Amazon Titan lmage Generator G1 er en banebrydende tekst-til-billede model, tilgængelig via Amazonas grundfjeld, der er i stand til at forstå prompter, der beskriver flere objekter i forskellige sammenhænge og fanger disse relevante detaljer i de billeder, den genererer. Den er tilgængelig i US East (N. Virginia) og US West (Oregon) AWS-regioner og kan udføre avancerede billedredigeringsopgaver såsom smart beskæring, in-painting og baggrundsændringer. Brugere vil dog gerne tilpasse modellen til unikke karakteristika i brugerdefinerede datasæt, som modellen ikke allerede er trænet i. Tilpassede datasæt kan omfatte meget proprietære data, der er i overensstemmelse med dine brandretningslinjer eller specifikke stilarter, såsom en tidligere kampagne. For at løse disse brugssager og generere fuldt personlige billeder, kan du finjustere Amazon Titan Image Generator med dine egne data ved hjælp af brugerdefinerede modeller til Amazon Bedrock.
Fra generering af billeder til redigering af dem har tekst-til-billede-modeller brede anvendelser på tværs af brancher. De kan øge medarbejdernes kreativitet og give mulighed for at forestille sig nye muligheder blot med tekstmæssige beskrivelser. For eksempel kan det hjælpe med design og gulvplanlægning for arkitekter og tillade hurtigere innovation ved at give mulighed for at visualisere forskellige designs uden den manuelle proces med at skabe dem. På samme måde kan det hjælpe med design på tværs af forskellige industrier såsom fremstilling, modedesign i detailhandlen og spildesign ved at strømline generationen af grafik og illustrationer. Tekst-til-billede-modeller forbedrer også din kundeoplevelse ved at give mulighed for personlig annoncering samt interaktive og fordybende visuelle chatbots i medie- og underholdningstilfælde.
I dette indlæg guider vi dig gennem processen med at finjustere Amazon Titan Image Generator-modellen for at lære to nye kategorier: Hunden Ron og katten Smila, vores yndlingskæledyr. Vi diskuterer, hvordan du forbereder dine data til modelfinjusteringsopgaven, og hvordan du opretter et modeltilpasningsjob i Amazon Bedrock. Til sidst viser vi dig, hvordan du tester og implementerer din finjusterede model med Forsynet gennemløb.
 |
 |
| Hunden Ron | Smil katten |
Evaluering af modelkapaciteter før finjustering af et job
Foundation-modeller trænes på store mængder data, så det er muligt, at din model fungerer godt nok ud af boksen. Derfor er det god praksis at tjekke, om du rent faktisk har brug for at finjustere din model til dit brugssag, eller om hurtig konstruktion er tilstrækkelig. Lad os prøve at generere nogle billeder af hunden Ron og katten Smila med basismodellen Amazon Titan Image Generator, som vist på de følgende skærmbilleder.


Som forventet kender out-of-the-box-modellen ikke Ron og Smila endnu, og de genererede output viser forskellige hunde og katte. Med nogle hurtige teknikker kan vi give flere detaljer for at komme tættere på udseendet af vores yndlingskæledyr.


Selvom de genererede billeder minder mere om Ron og Smila, ser vi, at modellen ikke er i stand til at gengive den fulde lighed med dem. Lad os nu starte et finjusteringsjob med billederne fra Ron og Smila for at få ensartede, personlige output.
Finjustering af Amazon Titan Image Generator
Amazon Bedrock giver dig en serverløs oplevelse til at finjustere din Amazon Titan Image Generator-model. Du behøver kun at forberede dine data og vælge dine hyperparametre, så klarer AWS de tunge løft for dig.
Når du bruger Amazon Titan Image Generator-modellen til at finjustere, oprettes en kopi af denne model i AWS-modeludviklingskontoen, der ejes og administreres af AWS, og der oprettes et modeltilpasningsjob. Dette job får derefter adgang til finjusteringsdataene fra en VPC, og Amazon Titan-modellen får sine vægte opdateret. Den nye model gemmes derefter i en Amazon Simple Storage Service (Amazon S3) placeret i samme modeludviklingskonto som den fortrænede model. Det kan nu kun bruges til slutninger af din konto og deles ikke med nogen anden AWS-konto. Når du kører inferens, får du adgang til denne model via en forudsat kapacitetsberegning eller direkte vha batch-inferens for Amazon Bedrock. Uafhængigt af den valgte inferensmodalitet forbliver dine data på din konto og kopieres ikke til nogen AWS-ejet konto eller bruges til at forbedre Amazon Titan Image Generator-modellen.
Følgende diagram illustrerer denne arbejdsgang.

Databeskyttelse og netværkssikkerhed
Dine data, der bruges til finjustering, inklusive prompter, såvel som de tilpassede modeller, forbliver private på din AWS-konto. De deles ikke eller bruges til modeltræning eller serviceforbedringer og deles ikke med tredjepartsmodeludbydere. Alle data, der bruges til finjustering, er krypteret under transport og hvile. Dataene forbliver i den samme region, hvor API-kaldet behandles. Du kan også bruge AWS PrivateLink for at skabe en privat forbindelse mellem AWS-kontoen, hvor dine data ligger, og VPC'en.
Forberedelse af data
Før du kan oprette et modeltilpasningsjob, skal du forberede dit træningsdatasæt. Formatet på dit træningsdatasæt afhænger af den type tilpasningsjob, du opretter (finjustering eller fortsat fortræning) og modaliteten af dine data (tekst-til-tekst, tekst-til-billede eller billede-til- indlejring). For Amazon Titan Image Generator-modellen skal du angive de billeder, du vil bruge til finjusteringen, og en billedtekst til hvert billede. Amazon Bedrock forventer, at dine billeder bliver gemt på Amazon S3, og at parrene af billeder og billedtekster leveres i et JSONL-format med flere JSON-linjer.
Hver JSON-linje er en prøve, der indeholder en billedreferering, S3-URI'en for et billede og en billedtekst, der indeholder en tekstprompt til billedet. Dine billeder skal være i JPEG- eller PNG-format. Følgende kode viser et eksempel på formatet:
{"image-ref": "s3://bucket/path/to/image001.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image002.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image003.png", "caption": ""}
Fordi "Ron" og "Smila" er navne, der også kan bruges i andre sammenhænge, såsom en persons navn, tilføjer vi identifikatorerne "Ron the dog" og "Smila the cat", når vi opretter prompten for at finjustere vores model . Selvom det ikke er et krav for finjustering af arbejdsgangen, giver denne yderligere information mere kontekstuel klarhed for modellen, når den tilpasses til de nye klasser, og vil undgå forvekslingen af "Ron the dog" med en person kaldet Ron og " Smila the cat” med byen Smila i Ukraine. Ved at bruge denne logik viser de følgende billeder et eksempel på vores træningsdatasæt.
 |
 |
 |
| Hunden Ron ligger på en hvid hundeseng | Hunden Ron sidder på et flisegulv | Hunden Ron ligger på en autostol |
 |
 |
 |
| Smila katten liggende på en sofa | Katten Smila stirrer på kameraet, der ligger på en sofa | Smila katten lægger sig i en kæledyrsbærer |
Når vi transformerer vores data til det format, der forventes af tilpasningsopgaven, får vi følgende eksempelstruktur:
{"image-ref": "/ron_01.jpg", "caption": "Hunden Ron ligger på en hvid hundeseng"} {"image-ref": "/ron_02.jpg", "caption": "Ron hunden sidder på et flisegulv"} {"image-ref": "/ron_03.jpg", "caption": "Ron hunden ligger på en autostol"} {"image-ref": "/smila_01.jpg", "caption": "Smila katten liggende på en sofa"} {"image-ref": "/smila_02.jpg", "caption": "Smila katten sidder ved siden af vinduet ved siden af en statue kat"} {"image-ref": "/smila_03.jpg", "caption": "Smila katten liggende på en kæledyrsbærer"}
Efter at vi har oprettet vores JSONL-fil, skal vi gemme den på en S3-bøtte for at starte vores tilpasningsjob. Amazon Titan Image Generator G1 finjusteringsjob vil fungere med 5-10,000 billeder. Til eksemplet diskuteret i dette indlæg bruger vi 60 billeder: 30 af hunden Ron og 30 af katten Smila. Generelt vil det at give flere varianter af den stil eller klasse, du prøver at lære, forbedre nøjagtigheden af din finjusterede model. Men jo flere billeder du bruger til at finjustere, jo mere tid vil der kræves for at finjustere jobbet. Antallet af brugte billeder påvirker også prisen på dit finjusterede job. Henvise til Priser for Amazons grundfjeld for mere information.
Finjustering af Amazon Titan Image Generator
Nu hvor vi har vores træningsdata klar, kan vi begynde et nyt tilpasningsjob. Denne proces kan udføres både via Amazon Bedrock-konsollen eller API'er. For at bruge Amazon Bedrock-konsollen skal du udføre følgende trin:
- Vælg på Amazon Bedrock-konsollen Brugerdefinerede modeller i navigationsruden.
- På Tilpas model menu, vælg Opret finjusteringsjob.
- Til Finjusteret modelnavn, indtast et navn til din nye model.
- Til Jobkonfiguration, indtast et navn til træningsjobbet.
- Til Indtast data, skal du indtaste S3-stien til inputdataene.

- I Hyperparametre sektion, angiv værdier for følgende:
- Antal trin – Antallet af gange, modellen er eksponeret for hver batch.
- Batch størrelse – Antallet af prøver behandlet før opdatering af modelparametrene.
- Læringsgrad – Den hastighed, hvormed modelparametrene opdateres efter hver batch. Valget af disse parametre afhænger af et givet datasæt. Som en generel retningslinje anbefaler vi, at du starter med at fastsætte batchstørrelsen til 8, indlæringshastigheden til 1e-5 og indstille antallet af trin i henhold til antallet af brugte billeder, som beskrevet i følgende tabel.
| Antal oplyst billeder | 8 | 32 | 64 | 1,000 | 10,000 |
| Antal anbefalede trin | 1,000 | 4,000 | 8,000 | 10,000 | 12,000 |
Hvis resultaterne af dit finjusteringsjob ikke er tilfredsstillende, kan du overveje at øge antallet af trin, hvis du ikke observerer nogen tegn på stilen i genererede billeder, og reducere antallet af trin, hvis du observerer stilen i de genererede billeder, men med artefakter eller sløring. Hvis den finjusterede model ikke formår at lære den unikke stil i dit datasæt selv efter 40,000 trin, kan du overveje at øge batchstørrelsen eller indlæringshastigheden.
- I Outputdata sektion, skal du indtaste S3-outputstien, hvor valideringsoutput, inklusive de periodisk registrerede valideringstab og nøjagtighedsmålinger, er gemt.
- I Serviceadgang sektion, generere en ny AWS identitets- og adgangsstyring (IAM)-rolle eller vælg en eksisterende IAM-rolle med de nødvendige tilladelser for at få adgang til dine S3-bøtter.
Denne autorisation gør det muligt for Amazon Bedrock at hente input- og valideringsdatasæt fra din udpegede bucket og gemme valideringsoutput problemfrit i din S3 bucket.
- Vælg Finjuster model.

Med de korrekte konfigurationer indstillet vil Amazon Bedrock nu træne din brugerdefinerede model.
Implementer den finjusterede Amazon Titan Image Generator med Provisioned Throughput
Når du har oprettet en tilpasset model, giver Provisioned Throughput dig mulighed for at allokere en forudbestemt, fast hastighed for behandlingskapacitet til den tilpassede model. Denne tildeling giver et ensartet niveau af ydeevne og kapacitet til håndtering af arbejdsbelastninger, hvilket resulterer i bedre ydeevne i produktionsbelastninger. Den anden fordel ved Provisioned Throughput er omkostningskontrol, fordi standard token-baseret prissætning med on-demand-inferenstilstand kan være svær at forudsige i stor skala.
Når finjusteringen af din model er færdig, vises denne model på Brugerdefinerede modeller' side på Amazon Bedrock-konsollen.
For at købe Provisioned Throughput skal du vælge den brugerdefinerede model, som du lige har finjusteret og vælge Køb Provisioned Throughput.
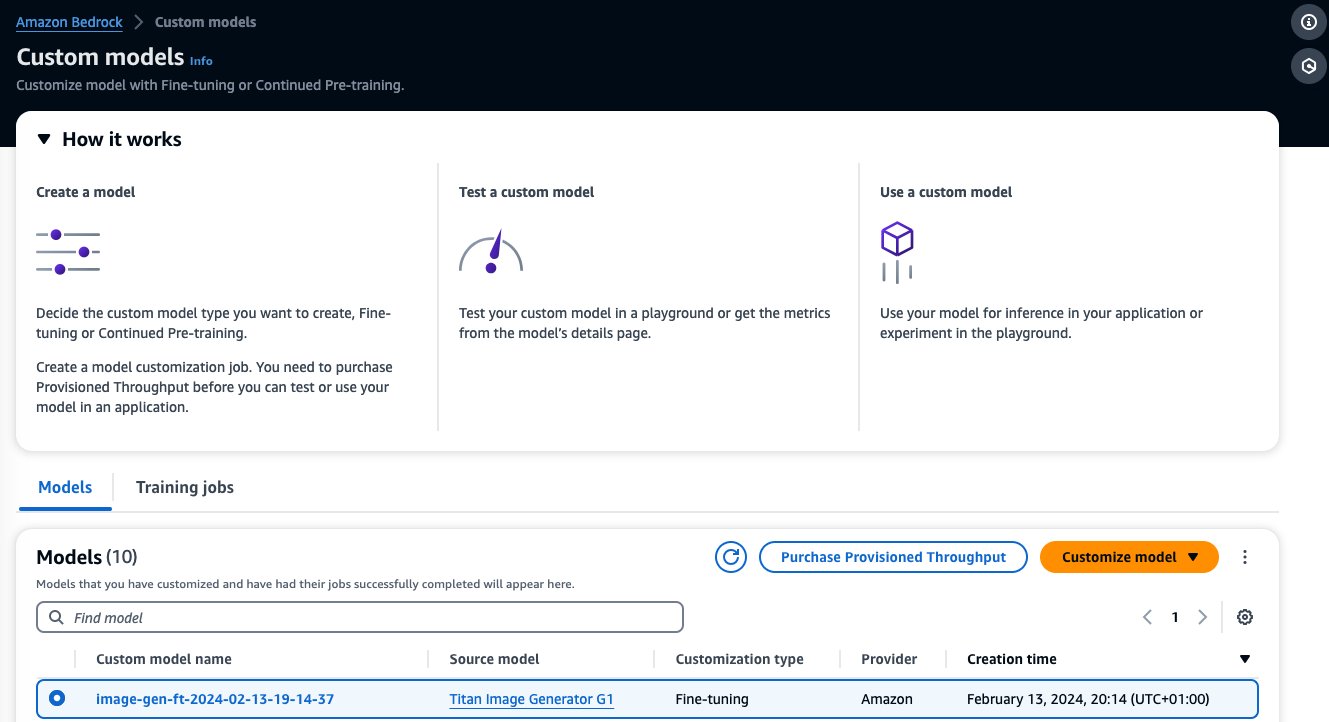
Dette udfylder den valgte model, som du vil købe Provisioned Throughput for. For at teste din finjusterede model før implementering skal du indstille modelenheder til en værdi på 1 og indstille forpligtelsesperioden til Ingen forpligtelse. Dette lader dig hurtigt begynde at teste dine modeller med dine brugerdefinerede prompter og kontrollere, om træningen er tilstrækkelig. Når nye finjusterede modeller og nye versioner er tilgængelige, kan du desuden opdatere den forudsatte kapacitet, så længe du opdaterer den med andre versioner af samme model.

Finjustering af resultater
Til vores opgave med at tilpasse modellen på hunden Ron og katten Smila viste eksperimenter, at de bedste hyperparametre var 5,000 trin med en batchstørrelse på 8 og en indlæringshastighed på 1e-5.
Følgende er nogle eksempler på de billeder, der genereres af den tilpassede model.
 |
 |
 |
| Hunden Ron iført en superheltekappe | Hunden Ron på månen | Ron hunden i en swimmingpool med solbriller |
 |
 |
 |
| Smil katten på sneen | Smil katten i sort/hvid og stirrer på kameraet | Katten Smila iført julehue |
Konklusion
I dette indlæg diskuterede vi, hvornår du skal bruge finjustering i stedet for at udvikle dine prompter til billedgenerering i bedre kvalitet. Vi viste, hvordan man finjusterer Amazon Titan Image Generator-modellen og implementerer den brugerdefinerede model på Amazon Bedrock. Vi har også givet generelle retningslinjer for, hvordan du forbereder dine data til finjustering og indstiller optimale hyperparametre for mere præcis modeltilpasning.
Som et næste skridt kan du tilpasse følgende eksempel til din brug for at generere hyper-personlige billeder ved hjælp af Amazon Titan Image Generator.
Om forfatterne
 Maira Ladeira Tanke er Senior Generative AI Data Scientist hos AWS. Med en baggrund i machine learning har hun over 10 års erfaring med at arkitekte og bygge AI-applikationer med kunder på tværs af brancher. Som teknisk lead hjælper hun kunder med at accelerere deres opnåelse af forretningsværdi gennem generative AI-løsninger på Amazon Bedrock. I sin fritid nyder Maira at rejse, lege med sin kat Smila og tilbringe tid med sin familie et varmt sted.
Maira Ladeira Tanke er Senior Generative AI Data Scientist hos AWS. Med en baggrund i machine learning har hun over 10 års erfaring med at arkitekte og bygge AI-applikationer med kunder på tværs af brancher. Som teknisk lead hjælper hun kunder med at accelerere deres opnåelse af forretningsværdi gennem generative AI-løsninger på Amazon Bedrock. I sin fritid nyder Maira at rejse, lege med sin kat Smila og tilbringe tid med sin familie et varmt sted.
 Dani Mitchell er AI/ML Specialist Solutions Architect hos Amazon Web Services. Han er fokuseret på computer vision use cases og hjælper kunder på tværs af EMEA med at accelerere deres ML rejse.
Dani Mitchell er AI/ML Specialist Solutions Architect hos Amazon Web Services. Han er fokuseret på computer vision use cases og hjælper kunder på tværs af EMEA med at accelerere deres ML rejse.
 Bharathi Srinivasan er Data Scientist hos AWS Professional Services, hvor hun elsker at bygge fede ting på Amazon Bedrock. Hun brænder for at skabe forretningsværdi fra maskinlæringsapplikationer med fokus på ansvarlig AI. Ud over at bygge nye AI-oplevelser for kunder, elsker Bharathi at skrive science fiction og udfordre sig selv med udholdenhedssport.
Bharathi Srinivasan er Data Scientist hos AWS Professional Services, hvor hun elsker at bygge fede ting på Amazon Bedrock. Hun brænder for at skabe forretningsværdi fra maskinlæringsapplikationer med fokus på ansvarlig AI. Ud over at bygge nye AI-oplevelser for kunder, elsker Bharathi at skrive science fiction og udfordre sig selv med udholdenhedssport.
 Achin Jain er en anvendt videnskabsmand med Amazon Artificial General Intelligence (AGI)-teamet. Han har ekspertise i tekst-til-billede-modeller og er fokuseret på at bygge Amazon Titan Image Generator.
Achin Jain er en anvendt videnskabsmand med Amazon Artificial General Intelligence (AGI)-teamet. Han har ekspertise i tekst-til-billede-modeller og er fokuseret på at bygge Amazon Titan Image Generator.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/fine-tune-your-amazon-titan-image-generator-g1-model-using-amazon-bedrock-model-customization/

