با ظهور هوش مصنوعی مولد، مدلهای پایه امروزی (FMs)، مانند مدلهای زبان بزرگ (LLMs) Claude 2 و Llama 2، میتوانند طیف وسیعی از وظایف مولد مانند پاسخگویی به سؤال، خلاصهسازی و ایجاد محتوا را بر روی دادههای متنی انجام دهند. با این حال، دادههای دنیای واقعی در حالتهای متعددی مانند متن، تصویر، ویدئو و صدا وجود دارند. برای مثال یک اسلاید پاورپوینت را در نظر بگیرید. این می تواند حاوی اطلاعاتی در قالب متن یا جاسازی شده در نمودارها، جداول و تصاویر باشد.
در این پست راه حلی را ارائه می دهیم که از FM های چند وجهی مانند آمازون Titan Multimodal Embeddings مدل و LLaVA 1.5 و خدمات AWS از جمله بستر آمازون و آمازون SageMaker برای انجام وظایف مولد مشابه روی داده های چندوجهی.
بررسی اجمالی راه حل
این راه حل پیاده سازی برای پاسخ به سوالات با استفاده از اطلاعات موجود در متن و عناصر بصری یک عرشه اسلاید فراهم می کند. طراحی بر مفهوم نسل افزوده بازیابی (RAG) متکی است. به طور سنتی، RAG با داده های متنی مرتبط است که می توانند توسط LLM ها پردازش شوند. در این پست، RAG را گسترش می دهیم تا تصاویر را نیز شامل شود. این یک قابلیت جستجوی قدرتمند برای استخراج محتوای مرتبط با زمینه از عناصر بصری مانند جداول و نمودارها همراه با متن فراهم می کند.
راه های مختلفی برای طراحی راه حل RAG که شامل تصاویر است وجود دارد. ما یک رویکرد را در اینجا ارائه کردهایم و در پست دوم این مجموعه سه قسمتی، رویکردی جایگزین را دنبال خواهیم کرد.
این راه حل شامل اجزای زیر است:
- مدل آمازون Titan Multimodal Embeddings - این FM برای ایجاد جاسازی برای محتوای موجود در عرشه اسلاید استفاده شده در این پست استفاده می شود. به عنوان یک مدل چند وجهی، این مدل Titan می تواند متن، تصاویر یا ترکیبی را به عنوان ورودی پردازش کند و جاسازی ها را ایجاد کند. مدل Titan Multimodal Embeddings بردارهایی با 1,024 بعد تولید می کند و از طریق Amazon Bedrock قابل دسترسی است.
- Large Language and Vision Assistant (LLaVA) – LLaVA یک مدل چندوجهی منبع باز برای درک بصری و زبانی است و برای تفسیر داده های موجود در اسلایدها از جمله عناصر بصری مانند نمودارها و جداول استفاده می شود. ما از نسخه 7 میلیاردی پارامتر استفاده می کنیم LLaVA 1.5-7b در این راه حل
- آمازون SageMaker – مدل LLaVA با استفاده از سرویس های میزبانی SageMaker بر روی یک نقطه پایانی SageMaker مستقر می شود و ما از نقطه پایانی به دست آمده برای اجرای استنتاج ها در برابر مدل LLaVA استفاده می کنیم. ما همچنین از نوتبوکهای SageMaker برای هماهنگسازی و نشان دادن این راهحل به انتها استفاده میکنیم.
- بدون سرور جستجوی باز آمازون – OpenSearch Serverless یک پیکربندی بدون سرور درخواستی برای آن است سرویس جستجوی باز آمازون. ما از OpenSearch Serverless به عنوان یک پایگاه داده برداری برای ذخیره جاسازی های تولید شده توسط مدل Titan Multimodal Embeddings استفاده می کنیم. ایندکس ایجاد شده در مجموعه OpenSearch Serverless به عنوان ذخیره بردار برای راه حل RAG ما عمل می کند.
- جذب جستجوی باز آمازون (OSI) – OSI یک گردآورنده داده کاملاً مدیریت شده و بدون سرور است که داده ها را به دامنه های سرویس OpenSearch و مجموعه های OpenSearch Serverless تحویل می دهد. در این پست، ما از یک خط لوله OSI برای تحویل داده ها به فروشگاه برداری بدون سرور OpenSearch استفاده می کنیم.
معماری راه حل
طراحی راه حل شامل دو بخش است: جذب و تعامل کاربر. در طول دریافت، ما عرشه اسلاید ورودی را با تبدیل هر اسلاید به یک تصویر پردازش میکنیم، جاسازیهایی را برای این تصاویر ایجاد میکنیم و سپس ذخیرهسازی دادههای برداری را پر میکنیم. این مراحل قبل از مراحل تعامل کاربر تکمیل می شوند.
در مرحله تعامل با کاربر، یک سوال از کاربر به تعبیهها تبدیل میشود و یک جستجوی شباهت در پایگاه داده برداری انجام میشود تا اسلایدی پیدا شود که به طور بالقوه میتواند حاوی پاسخهایی برای سؤال کاربر باشد. سپس این اسلاید (در قالب یک فایل تصویری) را به مدل LLaVA و سؤال کاربر به عنوان یک اعلان برای ایجاد پاسخ به سؤال ارائه می دهیم. تمام کدهای این پست در آدرس موجود است GitHub مخزن.
نمودار زیر معماری جذب را نشان می دهد.

مراحل گردش کار به شرح زیر است:
- اسلایدها به فایل های تصویری (یکی در هر اسلاید) با فرمت JPG تبدیل می شوند و برای ایجاد جاسازی به مدل Titan Multimodal Embeddings منتقل می شوند. در این پست از اسلاید دک با عنوان استفاده می کنیم با استفاده از AWS Trainium & AWS Inferentia، Stable Diffusion را آموزش و اجرا کنید از نشست AWS در تورنتو، ژوئن 2023، برای نشان دادن راه حل. عرشه نمونه دارای 31 اسلاید است، بنابراین ما 31 مجموعه از جاسازی های برداری را تولید می کنیم که هر کدام با 1,024 ابعاد هستند. ما فیلدهای فراداده اضافی را به این جاسازی های برداری ایجاد شده اضافه می کنیم و یک فایل JSON ایجاد می کنیم. این فیلدهای فراداده اضافی را می توان برای انجام پرس و جوهای جستجوی غنی با استفاده از قابلیت های جستجوی قدرتمند OpenSearch استفاده کرد.
- جاسازی های ایجاد شده در یک فایل JSON که در آن آپلود می شود کنار هم قرار می گیرند سرویس ذخیره سازی ساده آمازون (Amazon S3).
- از طريق اطلاعیه های رویداد آمازون S3، یک رویداد در یک قرار داده می شود سرویس صف ساده آمازون صف (Amazon SQS).
- این رویداد در صف SQS به عنوان یک ماشه برای اجرای خط لوله OSI عمل می کند که به نوبه خود داده ها (فایل JSON) را به عنوان اسناد در فهرست OpenSearch Serverless وارد می کند. توجه داشته باشید که نمایه OpenSearch Serverless به عنوان سینک برای این خط لوله پیکربندی شده است و به عنوان بخشی از مجموعه OpenSearch Serverless ایجاد شده است.
نمودار زیر معماری تعامل کاربر را نشان می دهد.
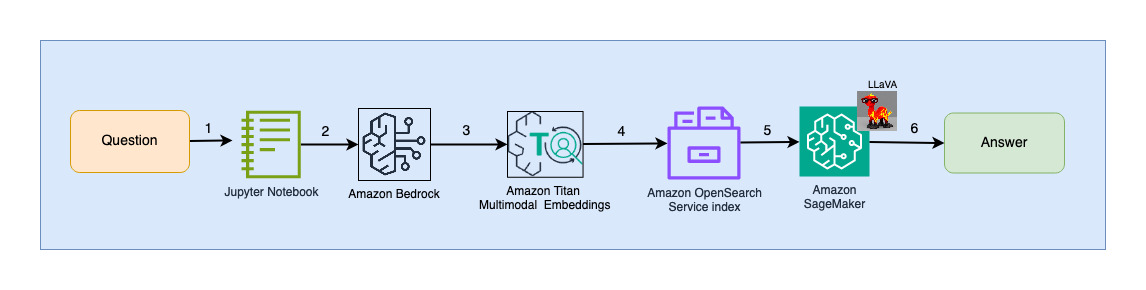
مراحل گردش کار به شرح زیر است:
- یک کاربر سؤالی مربوط به عرشه اسلایدی که بلعیده شده است ارسال می کند.
- ورودی کاربر با استفاده از مدل Titan Multimodal Embeddings که از طریق Amazon Bedrock قابل دسترسی است، به جاسازی ها تبدیل می شود. جستجوی برداری OpenSearch با استفاده از این جاسازی ها انجام می شود. ما یک جستوجوی k-نزدیکترین همسایه (k=1) انجام میدهیم تا مرتبطترین جاسازی مطابق با درخواست کاربر را بازیابی کنیم. تنظیم k=1 مرتبط ترین اسلاید را به سوال کاربر بازیابی می کند.
- فراداده پاسخ از OpenSearch Serverless حاوی مسیری به تصویر مربوط به مرتبط ترین اسلاید است.
- یک اعلان با ترکیب سوال کاربر و مسیر تصویر ایجاد می شود و به LLaVA میزبانی شده در SageMaker ارائه می شود. مدل LLaVA با بررسی داده های موجود در تصویر قادر به درک سوال کاربر و پاسخ به آن است.
- نتیجه این استنتاج به کاربر بازگردانده می شود.
این مراحل در بخش های بعدی به تفصیل مورد بحث قرار گرفته است. را ببینید نتایج بخش برای اسکرین شات ها و جزئیات خروجی.
پیش نیازها
برای پیاده سازی راه حل ارائه شده در این پست، باید یک حساب AWS و آشنایی با FMs، Amazon Bedrock، SageMaker و OpenSearch Service.
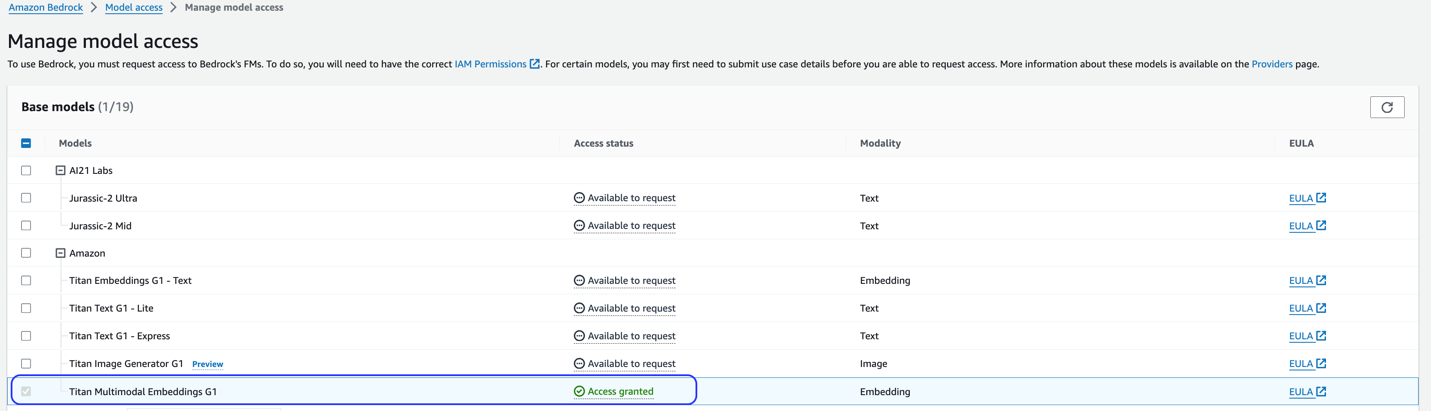
این راه حل از مدل Titan Multimodal Embeddings استفاده می کند. اطمینان حاصل کنید که این مدل برای استفاده در Amazon Bedrock فعال است. در کنسول بستر آمازون، انتخاب کنید دسترسی مدل در صفحه ناوبری اگر Titan Multimodal Embeddings فعال باشد، وضعیت دسترسی مشخص می شود دسترسی به داده.
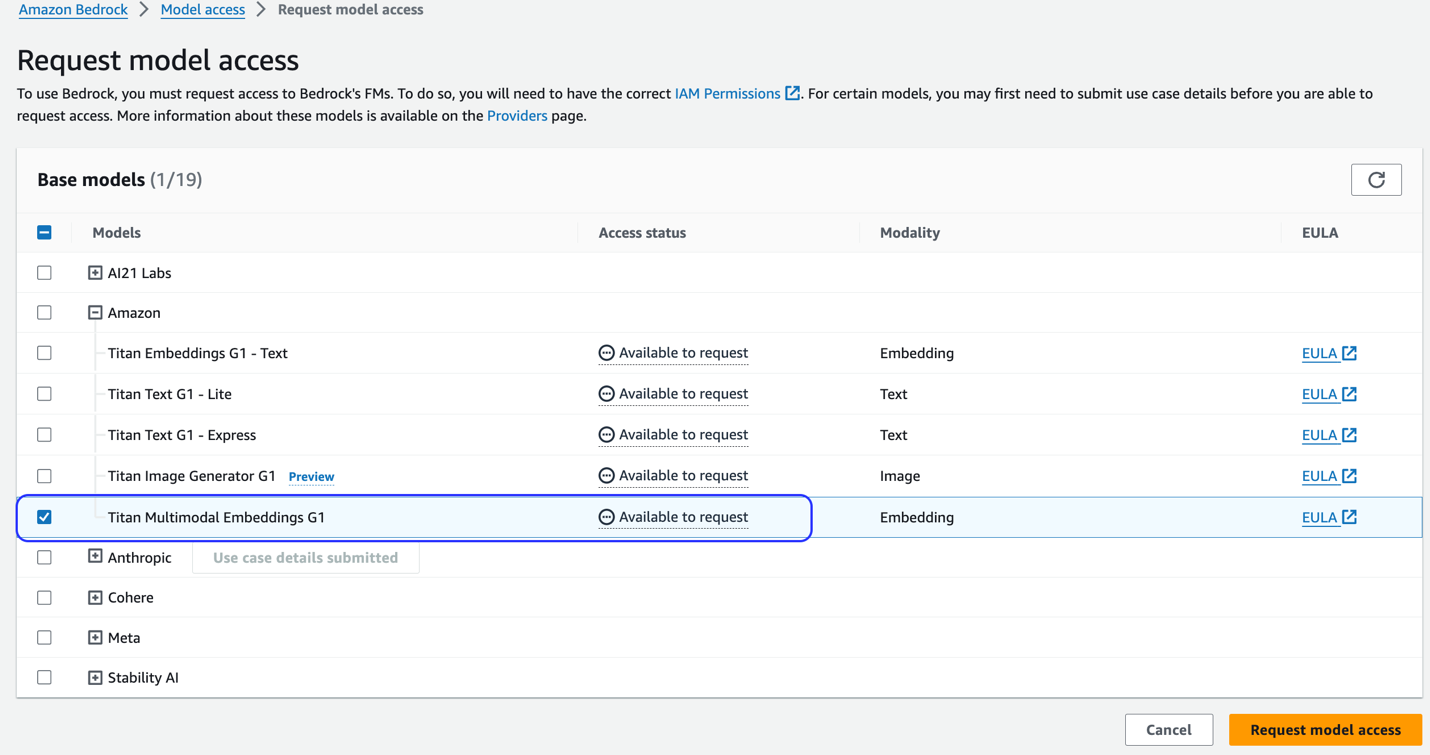
اگر مدل در دسترس نیست، با انتخاب، دسترسی به مدل را فعال کنید مدیریت دسترسی مدل، انتخاب کنید Titan Multimodal Embeddings G1، و انتخاب درخواست دسترسی مدل. این مدل بلافاصله برای استفاده فعال می شود.
از یک الگوی AWS CloudFormation برای ایجاد پشته راه حل استفاده کنید
از یکی از موارد زیر استفاده کنید AWS CloudFormation قالب ها (بسته به منطقه شما) برای راه اندازی منابع راه حل.
| منطقه AWS | ارتباط دادن |
|---|---|
us-east-1 |
|
us-west-2 |
پس از اینکه پشته با موفقیت ایجاد شد، به پشته بروید خروجی روی کنسول AWS CloudFormation برگه بزنید و مقدار آن را یادداشت کنید MultimodalCollectionEndpoint، که در مراحل بعدی از آن استفاده می کنیم.

قالب CloudFormation منابع زیر را ایجاد می کند:
- نقش های IAM - به شرح زیر هویت AWS و مدیریت دسترسی نقش های (IAM) ایجاد می شود. برای اعمال این نقش ها را به روز کنید مجوزهای کمترین امتیاز.
SMExecutionRoleبا دسترسی کامل Amazon S3، SageMaker، OpenSearch Service و Bedrock.OSPipelineExecutionRoleبا دسترسی به اقدامات خاص Amazon SQS و OSI.
- نوت بوک SageMaker – تمامی کدهای این پست از طریق این نوت بوک اجرا می شود.
- مجموعه بدون سرور OpenSearch – این پایگاه داده برداری برای ذخیره و بازیابی موارد تعبیه شده است.
- خط لوله OSI - این خط لوله برای دریافت داده ها در OpenSearch Serverless است.
- سطل S3 - تمام داده های این پست در این سطل ذخیره می شود.
- صف SQS - رویدادهای راه اندازی خط لوله OSI در این صف قرار می گیرند.
الگوی CloudFormation خط لوله OSI را با پردازش Amazon S3 و Amazon SQS به عنوان منبع و یک فهرست OpenSearch Serverless به عنوان سینک پیکربندی می کند. هر شیء ایجاد شده در سطل و پیشوند S3 مشخص شده (multimodal/osi-embeddings-json) اعلانهای SQS را فعال میکند، که توسط خط لوله OSI برای وارد کردن دادهها به OpenSearch Serverless استفاده میشود.
قالب CloudFormation نیز ایجاد می کند شبکه, رمزگذاریو دسترسی به داده ها خط مشی های مورد نیاز برای مجموعه OpenSearch Serverless. این خطمشیها را بهروزرسانی کنید تا مجوزهای کمترین امتیاز را اعمال کنید.
توجه داشته باشید که نام قالب CloudFormation در نوت بوک های SageMaker ذکر شده است. اگر نام قالب پیشفرض تغییر کرد، مطمئن شوید که همان را در آن بهروزرسانی کردهاید globals.py
محلول را تست کنید
پس از تکمیل مراحل پیش نیاز و ایجاد موفقیت آمیز پشته CloudFormation، اکنون آماده آزمایش راه حل هستید:
- در کنسول SageMaker، را انتخاب کنید نوت بوک در صفحه ناوبری
- را انتخاب کنید
MultimodalNotebookInstanceنمونه نوت بوک و انتخاب کنید JupyterLab را باز کنید.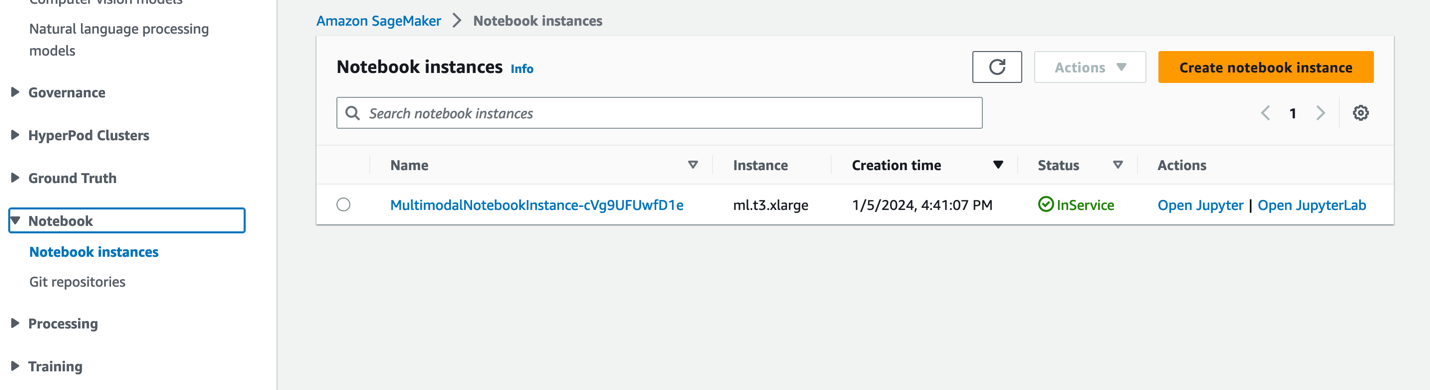
- In مرورگر پرونده، به پوشه notebooks بروید تا نوت بوک ها و فایل های پشتیبانی را ببینید.
نوت بوک ها به ترتیبی که در آن اجرا می شوند شماره گذاری می شوند. دستورالعمل ها و نظرات در هر نوت بوک اقدامات انجام شده توسط آن دفتر را توصیف می کند. ما این نوت بوک ها را یکی یکی اجرا می کنیم.
- را انتخاب کنید 0_deploy_llava.ipynb برای باز کردن آن در JupyterLab.
- بر دویدن منو ، انتخاب کنید اجرای همه سلول ها برای اجرای کد در این نوت بوک.
این نوت بوک مدل LLaVA-v1.5-7B را در نقطه پایانی SageMaker مستقر می کند. در این نوت بوک، مدل LLaVA-v1.5-7B را از HuggingFace Hub دانلود می کنیم، اسکریپت inference.py را با llava_inference.pyو یک فایل model.tar.gz برای این مدل ایجاد کنید. فایل model.tar.gz در آمازون S3 آپلود شده و برای استقرار مدل در نقطه پایانی SageMaker استفاده می شود. این llava_inference.py اسکریپت دارای کد اضافی برای خواندن یک فایل تصویری از Amazon S3 و اجرای استنتاج بر روی آن است.
- را انتخاب کنید 1_data_prep.ipynb برای باز کردن آن در JupyterLab.
- بر دویدن منو ، انتخاب کنید اجرای همه سلول ها برای اجرای کد در این نوت بوک.
این نوت بوک دانلود می کند عرشه اسلاید، هر اسلاید را به فرمت فایل JPG تبدیل می کند و آنها را در سطل S3 مورد استفاده برای این پست آپلود می کند.
- را انتخاب کنید 2_data_ingestion.ipynb برای باز کردن آن در JupyterLab.
- بر دویدن منو ، انتخاب کنید اجرای همه سلول ها برای اجرای کد در این نوت بوک.
در این دفترچه کارهای زیر را انجام می دهیم:
- ما یک فهرست در مجموعه OpenSearch Serverless ایجاد می کنیم. این شاخص داده های جاسازی ها را برای عرشه اسلاید ذخیره می کند. کد زیر را ببینید:
- ما از مدل Titan Multimodal Embeddings برای تبدیل تصاویر JPG ایجاد شده در نوت بوک قبلی به جاسازی های برداری استفاده می کنیم. این تعبیهها و ابردادههای اضافی (مانند مسیر S3 فایل تصویری) در یک فایل JSON ذخیره شده و در Amazon S3 آپلود میشوند. توجه داشته باشید که یک فایل JSON ایجاد می شود که حاوی اسنادی برای همه اسلایدها (تصاویر) تبدیل شده به جاسازی شده است. قطعه کد زیر نشان می دهد که چگونه یک تصویر (به شکل رشته رمزگذاری شده Base64) به جاسازی ها تبدیل می شود:
- این عمل باعث ایجاد خط لوله OpenSearch Ingestion می شود که فایل را پردازش کرده و در فهرست OpenSearch Serverless وارد می کند. نمونه زیر نمونه ای از فایل JSON ایجاد شده است. (بردار با چهار بعد در کد مثال نشان داده شده است. مدل Titan Multimodal Embeddings 1,024 بعد تولید می کند.)
- را انتخاب کنید 3_rag_inference.ipynb برای باز کردن آن در JupyterLab.
- بر دویدن منو ، انتخاب کنید اجرای همه سلول ها برای اجرای کد در این نوت بوک.
این نوت بوک راه حل RAG را پیاده سازی می کند: ما سوال کاربر را به جاسازی تبدیل می کنیم، یک تصویر مشابه (اسلاید) را از پایگاه داده برداری پیدا می کنیم و تصویر بازیابی شده را در اختیار LLaVA قرار می دهیم تا پاسخی برای سوال کاربر ایجاد کند. ما از الگوی سریع زیر استفاده می کنیم:
قطعه کد زیر گردش کار RAG را ارائه می دهد:
نتایج
در زیر مجموعهای از سوالات و پاسخهای کاربر است که توسط پیادهسازی ما ایجاد شده است. را سوال ستون سوال کاربر و پاسخ ستون پاسخ متنی تولید شده توسط LLaVA است. تصویر k نزدیکترین تطابق اسلاید (k=1) است که توسط جستجوی برداری بدون سرور OpenSearch برگردانده شده است. این اسلاید توسط LLaVA برای ارائه پاسخ تفسیر شده است.
نتایج RAG چند وجهی
| سوال | پاسخ | تصویر |
|---|---|---|
| عملکرد Inf2 چگونه با نمونه های EC2 قابل مقایسه است؟ من به اعداد نیاز دارم | با توجه به عرشه اسلاید، نمونه های Inf2 توسط AWS Inferentia2 در مقایسه با نمونه های EC4 قابل مقایسه، تا 10 برابر بازده بالاتر و 2 برابر تاخیر کمتر ارائه می دهند. |  |
| با توجه به چرخ لنگر AI/ML، خدمات AWS AI/ML چه چیزی را ارائه می دهند؟ | خدمات AWS AI/ML قابلیتهای بهتر $/perfer، قابلیتهای جدید و سرمایهگذاری در نوآوری را ارائه میکنند. |  |
| در مقایسه با GPT-2، GPT-3 چند پارامتر بیشتر دارد؟ تفاوت عددی بین اندازه پارامتر GPT-2 و GPT-3 چیست؟ | طبق اسلاید، GPT-3 دارای 175 میلیارد پارامتر است، در حالی که GPT-2 دارای 1.5 میلیارد پارامتر است. تفاوت عددی بین اندازه پارامتر GPT-2 و GPT-3 173.5 میلیارد است. |  |
| کوارک ها در فیزیک ذرات چیست؟ | من جواب این سوال را در عرشه اسلاید پیدا نکردم. |  |
با خیال راحت این راه حل را به عرشه اسلاید خود گسترش دهید. به سادگی متغیر SLIDE_DECK را در globals.py با یک URL به عرشه اسلاید خود به روز کنید و مراحل انتقال را که در بخش قبل توضیح داده شد اجرا کنید.
نوک
میتوانید از داشبوردهای OpenSearch برای تعامل با OpenSearch API برای اجرای آزمایشهای سریع روی فهرست و دادههای دریافتی خود استفاده کنید. تصویر زیر یک نمونه GET داشبورد OpenSearch را نشان می دهد.
پاک کردن
برای جلوگیری از تحمیل هزینههای آتی، منابعی را که ایجاد کردهاید حذف کنید. می توانید این کار را با حذف پشته از طریق کنسول CloudFormation انجام دهید.

علاوه بر این، نقطه پایانی استنتاج SageMaker ایجاد شده برای استنتاج LLaVA را حذف کنید. می توانید این کار را با حذف نظر مرحله پاکسازی انجام دهید 3_rag_inference.ipynb و اجرای سلول، یا با حذف نقطه پایانی از طریق کنسول SageMaker: را انتخاب کنید استنباط و نقاط پایان در قسمت ناوبری، سپس نقطه پایانی را انتخاب کرده و آن را حذف کنید.
نتیجه
شرکتها دائماً محتوای جدید تولید میکنند، و عرشههای اسلاید مکانیسم رایجی است که برای به اشتراک گذاشتن و انتشار اطلاعات در داخل با سازمان و در خارج با مشتریان یا در کنفرانسها استفاده میشود. با گذشت زمان، اطلاعات غنی می تواند در حالت های غیر متنی مانند نمودارها و جداول در این عرشه های اسلاید مدفون و پنهان بماند. شما می توانید از این راه حل و قدرت FM های چندوجهی مانند مدل Titan Multimodal Embeddings و LLaVA برای کشف اطلاعات جدید یا کشف دیدگاه های جدید در مورد محتوا در اسلایدها استفاده کنید.
ما شما را تشویق می کنیم که با کاوش بیشتر بیاموزید Amazon SageMaker JumpStart, مدل های آمازون تایتان، Amazon Bedrock و OpenSearch Service و ساخت راه حل با استفاده از نمونه پیاده سازی ارائه شده در این پست.
به عنوان بخشی از این مجموعه منتظر دو پست اضافی باشید. بخش 2 رویکرد دیگری را پوشش می دهد که می توانید برای صحبت با عرشه اسلاید خود در نظر بگیرید. این رویکرد استنتاج های LLaVA را تولید و ذخیره می کند و از آن استنباط های ذخیره شده برای پاسخ به پرسش های کاربر استفاده می کند. بخش 3 این دو رویکرد را با هم مقایسه می کند.
درباره نویسندگان
 آمیت آرورا یک معمار متخصص هوش مصنوعی و ML در خدمات وب آمازون است که به مشتریان سازمانی کمک می کند تا از خدمات یادگیری ماشینی مبتنی بر ابر استفاده کنند تا نوآوری های خود را به سرعت گسترش دهند. او همچنین یک مدرس کمکی در برنامه علوم داده و تجزیه و تحلیل MS در دانشگاه جورج تاون در واشنگتن دی سی است.
آمیت آرورا یک معمار متخصص هوش مصنوعی و ML در خدمات وب آمازون است که به مشتریان سازمانی کمک می کند تا از خدمات یادگیری ماشینی مبتنی بر ابر استفاده کنند تا نوآوری های خود را به سرعت گسترش دهند. او همچنین یک مدرس کمکی در برنامه علوم داده و تجزیه و تحلیل MS در دانشگاه جورج تاون در واشنگتن دی سی است.
 مانجو پراساد یک معمار ارشد راه حل در حساب های استراتژیک در خدمات وب آمازون است. او بر ارائه راهنماییهای فنی در حوزههای مختلف، از جمله AI/ML برای یک مشتری M&E متمرکز است. او قبل از پیوستن به AWS، راهحلهایی را برای شرکتهای بخش خدمات مالی و همچنین برای یک استارتآپ طراحی و ساخته بود.
مانجو پراساد یک معمار ارشد راه حل در حساب های استراتژیک در خدمات وب آمازون است. او بر ارائه راهنماییهای فنی در حوزههای مختلف، از جمله AI/ML برای یک مشتری M&E متمرکز است. او قبل از پیوستن به AWS، راهحلهایی را برای شرکتهای بخش خدمات مالی و همچنین برای یک استارتآپ طراحی و ساخته بود.
 آرچانا ایناپودی یک معمار ارشد راه حل در AWS است که از مشتریان استراتژیک پشتیبانی می کند. او بیش از یک دهه تجربه در کمک به مشتریان در طراحی و ساخت راه حل های تجزیه و تحلیل داده و پایگاه داده دارد. او مشتاق استفاده از فناوری برای ارائه ارزش به مشتریان و دستیابی به نتایج تجاری است.
آرچانا ایناپودی یک معمار ارشد راه حل در AWS است که از مشتریان استراتژیک پشتیبانی می کند. او بیش از یک دهه تجربه در کمک به مشتریان در طراحی و ساخت راه حل های تجزیه و تحلیل داده و پایگاه داده دارد. او مشتاق استفاده از فناوری برای ارائه ارزش به مشتریان و دستیابی به نتایج تجاری است.
 آنتارا رایسا یک معمار راه حل های هوش مصنوعی و ML در خدمات وب آمازون است که از مشتریان استراتژیک مستقر در دالاس، تگزاس پشتیبانی می کند. او همچنین تجربه قبلی کار با شرکای بزرگ سازمانی در AWS را دارد، جایی که او به عنوان معمار راه حل های موفقیت شریک برای مشتریان بومی دیجیتال کار می کرد.
آنتارا رایسا یک معمار راه حل های هوش مصنوعی و ML در خدمات وب آمازون است که از مشتریان استراتژیک مستقر در دالاس، تگزاس پشتیبانی می کند. او همچنین تجربه قبلی کار با شرکای بزرگ سازمانی در AWS را دارد، جایی که او به عنوان معمار راه حل های موفقیت شریک برای مشتریان بومی دیجیتال کار می کرد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/talk-to-your-slide-deck-using-multimodal-foundation-models-hosted-on-amazon-bedrock-and-amazon-sagemaker-part-1/

