Model explainability refers to the process of relating the prediction of a machine learning (ML) model to the input feature values of an instance in humanly understandable terms. This field is often referred to as explainable artificial intelligence (XAI). Amazon SageMaker Clarify is a feature of Amazon SageMaker that enables data scientists and ML engineers to explain the predictions of their ML models. It uses model agnostic methods like SHapely Additive exPlanations (SHAP) for feature attribution. Apart from supporting explanations for tabular data, Clarify also supports explainability for both computer vision (CV) and natural language processing (NLP) using the same SHAP algorithm.
In this post, we illustrate the use of Clarify for explaining NLP models. Specifically, we show how you can explain the predictions of a text classification model that has been trained using the SageMaker BlazingText algorithm. This helps you understand which parts or words of the text are most important for the predictions made by the model. Among other things, these observations can then be used to improve various processes like data acquisition that reduces bias in the dataset and model validation to ensure that models are performing as intended, and earn trust with all stakeholders when the model is deployed. This can be a key requirement in many application domains like sentiment analysis, legal reviews, medical diagnosis, and more.
We also provide a general design pattern that you can use while using Clarify with any of the SageMaker algorithms.
Solution overview
SageMaker algorithms have fixed input and output data formats. For example, the BlazingText algorithm container accepts inputs in JSON format. But customers often require specific formats that are compatible with their data pipelines. We present a couple of options that you can follow to use Clarify.
Option A
In this option, we use the inference pipeline feature of SageMaker hosting. An inference pipeline is a SageMaker model that constitutes a sequence of containers that processes inference requests. The following diagram illustrates an example.
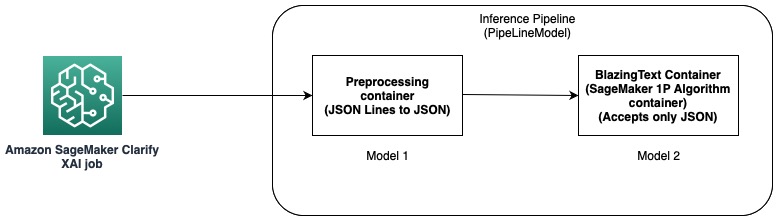
You can use inference pipelines to deploy a combination of your own custom models and SageMaker built-in algorithms packaged in different containers. For more information, refer to Hosting models along with pre-processing logic as serial inference pipeline behind one endpoint. Because Clarify supports only CSV and JSON Lines as input, you need to complete the following steps:
- Create a model and a container to convert the data from CSV (or JSON Lines) to JSON.
- After the model training step with the BlazingText algorithm, directly deploy the model. This will deploy the model using the BlazingText container, which accepts JSON as input. When using a different algorithm, SageMaker creates the model using that algorithm’s container.
- Use the preceding two models to create a PipelineModel. This chains the two models in a linear sequence and creates a single model. For an example, refer to Inference pipeline with Scikit-learn and Linear Learner.
With this solution, we have successfully created a single model whose input is compatible with Clarify and can be used by it to generate explanations.
Option B
This option demonstrates how you can integrate the use of different data formats between Clarify and SageMaker algorithms by bringing your own container for hosting the SageMaker model. The following diagram illustrates the architecture and the steps that are involved in the solution:
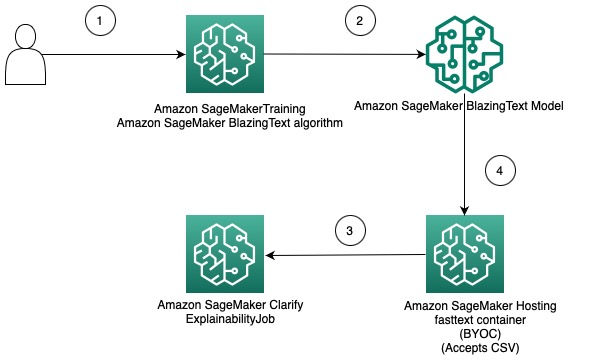
The steps are as follows:
- Use the BlazingText algorithm via the SageMaker Estimator to train a text classification model.
- After the model is trained, create a custom Docker container that can be used to create a SageMaker model and optionally deploy the model as a SageMaker model endpoint.
- Configure and create a Clarify job to use the hosting container for generating an explainability report.
- The custom container accepts the inference request as a CSV and enables Clarify to generate explanations.
It should be noted that this solution demonstrates the idea of obtaining offline explanations using Clarify for a BlazingText model. For more information about online explainability, refer to Online Explainability with SageMaker Clarify.
The rest of this post explains each of the steps in the second option.
Train a BlazingText model
We first train a text classification model using the BlazingText algorithm. In this example, we use the DBpedia Ontology dataset. DBpedia is a crowd-sourced initiative to extract structured content using information from various Wikimedia projects like Wikipedia. Specifically, we use the DBpedia ontology dataset as created by Zhang et al. It is constructed by selecting 14 non-overlapping classes from DBpedia 2014. The fields contain an abstract of a Wikipedia article and the corresponding class. The goal of a text classification model is to predict the class of an article given its abstract.
A detailed step-by-step process for training the model is available in the following notebook. After you have trained the model, take note of the Amazon Simple Storage Service (Amazon S3) URI path where the model artifacts are stored. For a step-by-step guide, refer to Text Classification using SageMaker BlazingText.
Deploy the trained BlazingText model using your own container on SageMaker
With Clarify, there are two options to provide the model information:
- Create a SageMaker model without deploying it to an endpoint – When a SageMaker model is provided to Clarify, it creates an ephemeral endpoint using the model.
- Create a SageMaker model and deploy it to an endpoint – When an endpoint is made available to Clarify, it uses the endpoint for obtaining explanations. This avoids the creation of an ephemeral endpoint and can reduce the runtime of a Clarify job.
In this post, we use the first option with Clarify. We use the SageMaker Python SDK for this purpose. For other options and more details, refer to Create your endpoint and deploy your model.
Bring your own container (BYOC)
We first build a custom Docker image that is used to create the SageMaker model. You can use the files and code in the source directory of our GitHub repository.
The Dockerfile describes the image we want to build. We start with a standard Ubuntu installation and then install Scikit-learn. We also clone fasttext and install the package. It’s used to load the BlazingText model for making predictions. Finally, we add the code that implements our algorithm in the form of the preceding files and set up the environment in the container. The entire Dockerfile is provided in our repository and you can use it as it is. Refer to Use Your Own Inference Code with Hosting Services for more details on how SageMaker interacts with your Docker container and its requirements.
Furthermore, predictor.py contains the code for loading the model and making the predictions. It accepts input data as a CSV, which makes it compatible with Clarify.
After you have the Dockerfile, build the Docker container and upload it to Amazon Elastic Container Registry (Amazon ECR). You can find the step-by-step process in the form of a shell script in our GitHub repository, which you can use to create and upload the Docker image to Amazon ECR.
Create the BlazingText model
The next step is to create a model object from the SageMaker Python SDK Model class that can be deployed to an HTTPS endpoint. We configure Clarify to use this model for generating explanations. For the code and other requirements for this step, refer to Deploy your trained SageMaker BlazingText Model using your own container in Amazon SageMaker.
Configure Clarify
Clarify NLP is compatible with regression and classification models. It helps you understand which parts of the input text influence the predictions of your model. Clarify supports 62 languages and can handle text with multiple languages. We use the SageMaker Python SDK to define the three configurations that are used by Clarify for creating the explainability report.
First, we need to create the processor object and also specify the location of the input dataset that will be used for the predictions and the feature attribution:
DataConfig
Here, you should configure the location of the input data, the feature column, and where you want the Clarify job to store the output. This is done by passing the relevant arguments while creating a DataConfig object:
ModelConfig
With ModelConfig, you should specify information about your trained model. Here, we specify the name of the BlazingText SageMaker model that we created in a prior step and also set other parameters like the Amazon Elastic Compute Cloud (Amazon EC2) instance type and the format of the content:
SHAPConfig
This is used to inform Clarify about how to obtain the feature attributions. TextConfig is used to specify the granularity of the text and the language. In our dataset, because we want to break down the input text into words and the language is English, we set these values to token and English, respectively. Depending on the nature of your dataset, you can set granularity to sentence or paragraph. The baseline is set to a special token. This means that Clarify will drop subsets of the input text and replace them with values from the baseline while obtaining predictions for computing the SHAP values. This is how it determines the effect of the tokens on the model’s predictions and in turn identifies their importance. The number of samples that are to be used in the Kernel SHAP algorithm is determined by the value of the num_samples argument. Higher values result in more robust feature attributions, but that can also increase the runtime of the job. Therefore, you need to make a trade-off between the two. See the following code:
For more information, see Feature Attributions that Use Shapley Values and Amazon AI Fairness and Explainability Whitepaper.
ModelPredictedLabelConfig
For Clarify to extract a predicted label or predicted scores or probabilities, this config object needs to be set. See the following code:
For more details, refer to the documentation in the SDK.
Run a Clarify job
After you create the different configurations, you’re now ready to trigger the Clarify processing job. The processing job validates the input and parameters, creates the ephemeral endpoint, and computes local and global feature attributions using the SHAP algorithm. When that’s complete, it deletes the ephemeral endpoint and generates the output files. See the following code:
The runtime of this step depends on the size of the dataset and the number of samples that are generated by SHAP.
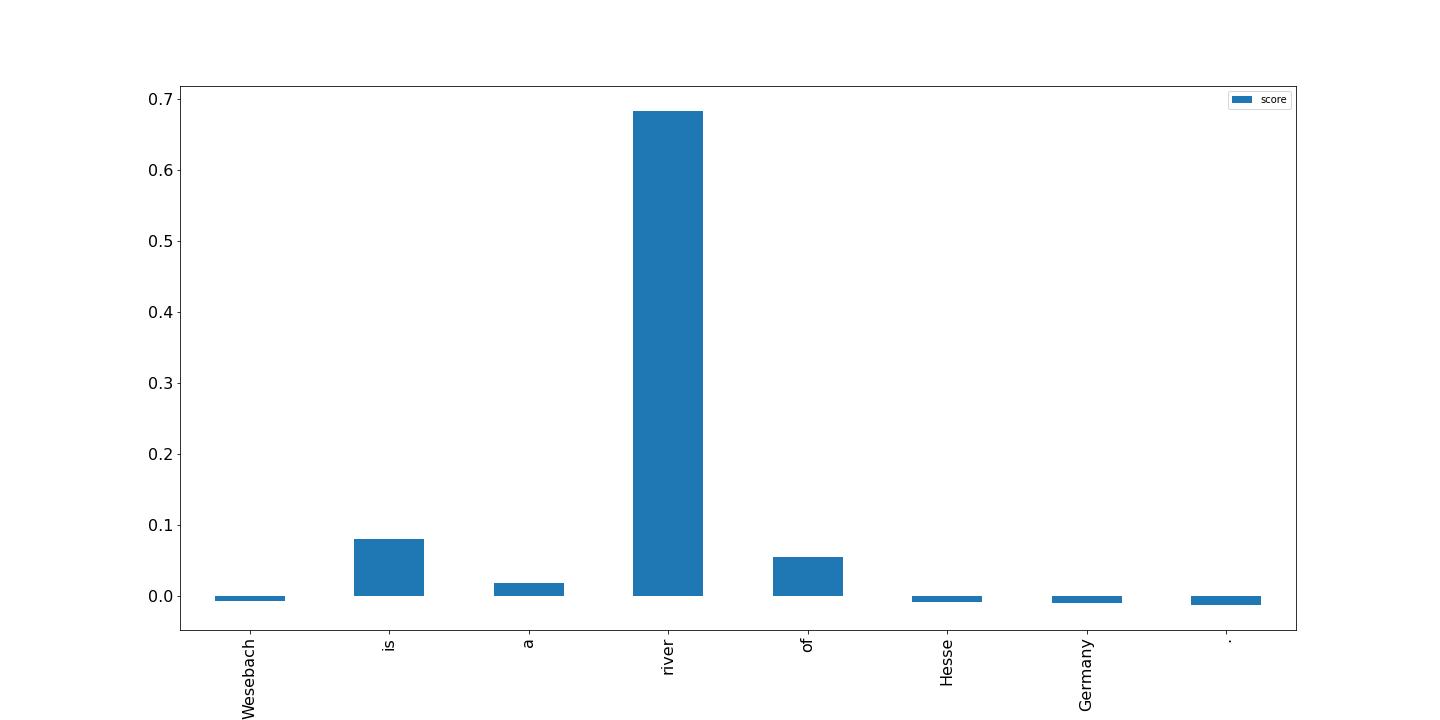
Visualize the results
Finally, we show a visualization of the results from the local feature attribution report that was generated by the Clarify processing job. The output is in a JSON Lines format and with some processing; you can plot the scores for the tokens in the input text like the following example. Higher bars have more impact on the target label. Furthermore, positive values are associated with higher predictions in the target variable and negative values with lower predictions. In this example, the model makes a prediction for the input text “Wesebach is a river of Hesse Germany.” The predicted class is Natural Place and the scores indicate that the model found the word “river” to be the most informative to make this prediction. This is intuitive for a human and by examining more samples, you can determine if the model is learning the right features and behaving as expected.
Conclusion
In this post, we explained how you can use Clarify to explain predictions from a text classification model that was trained using SageMaker BlazingText. Get started with explaining predictions from your text classification models using the sample notebook Text Explainability for SageMaker BlazingText.
We also discussed a more generic design pattern that you can use when using Clarify with SageMaker built-in algorithms. For more information, refer to What Is Fairness and Model Explainability for Machine Learning Predictions. We also encourage you to read the Amazon AI Fairness and Explainability Whitepaper, which provides an overview on the topic and discusses best practices and limitations.
About the Authors
 Pinak Panigrahi works with customers to build machine learning driven solutions to solve strategic business problems on AWS. When not occupied with machine learning, he can be found taking a hike, reading a book or catching up with sports.
Pinak Panigrahi works with customers to build machine learning driven solutions to solve strategic business problems on AWS. When not occupied with machine learning, he can be found taking a hike, reading a book or catching up with sports.
 Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- Platoblockchain. Web3 Metaverse Intelligence. Knowledge Amplified. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/explain-text-classification-model-predictions-using-amazon-sagemaker-clarify/

