Resilience plays a pivotal role in the development of any workload, and generative AI workloads are no different. There are unique considerations when engineering generative AI workloads through a resilience lens. Understanding and prioritizing resilience is crucial for generative AI workloads to meet organizational availability and business continuity requirements. In this post, we discuss the different stacks of a generative AI workload and what those considerations should be.
Full stack generative AI
Although a lot of the excitement around generative AI focuses on the models, a complete solution involves people, skills, and tools from several domains. Consider the following picture, which is an AWS view of the a16z emerging application stack for large language models (LLMs).
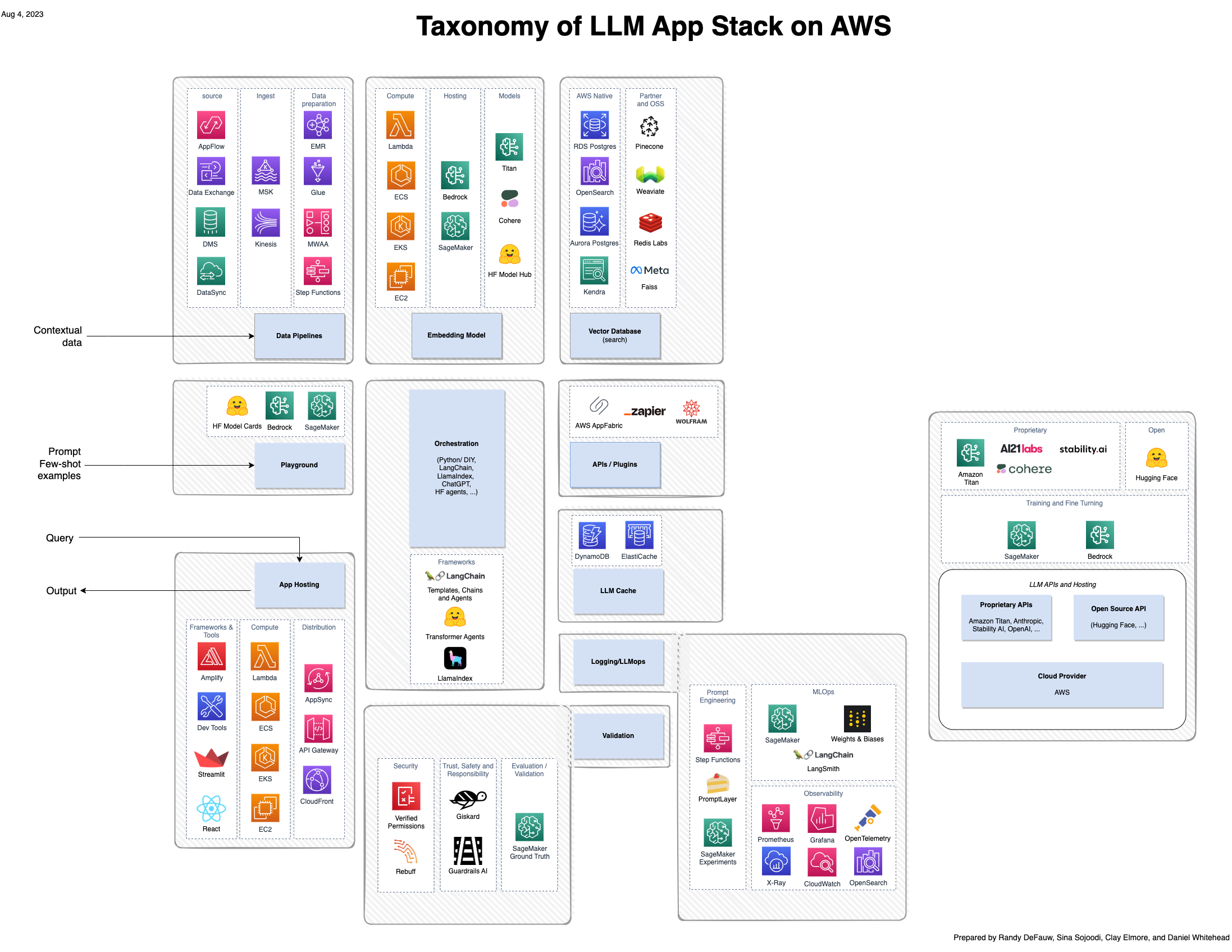
Compared to a more traditional solution built around AI and machine learning (ML), a generative AI solution now involves the following:
- New roles – You have to consider model tuners as well as model builders and model integrators
- New tools – The traditional MLOps stack doesn’t extend to cover the type of experiment tracking or observability necessary for prompt engineering or agents that invoke tools to interact with other systems
Agent reasoning
Unlike traditional AI models, Retrieval Augmented Generation (RAG) allows for more accurate and contextually relevant responses by integrating external knowledge sources. The following are some considerations when using RAG:
- Setting appropriate timeouts is important to the customer experience. Nothing says bad user experience more than being in the middle of a chat and getting disconnected.
- Make sure to validate prompt input data and prompt input size for allocated character limits that are defined by your model.
- If you’re performing prompt engineering, you should persist your prompts to a reliable data store. That will safeguard your prompts in case of accidental loss or as part of your overall disaster recovery strategy.
Data pipelines
In cases where you need to provide contextual data to the foundation model using the RAG pattern, you need a data pipeline that can ingest the source data, convert it to embedding vectors, and store the embedding vectors in a vector database. This pipeline could be a batch pipeline if you prepare contextual data in advance, or a low-latency pipeline if you’re incorporating new contextual data on the fly. In the batch case, there are a couple challenges compared to typical data pipelines.
The data sources may be PDF documents on a file system, data from a software as a service (SaaS) system like a CRM tool, or data from an existing wiki or knowledge base. Ingesting from these sources is different from the typical data sources like log data in an Amazon Simple Storage Service (Amazon S3) bucket or structured data from a relational database. The level of parallelism you can achieve may be limited by the source system, so you need to account for throttling and use backoff techniques. Some of the source systems may be brittle, so you need to build in error handling and retry logic.
The embedding model could be a performance bottleneck, regardless of whether you run it locally in the pipeline or call an external model. Embedding models are foundation models that run on GPUs and do not have unlimited capacity. If the model runs locally, you need to assign work based on GPU capacity. If the model runs externally, you need to make sure you’re not saturating the external model. In either case, the level of parallelism you can achieve will be dictated by the embedding model rather than how much CPU and RAM you have available in the batch processing system.
In the low-latency case, you need to account for the time it takes to generate the embedding vectors. The calling application should invoke the pipeline asynchronously.
Vector databases
A vector database has two functions: store embedding vectors, and run a similarity search to find the closest k matches to a new vector. There are three general types of vector databases:
- Dedicated SaaS options like Pinecone.
- Vector database features built into other services. This includes native AWS services like Amazon OpenSearch Service and Amazon Aurora.
- In-memory options that can be used for transient data in low-latency scenarios.
We don’t cover the similarity searching capabilities in detail in this post. Although they’re important, they are a functional aspect of the system and don’t directly affect resilience. Instead, we focus on the resilience aspects of a vector database as a storage system:
- Latency – Can the vector database perform well against a high or unpredictable load? If not, the calling application needs to handle rate limiting and backoff and retry.
- Scalability – How many vectors can the system hold? If you exceed the capacity of the vector database, you’ll need to look into sharding or other solutions.
- High availability and disaster recovery – Embedding vectors are valuable data, and recreating them can be expensive. Is your vector database highly available in a single AWS Region? Does it have the ability to replicate data to another Region for disaster recovery purposes?
Application tier
There are three unique considerations for the application tier when integrating generative AI solutions:
- Potentially high latency – Foundation models often run on large GPU instances and may have finite capacity. Make sure to use best practices for rate limiting, backoff and retry, and load shedding. Use asynchronous designs so that high latency doesn’t interfere with the application’s main interface.
- Security posture – If you’re using agents, tools, plugins, or other methods of connecting a model to other systems, pay extra attention to your security posture. Models may try to interact with these systems in unexpected ways. Follow the normal practice of least-privilege access, for example restricting incoming prompts from other systems.
- Rapidly evolving frameworks – Open source frameworks like LangChain are evolving rapidly. Use a microservices approach to isolate other components from these less mature frameworks.
Capacity
We can think about capacity in two contexts: inference and training model data pipelines. Capacity is a consideration when organizations are building their own pipelines. CPU and memory requirements are two of the biggest requirements when choosing instances to run your workloads.
Instances that can support generative AI workloads can be more difficult to obtain than your average general-purpose instance type. Instance flexibility can help with capacity and capacity planning. Depending on what AWS Region you are running your workload in, different instance types are available.
For the user journeys that are critical, organizations will want to consider either reserving or pre-provisioning instance types to ensure availability when needed. This pattern achieves a statically stable architecture, which is a resiliency best practice. To learn more about static stability in the AWS Well-Architected Framework reliability pillar, refer to Use static stability to prevent bimodal behavior.
Observability
Besides the resource metrics you typically collect, like CPU and RAM utilization, you need to closely monitor GPU utilization if you host a model on Amazon SageMaker or Amazon Elastic Compute Cloud (Amazon EC2). GPU utilization can change unexpectedly if the base model or the input data changes, and running out of GPU memory can put the system into an unstable state.
Higher up the stack, you will also want to trace the flow of calls through the system, capturing the interactions between agents and tools. Because the interface between agents and tools is less formally defined than an API contract, you should monitor these traces not only for performance but also to capture new error scenarios. To monitor the model or agent for any security risks and threats, you can use tools like Amazon GuardDuty.
You should also capture baselines of embedding vectors, prompts, context, and output, and the interactions between these. If these change over time, it may indicate that users are using the system in new ways, that the reference data is not covering the question space in the same way, or that the model’s output is suddenly different.
Disaster recovery
Having a business continuity plan with a disaster recovery strategy is a must for any workload. Generative AI workloads are no different. Understanding the failure modes that are applicable to your workload will help guide your strategy. If you are using AWS managed services for your workload, such as Amazon Bedrock and SageMaker, make sure the service is available in your recovery AWS Region. As of this writing, these AWS services don’t support replication of data across AWS Regions natively, so you need to think about your data management strategies for disaster recovery, and you also may need to fine-tune in multiple AWS Regions.
Conclusion
This post described how to take resilience into account when building generative AI solutions. Although generative AI applications have some interesting nuances, the existing resilience patterns and best practices still apply. It’s just a matter of evaluating each part of a generative AI application and applying the relevant best practices.
For more information about generative AI and using it with AWS services, refer to the following resources:
About the Authors
 Jennifer Moran is an AWS Senior Resiliency Specialist Solutions Architect based out of New York City. She has a diverse background, having worked in many technical disciplines, including software development, agile leadership, and DevOps, and is an advocate for women in tech. She enjoys helping customers design resilient solutions to improve resilience posture and publicly speaks about all topics related to resilience.
Jennifer Moran is an AWS Senior Resiliency Specialist Solutions Architect based out of New York City. She has a diverse background, having worked in many technical disciplines, including software development, agile leadership, and DevOps, and is an advocate for women in tech. She enjoys helping customers design resilient solutions to improve resilience posture and publicly speaks about all topics related to resilience.
 Randy DeFauw is a Senior Principal Solutions Architect at AWS. He holds an MSEE from the University of Michigan, where he worked on computer vision for autonomous vehicles. He also holds an MBA from Colorado State University. Randy has held a variety of positions in the technology space, ranging from software engineering to product management. He entered the big data space in 2013 and continues to explore that area. He is actively working on projects in the ML space and has presented at numerous conferences, including Strata and GlueCon.
Randy DeFauw is a Senior Principal Solutions Architect at AWS. He holds an MSEE from the University of Michigan, where he worked on computer vision for autonomous vehicles. He also holds an MBA from Colorado State University. Randy has held a variety of positions in the technology space, ranging from software engineering to product management. He entered the big data space in 2013 and continues to explore that area. He is actively working on projects in the ML space and has presented at numerous conferences, including Strata and GlueCon.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/designing-generative-ai-workloads-for-resilience/

