Asistenti konverzační umělé inteligence (AI) jsou navrženi tak, aby poskytovali přesné reakce v reálném čase prostřednictvím inteligentního směrování dotazů na nejvhodnější funkce umělé inteligence. S generativními službami AI AWS, jako je Amazonské podložímohou vývojáři vytvářet systémy, které odborně spravují a reagují na požadavky uživatelů. Amazon Bedrock je plně spravovaná služba, která nabízí výběr vysoce výkonných základních modelů (FM) od předních společností s umělou inteligencí, jako jsou AI21 Labs, Anthropic, Cohere, Meta, Stability AI a Amazon pomocí jediného rozhraní API spolu se širokou sadou funkce, které potřebujete k vytváření generativních aplikací AI se zabezpečením, soukromím a odpovědnou AI.
Tento příspěvek hodnotí dva primární přístupy k vývoji asistentů AI: používání řízených služeb, jako je např Agenti pro Amazon Bedrocka používání open source technologií, jako je LangChain. Zkoumáme výhody a výzvy každého z nich, takže si můžete vybrat nejvhodnější cestu pro vaše potřeby.
Co je asistent AI?
Asistent umělé inteligence je inteligentní systém, který rozumí dotazům v přirozeném jazyce a spolupracuje s různými nástroji, zdroji dat a rozhraními API za účelem provádění úkolů nebo získávání informací jménem uživatele. Efektivní AI asistenti mají následující klíčové schopnosti:
- Zpracování přirozeného jazyka (NLP) a tok konverzace
- Integrace znalostní báze a sémantické vyhledávání pro pochopení a získání relevantních informací na základě nuancí kontextu konverzace
- Spouštění úloh, jako jsou databázové dotazy a vlastní AWS Lambda funkce
- Zpracování specializovaných konverzací a požadavků uživatelů
Na příkladu demonstrujeme výhody asistentů umělé inteligence pomocí správy zařízení internetu věcí (IoT). V tomto případě může umělá inteligence pomoci technikům efektivně řídit strojní zařízení pomocí příkazů, které načítají data nebo automatizují úkoly, čímž zjednodušují operace ve výrobě.
Agenti pro Amazon Bedrock přistupují
Agenti pro Amazon Bedrock umožňuje vytvářet generativní aplikace umělé inteligence, které mohou spouštět vícestupňové úlohy napříč systémy a datovými zdroji společnosti. Nabízí následující klíčové funkce:
- Automatické rychlé vytváření z pokynů, podrobností API a informací o zdroji dat, což ušetří týdny rychlého inženýrského úsilí
- Retrieval Augmented Generation (RAG) pro bezpečné připojení agentů ke zdrojům dat společnosti a poskytování relevantních odpovědí
- Orchestrování a spouštění vícekrokových úloh rozdělením požadavků do logických sekvencí a voláním nezbytných API
- Viditelnost uvažování agenta prostřednictvím trasování řetězem myšlení (CoT), umožňující řešení problémů a řízení chování modelu
- Inženýrské schopnosti výzvy k úpravě automaticky generované šablony výzvy pro lepší kontrolu nad agenty
Můžete použít Agents for Amazon Bedrock a Znalostní báze pro Amazon Bedrock vytvářet a nasazovat asistenty umělé inteligence pro složité případy použití směrování. Poskytují strategickou výhodu pro vývojáře a organizace tím, že zjednodušují správu infrastruktury, vylepšují škálovatelnost, zlepšují zabezpečení a snižují nediferencované těžké zvedání. Umožňují také jednodušší kód aplikační vrstvy, protože logika směrování, vektorizace a paměť jsou plně spravovány.
Přehled řešení
Toto řešení představuje konverzačního asistenta AI přizpůsobeného pro správu a provoz zařízení IoT při použití Anthropic's Claude v2.1 na Amazon Bedrock. Základní funkce asistenta AI se řídí komplexní sadou pokynů, známých jako a systémová výzva, která vymezuje její schopnosti a oblasti odbornosti. Tento návod zajišťuje, že asistent umělé inteligence zvládne širokou škálu úkolů, od správy informací o zařízení až po spouštění provozních příkazů.
Vybavený těmito funkcemi, jak je podrobně popsáno v systémové výzvě, asistent AI sleduje strukturovaný pracovní postup, aby odpovídal na dotazy uživatelů. Následující obrázek poskytuje vizuální znázornění tohoto pracovního postupu ilustrující každý krok od počáteční interakce uživatele až po konečnou reakci.

Pracovní postup se skládá z následujících kroků:
- Proces začíná, když uživatel požádá asistenta, aby provedl úkol; například dotazem na maximální datové body pro konkrétní zařízení IoT
device_xxx. Tento textový vstup je zachycen a odeslán asistentovi AI. - Asistent AI interpretuje textový vstup uživatele. Využívá poskytnutou historii konverzace, akční skupiny a znalostní báze k pochopení kontextu a určení nezbytných úkolů.
- Po analýze a pochopení záměru uživatele asistent AI definuje úkoly. To je založeno na pokynech, které asistent interpretuje podle systémových pokynů a zadání uživatele.
- Úlohy jsou pak spuštěny prostřednictvím řady volání API. To se provádí pomocí Reagovat výzva, která rozděluje úlohu do řady kroků, které se zpracovávají postupně:
- Pro kontrolu metrik zařízení používáme
check-device-metricsakční skupina, která zahrnuje volání API funkcí Lambda, které se poté dotazují Amazonská Athéna pro požadovaná data. - Pro přímé akce zařízení, jako je spuštění, zastavení nebo restartování, používáme
action-on-deviceakční skupina, která vyvolá funkci Lambda. Tato funkce spouští proces, který odesílá příkazy do zařízení IoT. U tohoto příspěvku funkce Lambda odesílá upozornění pomocí Jednoduchá e-mailová služba Amazon (Amazon SES). - Používáme znalostní báze pro Amazon Bedrock k načítání historických dat uložených jako vložení v Služba Amazon OpenSearch vektorová databáze.
- Pro kontrolu metrik zařízení používáme
- Po dokončení úkolů vygeneruje Amazon Bedrock FM konečnou odpověď a předá ji zpět uživateli.
- Agenti pro Amazon Bedrock automaticky ukládají informace pomocí stavové relace k udržení stejné konverzace. Stav je vymazán po uplynutí nastavitelného časového limitu nečinnosti.
Technický přehled
Následující diagram ilustruje architekturu nasazení asistenta AI s Agents for Amazon Bedrock.
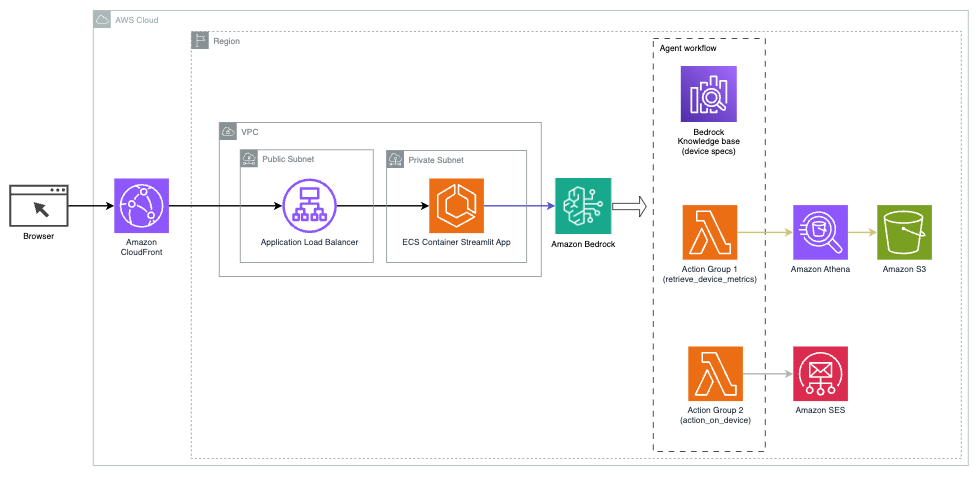
Skládá se z následujících klíčových součástí:
- Konverzační rozhraní – Konverzační rozhraní využívá Streamlit, open source knihovnu Pythonu, která zjednodušuje vytváření vlastních, vizuálně přitažlivých webových aplikací pro strojové učení (ML) a datovou vědu. Je hostován na Služba Amazon Elastic Container Service (Amazon ECS) s AWS Fargatea přistupuje se k němu pomocí nástroje pro vyrovnávání zatížení aplikací. Ke spuštění můžete použít Fargate s Amazon ECS kontejnery aniž byste museli spravovat servery, clustery nebo virtuální stroje.
- Agenti pro Amazon Bedrock – Agents for Amazon Bedrock dokončuje uživatelské dotazy prostřednictvím řady kroků uvažování a odpovídajících akcí na základě Výzva React:
- Znalostní báze pro Amazon Bedrock – Knowledge Bases for Amazon Bedrock poskytuje plně spravované HADR poskytnout asistentovi AI přístup k vašim datům. V našem případě použití jsme nahráli specifikace zařízení do souboru Služba Amazon Simple Storage Service (Amazon S3) kbelík. Slouží jako zdroj dat do znalostní báze.
- Akční skupiny – Jedná se o definovaná schémata API, která vyvolávají specifické funkce Lambda pro interakci se zařízeními IoT a dalšími službami AWS.
- Anthropic Claude v2.1 na Amazon Bedrock – Tento model interpretuje uživatelské dotazy a řídí tok úloh.
- Amazon Titan Embeddings – Tento model slouží jako model vkládání textu, který převádí text v přirozeném jazyce – od jednotlivých slov po složité dokumenty – na číselné vektory. To umožňuje funkce vektorového vyhledávání, což umožňuje systému sémanticky přiřazovat uživatelské dotazy k nejrelevantnějším záznamům znalostní báze pro efektivní vyhledávání.
Řešení je integrováno se službami AWS, jako je Lambda pro spouštění kódu v reakci na volání API, Athena pro dotazování datových sad, OpenSearch Service pro prohledávání znalostních bází a Amazon S3 pro ukládání. Tyto služby spolupracují, aby poskytovaly bezproblémovou správu operací zařízení IoT prostřednictvím příkazů přirozeného jazyka.
Výhody
Toto řešení nabízí následující výhody:
- Složitost implementace:
- Je potřeba méně řádků kódu, protože Agents for Amazon Bedrock abstrahuje velkou část základní složitosti a snižuje úsilí při vývoji
- Správa vektorových databází, jako je OpenSearch Service, je zjednodušená, protože znalostní báze pro Amazon Bedrock řeší vektorizaci a ukládání.
- Integrace s různými službami AWS je efektivnější díky předem definovaným skupinám akcí
- Vývojářské zkušenosti:
- Konzola Amazon Bedrock poskytuje uživatelsky přívětivé rozhraní pro rychlý vývoj, testování a analýzu hlavních příčin (RCA), což zlepšuje celkovou zkušenost vývojáře.
- Hbitost a flexibilita:
- Agents for Amazon Bedrock umožňuje bezproblémový upgrade na novější FM (jako je Claude 3.0), jakmile budou k dispozici, takže vaše řešení zůstane aktuální s nejnovějšími vylepšeními.
- Kvóty a omezení služeb jsou spravovány AWS, což snižuje režii infrastruktury monitorování a škálování
- Zabezpečení
- Amazon Bedrock je plně spravovaná služba, která dodržuje přísné standardy zabezpečení a dodržování předpisů AWS, což potenciálně zjednodušuje kontroly zabezpečení organizace
Přestože Agents for Amazon Bedrock nabízí efektivní a spravované řešení pro vytváření konverzačních aplikací AI, některé organizace mohou preferovat přístup s otevřeným zdrojovým kódem. V takových případech můžete použít frameworky jako LangChain, o kterých pojednáváme v další části.
Dynamický směrovací přístup LangChain
LangChain je open source framework, který zjednodušuje vytváření konverzační umělé inteligence tím, že umožňuje integraci velkých jazykových modelů (LLM) a schopností dynamického směrování. Pomocí jazyka LangChain Expression Language (LCEL) mohou vývojáři definovat Směrování, který umožňuje vytvářet nedeterministické řetězce, kde výstup předchozího kroku definuje krok další. Směrování pomáhá zajistit strukturu a konzistenci v interakcích s LLM.
Pro tento příspěvek používáme stejný příklad jako asistent AI pro správu zařízení IoT. Hlavní rozdíl je však v tom, že musíme zpracovávat systémové výzvy samostatně a s každým řetězcem zacházet jako se samostatnou entitou. Směrovací řetězec rozhoduje o cílovém řetězci na základě vstupu uživatele. Rozhodnutí je učiněno s podporou LLM předáním systémové výzvy, historie chatu a otázky uživatele.
Přehled řešení
Následující diagram znázorňuje pracovní postup řešení dynamického směrování.

Pracovní postup se skládá z následujících kroků:
- Uživatel položí otázku asistentovi AI. Například „Jaké jsou maximální metriky pro zařízení 1009?“
- LLM vyhodnocuje každou otázku spolu s historií chatu ze stejné relace, aby určil její povahu a do jaké oblasti spadá (jako je SQL, akce, vyhledávání nebo SME). LLM klasifikuje vstup a směrovací řetězec LCEL tento vstup přebírá.
- Řetězec směrovače vybere cílový řetězec na základě vstupu a LLM se zobrazí následující systémová výzva:
LLM vyhodnotí otázku uživatele spolu s historií chatu, aby určil povahu dotazu a do jaké oblasti spadá. LLM poté klasifikuje vstup a odešle odpověď JSON v následujícím formátu:
Řetězec směrovače používá tuto odpověď JSON k vyvolání odpovídajícího cílového řetězce. Existují čtyři cílové řetězce specifické pro daný předmět, z nichž každý má svou vlastní systémovou výzvu:
- Dotazy související s SQL jsou odesílány do cílového řetězce SQL pro interakce s databází. K sestavení můžete použít LCEL SQL řetězec.
- Otázky zaměřené na akci vyvolávají vlastní cílový řetězec Lambda pro provádění operací. Pomocí LCEL můžete definovat své vlastní vlastní funkce; v našem případě je to funkce pro spuštění předdefinované funkce Lambda pro odeslání e-mailu s analyzovaným ID zařízení. Příklad uživatelského vstupu může být „Vypnout zařízení 1009“.
- Dotazy zaměřené na vyhledávání pokračují na HADR cílový řetězec pro vyhledávání informací.
- Otázky týkající se malých a středních podniků směřují k cílovému řetězci malých a středních podniků/odborníků, aby získali specializované poznatky.
- Každý cílový řetězec přebírá vstup a spouští potřebné modely nebo funkce:
- Řetězec SQL používá Athena pro spouštění dotazů.
- Řetězec RAG používá službu OpenSearch Service pro sémantické vyhledávání.
- Vlastní řetězec Lambda spouští funkce Lambda pro akce.
- Řetězec malých a středních podniků/expertů poskytuje informace pomocí modelu Amazon Bedrock.
- Odpovědi z každého cílového řetězce jsou formulovány do koherentních přehledů LLM. Tyto statistiky jsou poté doručeny uživateli, čímž se dokončí cyklus dotazů.
- Uživatelské vstupy a odpovědi jsou uloženy v Amazon DynamoDB poskytnout kontext LLM pro aktuální relaci a z minulých interakcí. Doba trvání trvalých informací v DynamoDB je řízena aplikací.
Technický přehled
Následující diagram ilustruje architekturu řešení dynamického směrování LangChain.
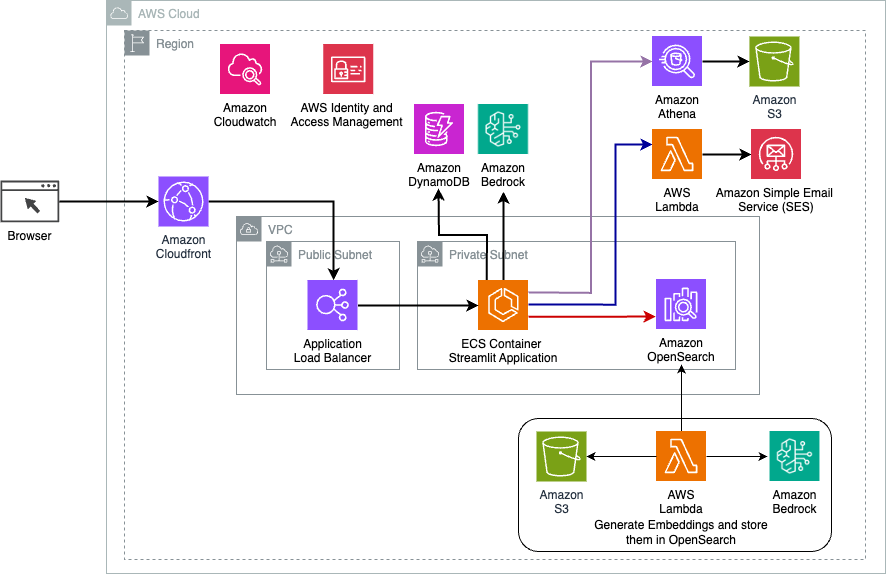
Webová aplikace je postavena na Streamlit hostovaném na Amazon ECS s Fargate a přistupuje se k ní pomocí nástroje Application Load Balancer. Jako náš LLM používáme Anthropic's Claude v2.1 na Amazon Bedrock. Webová aplikace spolupracuje s modelem pomocí knihoven LangChain. Spolupracuje také s řadou dalších služeb AWS, jako je OpenSearch Service, Athena a DynamoDB, aby uspokojil potřeby koncových uživatelů.
Výhody
Toto řešení nabízí následující výhody:
- Složitost implementace:
- Přestože vyžaduje více kódu a vlastního vývoje, LangChain poskytuje větší flexibilitu a kontrolu nad logikou směrování a integraci s různými komponentami.
- Správa vektorových databází, jako je OpenSearch Service, vyžaduje dodatečné nastavení a konfiguraci. Proces vektorizace je implementován v kódu.
- Integrace se službami AWS může vyžadovat více vlastního kódu a konfigurace.
- Vývojářské zkušenosti:
- Přístup LangChain založený na Pythonu a rozsáhlá dokumentace mohou být přitažlivé pro vývojáře, kteří již znají Python a open source nástroje.
- Rychlý vývoj a ladění může vyžadovat více manuálního úsilí ve srovnání s použitím konzole Amazon Bedrock.
- Hbitost a flexibilita:
- LangChain podporuje širokou škálu LLM, což vám umožňuje přepínat mezi různými modely nebo poskytovateli a podporuje flexibilitu.
- Open source povaha LangChain umožňuje komunitně řízená vylepšení a přizpůsobení.
- Zabezpečení
- Jako open source framework může LangChain vyžadovat přísnější bezpečnostní kontroly a prověřování v rámci organizací, což potenciálně zvyšuje režii.
Proč investovat do čističky vzduchu?
Asistenti konverzační umělé inteligence jsou transformačními nástroji pro zefektivnění operací a vylepšení uživatelských zkušeností. Tento příspěvek prozkoumal dva výkonné přístupy využívající služby AWS: spravované agenty pro Amazon Bedrock a flexibilní, open source dynamické směrování LangChain. Volba mezi těmito přístupy závisí na požadavcích vaší organizace, preferencích vývoje a požadované úrovni přizpůsobení. Bez ohledu na cestu, kterou se vydáte, vám AWS umožňuje vytvářet inteligentní asistenty umělé inteligence, kteří revolučním způsobem přinášejí obchodní a zákaznické interakce.
Najděte kód řešení a aktiva nasazení v našem Úložiště GitHub, kde můžete sledovat podrobné kroky pro každý přístup konverzační umělé inteligence.
Informace o autorech
 Ameer Hakme je AWS Solutions Architect se sídlem v Pensylvánii. Spolupracuje s nezávislými dodavateli softwaru (ISV) v regionu Severovýchod a pomáhá jim při navrhování a budování škálovatelných a moderních platforem na AWS Cloud. Ameer, odborník na AI/ML a generativní AI, pomáhá zákazníkům odhalit potenciál těchto špičkových technologií. Ve volném čase rád jezdí na motorce a tráví kvalitní čas se svou rodinou.
Ameer Hakme je AWS Solutions Architect se sídlem v Pensylvánii. Spolupracuje s nezávislými dodavateli softwaru (ISV) v regionu Severovýchod a pomáhá jim při navrhování a budování škálovatelných a moderních platforem na AWS Cloud. Ameer, odborník na AI/ML a generativní AI, pomáhá zákazníkům odhalit potenciál těchto špičkových technologií. Ve volném čase rád jezdí na motorce a tráví kvalitní čas se svou rodinou.
 Sharon Li je architektem řešení AI/ML ve společnosti Amazon Web Services se sídlem v Bostonu s vášní pro navrhování a vytváření aplikací generativní umělé inteligence na AWS. Spolupracuje se zákazníky na využití služeb AWS AI/ML pro inovativní řešení.
Sharon Li je architektem řešení AI/ML ve společnosti Amazon Web Services se sídlem v Bostonu s vášní pro navrhování a vytváření aplikací generativní umělé inteligence na AWS. Spolupracuje se zákazníky na využití služeb AWS AI/ML pro inovativní řešení.
 Kawsar Kamal je senior architekt řešení ve společnosti Amazon Web Services s více než 15 lety zkušeností v oblasti automatizace infrastruktury a zabezpečení. Pomáhá klientům navrhovat a vytvářet škálovatelná řešení DevSecOps a AI/ML v cloudu.
Kawsar Kamal je senior architekt řešení ve společnosti Amazon Web Services s více než 15 lety zkušeností v oblasti automatizace infrastruktury a zabezpečení. Pomáhá klientům navrhovat a vytvářet škálovatelná řešení DevSecOps a AI/ML v cloudu.
- SEO Powered Content & PR distribuce. Získejte posílení ještě dnes.
- PlatoData.Network Vertikální generativní Ai. Zmocnit se. Přístup zde.
- PlatoAiStream. Inteligence Web3. Znalosti rozšířené. Přístup zde.
- PlatoESG. Uhlík, CleanTech, Energie, Životní prostředí, Sluneční, Nakládání s odpady. Přístup zde.
- PlatoHealth. Inteligence biotechnologií a klinických studií. Přístup zde.
- Zdroj: https://aws.amazon.com/blogs/machine-learning/enhance-conversational-ai-with-advanced-routing-techniques-with-amazon-bedrock/

