En el panorama empresarial actual, las organizaciones buscan constantemente formas de optimizar sus procesos financieros, mejorar la eficiencia e impulsar el ahorro de costos. Un área que tiene un importante potencial de mejora son las cuentas por pagar. En un nivel alto, el proceso de cuentas por pagar incluye la recepción y escaneo de facturas, la extracción de los datos relevantes de las facturas escaneadas, la validación, aprobación y archivo. El segundo paso (extracción) puede ser complejo. Cada factura y recibo se ven diferentes. Las etiquetas son imperfectas e inconsistentes. La información más importante, como el precio, el nombre del proveedor, la dirección del proveedor y las condiciones de pago, a menudo no están etiquetadas explícitamente y deben interpretarse en función del contexto. El enfoque tradicional de utilizar revisores humanos para extraer los datos requiere mucho tiempo, es propenso a errores y no es escalable.
En esta publicación, mostramos cómo automatizar el proceso de cuentas por pagar usando Amazon Textil para la extracción de datos. También proporcionamos una arquitectura de referencia para crear un proceso de automatización de facturas que permita la extracción, verificación, archivo y búsqueda inteligente.
Resumen de la solución
El siguiente diagrama de arquitectura muestra las etapas de un flujo de trabajo de procesamiento de recibos y facturas. Comienza con una etapa de captura de documentos para recopilar y almacenar de forma segura facturas y recibos escaneados. La siguiente etapa es la fase de extracción, donde se pasan las facturas y recibos recopilados al Amazon Textract. AnalyzeExpense API para extraer relaciones financieras entre texto, como el nombre del proveedor, la fecha de recepción de la factura, la fecha del pedido, el monto adeudado, el monto pagado, etc. En la siguiente etapa, utiliza reglas de gastos predefinidas para determinar si debe aprobar o rechazar automáticamente el recibo. Los documentos aprobados y rechazados van a sus respectivas carpetas dentro del Servicio de almacenamiento simple de Amazon (Amazon S3) cubo. Para documentos aprobados, puede buscar todos los campos y valores extraídos usando Servicio Amazon OpenSearch. Puede visualizar los metadatos indexados utilizando OpenSearch Dashboards. Los documentos aprobados también están configurados para moverse a Niveles inteligentes de Amazon S3 para retención y archivo a largo plazo mediante políticas de ciclo de vida de S3.
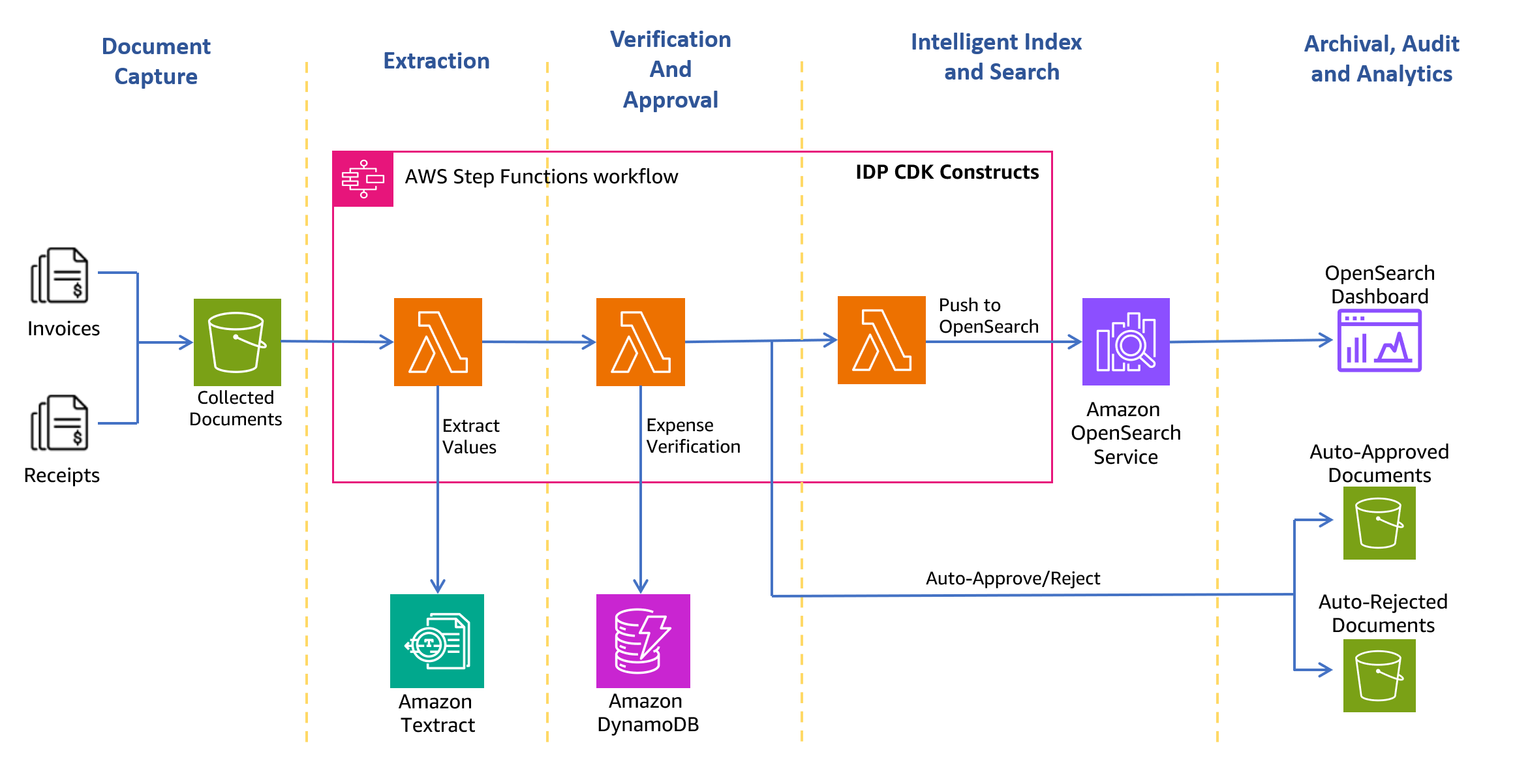
Las siguientes secciones lo guiarán a través del proceso de creación de la solución.
Requisitos previos
Para implementar esta solución, debe tener lo siguiente:
- Una cuenta de AWS.
- An Nube de AWS9 ambiente. AWS Cloud9 es un entorno de desarrollo integrado (IDE) basado en la nube que le permite escribir, ejecutar y depurar su código con solo un navegador. Incluye un editor de código, un depurador y una terminal.
Para crear el entorno de AWS Cloud9, proporcione un nombre y una descripción. Mantenga todo lo demás por defecto. Elija el enlace IDE en la consola de AWS Cloud9 para navegar al IDE. Ahora está listo para utilizar el entorno AWS Cloud9.
Implementar la solución
Para configurar la solución, utilice el Kit de desarrollo en la nube de AWS (AWS CDK) para implementar un Formación en la nube de AWS asociación.
- En su terminal IDE de AWS Cloud9, clone el Repositorio GitHub e instalar las dependencias. Ejecute los siguientes comandos para implementar el
InvoiceProcessorapilar:
La implementación demora alrededor de 25 minutos con la configuración predeterminada del repositorio de GitHub. También hay información de salida adicional disponible en la consola de AWS CloudFormation.
- Una vez completada la implementación de AWS CDK, cree reglas de validación de gastos en un Amazon DynamoDB mesa. Puede utilizar el mismo terminal AWS Cloud9 para ejecutar los siguientes comandos:
- En el depósito S3 que comienza con
invoiceprocessorworkflow-invoiceprocessorbucketf1-*, cree una carpeta de cargas.
In Cognito Amazonas, ya deberías tener un grupo de usuarios existente llamado OpenSearchResourcesCognitoUserPool*. Usamos este grupo de usuarios para crear un nuevo usuario.
- En la consola de Amazon Cognito, navegue hasta el grupo de usuarios.
OpenSearchResourcesCognitoUserPool*. - Cree un nuevo usuario de Amazon Cognito.
- Proporcione un nombre de usuario y una contraseña de su elección y anótelos para su uso posterior.
- Sube los documentos factura_aleatoria1 y factura_aleatoria2 al S3
uploadscarpeta para iniciar los flujos de trabajo.
Ahora profundicemos en cada uno de los pasos del procesamiento de documentos.
Captura de documentos
Los clientes manejan facturas y recibos en multitud de formatos de diferentes proveedores. Estos documentos se reciben a través de canales como copias impresas, copias escaneadas cargadas en un almacenamiento de archivos o dispositivos de almacenamiento compartido. En la etapa de captura de documentos, almacena todas las copias escaneadas de recibos y facturas en un almacenamiento altamente escalable, como en un depósito S3.
Extracción
La siguiente etapa es la fase de extracción, donde se pasan las facturas y recibos recopilados al Amazon Textract. AnalyzeExpense API para extraer relaciones financieras entre texto, como nombre del proveedor, fecha de recepción de la factura, fecha del pedido, monto adeudado/pagado, etc.
Analizar gastos es una API dedicada al procesamiento de documentos de facturas y recibos. Está disponible como API síncrona o asíncrona. La API sincrónica le permite enviar imágenes en formato de bytes y la API asincrónica le permite enviar archivos en formatos JPG, PNG, TIFF y PDF. El AnalyzeExpense La respuesta API consta de tres secciones distintas:
- Campos de resumen – Esta sección incluye tanto las claves normalizadas como las claves mencionadas explícitamente junto con sus valores.
AnalyzeExpensenormaliza las claves para la información relacionada con el contacto, como el nombre y la dirección del proveedor, las claves relacionadas con la identificación fiscal, como la identificación del contribuyente, las claves relacionadas con el pago, como el monto adeudado y el descuento, y las claves generales, como la identificación de la factura, la fecha de entrega y número de cuenta. Las claves que no están normalizadas siguen apareciendo en los campos de resumen como pares clave-valor. Para obtener una lista completa de los campos de gastos admitidos, consulte Análisis de facturas y recibos. - Artículos de línea – Esta sección incluye claves de artículos de línea normalizadas, como descripción del artículo, precio unitario, cantidad y código de producto.
- bloque de OCR – El bloque contiene el extracto de texto sin formato de la página de la factura. El extracto de texto sin formato se puede utilizar para posprocesar e identificar información que no está cubierta como parte de los campos de resumen y partidas individuales.
Esta publicación usa el Construcciones de CDK de IDP de Amazon Textract (Componentes de AWS CDK para definir la infraestructura para flujos de trabajo de procesamiento inteligente de documentos (IDP)), que le permite crear flujos de trabajo de IDP personalizables y específicos de casos de uso. Las construcciones y muestras son una colección de componentes para permitir la definición de procesos de IDP en AWS y publicarlos en GitHub. Los conceptos principales utilizados son las construcciones de AWS CDK, el real Pilas de AWS CDKy Funciones de paso de AWS.
La siguiente figura muestra el flujo de trabajo de Step Functions.
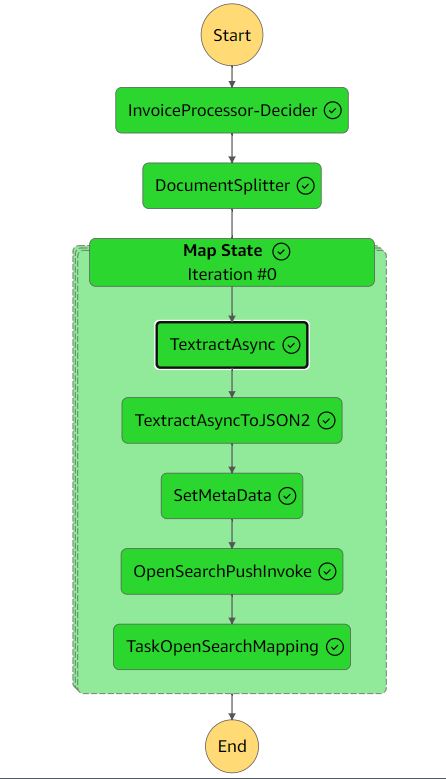
El flujo de trabajo de extracción incluye los siguientes pasos:
- Procesador de Facturas-Decisor - Un AWS Lambda función que verifica si el formato del documento de entrada es compatible con Amazon Textract. Para obtener más detalles sobre los formatos admitidos, consulte Documentos de entrada.
- Divisor de documentos – Una función Lambda que genera fragmentos de 2,500 páginas (máximo) a partir de documentos y puede procesar documentos grandes de varias páginas.
- Estado del mapa – Una función Lambda que procesa cada fragmento en paralelo.
- TextoAsync – Esta tarea llama a Amazon Textract utilizando la API asincrónica siguiente y las mejores prácticas Servicio de notificación simple de Amazon (Amazon SNS) notificaciones y usos
OutputConfigpara almacenar la salida JSON de Amazon Textract en el depósito S3 que creó anteriormente. Consta de dos funciones Lambda: una para enviar el documento para su procesamiento y otra que se activa con la notificación del SNS. - Extracto de textoAsyncToJSON2 - Porque el
TextractAsynctarea puede producir múltiples archivos de salida paginados, elTextractAsyncToJSON2El proceso los combina en un archivo JSON.
Analizamos los detalles de los siguientes tres pasos en las siguientes secciones.
Verificación y aprobación
Para la etapa de verificación, el SetMetaData La función Lambda verifica si el archivo cargado es un gasto válido según las reglas configuradas previamente en la tabla de DynamoDB. Para esta publicación, utiliza las siguientes reglas de ejemplo:
- La verificación es exitosa si
INVOICE_RECEIPT_IDestá presente y coincide con la expresión regular(?i)[0-9]{3}[a-z]{3}[0-9]{3}$y ifPO_NUMBERestá presente y coincide con la expresión regular(?i)[a-z0-9]+$ - La verificación no será exitosa si
PO_NUMBERorINVOICE_RECEIPT_IDes incorrecto o falta en el documento.
Después de procesar los archivos, la función de verificación de gastos mueve los archivos de entrada a approved or declined carpetas en el mismo depósito S3.
A los efectos de esta solución, utilizamos DynamoDB para almacenar las reglas de validación de gastos. Sin embargo, puede modificar esta solución para integrarla con soluciones de gestión o validación de gastos propias o comerciales.
Índice y búsqueda inteligentes
Con la OpenSearchPushInvoke Función Lambda, los metadatos de gastos extraídos se envían a un índice del servicio OpenSearch y están disponibles para búsqueda.
Las TaskOpenSearchMapping paso aclara el contexto, que de otro modo podría exceder el Cuota de funciones de paso del tamaño máximo de entrada o salida para una tarea, estado o ejecución de flujo de trabajo.
Una vez creado el índice del servicio OpenSearch, puede buscar palabras clave del texto extraído a través de los paneles de OpenSearch.
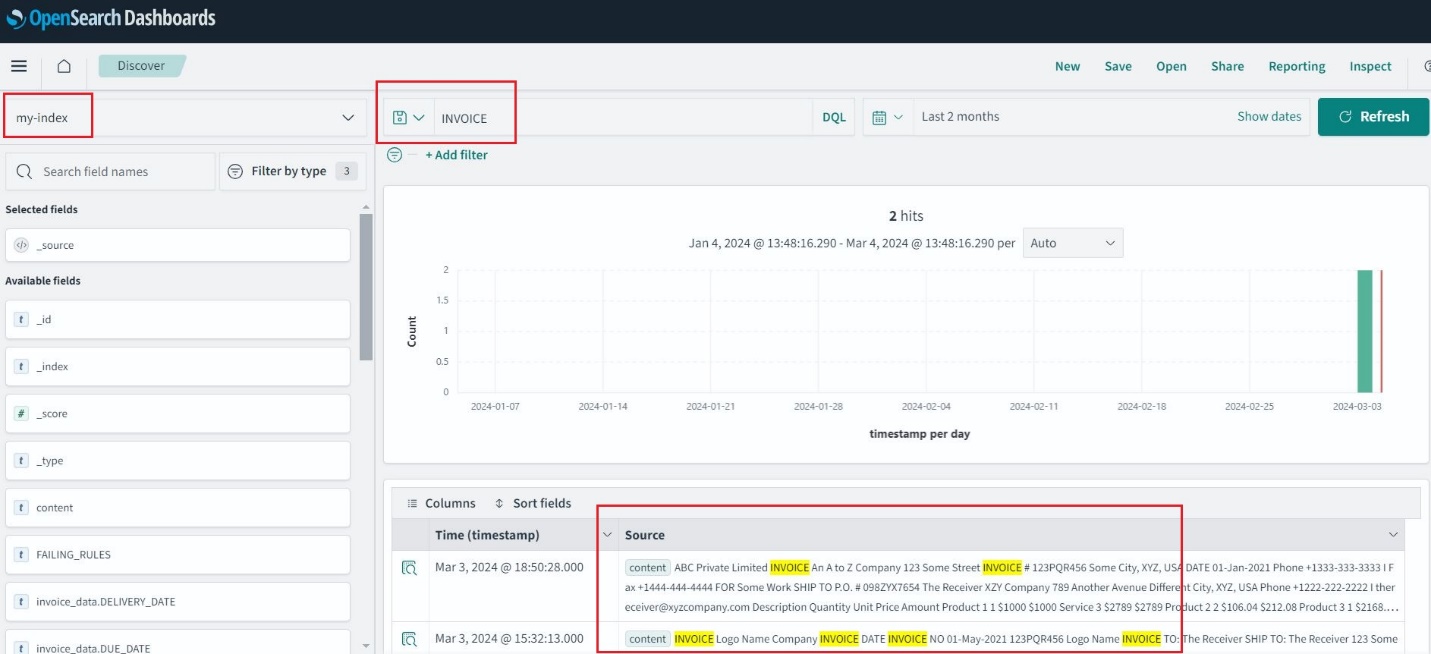
Archivo, auditoría y análisis
Para administrar el ciclo de vida y el archivado de facturas y recibos, puede configurar reglas del ciclo de vida de S3 para realizar la transición de objetos de S3 de clases de almacenamiento estándar a niveles inteligentes. S3 Intelligent-Tiering monitorea los patrones de acceso y mueve automáticamente los objetos al nivel de acceso poco frecuente cuando no se ha accedido a ellos durante 30 días consecutivos. Después de 90 días sin acceso, los objetos se mueven al nivel Archive Instant Access sin impacto en el rendimiento ni sobrecarga operativa.
Para auditoría y análisis, esta solución utiliza OpenSearch Service para ejecutar análisis en solicitudes de facturas. OpenSearch Service le permite ingerir, proteger, buscar, agregar, ver y analizar datos sin esfuerzo para una serie de casos de uso, como análisis de registros, búsqueda de aplicaciones, búsqueda empresarial y más.
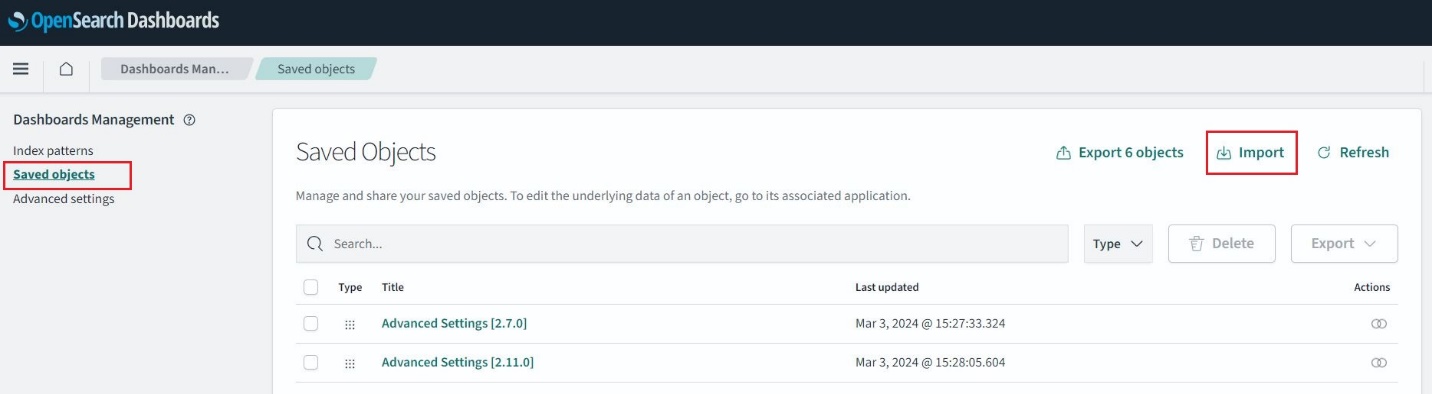
Inicie sesión en OpenSearch Dashboards y navegue hasta Gestión de pilas, Objetos guardados, A continuación, elija Importa. Elegir el facturas.ndjson archivo del repositorio clonado y elija Importa. Esto rellena previamente los índices y crea la visualización.
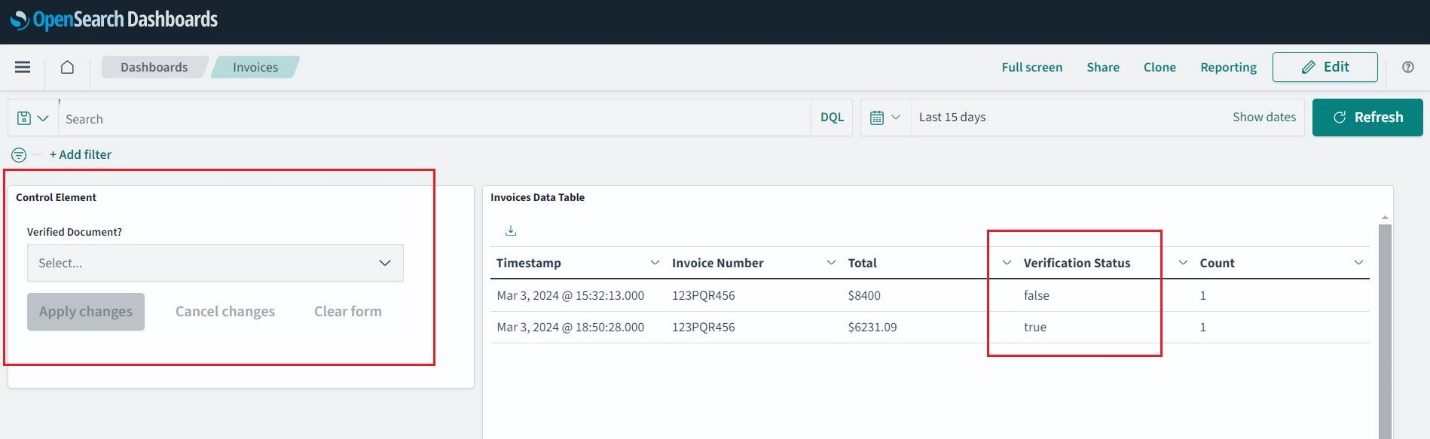
Actualiza la página y navega hasta Inicio, Panel De Controly abierto Facturas. Ahora puede seleccionar y aplicar filtros y expandir la ventana de tiempo para explorar facturas pasadas.
Limpiar
Cuando haya terminado de evaluar Amazon Textract para procesar recibos y facturas, le recomendamos limpiar todos los recursos que haya creado. Complete los siguientes pasos:
- Eliminar todo el contenido del depósito S3
invoiceprocessorworkflow-invoiceprocessorbucketf1-*. - En AWS Cloud9, ejecute los siguientes comandos para eliminar recursos de Amazon Cognito y pilas de CloudFormation:
- Elimine el entorno de AWS Cloud9 que creó desde la consola de AWS Cloud9.
Conclusión
En esta publicación, brindamos una descripción general de cómo podemos crear un proceso de automatización de facturas utilizando Amazon Textract para la extracción de datos y crear un flujo de trabajo para validación, archivo y búsqueda. Proporcionamos ejemplos de código sobre cómo utilizar el AnalyzeExpense API para extracción de campos críticos de una factura.
Para comenzar, inicie sesión en la consola de Amazon Textract para probar esta función. Para obtener más información sobre las capacidades de Amazon Textract, consulte la Guía para desarrolladores de Amazon Textract or Recursos de texto. Para obtener más información sobre IDP, consulte IDP con servicios de IA de AWS. Parte 1 y Parte 2 puestos.
Acerca de los autores
 Sushant Pradhan es arquitecto sénior de soluciones en Amazon Web Services y ayuda a clientes empresariales. Sus intereses y experiencia incluyen contenedores, tecnología sin servidor y DevOps. En su tiempo libre, Sushant disfruta pasar tiempo al aire libre con su familia.
Sushant Pradhan es arquitecto sénior de soluciones en Amazon Web Services y ayuda a clientes empresariales. Sus intereses y experiencia incluyen contenedores, tecnología sin servidor y DevOps. En su tiempo libre, Sushant disfruta pasar tiempo al aire libre con su familia.
 Shibin Michael Raj es gerente de productos sénior en el equipo de AWS Textract. Se centra en la creación de productos basados en IA/ML para clientes de AWS.
Shibin Michael Raj es gerente de productos sénior en el equipo de AWS Textract. Se centra en la creación de productos basados en IA/ML para clientes de AWS.
 Suprakash Dutta es Arquitecto de Soluciones Sr. en Amazon Web Services. Se centra en la estrategia de transformación digital, la modernización y migración de aplicaciones, el análisis de datos y el aprendizaje automático. Forma parte de la comunidad AI/ML en AWS y diseña soluciones inteligentes de procesamiento de documentos.
Suprakash Dutta es Arquitecto de Soluciones Sr. en Amazon Web Services. Se centra en la estrategia de transformación digital, la modernización y migración de aplicaciones, el análisis de datos y el aprendizaje automático. Forma parte de la comunidad AI/ML en AWS y diseña soluciones inteligentes de procesamiento de documentos.
 maran chandrasekaran es Arquitecto de Soluciones Sénior en Amazon Web Services y trabaja con nuestros clientes empresariales. Fuera del trabajo, le encanta viajar y andar en motocicleta en Texas Hill Country.
maran chandrasekaran es Arquitecto de Soluciones Sénior en Amazon Web Services y trabaja con nuestros clientes empresariales. Fuera del trabajo, le encanta viajar y andar en motocicleta en Texas Hill Country.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/build-a-receipt-and-invoice-processing-pipeline-with-amazon-textract/

