Dette er et gæsteindlæg, der er skrevet i samarbejde med ledergruppen for Iambic Therapeutics.
Iambisk Terapeutik er en lægemiddelopdagelsesstartup med en mission om at skabe innovative AI-drevne teknologier for at bringe bedre medicin til kræftpatienter hurtigere.
Vores avancerede generative og prædiktive kunstige intelligens (AI) værktøjer gør det muligt for os at søge i det store rum af mulige lægemiddelmolekyler hurtigere og mere effektivt. Vores teknologier er alsidige og anvendelige på tværs af terapeutiske områder, proteinklasser og virkningsmekanismer. Ud over at skabe differentierede AI-værktøjer har vi etableret en integreret platform, der kombinerer AI-software, cloud-baserede data, skalerbar beregningsinfrastruktur og high-throughput kemi- og biologifunktioner. Platformen aktiverer både vores kunstig intelligens – ved at levere data til at forfine vores modeller – og aktiveres af den og udnytter mulighederne for automatiseret beslutningstagning og databehandling.
Vi måler succes ud fra vores evne til at producere overlegne kliniske kandidater til at imødekomme akutte patientbehov, med hidtil uset hastighed: vi avancerede fra programlancering til kliniske kandidater på kun 24 måneder, betydeligt hurtigere end vores konkurrenter.
I dette indlæg fokuserer vi på, hvordan vi brugte Tømrer on Amazon Elastic Kubernetes Service (Amazon EKS) til at skalere AI-træning og inferens, som er kerneelementer i Iambic-opdagelsesplatformen.
Behovet for skalerbar AI-træning og inferens
Hver uge udfører Iambic AI-inferens på tværs af snesevis af modeller og millioner af molekyler, der tjener to primære anvendelsessager:
- Medicinske kemikere og andre videnskabsmænd bruger vores webapplikation, Insight, til at udforske kemisk rum, få adgang til og fortolke eksperimentelle data og forudsige egenskaber af nydesignede molekyler. Alt dette arbejde udføres interaktivt i realtid, hvilket skaber et behov for slutninger med lav latens og medium gennemløb.
- Samtidig designer vores generative AI-modeller automatisk molekyler, der målretter mod forbedring på tværs af adskillige egenskaber, søger millioner af kandidater og kræver enorm gennemstrømning og medium latens.
Vejledt af AI-teknologier og ekspertmedicinjægere genererer vores eksperimentelle platform tusindvis af unikke molekyler hver uge, og hver af dem udsættes for flere biologiske assays. De genererede datapunkter behandles automatisk og bruges til at finjustere vores AI-modeller hver uge. I starten tog vores modelfinjustering timers CPU-tid, så en ramme for skalering af modelfinjustering på GPU'er var bydende nødvendigt.
Vores deep learning-modeller har ikke-trivielle krav: de er gigabyte store, er talrige og heterogene og kræver GPU'er for hurtig inferens og finjustering. Med hensyn til cloud-infrastruktur havde vi brug for et system, der giver os mulighed for at få adgang til GPU'er, skalere op og ned hurtigt for at håndtere spidse, heterogene arbejdsbelastninger og køre store Docker-billeder.
Vi ønskede at bygge et skalerbart system til at understøtte AI-træning og inferens. Vi bruger Amazon EKS og ledte efter den bedste løsning til automatisk skalering af vores arbejderknudepunkter. Vi valgte Karpenter til Kubernetes node automatisk skalering af en række årsager:
- Nem integration med Kubernetes ved at bruge Kubernetes semantik til at definere nodekrav og pod-specifikationer til skalering
- Udskalering af noder med lav latens
- Nem integration med vores infrastruktur som kodeværktøj (Terraform)
Node-provisionerne understøtter ubesværet integration med Amazon EKS og andre AWS-ressourcer som f.eks Amazon Elastic Compute Cloud (Amazon EC2) forekomster og Amazon Elastic Block Store mængder. Kubernetes-semantikken, der bruges af provisionerne, understøtter rettet planlægning ved hjælp af Kubernetes-konstruktioner som f.eks. taints eller tolerationer og affinitets- eller anti-affinitetsspecifikationer; de letter også kontrol over antallet og typer af GPU-forekomster, der kan planlægges af Karpenter.
Løsningsoversigt
I dette afsnit præsenterer vi en generisk arkitektur, der ligner den, vi bruger til vores egne arbejdsbelastninger, som tillader elastisk implementering af modeller ved hjælp af effektiv automatisk skalering baseret på brugerdefinerede metrics.
Følgende diagram illustrerer løsningsarkitekturen.

Arkitekturen anvender en enkel service i en Kubernetes pod inden for en EKS klynge. Dette kan være en modelslutning, datasimulering eller enhver anden containerservice, der er tilgængelig via HTTP-anmodning. Tjenesten er eksponeret bag en omvendt proxy ved hjælp af Traefik. Den omvendte proxy indsamler metrics om opkald til tjenesten og eksponerer dem via en standard metrics API for Prometheus. Kubernetes Event Driven Autoscaler (KEDA) er konfigureret til automatisk at skalere antallet af servicepods baseret på de tilpassede metrics, der er tilgængelige i Prometheus. Her bruger vi antallet af anmodninger pr. sekund som en brugerdefineret metrik. Den samme arkitektoniske tilgang gælder, hvis du vælger en anden metrik for din arbejdsbyrde.
Karpenter overvåger for eventuelle ventende pods, der ikke kan køre på grund af mangel på tilstrækkelige ressourcer i klyngen. Hvis sådanne pods opdages, tilføjer Karpenter flere noder til klyngen for at give de nødvendige ressourcer. Omvendt, hvis der er flere noder i klyngen, end hvad der kræves af de planlagte pods, fjerner Karpenter nogle af worker noder, og pods bliver omlagt, og konsoliderer dem på færre forekomster. Antallet af HTTP-anmodninger pr. sekund og antallet af noder kan visualiseres ved hjælp af en grafana dashboard. For at demonstrere automatisk skalering kører vi en eller flere simple belastningsgenererende pods, som sender HTTP-anmodninger til tjenesten ved hjælp af krølle.
Udrulning af løsning
I trin-for-trin gennemgang, vi bruger AWS Cloud9 som et miljø til at implementere arkitekturen. Dette gør det muligt at udføre alle trin fra en webbrowser. Du kan også implementere løsningen fra en lokal computer eller EC2-instans.
For at forenkle implementeringen og forbedre reproducerbarheden følger vi principperne i lave rammer og strukturen af afhængig af docker skabelon. Vi kloner aws-do-eks projekt og ved hjælp af Docker, bygger vi et containerbillede, der er udstyret med det nødvendige værktøj og scripts. I containeren gennemgår vi alle trinene i ende-til-ende-gennemgangen, fra oprettelse af en EKS-klynge med Karpenter til skalering EC2 tilfælde.
Til eksemplet i dette indlæg bruger vi følgende EKS klynge manifest:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: do-eks-yaml-karpenter
version: '1.28'
region: us-west-2
tags:
karpenter.sh/discovery: do-eks-yaml-karpenter
iam:
withOIDC: true
addons:
- name: aws-ebs-csi-driver
version: v1.26.0-eksbuild.1
wellKnownPolicies:
ebsCSIController: true
managedNodeGroups:
- name: c5-xl-do-eks-karpenter-ng
instanceType: c5.xlarge
instancePrefix: c5-xl
privateNetworking: true
minSize: 0
desiredCapacity: 2
maxSize: 10
volumeSize: 300
iam:
withAddonPolicies:
cloudWatch: true
ebs: trueDette manifest definerer en klynge med navn do-eks-yaml-karpenter med EBS CSI-driveren installeret som en tilføjelse. En administreret nodegruppe med to c5.xlarge noder er inkluderet for at køre systempods, som er nødvendige for klyngen. Arbejdernoderne hostes i private undernet, og cluster API-slutpunktet er offentligt som standard.
Du kan også bruge en eksisterende EKS-klynge i stedet for at oprette en. Vi indsætter Karpenter ved at følge anvisninger i Karpenter-dokumentationen, eller ved at køre følgende script, som automatiserer installationsinstruktionerne.
Følgende kode viser den Karpenter-konfiguration, vi bruger i dette eksempel:
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
metadata: null
labels:
cluster-name: do-eks-yaml-karpenter
annotations:
purpose: karpenter-example
spec:
nodeClassRef:
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
name: default
requirements:
- key: karpenter.sh/capacity-type
operator: In
values:
- spot
- on-demand
- key: karpenter.k8s.aws/instance-category
operator: In
values:
- c
- m
- r
- g
- p
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values:
- '2'
disruption:
consolidationPolicy: WhenUnderutilized
#consolidationPolicy: WhenEmpty
#consolidateAfter: 30s
expireAfter: 720h
---
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default
spec:
amiFamily: AL2
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "do-eks-yaml-karpenter"
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "do-eks-yaml-karpenter"
role: "KarpenterNodeRole-do-eks-yaml-karpenter"
tags:
app: autoscaling-test
blockDeviceMappings:
- deviceName: /dev/xvda
ebs:
volumeSize: 80Gi
volumeType: gp3
iops: 10000
deleteOnTermination: true
throughput: 125
detailedMonitoring: trueVi definerer en standard Karpenter NodePool med følgende krav:
- Karpenter kan starte instanser fra begge
spot,on-demandkapacitetspuljer - Forekomster skal være fra "
c" (beregningsoptimeret), "m" (generelle formål), "r" (hukommelsesoptimeret) eller "g"Og"p” (GPU accelereret) computerfamilier - Forekomstgenerering skal være større end 2; for eksempel,
g3er acceptabelt, meng2er ikke
Standard NodePool definerer også afbrydelsespolitikker. Underudnyttede noder vil blive fjernet, så pods kan konsolideres til at køre på færre eller mindre noder. Alternativt kan vi konfigurere tomme noder til at blive fjernet efter den angivne tidsperiode. Det expireAfter indstilling angiver den maksimale levetid for enhver node, før den stoppes og om nødvendigt udskiftes. Dette hjælper med at reducere sikkerhedssårbarheder samt undgå problemer, der er typiske for noder med lang oppetid, såsom filfragmentering eller hukommelseslækager.
Som standard leverer Karpenter noder med en lille rodvolumen, som kan være utilstrækkelig til at køre AI eller maskinlæring (ML) arbejdsbelastninger. Nogle af deep learning-beholderbillederne kan være titusinder af GB store, og vi skal sørge for, at der er nok lagerplads på noderne til at køre pods ved hjælp af disse billeder. For at gøre det, definerer vi EC2NodeClass med blockDeviceMappings, som vist i den foregående kode.
Karpenter er ansvarlig for automatisk skalering på klyngeniveau. For at konfigurere automatisk skalering på pod-niveau, bruger vi KEDA til at definere en brugerdefineret ressource kaldet ScaledObject, som vist i følgende kode:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: keda-prometheus-hpa
namespace: hpa-example
spec:
scaleTargetRef:
name: php-apache
minReplicaCount: 1
cooldownPeriod: 30
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus- server.prometheus.svc.cluster.local:80
metricName: http_requests_total
threshold: '1'
query: rate(traefik_service_requests_total{service="hpa-example-php-apache-80@kubernetes",code="200"}[2m])Det foregående manifest definerer en ScaledObject som hedder keda-prometheus-hpa, som er ansvarlig for at skalere php-apache-implementeringen og altid holder mindst én replika kørende. Den skalerer pods af denne implementering baseret på metrikken http_requests_total tilgængelig i Prometheus opnået af den angivne forespørgsel, og har som mål at skalere podsene op, så hver pod ikke betjener mere end én anmodning pr. sekund. Den nedskalerer replikaerne, efter at anmodningsbelastningen har været under tærsklen i mere end 30 sekunder.
udrulningsspecifikation for vores eksempeltjeneste indeholder følgende ressourceanmodninger og begrænsninger:
resources:
limits:
cpu: 500m
nvidia.com/gpu: 1
requests:
cpu: 200m
nvidia.com/gpu: 1Med denne konfiguration vil hver af servicepods bruge præcis én NVIDIA GPU. Når nye pods er oprettet, vil de være i afventende tilstand, indtil en GPU er tilgængelig. Karpenter tilføjer GPU-noder til klyngen efter behov for at rumme de ventende pods.
A lastgenererende pod sender HTTP-anmodninger til tjenesten med en forudindstillet frekvens. Vi øger antallet af anmodninger ved at øge antallet af replikaer i belastningsgenerator udrulning.
En fuld skaleringscyklus med udnyttelsesbaseret nodekonsolidering visualiseres i et Grafana-dashboard. Det følgende dashboard viser antallet af noder i klyngen efter instanstype (øverst), antallet af anmodninger pr. sekund (nederst til venstre) og antallet af pods (nederst til højre).
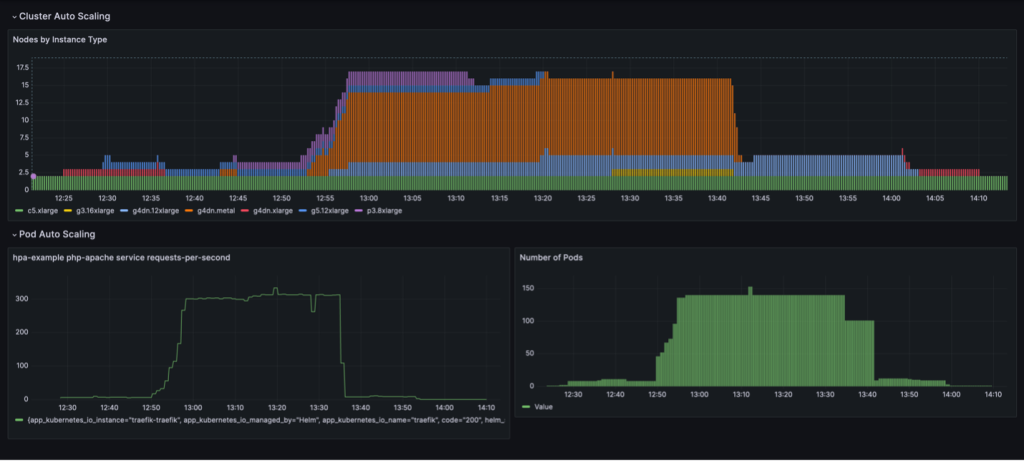
Vi starter med kun de to c5.xlarge CPU-instanser, som klyngen blev oprettet med. Derefter implementerer vi én serviceinstans, som kræver en enkelt GPU. Karpenter tilføjer en g4dn.xlarge-instans for at imødekomme dette behov. Vi implementerer derefter belastningsgeneratoren, hvilket får KEDA til at tilføje flere servicepods, og Karpenter tilføjer flere GPU-forekomster. Efter optimering sætter staten sig på én p3.8xlarge instans med 8 GPU'er og en g5.12xlarge instans med 4 GPU'er.
Når vi skalerer den belastningsgenererende implementering til 40 replikaer, opretter KEDA yderligere servicepods for at opretholde den nødvendige anmodningsbelastning pr. pod. Karpenter tilføjer g4dn.metal og g4dn.12xlarge noder til klyngen for at levere de nødvendige GPU'er til de ekstra pods. I den skalerede tilstand indeholder klyngen 16 GPU-noder og betjener omkring 300 anmodninger i sekundet. Når vi nedskalerer belastningsgeneratoren til 1 replika, sker den omvendte proces. Efter nedkølingsperioden reducerer KEDA antallet af servicepods. Efterhånden som færre pods kører, fjerner Karpenter de underudnyttede noder fra klyngen, og servicepodsene bliver konsolideret til at køre på færre noder. Når load generator pod fjernes, forbliver en enkelt service pod på en enkelt g4dn.xlarge instans med 1 GPU kørende. Når vi også fjerner servicepoden, efterlades klyngen i den oprindelige tilstand med kun to CPU-noder.
Vi kan observere denne adfærd, når NodePool har indstillingen consolidationPolicy: WhenUnderutilized.
Med denne indstilling konfigurerer Karpenter klyngen dynamisk med så få knudepunkter som muligt, samtidig med at de giver tilstrækkelige ressourcer til, at alle pods kan køre og minimerer også omkostningerne.
Skaleringsadfærden vist i det følgende dashboard observeres, når NodePool konsolideringspolitik er sat til WhenEmpty, sammen med consolidateAfter: 30s.
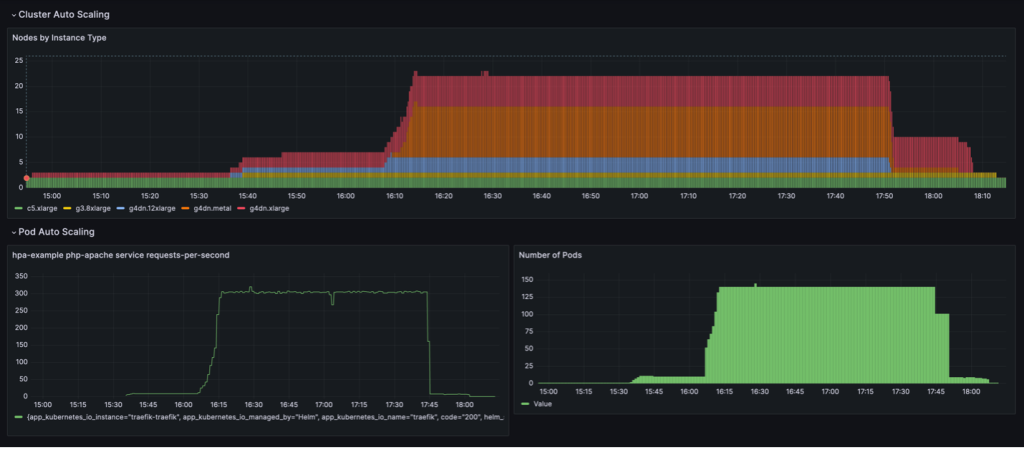
I dette scenarie stoppes noder kun, når der ikke er nogen pods, der kører på dem efter afkølingsperioden. Skaleringskurven virker glat sammenlignet med den udnyttelsesbaserede konsolideringspolitik; det kan dog ses, at der bruges flere noder i den skalerede tilstand (22 vs. 16).
Samlet set sikrer en kombination af pod og klynge automatisk skalering, at klyngen skalerer dynamisk med arbejdsbyrden, allokerer ressourcer, når det er nødvendigt og fjerner dem, når de ikke er i brug, og derved maksimerer udnyttelsen og minimerer omkostningerne.
Resultater
Iambic brugte denne arkitektur til at muliggøre effektiv brug af GPU'er på AWS og migrere arbejdsbelastninger fra CPU til GPU. Ved at bruge EC2 GPU-drevne instanser, Amazon EKS og Karpenter, var vi i stand til at muliggøre hurtigere inferens for vores fysikbaserede modeller og hurtige eksperimentiterationstider for anvendte videnskabsmænd, der er afhængige af træning som en service.
Følgende tabel opsummerer nogle af tidsmålingerne for denne migrering.
| Opgaver | CPU'er | GPU'er |
| Inferens ved hjælp af diffusionsmodeller til fysikbaserede ML-modeller | 3,600 sekunder |
100 sekunder (på grund af iboende batching af GPU'er) |
| ML modeluddannelse som en service | 180 minutter | 4 minutter |
Følgende tabel opsummerer nogle af vores tids- og omkostningsmålinger.
| Opgaver | Ydelse/omkostninger | |
| CPU'er | GPU'er | |
| ML model træning |
240 minutter gennemsnitligt 0.70 USD pr. træningsopgave |
20 minutter gennemsnitligt 0.38 USD pr. træningsopgave |
Resumé
I dette indlæg viste vi, hvordan Iambic brugte Karpenter og KEDA til at skalere vores Amazon EKS-infrastruktur for at imødekomme latenskravene for vores AI-inferens og træningsbelastninger. Karpenter og KEDA er kraftfulde open source-værktøjer, der hjælper med at automatisk skalere EKS-klynger og arbejdsbelastninger, der kører på dem. Dette hjælper med at optimere beregningsomkostningerne og samtidig opfylde ydeevnekravene. Du kan tjekke koden og implementere den samme arkitektur i dit eget miljø ved at følge den komplette gennemgang i dette GitHub repo.
Om forfatterne
 Matthew Welborn er direktør for Machine Learning hos Iambic Therapeutics. Han og hans team udnytter kunstig intelligens til at fremskynde identifikationen og udviklingen af nye terapeutiske midler, hvilket bringer livreddende medicin til patienter hurtigere.
Matthew Welborn er direktør for Machine Learning hos Iambic Therapeutics. Han og hans team udnytter kunstig intelligens til at fremskynde identifikationen og udviklingen af nye terapeutiske midler, hvilket bringer livreddende medicin til patienter hurtigere.
 Paul Whittemore er hovedingeniør hos Iambic Therapeutics. Han understøtter levering af infrastrukturen til den Iambic AI-drevne lægemiddelopdagelsesplatform.
Paul Whittemore er hovedingeniør hos Iambic Therapeutics. Han understøtter levering af infrastrukturen til den Iambic AI-drevne lægemiddelopdagelsesplatform.
 Alex Iankoulski er en Principal Solutions Architect, ML/AI Frameworks, som fokuserer på at hjælpe kunder med at orkestrere deres AI-arbejdsbelastninger ved hjælp af containere og accelereret computerinfrastruktur på AWS.
Alex Iankoulski er en Principal Solutions Architect, ML/AI Frameworks, som fokuserer på at hjælpe kunder med at orkestrere deres AI-arbejdsbelastninger ved hjælp af containere og accelereret computerinfrastruktur på AWS.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/scale-ai-training-and-inference-for-drug-discovery-through-amazon-eks-and-karpenter/

