Esta es una publicación invitada coescrita con el equipo de liderazgo de Iambic Therapeutics.
Terapéutica yámbica es una startup de descubrimiento de fármacos con la misión de crear tecnologías innovadoras impulsadas por IA para llevar mejores medicamentos a los pacientes con cáncer, más rápido.
Nuestras avanzadas herramientas de inteligencia artificial (IA) generativa y predictiva nos permiten buscar en el vasto espacio de posibles moléculas de fármacos de forma más rápida y eficaz. Nuestras tecnologías son versátiles y aplicables en áreas terapéuticas, clases de proteínas y mecanismos de acción. Más allá de crear herramientas de IA diferenciadas, hemos establecido una plataforma integrada que fusiona software de IA, datos basados en la nube, infraestructura de computación escalable y capacidades químicas y biológicas de alto rendimiento. La plataforma habilita nuestra IA (al proporcionar datos para refinar nuestros modelos) y es habilitada por ella, aprovechando oportunidades para la toma de decisiones y el procesamiento de datos automatizados.
Medimos el éxito por nuestra capacidad de producir candidatos clínicos superiores para abordar las necesidades urgentes de los pacientes, a una velocidad sin precedentes: avanzamos desde el lanzamiento del programa hasta los candidatos clínicos en solo 24 meses, significativamente más rápido que nuestros competidores.
En esta publicación, nos centramos en cómo usamos carpintero on Servicio Amazon Elastic Kubernetes (Amazon EKS) para escalar el entrenamiento y la inferencia de IA, que son elementos centrales de la plataforma de descubrimiento Iambic.
La necesidad de entrenamiento e inferencia de IA escalables
Cada semana, Iambic realiza inferencias de IA en docenas de modelos y millones de moléculas, lo que sirve para dos casos de uso principales:
- Los químicos medicinales y otros científicos utilizan nuestra aplicación web, Insight, para explorar el espacio químico, acceder e interpretar datos experimentales y predecir propiedades de moléculas recientemente diseñadas. Todo este trabajo se realiza de forma interactiva en tiempo real, lo que crea la necesidad de inferencia con baja latencia y rendimiento medio.
- Al mismo tiempo, nuestros modelos de IA generativa diseñan automáticamente moléculas destinadas a mejorar numerosas propiedades, buscando millones de candidatos y requiriendo un rendimiento enorme y una latencia media.
Guiada por tecnologías de inteligencia artificial y cazadores de drogas expertos, nuestra plataforma experimental genera miles de moléculas únicas cada semana, y cada una de ellas se somete a múltiples ensayos biológicos. Los puntos de datos generados se procesan y utilizan automáticamente para ajustar nuestros modelos de IA cada semana. Inicialmente, el ajuste de nuestro modelo requería horas de tiempo de CPU, por lo que era imperativo un marco para escalar el ajuste de modelo en GPU.
Nuestros modelos de aprendizaje profundo tienen requisitos no triviales: tienen un tamaño de gigabytes, son numerosos y heterogéneos, y requieren GPU para una rápida inferencia y ajuste. En cuanto a la infraestructura de la nube, necesitábamos un sistema que nos permitiera acceder a las GPU, escalar hacia arriba y hacia abajo rápidamente para manejar cargas de trabajo heterogéneas y puntiagudas y ejecutar grandes imágenes de Docker.
Queríamos construir un sistema escalable para respaldar el entrenamiento y la inferencia de IA. Usamos Amazon EKS y buscábamos la mejor solución para escalar automáticamente nuestros nodos trabajadores. Elegimos Karpenter para el escalado automático del nodo de Kubernetes por varias razones:
- Facilidad de integración con Kubernetes, utilizando la semántica de Kubernetes para definir los requisitos de los nodos y las especificaciones del pod para escalar.
- Escalamiento horizontal de nodos de baja latencia
- Facilidad de integración con nuestra infraestructura como herramienta de código (Terraform)
Los aprovisionadores de nodos admiten una integración sencilla con Amazon EKS y otros recursos de AWS, como Nube informática elástica de Amazon (Amazon EC2) instancias y Tienda de bloques elásticos de Amazon volúmenes. La semántica de Kubernetes utilizada por los proveedores admite la programación dirigida utilizando construcciones de Kubernetes, como manchas o tolerancias y especificaciones de afinidad o antiafinidad; También facilitan el control sobre la cantidad y los tipos de instancias de GPU que Karpenter puede programar.
Resumen de la solución
En esta sección, presentamos una arquitectura genérica similar a la que usamos para nuestras propias cargas de trabajo, que permite la implementación elástica de modelos utilizando un escalado automático eficiente basado en métricas personalizadas.
El siguiente diagrama ilustra la arquitectura de la solución.

La arquitectura despliega una servicio sencillo en un pod de Kubernetes dentro de un clúster EKS. Esto podría ser una inferencia de modelo, una simulación de datos o cualquier otro servicio en contenedores, accesible mediante una solicitud HTTP. El servicio está expuesto detrás de un proxy inverso usando Traefik. El proxy inverso recopila métricas sobre las llamadas al servicio y las expone a través de una API de métricas estándar para Prometeo. El escalador automático impulsado por eventos de Kubernetes (KEDA) está configurado para escalar automáticamente la cantidad de módulos de servicio, según las métricas personalizadas disponibles en Prometheus. Aquí utilizamos la cantidad de solicitudes por segundo como métrica personalizada. Se aplica el mismo enfoque arquitectónico si elige una métrica diferente para su carga de trabajo.
Karpenter monitorea cualquier pod pendiente que no pueda ejecutarse debido a la falta de recursos suficientes en el clúster. Si se detectan dichos pods, Karpenter agrega más nodos al clúster para proporcionar los recursos necesarios. Por el contrario, si hay más nodos en el clúster de los que necesitan los pods programados, Karpenter elimina algunos de los nodos trabajadores y los pods se reprograman, consolidándolos en menos instancias. El número de solicitudes HTTP por segundo y el número de nodos se pueden visualizar utilizando un Grafana panel. Para demostrar el escalado automático, ejecutamos uno o más vainas generadoras de carga simples, que envían solicitudes HTTP al servicio utilizando rizo.
Despliegue de la solución
En tutorial paso a paso, usamos Nube de AWS9 como entorno para desplegar la arquitectura. Esto permite completar todos los pasos desde un navegador web. También puede implementar la solución desde una computadora local o una instancia EC2.
Para simplificar la implementación y mejorar la reproducibilidad, seguimos los principios de la marco de trabajo y la estructura del plantilla acoplable dependiente de. Clonamos el aws-do-eks proyecto y, utilizando Docker, creamos una imagen de contenedor que está equipada con las herramientas y los scripts necesarios. Dentro del contenedor, repasamos todos los pasos del tutorial de un extremo a otro, desde la creación de un clúster EKS con Karpenter hasta el escalado. Instancias EC2.
Para el ejemplo de esta publicación, utilizamos lo siguiente Manifiesto del clúster EKS:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: do-eks-yaml-karpenter
version: '1.28'
region: us-west-2
tags:
karpenter.sh/discovery: do-eks-yaml-karpenter
iam:
withOIDC: true
addons:
- name: aws-ebs-csi-driver
version: v1.26.0-eksbuild.1
wellKnownPolicies:
ebsCSIController: true
managedNodeGroups:
- name: c5-xl-do-eks-karpenter-ng
instanceType: c5.xlarge
instancePrefix: c5-xl
privateNetworking: true
minSize: 0
desiredCapacity: 2
maxSize: 10
volumeSize: 300
iam:
withAddonPolicies:
cloudWatch: true
ebs: trueEste manifiesto define un clúster llamado do-eks-yaml-karpenter con el controlador EBS CSI instalado como complemento. Un grupo de nodos administrados con dos c5.xlarge Los nodos se incluyen para ejecutar los pods del sistema que necesita el clúster. Los nodos trabajadores están alojados en subredes privadas y el punto final de la API del clúster es público de forma predeterminada.
También podría utilizar un clúster EKS existente en lugar de crear uno. Implementamos Karpenter siguiendo las Instrucciones en la documentación de Karpenter, o ejecutando el siguiente guión, que automatiza las instrucciones de implementación.
El siguiente código muestra la configuración de Karpenter que utilizamos en este ejemplo:
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
metadata: null
labels:
cluster-name: do-eks-yaml-karpenter
annotations:
purpose: karpenter-example
spec:
nodeClassRef:
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
name: default
requirements:
- key: karpenter.sh/capacity-type
operator: In
values:
- spot
- on-demand
- key: karpenter.k8s.aws/instance-category
operator: In
values:
- c
- m
- r
- g
- p
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values:
- '2'
disruption:
consolidationPolicy: WhenUnderutilized
#consolidationPolicy: WhenEmpty
#consolidateAfter: 30s
expireAfter: 720h
---
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default
spec:
amiFamily: AL2
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "do-eks-yaml-karpenter"
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "do-eks-yaml-karpenter"
role: "KarpenterNodeRole-do-eks-yaml-karpenter"
tags:
app: autoscaling-test
blockDeviceMappings:
- deviceName: /dev/xvda
ebs:
volumeSize: 80Gi
volumeType: gp3
iops: 10000
deleteOnTermination: true
throughput: 125
detailedMonitoring: trueDefinimos un Karpenter NodePool predeterminado con los siguientes requisitos:
- Karpenter puede lanzar instancias desde ambos
spotyon-demandpiscinas de capacidad - Las instancias deben ser del “
c”(cómputo optimizado), “m" (propósito general), "r”(memoria optimizada) o “gyp”Familias informáticas (aceleradas por GPU) - La generación de instancias debe ser mayor que 2; Por ejemplo,
g3es aceptable, perog2no es
El NodePool predeterminado también define políticas de interrupción. Los nodos infrautilizados se eliminarán para que los pods se puedan consolidar para ejecutarse en menos nodos o en más pequeños. Alternativamente, podemos configurar los nodos vacíos para que se eliminen después del período de tiempo especificado. El expireAfter La configuración especifica la vida útil máxima de cualquier nodo, antes de detenerlo y reemplazarlo si es necesario. Esto ayuda a reducir las vulnerabilidades de seguridad y a evitar problemas típicos de los nodos con tiempos de actividad prolongados, como fragmentación de archivos o pérdidas de memoria.
De forma predeterminada, Karpenter aprovisiona nodos con un volumen raíz pequeño, que puede ser insuficiente para ejecutar cargas de trabajo de IA o aprendizaje automático (ML). Algunas de las imágenes de contenedores de aprendizaje profundo pueden tener un tamaño de decenas de GB y debemos asegurarnos de que haya suficiente espacio de almacenamiento en los nodos para ejecutar pods utilizando estas imágenes. Para ello definimos EC2NodeClass blockDeviceMappings, como se muestra en el código anterior.
Karpenter es responsable del escalado automático a nivel de clúster. Para configurar el escalado automático a nivel de pod, usamos KEDA para definir un recurso personalizado llamado ScaledObject, como se muestra en el siguiente código:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: keda-prometheus-hpa
namespace: hpa-example
spec:
scaleTargetRef:
name: php-apache
minReplicaCount: 1
cooldownPeriod: 30
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus- server.prometheus.svc.cluster.local:80
metricName: http_requests_total
threshold: '1'
query: rate(traefik_service_requests_total{service="hpa-example-php-apache-80@kubernetes",code="200"}[2m])El manifiesto anterior define una ScaledObject llamado keda-prometheus-hpa, que es responsable de escalar la implementación de php-apache y siempre mantiene al menos una réplica en ejecución. Escala los pods de esta implementación según la métrica http_requests_total disponible en Prometheus obtenido mediante la consulta especificada, y objetivos para escalar los pods de modo que cada pod atienda no más de una solicitud por segundo. Reduce las réplicas después de que la carga de solicitudes ha estado por debajo del umbral durante más de 30 segundos.
El especificación de implementación Para nuestro ejemplo, el servicio contiene lo siguiente. solicitudes y límites de recursos:
resources:
limits:
cpu: 500m
nvidia.com/gpu: 1
requests:
cpu: 200m
nvidia.com/gpu: 1Con esta configuración, cada uno de los módulos de servicio utilizará exactamente una GPU NVIDIA. Cuando se crean nuevos pods, estarán en estado Pendiente hasta que haya una GPU disponible. Karpenter agrega nodos de GPU al clúster según sea necesario para acomodar los pods pendientes.
A vaina generadora de carga envía solicitudes HTTP al servicio con una frecuencia preestablecida. Aumentamos el número de solicitudes aumentando el número de réplicas en el implementación del generador de carga.
En un panel de Grafana se visualiza un ciclo de escalamiento completo con consolidación de nodos basada en la utilización. El siguiente panel muestra la cantidad de nodos en el clúster por tipo de instancia (arriba), la cantidad de solicitudes por segundo (abajo a la izquierda) y la cantidad de pods (abajo a la derecha).
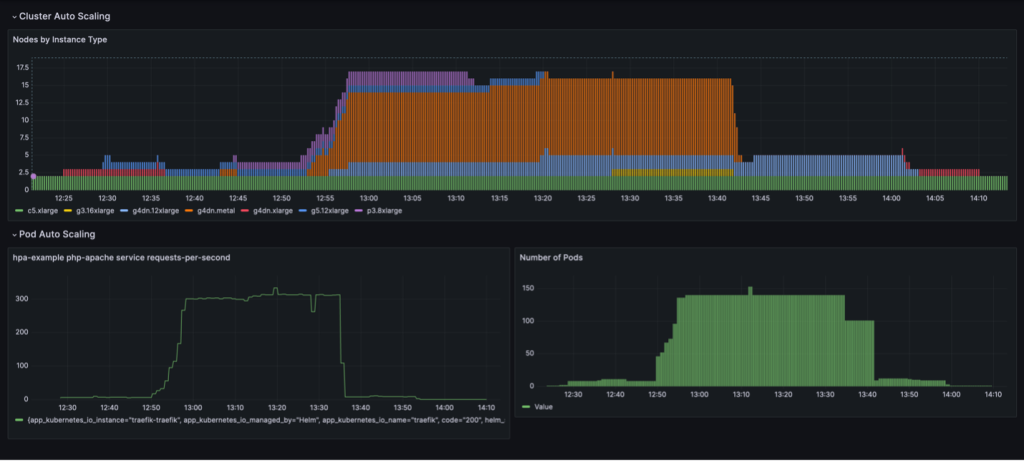
Comenzamos solo con las dos instancias de CPU c5.xlarge con las que se creó el clúster. Luego implementamos una instancia de servicio, que requiere una única GPU. Karpenter agrega una instancia g4dn.xlarge para satisfacer esta necesidad. Luego implementamos el generador de carga, lo que hace que KEDA agregue más pods de servicio y Karpenter agregue más instancias de GPU. Después de la optimización, el estado se establece en una instancia p3.8xlarge con 8 GPU y una instancia g5.12xlarge con 4 GPU.
Cuando escalamos la implementación de generación de carga a 40 réplicas, KEDA crea pods de servicio adicionales para mantener la carga de solicitudes requerida por pod. Karpenter agrega nodos g4dn.metal y g4dn.12xlarge al clúster para proporcionar las GPU necesarias para los pods adicionales. En el estado escalado, el clúster contiene 16 nodos GPU y atiende alrededor de 300 solicitudes por segundo. Cuando reducimos el generador de carga a 1 réplica, se produce el proceso inverso. Después del período de recuperación, KEDA reduce la cantidad de módulos de servicio. Luego, a medida que se ejecutan menos pods, Karpenter elimina los nodos infrautilizados del clúster y los pods de servicio se consolidan para ejecutarse en menos nodos. Cuando se elimina el pod del generador de carga, permanece ejecutándose un único pod de servicio en una única instancia de g4dn.xlarge con 1 GPU. Cuando también eliminamos el pod de servicio, el clúster queda en el estado inicial con solo dos nodos de CPU.
Podemos observar este comportamiento cuando el NodePool tiene la configuración consolidationPolicy: WhenUnderutilized.
Con esta configuración, Karpenter configura dinámicamente el clúster con la menor cantidad de nodos posible, al mismo tiempo que proporciona recursos suficientes para que se ejecuten todos los pods y también minimiza el costo.
El comportamiento de escalado que se muestra en el siguiente panel se observa cuando el NodePool La política de consolidación se centra en WhenEmpty, junto con consolidateAfter: 30s.
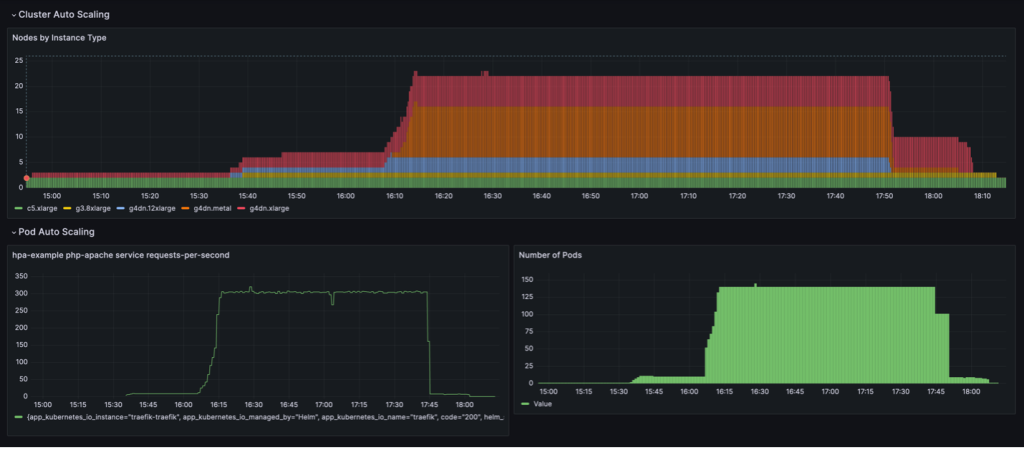
En este escenario, los nodos se detienen solo cuando no hay pods ejecutándose en ellos después del período de recuperación. La curva de escala parece suave, en comparación con la política de consolidación basada en la utilización; sin embargo, se puede ver que se utilizan más nodos en el estado escalado (22 frente a 16).
En general, la combinación del escalado automático de pods y clústeres garantiza que el clúster escale dinámicamente con la carga de trabajo, asignando recursos cuando sea necesario y eliminándolos cuando no estén en uso, maximizando así la utilización y minimizando los costos.
Resultados
Iambic utilizó esta arquitectura para permitir el uso eficiente de GPU en AWS y migrar cargas de trabajo de CPU a GPU. Al utilizar instancias con tecnología de GPU EC2, Amazon EKS y Karpenter, pudimos permitir una inferencia más rápida para nuestros modelos basados en la física y tiempos de iteración de experimentos rápidos para los científicos aplicados que dependen de la capacitación como servicio.
La siguiente tabla resume algunas de las métricas de tiempo de esta migración.
| Tarea | CPUs | GPU |
| Inferencia mediante modelos de difusión para modelos de aprendizaje automático basados en la física | 3,600 segundos |
100 segundos (debido al procesamiento por lotes inherente de GPU) |
| Entrenamiento del modelo ML como servicio | 180 minutos | 4 minutos |
La siguiente tabla resume algunas de nuestras métricas de tiempo y costos.
| Tarea | Rendimiento/Costo | |
| CPUs | GPU | |
| Entrenamiento de modelos de aprendizaje automático |
240 minutos promedio de $0.70 por tarea de capacitación |
20 minutos promedio de $0.38 por tarea de capacitación |
Resumen
En esta publicación, mostramos cómo Iambic utilizó Karpenter y KEDA para escalar nuestra infraestructura de Amazon EKS y cumplir con los requisitos de latencia de nuestras cargas de trabajo de capacitación e inferencia de IA. Karpenter y KEDA son potentes herramientas de código abierto que ayudan a escalar automáticamente los clústeres de EKS y las cargas de trabajo que se ejecutan en ellos. Esto ayuda a optimizar los costos informáticos y al mismo tiempo cumplir con los requisitos de rendimiento. Puede consultar el código e implementar la misma arquitectura en su propio entorno siguiendo el tutorial completo en este Repositorio GitHub.
Acerca de los autores
 Mateo Welborn es el director de Aprendizaje Automático en Iambic Therapeutics. Él y su equipo aprovechan la IA para acelerar la identificación y el desarrollo de nuevas terapias, llevando más rápidamente a los pacientes medicamentos que salvan vidas.
Mateo Welborn es el director de Aprendizaje Automático en Iambic Therapeutics. Él y su equipo aprovechan la IA para acelerar la identificación y el desarrollo de nuevas terapias, llevando más rápidamente a los pacientes medicamentos que salvan vidas.
 Pablo Whittemore es ingeniero principal en Iambic Therapeutics. Apoya la entrega de la infraestructura para la plataforma de descubrimiento de fármacos impulsada por IA Iambic.
Pablo Whittemore es ingeniero principal en Iambic Therapeutics. Apoya la entrega de la infraestructura para la plataforma de descubrimiento de fármacos impulsada por IA Iambic.
 Alex Iankoulski es un arquitecto principal de soluciones, ML/AI Frameworks, que se enfoca en ayudar a los clientes a orquestar sus cargas de trabajo de IA utilizando contenedores e infraestructura informática acelerada en AWS.
Alex Iankoulski es un arquitecto principal de soluciones, ML/AI Frameworks, que se enfoca en ayudar a los clientes a orquestar sus cargas de trabajo de IA utilizando contenedores e infraestructura informática acelerada en AWS.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/scale-ai-training-and-inference-for-drug-discovery-through-amazon-eks-and-karpenter/

