Skaleeritavate ja tõhusate masinõppe (ML) torujuhtmete loomine on ML-mudelite arendamise, juurutamise ja haldamise sujuvamaks muutmiseks ülioluline. Selles postituses tutvustame raamistikku suunatud atsüklilise graafiku (DAG) loomise automatiseerimiseks Amazon SageMakeri torujuhtmed põhineb lihtsatel konfiguratsioonifailidel. The raamistiku kood ja näited siin esitatud hõlmab ainult mudelõppe torujuhtmeid, kuid seda saab hõlpsasti laiendada ka partii järelduste torujuhtmetele.
See dünaamiline raamistik kasutab konfiguratsioonifaile eeltöötluse, koolituse, hindamise ja registreerimise etappide korraldamiseks nii ühe- kui ka mitme mudeli kasutusjuhtudel, mis põhinevad kasutaja määratletud Pythoni skriptidel, infrastruktuuri vajadustel (sh Amazoni virtuaalne privaatpilv (Amazon VPC) alamvõrgud ja turvarühmad, AWS-i identiteedi- ja juurdepääsuhaldus (IAM) rollid, AWS-i võtmehaldusteenus (AWS KMS) võtmed, konteinerite register ja eksemplaritüübid), sisend ja väljund Amazoni lihtne salvestusteenus (Amazon S3) teed ja ressursside sildid. Konfiguratsioonifailid (YAML ja JSON) võimaldavad ML-i praktikutel määrata diferentseerimata koodi koolituskonveierite korraldamiseks deklaratiivse süntaksi abil. See võimaldab andmeteadlastel kiiresti luua ja itereerida ML-mudeleid ning võimaldab ML-i inseneridel kiiremini läbida pidevat integreerimist ja pidevat tarnimist (CI/CD) ML-konveierid, vähendades mudelite tootmiseks kuluvat aega.
Lahenduse ülevaade
Pakutud raamistiku kood algab konfiguratsioonifailide lugemisega. Seejärel loob see dünaamiliselt SageMaker Pipelines DAG-i, mis põhineb konfiguratsioonifailides deklareeritud sammudel ning etappide interaktsioonidel ja sõltuvustel. See orkestreerimisraamistik sobib nii ühe mudeli kui ka mitme mudeli kasutusjuhtudele ning tagab sujuva andmete ja protsesside voo. Selle lahenduse peamised eelised on järgmised.
- Automaatika – Kogu ML-i töövoog alates andmete eeltöötlusest kuni mudeliregistrini on korraldatud ilma käsitsi sekkumiseta. See vähendab mudeli katsetamiseks ja kasutuselevõtuks kuluvat aega ja vaeva.
- Reprodutseeritavus – Eelmääratletud konfiguratsioonifaili abil saavad andmeteadlased ja ML-insenerid kogu töövoo reprodutseerida, saavutades ühtseid tulemusi mitmes käitamises ja keskkonnas.
- Skaalautuvus - Amazon SageMaker kasutatakse kogu torujuhtme vältel, võimaldades ML-i praktikutel töödelda suuri andmekogumeid ja koolitada keerulisi mudeleid ilma infrastruktuuriprobleemideta.
- Paindlikkus – Raamistik on paindlik ja mahutab laia valikut ML-i kasutusjuhtumeid, ML-i raamistikke (nt XGBoost ja TensorFlow), mitme mudeliga koolitust ja mitmeastmelist koolitust. Iga DAG-i koolitusetappi saab konfiguratsioonifaili kaudu kohandada.
- Juhtimise mudel - Amazon SageMakeri mudeliregister integratsioon võimaldab jälgida mudeliversioone ja seega neid enesekindlalt tootmisse viia.
Järgmisel arhitektuuridiagrammil on kujutatud, kuidas saate pakutud raamistikku kasutada nii ML-mudelite katsetamise kui ka kasutuselevõtu ajal. Katsetamise ajal saate selles postituses esitatud raamistiku koodihoidla ja oma projektipõhised lähtekoodihoidlad kloonida Amazon SageMaker Studioja seadistage oma virtuaalne keskkond (üksikasju selles postituses hiljem). Seejärel saate korrata eeltöötlus-, koolitus- ja hindamisskripte ning konfiguratsioonivalikuid. SageMaker Pipelinesi koolitus-DAG loomiseks ja käitamiseks võite helistada raamistiku sisenemispunkti, mis loeb kõik konfiguratsioonifailid, loob vajalikud sammud ja korraldab need määratud sammude järjestuse ja sõltuvuste alusel.
Käivitamise ajal kloonib CI torujuhe raamistiku koodihoidla ja projektispetsiifilised koolitushoidlad AWS CodeBuild töö, kus kutsutakse välja raamistiku sisenemispunkti skript, et luua või värskendada SageMaker Pipelines koolitus-DAG ja see seejärel käivitada.

Hoidla struktuur
. GitHubi hoidla sisaldab järgmisi katalooge ja faile:
- /framework/conf/ – See kataloog sisaldab konfiguratsioonifaili, mida kasutatakse tavaliste muutujate määramiseks kõigis modelleerimisüksustes, nagu alamvõrgud, turberühmad ja IAM-i roll käitusajal. Modelleerimisüksus on kuni kuuest etapist koosnev jada ML-mudeli treenimiseks.
- /framework/createmodel/ – See kataloog sisaldab Pythoni skripti, mis loob a SageMakeri mudel objekt, mis põhineb mudeli artefaktidel alates a SageMaker Pipelines koolitusetapp. Mudelobjekti kasutatakse hiljem a SageMakeri partii teisendus töö mudeli jõudluse hindamiseks katsekomplektis.
- /framework/modelmetrics/ – See kataloog sisaldab Pythoni skripti, mis loob Amazon SageMakeri töötlemine töö mudelimõõdikute JSON-aruande genereerimiseks koolitatud mudeli jaoks, mis põhineb testandmetel tehtud SageMakeri partii teisendustöö tulemustel.
- /framework/pipeline/ – See kataloog sisaldab Pythoni skripte, mis kasutavad SageMaker Pipelines DAG-i loomiseks või värskendamiseks määratud konfiguratsioonide põhjal teistes raamistiku kataloogides määratletud Pythoni klasse. Skripti model_unit.py kasutab pipeline_service.py ühe või mitme modelleerimisüksuse loomiseks. Iga modelleerimisüksus on kuni kuuest etapist koosnev jada ML-mudeli koolitamiseks: töötlemine, treenimine, mudeli loomine, teisendamine, mõõdikud ja mudeli registreerimine. Iga modelleerimisüksuse konfiguratsioonid tuleks täpsustada mudeli vastavas hoidlas. Pipeline_service.py määrab ka sõltuvused SageMaker Pipelines'i etappide vahel (kuidas samme modelleerimisüksustes ja nende vahel järjestatakse või aheldatakse), mis põhinevad jaotisel sagemakerPipeline, mis tuleks määratleda ühe mudelihoidla (ankurmudel) konfiguratsioonifailis. See võimaldab teil alistada SageMaker Pipelinesi tuletatud vaikesõltuvused. Konfiguratsioonifaili struktuuri käsitleme hiljem selles postituses.
- /raamistik/töötlus/ – See kataloog sisaldab Pythoni skripti, mis loob määratud Dockeri kujutise ja sisestuspunkti skripti põhjal SageMakeri töötlemistöö.
- /framework/registermodel/ – See kataloog sisaldab Pythoni skripti treenitud mudeli registreerimiseks koos selle arvutatud mõõdikutega SageMakeri mudeliregistris.
- /raamistik/koolitus/ – See kataloog sisaldab Pythoni skripti, mis loob SageMakeri koolitustöö.
- /framework/transform/ – See kataloog sisaldab Pythoni skripti, mis loob SageMakeri pakkteisendustöö. Mudelitreeningu kontekstis kasutatakse seda treenitud mudeli jõudlusmõõdiku arvutamiseks katseandmete põhjal.
- /framework/utilities/ – See kataloog sisaldab utiliidi skripte konfiguratsioonifailide lugemiseks ja ühendamiseks ning logimiseks.
- /framework_entrypoint.py – See fail on raamistiku koodi sisenemispunkt. See kutsub välja funktsiooni, mis on määratletud kataloogis /framework/pipeline/, et luua või värskendada SageMaker Pipelines DAG ja seda käivitada.
- /examples/ – See kataloog sisaldab mitmeid näiteid selle kohta, kuidas saate seda automatiseerimisraamistikku kasutada lihtsate ja keerukate koolitus-DAG-de loomiseks.
- /env.env – See fail võimaldab teil määrata keskkonnamuutujatena levinud muutujaid, nagu alamvõrgud, turberühmad ja IAM-i roll.
- /requirements.txt – See fail määrab Pythoni teegid, mis on vajalikud raamistiku koodi jaoks.
Eeldused
Enne selle lahenduse juurutamist peaksid teil olema järgmised eeltingimused.
- AWS-i konto
- SageMakeri stuudio
- SageMakeri roll Amazon S3 lugemise/kirjutamise ja AWS KMS-i krüpteerimis-/dekrüpteerimisõigustega
- S3 ämber andmete, skriptide ja mudeliartefaktide salvestamiseks
- Valikuliselt AWS-i käsurea liides (AWS CLI)
- Python3 (Python 3.7 või uuem) ja järgmised Pythoni paketid:
- boto3
- salveitegija
- PyYAML
- Täiendavad Pythoni paketid, mida kasutatakse teie kohandatud skriptides
Rakendage lahendus
Lahenduse juurutamiseks tehke järgmised sammud.
- Korraldage oma mudelitreeningu hoidla järgmise struktuuri järgi:
- Kloonige raamistiku kood ja mudeli lähtekood Giti hoidlatest:
-
- Kloonide
dynamic-sagemaker-pipelines-frameworkrepo koolituskataloogi. Järgmises koodis eeldame, et koolituskataloog kutsutakseaws-train: - Kloonige mudeli lähtekood samasse kataloogi. Mitme mudeliga treenimiseks korrake seda sammu nii paljude mudelite jaoks, kui vajate treenimiseks.
- Kloonide
Ühe mudeli koolituse puhul peaks teie kataloog välja nägema järgmine:
Mitme mudeliga koolituse jaoks peaks teie kataloog välja nägema järgmine:
- Seadistage järgmised keskkonnamuutujad. Tärnid tähistavad vajalikke keskkonnamuutujaid; ülejäänud on valikulised.
| Keskkonnamuutuja | Kirjeldus |
SMP_ACCOUNTID* |
AWS-i konto, kus käitatakse SageMakeri torujuhet |
SMP_REGION* |
AWS-i piirkond, kus juhitakse SageMakeri torujuhet |
SMP_S3BUCKETNAME* |
S3 ämbri nimi |
SMP_ROLE* |
SageMakeri roll |
SMP_MODEL_CONFIGPATH* |
Ühe mudeli või mitme mudeli konfiguratsioonifailide suhteline tee |
SMP_SUBNETS |
Alamvõrgu ID-d SageMakeri võrgukonfiguratsiooni jaoks |
SMP_SECURITYGROUPS |
SageMakeri võrgukonfiguratsiooni turvarühma ID-d |
Ühe mudeli kasutusjuhtudel SMP_MODEL_CONFIGPATH on <MODEL-DIR>/conf/conf.yaml. Mitme mudeli kasutamise korral SMP_MODEL_CONFIGPATH on */conf/conf.yaml, mis võimaldab teil leida kõik conf.yaml failid Pythoni glob-mooduli abil ja ühendage need globaalseks konfiguratsioonifailiks. Katsetamise ajal (kohalik testimine) saate määrata keskkonnamuutujad failis env.env ja seejärel eksportida need, käivitades terminalis järgmise käsu:
Pange tähele, et keskkonnamuutujate väärtused on env.env tuleks panna jutumärkidesse (näiteks SMP_REGION="us-east-1"). Käivitamise ajal peaksid need keskkonnamuutujad määrama CI konveieri.
- Looge ja aktiveerige virtuaalne keskkond, käivitades järgmised käsud:
- Installige vajalikud Pythoni paketid, käivitades järgmise käsu:
- Muutke oma modellikoolitust
conf.yamlfailid. Konfiguratsioonifaili struktuuri käsitleme järgmises jaotises. - Helistage terminalist raamistiku sisenemispunkti, et luua või värskendada ja käivitada SageMaker Pipeline koolitus-DAG:
- Vaadake ja siluge saidil töötavaid SageMakeri torujuhtmeid Torujuhtmed SageMaker Studio kasutajaliidese vahekaart.
Konfiguratsioonifaili struktuur
Pakutud lahenduses on kahte tüüpi konfiguratsioonifaile: raamistiku konfiguratsioon ja mudeli konfiguratsioon. Selles jaotises kirjeldame kõiki üksikasjalikult.
Raamistiku konfiguratsioon
. /framework/conf/conf.yaml fail määrab muutujad, mis on ühised kõigis modelleerimisüksustes. See sisaldab SMP_S3BUCKETNAME, SMP_ROLE, SMP_MODEL_CONFIGPATH, SMP_SUBNETS, SMP_SECURITYGROUPSja SMP_MODELNAME. Nende muutujate kirjeldused ja nende seadmine keskkonnamuutujate kaudu leiate juurutusjuhiste 3. sammust.
Mudeli konfiguratsioon
Iga projekti mudeli jaoks peame täpsustama järgmise <MODEL-DIR>/conf/conf.yaml fail (tärnid tähistavad vajalikke jaotisi; ülejäänud on valikulised):
- /conf/models* – Selles jaotises saate konfigureerida üht või mitut modelleerimisüksust. Kui raamistiku kood käivitatakse, loeb see käitusajal automaatselt kõik konfiguratsioonifailid ja lisab need konfiguratsioonipuusse. Teoreetiliselt saate määrata kõik modelleerimisüksused samas
conf.yamlfaili, kuid vigade minimeerimiseks on soovitatav määrata iga modelleerimisüksuse konfiguratsioon vastavas kataloogis või Giti hoidlas. Üksused on järgmised:- {mudeli nimi}* – mudeli nimi.
- allika_kataloog* - Tavaline
source_dirmodelleerimisüksuse kõigi etappide jaoks kasutatav tee. - eeltöötlus – See jaotis määrab eeltöötluse parameetrid.
- rong* – Selles jaotises määratakse koolitustöö parameetrid.
- teisenda* – Selles jaotises määratakse SageMakeri teisendustöö parameetrid testandmete ennustuste tegemiseks.
- hindama – See jaotis määrab kindlaks SageMakeri töötlemistöö parameetrid koolitatud mudeli jaoks mudelimõõdikute JSON-aruande genereerimiseks.
- register* – See jaotis määrab parameetrid koolitatud mudeli registreerimiseks SageMakeri mudeliregistris.
- /conf/sagemakerPipeline* – See jaotis määratleb SageMakeri torujuhtmete voo, sealhulgas sammudevahelised sõltuvused. Ühe mudeli kasutamise korral on see jaotis määratletud konfiguratsioonifaili lõpus. Mitme mudeli kasutusjuhtudel on
sagemakerPipelinejaotis tuleb määratleda ainult ühe mudeli (ükskõik millise mudeli) konfiguratsioonifailis. Me nimetame seda mudelit kui ankurmudel. Parameetrid on järgmised:- torujuhtmenimi* – SageMakeri torujuhtme nimi.
- mudelid* – Modelleerimisüksuste pesastatud loend:
- {mudeli nimi}* – Mudeli identifikaator, mis peaks ühtima jaotises /conf/models oleva identifikaatoriga {modell-name}.
- sammud* -
- sammu_nimi* – Sammu nimi, mis kuvatakse SageMaker Pipelines DAG-is.
- step_class* – (Liit[töötlemine, koolitus, mudeli loomine, teisendus, mõõdikud, registreerimismudel])
- sammu_tüüp* – See parameeter on vajalik ainult eeltöötlusetappide jaoks, mille jaoks tuleks see seada eeltöötlusele. Seda on vaja eeltöötluse eristamiseks ja sammude hindamiseks, millel mõlemal on a
step_classtöötlemisest. - enable_cache – ([Liit[tõene, vale]]). See näitab, kas lubada SageMaker Pipelines vahemällu salvestamine selle sammu jaoks.
- chain_input_source_step – ([loend[sammu_nimi]]). Saate seda kasutada teise etapi kanaliväljundite määramiseks selle sammu sisendiks.
- ahel_sisend_lisaprefiks – See on lubatud ainult teisenduse etappide puhul
step_class, ja seda saab kasutada kooschain_input_source_stepparameeter, et määrata täpselt fail, mida tuleks kasutada teisendusetapi sisendina.
- sammud* -
- {mudeli nimi}* – Mudeli identifikaator, mis peaks ühtima jaotises /conf/models oleva identifikaatoriga {modell-name}.
- sõltuvused – See jaotis määrab järjekorra, milles SageMaker Pipelinesi samme tuleks käivitada. Oleme selle jaotise jaoks kohandanud Apache Airflow tähistust (näiteks
{step_name} >> {step_name}). Kui see jaotis jäetakse tühjaks, on määratud otsesed sõltuvusedchain_input_source_stepparameeter või kaudsed sõltuvused määratlevad SageMaker Pipelinesi DAG-voo.
Pange tähele, et soovitame teha ühe treeningsammu modelleerimisüksuse kohta. Kui modelleerimisüksuse jaoks on määratletud mitu koolitusetappi, võtavad järgmised etapid mudeliobjekti loomiseks, mõõdikute arvutamiseks ja mudeli registreerimiseks vaikimisi viimase treeningsammu. Kui teil on vaja koolitada mitut mudelit, on soovitatav luua mitu modelleerimisüksust.
Näited
Selles jaotises demonstreerime kolme näidet esitatud raamistiku abil loodud ML-mudelitreeningu DAG-idest.
Ühe mudeli koolitus: LightGBM
See on ühe mudeli näide klassifitseerimise kasutusjuhtumi kohta, kus me kasutame LightGBM skriptirežiimis SageMakeris. andmestik koosneb kategoorilistest ja numbrilistest muutujatest, et ennustada binaarset silti Tulu (ennustamiseks, kas subjekt sooritab ostu või mitte). The eeltöötlusskript kasutatakse andmete modelleerimiseks koolituse ja testimise jaoks ning seejärel lavastage see S3 ämbrisse. Seejärel antakse S3 teed treeningu samm konfiguratsioonifailis.
Kui treeningetapp jookseb, laadib SageMaker faili konteinerisse aadressil /opt/ml/input/data/{channelName}/, millele pääseb juurde keskkonnamuutuja kaudu SM_CHANNEL_{channelName} konteineri peal (channelName= 'rong' või 'test') koolituse skript teeb järgmist:
- Laadige failid kohalikult konteineriteelt, kasutades NumPy koormus moodul.
- Määrake treeningalgoritmi hüperparameetrid.
- Salvestage koolitatud mudel kohalikule konteineriteele
/opt/ml/model/.
SageMaker võtab sisu /opt/ml/model/ alla, et luua tarball, mida kasutatakse mudeli juurutamiseks SageMakeris hostimiseks.
Teisendussamm on lavastatud sisendiks testfail sisendiks ja koolitatud mudel, et teha ennustusi treenitud mudeli kohta. Teisendusetapi väljund on aheldatud mõõdikute sammu, et hinnata mudelit selle suhtes maatõde, mis on selgesõnaliselt esitatud mõõdikute etapis. Lõpuks aheldatakse mõõdikute sammu väljund kaudselt registri sammuga, et registreerida mudel SageMakeri mudeliregistris koos mõõdikute sammus toodetud mudeli jõudluse teabega. Järgmisel joonisel on kujutatud treening-DAG visuaalselt. Saate vaadata selle näite skripte ja konfiguratsioonifaili jaotises GitHub repo.
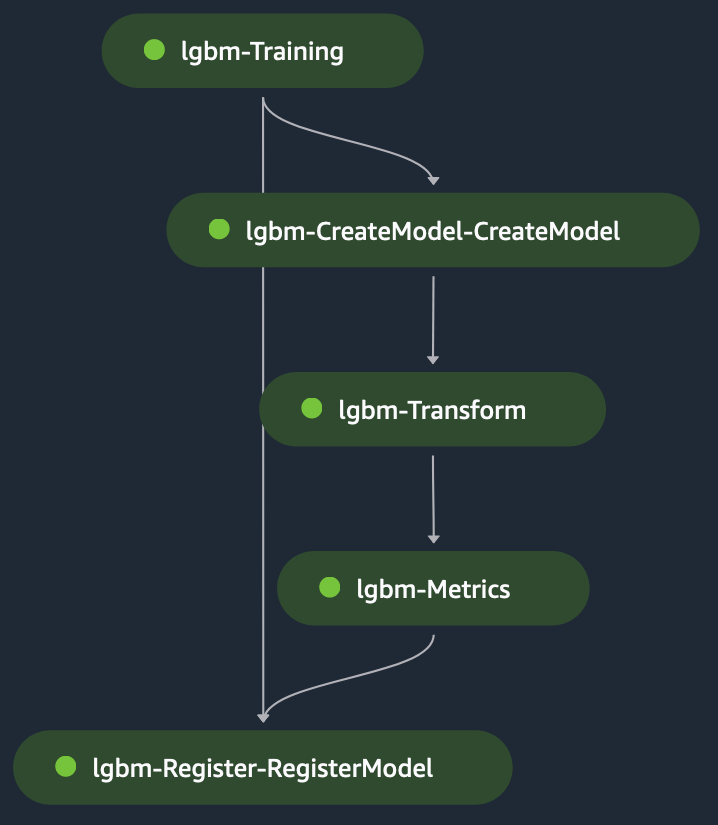
Ühe mudeli koolitus: LLM-i peenhäälestus
See on veel üks ühe mudeli koolitusnäide, kus me korraldame Hugging Face Hubi suure keelemudeli Falcon-40B (LLM) peenhäälestuse teksti kokkuvõtte kasutusjuhtumi jaoks. The eeltöötlusskript laadib samsum Hugging Face'i andmestik, laadib mudeli tokenisaatori ja töötleb rongi/testi andmete jaotusi, et täpsustada mudelit sellel domeeniandmetel falconi teksti kokkuvõtte eeltöötluse etapis.
Väljund on aheldatud pistriku-teksti kokkuvõtte-häälestuse sammule, kus koolituse skript laadib Hugging Face Hubist Falcon-40B LLM-i ja alustab kiirendatud peenhäälestamist kasutades LoRA rongis jagunes. Mudelit hinnatakse samas etapis pärast peenhäälestamist, mis väravavahid hindamiskaotus falcon-text-summerization-tuning sammu ebaõnnestumisel, mis põhjustab SageMakeri konveieri seiskumise enne, kui see suudab peenhäälestatud mudeli registreerida. Vastasel juhul kulgeb falconi teksti kokkuvõtte häälestamise samm edukalt ja mudel registreeritakse SageMakeri mudeliregistris. Järgmine joonis näitab LLM-i peenhäälestus-DAG-i visuaalset esitust. Selle näite skriptid ja konfiguratsioonifail on saadaval aadressil GitHub repo.
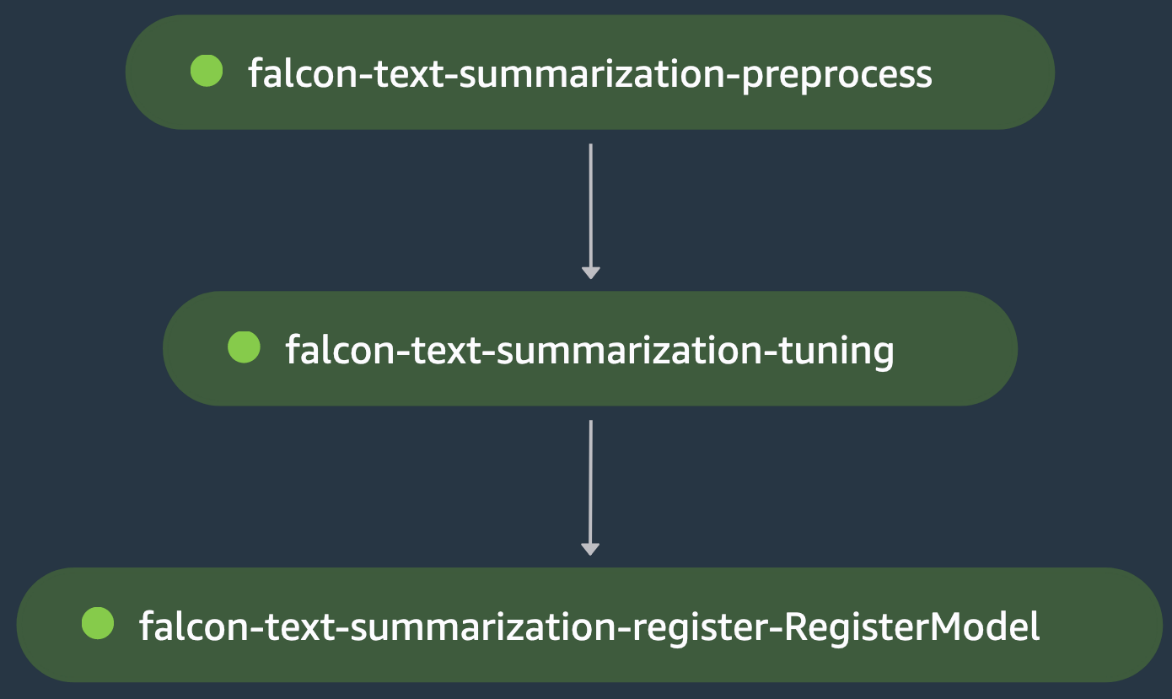
Mitme mudeli koolitus
See on mitme mudeli koolitusnäide, kus põhikomponentide analüüsi (PCA) mudelit õpetatakse mõõtmete vähendamiseks ja TensorFlow mitmekihilist perceptroni mudelit. California eluasemehinna ennustus. TensorFlow mudeli eeltöötlusetapp kasutab treenitud PCA mudelit, et vähendada treeningandmete mõõtmeid. Lisame konfiguratsiooni sõltuvuse, et tagada TensorFlow mudeli registreerimine pärast PCA mudeli registreerimist. Järgmisel joonisel on kujutatud mitme mudeliga koolituse DAG näite visuaalne esitus. Selle näite skriptid ja konfiguratsioonifailid on saadaval aadressil GitHub repo.

Koristage
Oma ressursside puhastamiseks tehke järgmised sammud.
- Kasutage selleks AWS-i CLI-d nimekiri ja kõrvaldama kõik ülejäänud Pythoni skriptidega loodud torujuhtmed.
- Soovi korral kustutage muud AWS-i ressursid, näiteks väljaspool SageMakeri torujuhtmeid loodud S3 ämber või IAM-i roll.
Järeldus
Selles postituses tutvustasime raamistikku SageMaker Pipelines DAG-i loomise automatiseerimiseks konfiguratsioonifailide põhjal. Kavandatud raamistik pakub tulevikku suunatud lahendust keerukate ML-töökoormuste korraldamise väljakutsele. Konfiguratsioonifaili kasutades pakub SageMaker Pipelines paindlikkust orkestreerimise koostamiseks minimaalse koodiga, et saaksite ühtlustada nii ühe- kui ka mitme mudeliga torujuhtmete loomise ja haldamise protsessi. See lähenemisviis mitte ainult ei säästa aega ja ressursse, vaid edendab ka MLOpsi parimaid tavasid, aidates kaasa ML-algatuste üldisele edule. Rakenduse üksikasjade kohta lisateabe saamiseks vaadake üle GitHub repo.
Autoritest
 Luis Felipe Yepez Barrios, on AWS-i professionaalsete teenustega masinõppeinsener, kes on keskendunud skaleeritavatele hajutatud süsteemidele ja automatiseerimistööriistadele, et kiirendada teaduslikku innovatsiooni masinõppe (ML) valdkonnas. Lisaks aitab ta ärikliente AWS-i teenuste kaudu nende masinõppelahendusi optimeerida.
Luis Felipe Yepez Barrios, on AWS-i professionaalsete teenustega masinõppeinsener, kes on keskendunud skaleeritavatele hajutatud süsteemidele ja automatiseerimistööriistadele, et kiirendada teaduslikku innovatsiooni masinõppe (ML) valdkonnas. Lisaks aitab ta ärikliente AWS-i teenuste kaudu nende masinõppelahendusi optimeerida.
 Jinzhao Feng, on masinõppe insener ettevõttes AWS Professional Services. Ta keskendub suuremahuliste Generative AI ja klassikaliste ML torujuhtmete lahenduste väljatöötamisele ja juurutamisele. Ta on spetsialiseerunud FMOps-le, LLMOpsile ja hajutatud koolitustele.
Jinzhao Feng, on masinõppe insener ettevõttes AWS Professional Services. Ta keskendub suuremahuliste Generative AI ja klassikaliste ML torujuhtmete lahenduste väljatöötamisele ja juurutamisele. Ta on spetsialiseerunud FMOps-le, LLMOpsile ja hajutatud koolitustele.
 Karm Asnani, on AWS-i masinõppeinsener. Tema taust on rakendusandmete teaduses, keskendudes masinõppe töökoormuste rakendamisele pilves.
Karm Asnani, on AWS-i masinõppeinsener. Tema taust on rakendusandmete teaduses, keskendudes masinõppe töökoormuste rakendamisele pilves.
 Hasan Shojaei, on vanem andmeteadlane teenuses AWS Professional Services, kus ta aitab erinevate tööstusharude klientidel lahendada nende äriprobleeme suurandmete, masinõppe ja pilvetehnoloogiate kasutamise kaudu. Enne seda rolli juhtis Hasan mitmeid algatusi, et töötada välja uudsed füüsikapõhised ja andmepõhised modelleerimistehnikad parimate energiaettevõtete jaoks. Väljaspool tööd on Hasan kirglik raamatute, matkamise, fotograafia ja ajaloo vastu.
Hasan Shojaei, on vanem andmeteadlane teenuses AWS Professional Services, kus ta aitab erinevate tööstusharude klientidel lahendada nende äriprobleeme suurandmete, masinõppe ja pilvetehnoloogiate kasutamise kaudu. Enne seda rolli juhtis Hasan mitmeid algatusi, et töötada välja uudsed füüsikapõhised ja andmepõhised modelleerimistehnikad parimate energiaettevõtete jaoks. Väljaspool tööd on Hasan kirglik raamatute, matkamise, fotograafia ja ajaloo vastu.
 Alec Jenab, on masinõppeinsener, kes on spetsialiseerunud masinõppelahenduste väljatöötamisele ja kasutuselevõtule ettevõtete klientide jaoks. Alec on kirglik uuenduslike lahenduste turule toomise vastu, eriti valdkondades, kus masinõpe võib lõppkasutaja kogemust oluliselt parandada. Väljaspool tööd meeldib talle mängida korvpalli, sõita lumelauaga ja avastada San Franciscos peidetud kalliskive.
Alec Jenab, on masinõppeinsener, kes on spetsialiseerunud masinõppelahenduste väljatöötamisele ja kasutuselevõtule ettevõtete klientide jaoks. Alec on kirglik uuenduslike lahenduste turule toomise vastu, eriti valdkondades, kus masinõpe võib lõppkasutaja kogemust oluliselt parandada. Väljaspool tööd meeldib talle mängida korvpalli, sõita lumelauaga ja avastada San Franciscos peidetud kalliskive.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- PlatoTervis. Biotehnoloogia ja kliiniliste uuringute luureandmed. Juurdepääs siia.
- Allikas: https://aws.amazon.com/blogs/machine-learning/automate-amazon-sagemaker-pipelines-dag-creation/

