این یک پست مهمان است که با تیم رهبری Iambic Therapeutics نوشته شده است.
Iambic Therapeutics یک استارتآپ کشف دارو با مأموریت ایجاد فناوریهای نوآورانه مبتنی بر هوش مصنوعی برای رساندن سریعتر داروهای بهتر به بیماران سرطانی است.
ابزارهای پیشرفته هوش مصنوعی مولد و پیشبینیکننده (AI) ما را قادر میسازد تا فضای وسیع مولکولهای دارویی احتمالی را سریعتر و مؤثرتر جستجو کنیم. فنآوریهای ما همه کاره هستند و در مناطق درمانی، کلاسهای پروتئینی و مکانیسمهای عمل قابل اجرا هستند. فراتر از ایجاد ابزارهای هوش مصنوعی متمایز، ما یک پلتفرم یکپارچه ایجاد کرده ایم که نرم افزار هوش مصنوعی، داده های مبتنی بر ابر، زیرساخت های محاسباتی مقیاس پذیر، و قابلیت های شیمی و زیست شناسی بالا را با هم ادغام می کند. این پلتفرم هم هوش مصنوعی ما را قادر میسازد – با ارائه دادهها برای اصلاح مدلهای ما – و هم توسط آن فعال میشود و از فرصتهایی برای تصمیمگیری خودکار و پردازش دادهها استفاده میکند.
ما موفقیت را با توانایی خود در تولید نامزدهای بالینی برتر برای رفع نیازهای فوری بیمار، با سرعتی بیسابقه اندازهگیری میکنیم: ما از راهاندازی برنامه به نامزدهای بالینی تنها در 24 ماه، بسیار سریعتر از رقبای خود، پیشرفت کردیم.
در این پست، ما بر نحوه استفاده خود تمرکز می کنیم نجار on سرویس الاستیک کوبرنتز آمازون (Amazon EKS) برای مقیاسبندی آموزش و استنتاج هوش مصنوعی، که عناصر اصلی پلتفرم اکتشاف Iambic هستند.
نیاز به آموزش هوش مصنوعی مقیاس پذیر و استنتاج
هر هفته، Iambic استنتاج هوش مصنوعی را در دهها مدل و میلیونها مولکول انجام میدهد و دو مورد استفاده اصلی را ارائه میکند:
- شیمیدانان دارویی و دانشمندان دیگر از برنامه وب ما، Insight، برای کاوش فضای شیمیایی، دسترسی و تفسیر داده های تجربی و پیش بینی خواص مولکول های جدید طراحی شده استفاده می کنند. همه این کارها به صورت تعاملی در زمان واقعی انجام می شود و نیاز به استنتاج با تاخیر کم و توان متوسط را ایجاد می کند.
- در همان زمان، مدلهای هوش مصنوعی مولد ما بهطور خودکار مولکولهایی را طراحی میکنند که بهبود در خواص متعدد را هدف قرار میدهند، میلیونها نامزد را جستجو میکنند و به توان عملیاتی بسیار زیاد و تأخیر متوسط نیاز دارند.
پلتفرم آزمایشی ما با هدایت فناوریهای هوش مصنوعی و شکارچیان متخصص مواد مخدر، هزاران مولکول منحصربهفرد را هر هفته تولید میکند و هر کدام تحت آزمایشهای بیولوژیکی متعدد قرار میگیرند. نقاط داده تولید شده به طور خودکار پردازش می شوند و هر هفته برای تنظیم دقیق مدل های هوش مصنوعی ما استفاده می شوند. در ابتدا، تنظیم دقیق مدل ما ساعت ها زمان CPU را می گرفت، بنابراین چارچوبی برای مقیاس بندی تنظیم دقیق مدل در GPU ها ضروری بود.
مدل های یادگیری عمیق ما الزامات غیر ضروری دارند: اندازه آنها گیگابایت است، متعدد و ناهمگن هستند و برای استنتاج سریع و تنظیم دقیق به GPU نیاز دارند. با نگاهی به زیرساخت های ابری، ما به سیستمی نیاز داشتیم که به ما امکان دسترسی به GPU ها، افزایش و کاهش سریع برای مدیریت بارهای کاری ناهمگون و ناهمگون و اجرای تصاویر بزرگ Docker را بدهد.
ما می خواستیم یک سیستم مقیاس پذیر برای پشتیبانی از آموزش و استنتاج هوش مصنوعی بسازیم. ما از Amazon EKS استفاده می کنیم و به دنبال بهترین راه حل برای مقیاس خودکار گره های کارگر خود هستیم. ما Karpenter را برای مقیاس خودکار گره Kubernetes به دلایل مختلفی انتخاب کردیم:
- سهولت ادغام با Kubernetes، استفاده از Semantics Kubernetes برای تعریف الزامات گره و مشخصات pod برای مقیاس بندی
- کاهش زمان تاخیر پایین گره ها
- سهولت ادغام با زیرساخت ما به عنوان ابزار کد (Terraform)
ارائه دهندگان گره از ادغام بدون زحمت با آمازون EKS و سایر منابع AWS مانند ابر محاسبه الاستیک آمازون (Amazon EC2) نمونه ها و فروشگاه بلوک الاستیک آمازون جلدها معناشناسی Kubernetes مورد استفاده توسط ارائه دهندگان، از زمان بندی هدایت شده با استفاده از ساختارهای Kubernetes مانند taints یا tolerations و مشخصات وابسته یا ضد قرابت پشتیبانی می کند. آنها همچنین کنترل تعداد و انواع نمونههای GPU را که ممکن است توسط Karpenter برنامهریزی شوند، تسهیل میکنند.
بررسی اجمالی راه حل
در این بخش، ما یک معماری عمومی ارائه میدهیم که شبیه به چیزی است که برای بارهای کاری خود استفاده میکنیم، که امکان استقرار الاستیک مدلها را با استفاده از مقیاس خودکار کارآمد بر اساس معیارهای سفارشی فراهم میکند.
نمودار زیر معماری راه حل را نشان می دهد.

معماری یک سرویس ساده در یک غلاف Kubernetes در یک خوشه EKS. این می تواند یک استنتاج مدل، شبیه سازی داده یا هر سرویس کانتینری دیگری باشد که با درخواست HTTP قابل دسترسی است. این سرویس در پشت پراکسی معکوس با استفاده قرار می گیرد ترافیک. پروکسی معکوس معیارهای مربوط به تماسهای سرویس را جمعآوری میکند و آنها را از طریق یک API معیارهای استاندارد در معرض دید قرار میدهد. تیتان فرزند پاپتوس. مقیاسکننده خودکار رویداد Kubernetes (KEDA) به گونه ای پیکربندی شده است که بر اساس معیارهای سفارشی موجود در Prometheus، تعداد غلاف های سرویس را به صورت خودکار مقیاس کند. در اینجا از تعداد درخواست ها در ثانیه به عنوان معیار سفارشی استفاده می کنیم. اگر معیار متفاوتی را برای حجم کاری خود انتخاب کنید، همان رویکرد معماری اعمال می شود.
Karpenter برای هر غلاف معلق که به دلیل کمبود منابع کافی در خوشه نمی تواند اجرا شود، نظارت می کند. اگر چنین غلاف هایی شناسایی شوند، کارپنتر گره های بیشتری را به خوشه اضافه می کند تا منابع لازم را فراهم کند. برعکس، اگر تعداد گرهها در خوشه بیشتر از مقدار مورد نیاز غلافهای زمانبندیشده باشد، کارپنتر برخی از گرههای کارگر را حذف میکند و غلافها مجدداً زمانبندی میشوند، و آنها را در نمونههای کمتری یکپارچه میکند. تعداد درخواست های HTTP در هر ثانیه و تعداد گره ها را می توان با استفاده از a تجسم کرد گرافانا داشبورد. برای نشان دادن مقیاس خودکار، یک یا چند مورد را اجرا می کنیم غلاف های تولید بار ساده، که درخواست های HTTP را با استفاده از آن به سرویس ارسال می کند حلقه.
استقرار راه حل
در قدم به قدم، ما استفاده می کنیم AWS Cloud9 به عنوان محیطی برای استقرار معماری. این کار تمام مراحل را از یک مرورگر وب تکمیل می کند. شما همچنین می توانید راه حل را از یک کامپیوتر محلی یا نمونه EC2 مستقر کنید.
برای سادهسازی استقرار و بهبود تکرارپذیری، از اصول آن پیروی میکنیم انجام چارچوب و ساختار قالب وابسته به داکر. ما کلون می کنیم aws-do-eks پروژه و با استفاده از کارگر بارانداز، یک تصویر ظرف می سازیم که مجهز به ابزار و اسکریپت های لازم است. در داخل کانتینر، ما تمام مراحل مرحله به انتها را طی می کنیم، از ایجاد یک خوشه EKS با کارپنتر تا مقیاس بندی. نمونه های EC2.
برای مثال در این پست از موارد زیر استفاده می کنیم مانیفست خوشه EKS:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: do-eks-yaml-karpenter
version: '1.28'
region: us-west-2
tags:
karpenter.sh/discovery: do-eks-yaml-karpenter
iam:
withOIDC: true
addons:
- name: aws-ebs-csi-driver
version: v1.26.0-eksbuild.1
wellKnownPolicies:
ebsCSIController: true
managedNodeGroups:
- name: c5-xl-do-eks-karpenter-ng
instanceType: c5.xlarge
instancePrefix: c5-xl
privateNetworking: true
minSize: 0
desiredCapacity: 2
maxSize: 10
volumeSize: 300
iam:
withAddonPolicies:
cloudWatch: true
ebs: trueاین مانیفست یک خوشه به نام را تعریف می کند do-eks-yaml-karpenter با درایور EBS CSI که به عنوان یک افزونه نصب شده است. یک گروه گره مدیریت شده با دو c5.xlarge گرهها برای اجرای غلافهای سیستم که مورد نیاز خوشه هستند گنجانده شده است. گره های کارگر در زیرشبکه های خصوصی میزبانی می شوند و نقطه پایانی API خوشه ای به طور پیش فرض عمومی است.
همچنین می توانید از یک خوشه EKS موجود به جای ایجاد یک خوشه استفاده کنید. ما کارپنتر را با دنبال کردن آن مستقر می کنیم دستورالعمل در مستندات کارپنتر یا با اجرای موارد زیر خط، که دستورالعمل های استقرار را خودکار می کند.
کد زیر پیکربندی Karpenter را نشان می دهد که در این مثال استفاده می کنیم:
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
metadata: null
labels:
cluster-name: do-eks-yaml-karpenter
annotations:
purpose: karpenter-example
spec:
nodeClassRef:
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
name: default
requirements:
- key: karpenter.sh/capacity-type
operator: In
values:
- spot
- on-demand
- key: karpenter.k8s.aws/instance-category
operator: In
values:
- c
- m
- r
- g
- p
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values:
- '2'
disruption:
consolidationPolicy: WhenUnderutilized
#consolidationPolicy: WhenEmpty
#consolidateAfter: 30s
expireAfter: 720h
---
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default
spec:
amiFamily: AL2
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "do-eks-yaml-karpenter"
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "do-eks-yaml-karpenter"
role: "KarpenterNodeRole-do-eks-yaml-karpenter"
tags:
app: autoscaling-test
blockDeviceMappings:
- deviceName: /dev/xvda
ebs:
volumeSize: 80Gi
volumeType: gp3
iops: 10000
deleteOnTermination: true
throughput: 125
detailedMonitoring: trueما یک NodePool پیشفرض Karpenter را با شرایط زیر تعریف میکنیم:
- Karpenter می تواند نمونه هایی را از هر دو راه اندازی کند
spotوon-demandاستخرهای ظرفیت - موارد باید از "
c” (محاسبه بهینه شده)، ”m" (همه منظوره)، "r” (بهینه سازی شده برای حافظه)، یاg"و"pخانواده های محاسباتی (GPU accelerated). - تولید نمونه باید بیشتر از 2 باشد. مثلا،
g3قابل قبول است اماg2نیست
NodePool پیش فرض نیز سیاست های اختلال را تعریف می کند. گره های کم استفاده حذف خواهند شد، بنابراین غلاف ها می توانند برای اجرا بر روی گره های کمتر یا کوچکتر ادغام شوند. همچنین، میتوانیم گرههای خالی را پیکربندی کنیم تا پس از بازه زمانی مشخص حذف شوند. این expireAfter تنظیم حداکثر طول عمر هر گره را قبل از توقف و در صورت لزوم جایگزین می کند. این به کاهش آسیبپذیریهای امنیتی کمک میکند و همچنین از مشکلاتی که برای گرههایی با زمان آپتایم طولانی معمول است، مانند قطعه قطعه شدن فایل یا نشت حافظه، جلوگیری میکند.
بهطور پیشفرض، کارپنتر گرههایی با حجم ریشه کوچک ارائه میکند که میتواند برای اجرای بارهای کاری هوش مصنوعی یا یادگیری ماشین (ML) کافی نباشد. برخی از تصاویر محفظه یادگیری عمیق می توانند ده ها گیگابایت حجم داشته باشند، و ما باید مطمئن شویم که فضای ذخیره سازی کافی روی گره ها برای اجرای پادها با استفاده از این تصاویر وجود دارد. برای انجام آن، ما تعریف می کنیم EC2NodeClass با blockDeviceMappings، همانطور که در کد قبل نشان داده شده است.
کارپنتر مسئول مقیاس بندی خودکار در سطح خوشه است. برای پیکربندی مقیاسبندی خودکار در سطح پاد، از KEDA برای تعریف یک منبع سفارشی به نام استفاده میکنیم ScaledObject، همانطور که در کد زیر نشان داده شده است:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: keda-prometheus-hpa
namespace: hpa-example
spec:
scaleTargetRef:
name: php-apache
minReplicaCount: 1
cooldownPeriod: 30
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus- server.prometheus.svc.cluster.local:80
metricName: http_requests_total
threshold: '1'
query: rate(traefik_service_requests_total{service="hpa-example-php-apache-80@kubernetes",code="200"}[2m])مانیفست قبلی a را تعریف می کند ScaledObject تحت عنوان keda-prometheus-hpa، که مسئول مقیاس بندی استقرار php-apache است و همیشه حداقل یک نسخه را در حال اجرا نگه می دارد. غلاف های این استقرار را بر اساس متریک مقیاس می کند http_requests_total در Prometheus موجود است که با پرس و جوی مشخص شده به دست می آید و هدف می گیرد تا غلاف ها را به گونه ای افزایش دهد که هر پاد بیش از یک درخواست در ثانیه ارائه ندهد. پس از اینکه بار درخواست برای بیش از 30 ثانیه کمتر از آستانه باشد، کپی ها را کاهش می دهد.
La مشخصات استقرار برای مثال سرویس ما شامل موارد زیر است درخواست ها و محدودیت های منابع:
resources:
limits:
cpu: 500m
nvidia.com/gpu: 1
requests:
cpu: 200m
nvidia.com/gpu: 1با این پیکربندی، هر یک از پادهای سرویس دقیقاً از یک پردازنده گرافیکی NVIDIA استفاده خواهند کرد. هنگامی که پادهای جدید ایجاد میشوند، تا زمانی که یک GPU در دسترس نباشد، در وضعیت معلق خواهند بود. Karpenter گرههای GPU را در صورت نیاز به کلاستر اضافه میکند تا غلافهای معلق را در خود جای دهد.
A غلاف مولد بار درخواست های HTTP را با فرکانس از پیش تعیین شده به سرویس ارسال می کند. ما تعداد درخواست ها را با افزایش تعداد کپی ها در آن افزایش می دهیم استقرار ژنراتور بار.
یک چرخه مقیاس بندی کامل با یکپارچه سازی گره مبتنی بر استفاده در داشبورد Grafana به تصویر کشیده شده است. داشبورد زیر تعداد گرهها در خوشه را بر اساس نوع نمونه (بالا)، تعداد درخواستها در هر ثانیه (پایین سمت چپ) و تعداد پادها (پایین سمت راست) نشان میدهد.
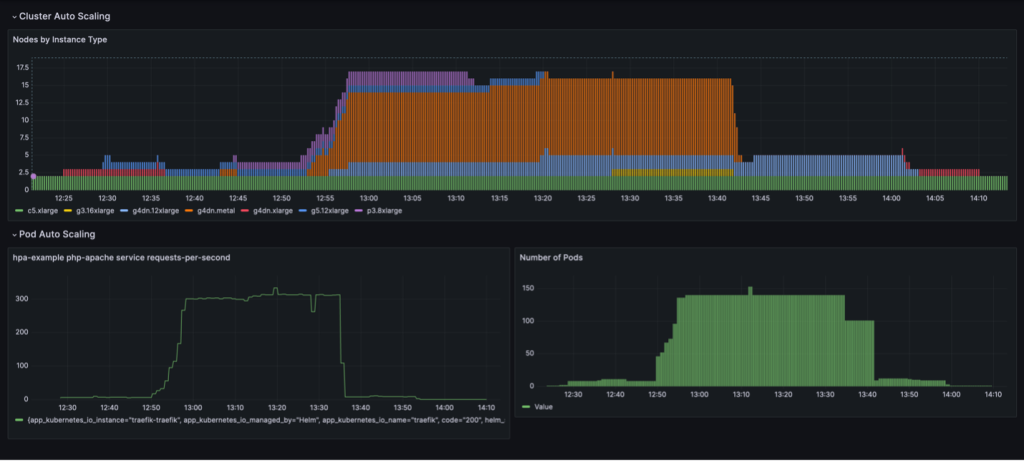
ما فقط با دو نمونه c5.xlarge CPU که کلاستر با آنها ایجاد شده است شروع می کنیم. سپس یک نمونه سرویس را مستقر می کنیم که به یک GPU واحد نیاز دارد. Karpenter یک نمونه g4dn.xlarge را برای پاسخگویی به این نیاز اضافه می کند. سپس مولد بار را مستقر می کنیم، که باعث می شود KEDA پادهای سرویس بیشتری اضافه کند و Karpenter نمونه های GPU بیشتری اضافه کند. پس از بهینه سازی، وضعیت روی یک نمونه p3.8xlarge با 8 پردازنده گرافیکی و یک نمونه g5.12xlarge با 4 پردازنده گرافیکی ثابت می شود.
هنگامی که استقرار تولید بار را به 40 نسخه تقلیل می دهیم، KEDA غلاف های سرویس اضافی را برای حفظ بار درخواست مورد نیاز در هر pod ایجاد می کند. Karpenter گرههای g4dn.metal و g4dn.12xlarge را به کلاستر اضافه میکند تا GPUهای مورد نیاز را برای پادهای اضافی فراهم کند. در حالت مقیاس شده، خوشه شامل 16 گره GPU است و حدود 300 درخواست در ثانیه را ارائه می دهد. هنگامی که مولد بار را به 1 ماکت کاهش می دهیم، فرآیند معکوس انجام می شود. پس از دوره خنک سازی، KEDA تعداد پادهای سرویس را کاهش می دهد. سپس با اجرای غلاف های کمتر، کارپنتر گره های کم استفاده را از خوشه حذف می کند و غلاف های سرویس برای اجرا بر روی گره های کمتری ادغام می شوند. وقتی غلاف مولد بار برداشته میشود، یک غلاف سرویس در یک نمونه g4dn.xlarge با 1 GPU در حال اجرا باقی میماند. وقتی سرویس pod را نیز حذف می کنیم، خوشه در حالت اولیه تنها با دو گره CPU باقی می ماند.
ما می توانیم این رفتار را زمانی مشاهده کنیم که NodePool تنظیمات را دارد consolidationPolicy: WhenUnderutilized.
با این تنظیمات، کارپنتر به صورت پویا خوشه را با کمترین تعداد گره ممکن پیکربندی می کند، در حالی که منابع کافی برای اجرا کردن همه پادها و همچنین به حداقل رساندن هزینه را فراهم می کند.
رفتار مقیاس بندی نشان داده شده در داشبورد زیر زمانی مشاهده می شود که NodePool سیاست تجمیع تنظیم شده است WhenEmpty، همراه با consolidateAfter: 30s.
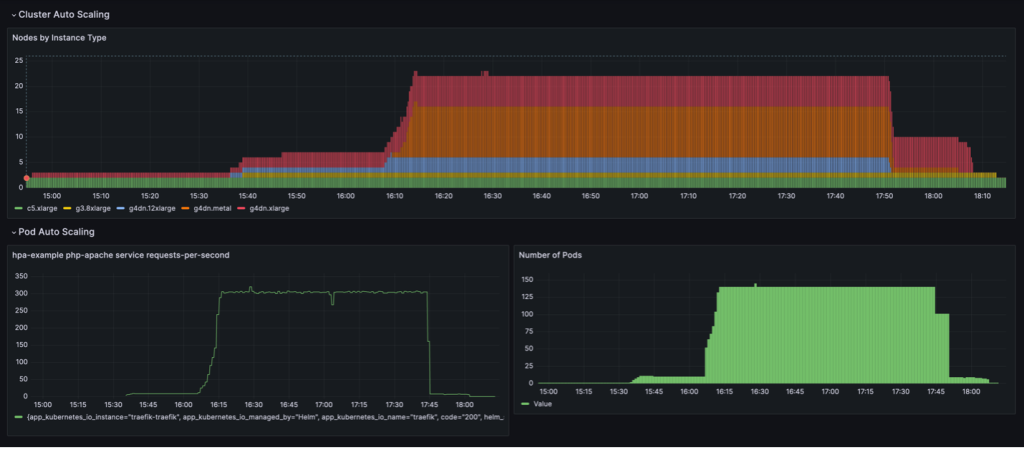
در این سناریو، گرهها تنها زمانی متوقف میشوند که پس از دوره خنکسازی، هیچ غلافی روی آنها در حال اجرا نباشد. منحنی مقیاس بندی در مقایسه با سیاست تلفیق مبتنی بر استفاده، صاف به نظر می رسد. با این حال، می توان دید که گره های بیشتری در حالت مقیاس بندی شده استفاده می شوند (22 در مقابل 16).
به طور کلی، ترکیب مقیاس خودکار غلاف و خوشه اطمینان حاصل می کند که خوشه به صورت پویا با حجم کار مقیاس می شود، منابع را در صورت نیاز تخصیص می دهد و زمانی که استفاده نمی شود حذف می شود، در نتیجه استفاده به حداکثر می رسد و هزینه به حداقل می رسد.
عواقب
Iambic از این معماری برای فعال کردن استفاده کارآمد از GPU ها در AWS و انتقال بار کاری از CPU به GPU استفاده کرد. با استفاده از نمونههای مجهز به EC2 GPU، Amazon EKS و Karpenter، ما توانستیم استنتاج سریعتری را برای مدلهای مبتنی بر فیزیک خود و زمانهای تکرار آزمایش سریعتر را برای دانشمندان کاربردی که به آموزش به عنوان یک سرویس متکی هستند، فعال کنیم.
جدول زیر برخی از معیارهای زمانی این مهاجرت را خلاصه می کند.
| کار | پردازنده ها | GPU ها |
| استنتاج با استفاده از مدلهای انتشار برای مدلهای ML مبتنی بر فیزیک | ثانیه 3,600 |
ثانیه 100 (به دلیل دسته بندی ذاتی پردازنده های گرافیکی) |
| آموزش مدل ML به عنوان یک سرویس | دقیقه 180 | دقیقه 4 |
جدول زیر برخی از معیارهای زمان و هزینه ما را خلاصه می کند.
| کار | عملکرد/هزینه | |
| پردازنده ها | GPU ها | |
| آموزش مدل ML |
دقیقه 240 میانگین 0.70 دلار برای هر کار آموزشی |
دقیقه 20 میانگین 0.38 دلار برای هر کار آموزشی |
خلاصه
در این پست، ما نشان دادیم که چگونه Iambic از Karpenter و KEDA برای مقیاسبندی زیرساخت Amazon EKS ما برای برآورده کردن الزامات تأخیر در استنتاج هوش مصنوعی و بارهای کاری ما استفاده کرد. Karpenter و KEDA ابزارهای منبع باز قدرتمندی هستند که به مقیاس خودکار کلاسترهای EKS و بارهای کاری در حال اجرا بر روی آنها کمک می کنند. این به بهینهسازی هزینههای محاسباتی و در عین حال برآوردن الزامات عملکرد کمک میکند. شما می توانید کد را بررسی کنید و با دنبال کردن مراحل کامل در این، همان معماری را در محیط خود مستقر کنید GitHub repo.
درباره نویسنده
 متیو ولبورن مدیر یادگیری ماشین در Iambic Therapeutics است. او و تیمش از هوش مصنوعی برای تسریع در شناسایی و توسعه درمانهای جدید استفاده میکنند و داروهای نجاتبخش را سریعتر به بیماران میرسانند.
متیو ولبورن مدیر یادگیری ماشین در Iambic Therapeutics است. او و تیمش از هوش مصنوعی برای تسریع در شناسایی و توسعه درمانهای جدید استفاده میکنند و داروهای نجاتبخش را سریعتر به بیماران میرسانند.
 پل ویتمور مهندس اصلی در Iambic Therapeutics است. او از ارائه زیرساخت برای پلت فرم کشف دارو مبتنی بر هوش مصنوعی Iambic پشتیبانی می کند.
پل ویتمور مهندس اصلی در Iambic Therapeutics است. او از ارائه زیرساخت برای پلت فرم کشف دارو مبتنی بر هوش مصنوعی Iambic پشتیبانی می کند.
 الکس ایانکولسکی یک معمار اصلی راهحلها، چارچوب ML/AI است که بر کمک به مشتریان تمرکز دارد تا حجم کاری هوش مصنوعی خود را با استفاده از کانتینرها و زیرساختهای محاسباتی سریع در AWS هماهنگ کنند.
الکس ایانکولسکی یک معمار اصلی راهحلها، چارچوب ML/AI است که بر کمک به مشتریان تمرکز دارد تا حجم کاری هوش مصنوعی خود را با استفاده از کانتینرها و زیرساختهای محاسباتی سریع در AWS هماهنگ کنند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/scale-ai-training-and-inference-for-drug-discovery-through-amazon-eks-and-karpenter/

