Conversational Artificial Intelligence (AI)-assistenter er udviklet til at give præcise svar i realtid gennem intelligent routing af forespørgsler til de bedst egnede AI-funktioner. Med AWS generative AI-tjenester som Amazonas grundfjeld, kan udviklere skabe systemer, der ekspertstyrer og reagerer på brugeranmodninger. Amazon Bedrock er en fuldt administreret tjeneste, der tilbyder et udvalg af højtydende fundamentmodeller (FM'er) fra førende AI-virksomheder som AI21 Labs, Anthropic, Cohere, Meta, Stability AI og Amazon ved hjælp af en enkelt API, sammen med et bredt sæt af funktioner, du har brug for for at bygge generative AI-applikationer med sikkerhed, privatliv og ansvarlig AI.
Dette indlæg vurderer to primære tilgange til udvikling af AI-assistenter: Brug af administrerede tjenester som f.eks Agenter for Amazon Bedrock, og anvender open source-teknologier som Langkæde. Vi udforsker fordelene og udfordringerne ved hver enkelt, så du kan vælge den bedst egnede vej til dine behov.
Hvad er en AI-assistent?
En AI-assistent er et intelligent system, der forstår naturlige sprogforespørgsler og interagerer med forskellige værktøjer, datakilder og API'er for at udføre opgaver eller hente information på vegne af brugeren. Effektive AI-assistenter har følgende nøglefunktioner:
- Naturlig sprogbehandling (NLP) og samtaleflow
- Videnbase-integration og semantiske søgninger for at forstå og hente relevant information baseret på nuancerne i samtalekontekst
- Kørende opgaver, såsom databaseforespørgsler og brugerdefinerede AWS Lambda funktioner
- Håndtering af specialiserede samtaler og brugerønsker
Vi demonstrerer fordelene ved AI-assistenter, der bruger Internet of Things (IoT) enhedsadministration som eksempel. I dette tilfælde kan AI hjælpe teknikere med at administrere maskineri effektivt med kommandoer, der henter data eller automatiserer opgaver, og strømliner operationer i produktionen.
Agenter for Amazon Bedrock tilgang
Agenter for Amazon Bedrock giver dig mulighed for at bygge generative AI-applikationer, der kan køre flertrinsopgaver på tværs af en virksomheds systemer og datakilder. Det tilbyder følgende nøglefunktioner:
- Automatisk prompt-oprettelse fra instruktioner, API-detaljer og datakildeoplysninger, hvilket sparer ugers hurtig ingeniørindsats
- Retrieval Augmented Generation (RAG) for sikkert at forbinde agenter til en virksomheds datakilder og give relevante svar
- Orkestrering og afvikling af flertrinsopgaver ved at opdele anmodninger i logiske sekvenser og kalde nødvendige API'er
- Synlighed i agentens ræsonnement gennem en chain-of-thought (CoT) sporing, der tillader fejlfinding og styring af modeladfærd
- Spørg tekniske evner til at ændre den automatisk genererede promptskabelon for forbedret kontrol over agenter
Du kan bruge Agents til Amazon Bedrock og Vidensbaser for Amazon Bedrock at bygge og implementere AI-assistenter til komplekse routingbrugssager. De giver en strategisk fordel for udviklere og organisationer ved at forenkle infrastrukturstyring, forbedre skalerbarheden, forbedre sikkerheden og reducere udifferentierede tunge løft. De giver også mulighed for enklere applikationslagskode, fordi routinglogikken, vektoriseringen og hukommelsen er fuldt styret.
Løsningsoversigt
Denne løsning introducerer en samtale-AI-assistent, der er skræddersyet til IoT-enhedsstyring og -operationer, når du bruger Anthropics Claude v2.1 på Amazon Bedrock. AI-assistentens kernefunktionalitet er styret af et omfattende sæt instruktioner, kendt som en systemprompt, som afgrænser dets evner og ekspertiseområder. Denne vejledning sikrer, at AI-assistenten kan håndtere en bred vifte af opgaver, fra administration af enhedsinformation til at køre operationelle kommandoer.
Udstyret med disse funktioner, som beskrevet i systemprompten, følger AI-assistenten en struktureret arbejdsgang for at løse brugerspørgsmål. Følgende figur giver en visuel repræsentation af denne arbejdsgang, der illustrerer hvert trin fra den første brugerinteraktion til det endelige svar.

Arbejdsgangen er sammensat af følgende trin:
- Processen begynder, når en bruger anmoder assistenten om at udføre en opgave; for eksempel at bede om de maksimale datapunkter for en specifik IoT-enhed
device_xxx. Denne tekstinput fanges og sendes til AI-assistenten. - AI-assistenten fortolker brugerens tekstinput. Den bruger den medfølgende samtalehistorik, handlingsgrupper og vidensbaser til at forstå konteksten og bestemme de nødvendige opgaver.
- Når brugerens hensigt er analyseret og forstået, definerer AI-assistenten opgaver. Dette er baseret på instruktionerne, der fortolkes af assistenten i henhold til systemprompten og brugerens input.
- Opgaverne køres derefter gennem en række API-kald. Dette gøres vha Reagere prompt, som opdeler opgaven i en række trin, der behandles sekventielt:
- Til kontrol af enhedsmetrikker bruger vi
check-device-metricshandlingsgruppe, som involverer et API-kald til Lambda-funktioner, der derefter forespørger Amazonas Athena for de ønskede data. - Til direkte enhedshandlinger som start, stop eller genstart bruger vi
action-on-deviceaktionsgruppe, som påberåber sig en lambdafunktion. Denne funktion starter en proces, der sender kommandoer til IoT-enheden. Til dette indlæg sender Lambda-funktionen meddelelser vha Amazon Simple Email Service (Amazon SES). - Vi bruger Knowledge Bases for Amazon Bedrock til at hente fra historiske data, der er gemt som indlejringer i Amazon OpenSearch Service vektor database.
- Til kontrol af enhedsmetrikker bruger vi
- Når opgaverne er afsluttet, genereres det endelige svar af Amazon Bedrock FM og sendes tilbage til brugeren.
- Agenter for Amazon Bedrock gemmer automatisk information ved hjælp af en stateful session for at opretholde den samme samtale. Tilstanden slettes efter en konfigurerbar inaktiv timeout er udløbet.
Teknisk oversigt
Følgende diagram illustrerer arkitekturen til at implementere en AI-assistent med Agents for Amazon Bedrock.
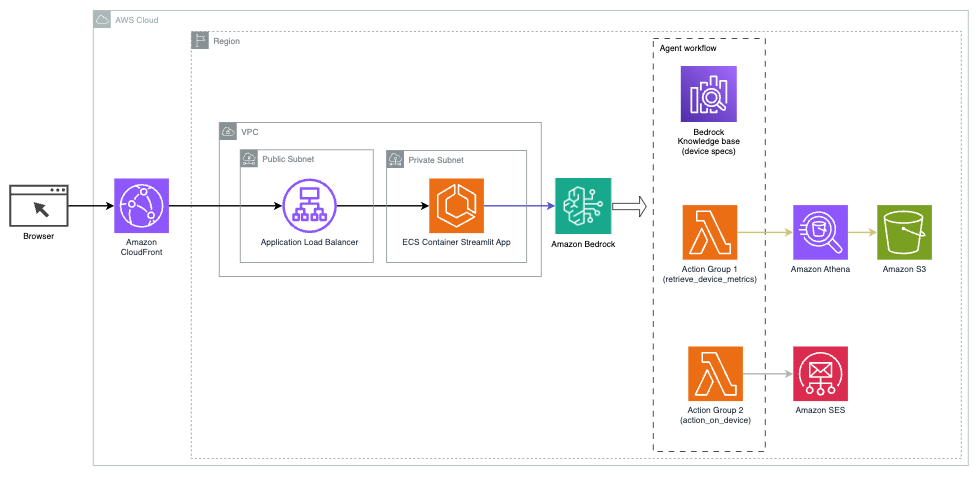
Den består af følgende nøglekomponenter:
- Samtalegrænseflade – Samtalegrænsefladen bruger Streamlit, et open source Python-bibliotek, der forenkler oprettelsen af tilpassede, visuelt tiltalende webapps til maskinlæring (ML) og datavidenskab. Det er hostet på Amazon Elastic Container Service (Amazon ECS) med AWS Fargate, og den tilgås ved hjælp af en Application Load Balancer. Du kan bruge Fargate med Amazon ECS til at køre beholdere uden at skulle administrere servere, klynger eller virtuelle maskiner.
- Agenter for Amazon Bedrock – Agenter for Amazon Bedrock afslutter brugerforespørgslerne gennem en række ræsonnementtrin og tilsvarende handlinger baseret på React prompt:
- Vidensbaser for Amazon Bedrock – Vidensbaser til Amazon Bedrock giver fuldt administreret KLUD at give AI-assistenten adgang til dine data. I vores anvendelsestilfælde uploadede vi enhedsspecifikationer til en Amazon Simple Storage Service (Amazon S3) spand. Det fungerer som datakilden til videnbasen.
- Aktionsgrupper – Disse er definerede API-skemaer, der påkalder specifikke Lambda-funktioner for at interagere med IoT-enheder og andre AWS-tjenester.
- Antropiske Claude v2.1 på Amazon Bedrock – Denne model fortolker brugerforespørgsler og orkestrerer strømmen af opgaver.
- Amazon Titan-indlejringer – Denne model fungerer som en tekstindlejringsmodel, der transformerer tekst i naturligt sprog – fra enkelte ord til komplekse dokumenter – til numeriske vektorer. Dette muliggør vektorsøgningsfunktioner, hvilket gør det muligt for systemet semantisk at matche brugerforespørgsler med de mest relevante vidensbaseindgange til effektiv søgning.
Løsningen er integreret med AWS-tjenester såsom Lambda til at køre kode som svar på API-kald, Athena til forespørgsel på datasæt, OpenSearch Service til søgning gennem vidensbaser og Amazon S3 til lagring. Disse tjenester arbejder sammen for at give en problemfri oplevelse for IoT-enhedsdriftsstyring gennem naturlige sprogkommandoer.
Fordele
Denne løsning giver følgende fordele:
- Implementeringskompleksitet:
- Der kræves færre linjer kode, fordi Agents for Amazon Bedrock abstraherer meget af den underliggende kompleksitet, hvilket reducerer udviklingsindsatsen
- Håndtering af vektordatabaser som OpenSearch Service er forenklet, fordi Knowledge Bases for Amazon Bedrock håndterer vektorisering og lagring
- Integration med forskellige AWS-tjenester er mere strømlinet gennem foruddefinerede handlingsgrupper
- Udviklererfaring:
- Amazon Bedrock-konsollen giver en brugervenlig grænseflade til hurtig udvikling, test og rodårsagsanalyse (RCA), hvilket forbedrer den overordnede udvikleroplevelse
- Agilitet og fleksibilitet:
- Agenter for Amazon Bedrock giver mulighed for problemfri opgraderinger til nyere FM'er (såsom Claude 3.0), når de bliver tilgængelige, så din løsning forbliver opdateret med de seneste fremskridt
- Servicekvoter og begrænsninger administreres af AWS, hvilket reducerer omkostningerne ved overvågning og skalering af infrastruktur
- Sikkerhed:
- Amazon Bedrock er en fuldt administreret tjeneste, der overholder AWS's strenge sikkerheds- og overholdelsesstandarder, hvilket potentielt forenkler organisatoriske sikkerhedsgennemgange
Selvom Agents for Amazon Bedrock tilbyder en strømlinet og administreret løsning til at bygge samtale-AI-applikationer, foretrækker nogle organisationer måske en open source-tilgang. I sådanne tilfælde kan du bruge rammer som LangChain, som vi diskuterer i næste afsnit.
LangChain dynamisk routing tilgang
LangChain er en open source-ramme, der forenkler opbygning af konversations-AI ved at tillade integration af store sprogmodeller (LLM'er) og dynamiske routing-funktioner. Med LangChain Expression Language (LCEL) kan udviklere definere routing, som giver dig mulighed for at oprette ikke-deterministiske kæder, hvor outputtet fra et tidligere trin definerer det næste trin. Routing hjælper med at give struktur og konsistens i interaktioner med LLM'er.
Til dette indlæg bruger vi det samme eksempel som AI-assistenten til IoT-enhedshåndtering. Den største forskel er dog, at vi skal håndtere systemprompts separat og behandle hver kæde som en separat enhed. Rutekæden bestemmer destinationskæden baseret på brugerens input. Beslutningen træffes med støtte fra en LLM ved at sende systemprompten, chathistorikken og brugerens spørgsmål.
Løsningsoversigt
Følgende diagram illustrerer den dynamiske routingløsnings arbejdsgang.

Arbejdsgangen består af følgende trin:
- Brugeren præsenterer et spørgsmål til AI-assistenten. For eksempel "Hvad er de maksimale metrics for enhed 1009?"
- En LLM evaluerer hvert spørgsmål sammen med chathistorikken fra den samme session for at bestemme dets karakter og hvilket emne det falder ind under (såsom SQL, handling, søgning eller SME). LLM klassificerer inputtet, og LCEL-routingkæden tager det input.
- Routerkæden vælger destinationskæden baseret på inputtet, og LLM er forsynet med følgende systemprompt:
LLM'en evaluerer brugerens spørgsmål sammen med chathistorikken for at bestemme arten af forespørgslen og hvilket emneområde den falder ind under. LLM klassificerer derefter inputtet og udsender et JSON-svar i følgende format:
Routerkæden bruger dette JSON-svar til at kalde den tilsvarende destinationskæde. Der er fire emnespecifikke destinationskæder, hver med sin egen systemprompt:
- SQL-relaterede forespørgsler sendes til SQL-destinationskæden for databaseinteraktioner. Du kan bruge LCEL til at bygge SQL kæde.
- Handlingsorienterede spørgsmål påberåber sig den tilpassede Lambda-destinationskæde til at køre operationer. Med LCEL kan du definere din egen brugerdefineret funktion; i vores tilfælde er det en funktion at køre en foruddefineret Lambda-funktion for at sende en e-mail med et parset enheds-id. Eksempel på brugerinput kan være "Sluk enhed 1009".
- Søgefokuserede forespørgsler fortsætter til KLUD destinationskæde til informationssøgning.
- SMV-relaterede spørgsmål går til SMV-/ekspertdestinationskæden for specialiseret indsigt.
- Hver destinationskæde tager inputtet og kører de nødvendige modeller eller funktioner:
- SQL-kæden bruger Athena til at køre forespørgsler.
- RAG-kæden bruger OpenSearch Service til semantisk søgning.
- Den tilpassede Lambda-kæde kører Lambda-funktioner til handlinger.
- SMV/ekspertkæden giver indsigt ved hjælp af Amazon Bedrock-modellen.
- Svar fra hver destinationskæde formuleres til sammenhængende indsigt af LLM. Disse indsigter leveres derefter til brugeren og fuldender forespørgselscyklussen.
- Brugerinput og -svar gemmes i Amazon DynamoDB at give kontekst til LLM for den aktuelle session og fra tidligere interaktioner. Varigheden af vedvarende information i DynamoDB styres af applikationen.
Teknisk oversigt
Følgende diagram illustrerer arkitekturen af LangChain dynamiske routing-løsning.
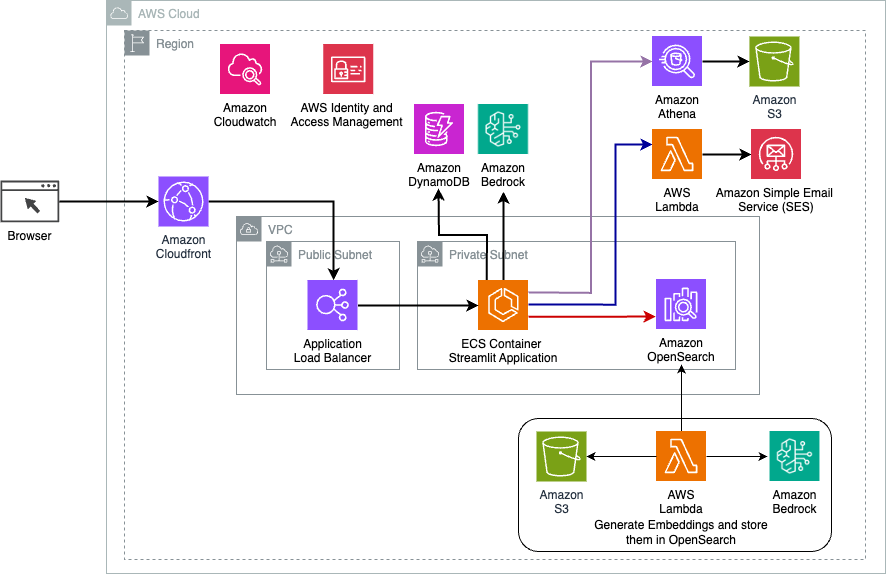
Webapplikationen er bygget på Streamlit hostet på Amazon ECS med Fargate, og den tilgås ved hjælp af en Application Load Balancer. Vi bruger Anthropics Claude v2.1 på Amazon Bedrock som vores LLM. Webapplikationen interagerer med modellen ved hjælp af LangChain-biblioteker. Det interagerer også med en række andre AWS-tjenester, såsom OpenSearch Service, Athena og DynamoDB for at opfylde slutbrugernes behov.
Fordele
Denne løsning giver følgende fordele:
- Implementeringskompleksitet:
- Selvom det kræver mere kode og tilpasset udvikling, giver LangChain større fleksibilitet og kontrol over routinglogikken og integrationen med forskellige komponenter.
- Håndtering af vektordatabaser som OpenSearch Service kræver yderligere opsætning og konfiguration. Vektoriseringsprocessen er implementeret i kode.
- Integration med AWS-tjenester kan involvere mere tilpasset kode og konfiguration.
- Udviklererfaring:
- LangChains Python-baserede tilgang og omfattende dokumentation kan appellere til udviklere, der allerede er bekendt med Python og open source-værktøjer.
- Hurtig udvikling og fejlretning kan kræve mere manuel indsats sammenlignet med at bruge Amazon Bedrock-konsollen.
- Agilitet og fleksibilitet:
- LangChain understøtter en bred vifte af LLM'er, så du kan skifte mellem forskellige modeller eller udbydere, hvilket fremmer fleksibilitet.
- LangChains open source-karakter muliggør fællesskabsdrevne forbedringer og tilpasninger.
- Sikkerhed:
- Som en open source-ramme kan LangChain kræve mere stringente sikkerhedsgennemgange og kontrol inden for organisationer, hvilket potentielt kan tilføje overhead.
Konklusion
Conversational AI-assistenter er transformative værktøjer til at strømline driften og forbedre brugeroplevelsen. Dette indlæg udforskede to kraftfulde tilgange ved hjælp af AWS-tjenester: de administrerede agenter til Amazon Bedrock og den fleksible, open source LangChain dynamiske routing. Valget mellem disse tilgange afhænger af din organisations krav, udviklingspræferencer og det ønskede tilpasningsniveau. Uanset vejen, giver AWS dig mulighed for at skabe intelligente AI-assistenter, der revolutionerer forretnings- og kundeinteraktioner
Find løsningskoden og implementeringsaktiverne i vores GitHub repository, hvor du kan følge de detaljerede trin for hver samtale-AI-tilgang.
Om forfatterne
 Ameer Hakme er en AWS Solutions Architect baseret i Pennsylvania. Han samarbejder med Independent Software Vendors (ISV'er) i den nordøstlige region og hjælper dem med at designe og bygge skalerbare og moderne platforme på AWS Cloud. En ekspert i AI/ML og generativ AI, Ameer hjælper kunder med at frigøre potentialet i disse banebrydende teknologier. I sin fritid nyder han at køre på sin motorcykel og tilbringe kvalitetstid med sin familie.
Ameer Hakme er en AWS Solutions Architect baseret i Pennsylvania. Han samarbejder med Independent Software Vendors (ISV'er) i den nordøstlige region og hjælper dem med at designe og bygge skalerbare og moderne platforme på AWS Cloud. En ekspert i AI/ML og generativ AI, Ameer hjælper kunder med at frigøre potentialet i disse banebrydende teknologier. I sin fritid nyder han at køre på sin motorcykel og tilbringe kvalitetstid med sin familie.
 Sharon Lic er en AI/ML Solutions Architect hos Amazon Web Services baseret i Boston, med en passion for at designe og bygge Generative AI-applikationer på AWS. Hun samarbejder med kunder for at udnytte AWS AI/ML-tjenester til innovative løsninger.
Sharon Lic er en AI/ML Solutions Architect hos Amazon Web Services baseret i Boston, med en passion for at designe og bygge Generative AI-applikationer på AWS. Hun samarbejder med kunder for at udnytte AWS AI/ML-tjenester til innovative løsninger.
 Kawsar Kamal er en senior løsningsarkitekt hos Amazon Web Services med over 15 års erfaring inden for infrastrukturautomatisering og sikkerhedsområdet. Han hjælper kunder med at designe og bygge skalerbare DevSecOps og AI/ML-løsninger i skyen.
Kawsar Kamal er en senior løsningsarkitekt hos Amazon Web Services med over 15 års erfaring inden for infrastrukturautomatisering og sikkerhedsområdet. Han hjælper kunder med at designe og bygge skalerbare DevSecOps og AI/ML-løsninger i skyen.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/enhance-conversational-ai-with-advanced-routing-techniques-with-amazon-bedrock/

