স্ট্রাকচার্ড কোয়েরি ল্যাঙ্গুয়েজ (SQL) হল একটি জটিল ভাষা যার জন্য ডেটাবেস এবং মেটাডেটা বোঝার প্রয়োজন। আজ, জেনারেটিভ এআই SQL জ্ঞান ছাড়া মানুষ সক্ষম করতে পারেন. এই জেনারেটিভ এআই টাস্কটিকে টেক্সট-টু-এসকিউএল বলা হয়, যা ন্যাচারাল ল্যাঙ্গুয়েজ প্রসেসিং (এনএলপি) থেকে এসকিউএল কোয়েরি তৈরি করে এবং টেক্সটকে শব্দার্থগতভাবে সঠিক এসকিউএল-এ রূপান্তর করে। এই পোস্টের সমাধানটি প্রাকৃতিক ভাষা ব্যবহার করে আপনার ডেটার পথকে ছোট করে এন্টারপ্রাইজ বিশ্লেষণ ক্রিয়াকলাপকে পরবর্তী স্তরে নিয়ে আসা।
বৃহৎ ভাষা মডেলের (এলএলএম) উত্থানের সাথে সাথে, এনএলপি-ভিত্তিক এসকিউএল প্রজন্মের একটি উল্লেখযোগ্য রূপান্তর ঘটেছে। ব্যতিক্রমী কর্মক্ষমতা প্রদর্শন করে, এলএলএম এখন প্রাকৃতিক ভাষার বর্ণনা থেকে সঠিক SQL প্রশ্ন তৈরি করতে সক্ষম। তবে, চ্যালেঞ্জগুলি এখনও রয়ে গেছে। প্রথমত, মানুষের ভাষা সহজাতভাবে অস্পষ্ট এবং প্রসঙ্গ-নির্ভর, যেখানে SQL সুনির্দিষ্ট, গাণিতিক এবং কাঠামোগত। এই ব্যবধানের ফলে তৈরি হওয়া SQL-এ ব্যবহারকারীর চাহিদার ভুল রূপান্তর হতে পারে। দ্বিতীয়ত, আপনাকে প্রতিটি ডাটাবেসের জন্য পাঠ্য-টু-এসকিউএল বৈশিষ্ট্যগুলি তৈরি করতে হতে পারে কারণ ডেটা প্রায়শই একটি একক লক্ষ্যে সংরক্ষণ করা হয় না। NLP-ভিত্তিক SQL প্রজন্মের সাথে ব্যবহারকারীদের সক্ষম করার জন্য আপনাকে প্রতিটি ডাটাবেসের জন্য ক্ষমতা পুনরায় তৈরি করতে হতে পারে। তৃতীয়ত, ডেটা লেক এবং গুদামগুলির মতো কেন্দ্রীভূত বিশ্লেষণ সমাধানগুলির বৃহত্তর গ্রহণ সত্ত্বেও, বিভিন্ন টেবিলের নাম এবং অন্যান্য মেটাডেটা নিয়ে জটিলতা বৃদ্ধি পায় যা পছন্দসই উত্সগুলির জন্য SQL তৈরি করতে প্রয়োজনীয়। অতএব, ব্যাপক এবং উচ্চ-মানের মেটাডেটা সংগ্রহ করাও একটি চ্যালেঞ্জ। টেক্সট-টু-এসকিউএল সেরা অনুশীলন এবং ডিজাইন প্যাটার্ন সম্পর্কে আরও জানতে, দেখুন এন্টারপ্রাইজ ডেটা থেকে মান তৈরি করা: Text2SQL এবং জেনারেটিভ এআই-এর জন্য সেরা অনুশীলন.
আমাদের সমাধান ব্যবহার করে সেই চ্যালেঞ্জ মোকাবেলা করার লক্ষ্য আমাজন বেডরক এবং AWS বিশ্লেষণ সেবা। আমরা ব্যাবহার করি নৃতাত্ত্বিক ক্লদ v2.1 আমাদের এলএলএম হিসাবে অ্যামাজন বেডরকে। চ্যালেঞ্জ মোকাবেলা করার জন্য, আমাদের সমাধান প্রথমে তথ্য উৎসের মেটাডেটা অন্তর্ভুক্ত করে এডাব্লুএস আঠালো ডেটা ক্যাটালগ জেনারেট করা এসকিউএল কোয়েরির যথার্থতা বাড়াতে। ওয়ার্কফ্লোতে একটি চূড়ান্ত মূল্যায়ন এবং সংশোধন লুপ অন্তর্ভুক্ত থাকে, যদি কোনো SQL সমস্যা দ্বারা চিহ্নিত করা হয় অ্যামাজন অ্যাথেনা, যা এসকিউএল ইঞ্জিন হিসাবে ডাউনস্ট্রিম ব্যবহার করা হয়। এথেনা আমাদের একটি ভিড় ব্যবহার করার অনুমতি দেয় সমর্থিত শেষ পয়েন্ট এবং সংযোগকারী ডেটা উত্সের একটি বড় সেট কভার করতে।
আমরা সমাধানটি তৈরি করার ধাপগুলি অতিক্রম করার পরে, আমরা বিভিন্ন এসকিউএল জটিলতার মাত্রা সহ কিছু পরীক্ষার পরিস্থিতির ফলাফল উপস্থাপন করি। পরিশেষে, আমরা আলোচনা করি যে আপনার SQL কোয়েরিতে বিভিন্ন ডেটা উৎসকে একত্রিত করা কিভাবে সহজ।
সমাধান ওভারভিউ
আমাদের আর্কিটেকচারে তিনটি গুরুত্বপূর্ণ উপাদান রয়েছে: ডেটাবেস মেটাডেটা সহ পুনরুদ্ধার অগমেন্টেড জেনারেশন (RAG), একটি বহু-পদক্ষেপ স্ব-সংশোধন লুপ এবং আমাদের SQL ইঞ্জিন হিসাবে অ্যাথেনা।
অনুরোধটি সঠিক টেবিল এবং ডেটাসেটের সাথে সম্পর্কিত তা নিশ্চিত করার জন্য আমরা AWS Glue মেটাস্টোর থেকে টেবিলের বিবরণ এবং স্কিমা বিবরণ (কলাম) পুনরুদ্ধার করতে RAG পদ্ধতি ব্যবহার করি। আমাদের সমাধানে, আমরা প্রদর্শনের উদ্দেশ্যে AWS আঠালো ডেটা ক্যাটালগের সাথে একটি RAG ফ্রেমওয়ার্ক চালানোর জন্য পৃথক পদক্ষেপগুলি তৈরি করেছি। তবে, আপনিও ব্যবহার করতে পারেন জ্ঞান বেস অ্যামাজন বেডরকে দ্রুত RAG সমাধান তৈরি করতে।
মাল্টি-স্টেপ কম্পোনেন্ট LLM কে নির্ভুলতার জন্য জেনারেট করা SQL কোয়েরি সংশোধন করতে দেয়। এখানে, সিনট্যাক্স ত্রুটির জন্য তৈরি করা SQL পাঠানো হয়। আমরা জেনারেট করা SQL-এ আরও সঠিক এবং কার্যকর সংশোধনের জন্য LLM-এর জন্য আমাদের প্রম্পটকে সমৃদ্ধ করতে অ্যাথেনা ত্রুটি বার্তা ব্যবহার করি।
আপনি মাঝে মাঝে এথেনা থেকে আসা ত্রুটির বার্তাগুলি যেমন প্রতিক্রিয়া বিবেচনা করতে পারেন৷ একটি ত্রুটি সংশোধন পদক্ষেপের খরচ প্রভাব বিতরণ করা মানের তুলনায় নগণ্য। এমনকি আপনি আপনার LLM গুলিকে সূক্ষ্ম-টিউন করার জন্য তত্ত্বাবধানে চাঙ্গা শেখার উদাহরণ হিসাবে এই সংশোধনমূলক পদক্ষেপগুলি অন্তর্ভুক্ত করতে পারেন। যাইহোক, আমরা সরলতার উদ্দেশ্যে আমাদের পোস্টে এই প্রবাহটি কভার করিনি।
মনে রাখবেন যে সবসময় ভুল থাকার অন্তর্নিহিত ঝুঁকি থাকে, যা স্বাভাবিকভাবেই জেনারেটিভ এআই সমাধানের সাথে আসে। এমনকি যদি এথেনা ত্রুটি বার্তাগুলি এই ঝুঁকি হ্রাস করার জন্য অত্যন্ত কার্যকর হয়, আপনি আরও নিয়ন্ত্রণ এবং দৃষ্টিভঙ্গি যোগ করতে পারেন, যেমন মানব প্রতিক্রিয়া বা ফাইন-টিউনিংয়ের জন্য উদাহরণের প্রশ্ন, এই ধরনের ঝুঁকিগুলিকে আরও কমিয়ে আনতে।
এথেনা আমাদের শুধুমাত্র SQL কোয়েরি সংশোধন করার অনুমতি দেয় না, কিন্তু এটি আমাদের জন্য সামগ্রিক সমস্যাকেও সহজ করে কারণ এটি হাব হিসেবে কাজ করে, যেখানে স্পোকগুলি একাধিক ডেটা উৎস। অ্যাক্সেস ম্যানেজমেন্ট, এসকিউএল সিনট্যাক্স এবং আরও অনেক কিছু এথেনার মাধ্যমে পরিচালিত হয়।
নিম্নলিখিত চিত্রটি সমাধানের স্থাপত্যকে চিত্রিত করে।
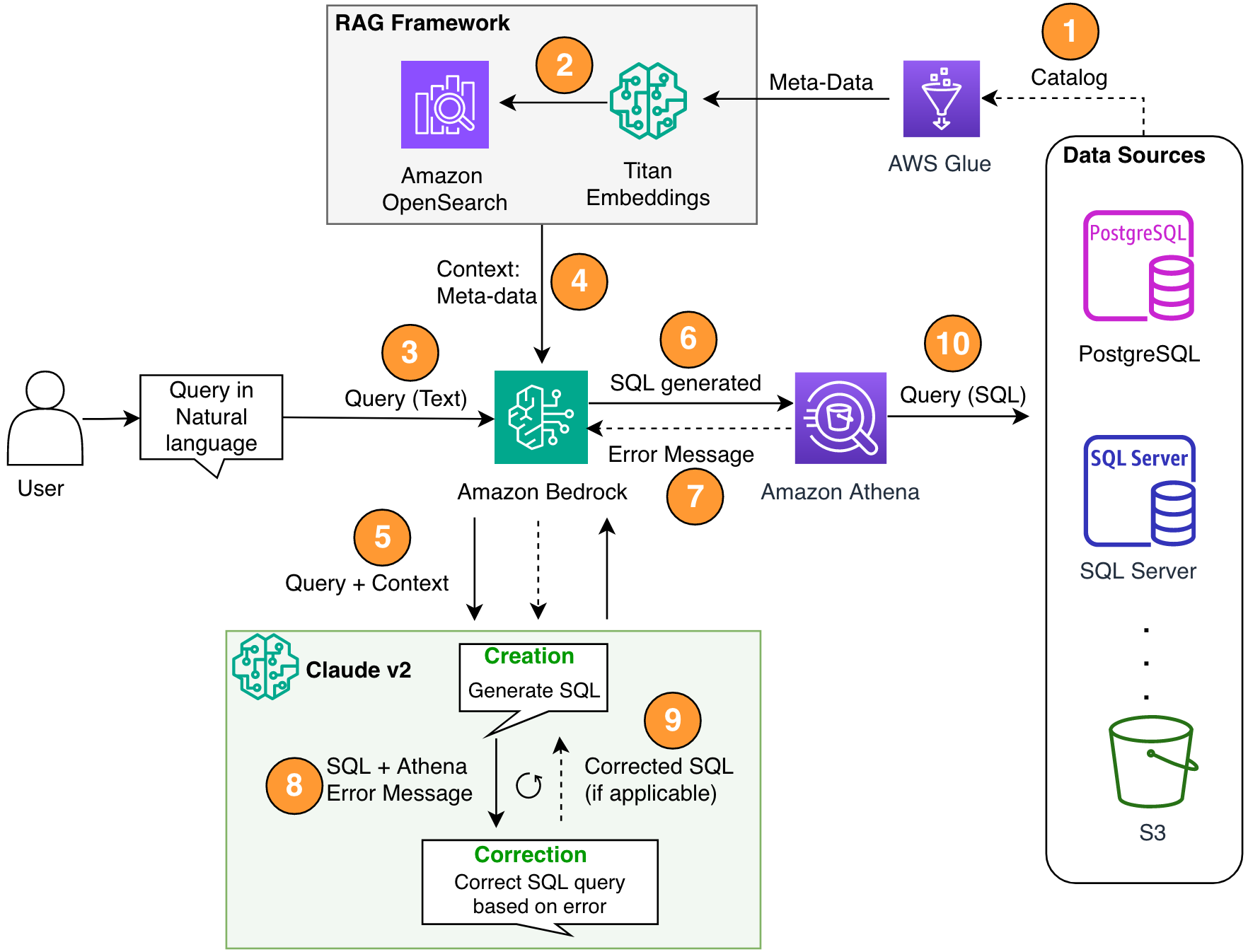
চিত্র 1. সমাধান আর্কিটেকচার এবং প্রক্রিয়া প্রবাহ.
প্রক্রিয়া প্রবাহ নিম্নলিখিত পদক্ষেপগুলি অন্তর্ভুক্ত করে:
- AWS আঠালো ডেটা ক্যাটালগ তৈরি করুন একটি AWS আঠালো ক্রলার ব্যবহার করে (বা একটি ভিন্ন পদ্ধতি)।
- উপরের অ্যামাজন বেডরে টাইটান-টেক্সট-এম্বেডিং মডেল, মেটাডেটাকে এম্বেডিং-এ রূপান্তর করুন এবং একটিতে সংরক্ষণ করুন অ্যামাজন ওপেনসার্চ সার্ভারহীন ভেক্টর স্টোর, যা আমাদের RAG কাঠামোতে আমাদের জ্ঞানের ভিত্তি হিসাবে কাজ করে।
এই পর্যায়ে, প্রক্রিয়াটি স্বাভাবিক ভাষায় প্রশ্ন গ্রহণের জন্য প্রস্তুত। ধাপ 7-9 একটি সংশোধন লুপ প্রতিনিধিত্ব করে, যদি প্রযোজ্য হয়।
- ব্যবহারকারী স্বাভাবিক ভাষায় তাদের প্রশ্ন প্রবেশ করে। চ্যাট UI প্রদান করতে আপনি যেকোনো ওয়েব অ্যাপ্লিকেশন ব্যবহার করতে পারেন। অতএব, আমরা আমাদের পোস্টে UI বিবরণ কভার করিনি।
- সমাধানটি একটি RAG কাঠামোর মাধ্যমে প্রয়োগ করে মিল অনুসন্ধান, যা ভেক্টর ডাটাবেস থেকে মেটাডেটা থেকে অতিরিক্ত প্রসঙ্গ যোগ করে। এই টেবিলটি সঠিক টেবিল, ডাটাবেস এবং বৈশিষ্ট্যগুলি খুঁজে বের করার জন্য ব্যবহার করা হয়।
- প্রশ্নটি প্রসঙ্গটির সাথে একত্রিত করা হয়েছে এবং এতে পাঠানো হয়েছে৷ নৃতাত্ত্বিক ক্লদ v2.1 অ্যামাজন বেডরকে।
- মডেলটি জেনারেট করা এসকিউএল কোয়েরি পায় এবং সিনট্যাক্স যাচাই করতে এথেনার সাথে সংযোগ করে।
- যদি এথেনা একটি ত্রুটি বার্তা প্রদান করে যা উল্লেখ করে যে সিনট্যাক্সটি ভুল, মডেলটি এথেনার প্রতিক্রিয়া থেকে ত্রুটি পাঠ্য ব্যবহার করে।
- নতুন প্রম্পট এথেনার প্রতিক্রিয়া যোগ করে।
- মডেলটি সংশোধন করা SQL তৈরি করে এবং প্রক্রিয়াটি চালিয়ে যায়। এই পুনরাবৃত্তি একাধিক বার সঞ্চালিত করা যেতে পারে.
- অবশেষে, আমরা Athena ব্যবহার করে SQL চালাই এবং আউটপুট তৈরি করি। এখানে, আউটপুট ব্যবহারকারীর কাছে উপস্থাপন করা হয়। স্থাপত্যের সরলতার জন্য, আমরা এই পদক্ষেপটি দেখাইনি।
পূর্বশর্ত
এই পোস্টের জন্য, আপনাকে নিম্নলিখিত পূর্বশর্তগুলি পূরণ করতে হবে:
- একটি আছে এডাব্লুএস অ্যাকাউন্ট.
- ইনস্টল করুন দ্য এডাব্লুএস কমান্ড লাইন ইন্টারফেস (AWS CLI)।
- সেট আপ করুন পাইথনের জন্য SDK (Boto3).
- AWS আঠালো ডেটা ক্যাটালগ তৈরি করুন একটি AWS আঠালো ক্রলার ব্যবহার করে (বা একটি ভিন্ন পদ্ধতি)।
- উপরের অ্যামাজন বেডরে টাইটান-টেক্সট-এম্বেডিং মডেল, মেটাডেটাকে এম্বেডিং-এ রূপান্তর করুন এবং একটি OpenSearch Serverless এ সংরক্ষণ করুন ভেক্টর স্টোর.
সমাধান বাস্তবায়ন করুন
আপনি নিম্নলিখিত ব্যবহার করতে পারেন জুপিটার নোটবুক, যা সমাধান তৈরি করতে এই বিভাগে দেওয়া সমস্ত কোড স্নিপেট অন্তর্ভুক্ত করে। আমরা ব্যবহার করার পরামর্শ দিই অ্যামাজন সেজমেকার স্টুডিও পাইথন 3 (ডেটা সায়েন্স) কার্নেলের সাথে একটি ml.t3.medium ইন্সট্যান্স সহ এই নোটবুকটি খুলতে। নির্দেশাবলীর জন্য, পড়ুন একটি মেশিন লার্নিং মডেল প্রশিক্ষণ. সমাধান সেট আপ করতে নিম্নলিখিত পদক্ষেপগুলি সম্পূর্ণ করুন:
- RAG ফ্রেমওয়ার্কের জন্য OpenSearch Service-এ জ্ঞানের ভিত্তি তৈরি করুন:
- প্রম্পট তৈরি করুন (
final_question) প্রাকৃতিক ভাষায় ব্যবহারকারীর ইনপুট একত্রিত করে (user_query), ভেক্টর স্টোর থেকে প্রাসঙ্গিক মেটাডেটা (vector_search_match), এবং আমাদের নির্দেশাবলী (details): - LLM (Claude v2) এর জন্য অ্যামাজন বেডরককে আহ্বান করুন এবং এটিকে SQL কোয়েরি তৈরি করতে অনুরোধ করুন। নিম্নলিখিত কোডে, এটি স্ব-সংশোধনের পদক্ষেপটি চিত্রিত করার জন্য একাধিক প্রচেষ্টা করে:x
- জেনারেট করা এসকিউএল ক্যোয়ারীতে যদি কোনো সমস্যা পাওয়া যায় (
{sqlgenerated}) এথেনা প্রতিক্রিয়া থেকে ({syntaxcheckmsg}), নতুন প্রম্পট (prompt) প্রতিক্রিয়ার উপর ভিত্তি করে তৈরি করা হয় এবং মডেলটি আবার নতুন SQL তৈরি করার চেষ্টা করে: - এসকিউএল তৈরি হওয়ার পরে, অ্যাথেনা ক্লায়েন্টকে আউটপুট চালানো এবং জেনারেট করার জন্য আহ্বান জানানো হয়:
সমাধান পরীক্ষা করুন
এই বিভাগে, আমরা SQL প্রশ্নের বিভিন্ন জটিলতা স্তর পরীক্ষা করার জন্য বিভিন্ন উদাহরণের সাথে আমাদের সমাধান চালাই।
আমাদের পাঠ্য থেকে এসকিউএল পরীক্ষা করতে, আমরা দুটি ব্যবহার করি IMDB থেকে উপলভ্য ডেটাসেট। IMDb ডেটার উপসেট ব্যক্তিগত এবং অ-বাণিজ্যিক ব্যবহারের জন্য উপলব্ধ। আপনি ডেটাসেটগুলি ডাউনলোড করতে পারেন এবং সেগুলি সংরক্ষণ করতে পারেন৷ আমাজন সিম্পল স্টোরেজ সার্ভিস (Amazon S3)। AWS গ্লুতে টেবিল তৈরি করতে আপনি নিম্নলিখিত স্পার্ক SQL স্নিপেট ব্যবহার করতে পারেন। এই উদাহরণের জন্য, আমরা ব্যবহার করি title_ratings এবং title:
Amazon S3-এ ডেটা সঞ্চয় করুন এবং AWS Glue-এ মেটাডেটা
এই পরিস্থিতিতে, আমাদের ডেটাসেট একটি S3 বালতিতে সংরক্ষণ করা হয়। এথেনার একটি S3 সংযোগকারী রয়েছে যা আপনাকে আমাজন S3 একটি ডেটা উৎস হিসাবে ব্যবহার করতে দেয় যা জিজ্ঞাসা করা যেতে পারে.
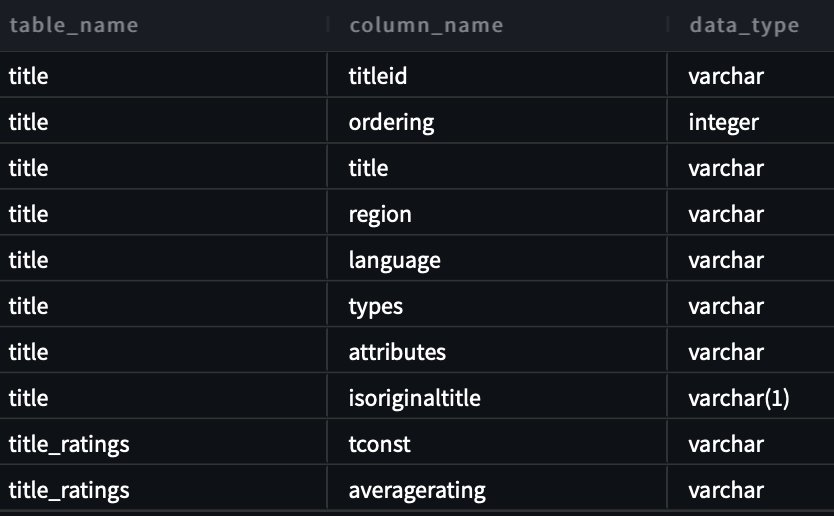
আমাদের প্রথম প্রশ্নের জন্য, আমরা ইনপুট প্রদান করি "আমি এতে নতুন। আপনি কি আমাকে imdb স্কিমার সমস্ত টেবিল এবং কলাম দেখতে সাহায্য করতে পারেন?"
নিম্নলিখিতটি জেনারেট করা প্রশ্ন:
নিম্নলিখিত স্ক্রিনশট এবং কোড আমাদের আউটপুট দেখায়।
আমাদের দ্বিতীয় প্রশ্নের জন্য, আমরা জিজ্ঞাসা করি "আমাকে মার্কিন অঞ্চলের সমস্ত শিরোনাম এবং বিবরণ দেখান যার রেটিং 9.5 এর বেশি।"
নিম্নলিখিত আমাদের জেনারেট করা প্রশ্ন:
প্রতিক্রিয়া নিম্নরূপ.

আমাদের তৃতীয় প্রশ্নের জন্য, আমরা লিখি "দারুণ প্রতিক্রিয়া! এখন আমাকে 7.5-এর বেশি রেটিং সহ সমস্ত মূল ধরণের শিরোনাম দেখান এবং মার্কিন অঞ্চলে নয়।"
নিম্নলিখিত প্রশ্ন তৈরি করা হয়:
আমরা নিম্নলিখিত ফলাফল পেতে.

স্ব-সংশোধিত এসকিউএল তৈরি করুন
এই দৃশ্যটি একটি SQL কোয়েরি অনুকরণ করে যাতে সিনট্যাক্স সমস্যা রয়েছে। এখানে, অ্যাথেনার প্রতিক্রিয়ার উপর ভিত্তি করে তৈরি করা SQL স্ব-সংশোধিত হবে। নিম্নলিখিত প্রতিক্রিয়া, এথেনা একটি দিয়েছেন COLUMN_NOT_FOUND ত্রুটি এবং উল্লেখ করা হয়েছে যে table_description সমাধান করা যাবে না:
অন্যান্য ডেটা উত্সের সাথে সমাধান ব্যবহার করা
অন্যান্য ডেটা উত্সের সাথে সমাধানটি ব্যবহার করতে, অ্যাথেনা আপনার জন্য কাজ পরিচালনা করে। এটি করার জন্য, এথেনা ব্যবহার করে তথ্য উৎস সংযোগকারী যে সঙ্গে ব্যবহার করা যেতে পারে ফেডারেটেড প্রশ্ন. আপনি এথেনা কোয়েরি ইঞ্জিনের এক্সটেনশন হিসাবে একটি সংযোগকারীকে বিবেচনা করতে পারেন। প্রাক-নির্মিত এথেনা ডেটা উত্স সংযোগকারী যেমন ডেটা উত্সের জন্য বিদ্যমান অ্যামাজন ক্লাউডওয়াচ লগস, আমাজন ডায়নামোডিবি, আমাজন ডকুমেন্টডিবি (মঙ্গোডিবি সামঞ্জস্য সহ), এবং অ্যামাজন রিলেশনাল ডাটাবেস পরিষেবা (Amazon RDS), এবং Apache 2.0 লাইসেন্সের অধীনে JDBC- অনুগত রিলেশনাল ডেটা উৎস যেমন MySQL, এবং PostgreSQL। আপনি যেকোনো ডেটা উৎসের সাথে একটি সংযোগ সেট আপ করার পরে, আপনি সমাধানটি প্রসারিত করতে পূর্ববর্তী কোড বেস ব্যবহার করতে পারেন। আরো তথ্যের জন্য, পড়ুন Amazon Athena-এর নতুন ফেডারেটেড ক্যোয়ারী সহ যেকোন ডেটা সোর্স কোয়েরি করুন.
পরিষ্কার কর
সম্পদ পরিষ্কার করতে, আপনি শুরু করতে পারেন আপনার S3 বালতি পরিষ্কার করা হচ্ছে যেখানে ডেটা থাকে। আপনার অ্যাপ্লিকেশান অ্যামাজন বেডরককে আমন্ত্রণ না করলে, এটির কোনো খরচ হবে না। অবকাঠামো পরিচালনার সর্বোত্তম অনুশীলনের জন্য, আমরা এই প্রদর্শনীতে তৈরি সংস্থানগুলি মুছে ফেলার পরামর্শ দিই।
উপসংহার
এই পোস্টে, আমরা একটি সমাধান উপস্থাপন করেছি যা আপনাকে অ্যাথেনা দ্বারা সক্ষম বিভিন্ন সংস্থান সহ জটিল SQL কোয়েরি তৈরি করতে NLP ব্যবহার করতে দেয়। আমরা ডাউনস্ট্রিম প্রসেস থেকে ত্রুটি বার্তার উপর ভিত্তি করে বহু-পদক্ষেপ মূল্যায়ন লুপের মাধ্যমে জেনারেট করা SQL কোয়েরির যথার্থতাও বাড়িয়েছি। উপরন্তু, আমরা AWS Glue Data Catalog-এ মেটাডেটা ব্যবহার করেছি RAG ফ্রেমওয়ার্কের মাধ্যমে প্রশ্নে জিজ্ঞাসা করা টেবিলের নাম বিবেচনা করতে। তারপরে আমরা বিভিন্ন প্রশ্নের জটিলতার স্তর সহ বিভিন্ন বাস্তবসম্মত পরিস্থিতিতে সমাধানটি পরীক্ষা করেছি। অবশেষে, আমরা আলোচনা করেছি কিভাবে এথেনা দ্বারা সমর্থিত বিভিন্ন ডেটা উৎসে এই সমাধানটি প্রয়োগ করা যায়।
অ্যামাজন বেডরক এই সমাধানের কেন্দ্রে রয়েছে। অ্যামাজন বেডরক আপনাকে অনেক জেনারেটিভ এআই অ্যাপ্লিকেশন তৈরি করতে সাহায্য করতে পারে। অ্যামাজন বেডরকের সাথে শুরু করার জন্য, আমরা নিম্নলিখিতটি দ্রুত শুরু করার পরামর্শ দিই গিটহুব রেপো এবং জেনারেটিভ এআই অ্যাপ্লিকেশন তৈরির সাথে নিজেকে পরিচিত করা। আপনিও চেষ্টা করে দেখতে পারেন জ্ঞান বেস অ্যামাজন বেডরকে এই ধরনের RAG সমাধানগুলি দ্রুত তৈরি করতে।
লেখক সম্পর্কে
 সঞ্জীব পান্ডা অ্যামাজনে একজন ডেটা এবং এমএল ইঞ্জিনিয়ার। AI/ML, ডেটা সায়েন্স এবং বিগ ডেটার পটভূমিতে, সঞ্জীব উদ্ভাবনী ডেটা এবং এমএল সমাধানগুলি ডিজাইন এবং বিকাশ করে যা জটিল প্রযুক্তিগত চ্যালেঞ্জগুলি সমাধান করে এবং বিশ্বব্যাপী 3P বিক্রেতাদের Amazon-এ তাদের ব্যবসা পরিচালনা করার জন্য কৌশলগত লক্ষ্য অর্জন করে। অ্যামাজনে ডেটা এবং এমএল ইঞ্জিনিয়ার হিসাবে তার কাজের বাইরে, সঞ্জীব পান্ডা একজন উত্সাহী ভোজনরসিক এবং সংগীত উত্সাহী।
সঞ্জীব পান্ডা অ্যামাজনে একজন ডেটা এবং এমএল ইঞ্জিনিয়ার। AI/ML, ডেটা সায়েন্স এবং বিগ ডেটার পটভূমিতে, সঞ্জীব উদ্ভাবনী ডেটা এবং এমএল সমাধানগুলি ডিজাইন এবং বিকাশ করে যা জটিল প্রযুক্তিগত চ্যালেঞ্জগুলি সমাধান করে এবং বিশ্বব্যাপী 3P বিক্রেতাদের Amazon-এ তাদের ব্যবসা পরিচালনা করার জন্য কৌশলগত লক্ষ্য অর্জন করে। অ্যামাজনে ডেটা এবং এমএল ইঞ্জিনিয়ার হিসাবে তার কাজের বাইরে, সঞ্জীব পান্ডা একজন উত্সাহী ভোজনরসিক এবং সংগীত উত্সাহী।
 বুরাক গোজলুকলু বোস্টন, এমএ-তে অবস্থিত একজন প্রিন্সিপাল এআই/এমএল স্পেশালিস্ট সলিউশন আর্কিটেক্ট। তিনি কৌশলগত গ্রাহকদের তাদের ব্যবসায়িক লক্ষ্য অর্জনের জন্য AWS প্রযুক্তি এবং বিশেষ করে জেনারেটিভ এআই সমাধান গ্রহণ করতে সহায়তা করেন। বুরাকের METU থেকে অ্যারোস্পেস ইঞ্জিনিয়ারিংয়ে পিএইচডি, সিস্টেম ইঞ্জিনিয়ারিংয়ে এমএস এবং কেমব্রিজে এমআইটি থেকে সিস্টেম ডাইনামিক্সে পোস্ট-ডক, এমএ। বুরাক এখনও এমআইটিতে একটি গবেষণা অনুমোদিত। বুরাক যোগব্যায়াম এবং ধ্যান সম্পর্কে উত্সাহী।
বুরাক গোজলুকলু বোস্টন, এমএ-তে অবস্থিত একজন প্রিন্সিপাল এআই/এমএল স্পেশালিস্ট সলিউশন আর্কিটেক্ট। তিনি কৌশলগত গ্রাহকদের তাদের ব্যবসায়িক লক্ষ্য অর্জনের জন্য AWS প্রযুক্তি এবং বিশেষ করে জেনারেটিভ এআই সমাধান গ্রহণ করতে সহায়তা করেন। বুরাকের METU থেকে অ্যারোস্পেস ইঞ্জিনিয়ারিংয়ে পিএইচডি, সিস্টেম ইঞ্জিনিয়ারিংয়ে এমএস এবং কেমব্রিজে এমআইটি থেকে সিস্টেম ডাইনামিক্সে পোস্ট-ডক, এমএ। বুরাক এখনও এমআইটিতে একটি গবেষণা অনুমোদিত। বুরাক যোগব্যায়াম এবং ধ্যান সম্পর্কে উত্সাহী।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- PlatoData.Network উল্লম্ব জেনারেটিভ Ai. নিজেকে ক্ষমতায়িত করুন। এখানে প্রবেশ করুন.
- প্লেটোএআইস্ট্রিম। Web3 ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- প্লেটোইএসজি। কার্বন, ক্লিনটেক, শক্তি, পরিবেশ সৌর, বর্জ্য ব্যবস্থাপনা. এখানে প্রবেশ করুন.
- প্লেটো হেলথ। বায়োটেক এবং ক্লিনিক্যাল ট্রায়াল ইন্টেলিজেন্স। এখানে প্রবেশ করুন.
- উত্স: https://aws.amazon.com/blogs/machine-learning/build-a-robust-text-to-sql-solution-generating-complex-queries-self-correcting-and-querying-diverse-data-sources/

