tukee myös muistia ja lähdeasiakirjojen palauttamista. Näin voit käyttää muistia ketjussa:
from operator import itemgetter
from langchain.memory import ConversationBufferMemory # Create a memory instance
memory = ConversationBufferMemory( return_messages=True, output_key="answer", input_key="question"
) # Define steps for the chain
loaded_memory = RunnablePassthrough.assign( chat_history=RunnableLambda(memory.load_memory_variables) | itemgetter("history"),
) standalone_question = { "standalone_question": { "question": lambda x: x["question"], "chat_history": lambda x: _format_chat_history(x["chat_history"]), } | CONDENSE_QUESTION_PROMPT | ChatOpenAI(temperature=0) | StrOutputParser(),
} retrieved_documents = { "docs": itemgetter("standalone_question") | retriever, "question": lambda x: x["standalone_question"],
} final_inputs = { "context": lambda x: _combine_documents(x["docs"]), "question": itemgetter("question"),
} answer = { "answer": final_inputs | ANSWER_PROMPT | ChatOpenAI(), "docs": itemgetter("docs"),
} # Create the final chain by combining the steps
final_chain = loaded_memory | standalone_question | retrieved_documents | answer inputs = {"question": "where did harrison work?"}
result = final_chain.invoke(inputs)
print(result)
Tässä esimerkissä muistia käytetään keskusteluhistorian ja lähdeasiakirjojen tallentamiseen ja hakemiseen.
Useita ketjuja
Voit yhdistää useita ketjuja Runnablesin avulla. Tässä on esimerkki:
from operator import itemgetter from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser prompt1 = ChatPromptTemplate.from_template("what is the city {person} is from?")
prompt2 = ChatPromptTemplate.from_template( "what country is the city {city} in? respond in {language}"
) model = ChatOpenAI() chain1 = prompt1 | model | StrOutputParser() chain2 = ( {"city": chain1, "language": itemgetter("language")} | prompt2 | model | StrOutputParser()
) result = chain2.invoke({"person": "obama", "language": "spanish"})
print(result)
Tässä esimerkissä kaksi ketjua yhdistetään luomaan tietoa kaupungista ja sen maasta tietyllä kielellä.
Haaroittuminen ja yhdistäminen
LCEL mahdollistaa ketjujen jakamisen ja yhdistämisen RunnableMapsin avulla. Tässä on esimerkki haarautumisesta ja yhdistämisestä:
from operator import itemgetter from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser planner = ( ChatPromptTemplate.from_template("Generate an argument about: {input}") | ChatOpenAI() | StrOutputParser() | {"base_response": RunnablePassthrough()}
) arguments_for = ( ChatPromptTemplate.from_template( "List the pros or positive aspects of {base_response}" ) | ChatOpenAI() | StrOutputParser()
)
arguments_against = ( ChatPromptTemplate.from_template( "List the cons or negative aspects of {base_response}" ) | ChatOpenAI() | StrOutputParser()
) final_responder = ( ChatPromptTemplate.from_messages( [ ("ai", "{original_response}"), ("human", "Pros:n{results_1}nnCons:n{results_2}"), ("system", "Generate a final response given the critique"), ] ) | ChatOpenAI() | StrOutputParser()
) chain = ( planner | { "results_1": arguments_for, "results_2": arguments_against, "original_response": itemgetter("base_response"), } | final_responder
) result = chain.invoke({"input": "scrum"})
print(result)
Tässä esimerkissä haarautuvaa ja yhdistävää ketjua käytetään argumentin luomiseen ja sen edut ja haitat arvioimiseen ennen lopullisen vastauksen luomista.
Python-koodin kirjoittaminen LCEL:llä
Yksi LangChain Expression Language (LCEL) -sovelluksista on Python-koodin kirjoittaminen käyttäjien ongelmien ratkaisemiseksi. Alla on esimerkki LCEL:n käyttämisestä Python-koodin kirjoittamiseen:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain_experimental.utilities import PythonREPL template = """Write some python code to solve the user's problem. Return only python code in Markdown format, e.g.: ```python
....
```"""
prompt = ChatPromptTemplate.from_messages([("system", template), ("human", "{input}")]) model = ChatOpenAI() def _sanitize_output(text: str): _, after = text.split("```python") return after.split("```")[0] chain = prompt | model | StrOutputParser() | _sanitize_output | PythonREPL().run result = chain.invoke({"input": "what's 2 plus 2"})
print(result)
Tässä esimerkissä käyttäjä antaa syötteen, ja LCEL luo Python-koodin ongelman ratkaisemiseksi. Koodi suoritetaan sitten käyttämällä Python REPL:ää ja tuloksena saatu Python-koodi palautetaan Markdown-muodossa.
Huomaa, että Python REPL:n käyttäminen voi suorittaa mielivaltaisen koodin, joten käytä sitä varoen.
Muistin lisääminen ketjuun
Muisti on välttämätön monissa keskustelupohjaisissa tekoälysovelluksissa. Näin lisäät muistia mielivaltaiseen ketjuun:
from operator import itemgetter
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder model = ChatOpenAI()
prompt = ChatPromptTemplate.from_messages( [ ("system", "You are a helpful chatbot"), MessagesPlaceholder(variable_name="history"), ("human", "{input}"), ]
) memory = ConversationBufferMemory(return_messages=True) # Initialize memory
memory.load_memory_variables({}) chain = ( RunnablePassthrough.assign( history=RunnableLambda(memory.load_memory_variables) | itemgetter("history") ) | prompt | model
) inputs = {"input": "hi, I'm Bob"}
response = chain.invoke(inputs)
response # Save the conversation in memory
memory.save_context(inputs, {"output": response.content}) # Load memory to see the conversation history
memory.load_memory_variables({})
Tässä esimerkissä muistia käytetään keskusteluhistorian tallentamiseen ja hakemiseen, jolloin chatbot voi ylläpitää kontekstia ja vastata asianmukaisesti.
Ulkoisten työkalujen käyttö Runnablesissa
LCEL:n avulla voit integroida ulkoiset työkalut saumattomasti Runnablesiin. Tässä on esimerkki DuckDuckGo-hakutyökalusta:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.tools import DuckDuckGoSearchRun search = DuckDuckGoSearchRun() template = """Turn the following user input into a search query for a search engine: {input}"""
prompt = ChatPromptTemplate.from_template(template) model = ChatOpenAI() chain = prompt | model | StrOutputParser() | search search_result = chain.invoke({"input": "I'd like to figure out what games are tonight"})
print(search_result)
Tässä esimerkissä LCEL integroi DuckDuckGo Search -työkalun ketjuun, jolloin se voi luoda hakukyselyn käyttäjän syötteestä ja hakea hakutuloksia.
LCEL:n joustavuuden ansiosta on helppo sisällyttää erilaisia ulkoisia työkaluja ja palveluita kielenkäsittelyputkiin, mikä parantaa niiden ominaisuuksia ja toimivuutta.
Moderoinnin lisääminen LLM-sovellukseen
Varmistaaksesi, että LLM-sovelluksesi noudattaa sisältökäytäntöjä ja sisältää valvontasuojat, voit integroida moderointitarkistukset ketjuusi. Voit lisätä moderoinnin LangChainilla seuraavasti:
from langchain.chains import OpenAIModerationChain
from langchain.llms import OpenAI
from langchain.prompts import ChatPromptTemplate moderate = OpenAIModerationChain() model = OpenAI()
prompt = ChatPromptTemplate.from_messages([("system", "repeat after me: {input}")]) chain = prompt | model # Original response without moderation
response_without_moderation = chain.invoke({"input": "you are stupid"})
print(response_without_moderation) moderated_chain = chain | moderate # Response after moderation
response_after_moderation = moderated_chain.invoke({"input": "you are stupid"})
print(response_after_moderation)
Tässä esimerkissä OpenAIModerationChain käytetään lisäämään maltillisuutta LLM:n luomaan vastaukseen. Valvontaketju tarkistaa vastauksen sisällön, joka rikkoo OpenAI:n sisältökäytäntöä. Jos rikkomuksia havaitaan, se ilmoittaa vastauksesta vastaavasti.
Reititys semanttisen samankaltaisuuden mukaan
LCEL mahdollistaa mukautetun reitityslogiikan toteuttamisen käyttäjän syötteiden semanttisen samankaltaisuuden perusteella. Tässä on esimerkki ketjulogiikan määrittämisestä dynaamisesti käyttäjän syötteen perusteella:
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import PromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableLambda, RunnablePassthrough
from langchain.utils.math import cosine_similarity physics_template = """You are a very smart physics professor. You are great at answering questions about physics in a concise and easy to understand manner. When you don't know the answer to a question you admit that you don't know. Here is a question:
{query}""" math_template = """You are a very good mathematician. You are great at answering math questions. You are so good because you are able to break down hard problems into their component parts, answer the component parts, and then put them together to answer the broader question. Here is a question:
{query}""" embeddings = OpenAIEmbeddings()
prompt_templates = [physics_template, math_template]
prompt_embeddings = embeddings.embed_documents(prompt_templates) def prompt_router(input): query_embedding = embeddings.embed_query(input["query"]) similarity = cosine_similarity([query_embedding], prompt_embeddings)[0] most_similar = prompt_templates[similarity.argmax()] print("Using MATH" if most_similar == math_template else "Using PHYSICS") return PromptTemplate.from_template(most_similar) chain = ( {"query": RunnablePassthrough()} | RunnableLambda(prompt_router) | ChatOpenAI() | StrOutputParser()
) print(chain.invoke({"query": "What's a black hole"}))
print(chain.invoke({"query": "What's a path integral"}))
Tässä esimerkissä prompt_router funktio laskee kosinin samankaltaisuuden käyttäjän syötteen ja fysiikan ja matematiikan kysymysten ennalta määritettyjen kehotemallien välillä. Samankaltaisuuspisteiden perusteella ketju valitsee dynaamisesti osuvimman kehotemallin ja varmistaa, että chatbot vastaa asianmukaisesti käyttäjän kysymykseen.
Agenttien ja juoksujen käyttäminen
LangChainin avulla voit luoda agentteja yhdistämällä Runnables, kehotteet, mallit ja työkalut. Tässä on esimerkki agentin rakentamisesta ja sen käytöstä:
from langchain.agents import XMLAgent, tool, AgentExecutor
from langchain.chat_models import ChatAnthropic model = ChatAnthropic(model="claude-2") @tool
def search(query: str) -> str: """Search things about current events.""" return "32 degrees" tool_list = [search] # Get prompt to use
prompt = XMLAgent.get_default_prompt() # Logic for going from intermediate steps to a string to pass into the model
def convert_intermediate_steps(intermediate_steps): log = "" for action, observation in intermediate_steps: log += ( f"<tool>{action.tool}</tool><tool_input>{action.tool_input}" f"</tool_input><observation>{observation}</observation>" ) return log # Logic for converting tools to a string to go in the prompt
def convert_tools(tools): return "n".join([f"{tool.name}: {tool.description}" for tool in tools]) agent = ( { "question": lambda x: x["question"], "intermediate_steps": lambda x: convert_intermediate_steps( x["intermediate_steps"] ), } | prompt.partial(tools=convert_tools(tool_list)) | model.bind(stop=["</tool_input>", "</final_answer>"]) | XMLAgent.get_default_output_parser()
) agent_executor = AgentExecutor(agent=agent, tools=tool_list, verbose=True) result = agent_executor.invoke({"question": "What's the weather in New York?"})
print(result)
Tässä esimerkissä agentti luodaan yhdistämällä malli, työkalut, kehote ja mukautettu logiikka välivaiheita ja työkalun muuntamista varten. Agentti suoritetaan tämän jälkeen ja antaa vastauksen käyttäjän kyselyyn.
Kyselyt SQL-tietokannasta
LangChainilla voit tehdä kyselyitä SQL-tietokannasta ja luoda SQL-kyselyjä käyttäjien kysymyksiin perustuen. Tässä on esimerkki:
from langchain.prompts import ChatPromptTemplate template = """Based on the table schema below, write a SQL query that would answer the user's question:
{schema} Question: {question}
SQL Query:"""
prompt = ChatPromptTemplate.from_template(template) from langchain.utilities import SQLDatabase # Initialize the database (you'll need the Chinook sample DB for this example)
db = SQLDatabase.from_uri("sqlite:///./Chinook.db") def get_schema(_): return db.get_table_info() def run_query(query): return db.run(query) from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough model = ChatOpenAI() sql_response = ( RunnablePassthrough.assign(schema=get_schema) | prompt | model.bind(stop=["nSQLResult:"]) | StrOutputParser()
) result = sql_response.invoke({"question": "How many employees are there?"})
print(result) template = """Based on the table schema below, question, SQL query, and SQL response, write a natural language response:
{schema} Question: {question}
SQL Query: {query}
SQL Response: {response}"""
prompt_response = ChatPromptTemplate.from_template(template) full_chain = ( RunnablePassthrough.assign(query=sql_response) | RunnablePassthrough.assign( schema=get_schema, response=lambda x: db.run(x["query"]), ) | prompt_response | model
) response = full_chain.invoke({"question": "How many employees are there?"})
print(response)
Tässä esimerkissä LangChainia käytetään SQL-kyselyjen luomiseen käyttäjien kysymyksiin ja vastausten hakemiseen SQL-tietokannasta. Kehotteet ja vastaukset on muotoiltu tarjoamaan luonnollisen kielen vuorovaikutusta tietokannan kanssa.
Automatisoi manuaalisia tehtäviä ja työnkulkuja tekoälypohjaisella työnkulun rakentajallamme, jonka Nanonets on suunnitellut sinulle ja ryhmillesi.
LangServe & LangSmith
LangServe auttaa kehittäjiä ottamaan käyttöön LangChainin ajettavia tiedostoja ja ketjuja REST API:na. Tämä kirjasto on integroitu FastAPI:hen ja käyttää pydanticia tietojen validointiin. Lisäksi se tarjoaa asiakkaan, jonka avulla voidaan kutsua palvelimelle asennettuja ajettavia tiedostoja, ja JavaScript-asiakas on saatavilla LangChainJS:ssä.
Ominaisuudet
- Tulo- ja lähtöskeemat päätellään automaattisesti LangChain-objektistasi ja ne pakotetaan jokaisessa API-kutsussa runsailla virheilmoituksilla.
- API-dokumenttien sivu, jossa on JSONSchema ja Swagger, on saatavilla.
- Tehokkaat /invoke-, /batch- ja /stream-päätepisteet, jotka tukevat monia samanaikaisia pyyntöjä yhdellä palvelimella.
- /stream_log-päätepiste kaikkien (tai joidenkin) välivaiheiden suoratoistoon ketjustasi/agentistasi.
- Leikkikenttäsivu osoitteessa /playground, jossa on suoratoistolähtö ja välivaiheet.
- Sisäänrakennettu (valinnainen) jäljitys LangSmithiin; lisää vain API-avain (katso ohjeet).
- Kaikki on rakennettu taistelutestatuilla avoimen lähdekoodin Python-kirjastoilla, kuten FastAPI, Pydantic, uvloop ja asyncio.
Rajoitukset
- Asiakkaan takaisinkutsuja ei vielä tueta tapahtumille, jotka ovat peräisin palvelimelta.
- OpenAPI-dokumentteja ei luoda, kun käytetään Pydantic V2:ta. FastAPI ei tue pydantisten v1- ja v2-nimitilojen sekoittamista. Katso lisätietoja alla olevasta osiosta.
LangChain CLI:n avulla voit käynnistää LangServe-projektin nopeasti. Jos haluat käyttää langchain CLI:tä, varmista, että sinulla on asennettuna uusin versio langchain-cli:stä. Voit asentaa sen komennolla pip install -U langchain-cli.
langchain app new ../path/to/directory
Aloita LangServe-ilmentymäsi nopeasti LangChain Templates -malleilla. Katso lisää esimerkkejä mallien hakemistosta tai esimerkkihakemistosta.
Tässä on palvelin, joka käyttää OpenAI-chat-mallia, Anthropic-chat-mallia ja ketju, joka käyttää Anthropic-mallia kertoakseen vitsin aiheesta.
#!/usr/bin/env python
from fastapi import FastAPI
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatAnthropic, ChatOpenAI
from langserve import add_routes app = FastAPI( title="LangChain Server", version="1.0", description="A simple api server using Langchain's Runnable interfaces",
) add_routes( app, ChatOpenAI(), path="/openai",
) add_routes( app, ChatAnthropic(), path="/anthropic",
) model = ChatAnthropic()
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
add_routes( app, prompt | model, path="/chain",
) if __name__ == "__main__": import uvicorn uvicorn.run(app, host="localhost", port=8000)
Kun olet ottanut yllä olevan palvelimen käyttöön, voit tarkastella luotuja OpenAPI-dokumentteja käyttämällä:
curl localhost:8000/docs
Muista lisätä /docs-liite.
from langchain.schema import SystemMessage, HumanMessage
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnableMap
from langserve import RemoteRunnable openai = RemoteRunnable("https://localhost:8000/openai/")
anthropic = RemoteRunnable("https://localhost:8000/anthropic/")
joke_chain = RemoteRunnable("https://localhost:8000/chain/") joke_chain.invoke({"topic": "parrots"}) # or async
await joke_chain.ainvoke({"topic": "parrots"}) prompt = [ SystemMessage(content='Act like either a cat or a parrot.'), HumanMessage(content='Hello!')
] # Supports astream
async for msg in anthropic.astream(prompt): print(msg, end="", flush=True) prompt = ChatPromptTemplate.from_messages( [("system", "Tell me a long story about {topic}")]
) # Can define custom chains
chain = prompt | RunnableMap({ "openai": openai, "anthropic": anthropic,
}) chain.batch([{ "topic": "parrots" }, { "topic": "cats" }])
TypeScriptissä (vaatii LangChain.js-version 0.0.166 tai uudempi):
import { RemoteRunnable } from "langchain/runnables/remote"; const chain = new RemoteRunnable({ url: `https://localhost:8000/chain/invoke/`,
});
const result = await chain.invoke({ topic: "cats",
});
Python käyttää pyyntöjä:
import requests
response = requests.post( "https://localhost:8000/chain/invoke/", json={'input': {'topic': 'cats'}}
)
response.json()
Voit myös käyttää curl:ia:
curl --location --request POST 'https://localhost:8000/chain/invoke/' --header 'Content-Type: application/json' --data-raw '{ "input": { "topic": "cats" } }'
Seuraava koodi:
...
add_routes( app, runnable, path="/my_runnable",
)
lisää näistä päätepisteistä palvelimelle:
- POST /my_runnable/invoke – kutsua suoritettavan tiedoston yhdellä syötteellä
- POST /my_runnable/batch – kutsua suoritettavaa erää syötteitä
- POST /my_runnable/stream – kutsu yhdestä tulosta ja suoratoista tulos
- POST /my_runnable/stream_log – kutsu yhdestä syötteestä ja suoratoistaa tulos, mukaan lukien välivaiheiden tulos, kun se luodaan
- GET /my_runnable/input_schema – json-skeema syötettäväksi suoritettavaan tiedostoon
- GET /my_runnable/output_schema – json-skeema suoritettavan tiedoston ulostulolle
- GET /my_runnable/config_schema – json-skeema suoritettavan tiedoston konfiguraatiolle
Löydät juoksevasi leikkipaikkasivun osoitteesta /my_runnable/playground. Tämä paljastaa yksinkertaisen käyttöliittymän, jolla voit määrittää ja kutsua suoritettavaa sisältöä suoratoiston ja välivaiheiden avulla.
Sekä asiakkaalle että palvelimelle:
pip install "langserve[all]"
tai pip install “langserve[client]” asiakaskoodille ja pip install “langserve[server]” palvelinkoodille.
Jos haluat lisätä todennusta palvelimellesi, tutustu FastAPI:n tietoturvadokumentaatioon ja väliohjelmiston dokumentaatioon.
Voit ottaa käyttöön GCP Cloud Runin käyttämällä seuraavaa komentoa:
gcloud run deploy [your-service-name] --source . --port 8001 --allow-unauthenticated --region us-central1 --set-env-vars=OPENAI_API_KEY=your_key
LangServe tukee Pydantic 2:ta tietyin rajoituksin. OpenAPI-dokumentteja ei luoda invoke/batch/stream/stream_log-tiedostolle käytettäessä Pydantic V2:ta. Fast API ei tue pydantisten v1- ja v2-nimitilojen sekoittamista. LangChain käyttää v1-nimiavaruutta Pydantic v2:ssa. Lue seuraavat ohjeet varmistaaksesi yhteensopivuuden LangChainin kanssa. Näitä rajoituksia lukuun ottamatta odotamme, että API-päätepisteet, leikkikenttä ja kaikki muut ominaisuudet toimivat odotetulla tavalla.
LLM-sovellukset käsittelevät usein tiedostoja. On olemassa erilaisia arkkitehtuureja, jotka voidaan tehdä toteuttamaan tiedostojen käsittelyä; korkealla tasolla:
- Tiedosto voidaan ladata palvelimelle erillisen päätepisteen kautta ja käsitellä erillisen päätepisteen avulla.
- Tiedosto voidaan ladata joko arvon (tiedoston tavut) tai viittauksen (esim. s3 url tiedoston sisältöön) perusteella.
- Käsittelyn päätepiste voi olla estävä tai ei-esto.
- Jos tarvitaan merkittävää käsittelyä, käsittely voidaan siirtää omistettuun prosessipooliin.
Sinun tulee määrittää, mikä on sopiva arkkitehtuuri sovelluksellesi. Tällä hetkellä tiedostojen lataamiseksi arvon mukaan ajettavaan tiedostoon käytetään base64-koodausta (moniosaisia/muototietoja ei vielä tueta).
Tässä esimerkki joka näyttää, kuinka käyttää base64-koodausta tiedoston lähettämiseen etäajettavaan tiedostoon. Muista, että voit aina ladata tiedostoja viitteellä (esim. s3 url) tai lähettää ne moniosaisena/lomaketietona erityiseen päätepisteeseen.
Tulo- ja ulostulotyypit on määritelty kaikille suoritettaville malleille. Voit käyttää niitä input_schema- ja output_schema-ominaisuuksien kautta. LangServe käyttää näitä tyyppejä validointiin ja dokumentointiin. Jos haluat ohittaa oletusarvoiset päätellyt tyypit, voit käyttää with_types -menetelmää.
Tässä on esimerkki lelusta idean havainnollistamiseksi:
from typing import Any
from fastapi import FastAPI
from langchain.schema.runnable import RunnableLambda app = FastAPI() def func(x: Any) -> int: """Mistyped function that should accept an int but accepts anything.""" return x + 1 runnable = RunnableLambda(func).with_types( input_schema=int,
) add_routes(app, runnable)
Peri CustomUserType-tyypistä, jos haluat tietojen sarjallistuvan pydanttiseksi malliksi vastaavan saneluesityksen sijaan. Tällä hetkellä tämä tyyppi toimii vain palvelinpuolella ja sitä käytetään määrittämään haluttu dekoodauskäyttäytyminen. Jos palvelin perii tästä tyypistä, palvelin säilyttää dekoodatun tyypin pydanttisena mallina sen sijaan, että se muuttaisi sen diktatuuriksi.
from fastapi import FastAPI
from langchain.schema.runnable import RunnableLambda
from langserve import add_routes
from langserve.schema import CustomUserType app = FastAPI() class Foo(CustomUserType): bar: int def func(foo: Foo) -> int: """Sample function that expects a Foo type which is a pydantic model""" assert isinstance(foo, Foo) return foo.bar add_routes(app, RunnableLambda(func), path="/foo")
Leikkikentän avulla voit määrittää mukautettuja widgetejä ajettavalle ohjelmallesi taustasta. Widget määritetään kenttätasolla ja toimitetaan osana syötetyypin JSON-skeemaa. Widgetin on sisällettävä avain nimeltä tyyppi, jonka arvo on yksi tunnetusta widgetiluettelosta. Muut widget-avaimet liitetään arvoihin, jotka kuvaavat polkuja JSON-objektissa.
Yleinen skeema:
type JsonPath = number | string | (number | string)[];
type NameSpacedPath = { title: string; path: JsonPath }; // Using title to mimic json schema, but can use namespace
type OneOfPath = { oneOf: JsonPath[] }; type Widget = { type: string // Some well-known type (e.g., base64file, chat, etc.) [key: string]: JsonPath | NameSpacedPath | OneOfPath;
};
Mahdollistaa tiedostojen lataussyötteen luomisen käyttöliittymän leikkikentällä tiedostoille, jotka ladataan base64-koodatuina merkkijonoina. Tässä on täydellinen esimerkki.
try: from pydantic.v1 import Field
except ImportError: from pydantic import Field from langserve import CustomUserType # ATTENTION: Inherit from CustomUserType instead of BaseModel otherwise
# the server will decode it into a dict instead of a pydantic model.
class FileProcessingRequest(CustomUserType): """Request including a base64 encoded file.""" # The extra field is used to specify a widget for the playground UI. file: str = Field(..., extra={"widget": {"type": "base64file"}}) num_chars: int = 100
Automatisoi manuaalisia tehtäviä ja työnkulkuja tekoälypohjaisella työnkulun rakentajallamme, jonka Nanonets on suunnitellut sinulle ja ryhmillesi.
LangSmithin esittely
LangChain tekee LLM-sovellusten ja agenttien prototyypeistä helppoa. LLM-sovellusten toimittaminen tuotantoon voi kuitenkin olla petollisen vaikeaa. Sinun on todennäköisesti muokattava ja toistettava kehotteitasi, ketjujasi ja muita komponenttejasi luodaksesi korkealaatuisen tuotteen.
Tämän prosessin auttamiseksi esiteltiin LangSmith, yhtenäinen alusta LLM-sovellustesi virheenkorjaukseen, testaukseen ja valvontaan.
Milloin tästä voi olla hyötyä? Saatat olla hyödyllinen, kun haluat nopeasti korjata uuden ketjun, agentin tai työkalujoukon vian, visualisoida, miten komponentit (ketjut, LLMS:t, noutajat jne.) liittyvät toisiinsa ja niitä käytetään, arvioida yksittäisen komponentin erilaisia kehotteita ja LLM:itä, ajaa tietty ketju useita kertoja tietojoukon yli varmistaaksesi, että se vastaa jatkuvasti laatupalkkia, tai tallenna käyttöjäljet ja käytä LLM:itä tai analytiikkaputkia oivallusten luomiseen.
Edellytykset:
- Luo LangSmith-tili ja luo API-avain (katso vasen alakulma).
- Tutustu alustaan selaamalla asiakirjoja.
Aloitetaan nyt!
Määritä ensin ympäristömuuttujat käskemään LangChain kirjaamaan jälkiä. Tämä tehdään asettamalla ympäristömuuttujan LANGCHAIN_TRACING_V2 arvoksi tosi. Voit kertoa LangChainille, mihin projektiin kirjautua, asettamalla ympäristömuuttujan LANGCHAIN_PROJECT (jos tätä ei ole asetettu, ajot kirjataan oletusprojektiin). Tämä luo automaattisesti projektin puolestasi, jos sitä ei ole olemassa. Sinun on myös asetettava ympäristömuuttujat LANGCHAIN_ENDPOINT ja LANGCHAIN_API_KEY.
HUOMAUTUS: Voit myös käyttää pythonissa kontekstinhallintaa jäljittämiseen käyttämällä:
from langchain.callbacks.manager import tracing_v2_enabled with tracing_v2_enabled(project_name="My Project"): agent.run("How many people live in canada as of 2023?")
Tässä esimerkissä käytämme kuitenkin ympäristömuuttujia.
%pip install openai tiktoken pandas duckduckgo-search --quiet import os
from uuid import uuid4 unique_id = uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"Tracing Walkthrough - {unique_id}"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "<YOUR-API-KEY>" # Update to your API key # Used by the agent in this tutorial
os.environ["OPENAI_API_KEY"] = "<YOUR-OPENAI-API-KEY>"
Luo LangSmith-asiakassovellus ollaksesi vuorovaikutuksessa API:n kanssa:
from langsmith import Client client = Client()
Luo LangChain-komponentti ja loki suoritetaan alustalle. Tässä esimerkissä luomme ReAct-tyylisen agentin, jolla on pääsy yleiseen hakutyökaluun (DuckDuckGo). Agentin kehotteen voi katsoa Hubissa täältä:
from langchain import hub
from langchain.agents import AgentExecutor
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.chat_models import ChatOpenAI
from langchain.tools import DuckDuckGoSearchResults
from langchain.tools.render import format_tool_to_openai_function # Fetches the latest version of this prompt
prompt = hub.pull("wfh/langsmith-agent-prompt:latest") llm = ChatOpenAI( model="gpt-3.5-turbo-16k", temperature=0,
) tools = [ DuckDuckGoSearchResults( name="duck_duck_go" ), # General internet search using DuckDuckGo
] llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools]) runnable_agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
) agent_executor = AgentExecutor( agent=runnable_agent, tools=tools, handle_parsing_errors=True
)
Käytämme agenttia samanaikaisesti useilla tuloilla latenssin vähentämiseksi. Ajot kirjautuvat LangSmithiin taustalla, joten suoritusviive ei muutu:
inputs = [ "What is LangChain?", "What's LangSmith?", "When was Llama-v2 released?", "What is the langsmith cookbook?", "When did langchain first announce the hub?",
] results = agent_executor.batch([{"input": x} for x in inputs], return_exceptions=True) results[:2]
Olettaen, että olet määrittänyt ympäristösi onnistuneesti, agenttijälkien pitäisi näkyä sovelluksen Projektit-osiossa. Onnittelut!
Näyttää siltä, että agentti ei kuitenkaan käytä työkaluja tehokkaasti. Arvioidaan tämä, jotta meillä on lähtökohta.
Kirjausajojen lisäksi LangSmith antaa sinun myös testata ja arvioida LLM-sovelluksiasi.
Tässä osiossa hyödynnät LangSmithiä luomaan vertailutietojoukon ja suorittamaan tekoälyn avustamia arvioijia agentilla. Teet sen muutamassa vaiheessa:
- Luo LangSmith-tietojoukko:
Alla käytämme LangSmith-asiakasta luodaksemme tietojoukon ylhäältä tulevista syötekysymyksistä ja luettelotunnisteista. Käytät näitä myöhemmin uuden agentin suorituskyvyn mittaamiseen. Tietojoukko on kokoelma esimerkkejä, jotka ovat vain syöttö-lähtö-pareja, joita voit käyttää sovelluksesi testitapauksina:
outputs = [ "LangChain is an open-source framework for building applications using large language models. It is also the name of the company building LangSmith.", "LangSmith is a unified platform for debugging, testing, and monitoring language model applications and agents powered by LangChain", "July 18, 2023", "The langsmith cookbook is a github repository containing detailed examples of how to use LangSmith to debug, evaluate, and monitor large language model-powered applications.", "September 5, 2023",
] dataset_name = f"agent-qa-{unique_id}" dataset = client.create_dataset( dataset_name, description="An example dataset of questions over the LangSmith documentation.",
) for query, answer in zip(inputs, outputs): client.create_example( inputs={"input": query}, outputs={"output": answer}, dataset_id=dataset.id )
- Alusta uusi agentti vertailua varten:
LangSmithin avulla voit arvioida minkä tahansa LLM:n, ketjun, agentin tai jopa mukautetun toiminnon. Keskusteluagentit ovat tilallisia (heillä on muisti); varmistaaksemme, että tätä tilaa ei jaeta tietojoukkoajon välillä, välitämme ketjun_tehdas (
alias konstruktori) -funktio, joka alustetaan jokaiselle kutsulle:
# Since chains can be stateful (e.g. they can have memory), we provide
# a way to initialize a new chain for each row in the dataset. This is done
# by passing in a factory function that returns a new chain for each row.
def agent_factory(prompt): llm_with_tools = llm.bind( functions=[format_tool_to_openai_function(t) for t in tools] ) runnable_agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser() ) return AgentExecutor(agent=runnable_agent, tools=tools, handle_parsing_errors=True)
- Määritä arviointi:
Ketjujen tulosten manuaalinen vertailu käyttöliittymässä on tehokasta, mutta se voi viedä aikaa. Voi olla hyödyllistä käyttää automatisoituja mittareita ja tekoälyavusteista palautetta komponenttisi suorituskyvyn arvioinnissa:
from langchain.evaluation import EvaluatorType
from langchain.smith import RunEvalConfig evaluation_config = RunEvalConfig( evaluators=[ EvaluatorType.QA, EvaluatorType.EMBEDDING_DISTANCE, RunEvalConfig.LabeledCriteria("helpfulness"), RunEvalConfig.LabeledScoreString( { "accuracy": """
Score 1: The answer is completely unrelated to the reference.
Score 3: The answer has minor relevance but does not align with the reference.
Score 5: The answer has moderate relevance but contains inaccuracies.
Score 7: The answer aligns with the reference but has minor errors or omissions.
Score 10: The answer is completely accurate and aligns perfectly with the reference.""" }, normalize_by=10, ), ], custom_evaluators=[],
)
- Suorita agentti ja arvioijat:
Käytä run_on_dataset (tai asynkronista arun_on_dataset) -funktiota mallin arvioimiseen. Tämä tulee:
- Hae esimerkkirivit määritetystä tietojoukosta.
- Suorita agenttisi (tai mikä tahansa mukautettu toiminto) jokaisessa esimerkissä.
- Käytä arvioijia tuloksena oleviin ajojäljiin ja vastaaviin viiteesimerkkeihin automaattisen palautteen luomiseksi.
Tulokset näkyvät LangSmith-sovelluksessa:
chain_results = run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=functools.partial(agent_factory, prompt=prompt), evaluation=evaluation_config, verbose=True, client=client, project_name=f"runnable-agent-test-5d466cbc-{unique_id}", tags=[ "testing-notebook", "prompt:5d466cbc", ],
)
Nyt kun meillä on testiajon tulokset, voimme tehdä muutoksia agenttiimme ja vertailla niitä. Kokeillaan tätä uudelleen eri kehotteessa ja katsotaan tuloksia:
candidate_prompt = hub.pull("wfh/langsmith-agent-prompt:39f3bbd0") chain_results = run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=functools.partial(agent_factory, prompt=candidate_prompt), evaluation=evaluation_config, verbose=True, client=client, project_name=f"runnable-agent-test-39f3bbd0-{unique_id}", tags=[ "testing-notebook", "prompt:39f3bbd0", ],
)
LangSmithin avulla voit viedä tietoja yleisiin muotoihin, kuten CSV tai JSONL, suoraan verkkosovelluksessa. Voit myös käyttää asiakasohjelmaa ajojen hakemiseen lisäanalyysiä varten, tallentamiseen omaan tietokantaan tai jakamiseen muiden kanssa. Haetaan ajojäljet arviointiajosta:
runs = client.list_runs(project_name=chain_results["project_name"], execution_order=1) # After some time, these will be populated.
client.read_project(project_name=chain_results["project_name"]).feedback_stats
Tämä oli nopea aloitusopas, mutta LangSmithillä on monia muita tapoja nopeuttaa kehittäjien toimintaa ja tuottaa parempia tuloksia.
Katso LangSmithin dokumentaatiosta lisätietoja siitä, kuinka saat eniten irti LangSmithistä.
Nouse tasolle Nanonetsilla
Vaikka LangChain on arvokas työkalu kielimallien (LLM) integroimiseen sovelluksiisi, se saattaa kohdata rajoituksia yrityskäyttötapauksissa. Tutkitaan, kuinka Nanonets ylittää LangChainin vastatakseen näihin haasteisiin:
1. Kattavat datayhteydet:
LangChain tarjoaa liittimiä, mutta se ei välttämättä kata kaikkia työtilasovelluksia ja tietomuotoja, joihin yritykset luottavat. Nanonets tarjoaa dataliittimet yli 100 laajasti käytetylle työtilasovellukselle, mukaan lukien Slack, Notion, Google Suite, Salesforce, Zendesk ja monet muut. Se tukee myös kaikkia rakenteettomia tietotyyppejä, kuten PDF-tiedostoja, TXT-tiedostoja, kuvia, äänitiedostoja ja videotiedostoja, sekä strukturoituja tietotyyppejä, kuten CSV-tiedostoja, laskentataulukoita, MongoDB- ja SQL-tietokantoja.

2. Tehtävien automatisointi Workspace-sovelluksille:
Vaikka tekstin/vastauksen luominen toimii hyvin, LangChainin ominaisuudet ovat rajalliset, kun on kyse luonnollisen kielen käyttämisestä tehtävien suorittamiseen eri sovelluksissa. Nanonets tarjoaa laukaisu-/toimintoagentteja suosituimmille työtilasovelluksille, joiden avulla voit määrittää työnkulkuja, jotka kuuntelevat tapahtumia ja suorittavat toimintoja. Voit esimerkiksi automatisoida sähköpostivastaukset, CRM-merkinnät, SQL-kyselyt ja paljon muuta luonnollisen kielen komentojen avulla.

3. Reaaliaikainen tietojen synkronointi:
LangChain hakee staattista dataa tietoliittimillä, jotka eivät välttämättä pysy perässä lähdetietokannan tietojen muutoksissa. Sitä vastoin Nanonets varmistaa reaaliaikaisen synkronoinnin tietolähteiden kanssa ja varmistaa, että työskentelet aina uusimpien tietojen kanssa.

3. Yksinkertaistettu määritys:
LangChain-liukuhihnan elementtien, kuten noutajien ja syntetisaattoreiden, määrittäminen voi olla monimutkainen ja aikaa vievä prosessi. Nanonets virtaviivaistaa tätä tarjoamalla optimoidun tiedonkeruun ja indeksoinnin kullekin tietotyypille, mitä kaikkea taustalla käsittelee AI Assistant. Tämä vähentää hienosäädön taakkaa ja helpottaa määritystä ja käyttöä.
4. Yhtenäinen ratkaisu:
Toisin kuin LangChain, joka saattaa vaatia ainutlaatuisia toteutuksia jokaiselle tehtävälle, Nanonets toimii yhden luukun ratkaisuna tietojesi yhdistämiseen LLM:ihin. Haluatpa sitten luoda LLM-sovelluksia tai tekoälytyönkulkuja, Nanonets tarjoaa yhtenäisen alustan erilaisiin tarpeisiisi.
Nanonets AI -työnkulut
Nanonets Workflows on turvallinen, monikäyttöinen AI Assistant, joka yksinkertaistaa tietosi ja tietosi integrointia LLM:ien kanssa ja helpottaa koodittomien sovellusten ja työnkulkujen luomista. Se tarjoaa helppokäyttöisen käyttöliittymän, joten se on sekä yksilöiden että organisaatioiden käytettävissä.
Aloita soittamalla puhelun tekoälyasiantuntijamme kanssa, joka voi tarjota henkilökohtaisen esittelyn ja kokeiluversion Nanonets Workflowsista, jotka on räätälöity sinun käyttötapauksiisi.
Kun olet määrittänyt, voit käyttää luonnollista kieltä suunnitellaksesi ja suorittaaksesi monimutkaisia sovelluksia ja työnkulkuja, jotka toimivat LLM:n avulla ja integroituvat saumattomasti sovelluksiisi ja tietoihisi.

Lisää tiimejäsi Nanonets AI:lla luodaksesi sovelluksia ja integroidaksesi tietosi tekoälypohjaisiin sovelluksiin ja työnkulkuihin, jolloin tiimisi voivat keskittyä olennaiseen.
Automatisoi manuaalisia tehtäviä ja työnkulkuja tekoälypohjaisella työnkulun rakentajallamme, jonka Nanonets on suunnitellut sinulle ja ryhmillesi.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://nanonets.com/blog/langchain/

