In der heutigen Geschäftslandschaft suchen Unternehmen ständig nach Möglichkeiten, ihre Finanzprozesse zu optimieren, die Effizienz zu steigern und Kosteneinsparungen voranzutreiben. Ein Bereich, der erhebliches Verbesserungspotenzial birgt, ist die Kreditorenbuchhaltung. Auf einer übergeordneten Ebene umfasst der Kreditorenbuchhaltungsprozess den Empfang und das Scannen von Rechnungen, das Extrahieren der relevanten Daten aus gescannten Rechnungen, die Validierung, Genehmigung und Archivierung. Der zweite Schritt (Extraktion) kann komplex sein. Jede Rechnung und Quittung sieht anders aus. Die Etiketten sind unvollständig und inkonsistent. Die wichtigsten Informationen wie Preis, Anbietername, Anbieteradresse und Zahlungsbedingungen sind oft nicht explizit gekennzeichnet und müssen kontextbezogen interpretiert werden. Der traditionelle Ansatz, menschliche Prüfer zum Extrahieren der Daten einzusetzen, ist zeitaufwändig, fehleranfällig und nicht skalierbar.
In diesem Beitrag zeigen wir, wie Sie den Kreditorenbuchhaltungsprozess automatisieren können Amazontext zur Datenextraktion. Wir bieten außerdem eine Referenzarchitektur zum Aufbau einer Pipeline zur Rechnungsautomatisierung, die Extraktion, Überprüfung, Archivierung und intelligente Suche ermöglicht.
Lösungsüberblick
Das folgende Architekturdiagramm zeigt die Phasen eines Empfangs- und Rechnungsverarbeitungsworkflows. Es beginnt mit der Dokumentenerfassungsphase, um gescannte Rechnungen und Quittungen sicher zu sammeln und zu speichern. Der nächste Schritt ist die Extraktionsphase, in der Sie die gesammelten Rechnungen und Quittungen an Amazon Textract übergeben AnalyzeExpense API zum Extrahieren finanziell relevanter Beziehungen zwischen Texten wie z. B. dem Namen des Lieferanten, dem Rechnungseingangsdatum, dem Bestelldatum, dem fälligen Betrag, dem gezahlten Betrag usw. Im nächsten Schritt bestimmen Sie anhand vordefinierter Spesenregeln, ob Sie den Beleg automatisch genehmigen oder ablehnen sollen. Genehmigte und abgelehnte Dokumente werden in den entsprechenden Ordnern innerhalb der abgelegt Amazon Simple Storage-Service (Amazon S3) Eimer. Für genehmigte Dokumente können Sie mit alle extrahierten Felder und Werte durchsuchen Amazon OpenSearch-Dienst. Sie können die indizierten Metadaten mithilfe von OpenSearch-Dashboards visualisieren. Genehmigte Dokumente werden ebenfalls zum Verschieben eingerichtet Amazon S3 Intelligent-Tiering für die langfristige Aufbewahrung und Archivierung mithilfe von S3-Lebenszyklusrichtlinien.
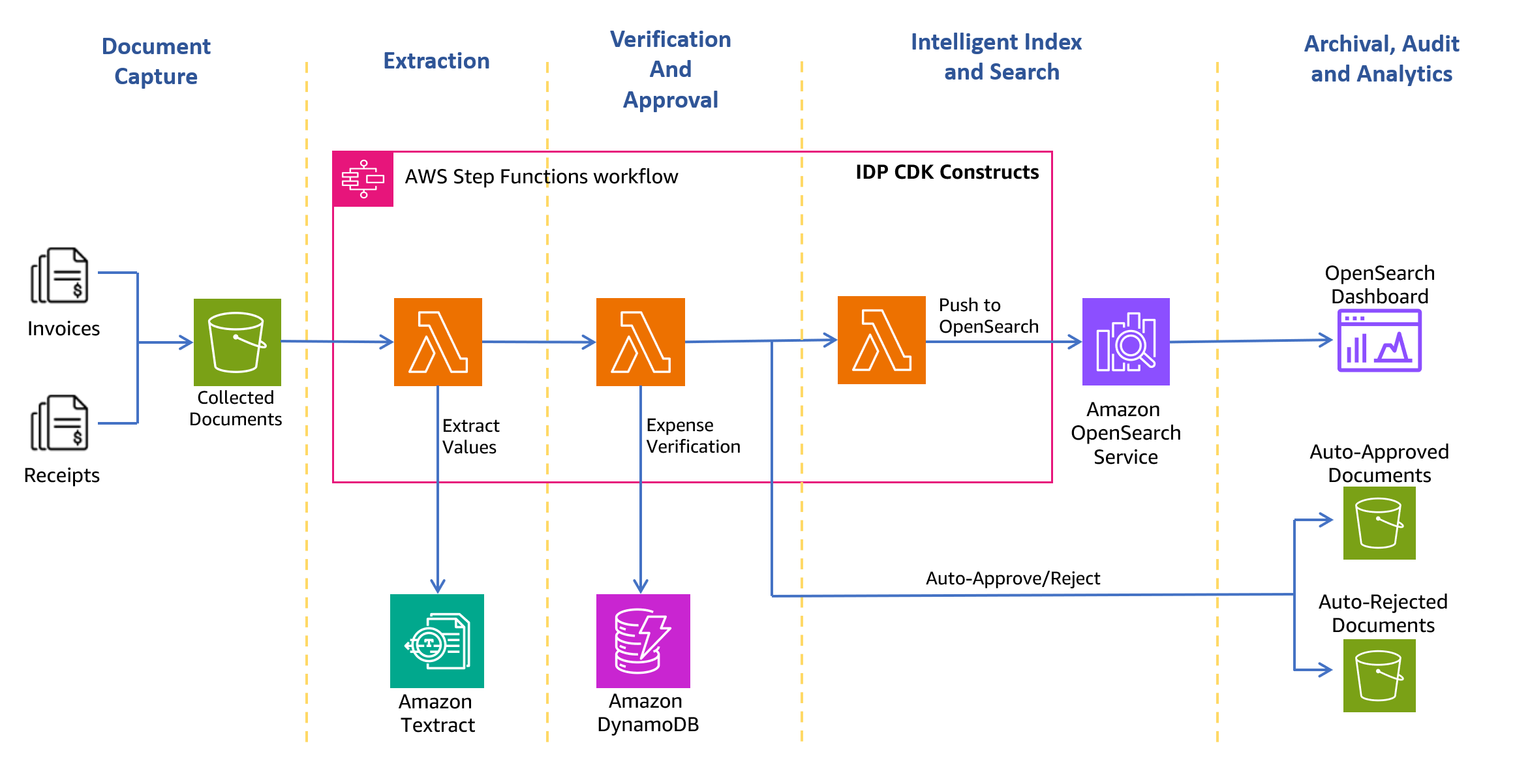
Die folgenden Abschnitte führen Sie durch den Prozess der Lösungserstellung.
Voraussetzungen:
Um diese Lösung bereitzustellen, müssen Sie über Folgendes verfügen:
- Ein AWS-Konto.
- An AWS Cloud9 Umfeld. AWS Cloud9 ist eine cloudbasierte integrierte Entwicklungsumgebung (IDE), mit der Sie Ihren Code nur mit einem Browser schreiben, ausführen und debuggen können. Es umfasst einen Code-Editor, einen Debugger und ein Terminal.
Geben Sie zum Erstellen der AWS Cloud9-Umgebung einen Namen und eine Beschreibung an. Behalten Sie alles andere als Standard bei. Wählen Sie den IDE-Link auf der AWS Cloud9-Konsole, um zur IDE zu navigieren. Sie sind jetzt bereit, die AWS Cloud9-Umgebung zu verwenden.
Stellen Sie die Lösung bereit
Um die Lösung einzurichten, verwenden Sie die AWS Cloud-Entwicklungskit (AWS CDK) zum Bereitstellen eines AWS CloudFormation Stapel.
- Klonen Sie in Ihrem AWS Cloud9 IDE-Terminal die GitHub-Repository und installieren Sie die Abhängigkeiten. Führen Sie die folgenden Befehle aus, um die bereitzustellen
InvoiceProcessorStapel:
Die Bereitstellung dauert mit den Standardkonfigurationseinstellungen aus dem GitHub-Repository etwa 25 Minuten. Zusätzliche Ausgabeinformationen sind auch auf der AWS CloudFormation-Konsole verfügbar.
- Nachdem die AWS CDK-Bereitstellung abgeschlossen ist, erstellen Sie Ausgabenvalidierungsregeln in einem Amazon DynamoDB Tisch. Sie können dasselbe AWS Cloud9-Terminal verwenden, um die folgenden Befehle auszuführen:
- Im S3-Eimer beginnt das mit
invoiceprocessorworkflow-invoiceprocessorbucketf1-*, erstellen Sie einen Upload-Ordner.
In Amazon Cognito, sollten Sie bereits über einen vorhandenen Benutzerpool mit dem Namen verfügen OpenSearchResourcesCognitoUserPool*. Wir verwenden diesen Benutzerpool, um einen neuen Benutzer zu erstellen.
- Navigieren Sie in der Amazon Cognito-Konsole zum Benutzerpool
OpenSearchResourcesCognitoUserPool*. - Erstellen Sie einen neuen Amazon Cognito-Benutzer.
- Geben Sie einen Benutzernamen und ein Passwort Ihrer Wahl ein und notieren Sie diese zur späteren Verwendung.
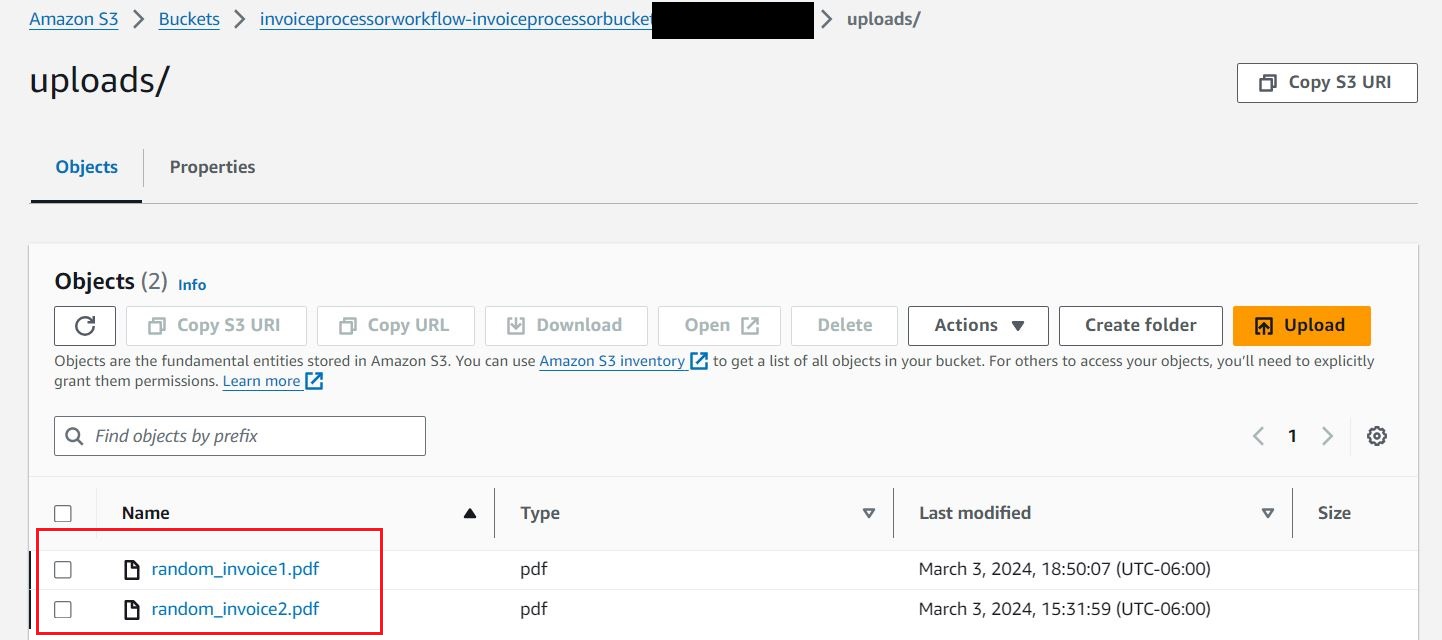
- Laden Sie die Dokumente hoch random_invoice1 und random_invoice2 zur S3
uploadsOrdner zum Starten der Workflows.
Lassen Sie uns nun in die einzelnen Schritte der Dokumentenverarbeitung eintauchen.
Dokumentenerfassung
Kunden verarbeiten Rechnungen und Quittungen in einer Vielzahl von Formaten von verschiedenen Anbietern. Diese Dokumente werden über Kanäle wie Ausdrucke, gescannte Kopien, die in den Dateispeicher hochgeladen werden, oder gemeinsam genutzte Speichergeräte empfangen. In der Dokumentenerfassungsphase speichern Sie alle gescannten Kopien von Quittungen und Rechnungen in einem hoch skalierbaren Speicher, beispielsweise in einem S3-Bucket.
Extrahierung
Der nächste Schritt ist die Extraktionsphase, in der Sie die gesammelten Rechnungen und Quittungen an Amazon Textract übergeben AnalyzeExpense API zum Extrahieren finanziell relevanter Beziehungen zwischen Texten wie dem Namen des Lieferanten, dem Rechnungseingangsdatum, dem Bestelldatum, dem fälligen/bezahlten Betrag usw.
Kosten analysieren ist eine API zur Verarbeitung von Rechnungs- und Belegdokumenten. Es ist sowohl als synchrone als auch als asynchrone API verfügbar. Mit der synchronen API können Sie Bilder im Byte-Format senden, und mit der asynchronen API können Sie Dateien in den Formaten JPG, PNG, TIFF und PDF senden. Der AnalyzeExpense Die API-Antwort besteht aus drei verschiedenen Abschnitten:
- Zusammenfassungsfelder – Dieser Abschnitt enthält sowohl normalisierte Schlüssel als auch die explizit genannten Schlüssel zusammen mit ihren Werten.
AnalyzeExpensenormalisiert die Schlüssel für kontaktbezogene Informationen wie Lieferantenname und Lieferantenadresse, Steuer-ID-bezogene Schlüssel wie Steuerzahler-ID, zahlungsbezogene Schlüssel wie fälliger Betrag und Rabatt sowie allgemeine Schlüssel wie Rechnungs-ID, Lieferdatum usw Accountnummer. Nicht normalisierte Schlüssel werden in den Zusammenfassungsfeldern weiterhin als Schlüssel-Wert-Paare angezeigt. Eine vollständige Liste der unterstützten Ausgabenfelder finden Sie unter Rechnungen und Belege analysieren. - Werbebuchungen – Dieser Abschnitt enthält normalisierte Einzelpostenschlüssel wie Artikelbeschreibung, Stückpreis, Menge und Produktcode.
- OCR-Block – Der Block enthält den Rohtextauszug aus der Rechnungsseite. Der Rohtextextrakt kann zur Nachbearbeitung und Identifizierung von Informationen verwendet werden, die nicht in den Zusammenfassungs- und Einzelpostenfeldern enthalten sind.
Dieser Beitrag verwendet die Amazon Textract IDP CDK-Konstrukte (AWS CDK-Komponenten zum Definieren der Infrastruktur für IDP-Workflows (Intelligent Document Processing)), mit denen Sie anwendungsfallspezifische, anpassbare IDP-Workflows erstellen können. Bei den Konstrukten und Beispielen handelt es sich um eine Sammlung von Komponenten, die die Definition von IDP-Prozessen in AWS und deren Veröffentlichung ermöglichen GitHub. Die wichtigsten verwendeten Konzepte sind die AWS CDK-Konstrukte, die tatsächlichen AWS CDK-Stacks und AWS Step-Funktionen.
Die folgende Abbildung zeigt den Step Functions-Workflow.
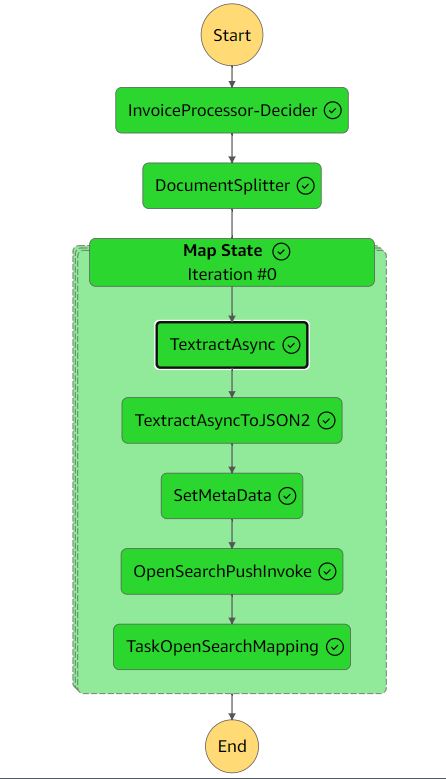
Der Extraktionsworkflow umfasst die folgenden Schritte:
- Rechnungsprozessor-Entscheider - Ein AWS Lambda Funktion, die überprüft, ob das Eingabedokumentformat von Amazon Textract unterstützt wird. Weitere Einzelheiten zu unterstützten Formaten finden Sie unter Eingabedokumente.
- DocumentSplitter – Eine Lambda-Funktion, die aus Dokumenten Blöcke mit maximal 2,500 Seiten generiert und große mehrseitige Dokumente verarbeiten kann.
- Kartenstatus – Eine Lambda-Funktion, die jeden Block parallel verarbeitet.
- TextractAsync – Diese Aufgabe ruft Amazon Textract mithilfe der folgenden asynchronen API auf Best Practices mit Amazon Simple Notification Service (Amazon SNS) Benachrichtigungen und Verwendungen
OutputConfigum die JSON-Ausgabe von Amazon Textract in dem zuvor erstellten S3-Bucket zu speichern. Es besteht aus zwei Lambda-Funktionen: eine zum Einreichen des Dokuments zur Verarbeitung und eine, die durch die SNS-Benachrichtigung ausgelöst wird. - TextractAsyncToJSON2 - Weil das
TextractAsyncDie Aufgabe kann mehrere paginierte Ausgabedateien erzeugenTextractAsyncToJSON2Der Prozess kombiniert sie in einer JSON-Datei.
Die Details der nächsten drei Schritte besprechen wir in den folgenden Abschnitten.
Überprüfung und Genehmigung
Für die Verifizierungsphase wird die SetMetaData Die Lambda-Funktion überprüft, ob die hochgeladene Datei eine gültige Ausgabe gemäß den zuvor in der DynamoDB-Tabelle konfigurierten Regeln ist. Für diesen Beitrag verwenden Sie die folgenden Beispielregeln:
- Die Verifizierung ist erfolgreich, wenn
INVOICE_RECEIPT_IDist vorhanden und entspricht dem regulären Ausdruck(?i)[0-9]{3}[a-z]{3}[0-9]{3}$und ifPO_NUMBERist vorhanden und entspricht dem regulären Ausdruck(?i)[a-z0-9]+$ - In beiden Fällen ist die Überprüfung nicht erfolgreich
PO_NUMBERorINVOICE_RECEIPT_IDist falsch oder fehlt im Dokument.
Nachdem die Dateien verarbeitet wurden, verschiebt die Spesenüberprüfungsfunktion die Eingabedateien in eines der beiden Verzeichnisse approved or declined Ordner im selben S3-Bucket.
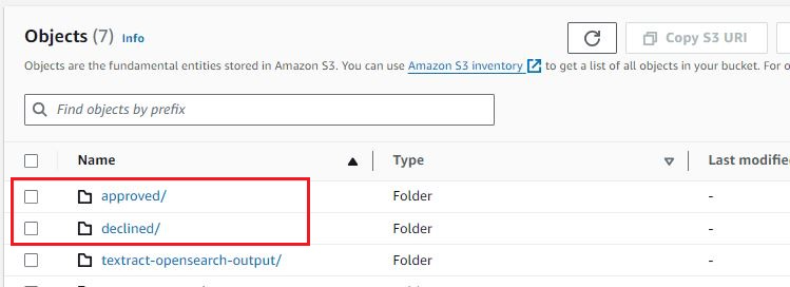
Für die Zwecke dieser Lösung verwenden wir DynamoDB zum Speichern der Spesenvalidierungsregeln. Sie können diese Lösung jedoch ändern, um sie in Ihre eigenen oder kommerziellen Ausgabenvalidierungs- oder -verwaltungslösungen zu integrieren.
Intelligente Indexierung und Suche
Mit der OpenSearchPushInvoke Mit der Lambda-Funktion werden die extrahierten Spesenmetadaten an einen OpenSearch-Service-Index übertragen und stehen für die Suche zur Verfügung.
Das endgültige TaskOpenSearchMapping Schritt löscht den Kontext, der andernfalls überschritten werden könnte Kontingent für Schrittfunktionen der maximalen Eingabe- oder Ausgabegröße für eine Aufgabe, einen Status oder eine Workflow-Ausführung.
Nachdem der OpenSearch-Service-Index erstellt wurde, können Sie über OpenSearch-Dashboards nach Schlüsselwörtern aus dem extrahierten Text suchen.
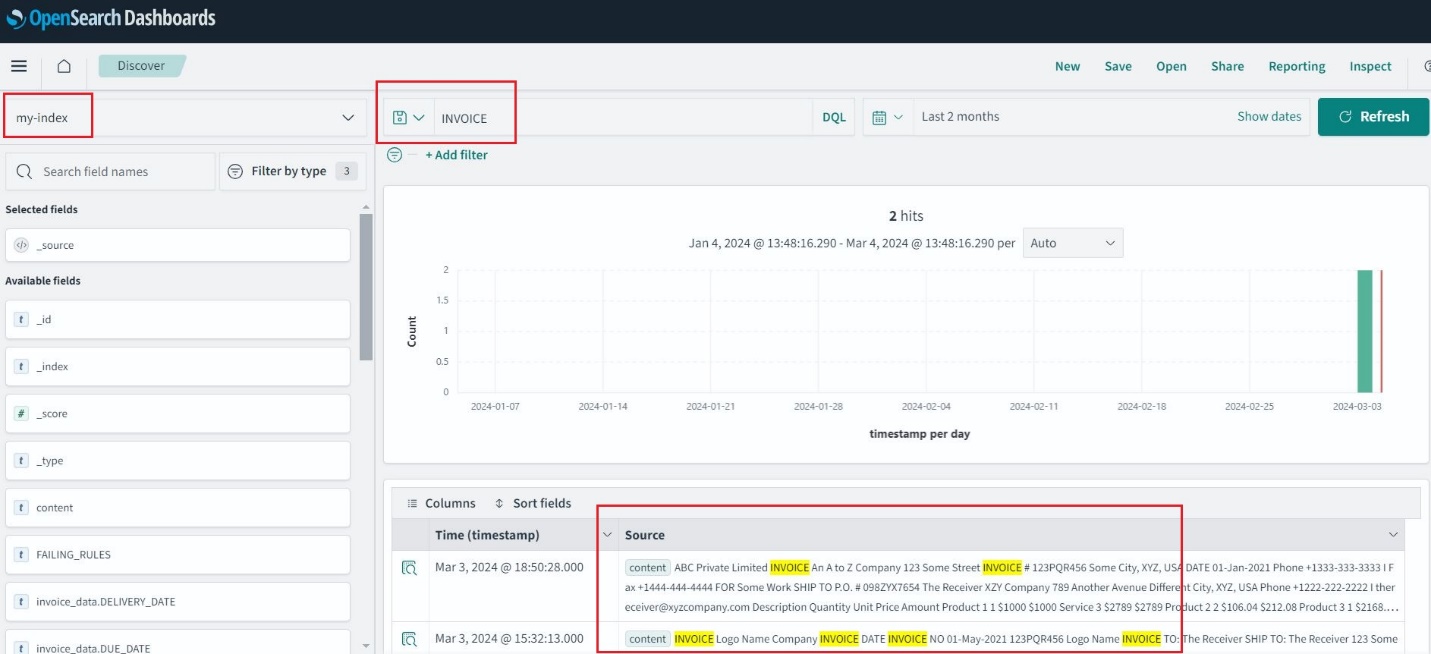
Archivierung, Prüfung und Analyse
Um den Lebenszyklus und die Archivierung von Rechnungen und Belegen zu verwalten, können Sie S3-Lebenszyklusregeln konfigurieren, um S3-Objekte von Standard- in Intelligent-Tiering-Speicherklassen zu überführen. S3 Intelligent-Tiering überwacht Zugriffsmuster und verschiebt Objekte automatisch in die Stufe „Infrequent Access“, wenn 30 aufeinanderfolgende Tage lang nicht auf sie zugegriffen wurde. Nach 90 Tagen ohne Zugriff werden die Objekte ohne Leistungseinbußen oder Betriebsaufwand auf die Ebene „Archive Instant Access“ verschoben.
Zur Prüfung und Analyse nutzt diese Lösung OpenSearch Service zur Durchführung von Analysen zu Rechnungsanfragen. Mit OpenSearch Service können Sie mühelos Daten für eine Reihe von Anwendungsfällen erfassen, sichern, suchen, aggregieren, anzeigen und analysieren, z. B. Protokollanalyse, Anwendungssuche, Unternehmenssuche und mehr.
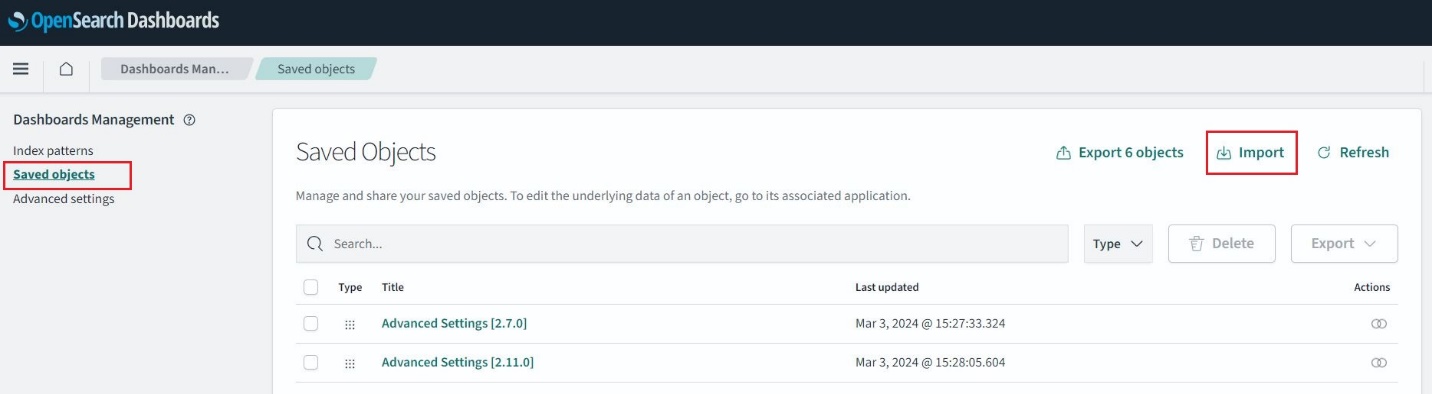
Melden Sie sich bei OpenSearch Dashboards an und navigieren Sie zu Stapelverwaltung, Gespeicherte Objekte, Dann wählen Import. Wählen Sie das Rechnungen.ndjson Datei aus dem geklonten Repository und wählen Sie Import. Dadurch werden Indizes vorab ausgefüllt und die Visualisierung erstellt.
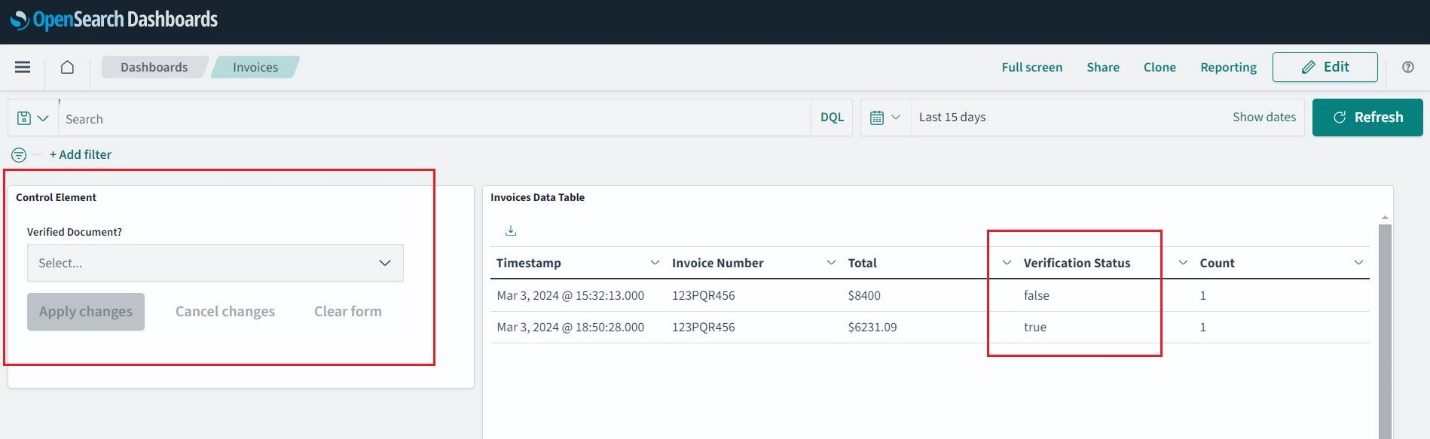
Aktualisieren Sie die Seite und navigieren Sie zu Startseite, Dashboardund offen Rechnungen. Sie können jetzt Filter auswählen und anwenden sowie das Zeitfenster erweitern, um frühere Rechnungen zu durchsuchen.
Aufräumen
Wenn Sie mit der Evaluierung von Amazon Textract für die Verarbeitung von Quittungen und Rechnungen fertig sind, empfehlen wir Ihnen, alle von Ihnen erstellten Ressourcen zu bereinigen. Führen Sie die folgenden Schritte aus:
- Löschen Sie alle Inhalte aus dem S3-Bucket
invoiceprocessorworkflow-invoiceprocessorbucketf1-*. - Führen Sie in AWS Cloud9 die folgenden Befehle aus, um Amazon Cognito-Ressourcen und CloudFormation-Stacks zu löschen:
- Löschen Sie die AWS Cloud9-Umgebung, die Sie über die AWS Cloud9-Konsole erstellt haben.
Zusammenfassung
In diesem Beitrag haben wir einen Überblick darüber gegeben, wie wir mit Amazon Textract eine Pipeline zur Rechnungsautomatisierung zur Datenextraktion aufbauen und einen Workflow für die Validierung, Archivierung und Suche erstellen können. Wir haben Codebeispiele zur Verwendung bereitgestellt AnalyzeExpense API zur Extraktion kritischer Felder aus einer Rechnung.
Melden Sie sich zunächst bei der Amazon Textract-Konsole an, um diese Funktion auszuprobieren. Weitere Informationen zu den Funktionen von Amazon Textract finden Sie im Amazon Textract Entwicklerhandbuch or Textract-Ressourcen. Weitere Informationen zu IDP finden Sie unter IDP mit AWS AI-Services Teil 1 und Teil 2 Beiträge.
Über die Autoren
 Sushant Pradhan ist Senior Solutions Architect bei Amazon Web Services und unterstützt Unternehmenskunden. Zu seinen Interessen und Erfahrungen zählen Container, serverlose Technologie und DevOps. In seiner Freizeit verbringt Sushant gerne Zeit im Freien mit seiner Familie.
Sushant Pradhan ist Senior Solutions Architect bei Amazon Web Services und unterstützt Unternehmenskunden. Zu seinen Interessen und Erfahrungen zählen Container, serverlose Technologie und DevOps. In seiner Freizeit verbringt Sushant gerne Zeit im Freien mit seiner Familie.
 Schibin Michaelraj ist Senior Product Manager im AWS Textract-Team. Er konzentriert sich auf die Entwicklung von AI/ML-basierten Produkten für AWS-Kunden.
Schibin Michaelraj ist Senior Product Manager im AWS Textract-Team. Er konzentriert sich auf die Entwicklung von AI/ML-basierten Produkten für AWS-Kunden.
 Suprakash Dutta ist Senior Solutions Architect bei Amazon Web Services. Er konzentriert sich auf Strategien zur digitalen Transformation, Anwendungsmodernisierung und -migration, Datenanalyse und maschinelles Lernen. Er ist Teil der AI/ML-Community bei AWS und entwirft intelligente Dokumentenverarbeitungslösungen.
Suprakash Dutta ist Senior Solutions Architect bei Amazon Web Services. Er konzentriert sich auf Strategien zur digitalen Transformation, Anwendungsmodernisierung und -migration, Datenanalyse und maschinelles Lernen. Er ist Teil der AI/ML-Community bei AWS und entwirft intelligente Dokumentenverarbeitungslösungen.
 Maran Chandrasekaran ist Senior Solutions Architect bei Amazon Web Services und arbeitet mit unseren Unternehmenskunden zusammen. Außerhalb der Arbeit liebt er es zu reisen und Motorrad im Texas Hill Country zu fahren.
Maran Chandrasekaran ist Senior Solutions Architect bei Amazon Web Services und arbeitet mit unseren Unternehmenskunden zusammen. Außerhalb der Arbeit liebt er es zu reisen und Motorrad im Texas Hill Country zu fahren.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/build-a-receipt-and-invoice-processing-pipeline-with-amazon-textract/

