Sissejuhatus
See juhend on kolmas ja viimane osa kolmest tugivektori masinaid (SVM) käsitlevast juhendist. Selles juhendis jätkame töötamist võltsitud pangatähtede kasutusjuhtumitega, teeme kiire kokkuvõtte SVM-ide üldisest ideest, mõistame, mis on tuumatrikk, ja rakendame Scikit-Learniga erinevat tüüpi mittelineaarseid tuumasid.
SVM-i juhendite täielikust seeriast saate lisaks teist tüüpi SVM-ide tundmaõppimisele teada ka lihtsate SVM-i, SVM-i eelmääratletud parameetrite, C- ja Gamma-hüperparameetrite ning nende häälestamise kohta võrguotsingu ja ristvalideerimisega.
Kui soovite lugeda eelmisi juhendeid, võite heita pilgu kahele esimesele juhendile või vaadata, millised teemad teid kõige rohkem huvitavad. Allpool on igas juhendis käsitletud teemade tabel:
- Kasutusjuht: unusta pangatähed
- SVM-ide taust
- Lihtne (lineaarne) SVM-mudel
- Andmestiku kohta
- Andmestiku importimine
- Andmestiku uurimine
- SVM-i juurutamine Scikit-Learniga
- Andmete jagamine rongi/katsekomplektideks
- Modelli koolitamine
- Ennustuste tegemine
- Mudeli hindamine
- Tulemuste tõlgendamine
- C hüperparameeter
- Gamma hüperparameeter
3. Muude SVM-i maitsete rakendamine Pythoni Scikit-Learniga
- SVM-ide üldine idee (kokkuvõte)
- Kerneli (trikk) SVM
- Mittelineaarse kerneli SVM-i juurutamine Scikit-Learniga
- Raamatukogude importimine
- Andmestiku importimine
- Andmete jagamine funktsioonideks (X) ja sihtmärgiks (y)
- Andmete jagamine rongi/katsekomplektideks
- Algoritmi treenimine
- Polünoomtuum
- Ennustuste tegemine
- Algoritmi hindamine
- Gaussi tuum
- Ennustamine ja hindamine
- Sigmoidne tuum
- Ennustamine ja hindamine
- Mittelineaarse tuuma jõudluse võrdlus
Enne huvitavate SVM-i kerneli variatsioonide nägemist meenutagem, mida SVM endast kujutab.
SVM-ide üldine idee
Lineaarselt eraldatavate kahemõõtmeliste andmete puhul (nagu on näidatud joonisel 1) oleks tüüpiline masinõppe algoritmi lähenemisviis püüda leida piir, mis jagab andmed nii, et valesti klassifitseerimise viga oleks minimaalne. Kui vaatate joonist 1 tähelepanelikult, märkige, et andmepunktid jagavad õigesti mitu piiri (lõpmatu). Nii kaks katkendjoont kui ka pidev joon on kõik kehtivad andmete klassifikatsioonid.
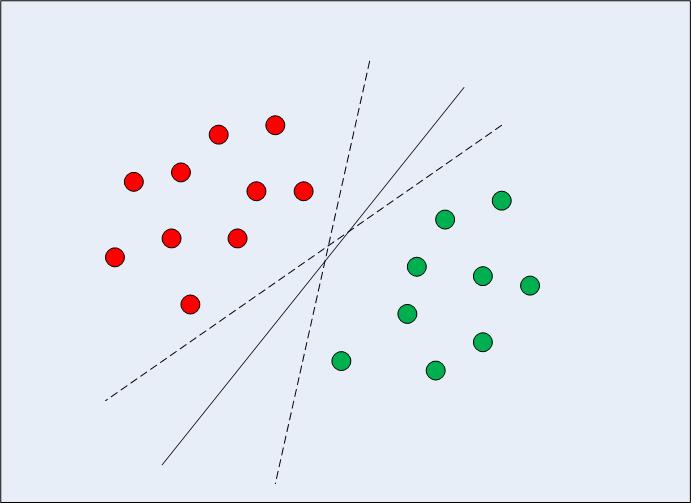
Joonis 1: Mitu otsustuspiiri
Kui SVM valib otsuse piir, valib see piiri, mis maksimeerib kauguse enda ja klasside lähimate andmepunktide vahel. Teame juba, et lähimad andmepunktid on tugivektorid ja et kaugust saab parametriseerida mõlema abil C ja gamma hüperparameetrid.
Selle otsustuspiiri arvutamisel valib algoritm, mitu punkti arvesse võtta ja kui kaugele varu võib ulatuda – see konfigureerib marginaali maksimeerimise probleemi. Selle marginaali maksimeerimise probleemi lahendamisel kasutab SVM tugivektoreid (nagu on näha joonisel 2) ja püüab välja selgitada, millised on optimaalsed väärtused, mis hoiavad veerise kaugust suuremana, klassifitseerides samal ajal rohkem punkte õigesti vastavalt funktsioonile, mida kasutatakse eraldage andmed.
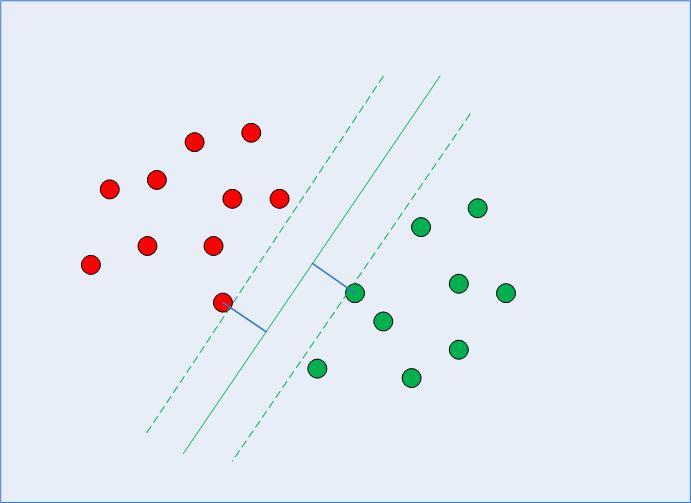
Joonis 2: Otsuse piir koos tugivektoritega
See on põhjus, miks SVM erineb teistest klassifitseerimisalgoritmidest, kuna see ei leia lihtsalt otsustuspiiri, vaid leiab lõpuks ka optimaalse otsustuspiiri.
Toevektorite leidmise, otsustuspiiri ja tugivektorite vahelise varu arvutamise ja selle marginaali maksimeerimise taga on keeruline matemaatika, mis on tuletatud statistikast ja arvutusmeetoditest. Seekord me ei lasku matemaatika detailidesse.
Alati on oluline sukelduda sügavamale ja veenduda, et masinõppealgoritmid ei oleks mingi salapärane loits, kuigi see, et te praegu ei teadnud kõiki matemaatilisi detaile, ei takistanud ega takista teil algoritmi täitmast ja tulemusi saada.
Nõuanne: Nüüd, kui oleme algoritmilise protsessi kokkuvõtte teinud, on selge, et andmepunktide vaheline kaugus mõjutab otsustuspiiri, mille SVM valib. andmete skaleerimine on tavaliselt vajalik SVM-klassifikaatori kasutamisel. Proovige kasutada Scikit-learni standardskaalari meetod andmete ettevalmistamiseks ja seejärel käivitage koodid uuesti, et näha, kas tulemustes on erinevusi.
Kerneli (trikk) SVM
Eelmises osas oleme meelde jätnud ja korrastanud SVM-i üldidee – vaadatuna, kuidas selle abil saab leida lineaarselt eraldatavate andmete jaoks optimaalse otsustuspiiri. Kuid mittelineaarselt eraldatavate andmete puhul, nagu on kujutatud joonisel 3, teame juba, et sirgjoont ei saa kasutada otsustuspiirina.
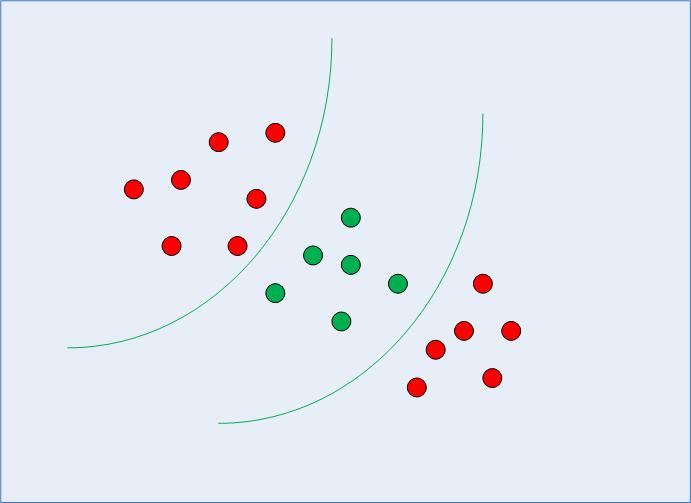
Joonis 3: Mittelineaarselt eraldatavad andmed
Pigem saame kasutada SVM-i muudetud versiooni, millest me alguses rääkisime, nimega Kernel SVM.
Põhimõtteliselt projitseerib kerneli SVM madalamate mõõtmetega mittelineaarselt eraldatavad andmed vastavale kujule kõrgemates mõõtmetes. See on trikk, sest projitseerides mittelineaarselt eraldatavaid andmeid kõrgematesse dimensioonidesse, muutub andmete kuju nii, et see muutub eraldatavaks. Näiteks kui mõelda kolmele mõõtmele, võidakse iga klassi andmepunktid paigutada erinevasse dimensiooni, muutes selle eraldatavaks. Üks viis andmete mõõtmete suurendamiseks võib olla nende eksponentsiaalne suurendamine. Jällegi on sellega seotud keeruline matemaatika, kuid SVM-i kasutamiseks ei pea te selle pärast muretsema. Pigem saame mittelineaarsete tuumade juurutamiseks ja kasutamiseks kasutada Pythoni Scikit-Learni teeki samal viisil, nagu oleme kasutanud lineaarset.
Mittelineaarse kerneli SVM-i juurutamine Scikit-Learniga
Selles jaotises kasutame sama andmestikku, et ennustada, kas pangatäht on ehtne või võltsitud nelja meile juba tuntud tunnuse järgi.
Näete, et ülejäänud toimingud on tüüpilised masinõppeetapid ja vajavad väga vähe selgitusi, kuni jõuame selle osani, kus koolitame oma mittelineaarseid kerneli SVM-e.
Raamatukogude importimine
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
Andmestiku importimine
data_link = "https://archive.ics.uci.edu/ml/machine-learning-databases/00267/data_banknote_authentication.txt"
col_names = ["variance", "skewness", "curtosis", "entropy", "class"] bankdata = pd.read_csv(data_link, names=col_names, sep=",", header=None)
bankdata.head()mes)
Andmete jagamine funktsioonideks (X) ja sihtmärgiks (y)
X = bankdata.drop('class', axis=1)
y = bankdata['class']
Andmete jagamine rongi/katsekomplektideks
SEED = 42 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = SEED)
Algoritmi treenimine
Kerneli SVM-i koolitamiseks kasutame sama SVC klassi Scikit-Learn's svm raamatukogu. Erinevus seisneb parameetri tuuma parameetri väärtuses SVC klass.
Lihtsa SVM-i puhul oleme kasutanud kerneli parameetri väärtusena lineaarset. Kuid nagu me varem mainisime, saame kerneli SVM-i jaoks kasutada Gaussi, polünoomi, sigmoid- või arvutatavaid tuumasid. Rakendame polünoomi-, Gaussi- ja sigmoidtuumad ning vaatame nende lõplikke mõõdikuid, et näha, milline neist näib sobivat meie klassidele kõrgema mõõdikuga.
1. Polünoomtuum
Algebras on polünoom järgmise vormi avaldis:
$$
2a*b^3 + 4a–9
$$
Sellel on muutujad, nt a ja b, konstandid, meie näites 9 ja koefitsiendid (konstandid koos muutujatega), nt 2 ja 4. 3 loetakse polünoomi astmeks.
On erinevaid andmetüüpe, mida saab kõige paremini kirjeldada polünoomfunktsiooni kasutamisel. Siin kaardistab kernel meie andmed polünoomiga, mille astme valime. Mida kõrgem on kraad, seda rohkem püüab funktsioon andmetele lähemale jõuda, seega on otsustuspiir paindlikum (ja kalduvus üle sobima) – mida madalam aste, seda vähem paindlik.
Tutvuge meie praktilise ja praktilise Giti õppimise juhendiga, mis sisaldab parimaid tavasid, tööstusharus aktsepteeritud standardeid ja kaasas olevat petulehte. Lõpetage Giti käskude guugeldamine ja tegelikult õppima seda!
Niisiis, rakendamiseks polünoomtuum, lisaks valikule poly kernel, edastame ka väärtuse degree parameeter SVC klass. Allpool on kood:
from sklearn.svm import SVC
svc_poly = SVC(kernel='poly', degree=8)
svc_poly.fit(X_train, y_train)
Ennustuste tegemine
Nüüd, kui oleme algoritmi välja õpetanud, on järgmine samm katseandmete põhjal prognooside tegemine.
Nagu oleme varemgi teinud, saame selleks käivitada järgmise skripti:
y_pred_poly = svclassifier.predict(X_test)
Algoritmi hindamine
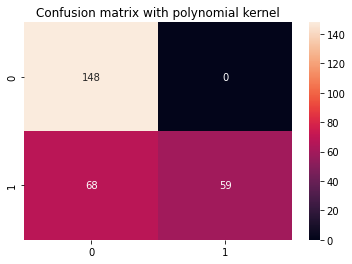
Nagu tavaliselt, on viimane samm polünoomituuma hinnangute tegemine. Kuna oleme klassifikatsiooniraporti ja segadusmaatriksi koodi paar korda korranud, siis muudame selle funktsiooniks, mis display_results pärast vastavate kättesaamist y_test, y_pred ja Seaborni segadusmaatriksi pealkiri cm_title:
def display_results(y_test, y_pred, cm_title): cm = confusion_matrix(y_test,y_pred) sns.heatmap(cm, annot=True, fmt='d').set_title(cm_title) print(classification_report(y_test,y_pred))
Nüüd saame funktsiooni kutsuda ja vaadata polünoomi tuumaga saadud tulemusi:
cm_title_poly = "Confusion matrix with polynomial kernel"
display_results(y_test, y_pred_poly, cm_title_poly)
Väljund näeb välja selline:
precision recall f1-score support 0 0.69 1.00 0.81 148 1 1.00 0.46 0.63 127 accuracy 0.75 275 macro avg 0.84 0.73 0.72 275
weighted avg 0.83 0.75 0.73 275
Nüüd saame korrata samu samme Gaussi ja sigmoidsete tuumade puhul.
2. Gaussi tuum
Gaussi tuuma kasutamiseks peame määrama väärtuseks ainult 'rbf' kernel SVC klassi parameeter:
svc_gaussian = SVC(kernel='rbf', degree=8)
svc_gaussian.fit(X_train, y_train)
Selle kerneli edasisel uurimisel saate kasutada ka ruudustikuotsingut, et kombineerida seda erinevatega C ja gamma väärtused.
Ennustamine ja hindamine
y_pred_gaussian = svc_gaussian.predict(X_test)
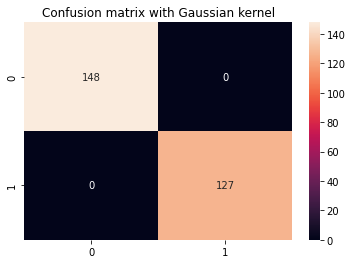
cm_title_gaussian = "Confusion matrix with Gaussian kernel"
display_results(y_test, y_pred_gaussian, cm_title_gaussian)
Gaussi kerneli SVM-i väljund näeb välja selline:
precision recall f1-score support 0 1.00 1.00 1.00 148 1 1.00 1.00 1.00 127 accuracy 1.00 275 macro avg 1.00 1.00 1.00 275
weighted avg 1.00 1.00 1.00 275
3. Sigmoidne tuum
Lõpuks kasutame Kerneli SVM-i juurutamiseks sigmoidset tuuma. Vaadake järgmist skripti:
svc_sigmoid = SVC(kernel='sigmoid')
svc_sigmoid.fit(X_train, y_train)
Sigmoidse tuuma kasutamiseks peate määrama väärtuseks 'sigmoid' kernel parameeter SVC klass.
Ennustamine ja hindamine
y_pred_sigmoid = svc_sigmoid.predict(X_test)
cm_title_sigmoid = "Confusion matrix with Sigmoid kernel"
display_results(y_test, y_pred_sigmoid, cm_title_sigmoid)
Kerneli SVM-i väljund Sigmoidi tuumaga näeb välja järgmine:
precision recall f1-score support 0 0.67 0.71 0.69 148 1 0.64 0.59 0.61 127 accuracy 0.65 275 macro avg 0.65 0.65 0.65 275
weighted avg 0.65 0.65 0.65 275

Mittelineaarse tuuma jõudluse võrdlus
Kui võrrelda lühidalt erinevat tüüpi mittelineaarsete tuumade jõudlust, võib tunduda, et sigmoidtuumal on madalaim näitajad, seega halvim jõudlus.
Gaussi ja polünoomi tuumade hulgast näeme, et Gaussi tuum saavutas täiusliku 100% ennustusmäära – mis on tavaliselt kahtlane ja võib viidata ületalitlusele, samas kui polünoomituum klassifitseeris 68 klassi 1 eksemplari valesti.
Seetõttu pole kindlat reeglit selle kohta, milline tuum toimib kõige paremini igas stsenaariumis või meie praeguses stsenaariumis ilma täiendava hüperparameetrite otsimise, iga funktsiooni kujundi mõistmise, andmete uurimise ning rongi- ja testitulemuste võrdlemiseta, et näha, kas algoritm on on üldistav.
See kõik seisneb kõigi tuumade testimises ja selle valimises parameetrite ja andmete ettevalmistamise kombinatsiooniga, mis annavad oodatud tulemused vastavalt teie projekti kontekstile.
Edasiminek – käeshoitav otsast lõpuni projekt
Sinu uudishimulik loomus tekitab sinus soovi minna kaugemale? Soovitame tutvuda meiega Juhendatud projekt: "Hands-on majahinna ennustamine – masinõpe Pythonis".

Selles juhendatud projektis saate teada, kuidas luua võimsaid traditsioonilisi masinõppemudeleid ja süvaõppe mudeleid, kasutada ansambliõpet ja koolitada meta-õppijaid, et ennustada majahindu Scikit-Learni ja Kerase mudelite koti põhjal.
Kasutades Tensorflow peale ehitatud süvaõppe API-t Keras, katsetame arhitektuuridega, loome virnastatud mudelite ansambli ja koolitame meta-õppija närvivõrk (1. taseme mudel), et välja selgitada maja hinnakujundus.
Sügav õppimine on hämmastav – kuid enne selle poole pöördumist on soovitatav proovida probleemi lahendada ka lihtsamate tehnikatega, näiteks pinnapealne õppimine algoritmid. Meie algtaseme jõudlus põhineb a Juhuslik metsa regressioon algoritm. Lisaks uurime mudelite ansamblite loomist Scikit-Learni abil selliste tehnikate abil nagu kottimine ja hääletamine.
See on otsast lõpuni projekt ja nagu kõik masinõppeprojektid, alustame sellest – koos Uurimisandmete analüüs, millele järgneb Andmete eeltöötlemine ja lõpuks Madal hoone ja Süvaõppe mudelid et sobituda varem uuritud ja puhastatud andmetega.
Järeldus
Selles artiklis tegime SVM-ide kohta kiire kokkuvõtte, uurisime tuumatrikki ja rakendasime mittelineaarsete SVM-ide erinevaid maitseid.
Soovitan teil rakendada iga tuuma ja jätkata. Saate uurida erinevate tuumade loomisel kasutatud matemaatikat, nende loomise põhjuseid ja erinevusi nende hüperparameetrite osas. Nii saate teada tehnikatest ja sellest, millist tüüpi kernelit on kõige parem kasutada, olenevalt kontekstist ja saadaolevatest andmetest.
Iga kerneli tööpõhimõtte ja selle kasutamise selge mõistmine aitab teid kindlasti teie teekonnal. Andke meile teada, kuidas edusammud lähevad, ja head kodeerimist!
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- Platoblockchain. Web3 metaversiooni intelligentsus. Täiustatud teadmised. Juurdepääs siia.
- Tuleviku rahapaja Adryenn Ashley. Juurdepääs siia.
- Allikas: https://stackabuse.com/implementing-other-svm-flavors-with-pythons-scikit-learn/

