এর মাঝখানে, ল্যাংচেইন এটি এমন একটি উদ্ভাবনী কাঠামো যা অ্যাপ্লিকেশন তৈরি করার জন্য তৈরি করা হয়েছে যা ভাষার মডেলের ক্ষমতাকে কাজে লাগায়। এটি একটি টুলকিট যা প্রসঙ্গ-সচেতন এবং পরিশীলিত যুক্তিতে সক্ষম এমন অ্যাপ্লিকেশন তৈরি করার জন্য ডেভেলপারদের জন্য ডিজাইন করা হয়েছে।
এর অর্থ হল ল্যাংচেইন অ্যাপ্লিকেশনগুলি প্রম্পট নির্দেশাবলী বা বিষয়বস্তু গ্রাউন্ডিং প্রতিক্রিয়াগুলির মতো প্রসঙ্গ বুঝতে পারে এবং কীভাবে প্রতিক্রিয়া জানাতে হবে বা কী পদক্ষেপ নিতে হবে তা সিদ্ধান্ত নেওয়ার মতো জটিল যুক্তিযুক্ত কাজের জন্য ভাষা মডেলগুলি ব্যবহার করতে পারে। LangChain বুদ্ধিমান অ্যাপ্লিকেশন বিকাশের জন্য একীভূত পদ্ধতির প্রতিনিধিত্ব করে, এর বিভিন্ন উপাদানের সাথে ধারণা থেকে বাস্তবায়নের যাত্রাকে সহজ করে।
ল্যাংচেইন বোঝা
ল্যাংচেইন কেবল একটি কাঠামোর চেয়ে অনেক বেশি; এটি একটি পূর্ণাঙ্গ ইকোসিস্টেম যা বিভিন্ন অবিচ্ছেদ্য অংশ নিয়ে গঠিত।
- প্রথমত, পাইথন এবং জাভাস্ক্রিপ্ট উভয় ক্ষেত্রেই ল্যাংচেইন লাইব্রেরি রয়েছে। এই লাইব্রেরিগুলি হল LangChain-এর মেরুদণ্ড, বিভিন্ন উপাদানের জন্য ইন্টারফেস এবং ইন্টিগ্রেশন প্রদান করে। তারা অবিলম্বে ব্যবহারের জন্য রেডিমেড বাস্তবায়নের সাথে এই উপাদানগুলিকে সমন্বিত চেইন এবং এজেন্টগুলিতে একত্রিত করার জন্য একটি মৌলিক রানটাইম প্রদান করে।
- এর পরে, আমাদের কাছে ল্যাংচেইন টেমপ্লেট রয়েছে। এগুলি বিস্তৃত কাজের জন্য উপযোগী স্থাপনযোগ্য রেফারেন্স আর্কিটেকচারের একটি সংগ্রহ। আপনি একটি চ্যাটবট বা একটি জটিল বিশ্লেষণাত্মক সরঞ্জাম তৈরি করছেন না কেন, এই টেমপ্লেটগুলি একটি কঠিন সূচনা পয়েন্ট অফার করে৷
- LangServe REST API হিসাবে LangChain চেইন স্থাপনের জন্য একটি বহুমুখী লাইব্রেরি হিসাবে পদক্ষেপ নেয়। আপনার LangChain প্রকল্পগুলিকে অ্যাক্সেসযোগ্য এবং মাপযোগ্য ওয়েব পরিষেবাগুলিতে পরিণত করার জন্য এই সরঞ্জামটি অপরিহার্য।
- অবশেষে, ল্যাংস্মিথ একটি বিকাশকারী প্ল্যাটফর্ম হিসাবে কাজ করে। এটি ডিবাগ, পরীক্ষা, মূল্যায়ন এবং যেকোন LLM ফ্রেমওয়ার্কে নির্মিত চেইনগুলি নিরীক্ষণ করার জন্য ডিজাইন করা হয়েছে৷ LangChain এর সাথে নিরবচ্ছিন্ন একীকরণ এটিকে তাদের অ্যাপ্লিকেশনগুলিকে পরিমার্জিত এবং নিখুঁত করার লক্ষ্যে বিকাশকারীদের জন্য একটি অপরিহার্য হাতিয়ার করে তোলে।
একসাথে, এই উপাদানগুলি আপনাকে সহজে অ্যাপ্লিকেশনগুলি বিকাশ, উত্পাদন এবং স্থাপন করার ক্ষমতা দেয়৷ LangChain এর সাথে, আপনি লাইব্রেরি ব্যবহার করে আপনার অ্যাপ্লিকেশনগুলি লিখে, নির্দেশনার জন্য টেমপ্লেট উল্লেখ করে শুরু করেন। ল্যাংস্মিথ তারপরে আপনার চেইনগুলি পরিদর্শন, পরীক্ষা এবং নিরীক্ষণে আপনাকে সহায়তা করে, নিশ্চিত করে যে আপনার অ্যাপ্লিকেশনগুলি ক্রমাগত উন্নতি করছে এবং স্থাপনার জন্য প্রস্তুত। অবশেষে, LangServe-এর সাহায্যে, আপনি সহজেই যেকোন চেইনকে একটি এপিআইতে রূপান্তর করতে পারেন, স্থাপনাকে একটি হাওয়ায় পরিণত করে।
পরবর্তী বিভাগে, আমরা কীভাবে LangChain সেট আপ করতে হয় এবং বুদ্ধিমান, ভাষা মডেল-চালিত অ্যাপ্লিকেশন তৈরিতে আপনার যাত্রা শুরু করতে হয় সে সম্পর্কে গভীরভাবে আলোচনা করব।
আমাদের AI-চালিত ওয়ার্কফ্লো নির্মাতার সাথে ম্যানুয়াল কাজ এবং ওয়ার্কফ্লোগুলি স্বয়ংক্রিয় করুন, আপনার এবং আপনার দলের জন্য Nanonets দ্বারা ডিজাইন করা হয়েছে৷
ইনস্টলেশন এবং সেটআপ
আপনি কি ল্যাংচেইনের জগতে ডুব দিতে প্রস্তুত? এটি সেট আপ করা সহজ, এবং এই নির্দেশিকা আপনাকে ধাপে ধাপে প্রক্রিয়ার মধ্য দিয়ে নিয়ে যাবে।
আপনার LangChain যাত্রার প্রথম ধাপ হল এটি ইনস্টল করা। আপনি পিপ বা কনডা ব্যবহার করে সহজেই এটি করতে পারেন। আপনার টার্মিনালে নিম্নলিখিত কমান্ডটি চালান:
pip install langchain
যারা লেটেস্ট ফিচার পছন্দ করেন এবং একটু বেশি অ্যাডভেঞ্চারে স্বাচ্ছন্দ্য বোধ করেন, আপনি সরাসরি উৎস থেকে ল্যাংচেইন ইনস্টল করতে পারেন। সংগ্রহস্থল ক্লোন করুন এবং নেভিগেট করুন langchain/libs/langchain ডিরেক্টরি তারপর, চালান:
pip install -e .
পরীক্ষামূলক বৈশিষ্ট্যগুলির জন্য, ইনস্টল করার কথা বিবেচনা করুন langchain-experimental. এটি একটি প্যাকেজ যা অত্যাধুনিক কোড ধারণ করে এবং এটি গবেষণা এবং পরীক্ষামূলক উদ্দেশ্যে তৈরি। এটি ব্যবহার করে ইনস্টল করুন:
pip install langchain-experimental
LangChain CLI হল LangChain টেমপ্লেট এবং LangServe প্রকল্পগুলির সাথে কাজ করার জন্য একটি সহজ টুল। LangChain CLI ইনস্টল করতে, ব্যবহার করুন:
pip install langchain-cli
আপনার LangChain চেইনগুলিকে একটি REST API হিসাবে স্থাপন করার জন্য LangServe অপরিহার্য৷ এটি LangChain CLI এর পাশাপাশি ইনস্টল করা হয়।
LangChain-এর প্রায়শই মডেল প্রদানকারী, ডেটা স্টোর, API ইত্যাদির সাথে একীকরণের প্রয়োজন হয়। এই উদাহরণের জন্য, আমরা OpenAI-এর মডেল API ব্যবহার করব। ব্যবহার করে OpenAI পাইথন প্যাকেজ ইনস্টল করুন:
pip install openai
API অ্যাক্সেস করতে, আপনার OpenAI API কী একটি পরিবেশ পরিবর্তনশীল হিসাবে সেট করুন:
export OPENAI_API_KEY="your_api_key"
বিকল্পভাবে, আপনার পাইথন পরিবেশে সরাসরি কীটি পাস করুন:
import os
os.environ['OPENAI_API_KEY'] = 'your_api_key'
ল্যাংচেইন মডিউলগুলির মাধ্যমে ভাষা মডেল অ্যাপ্লিকেশন তৈরির অনুমতি দেয়। এই মডিউলগুলি হয় একা দাঁড়াতে পারে বা জটিল ব্যবহারের ক্ষেত্রে তৈরি করা যেতে পারে। এই মডিউলগুলো হল-
- মডেল I/O: বিভিন্ন ভাষার মডেলের সাথে মিথস্ক্রিয়া সহজ করে, তাদের ইনপুট এবং আউটপুটগুলি দক্ষতার সাথে পরিচালনা করে।
- উদ্ধার: অ্যাপ্লিকেশান-নির্দিষ্ট ডেটা অ্যাক্সেস এবং ইন্টারঅ্যাকশন সক্ষম করে, গতিশীল ডেটা ব্যবহারের জন্য গুরুত্বপূর্ণ৷
- এজেন্ট: উচ্চ-স্তরের নির্দেশের উপর ভিত্তি করে উপযুক্ত সরঞ্জাম নির্বাচন করার জন্য অ্যাপ্লিকেশনগুলিকে ক্ষমতায়ন করুন, সিদ্ধান্ত গ্রহণের ক্ষমতা বৃদ্ধি করুন৷
- চেইন: পূর্ব-সংজ্ঞায়িত, পুনঃব্যবহারযোগ্য রচনাগুলি অফার করে যা অ্যাপ্লিকেশন বিকাশের জন্য বিল্ডিং ব্লক হিসাবে কাজ করে৷
- স্মৃতি: প্রসঙ্গ-সচেতন ইন্টারঅ্যাকশনের জন্য প্রয়োজনীয় একাধিক চেইন এক্সিকিউশন জুড়ে অ্যাপ্লিকেশন অবস্থা বজায় রাখে।
প্রতিটি মডিউল নির্দিষ্ট উন্নয়নের চাহিদাকে লক্ষ্য করে, ল্যাংচেইনকে উন্নত ভাষার মডেল অ্যাপ্লিকেশন তৈরি করার জন্য একটি ব্যাপক টুলকিট তৈরি করে।
উপরের উপাদানগুলির পাশাপাশি, আমাদেরও রয়েছে ল্যাংচেইন এক্সপ্রেশন ল্যাঙ্গুয়েজ (এলসিইএল), যা সহজেই একসাথে মডিউল রচনা করার একটি ঘোষণামূলক উপায় এবং এটি একটি সর্বজনীন রানযোগ্য ইন্টারফেস ব্যবহার করে উপাদানগুলির চেইনিং সক্ষম করে।
LCEL দেখতে এরকম কিছু -
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import BaseOutputParser # Example chain
chain = ChatPromptTemplate() | ChatOpenAI() | CustomOutputParser()
এখন যেহেতু আমরা মৌলিক বিষয়গুলি কভার করেছি, আমরা চালিয়ে যাব:
- প্রতিটি ল্যাংচেইন মডিউলে বিস্তারিতভাবে গভীরভাবে খনন করুন।
- ল্যাংচেইন এক্সপ্রেশন ভাষা কীভাবে ব্যবহার করবেন তা শিখুন।
- সাধারণ ব্যবহারের ক্ষেত্রে অন্বেষণ করুন এবং তাদের বাস্তবায়ন করুন।
- LangServe এর সাথে একটি এন্ড-টু-এন্ড অ্যাপ্লিকেশন স্থাপন করুন।
- ডিবাগিং, পরীক্ষা এবং পর্যবেক্ষণের জন্য ল্যাংস্মিথ দেখুন।
চল শুরু করি!
মডিউল I: মডেল I/O
LangChain-এ, যেকোনো অ্যাপ্লিকেশনের মূল উপাদান ভাষা মডেলের চারপাশে ঘোরে। এই মডিউলটি যেকোন ভাষার মডেলের সাথে কার্যকরভাবে ইন্টারফেস করার জন্য প্রয়োজনীয় বিল্ডিং ব্লকগুলি প্রদান করে, বিরামহীন একীকরণ এবং যোগাযোগ নিশ্চিত করে।
মডেল I/O এর মূল উপাদান
- এলএলএম এবং চ্যাট মডেল (অন্তর্পরিবর্তনযোগ্যভাবে ব্যবহৃত):
- এলএলএম:
- সংজ্ঞা: বিশুদ্ধ পাঠ সমাপ্তি মডেল.
- ইনপুট আউটপুট: ইনপুট হিসাবে একটি পাঠ্য স্ট্রিং নিন এবং আউটপুট হিসাবে একটি পাঠ্য স্ট্রিং ফেরত দিন।
- চ্যাট মডেল
- এলএলএম:
- সংজ্ঞা: যে মডেলগুলি একটি ভাষা মডেলকে ভিত্তি হিসাবে ব্যবহার করে কিন্তু ইনপুট এবং আউটপুট বিন্যাসে ভিন্ন।
- ইনপুট আউটপুট: ইনপুট হিসাবে চ্যাট বার্তাগুলির একটি তালিকা গ্রহণ করুন এবং একটি চ্যাট বার্তা ফেরত দিন৷
- অনুরোধ জানানো: মডেল ইনপুট টেমপ্লেটাইজ করুন, গতিশীলভাবে নির্বাচন করুন এবং পরিচালনা করুন। নমনীয় এবং প্রসঙ্গ-নির্দিষ্ট প্রম্পট তৈরি করার অনুমতি দেয় যা ভাষা মডেলের প্রতিক্রিয়া নির্দেশ করে।
- আউটপুট পার্সার্স: মডেল আউটপুট থেকে তথ্য বের করুন এবং ফর্ম্যাট করুন। ভাষা মডেলের কাঁচা আউটপুটকে স্ট্রাকচার্ড ডেটা বা অ্যাপ্লিকেশনের জন্য প্রয়োজনীয় নির্দিষ্ট বিন্যাসে রূপান্তর করার জন্য দরকারী।
এলএলএম
OpenAI, Cohere, এবং Hugging Face-এর মতো LangChain-এর লার্জ ল্যাঙ্গুয়েজ মডেলের (LLM) সাথে একীকরণ হল এর কার্যকারিতার একটি মৌলিক দিক। LangChain নিজেই LLM হোস্ট করে না কিন্তু বিভিন্ন LLM-এর সাথে ইন্টারঅ্যাক্ট করার জন্য একটি অভিন্ন ইন্টারফেস অফার করে।
এই বিভাগটি ল্যাংচেইনে OpenAI LLM র্যাপার ব্যবহার করার একটি ওভারভিউ প্রদান করে, অন্যান্য LLM প্রকারের ক্ষেত্রেও প্রযোজ্য। আমরা ইতিমধ্যেই "শুরু করা" বিভাগে এটি ইনস্টল করেছি। আসুন এলএলএম শুরু করি।
from langchain.llms import OpenAI
llm = OpenAI()
- এলএলএম বাস্তবায়ন করে চলমান ইন্টারফেস, মৌলিক বিল্ডিং ব্লক ল্যাংচেইন এক্সপ্রেশন ল্যাঙ্গুয়েজ (এলসিইএল). এর মানে তারা সমর্থন করে
invoke,ainvoke,stream,astream,batch,abatch,astream_logকল। - এলএলএম গ্রহণ করে স্ট্রিং ইনপুট হিসাবে, বা বস্তু যা স্ট্রিং প্রম্পটে বাধ্য করা যেতে পারে, সহ
List[BaseMessage]এবংPromptValue. (পরে এগুলি সম্পর্কে আরও)
আসুন কিছু উদাহরণ দেখি।
response = llm.invoke("List the seven wonders of the world.")
print(response)

পাঠ্য প্রতিক্রিয়া স্ট্রিম করতে আপনি বিকল্পভাবে স্ট্রিম পদ্ধতিতে কল করতে পারেন।
for chunk in llm.stream("Where were the 2012 Olympics held?"): print(chunk, end="", flush=True)

চ্যাট মডেল
ইন্টারেক্টিভ চ্যাট অ্যাপ্লিকেশন তৈরির জন্য ল্যাংচেইনের চ্যাট মডেলের সাথে একীকরণ, ভাষা মডেলের একটি বিশেষ বৈচিত্র্য অপরিহার্য। যদিও তারা অভ্যন্তরীণভাবে ভাষার মডেলগুলি ব্যবহার করে, চ্যাট মডেলগুলি ইনপুট এবং আউটপুট হিসাবে চ্যাট বার্তাগুলির চারপাশে কেন্দ্রীভূত একটি স্বতন্ত্র ইন্টারফেস উপস্থাপন করে। এই বিভাগটি LangChain-এ OpenAI-এর চ্যাট মডেল ব্যবহারের একটি বিস্তারিত ওভারভিউ প্রদান করে।
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
LangChain-এ চ্যাট মডেলগুলি বিভিন্ন ধরনের বার্তার সাথে কাজ করে যেমন AIMessage, HumanMessage, SystemMessage, FunctionMessage, এবং ChatMessage (একটি নির্বিচারে ভূমিকা পরামিতি সহ)। সাধারণত, HumanMessage, AIMessage, এবং SystemMessage সবচেয়ে ঘন ঘন ব্যবহৃত হয়.
চ্যাট মডেল প্রাথমিকভাবে গ্রহণ List[BaseMessage] ইনপুট হিসাবে। স্ট্রিং-এ রূপান্তর করা যায় HumanMessage, এবং PromptValue সমর্থিত হয়।
from langchain.schema.messages import HumanMessage, SystemMessage
messages = [ SystemMessage(content="You are Micheal Jordan."), HumanMessage(content="Which shoe manufacturer are you associated with?"),
]
response = chat.invoke(messages)
print(response.content)
অনুরোধ জানানো
প্রাসঙ্গিক এবং সুসংগত আউটপুট জেনারেট করার জন্য ভাষা মডেলকে গাইড করার জন্য প্রম্পট অপরিহার্য। তারা সহজ নির্দেশাবলী থেকে জটিল কয়েক শট উদাহরণ পরিসীমা হতে পারে. LangChain-এ, প্রম্পট হ্যান্ডলিং একটি খুব সুগমিত প্রক্রিয়া হতে পারে, অনেকগুলি ডেডিকেটেড ক্লাস এবং ফাংশনগুলির জন্য ধন্যবাদ।
ল্যাংচেইনের PromptTemplate ক্লাস স্ট্রিং প্রম্পট তৈরি করার জন্য একটি বহুমুখী টুল। এটি পাইথন ব্যবহার করে str.format সিনট্যাক্স, গতিশীল প্রম্পট জেনারেশনের জন্য অনুমতি দেয়। আপনি স্থানধারক সহ একটি টেমপ্লেট সংজ্ঞায়িত করতে পারেন এবং প্রয়োজন অনুসারে নির্দিষ্ট মান দিয়ে সেগুলি পূরণ করতে পারেন।
from langchain.prompts import PromptTemplate # Simple prompt with placeholders
prompt_template = PromptTemplate.from_template( "Tell me a {adjective} joke about {content}."
) # Filling placeholders to create a prompt
filled_prompt = prompt_template.format(adjective="funny", content="robots")
print(filled_prompt)চ্যাট মডেলগুলির জন্য, প্রম্পটগুলি আরও কাঠামোগত, নির্দিষ্ট ভূমিকা সহ বার্তাগুলি জড়িত৷ ল্যাংচেইন অফার করে ChatPromptTemplate এই উদ্দেশ্যে.
from langchain.prompts import ChatPromptTemplate # Defining a chat prompt with various roles
chat_template = ChatPromptTemplate.from_messages( [ ("system", "You are a helpful AI bot. Your name is {name}."), ("human", "Hello, how are you doing?"), ("ai", "I'm doing well, thanks!"), ("human", "{user_input}"), ]
) # Formatting the chat prompt
formatted_messages = chat_template.format_messages(name="Bob", user_input="What is your name?")
for message in formatted_messages: print(message)
এই পদ্ধতিটি গতিশীল প্রতিক্রিয়া সহ ইন্টারেক্টিভ, আকর্ষক চ্যাটবট তৈরি করার অনুমতি দেয়।
উভয় PromptTemplate এবং ChatPromptTemplate LangChain এক্সপ্রেশন ল্যাঙ্গুয়েজ (LCEL) এর সাথে নির্বিঘ্নে একত্রিত করুন, তাদেরকে বৃহত্তর, জটিল কর্মপ্রবাহের অংশ হতে সক্ষম করে। আমরা পরে এই বিষয়ে আরও আলোচনা করব।
কাস্টম প্রম্পট টেমপ্লেটগুলি কখনও কখনও অনন্য ফর্ম্যাটিং বা নির্দিষ্ট নির্দেশাবলীর প্রয়োজনের জন্য প্রয়োজনীয়। একটি কাস্টম প্রম্পট টেমপ্লেট তৈরি করার জন্য ইনপুট ভেরিয়েবল এবং একটি কাস্টম ফর্ম্যাটিং পদ্ধতি সংজ্ঞায়িত করা জড়িত। এই নমনীয়তা ল্যাংচেইনকে অ্যাপ্লিকেশন-নির্দিষ্ট প্রয়োজনীয়তার বিস্তৃত অ্যারে পূরণ করতে দেয়। আরো পড়ুন এখানে।
LangChain কয়েক শট প্রম্পটিং সমর্থন করে, মডেলটিকে উদাহরণ থেকে শিখতে সক্ষম করে। এই বৈশিষ্ট্যটি প্রাসঙ্গিক বোঝাপড়া বা নির্দিষ্ট প্যাটার্নের প্রয়োজন এমন কাজের জন্য গুরুত্বপূর্ণ। কিছু-শট প্রম্পট টেমপ্লেট উদাহরণের একটি সেট থেকে বা একটি উদাহরণ নির্বাচক বস্তু ব্যবহার করে তৈরি করা যেতে পারে। আরো পড়ুন এখানে।
আউটপুট পার্সার্স
আউটপুট পার্সাররা ল্যাংচেইনে একটি গুরুত্বপূর্ণ ভূমিকা পালন করে, ব্যবহারকারীদের ভাষা মডেল দ্বারা উত্পন্ন প্রতিক্রিয়াগুলি গঠন করতে সক্ষম করে। এই বিভাগে, আমরা আউটপুট পার্সারের ধারণাটি অন্বেষণ করব এবং ল্যাংচেইনের PydanticOutputParser, SimpleJsonOutputParser, CommaSeparatedListOutputParser, DatetimeOutputParser এবং XMLOoutputParser ব্যবহার করে কোড উদাহরণ প্রদান করব।
PydanticOutputParser
Pydantic ডেটা স্ট্রাকচারে প্রতিক্রিয়া পার্স করার জন্য Langchain PydanticOutputParser প্রদান করে। এটি কীভাবে ব্যবহার করবেন তার একটি ধাপে ধাপে উদাহরণ নীচে দেওয়া হল:
from typing import List
from langchain.llms import OpenAI
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import PromptTemplate
from langchain.pydantic_v1 import BaseModel, Field, validator # Initialize the language model
model = OpenAI(model_name="text-davinci-003", temperature=0.0) # Define your desired data structure using Pydantic
class Joke(BaseModel): setup: str = Field(description="question to set up a joke") punchline: str = Field(description="answer to resolve the joke") @validator("setup") def question_ends_with_question_mark(cls, field): if field[-1] != "?": raise ValueError("Badly formed question!") return field # Set up a PydanticOutputParser
parser = PydanticOutputParser(pydantic_object=Joke) # Create a prompt with format instructions
prompt = PromptTemplate( template="Answer the user query.n{format_instructions}n{query}n", input_variables=["query"], partial_variables={"format_instructions": parser.get_format_instructions()},
) # Define a query to prompt the language model
query = "Tell me a joke." # Combine prompt, model, and parser to get structured output
prompt_and_model = prompt | model
output = prompt_and_model.invoke({"query": query}) # Parse the output using the parser
parsed_result = parser.invoke(output) # The result is a structured object
print(parsed_result)
আউটপুট হতে হবে:

SimpleJsonOutputParser
ল্যাংচেইনের SimpleJsonOutputParser ব্যবহার করা হয় যখন আপনি JSON-এর মতো আউটপুট পার্স করতে চান। এখানে একটি উদাহরণ:
from langchain.output_parsers.json import SimpleJsonOutputParser # Create a JSON prompt
json_prompt = PromptTemplate.from_template( "Return a JSON object with `birthdate` and `birthplace` key that answers the following question: {question}"
) # Initialize the JSON parser
json_parser = SimpleJsonOutputParser() # Create a chain with the prompt, model, and parser
json_chain = json_prompt | model | json_parser # Stream through the results
result_list = list(json_chain.stream({"question": "When and where was Elon Musk born?"})) # The result is a list of JSON-like dictionaries
print(result_list)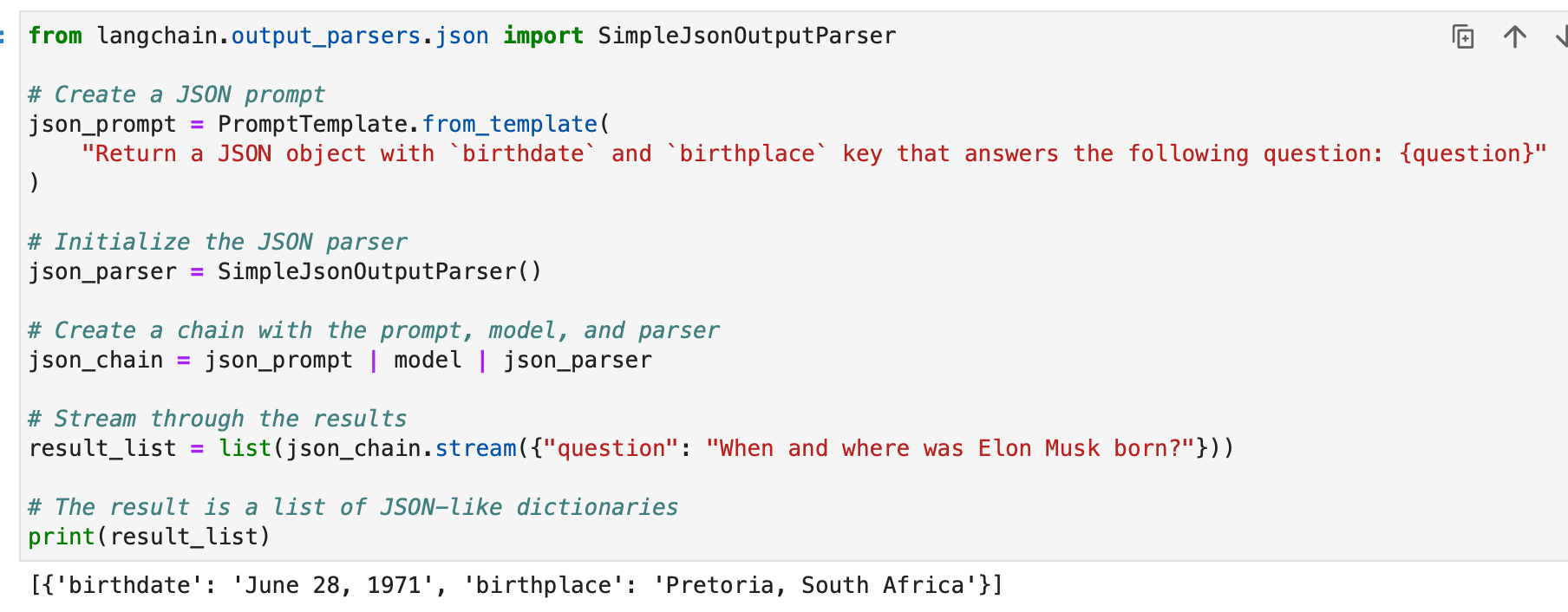
CommaSeparatedListOutputParser
যখন আপনি মডেল প্রতিক্রিয়াগুলি থেকে কমা-বিচ্ছিন্ন তালিকাগুলি বের করতে চান তখন CommaSeparatedListOutputParserটি কার্যকর। এখানে একটি উদাহরণ:
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI # Initialize the parser
output_parser = CommaSeparatedListOutputParser() # Create format instructions
format_instructions = output_parser.get_format_instructions() # Create a prompt to request a list
prompt = PromptTemplate( template="List five {subject}.n{format_instructions}", input_variables=["subject"], partial_variables={"format_instructions": format_instructions}
) # Define a query to prompt the model
query = "English Premier League Teams" # Generate the output
output = model(prompt.format(subject=query)) # Parse the output using the parser
parsed_result = output_parser.parse(output) # The result is a list of items
print(parsed_result)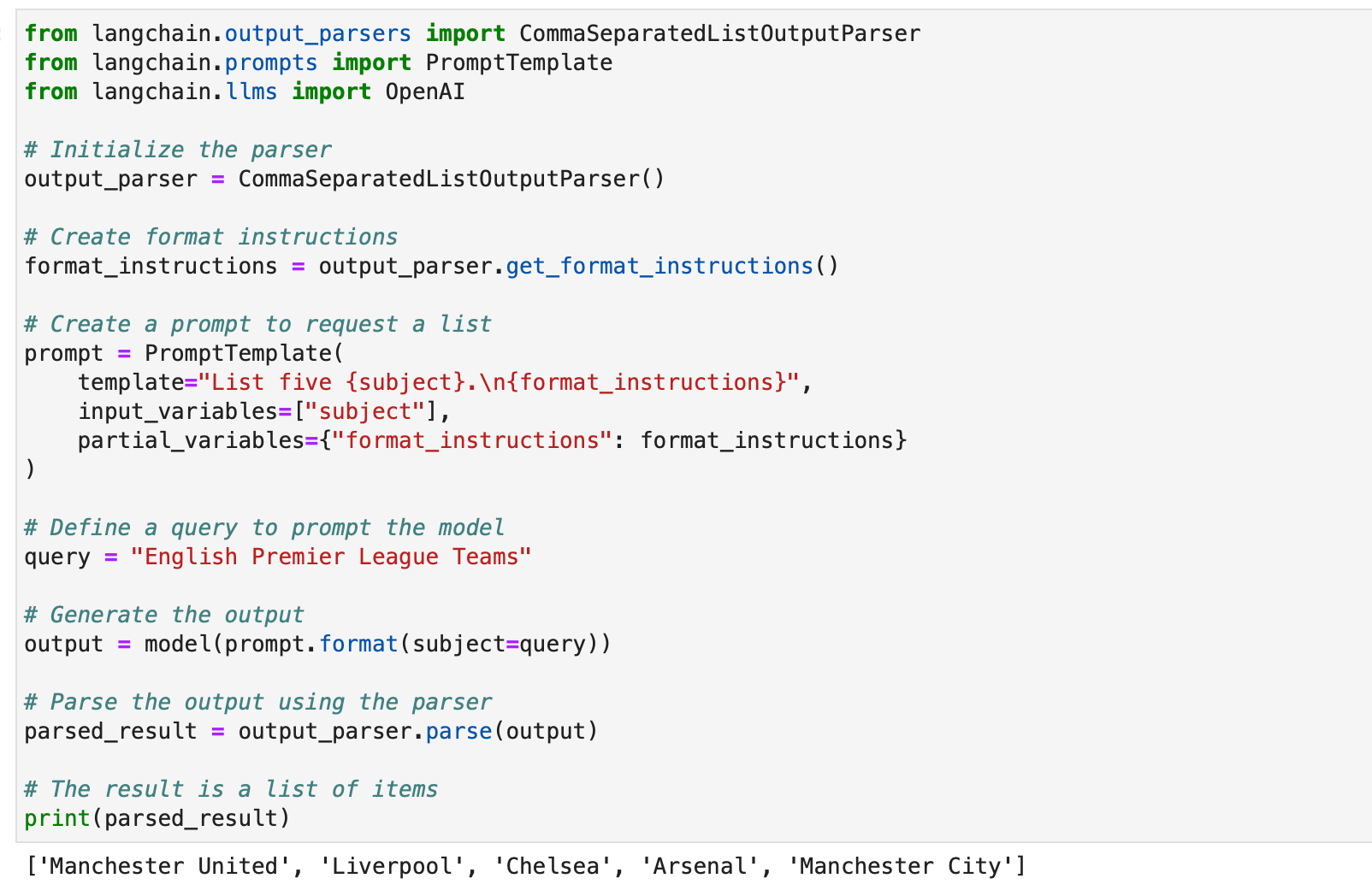
ডেটটাইম আউটপুট পার্সার
Langchain এর DatetimeOutputParser তারিখের সময় তথ্য পার্স করার জন্য ডিজাইন করা হয়েছে। এটি কীভাবে ব্যবহার করবেন তা এখানে:
from langchain.prompts import PromptTemplate
from langchain.output_parsers import DatetimeOutputParser
from langchain.chains import LLMChain
from langchain.llms import OpenAI # Initialize the DatetimeOutputParser
output_parser = DatetimeOutputParser() # Create a prompt with format instructions
template = """
Answer the user's question:
{question}
{format_instructions} """ prompt = PromptTemplate.from_template( template, partial_variables={"format_instructions": output_parser.get_format_instructions()},
) # Create a chain with the prompt and language model
chain = LLMChain(prompt=prompt, llm=OpenAI()) # Define a query to prompt the model
query = "when did Neil Armstrong land on the moon in terms of GMT?" # Run the chain
output = chain.run(query) # Parse the output using the datetime parser
parsed_result = output_parser.parse(output) # The result is a datetime object
print(parsed_result)
এই উদাহরণগুলি দেখায় কিভাবে ল্যাংচেইনের আউটপুট পার্সারগুলিকে বিভিন্ন ধরণের মডেল প্রতিক্রিয়া গঠন করতে ব্যবহার করা যেতে পারে, তাদের বিভিন্ন অ্যাপ্লিকেশন এবং ফর্ম্যাটের জন্য উপযুক্ত করে তোলে। আউটপুট পার্সারগুলি ল্যাংচেইনের ভাষা মডেল আউটপুটগুলির ব্যবহারযোগ্যতা এবং ব্যাখ্যাযোগ্যতা বাড়ানোর জন্য একটি মূল্যবান হাতিয়ার।
আমাদের AI-চালিত ওয়ার্কফ্লো নির্মাতার সাথে ম্যানুয়াল কাজ এবং ওয়ার্কফ্লোগুলি স্বয়ংক্রিয় করুন, আপনার এবং আপনার দলের জন্য Nanonets দ্বারা ডিজাইন করা হয়েছে৷
মডিউল II: পুনরুদ্ধার
LangChain-এ পুনরুদ্ধার এমন অ্যাপ্লিকেশনগুলিতে একটি গুরুত্বপূর্ণ ভূমিকা পালন করে যার জন্য ব্যবহারকারী-নির্দিষ্ট ডেটা প্রয়োজন, মডেলের প্রশিক্ষণ সেটে অন্তর্ভুক্ত নয়। Retrieval Augmented Generation (RAG) নামে পরিচিত এই প্রক্রিয়াটির মধ্যে বাহ্যিক ডেটা আনা এবং ভাষা মডেলের জেনারেশন প্রক্রিয়ার সাথে এটিকে একীভূত করা জড়িত। LangChain এই প্রক্রিয়াটিকে সহজতর করার জন্য সরঞ্জাম এবং কার্যকারিতাগুলির একটি বিস্তৃত স্যুট প্রদান করে, সহজ এবং জটিল উভয় অ্যাপ্লিকেশনের জন্যই।
LangChain উপাদানগুলির একটি সিরিজের মাধ্যমে পুনরুদ্ধার অর্জন করে যা আমরা একে একে আলোচনা করব।
ডকুমেন্ট লোডার
LangChain-এ ডকুমেন্ট লোডারগুলি বিভিন্ন উত্স থেকে ডেটা নিষ্কাশন সক্ষম করে৷ 100 টিরও বেশি লোডার উপলব্ধ সহ, তারা বিভিন্ন ধরণের নথি, অ্যাপ এবং উত্স (ব্যক্তিগত s3 বালতি, সর্বজনীন ওয়েবসাইট, ডেটাবেস) সমর্থন করে।
আপনি আপনার প্রয়োজনীয়তার উপর ভিত্তি করে একটি নথি লোডার চয়ন করতে পারেন এখানে.
এই সমস্ত লোডার ডাটা ইনজেস্ট করে দলিল ক্লাস আমরা পরে ডকুমেন্ট ক্লাসে ইনজেস্ট করা ডেটা কীভাবে ব্যবহার করতে হয় তা শিখব।
টেক্সট ফাইল লোডার: একটি সহজ লোড .txt একটি নথিতে ফাইল করুন।
from langchain.document_loaders import TextLoader loader = TextLoader("./sample.txt")
document = loader.load()
CSV লোডার: একটি নথিতে একটি CSV ফাইল লোড করুন।
from langchain.document_loaders.csv_loader import CSVLoader loader = CSVLoader(file_path='./example_data/sample.csv')
documents = loader.load()
আমরা ক্ষেত্রের নাম উল্লেখ করে পার্সিং কাস্টমাইজ করতে পারি -
loader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv', csv_args={ 'delimiter': ',', 'quotechar': '"', 'fieldnames': ['MLB Team', 'Payroll in millions', 'Wins']
})
documents = loader.load()
পিডিএফ লোডার: LangChain-এ PDF লোডারগুলি PDF ফাইলগুলি থেকে বিষয়বস্তু পার্সিং এবং বের করার জন্য বিভিন্ন পদ্ধতি অফার করে। প্রতিটি লোডার বিভিন্ন প্রয়োজনীয়তা পূরণ করে এবং বিভিন্ন অন্তর্নিহিত লাইব্রেরি ব্যবহার করে। নীচে প্রতিটি লোডারের জন্য বিস্তারিত উদাহরণ রয়েছে।
PyPDFLloader মৌলিক PDF পার্সিংয়ের জন্য ব্যবহৃত হয়।
from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
MathPixLoader গাণিতিক বিষয়বস্তু এবং ডায়াগ্রাম বের করার জন্য আদর্শ।
from langchain.document_loaders import MathpixPDFLoader loader = MathpixPDFLoader("example_data/math-content.pdf")
data = loader.load()
PyMuPDFLloader দ্রুত এবং বিস্তারিত মেটাডেটা নিষ্কাশন অন্তর্ভুক্ত।
from langchain.document_loaders import PyMuPDFLoader loader = PyMuPDFLoader("example_data/layout-parser-paper.pdf")
data = loader.load() # Optionally pass additional arguments for PyMuPDF's get_text() call
data = loader.load(option="text")
PDFMiner লোডার পাঠ্য নিষ্কাশনের উপর আরও দানাদার নিয়ন্ত্রণের জন্য ব্যবহার করা হয়।
from langchain.document_loaders import PDFMinerLoader loader = PDFMinerLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
AmazonTextractPDFParser OCR এবং অন্যান্য উন্নত PDF পার্সিং বৈশিষ্ট্যের জন্য AWS Textract ব্যবহার করে।
from langchain.document_loaders import AmazonTextractPDFLoader # Requires AWS account and configuration
loader = AmazonTextractPDFLoader("example_data/complex-layout.pdf")
documents = loader.load()
PDFMinerPDFasHTMLLoader শব্দার্থিক পার্সিংয়ের জন্য PDF থেকে HTML তৈরি করে।
from langchain.document_loaders import PDFMinerPDFasHTMLLoader loader = PDFMinerPDFasHTMLLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
PDFPlumberLoader বিস্তারিত মেটাডেটা প্রদান করে এবং প্রতি পৃষ্ঠায় একটি নথি সমর্থন করে।
from langchain.document_loaders import PDFPlumberLoader loader = PDFPlumberLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
ইন্টিগ্রেটেড লোডার: LangChain আপনার অ্যাপ (যেমন Slack, Sigma, Notion, Confluence, Google Drive এবং আরও অনেক কিছু) এবং ডাটাবেস থেকে সরাসরি ডেটা লোড করতে এবং LLM অ্যাপ্লিকেশনগুলিতে ব্যবহার করার জন্য বিভিন্ন ধরনের কাস্টম লোডার অফার করে।
সম্পূর্ণ তালিকা হল এখানে.
এটি বোঝানোর জন্য নীচে কয়েকটি উদাহরণ দেওয়া হল-
উদাহরণ I – স্ল্যাক
স্ল্যাক, একটি ব্যাপকভাবে ব্যবহৃত তাত্ক্ষণিক বার্তাপ্রেরণ প্ল্যাটফর্ম, এলএলএম ওয়ার্কফ্লো এবং অ্যাপ্লিকেশনগুলিতে একীভূত করা যেতে পারে।
- আপনার স্ল্যাক ওয়ার্কস্পেস ম্যানেজমেন্ট পৃষ্ঠায় যান।
- নেভিগেট করুন
{your_slack_domain}.slack.com/services/export. - পছন্দসই তারিখ পরিসীমা নির্বাচন করুন এবং রপ্তানি শুরু করুন।
- রপ্তানি প্রস্তুত হয়ে গেলে স্ল্যাক ইমেল এবং ডিএম-এর মাধ্যমে বিজ্ঞপ্তি দেয়।
- রপ্তানি ফলাফল a
.zipআপনার ডাউনলোড ফোল্ডারে বা আপনার নির্ধারিত ডাউনলোড পাথে অবস্থিত ফাইল। - ডাউনলোড করা পাথ বরাদ্দ করুন
.zipফাইলের জন্যLOCAL_ZIPFILE. - ব্যবহার
SlackDirectoryLoaderথেকেlangchain.document_loadersপ্যাকেজ।
from langchain.document_loaders import SlackDirectoryLoader SLACK_WORKSPACE_URL = "https://xxx.slack.com" # Replace with your Slack URL
LOCAL_ZIPFILE = "" # Path to the Slack zip file loader = SlackDirectoryLoader(LOCAL_ZIPFILE, SLACK_WORKSPACE_URL)
docs = loader.load()
print(docs)
উদাহরণ II – ফিগমা
ফিগমা, ইন্টারফেস ডিজাইনের জন্য একটি জনপ্রিয় টুল, ডেটা ইন্টিগ্রেশনের জন্য একটি REST API অফার করে।
- ইউআরএল ফরম্যাট থেকে ফিগমা ফাইল কী পান:
https://www.figma.com/file/{filekey}/sampleFilename. - ইউআরএল প্যারামিটারে নোড আইডি পাওয়া যায়
?node-id={node_id}. - নির্দেশাবলী অনুসরণ করে একটি অ্যাক্সেস টোকেন তৈরি করুন ফিগমা সহায়তা কেন্দ্র.
- সার্জারির
FigmaFileLoaderথেকে ক্লাসlangchain.document_loaders.figmaফিগমা ডেটা লোড করতে ব্যবহৃত হয়। - বিভিন্ন LangChain মডিউল মত
CharacterTextSplitter,ChatOpenAIইত্যাদি, প্রক্রিয়াকরণের জন্য নিযুক্ত করা হয়।
import os
from langchain.document_loaders.figma import FigmaFileLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.indexes import VectorstoreIndexCreator
from langchain.chains import ConversationChain, LLMChain
from langchain.memory import ConversationBufferWindowMemory
from langchain.prompts.chat import ChatPromptTemplate, SystemMessagePromptTemplate, AIMessagePromptTemplate, HumanMessagePromptTemplate figma_loader = FigmaFileLoader( os.environ.get("ACCESS_TOKEN"), os.environ.get("NODE_IDS"), os.environ.get("FILE_KEY"),
) index = VectorstoreIndexCreator().from_loaders([figma_loader])
figma_doc_retriever = index.vectorstore.as_retriever()
- সার্জারির
generate_codeফাংশন এইচটিএমএল/সিএসএস কোড তৈরি করতে ফিগমা ডেটা ব্যবহার করে। - এটি একটি GPT-ভিত্তিক মডেলের সাথে একটি টেমপ্লেটেড কথোপকথন নিয়োগ করে।
def generate_code(human_input): # Template for system and human prompts system_prompt_template = "Your coding instructions..." human_prompt_template = "Code the {text}. Ensure it's mobile responsive" # Creating prompt templates system_message_prompt = SystemMessagePromptTemplate.from_template(system_prompt_template) human_message_prompt = HumanMessagePromptTemplate.from_template(human_prompt_template) # Setting up the AI model gpt_4 = ChatOpenAI(temperature=0.02, model_name="gpt-4") # Retrieving relevant documents relevant_nodes = figma_doc_retriever.get_relevant_documents(human_input) # Generating and formatting the prompt conversation = [system_message_prompt, human_message_prompt] chat_prompt = ChatPromptTemplate.from_messages(conversation) response = gpt_4(chat_prompt.format_prompt(context=relevant_nodes, text=human_input).to_messages()) return response # Example usage
response = generate_code("page top header")
print(response.content)
- সার্জারির
generate_codeফাংশন, যখন কার্যকর করা হয়, ফিগমা ডিজাইন ইনপুটের উপর ভিত্তি করে HTML/CSS কোড প্রদান করে।
আসুন এখন আমাদের জ্ঞান ব্যবহার করে কয়েকটি নথি সেট তৈরি করি।
আমরা প্রথমে একটি PDF লোড করি, BCG বার্ষিক স্থায়িত্ব প্রতিবেদন।
আমরা এর জন্য PyPDFLloader ব্যবহার করি।
from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("bcg-2022-annual-sustainability-report-apr-2023.pdf")
pdfpages = loader.load_and_split()
আমরা এখন Airtable থেকে ডেটা ইনজেস্ট করব। আমাদের কাছে একটি এয়ারটেবল রয়েছে যাতে বিভিন্ন OCR এবং ডেটা এক্সট্রাকশন মডেল সম্পর্কে তথ্য রয়েছে -
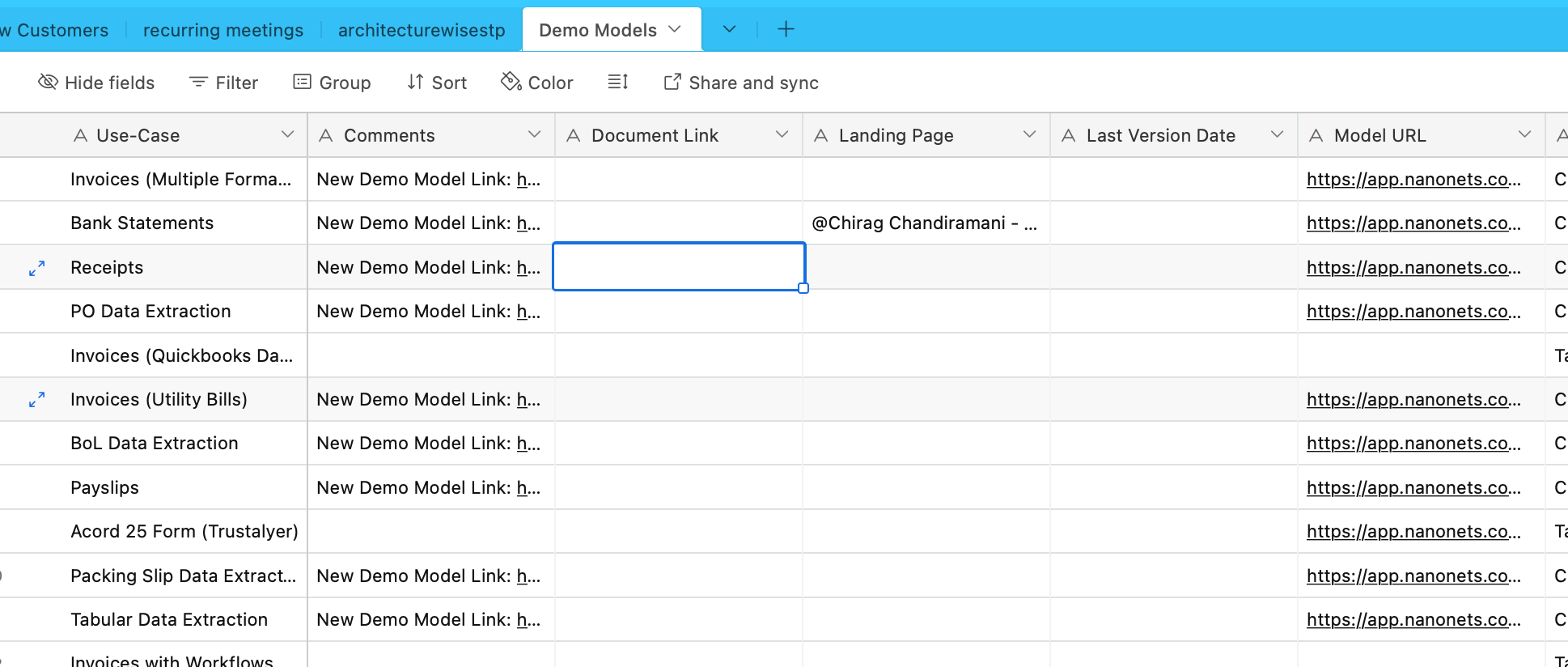
এর জন্য আমরা AirtableLoader ব্যবহার করি, যা ইন্টিগ্রেটেড লোডারগুলির তালিকায় পাওয়া যায়।
from langchain.document_loaders import AirtableLoader api_key = "XXXXX"
base_id = "XXXXX"
table_id = "XXXXX" loader = AirtableLoader(api_key, table_id, base_id)
airtabledocs = loader.load()
আসুন এখন এগিয়ে যাই এবং এই ডকুমেন্ট ক্লাসগুলি কিভাবে ব্যবহার করতে হয় তা শিখি।
ডকুমেন্ট ট্রান্সফরমার
LangChain-এ ডকুমেন্ট ট্রান্সফরমার হল ডকুমেন্ট ম্যানিপুলেট করার জন্য ডিজাইন করা অপরিহার্য টুল, যা আমরা আমাদের আগের সাবসেকশনে তৈরি করেছি।
এগুলি লম্বা নথিগুলিকে ছোট খণ্ডে বিভক্ত করা, একত্রিত করা এবং ফিল্টার করার মতো কাজের জন্য ব্যবহৃত হয়, যা নথিগুলিকে মডেলের প্রসঙ্গ উইন্ডোতে অভিযোজিত করার জন্য বা নির্দিষ্ট অ্যাপ্লিকেশনের প্রয়োজন মেটানোর জন্য গুরুত্বপূর্ণ।
এরকম একটি টুল হল Recursive CharacterTextSplitter, একটি বহুমুখী টেক্সট স্প্লিটার যা বিভক্ত করার জন্য একটি অক্ষর তালিকা ব্যবহার করে। এটি খণ্ডের আকার, ওভারল্যাপ এবং প্রারম্ভিক সূচকের মতো পরামিতিগুলিকে অনুমতি দেয়। পাইথনে এটি কীভাবে ব্যবহার করা হয় তার একটি উদাহরণ এখানে দেওয়া হল:
from langchain.text_splitter import RecursiveCharacterTextSplitter state_of_the_union = "Your long text here..." text_splitter = RecursiveCharacterTextSplitter( chunk_size=100, chunk_overlap=20, length_function=len, add_start_index=True,
) texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
আরেকটি টুল হল CharacterTextSplitter, যা একটি নির্দিষ্ট অক্ষরের উপর ভিত্তি করে পাঠ্যকে বিভক্ত করে এবং খণ্ডের আকার এবং ওভারল্যাপের জন্য নিয়ন্ত্রণ অন্তর্ভুক্ত করে:
from langchain.text_splitter import CharacterTextSplitter text_splitter = CharacterTextSplitter( separator="nn", chunk_size=1000, chunk_overlap=200, length_function=len, is_separator_regex=False,
) texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
HTMLHeaderTextSplitter হেডার ট্যাগের উপর ভিত্তি করে এইচটিএমএল বিষয়বস্তু বিভক্ত করার জন্য ডিজাইন করা হয়েছে, শব্দার্থিক গঠন বজায় রেখে:
from langchain.text_splitter import HTMLHeaderTextSplitter html_string = "Your HTML content here..."
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")] html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text(html_string)
print(html_header_splits[0])
HTMLHeaderTextSplitter-এর সাথে অন্য একটি স্প্লিটার, যেমন Pipelined Splitter-এর সাথে একত্রিত করে আরও জটিল ম্যানিপুলেশন অর্জন করা যেতে পারে:
from langchain.text_splitter import HTMLHeaderTextSplitter, RecursiveCharacterTextSplitter url = "https://example.com"
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url) chunk_size = 500
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size)
splits = text_splitter.split_documents(html_header_splits)
print(splits[0])
ল্যাংচেইন বিভিন্ন প্রোগ্রামিং ভাষার জন্য নির্দিষ্ট স্প্লিটারও অফার করে, যেমন পাইথন কোড স্প্লিটার এবং জাভাস্ক্রিপ্ট কোড স্প্লিটার:
from langchain.text_splitter import RecursiveCharacterTextSplitter, Language python_code = """
def hello_world(): print("Hello, World!")
hello_world() """ python_splitter = RecursiveCharacterTextSplitter.from_language( language=Language.PYTHON, chunk_size=50
)
python_docs = python_splitter.create_documents([python_code])
print(python_docs[0]) js_code = """
function helloWorld() { console.log("Hello, World!");
}
helloWorld(); """ js_splitter = RecursiveCharacterTextSplitter.from_language( language=Language.JS, chunk_size=60
)
js_docs = js_splitter.create_documents([js_code])
print(js_docs[0])
টোকেন সংখ্যার উপর ভিত্তি করে পাঠ্য বিভক্ত করার জন্য, যা টোকেন সীমা সহ ভাষার মডেলগুলির জন্য উপযোগী, টোকেন টেক্সট স্প্লিটার ব্যবহার করা হয়:
from langchain.text_splitter import TokenTextSplitter text_splitter = TokenTextSplitter(chunk_size=10)
texts = text_splitter.split_text(state_of_the_union)
print(texts[0])
অবশেষে, লং কনটেক্সট রিঅর্ডার দীর্ঘ প্রেক্ষাপটের কারণে মডেলগুলিতে কর্মক্ষমতা হ্রাস রোধ করতে নথিগুলিকে পুনরায় সাজায়:
from langchain.document_transformers import LongContextReorder reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs)
print(reordered_docs[0])
এই টুলগুলি LangChain-এ নথিগুলিকে রূপান্তরিত করার বিভিন্ন উপায় প্রদর্শন করে, সাধারণ পাঠ্য বিভাজন থেকে জটিল পুনর্বিন্যাস এবং ভাষা-নির্দিষ্ট বিভাজন পর্যন্ত। আরও গভীরভাবে এবং নির্দিষ্ট ব্যবহারের ক্ষেত্রে, LangChain ডকুমেন্টেশন এবং ইন্টিগ্রেশন বিভাগের পরামর্শ নেওয়া উচিত।
আমাদের উদাহরণগুলিতে, লোডাররা ইতিমধ্যেই আমাদের জন্য খণ্ডিত নথি তৈরি করেছে এবং এই অংশটি ইতিমধ্যেই পরিচালনা করা হয়েছে।
টেক্সট এমবেডিং মডেল
LangChain-এ টেক্সট এমবেডিং মডেলগুলি OpenAI, Cohere এবং Hugging Face এর মত বিভিন্ন এমবেডিং মডেল প্রদানকারীদের জন্য একটি প্রমিত ইন্টারফেস প্রদান করে। এই মডেলগুলি পাঠ্যকে ভেক্টর উপস্থাপনায় রূপান্তরিত করে, ভেক্টর স্পেসে পাঠ্যের সাদৃশ্যের মাধ্যমে শব্দার্থিক অনুসন্ধানের মতো ক্রিয়াকলাপগুলিকে সক্ষম করে।
পাঠ্য এমবেডিং মডেলগুলির সাথে শুরু করার জন্য, আপনাকে সাধারণত নির্দিষ্ট প্যাকেজগুলি ইনস্টল করতে হবে এবং API কীগুলি সেট আপ করতে হবে৷ আমরা ইতিমধ্যে OpenAI এর জন্য এটি করেছি
LangChain মধ্যে, embed_documents পদ্ধতিটি একাধিক পাঠ্য এম্বেড করতে ব্যবহৃত হয়, ভেক্টর উপস্থাপনাগুলির একটি তালিকা প্রদান করে। এই ক্ষেত্রে:
from langchain.embeddings import OpenAIEmbeddings # Initialize the model
embeddings_model = OpenAIEmbeddings() # Embed a list of texts
embeddings = embeddings_model.embed_documents( ["Hi there!", "Oh, hello!", "What's your name?", "My friends call me World", "Hello World!"]
)
print("Number of documents embedded:", len(embeddings))
print("Dimension of each embedding:", len(embeddings[0]))
একটি একক পাঠ্য এমবেড করার জন্য, যেমন একটি অনুসন্ধান ক্যোয়ারী, embed_query পদ্ধতি ব্যবহার করা হয়। ডকুমেন্ট এম্বেডিংয়ের একটি সেটের সাথে একটি ক্যোয়ারী তুলনা করার জন্য এটি কার্যকর। উদাহরণ স্বরূপ:
from langchain.embeddings import OpenAIEmbeddings # Initialize the model
embeddings_model = OpenAIEmbeddings() # Embed a single query
embedded_query = embeddings_model.embed_query("What was the name mentioned in the conversation?")
print("First five dimensions of the embedded query:", embedded_query[:5])
এই এমবেডিং বোঝা অত্যন্ত গুরুত্বপূর্ণ. পাঠ্যের প্রতিটি অংশ একটি ভেক্টরে রূপান্তরিত হয়, যার মাত্রা ব্যবহৃত মডেলের উপর নির্ভর করে। উদাহরণস্বরূপ, OpenAI মডেলগুলি সাধারণত 1536-মাত্রিক ভেক্টর তৈরি করে। এই এমবেডিংগুলি তখন প্রাসঙ্গিক তথ্য পুনরুদ্ধারের জন্য ব্যবহার করা হয়।
LangChain এর এমবেডিং কার্যকারিতা OpenAI এর মধ্যে সীমাবদ্ধ নয় বরং বিভিন্ন প্রদানকারীর সাথে কাজ করার জন্য ডিজাইন করা হয়েছে। সেটআপ এবং ব্যবহার প্রদানকারীর উপর নির্ভর করে কিছুটা আলাদা হতে পারে, তবে ভেক্টর স্পেসে পাঠ্য এম্বেড করার মূল ধারণা একই থাকে। উন্নত কনফিগারেশন এবং বিভিন্ন এমবেডিং মডেল প্রদানকারীদের সাথে ইন্টিগ্রেশন সহ বিস্তারিত ব্যবহারের জন্য, ইন্টিগ্রেশন বিভাগে ল্যাংচেইন ডকুমেন্টেশন একটি মূল্যবান সম্পদ।
ভেক্টর স্টোর
ল্যাংচেইনের ভেক্টর স্টোরগুলি টেক্সট এম্বেডিংয়ের দক্ষ স্টোরেজ এবং অনুসন্ধানকে সমর্থন করে। LangChain 50 টিরও বেশি ভেক্টর স্টোরের সাথে সংহত করে, ব্যবহারের সহজতার জন্য একটি প্রমিত ইন্টারফেস প্রদান করে।
উদাহরণ: এম্বেডিং সঞ্চয় করা এবং অনুসন্ধান করা
পাঠ্য এম্বেড করার পরে, আমরা সেগুলিকে একটি ভেক্টর স্টোরে সংরক্ষণ করতে পারি Chroma এবং সাদৃশ্য অনুসন্ধানগুলি সম্পাদন করুন:
from langchain.vectorstores import Chroma db = Chroma.from_texts(embedded_texts)
similar_texts = db.similarity_search("search query")
আমাদের নথিগুলির জন্য সূচী তৈরি করতে আমাদের বিকল্পভাবে FAISS ভেক্টর স্টোর ব্যবহার করা যাক।
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS pdfstore = FAISS.from_documents(pdfpages, embedding=OpenAIEmbeddings()) airtablestore = FAISS.from_documents(airtabledocs, embedding=OpenAIEmbeddings())

উদ্ধারকারী
LangChain-এ পুনরুদ্ধারকারীরা এমন ইন্টারফেস যা একটি অসংগঠিত প্রশ্নের উত্তরে নথি ফেরত দেয়। এগুলি ভেক্টর স্টোরের চেয়ে বেশি সাধারণ, স্টোরেজের পরিবর্তে পুনরুদ্ধারের দিকে মনোনিবেশ করে। যদিও ভেক্টর স্টোরগুলি পুনরুদ্ধারের মেরুদণ্ড হিসাবে ব্যবহার করা যেতে পারে, তবে অন্যান্য ধরণের পুনরুদ্ধারও রয়েছে।
একটি Chroma রিট্রিভার সেট আপ করতে, আপনি প্রথমে এটি ব্যবহার করে ইনস্টল করুন৷ pip install chromadb. তারপর, আপনি পাইথন কমান্ডের একটি সিরিজ ব্যবহার করে নথি লোড, বিভক্ত, এম্বেড এবং পুনরুদ্ধার করুন। এখানে একটি ক্রোমা পুনরুদ্ধার সেট আপ করার জন্য একটি কোড উদাহরণ:
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma full_text = open("state_of_the_union.txt", "r").read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
texts = text_splitter.split_text(full_text) embeddings = OpenAIEmbeddings()
db = Chroma.from_texts(texts, embeddings)
retriever = db.as_retriever() retrieved_docs = retriever.invoke("What did the president say about Ketanji Brown Jackson?")
print(retrieved_docs[0].page_content)
MultiQueryRetriever একটি ব্যবহারকারীর ইনপুট ক্যোয়ারির জন্য একাধিক প্রশ্ন তৈরি করে এবং ফলাফলগুলিকে একত্রিত করে প্রম্পট টিউনিং স্বয়ংক্রিয় করে। এখানে এর সহজ ব্যবহারের একটি উদাহরণ:
from langchain.chat_models import ChatOpenAI
from langchain.retrievers.multi_query import MultiQueryRetriever question = "What are the approaches to Task Decomposition?"
llm = ChatOpenAI(temperature=0)
retriever_from_llm = MultiQueryRetriever.from_llm( retriever=db.as_retriever(), llm=llm
) unique_docs = retriever_from_llm.get_relevant_documents(query=question)
print("Number of unique documents:", len(unique_docs))
LangChain-এ প্রাসঙ্গিক সংকোচন শুধুমাত্র প্রাসঙ্গিক তথ্য ফেরত নিশ্চিত করে, কোয়েরির প্রসঙ্গ ব্যবহার করে পুনরুদ্ধার করা নথিগুলিকে সংকুচিত করে। এর মধ্যে বিষয়বস্তু হ্রাস করা এবং কম প্রাসঙ্গিক নথিগুলি ফিল্টার করা জড়িত৷ নিম্নলিখিত কোড উদাহরণ দেখায় কিভাবে প্রাসঙ্গিক কম্প্রেশন রিট্রিভার ব্যবহার করতে হয়:
from langchain.llms import OpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever) compressed_docs = compression_retriever.get_relevant_documents("What did the president say about Ketanji Jackson Brown")
print(compressed_docs[0].page_content)
EnsembleRetriever আরও ভালো কর্মক্ষমতা অর্জনের জন্য বিভিন্ন পুনরুদ্ধার অ্যালগরিদমকে একত্রিত করে। BM25 এবং FAISS Retrievers একত্রিত করার একটি উদাহরণ নিম্নলিখিত কোডে দেখানো হয়েছে:
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain.vectorstores import FAISS bm25_retriever = BM25Retriever.from_texts(doc_list).set_k(2)
faiss_vectorstore = FAISS.from_texts(doc_list, OpenAIEmbeddings())
faiss_retriever = faiss_vectorstore.as_retriever(search_kwargs={"k": 2}) ensemble_retriever = EnsembleRetriever( retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5]
) docs = ensemble_retriever.get_relevant_documents("apples")
print(docs[0].page_content)
LangChain-এ মাল্টিভেক্টর রিট্রিভার ডকুমেন্ট প্রতি একাধিক ভেক্টর সহ ডকুমেন্ট অনুসন্ধান করার অনুমতি দেয়, যা একটি নথির মধ্যে বিভিন্ন শব্দার্থিক দিক ক্যাপচার করার জন্য দরকারী। একাধিক ভেক্টর তৈরির পদ্ধতির মধ্যে রয়েছে ছোট ছোট খণ্ডে বিভক্ত করা, সংক্ষিপ্তকরণ করা বা অনুমানমূলক প্রশ্ন তৈরি করা। নথিগুলিকে ছোট খণ্ডে বিভক্ত করার জন্য, নিম্নলিখিত পাইথন কোড ব্যবহার করা যেতে পারে:
python
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.storage import InMemoryStore
from langchain.document_loaders from TextLoader
import uuid loaders = [TextLoader("file1.txt"), TextLoader("file2.txt")]
docs = [doc for loader in loaders for doc in loader.load()]
text_splitter = RecursiveCharacterTextSplitter(chunk_size=10000)
docs = text_splitter.split_documents(docs) vectorstore = Chroma(collection_name="full_documents", embedding_function=OpenAIEmbeddings())
store = InMemoryStore()
id_key = "doc_id"
retriever = MultiVectorRetriever(vectorstore=vectorstore, docstore=store, id_key=id_key) doc_ids = [str(uuid.uuid4()) for _ in docs]
child_text_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
sub_docs = [sub_doc for doc in docs for sub_doc in child_text_splitter.split_documents([doc])]
for sub_doc in sub_docs: sub_doc.metadata[id_key] = doc_ids[sub_docs.index(sub_doc)] retriever.vectorstore.add_documents(sub_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
আরও মনোযোগী বিষয়বস্তু উপস্থাপনের কারণে আরও ভাল পুনরুদ্ধারের জন্য সারাংশ তৈরি করা আরেকটি পদ্ধতি। এখানে সারাংশ তৈরি করার একটি উদাহরণ:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.document import Document chain = (lambda x: x.page_content) | ChatPromptTemplate.from_template("Summarize the following document:nn{doc}") | ChatOpenAI(max_retries=0) | StrOutputParser()
summaries = chain.batch(docs, {"max_concurrency": 5}) summary_docs = [Document(page_content=s, metadata={id_key: doc_ids[i]}) for i, s in enumerate(summaries)]
retriever.vectorstore.add_documents(summary_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
এলএলএম ব্যবহার করে প্রতিটি নথির সাথে প্রাসঙ্গিক অনুমানমূলক প্রশ্ন তৈরি করা আরেকটি পদ্ধতি। এটি নিম্নলিখিত কোড দিয়ে করা যেতে পারে:
functions = [{"name": "hypothetical_questions", "parameters": {"questions": {"type": "array", "items": {"type": "string"}}}}]
from langchain.output_parsers.openai_functions import JsonKeyOutputFunctionsParser chain = (lambda x: x.page_content) | ChatPromptTemplate.from_template("Generate 3 hypothetical questions:nn{doc}") | ChatOpenAI(max_retries=0).bind(functions=functions, function_call={"name": "hypothetical_questions"}) | JsonKeyOutputFunctionsParser(key_name="questions")
hypothetical_questions = chain.batch(docs, {"max_concurrency": 5}) question_docs = [Document(page_content=q, metadata={id_key: doc_ids[i]}) for i, questions in enumerate(hypothetical_questions) for q in questions]
retriever.vectorstore.add_documents(question_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
দ্য প্যারেন্ট ডকুমেন্ট রিট্রিভার হল আরেকটি পুনরুদ্ধারকারী যেটি ছোট খণ্ডগুলি সংরক্ষণ করে এবং তাদের বৃহত্তর মূল নথিগুলি পুনরুদ্ধার করে এম্বেডিং নির্ভুলতা এবং প্রসঙ্গ ধরে রাখার মধ্যে ভারসাম্য বজায় রাখে। এর বাস্তবায়ন নিম্নরূপ:
from langchain.retrievers import ParentDocumentRetriever loaders = [TextLoader("file1.txt"), TextLoader("file2.txt")]
docs = [doc for loader in loaders for doc in loader.load()] child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
vectorstore = Chroma(collection_name="full_documents", embedding_function=OpenAIEmbeddings())
store = InMemoryStore()
retriever = ParentDocumentRetriever(vectorstore=vectorstore, docstore=store, child_splitter=child_splitter) retriever.add_documents(docs, ids=None) retrieved_docs = retriever.get_relevant_documents("query")
একটি স্ব-কোয়েরি পুনরুদ্ধারকারী প্রাকৃতিক ভাষা ইনপুট থেকে কাঠামোগত প্রশ্ন তৈরি করে এবং তাদের অন্তর্নিহিত ভেক্টরস্টোরে প্রয়োগ করে। এর বাস্তবায়ন নিম্নলিখিত কোডে দেখানো হয়েছে:
from langchain.chat_models from ChatOpenAI
from langchain.chains.query_constructor.base from AttributeInfo
from langchain.retrievers.self_query.base from SelfQueryRetriever metadata_field_info = [AttributeInfo(name="genre", description="...", type="string"), ...]
document_content_description = "Brief summary of a movie"
llm = ChatOpenAI(temperature=0) retriever = SelfQueryRetriever.from_llm(llm, vectorstore, document_content_description, metadata_field_info) retrieved_docs = retriever.invoke("query")
WebResearchRetriever একটি প্রদত্ত প্রশ্নের উপর ভিত্তি করে ওয়েব গবেষণা করে -
from langchain.retrievers.web_research import WebResearchRetriever # Initialize components
llm = ChatOpenAI(temperature=0)
search = GoogleSearchAPIWrapper()
vectorstore = Chroma(embedding_function=OpenAIEmbeddings()) # Instantiate WebResearchRetriever
web_research_retriever = WebResearchRetriever.from_llm(vectorstore=vectorstore, llm=llm, search=search) # Retrieve documents
docs = web_research_retriever.get_relevant_documents("query")
আমাদের উদাহরণগুলির জন্য, আমরা আমাদের ভেক্টর স্টোর অবজেক্টের অংশ হিসাবে ইতিমধ্যে বাস্তবায়িত স্ট্যান্ডার্ড পুনরুদ্ধার ব্যবহার করতে পারি -

আমরা এখন উদ্ধারকারীদের জিজ্ঞাসা করতে পারি। আমাদের কোয়েরির আউটপুট হবে ডকুমেন্ট অবজেক্ট যা কোয়েরির সাথে প্রাসঙ্গিক। এগুলি শেষ পর্যন্ত পরবর্তী বিভাগে প্রাসঙ্গিক প্রতিক্রিয়া তৈরি করতে ব্যবহার করা হবে।


আমাদের AI-চালিত ওয়ার্কফ্লো নির্মাতার সাথে ম্যানুয়াল কাজ এবং ওয়ার্কফ্লোগুলি স্বয়ংক্রিয় করুন, আপনার এবং আপনার দলের জন্য Nanonets দ্বারা ডিজাইন করা হয়েছে৷
মডিউল III: এজেন্ট
LangChain "এজেন্টস" নামে একটি শক্তিশালী ধারণা প্রবর্তন করে যা চেইনের ধারণাটিকে সম্পূর্ণ নতুন স্তরে নিয়ে যায়। এজেন্ট ভাষা মডেলগুলিকে গতিশীলভাবে সঞ্চালনের জন্য ক্রিয়াগুলির ক্রম নির্ধারণ করে, তাদের অবিশ্বাস্যভাবে বহুমুখী এবং অভিযোজিত করে তোলে। প্রথাগত চেইনের বিপরীতে, যেখানে ক্রিয়াগুলিকে কোডে হার্ডকোড করা হয়, এজেন্টরা কোন ক্রিয়াগুলি এবং কোন ক্রমে নিতে হবে তা সিদ্ধান্ত নিতে যুক্তিযুক্ত ইঞ্জিন হিসাবে ভাষা মডেলগুলিকে নিয়োগ করে।
প্রতিনিধি সিদ্ধান্ত গ্রহণের জন্য দায়ী মূল উপাদান। এটি একটি ভাষা মডেলের শক্তি এবং একটি নির্দিষ্ট উদ্দেশ্য অর্জনের জন্য পরবর্তী পদক্ষেপগুলি নির্ধারণ করার জন্য একটি প্রম্পট ব্যবহার করে। একটি এজেন্টের ইনপুটগুলি সাধারণত অন্তর্ভুক্ত করে:
- সরঞ্জাম: উপলব্ধ সরঞ্জামের বর্ণনা (পরে এই বিষয়ে আরও)।
- ব্যবহারকারীর ইনপুট: ব্যবহারকারীর কাছ থেকে উচ্চ-স্তরের উদ্দেশ্য বা প্রশ্ন।
- মধ্যবর্তী ধাপ: বর্তমান ব্যবহারকারীর ইনপুটে পৌঁছানোর জন্য (ক্রিয়া, টুল আউটপুট) জোড়ার ইতিহাস।
একটি এজেন্ট এর আউটপুট পরবর্তী হতে পারে কর্ম পদক্ষেপ নিতে (এজেন্ট অ্যাকশন) বা ফাইনাল প্রতিক্রিয়া ব্যবহারকারীকে পাঠাতে (এজেন্ট ফিনিশ)। একটি কর্ম একটি নির্দিষ্ট করে টুল এবং ইনপুট যে টুলের জন্য।
টুলস
টুল হল ইন্টারফেস যা একজন এজেন্ট বিশ্বের সাথে যোগাযোগ করতে ব্যবহার করতে পারে। তারা এজেন্টদের বিভিন্ন কাজ সম্পাদন করতে সক্ষম করে, যেমন ওয়েব অনুসন্ধান করা, শেল কমান্ড চালানো, বা বহিরাগত API অ্যাক্সেস করা। LangChain-এ, এজেন্টদের ক্ষমতা বাড়ানোর জন্য এবং বিভিন্ন কাজ সম্পন্ন করতে তাদের সক্ষম করার জন্য সরঞ্জামগুলি অপরিহার্য।
LangChain-এ সরঞ্জামগুলি ব্যবহার করতে, আপনি নিম্নলিখিত স্নিপেট ব্যবহার করে সেগুলি লোড করতে পারেন:
from langchain.agents import load_tools tool_names = [...]
tools = load_tools(tool_names)
কিছু টুল শুরু করার জন্য একটি বেস ল্যাঙ্গুয়েজ মডেল (LLM) প্রয়োজন হতে পারে। এই ধরনের ক্ষেত্রে, আপনি একটি এলএলএমও পাস করতে পারেন:
from langchain.agents import load_tools tool_names = [...]
llm = ...
tools = load_tools(tool_names, llm=llm)
এই সেটআপ আপনাকে বিভিন্ন ধরনের টুল অ্যাক্সেস করতে এবং আপনার এজেন্টের ওয়ার্কফ্লোতে সেগুলিকে একীভূত করতে দেয়। ব্যবহারের ডকুমেন্টেশন সহ সরঞ্জামগুলির সম্পূর্ণ তালিকা হল এখানে.
আসুন আমরা টুলের কিছু উদাহরণ দেখি।
DuckDuckGo
DuckDuckGo টুল আপনাকে এর সার্চ ইঞ্জিন ব্যবহার করে ওয়েব সার্চ করতে সক্ষম করে। এটি কীভাবে ব্যবহার করবেন তা এখানে:
from langchain.tools import DuckDuckGoSearchRun
search = DuckDuckGoSearchRun()
search.run("manchester united vs luton town match summary")

DataForSeo
DataForSeo টুলকিট আপনাকে DataForSeo API ব্যবহার করে সার্চ ইঞ্জিনের ফলাফল পেতে দেয়। এই টুলকিট ব্যবহার করতে, আপনাকে আপনার API শংসাপত্র সেট আপ করতে হবে৷ শংসাপত্রগুলি কীভাবে কনফিগার করবেন তা এখানে:
import os os.environ["DATAFORSEO_LOGIN"] = "<your_api_access_username>"
os.environ["DATAFORSEO_PASSWORD"] = "<your_api_access_password>"
আপনার শংসাপত্র সেট হয়ে গেলে, আপনি একটি তৈরি করতে পারেন DataForSeoAPIWrapper API অ্যাক্সেস করার টুল:
from langchain.utilities.dataforseo_api_search import DataForSeoAPIWrapper wrapper = DataForSeoAPIWrapper() result = wrapper.run("Weather in Los Angeles")
সার্জারির DataForSeoAPIWrapper টুল বিভিন্ন উৎস থেকে সার্চ ইঞ্জিন ফলাফল পুনরুদ্ধার করে।
আপনি JSON প্রতিক্রিয়ায় প্রত্যাবর্তিত ফলাফল এবং ক্ষেত্রগুলির ধরন কাস্টমাইজ করতে পারেন। উদাহরণস্বরূপ, আপনি ফলাফলের ধরন, ক্ষেত্র নির্দিষ্ট করতে পারেন এবং সেরা ফলাফলের সংখ্যার জন্য সর্বোচ্চ গণনা সেট করতে পারেন:
json_wrapper = DataForSeoAPIWrapper( json_result_types=["organic", "knowledge_graph", "answer_box"], json_result_fields=["type", "title", "description", "text"], top_count=3,
) json_result = json_wrapper.results("Bill Gates")
এই উদাহরণটি ফলাফলের ধরন, ক্ষেত্র নির্দিষ্ট করে এবং ফলাফলের সংখ্যা সীমিত করে JSON প্রতিক্রিয়া কাস্টমাইজ করে।
আপনি API র্যাপারে অতিরিক্ত প্যারামিটার পাস করে আপনার অনুসন্ধান ফলাফলের জন্য অবস্থান এবং ভাষা নির্দিষ্ট করতে পারেন:
customized_wrapper = DataForSeoAPIWrapper( top_count=10, json_result_types=["organic", "local_pack"], json_result_fields=["title", "description", "type"], params={"location_name": "Germany", "language_code": "en"},
) customized_result = customized_wrapper.results("coffee near me")
অবস্থান এবং ভাষা পরামিতি প্রদান করে, আপনি নির্দিষ্ট অঞ্চল এবং ভাষার জন্য আপনার অনুসন্ধানের ফলাফলগুলিকে উপযোগী করতে পারেন৷
আপনি যে সার্চ ইঞ্জিন ব্যবহার করতে চান তা বেছে নেওয়ার নমনীয়তা আপনার আছে। শুধু পছন্দসই সার্চ ইঞ্জিন নির্দিষ্ট করুন:
customized_wrapper = DataForSeoAPIWrapper( top_count=10, json_result_types=["organic", "local_pack"], json_result_fields=["title", "description", "type"], params={"location_name": "Germany", "language_code": "en", "se_name": "bing"},
) customized_result = customized_wrapper.results("coffee near me")
এই উদাহরণে, সার্চ ইঞ্জিন হিসাবে Bing ব্যবহার করার জন্য অনুসন্ধান কাস্টমাইজ করা হয়েছে।
এপিআই র্যাপার আপনাকে আপনি যে ধরনের অনুসন্ধান করতে চান তা নির্দিষ্ট করার অনুমতি দেয়। উদাহরণস্বরূপ, আপনি একটি মানচিত্র অনুসন্ধান করতে পারেন:
maps_search = DataForSeoAPIWrapper( top_count=10, json_result_fields=["title", "value", "address", "rating", "type"], params={ "location_coordinate": "52.512,13.36,12z", "language_code": "en", "se_type": "maps", },
) maps_search_result = maps_search.results("coffee near me")
এটি মানচিত্র-সম্পর্কিত তথ্য পুনরুদ্ধার করতে অনুসন্ধানকে কাস্টমাইজ করে।
শেল (ব্যাশ)
শেল টুলকিট এজেন্টদের শেল এনভায়রনমেন্টে অ্যাক্সেস প্রদান করে, তাদের শেল কমান্ড চালানোর অনুমতি দেয়। এই বৈশিষ্ট্যটি শক্তিশালী কিন্তু সতর্কতার সাথে ব্যবহার করা উচিত, বিশেষ করে স্যান্ডবক্সযুক্ত পরিবেশে। এখানে আপনি শেল টুল ব্যবহার করতে পারেন কিভাবে:
from langchain.tools import ShellTool shell_tool = ShellTool() result = shell_tool.run({"commands": ["echo 'Hello World!'", "time"]})
এই উদাহরণে, শেল টুল দুটি শেল কমান্ড চালায়: "হ্যালো ওয়ার্ল্ড!" প্রতিধ্বনি। এবং বর্তমান সময় প্রদর্শন।

আপনি আরও জটিল কাজ সম্পাদন করার জন্য একজন এজেন্টকে শেল টুল প্রদান করতে পারেন। এখানে শেল টুল ব্যবহার করে একটি ওয়েব পৃষ্ঠা থেকে লিঙ্ক আনার একটি এজেন্টের উদাহরণ রয়েছে:
from langchain.agents import AgentType, initialize_agent
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(temperature=0.1) shell_tool.description = shell_tool.description + f"args {shell_tool.args}".replace( "{", "{{"
).replace("}", "}}")
self_ask_with_search = initialize_agent( [shell_tool], llm, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
self_ask_with_search.run( "Download the langchain.com webpage and grep for all urls. Return only a sorted list of them. Be sure to use double quotes."
)
এই পরিস্থিতিতে, এজেন্ট শেল টুল ব্যবহার করে একটি ওয়েব পেজ থেকে ইউআরএল আনতে, ফিল্টার করতে এবং সাজানোর জন্য কমান্ডের একটি ক্রম চালায়।
প্রদত্ত উদাহরণগুলি LangChain-এ উপলব্ধ কিছু সরঞ্জাম প্রদর্শন করে। এই সরঞ্জামগুলি শেষ পর্যন্ত এজেন্টদের ক্ষমতা প্রসারিত করে (পরবর্তী উপধারায় অন্বেষণ করা হয়েছে) এবং দক্ষতার সাথে বিভিন্ন কাজ সম্পাদন করতে তাদের ক্ষমতায়ন করে। আপনার প্রয়োজনীয়তার উপর নির্ভর করে, আপনি আপনার প্রজেক্টের প্রয়োজনের সাথে সবচেয়ে উপযুক্ত টুল এবং টুলকিটগুলি বেছে নিতে পারেন এবং সেগুলিকে আপনার এজেন্টের ওয়ার্কফ্লোতে একীভূত করতে পারেন।
এজেন্ট-এ ফেরত যান
এখন এজেন্টদের দিকে যাওয়া যাক।
AgentExecutor হল একজন এজেন্টের জন্য রানটাইম পরিবেশ। এটি এজেন্টকে কল করার জন্য, এটি বেছে নেওয়া ক্রিয়াগুলি সম্পাদন করার জন্য, এজেন্টের কাছে অ্যাকশন আউটপুটগুলি ফেরত দেওয়ার জন্য এবং এজেন্ট শেষ না হওয়া পর্যন্ত প্রক্রিয়াটি পুনরাবৃত্তি করার জন্য দায়ী৷ সিউডোকোডে, AgentExecutor এরকম কিছু দেখতে পারে:
next_action = agent.get_action(...)
while next_action != AgentFinish: observation = run(next_action) next_action = agent.get_action(..., next_action, observation)
return next_action
AgentExecutor বিভিন্ন জটিলতাগুলি পরিচালনা করে, যেমন এমন ক্ষেত্রে মোকাবেলা করা যেখানে এজেন্ট একটি অস্তিত্বহীন টুল নির্বাচন করে, টুলের ত্রুটিগুলি পরিচালনা করে, এজেন্ট-উত্পাদিত আউটপুটগুলি পরিচালনা করে এবং সমস্ত স্তরে লগিং এবং পর্যবেক্ষণযোগ্যতা প্রদান করে।
LangChain-এ AgentExecutor ক্লাস হল প্রাথমিক এজেন্ট রানটাইম, সেখানে অন্যান্য, আরও পরীক্ষামূলক রানটাইম সমর্থিত, যার মধ্যে রয়েছে:
- প্ল্যান এবং এক্সিকিউট এজেন্ট
- বেবি এজিআই
- অটো জিপিটি
এজেন্ট ফ্রেমওয়ার্ক সম্পর্কে আরও ভালোভাবে বোঝার জন্য, আসুন স্ক্র্যাচ থেকে একটি মৌলিক এজেন্ট তৈরি করি এবং তারপরে পূর্ব-নির্মিত এজেন্ট অন্বেষণ করতে এগিয়ে যান।
আমরা এজেন্ট তৈরিতে ডুব দেওয়ার আগে, কিছু মূল পরিভাষা এবং স্কিমা পুনর্বিবেচনা করা অপরিহার্য:
- এজেন্ট অ্যাকশন: এটি একটি ডেটা শ্রেণী যা প্রতিনিধিত্ব করে একটি এজেন্টের করা উচিত৷ এটি একটি নিয়ে গঠিত
toolসম্পত্তি (আবহ করার টুলের নাম) এবং কtool_inputসম্পত্তি (সেই টুলের জন্য ইনপুট)। - এজেন্ট ফিনিশ: এই ডেটা ক্লাসটি নির্দেশ করে যে এজেন্ট তার কাজ শেষ করেছে এবং ব্যবহারকারীকে একটি প্রতিক্রিয়া ফেরত দেওয়া উচিত। এটি সাধারণত রিটার্ন মানগুলির একটি অভিধান অন্তর্ভুক্ত করে, প্রায়শই একটি কী "আউটপুট" সহ প্রতিক্রিয়া পাঠ্য থাকে।
- মধ্যবর্তী ধাপ: এগুলি হল পূর্ববর্তী এজেন্ট ক্রিয়াকলাপ এবং সংশ্লিষ্ট আউটপুটগুলির রেকর্ড৷ এজেন্টের ভবিষ্যতের পুনরাবৃত্তির প্রসঙ্গ পাস করার জন্য এগুলি অত্যন্ত গুরুত্বপূর্ণ।
আমাদের উদাহরণে, আমরা আমাদের এজেন্ট তৈরি করতে OpenAI ফাংশন কলিং ব্যবহার করব। এই পদ্ধতি এজেন্ট তৈরির জন্য নির্ভরযোগ্য। আমরা একটি সহজ টুল তৈরি করে শুরু করব যা একটি শব্দের দৈর্ঘ্য গণনা করে। এই টুলটি দরকারী কারণ ভাষার মডেলগুলি কখনও কখনও শব্দের দৈর্ঘ্য গণনা করার সময় টোকেনাইজেশনের কারণে ভুল করতে পারে।
প্রথমে, আসুন আমরা এজেন্টকে নিয়ন্ত্রণ করতে যে ভাষা মডেলটি ব্যবহার করব তা লোড করি:
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
আসুন একটি শব্দ দৈর্ঘ্য গণনা সহ মডেলটি পরীক্ষা করি:
llm.invoke("how many letters in the word educa?")
প্রতিক্রিয়াটি "educa" শব্দের অক্ষরের সংখ্যা নির্দেশ করবে।
এর পরে, আমরা একটি শব্দের দৈর্ঘ্য গণনা করার জন্য একটি সাধারণ পাইথন ফাংশন সংজ্ঞায়িত করব:
from langchain.agents import tool @tool
def get_word_length(word: str) -> int: """Returns the length of a word.""" return len(word)
আমরা নামের একটি টুল তৈরি করেছি get_word_length যেটি একটি শব্দকে ইনপুট হিসেবে নেয় এবং এর দৈর্ঘ্য প্রদান করে।
এখন, এজেন্টের জন্য প্রম্পট তৈরি করা যাক। প্রম্পট এজেন্টকে নির্দেশ দেয় কিভাবে যুক্তি এবং আউটপুট ফর্ম্যাট করতে হয়। আমাদের ক্ষেত্রে, আমরা OpenAI ফাংশন কলিং ব্যবহার করছি, যার জন্য ন্যূনতম নির্দেশাবলী প্রয়োজন। আমরা ব্যবহারকারীর ইনপুট এবং এজেন্ট স্ক্র্যাচপ্যাডের জন্য স্থানধারক সহ প্রম্পটটি সংজ্ঞায়িত করব:
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a very powerful assistant but not great at calculating word lengths.", ), ("user", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"), ]
)
এখন, এজেন্ট কীভাবে জানে যে এটি কোন সরঞ্জামগুলি ব্যবহার করতে পারে? আমরা OpenAI ফাংশন কলিং ল্যাঙ্গুয়েজ মডেলের উপর নির্ভর করছি, যার জন্য আলাদাভাবে ফাংশন পাস করতে হবে। এজেন্টকে আমাদের টুল সরবরাহ করতে, আমরা সেগুলিকে OpenAI ফাংশন কল হিসাবে ফর্ম্যাট করব:
from langchain.tools.render import format_tool_to_openai_function llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools])
এখন, আমরা ইনপুট ম্যাপিং সংজ্ঞায়িত করে এবং উপাদানগুলিকে সংযুক্ত করে এজেন্ট তৈরি করতে পারি:
এটি LCEL ভাষা। আমরা এই বিষয়ে পরে বিস্তারিত আলোচনা করব।
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai _function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
)
আমরা আমাদের এজেন্ট তৈরি করেছি, যা ব্যবহারকারীর ইনপুট বোঝে, উপলব্ধ সরঞ্জাম ব্যবহার করে এবং আউটপুট ফর্ম্যাট করে। এখন, এর সাথে যোগাযোগ করা যাক:
agent.invoke({"input": "how many letters in the word educa?", "intermediate_steps": []})
এজেন্টকে একটি AgentAction দিয়ে প্রতিক্রিয়া জানাতে হবে, যা পরবর্তী পদক্ষেপ নিতে হবে তা নির্দেশ করে।
আমরা এজেন্ট তৈরি করেছি, কিন্তু এখন আমাদের এটির জন্য একটি রানটাইম লিখতে হবে। সবচেয়ে সহজ রানটাইম হল যেটি ক্রমাগত এজেন্টকে কল করে, অ্যাকশন চালায় এবং এজেন্ট শেষ না হওয়া পর্যন্ত পুনরাবৃত্তি করে। এখানে একটি উদাহরণ:
from langchain.schema.agent import AgentFinish user_input = "how many letters in the word educa?"
intermediate_steps = [] while True: output = agent.invoke( { "input": user_input, "intermediate_steps": intermediate_steps, } ) if isinstance(output, AgentFinish): final_result = output.return_values["output"] break else: print(f"TOOL NAME: {output.tool}") print(f"TOOL INPUT: {output.tool_input}") tool = {"get_word_length": get_word_length}[output.tool] observation = tool.run(output.tool_input) intermediate_steps.append((output, observation)) print(final_result)
এই লুপে, আমরা বারবার এজেন্টকে কল করি, অ্যাকশন চালাই এবং এজেন্ট শেষ না হওয়া পর্যন্ত মধ্যবর্তী ধাপগুলি আপডেট করি। আমরা লুপের মধ্যে টুল ইন্টারঅ্যাকশনও পরিচালনা করি।

এই প্রক্রিয়াটিকে সহজ করার জন্য, LangChain AgentExecutor ক্লাস প্রদান করে, যা এজেন্ট এক্সিকিউশনকে এনক্যাপসুলেট করে এবং এরর হ্যান্ডলিং, তাড়াতাড়ি থামানো, ট্রেসিং এবং অন্যান্য উন্নতি অফার করে। আসুন এজেন্টের সাথে ইন্টারঅ্যাক্ট করতে AgentExecutor ব্যবহার করি:
from langchain.agents import AgentExecutor agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True) agent_executor.invoke({"input": "how many letters in the word educa?"})
AgentExecutor কার্যকর করার প্রক্রিয়া সহজ করে এবং এজেন্টের সাথে যোগাযোগ করার একটি সুবিধাজনক উপায় প্রদান করে।
স্মৃতি নিয়েও পরে বিস্তারিত আলোচনা করা হয়েছে।
আমরা এখন পর্যন্ত যে এজেন্ট তৈরি করেছি তা স্টেটলেস, মানে এটি আগের মিথস্ক্রিয়া মনে রাখে না। ফলো-আপ প্রশ্ন এবং কথোপকথন সক্ষম করতে, আমাদের এজেন্টে মেমরি যোগ করতে হবে। এটি দুটি পদক্ষেপ জড়িত:
- চ্যাট ইতিহাস সঞ্চয় করার জন্য প্রম্পটে একটি মেমরি ভেরিয়েবল যোগ করুন।
- মিথস্ক্রিয়া চলাকালীন চ্যাট ইতিহাসের উপর নজর রাখুন।
প্রম্পটে একটি মেমরি প্লেসহোল্ডার যোগ করে শুরু করা যাক:
from langchain.prompts import MessagesPlaceholder MEMORY_KEY = "chat_history"
prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a very powerful assistant but not great at calculating word lengths.", ), MessagesPlaceholder(variable_name=MEMORY_KEY), ("user", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"), ]
)
এখন, চ্যাটের ইতিহাস ট্র্যাক করতে একটি তালিকা তৈরি করুন:
from langchain.schema.messages import HumanMessage, AIMessage chat_history = []
এজেন্ট তৈরির ধাপে, আমরা মেমরিটিও অন্তর্ভুক্ত করব:
agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), "chat_history": lambda x: x["chat_history"], } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
)
এখন, এজেন্ট চালানোর সময়, চ্যাটের ইতিহাস আপডেট করতে ভুলবেন না:
input1 = "how many letters in the word educa?"
result = agent_executor.invoke({"input": input1, "chat_history": chat_history})
chat_history.extend([ HumanMessage(content=input1), AIMessage(content=result["output"]),
])
agent_executor.invoke({"input": "is that a real word?", "chat_history": chat_history})
এটি এজেন্টকে কথোপকথনের ইতিহাস বজায় রাখতে এবং পূর্ববর্তী মিথস্ক্রিয়াগুলির উপর ভিত্তি করে ফলো-আপ প্রশ্নের উত্তর দিতে সক্ষম করে।
অভিনন্দন! আপনি LangChain-এ আপনার প্রথম এন্ড-টু-এন্ড এজেন্ট সফলভাবে তৈরি ও সম্পাদন করেছেন। LangChain এর ক্ষমতার গভীরে অনুসন্ধান করতে, আপনি অন্বেষণ করতে পারেন:
- বিভিন্ন এজেন্ট প্রকার সমর্থিত।
- প্রাক-নির্মিত এজেন্ট
- টুলস এবং টুল ইন্টিগ্রেশনের সাথে কিভাবে কাজ করবেন।
এজেন্ট প্রকার
LangChain বিভিন্ন ধরণের এজেন্ট অফার করে, প্রতিটি নির্দিষ্ট ব্যবহারের ক্ষেত্রে উপযুক্ত। এখানে কিছু উপলব্ধ এজেন্ট রয়েছে:
- জিরো-শট প্রতিক্রিয়া: এই এজেন্ট শুধুমাত্র তাদের বর্ণনার উপর ভিত্তি করে টুল বেছে নিতে ReAct ফ্রেমওয়ার্ক ব্যবহার করে। এটি প্রতিটি টুলের জন্য বর্ণনা প্রয়োজন এবং অত্যন্ত বহুমুখী।
- স্ট্রাকচার্ড ইনপুট ReAct: এই এজেন্ট মাল্টি-ইনপুট টুল পরিচালনা করে এবং একটি ওয়েব ব্রাউজার নেভিগেট করার মতো জটিল কাজের জন্য উপযুক্ত। এটি কাঠামোগত ইনপুটের জন্য একটি সরঞ্জামের আর্গুমেন্ট স্কিমা ব্যবহার করে।
- OpenAI ফাংশন: বিশেষভাবে ফাংশন কলিংয়ের জন্য সূক্ষ্ম-সুর করা মডেলগুলির জন্য ডিজাইন করা হয়েছে, এই এজেন্টটি gpt-3.5-turbo-0613 এবং gpt-4-0613-এর মতো মডেলগুলির সাথে সামঞ্জস্যপূর্ণ। আমরা উপরে আমাদের প্রথম এজেন্ট তৈরি করতে এটি ব্যবহার করেছি।
- কথোপকথনমূলক: কথোপকথন সেটিংসের জন্য ডিজাইন করা, এই এজেন্ট টুল নির্বাচনের জন্য ReAct ব্যবহার করে এবং পূর্ববর্তী মিথস্ক্রিয়া মনে রাখার জন্য মেমরি ব্যবহার করে।
- অনুসন্ধানের সাথে নিজেকে জিজ্ঞাসা করুন: এই এজেন্ট একটি একক টুলের উপর নির্ভর করে, "ইন্টারমিডিয়েট উত্তর", যা প্রশ্নের বাস্তবিক উত্তর খোঁজে। এটি সার্চ পেপারের সাথে মূল স্ব-জিজ্ঞাসা সমতুল্য।
- প্রতিক্রিয়া নথির দোকান: এই এজেন্ট ReAct ফ্রেমওয়ার্ক ব্যবহার করে একটি ডকুমেন্ট স্টোরের সাথে যোগাযোগ করে। এটির জন্য "অনুসন্ধান" এবং "লুকআপ" সরঞ্জামগুলির প্রয়োজন এবং এটি আসল ReAct পেপারের উইকিপিডিয়া উদাহরণের মতো৷
LangChain-এ আপনার প্রয়োজন অনুসারে সবচেয়ে উপযুক্ত একটি খুঁজে পেতে এই এজেন্টের ধরনগুলি অন্বেষণ করুন। এই এজেন্টগুলি আপনাকে তাদের মধ্যে ক্রিয়াকলাপ পরিচালনা করতে এবং প্রতিক্রিয়া তৈরি করতে সরঞ্জামগুলির সেট বাঁধতে দেয়। আরো জানুন কিভাবে এখানে টুল দিয়ে আপনার নিজস্ব এজেন্ট তৈরি করবেন.
পূর্বনির্মাণ এজেন্ট
আসুন LangChain-এ উপলব্ধ প্রি-বিল্ট এজেন্টগুলির উপর ফোকাস করে আমাদের এজেন্টদের অনুসন্ধান চালিয়ে যাই।
জিমেইল
LangChain একটি Gmail টুলকিট অফার করে যা আপনাকে আপনার LangChain ইমেলকে Gmail API এর সাথে সংযুক্ত করতে দেয়। শুরু করার জন্য, আপনাকে আপনার শংসাপত্রগুলি সেট আপ করতে হবে, যা Gmail API ডকুমেন্টেশনে ব্যাখ্যা করা হয়েছে৷ একবার আপনি ডাউনলোড করেছেন credentials.json ফাইল, আপনি Gmail API ব্যবহার করে এগিয়ে যেতে পারেন। অতিরিক্তভাবে, আপনাকে নিম্নলিখিত কমান্ডগুলি ব্যবহার করে কিছু প্রয়োজনীয় লাইব্রেরি ইনস্টল করতে হবে:
pip install --upgrade google-api-python-client > /dev/null
pip install --upgrade google-auth-oauthlib > /dev/null
pip install --upgrade google-auth-httplib2 > /dev/null
pip install beautifulsoup4 > /dev/null # Optional for parsing HTML messages
আপনি নিম্নলিখিত হিসাবে Gmail টুলকিট তৈরি করতে পারেন:
from langchain.agents.agent_toolkits import GmailToolkit toolkit = GmailToolkit()
আপনি আপনার প্রয়োজন অনুযায়ী প্রমাণীকরণ কাস্টমাইজ করতে পারেন। পর্দার পিছনে, নিম্নলিখিত পদ্ধতিগুলি ব্যবহার করে একটি googleapi সংস্থান তৈরি করা হয়েছে:
from langchain.tools.gmail.utils import build_resource_service, get_gmail_credentials credentials = get_gmail_credentials( token_file="token.json", scopes=["https://mail.google.com/"], client_secrets_file="credentials.json",
)
api_resource = build_resource_service(credentials=credentials)
toolkit = GmailToolkit(api_resource=api_resource)
টুলকিট বিভিন্ন সরঞ্জাম অফার করে যা একটি এজেন্টের মধ্যে ব্যবহার করা যেতে পারে, যার মধ্যে রয়েছে:
GmailCreateDraft: নির্দিষ্ট বার্তা ক্ষেত্র সহ একটি খসড়া ইমেল তৈরি করুন৷GmailSendMessage: ইমেল বার্তা পাঠান.GmailSearch: ইমেল বার্তা বা থ্রেড অনুসন্ধান করুন.GmailGetMessage: বার্তা আইডি দ্বারা একটি ইমেল আনুন.GmailGetThread: ইমেল বার্তা অনুসন্ধান করুন.
একটি এজেন্টের মধ্যে এই সরঞ্জামগুলি ব্যবহার করার জন্য, আপনি নিম্নরূপ এজেন্ট শুরু করতে পারেন:
from langchain.llms import OpenAI
from langchain.agents import initialize_agent, AgentType llm = OpenAI(temperature=0)
agent = initialize_agent( tools=toolkit.get_tools(), llm=llm, agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
)
এই সরঞ্জামগুলি কীভাবে ব্যবহার করা যেতে পারে তার কয়েকটি উদাহরণ এখানে দেওয়া হল:
- সম্পাদনার জন্য একটি Gmail খসড়া তৈরি করুন:
agent.run( "Create a gmail draft for me to edit of a letter from the perspective of a sentient parrot " "who is looking to collaborate on some research with her estranged friend, a cat. " "Under no circumstances may you send the message, however."
)
- আপনার খসড়াগুলিতে সর্বশেষ ইমেল অনুসন্ধান করুন:
agent.run("Could you search in my drafts for the latest email?")
এই উদাহরণগুলি একটি এজেন্টের মধ্যে LangChain-এর Gmail টুলকিটের ক্ষমতা প্রদর্শন করে, যা আপনাকে প্রোগ্রামগতভাবে Gmail এর সাথে যোগাযোগ করতে সক্ষম করে।
এসকিউএল ডাটাবেস এজেন্ট
এই বিভাগটি এসকিউএল ডাটাবেসের সাথে ইন্টারঅ্যাক্ট করার জন্য ডিজাইন করা একটি এজেন্টের একটি ওভারভিউ প্রদান করে, বিশেষ করে চিনুক ডাটাবেস। এই এজেন্ট একটি ডাটাবেস সম্পর্কে সাধারণ প্রশ্নের উত্তর দিতে পারে এবং ত্রুটিগুলি থেকে পুনরুদ্ধার করতে পারে। দয়া করে মনে রাখবেন যে এটি এখনও সক্রিয় বিকাশে রয়েছে এবং সমস্ত উত্তর সঠিক নাও হতে পারে। সংবেদনশীল ডেটাতে এটি চালানোর সময় সতর্ক থাকুন, কারণ এটি আপনার ডাটাবেসে DML বিবৃতি সম্পাদন করতে পারে।
এই এজেন্টটি ব্যবহার করতে, আপনি এটিকে নিম্নরূপ শুরু করতে পারেন:
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.sql_database import SQLDatabase
from langchain.llms.openai import OpenAI
from langchain.agents import AgentExecutor
from langchain.agents.agent_types import AgentType
from langchain.chat_models import ChatOpenAI db = SQLDatabase.from_uri("sqlite:///../../../../../notebooks/Chinook.db")
toolkit = SQLDatabaseToolkit(db=db, llm=OpenAI(temperature=0)) agent_executor = create_sql_agent( llm=OpenAI(temperature=0), toolkit=toolkit, verbose=True, agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)
এই এজেন্ট ব্যবহার করে আরম্ভ করা যেতে পারে ZERO_SHOT_REACT_DESCRIPTION এজেন্ট প্রকার। এটি প্রশ্নের উত্তর এবং বিবরণ প্রদানের জন্য ডিজাইন করা হয়েছে। বিকল্পভাবে, আপনি ব্যবহার করে এজেন্ট শুরু করতে পারেন OPENAI_FUNCTIONS OpenAI এর GPT-3.5-টার্বো মডেলের সাথে এজেন্ট টাইপ, যা আমরা আমাদের আগের ক্লায়েন্টে ব্যবহার করেছি।
দায়িত্ব অস্বীকার
- ক্যোয়ারী চেইন সন্নিবেশ/আপডেট/ডিলিট কোয়েরি তৈরি করতে পারে। সতর্ক থাকুন, এবং একটি কাস্টম প্রম্পট ব্যবহার করুন বা প্রয়োজনে লেখার অনুমতি ছাড়াই একটি SQL ব্যবহারকারী তৈরি করুন।
- সচেতন হোন যে কিছু কোয়েরি চালানো, যেমন "সম্ভব সবচেয়ে বড় কোয়েরি চালান" আপনার SQL ডাটাবেসকে ওভারলোড করতে পারে, বিশেষ করে যদি এতে লক্ষ লক্ষ সারি থাকে।
- ডেটা গুদাম-ভিত্তিক ডেটাবেসগুলি প্রায়শই সংস্থান ব্যবহার সীমিত করতে ব্যবহারকারী-স্তরের কোটা সমর্থন করে।
আপনি এজেন্টকে একটি টেবিল বর্ণনা করতে বলতে পারেন, যেমন "প্লেলিস্টট্র্যাক" টেবিল। এটি কিভাবে করতে হয় তার একটি উদাহরণ এখানে:
agent_executor.run("Describe the playlisttrack table")
এজেন্ট টেবিলের স্কিমা এবং নমুনা সারি সম্পর্কে তথ্য প্রদান করবে।
যদি আপনি ভুলবশত এমন একটি টেবিল সম্পর্কে জিজ্ঞাসা করেন যেটির অস্তিত্ব নেই, তাহলে এজেন্ট পুনরুদ্ধার করতে পারে এবং নিকটতম মেলানো টেবিল সম্পর্কে তথ্য প্রদান করতে পারে। উদাহরণ স্বরূপ:
agent_executor.run("Describe the playlistsong table")
এজেন্ট নিকটতম মিলিত টেবিল খুঁজে বের করবে এবং এটি সম্পর্কে তথ্য প্রদান করবে।
আপনি এজেন্টকে ডাটাবেসে প্রশ্ন চালাতেও বলতে পারেন। এই ক্ষেত্রে:
agent_executor.run("List the total sales per country. Which country's customers spent the most?")
এজেন্ট ক্যোয়ারীটি চালাবে এবং ফলাফল প্রদান করবে, যেমন দেশের সর্বোচ্চ মোট বিক্রয় আছে।
প্রতিটি প্লেলিস্টে মোট ট্র্যাকের সংখ্যা পেতে, আপনি নিম্নলিখিত ক্যোয়ারী ব্যবহার করতে পারেন:
agent_executor.run("Show the total number of tracks in each playlist. The Playlist name should be included in the result.")
এজেন্ট সংশ্লিষ্ট মোট ট্র্যাকের সংখ্যা সহ প্লেলিস্টের নামগুলি ফেরত দেবে।
যে ক্ষেত্রে এজেন্ট ত্রুটির সম্মুখীন হয়, এটি পুনরুদ্ধার করতে পারে এবং সঠিক প্রতিক্রিয়া প্রদান করতে পারে। এই ক্ষেত্রে:
agent_executor.run("Who are the top 3 best selling artists?")
এমনকি একটি প্রাথমিক ত্রুটির সম্মুখীন হওয়ার পরেও, এজেন্ট সামঞ্জস্য করবে এবং সঠিক উত্তর প্রদান করবে, যা এই ক্ষেত্রে, শীর্ষ 3 সেরা-বিক্রীত শিল্পী।
পান্ডাস ডেটাফ্রেম এজেন্ট
এই বিভাগে প্রশ্ন-উত্তর দেওয়ার উদ্দেশ্যে পান্ডাস ডেটাফ্রেমের সাথে যোগাযোগ করার জন্য ডিজাইন করা একটি এজেন্টের পরিচয় দেওয়া হয়েছে। অনুগ্রহ করে মনে রাখবেন যে এই এজেন্ট একটি ভাষা মডেল (LLM) দ্বারা উত্পন্ন পাইথন কোড চালানোর জন্য হুডের নিচে পাইথন এজেন্ট ব্যবহার করে। LLM দ্বারা উত্পন্ন ক্ষতিকারক পাইথন কোড থেকে সম্ভাব্য ক্ষতি রোধ করতে এই এজেন্ট ব্যবহার করার সময় সতর্কতা অবলম্বন করুন।
আপনি নিম্নলিখিত হিসাবে পান্ডাস ডেটাফ্রেম এজেন্ট শুরু করতে পারেন:
from langchain_experimental.agents.agent_toolkits import create_pandas_dataframe_agent
from langchain.chat_models import ChatOpenAI
from langchain.agents.agent_types import AgentType from langchain.llms import OpenAI
import pandas as pd df = pd.read_csv("titanic.csv") # Using ZERO_SHOT_REACT_DESCRIPTION agent type
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), df, verbose=True) # Alternatively, using OPENAI_FUNCTIONS agent type
# agent = create_pandas_dataframe_agent(
# ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613"),
# df,
# verbose=True,
# agent_type=AgentType.OPENAI_FUNCTIONS,
# )
আপনি এজেন্টকে ডেটাফ্রেমে সারির সংখ্যা গণনা করতে বলতে পারেন:
agent.run("how many rows are there?")
এজেন্ট কোডটি কার্যকর করবে df.shape[0] এবং উত্তর প্রদান করুন, যেমন "ডেটাফ্রেমে 891টি সারি আছে।"
আপনি এজেন্টকে নির্দিষ্ট মানদণ্ডের উপর ভিত্তি করে সারিগুলি ফিল্টার করতেও বলতে পারেন, যেমন 3 জনের বেশি ভাইবোনের সংখ্যা খুঁজে বের করা:
agent.run("how many people have more than 3 siblings")
এজেন্ট কোডটি কার্যকর করবে df[df['SibSp'] > 3].shape[0] এবং উত্তর প্রদান করুন, যেমন "30 জনের 3 জনের বেশি ভাইবোন আছে।"
আপনি যদি গড় বয়সের বর্গমূল গণনা করতে চান, আপনি এজেন্টকে জিজ্ঞাসা করতে পারেন:
agent.run("whats the square root of the average age?")
এজেন্ট ব্যবহার করে গড় বয়স গণনা করবে df['Age'].mean() এবং তারপর ব্যবহার করে বর্গমূল গণনা করুন math.sqrt(). এটি উত্তর প্রদান করবে, যেমন "গড় বয়সের বর্গমূল হল 5.449689683556195।"
আসুন ডেটাফ্রেমের একটি অনুলিপি তৈরি করি, এবং অনুপস্থিত বয়সের মানগুলি গড় বয়স দিয়ে পূর্ণ হয়:
df1 = df.copy()
df1["Age"] = df1["Age"].fillna(df1["Age"].mean())
তারপর, আপনি উভয় ডেটাফ্রেম দিয়ে এজেন্টকে আরম্ভ করতে পারেন এবং এটিকে একটি প্রশ্ন জিজ্ঞাসা করতে পারেন:
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), [df, df1], verbose=True)
agent.run("how many rows in the age column are different?")
এজেন্ট উভয় ডেটাফ্রেমের বয়সের কলামের তুলনা করবে এবং উত্তর দেবে, যেমন "বয়স কলামের 177 সারি ভিন্ন।"
জিরা টুলকিট
এই বিভাগটি ব্যাখ্যা করে যে কীভাবে জিরা টুলকিট ব্যবহার করতে হয়, যা এজেন্টদের জিরা উদাহরণের সাথে যোগাযোগ করতে দেয়। আপনি এই টুলকিট ব্যবহার করে সমস্যাগুলি অনুসন্ধান এবং সমস্যা তৈরি করার মতো বিভিন্ন ক্রিয়া সম্পাদন করতে পারেন। এটি অ্যাটলাসিয়ান-পাইথন-এপিআই লাইব্রেরি ব্যবহার করে। এই টুলকিটটি ব্যবহার করার জন্য, আপনাকে আপনার জিরা উদাহরণের জন্য পরিবেশ ভেরিয়েবল সেট করতে হবে, যার মধ্যে JIRA_API_TOKEN, JIRA_USERNAME, এবং JIRA_INSTANCE_URL রয়েছে৷ অতিরিক্তভাবে, আপনাকে একটি পরিবেশ পরিবর্তনশীল হিসাবে আপনার OpenAI API কী সেট করতে হতে পারে।
শুরু করতে, atlassian-python-api লাইব্রেরি ইনস্টল করুন এবং প্রয়োজনীয় পরিবেশ ভেরিয়েবল সেট করুন:
%pip install atlassian-python-api import os
from langchain.agents import AgentType
from langchain.agents import initialize_agent
from langchain.agents.agent_toolkits.jira.toolkit import JiraToolkit
from langchain.llms import OpenAI
from langchain.utilities.jira import JiraAPIWrapper os.environ["JIRA_API_TOKEN"] = "abc"
os.environ["JIRA_USERNAME"] = "123"
os.environ["JIRA_INSTANCE_URL"] = "https://jira.atlassian.com"
os.environ["OPENAI_API_KEY"] = "xyz" llm = OpenAI(temperature=0)
jira = JiraAPIWrapper()
toolkit = JiraToolkit.from_jira_api_wrapper(jira)
agent = initialize_agent( toolkit.get_tools(), llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
আপনি একটি সারাংশ এবং বিবরণ সহ একটি নির্দিষ্ট প্রকল্পে একটি নতুন সমস্যা তৈরি করার জন্য এজেন্টকে নির্দেশ দিতে পারেন:
agent.run("make a new issue in project PW to remind me to make more fried rice")
এজেন্ট সমস্যাটি তৈরি করতে প্রয়োজনীয় পদক্ষেপগুলি সম্পাদন করবে এবং একটি প্রতিক্রিয়া প্রদান করবে, যেমন "প্রজেক্ট পিডব্লিউ-তে একটি নতুন সমস্যা তৈরি করা হয়েছে যার সারাংশ 'আরো ফ্রাইড রাইস তৈরি করুন' এবং 'আরো ফ্রাইড রাইস তৈরি করার জন্য অনুস্মারক'।
এটি আপনাকে প্রাকৃতিক ভাষার নির্দেশাবলী এবং জিরা টুলকিট ব্যবহার করে আপনার জিরা উদাহরণের সাথে যোগাযোগ করতে দেয়।
আমাদের AI-চালিত ওয়ার্কফ্লো নির্মাতার সাথে ম্যানুয়াল কাজ এবং ওয়ার্কফ্লোগুলি স্বয়ংক্রিয় করুন, আপনার এবং আপনার দলের জন্য Nanonets দ্বারা ডিজাইন করা হয়েছে৷
মডিউল IV: চেইন
LangChain হল একটি টুল যা জটিল অ্যাপ্লিকেশনগুলিতে লার্জ ল্যাঙ্গুয়েজ মডেল (LLMs) ব্যবহার করার জন্য ডিজাইন করা হয়েছে। এটি এলএলএম এবং অন্যান্য ধরণের উপাদান সহ উপাদানগুলির চেইন তৈরির জন্য কাঠামো সরবরাহ করে। দুটি প্রাথমিক কাঠামো
- ল্যাংচেইন এক্সপ্রেশন ল্যাঙ্গুয়েজ (এলসিইএল)
- লিগ্যাসি চেইন ইন্টারফেস
ল্যাংচেইন এক্সপ্রেশন ল্যাঙ্গুয়েজ (এলসিইএল) হল একটি সিনট্যাক্স যা চেইনগুলির স্বজ্ঞাত রচনার জন্য অনুমতি দেয়। এটি স্ট্রিমিং, অ্যাসিঙ্ক্রোনাস কল, ব্যাচিং, সমান্তরালকরণ, পুনরায় চেষ্টা, ফলব্যাক এবং ট্রেসিংয়ের মতো উন্নত বৈশিষ্ট্যগুলিকে সমর্থন করে। উদাহরণস্বরূপ, আপনি নিম্নলিখিত কোডে দেখানো হিসাবে LCEL-তে একটি প্রম্পট, মডেল এবং আউটপুট পার্সার রচনা করতে পারেন:
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
prompt = ChatPromptTemplate.from_messages([ ("system", "You're a very knowledgeable historian who provides accurate and eloquent answers to historical questions."), ("human", "{question}")
])
runnable = prompt | model | StrOutputParser() for chunk in runnable.stream({"question": "What are the seven wonders of the world"}): print(chunk, end="", flush=True)
বিকল্পভাবে, LLMCchain উপাদানগুলি রচনা করার জন্য LCEL-এর মতো একটি বিকল্প। LLMCchain উদাহরণটি নিম্নরূপ:
from langchain.chains import LLMChain chain = LLMChain(llm=model, prompt=prompt, output_parser=StrOutputParser())
chain.run(question="What are the seven wonders of the world")
LangChain-এ চেইনগুলিও একটি মেমরি অবজেক্ট অন্তর্ভুক্ত করে রাষ্ট্রীয় হতে পারে। এটি কল জুড়ে ডেটা স্থিরতার অনুমতি দেয়, যেমন এই উদাহরণে দেখানো হয়েছে:
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory conversation = ConversationChain(llm=chat, memory=ConversationBufferMemory())
conversation.run("Answer briefly. What are the first 3 colors of a rainbow?")
conversation.run("And the next 4?")
ল্যাংচেইন ওপেনএআই-এর ফাংশন-কলিং এপিআইগুলির সাথে একীকরণকে সমর্থন করে, যা একটি চেইনের মধ্যে কাঠামোগত আউটপুট প্রাপ্ত এবং কার্য সম্পাদনের জন্য দরকারী। কাঠামোগত আউটপুট পাওয়ার জন্য, আপনি Pydantic ক্লাস বা JsonSchema ব্যবহার করে তাদের নির্দিষ্ট করতে পারেন, যেমনটি নীচের চিত্রিত হয়েছে:
from langchain.pydantic_v1 import BaseModel, Field
from langchain.chains.openai_functions import create_structured_output_runnable
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate class Person(BaseModel): name: str = Field(..., description="The person's name") age: int = Field(..., description="The person's age") fav_food: Optional[str] = Field(None, description="The person's favorite food") llm = ChatOpenAI(model="gpt-4", temperature=0)
prompt = ChatPromptTemplate.from_messages([ # Prompt messages here
]) runnable = create_structured_output_runnable(Person, llm, prompt)
runnable.invoke({"input": "Sally is 13"})
কাঠামোগত আউটপুটগুলির জন্য, LLMCchain ব্যবহার করে একটি উত্তরাধিকার পদ্ধতিও উপলব্ধ:
from langchain.chains.openai_functions import create_structured_output_chain class Person(BaseModel): name: str = Field(..., description="The person's name") age: int = Field(..., description="The person's age") chain = create_structured_output_chain(Person, llm, prompt, verbose=True)
chain.run("Sally is 13")
ল্যাংচেইন বিভিন্ন উদ্দেশ্যে বিভিন্ন নির্দিষ্ট চেইন তৈরি করতে ওপেনএআই ফাংশন ব্যবহার করে। এর মধ্যে এক্সট্রাকশন, ট্যাগিং, ওপেনএপিআই এবং উদ্ধৃতি সহ QA এর জন্য চেইন অন্তর্ভুক্ত।
নিষ্কাশনের প্রসঙ্গে, প্রক্রিয়াটি কাঠামোগত আউটপুট চেইনের অনুরূপ কিন্তু তথ্য বা সত্তা নিষ্কাশনের উপর দৃষ্টি নিবদ্ধ করে। ট্যাগিংয়ের জন্য, ধারণাটি হল অনুভূতি, ভাষা, শৈলী, আচ্ছাদিত বিষয় বা রাজনৈতিক প্রবণতার মতো ক্লাস সহ একটি নথিকে লেবেল করা।
LangChain-এ ট্যাগিং কীভাবে কাজ করে তার একটি উদাহরণ পাইথন কোড দিয়ে দেখানো যেতে পারে। প্রক্রিয়াটি প্রয়োজনীয় প্যাকেজগুলি ইনস্টল করার এবং পরিবেশ স্থাপনের সাথে শুরু হয়:
pip install langchain openai
# Set env var OPENAI_API_KEY or load from a .env file:
# import dotenv
# dotenv.load_dotenv() from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import create_tagging_chain, create_tagging_chain_pydantic
ট্যাগিংয়ের জন্য স্কিমা সংজ্ঞায়িত করা হয়েছে, বৈশিষ্ট্যগুলি এবং তাদের প্রত্যাশিত প্রকারগুলি নির্দিষ্ট করে:
schema = { "properties": { "sentiment": {"type": "string"}, "aggressiveness": {"type": "integer"}, "language": {"type": "string"}, }
} llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
chain = create_tagging_chain(schema, llm)
বিভিন্ন ইনপুট সহ ট্যাগিং চেইন চালানোর উদাহরণগুলি মডেলের অনুভূতি, ভাষা এবং আক্রমণাত্মকতা ব্যাখ্যা করার ক্ষমতা দেখায়:
inp = "Estoy increiblemente contento de haberte conocido! Creo que seremos muy buenos amigos!"
chain.run(inp)
# {'sentiment': 'positive', 'language': 'Spanish'} inp = "Estoy muy enojado con vos! Te voy a dar tu merecido!"
chain.run(inp)
# {'sentiment': 'enojado', 'aggressiveness': 1, 'language': 'es'}
সূক্ষ্ম নিয়ন্ত্রণের জন্য, স্কিমাকে আরও নির্দিষ্টভাবে সংজ্ঞায়িত করা যেতে পারে, সম্ভাব্য মান, বর্ণনা এবং প্রয়োজনীয় বৈশিষ্ট্য সহ। এই বর্ধিত নিয়ন্ত্রণের একটি উদাহরণ নীচে দেখানো হয়েছে:
schema = { "properties": { # Schema definitions here }, "required": ["language", "sentiment", "aggressiveness"],
} chain = create_tagging_chain(schema, llm)
Pydantic স্কিমাগুলি ট্যাগিংয়ের মানদণ্ড নির্ধারণের জন্যও ব্যবহার করা যেতে পারে, প্রয়োজনীয় বৈশিষ্ট্য এবং প্রকারগুলি নির্দিষ্ট করার জন্য একটি পাইথনিক উপায় প্রদান করে:
from enum import Enum
from pydantic import BaseModel, Field class Tags(BaseModel): # Class fields here chain = create_tagging_chain_pydantic(Tags, llm)
উপরন্তু, LangChain এর মেটাডেটা ট্যাগার ডকুমেন্ট ট্রান্সফরমার LangChain ডকুমেন্ট থেকে মেটাডেটা বের করতে ব্যবহার করা যেতে পারে, ট্যাগিং চেইনের অনুরূপ কার্যকারিতা প্রদান করে কিন্তু একটি LangChain ডকুমেন্টে প্রয়োগ করা হয়।
টেক্সট থেকে উদ্ধৃতি বের করতে OpenAI ফাংশন ব্যবহার করে, LangChain-এর আরেকটি বৈশিষ্ট্য হল পুনরুদ্ধারের উত্স উদ্ধৃত করা। এটি নিম্নলিখিত কোডে প্রদর্শিত হয়:
from langchain.chains import create_citation_fuzzy_match_chain
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
chain = create_citation_fuzzy_match_chain(llm)
# Further code for running the chain and displaying results
LangChain-এ, লার্জ ল্যাঙ্গুয়েজ মডেল (LLM) অ্যাপ্লিকেশনে চেইনিং সাধারণত একটি LLM এবং ঐচ্ছিকভাবে একটি আউটপুট পার্সারের সাথে একটি প্রম্পট টেমপ্লেটকে একত্রিত করে। এটি করার প্রস্তাবিত উপায় হল LangChain এক্সপ্রেশন ল্যাঙ্গুয়েজ (LCEL), যদিও লিগ্যাসি LLMCchain পদ্ধতিও সমর্থিত।
LCEL ব্যবহার করে, BasePromptTemplate, BaseLanguageModel, এবং BaseOutputParser সকলেই Runnable ইন্টারফেস বাস্তবায়ন করে এবং সহজেই একে অপরের সাথে পাইপ করা যায়। এখানে এটি প্রদর্শনের একটি উদাহরণ:
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema import StrOutputParser prompt = PromptTemplate.from_template( "What is a good name for a company that makes {product}?"
)
runnable = prompt | ChatOpenAI() | StrOutputParser()
runnable.invoke({"product": "colorful socks"})
# Output: 'VibrantSocks'
LangChain-এ রাউটিং নন-ডিটারমিনিস্টিক চেইন তৈরি করার অনুমতি দেয় যেখানে পূর্ববর্তী ধাপের আউটপুট পরবর্তী ধাপ নির্ধারণ করে। এটি LLM-এর সাথে মিথস্ক্রিয়ায় কাঠামোগত এবং সামঞ্জস্য বজায় রাখতে সহায়তা করে। উদাহরণস্বরূপ, যদি আপনার কাছে বিভিন্ন ধরণের প্রশ্নের জন্য দুটি টেমপ্লেট অপ্টিমাইজ করা থাকে তবে আপনি ব্যবহারকারীর ইনপুটের উপর ভিত্তি করে টেমপ্লেটটি বেছে নিতে পারেন।
একটি RunnableBranch এর সাথে LCEL ব্যবহার করে আপনি কীভাবে এটি অর্জন করতে পারেন তা এখানে রয়েছে, যা (শর্ত, রানযোগ্য) জোড়ার একটি তালিকা এবং একটি ডিফল্ট রানেবলের সাথে শুরু করা হয়েছে:
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableBranch
# Code for defining physics_prompt and math_prompt general_prompt = PromptTemplate.from_template( "You are a helpful assistant. Answer the question as accurately as you can.nn{input}"
)
prompt_branch = RunnableBranch( (lambda x: x["topic"] == "math", math_prompt), (lambda x: x["topic"] == "physics", physics_prompt), general_prompt,
) # More code for setting up the classifier and final chain
ইনপুটের বিষয়ের উপর ভিত্তি করে প্রবাহ নির্ণয় করার জন্য তারপরে চূড়ান্ত চেইনটি বিভিন্ন উপাদান ব্যবহার করে তৈরি করা হয়, যেমন একটি বিষয় শ্রেণিবদ্ধকারী, প্রম্পট শাখা এবং একটি আউটপুট পার্সার:
from operator import itemgetter
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough final_chain = ( RunnablePassthrough.assign(topic=itemgetter("input") | classifier_chain) | prompt_branch | ChatOpenAI() | StrOutputParser()
) final_chain.invoke( { "input": "What is the first prime number greater than 40 such that one plus the prime number is divisible by 3?" }
)
# Output: Detailed answer to the math question
এই পদ্ধতিটি জটিল প্রশ্নগুলি পরিচালনা করতে এবং ইনপুটের উপর ভিত্তি করে যথাযথভাবে রাউটিং করার ক্ষেত্রে ল্যাংচেইনের নমনীয়তা এবং শক্তির উদাহরণ দেয়।
ভাষার মডেলের ক্ষেত্রে, একটি সাধারণ অভ্যাস হল একটি প্রাথমিক কল অনুসরণ করে পরবর্তী কলগুলির একটি সিরিজের সাথে, একটি কলের আউটপুটকে পরবর্তী কলের জন্য ইনপুট হিসাবে ব্যবহার করে। এই অনুক্রমিক পদ্ধতিটি বিশেষত উপকারী যখন আপনি পূর্ববর্তী মিথস্ক্রিয়ায় উত্পন্ন তথ্যের উপর ভিত্তি করে তৈরি করতে চান। যদিও ল্যাংচেইন এক্সপ্রেশন ল্যাঙ্গুয়েজ (এলসিইএল) এই সিকোয়েন্সগুলি তৈরি করার জন্য প্রস্তাবিত পদ্ধতি, সিকোয়েন্সিয়াল চেইন পদ্ধতিটি এখনও তার পশ্চাদগামী সামঞ্জস্যের জন্য নথিভুক্ত।
এটি ব্যাখ্যা করার জন্য, আসুন একটি দৃশ্যকল্প বিবেচনা করি যেখানে আমরা প্রথমে একটি নাটকের সংক্ষিপ্তসার তৈরি করি এবং তারপর সেই সংক্ষিপ্তসারের উপর ভিত্তি করে একটি পর্যালোচনা করি। পাইথন ব্যবহার করে langchain.prompts, আমরা দুটি তৈরি করি PromptTemplate উদাহরণ: একটি সারসংক্ষেপের জন্য এবং আরেকটি পর্যালোচনার জন্য। এই টেমপ্লেট সেট আপ করার কোড এখানে:
from langchain.prompts import PromptTemplate synopsis_prompt = PromptTemplate.from_template( "You are a playwright. Given the title of play, it is your job to write a synopsis for that title.nnTitle: {title}nPlaywright: This is a synopsis for the above play:"
) review_prompt = PromptTemplate.from_template( "You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:"
)
LCEL পদ্ধতিতে, আমরা এই প্রম্পটগুলির সাথে চেইন করি ChatOpenAI এবং StrOutputParser একটি ক্রম তৈরি করতে যা প্রথমে একটি সংক্ষিপ্তসার এবং তারপর একটি পর্যালোচনা তৈরি করে। কোড স্নিপেট নিম্নরূপ:
from langchain.chat_models import ChatOpenAI
from langchain.schema import StrOutputParser llm = ChatOpenAI()
chain = ( {"synopsis": synopsis_prompt | llm | StrOutputParser()} | review_prompt | llm | StrOutputParser()
)
chain.invoke({"title": "Tragedy at sunset on the beach"})
আমাদের যদি সারসংক্ষেপ এবং পর্যালোচনা উভয়েরই প্রয়োজন হয় তবে আমরা ব্যবহার করতে পারি RunnablePassthrough প্রতিটির জন্য একটি পৃথক চেইন তৈরি করতে এবং তারপরে তাদের একত্রিত করতে:
from langchain.schema.runnable import RunnablePassthrough synopsis_chain = synopsis_prompt | llm | StrOutputParser()
review_chain = review_prompt | llm | StrOutputParser()
chain = {"synopsis": synopsis_chain} | RunnablePassthrough.assign(review=review_chain)
chain.invoke({"title": "Tragedy at sunset on the beach"})
আরো জটিল ক্রম জড়িত পরিস্থিতিতে জন্য, SequentialChain পদ্ধতি খেলার মধ্যে আসে। এটি একাধিক ইনপুট এবং আউটপুটগুলির জন্য অনুমতি দেয়। একটি কেস বিবেচনা করুন যেখানে আমাদের একটি নাটকের শিরোনাম এবং যুগের উপর ভিত্তি করে একটি সংক্ষিপ্তসার প্রয়োজন। আমরা এটি কিভাবে সেট আপ করতে পারি তা এখানে:
from langchain.llms import OpenAI
from langchain.chains import LLMChain, SequentialChain
from langchain.prompts import PromptTemplate llm = OpenAI(temperature=0.7) synopsis_template = "You are a playwright. Given the title of play and the era it is set in, it is your job to write a synopsis for that title.nnTitle: {title}nEra: {era}nPlaywright: This is a synopsis for the above play:"
synopsis_prompt_template = PromptTemplate(input_variables=["title", "era"], template=synopsis_template)
synopsis_chain = LLMChain(llm=llm, prompt=synopsis_prompt_template, output_key="synopsis") review_template = "You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:"
prompt_template = PromptTemplate(input_variables=["synopsis"], template=review_template)
review_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="review") overall_chain = SequentialChain( chains=[synopsis_chain, review_chain], input_variables=["era", "title"], output_variables=["synopsis", "review"], verbose=True,
) overall_chain({"title": "Tragedy at sunset on the beach", "era": "Victorian England"})
এমন পরিস্থিতিতে যেখানে আপনি একটি চেইন জুড়ে বা চেইনের পরবর্তী অংশের জন্য প্রসঙ্গ বজায় রাখতে চান, SimpleMemory ব্যবহার করা যেতে পারে. এটি জটিল ইনপুট/আউটপুট সম্পর্ক পরিচালনার জন্য বিশেষভাবে কার্যকর। উদাহরণস্বরূপ, একটি দৃশ্যে যেখানে আমরা একটি নাটকের শিরোনাম, যুগ, সারসংক্ষেপ এবং পর্যালোচনার উপর ভিত্তি করে সামাজিক মিডিয়া পোস্ট তৈরি করতে চাই, SimpleMemory এই ভেরিয়েবলগুলি পরিচালনা করতে সাহায্য করতে পারে:
from langchain.memory import SimpleMemory
from langchain.chains import SequentialChain template = "You are a social media manager for a theater company. Given the title of play, the era it is set in, the date, time and location, the synopsis of the play, and the review of the play, it is your job to write a social media post for that play.nnHere is some context about the time and location of the play:nDate and Time: {time}nLocation: {location}nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:n{review}nnSocial Media Post:"
prompt_template = PromptTemplate(input_variables=["synopsis", "review", "time", "location"], template=template)
social_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="social_post_text") overall_chain = SequentialChain( memory=SimpleMemory(memories={"time": "December 25th, 8pm PST", "location": "Theater in the Park"}), chains=[synopsis_chain, review_chain, social_chain], input_variables=["era", "title"], output_variables=["social_post_text"], verbose=True,
) overall_chain({"title": "Tragedy at sunset on the beach", "era": "Victorian England"})
অনুক্রমিক চেইন ছাড়াও, নথিগুলির সাথে কাজ করার জন্য বিশেষ চেইন রয়েছে। এই চেইনগুলির প্রতিটি একটি ভিন্ন উদ্দেশ্য পরিবেশন করে, দস্তাবেজগুলি একত্রিত করা থেকে শুরু করে পুনরাবৃত্তিমূলক নথি বিশ্লেষণের উপর ভিত্তি করে উত্তরগুলি পরিমার্জন করা, স্কোর করা প্রতিক্রিয়াগুলির উপর ভিত্তি করে সংক্ষিপ্তকরণ বা পুনরায় র্যাঙ্কিংয়ের জন্য নথির বিষয়বস্তু ম্যাপিং এবং হ্রাস করা। অতিরিক্ত নমনীয়তা এবং কাস্টমাইজেশনের জন্য এই চেইনগুলি LCEL দিয়ে পুনরায় তৈরি করা যেতে পারে।
-
StuffDocumentsChainএকটি এলএলএম-এ পাস করা একক প্রম্পটে নথিগুলির একটি তালিকা একত্রিত করে। -
RefineDocumentsChainপ্রতিটি নথির জন্য তার উত্তরটি পুনরাবৃত্তিমূলকভাবে আপডেট করে, যে কাজের জন্য উপযুক্ত যেখানে নথিগুলি মডেলের প্রসঙ্গ ক্ষমতা অতিক্রম করে। -
MapReduceDocumentsChainপ্রতিটি নথিতে পৃথকভাবে একটি চেইন প্রয়োগ করে এবং তারপর ফলাফলগুলিকে একত্রিত করে। -
MapRerankDocumentsChainপ্রতিটি নথি-ভিত্তিক প্রতিক্রিয়া স্কোর করে এবং সর্বোচ্চ-স্কোরিং একটি নির্বাচন করে।
এখানে আপনি একটি সেট আপ করতে পারে কিভাবে একটি উদাহরণ MapReduceDocumentsChain LCEL ব্যবহার করে:
from functools import partial
from langchain.chains.combine_documents import collapse_docs, split_list_of_docs
from langchain.schema import Document, StrOutputParser
from langchain.schema.prompt_template import format_document
from langchain.schema.runnable import RunnableParallel, RunnablePassthrough llm = ChatAnthropic()
document_prompt = PromptTemplate.from_template("{page_content}")
partial_format_document = partial(format_document, prompt=document_prompt) map_chain = ( {"context": partial_format_document} | PromptTemplate.from_template("Summarize this content:nn{context}") | llm | StrOutputParser()
) map_as_doc_chain = ( RunnableParallel({"doc": RunnablePassthrough(), "content": map_chain}) | (lambda x: Document(page_content=x["content"], metadata=x["doc"].metadata))
).with_config(run_name="Summarize (return doc)") def format_docs(docs): return "nn".join(partial_format_document(doc) for doc in docs) collapse_chain = ( {"context": format_docs} | PromptTemplate.from_template("Collapse this content:nn{context}") | llm | StrOutputParser()
) reduce_chain = ( {"context": format_docs} | PromptTemplate.from_template("Combine these summaries:nn{context}") | llm | StrOutputParser()
).with_config(run_name="Reduce") map_reduce = (map_as_doc_chain.map() | collapse | reduce_chain).with_config(run_name="Map reduce")
এই কনফিগারেশনটি LCEL এর শক্তি এবং অন্তর্নিহিত ভাষা মডেলের ব্যবহার করে নথির বিষয়বস্তুর বিস্তারিত এবং ব্যাপক বিশ্লেষণের অনুমতি দেয়।
আমাদের AI-চালিত ওয়ার্কফ্লো নির্মাতার সাথে ম্যানুয়াল কাজ এবং ওয়ার্কফ্লোগুলি স্বয়ংক্রিয় করুন, আপনার এবং আপনার দলের জন্য Nanonets দ্বারা ডিজাইন করা হয়েছে৷
মডিউল V: মেমরি
LangChain-এ, মেমরি হল কথোপকথনমূলক ইন্টারফেসের একটি মৌলিক দিক, যা সিস্টেমগুলিকে অতীতের মিথস্ক্রিয়া উল্লেখ করতে দেয়। এটি দুটি প্রাথমিক ক্রিয়া সহ তথ্য সংরক্ষণ এবং অনুসন্ধানের মাধ্যমে অর্জন করা হয়: পড়া এবং লেখা। মেমরি সিস্টেমটি একটি দৌড়ের সময় একটি চেইনের সাথে দুবার ইন্টারঅ্যাক্ট করে, ব্যবহারকারীর ইনপুট বৃদ্ধি করে এবং ভবিষ্যতের রেফারেন্সের জন্য ইনপুট এবং আউটপুট সংরক্ষণ করে।
একটি সিস্টেমে মেমরি তৈরি করা
- চ্যাট বার্তা সংরক্ষণ করা: ল্যাংচেইন মেমরি মডিউল ইন-মেমরি তালিকা থেকে ডাটাবেস পর্যন্ত চ্যাট বার্তাগুলি সংরক্ষণ করার জন্য বিভিন্ন পদ্ধতিকে সংহত করে। এটি নিশ্চিত করে যে সমস্ত চ্যাট ইন্টারঅ্যাকশন ভবিষ্যতের রেফারেন্সের জন্য রেকর্ড করা হয়েছে।
- চ্যাট বার্তা জিজ্ঞাসা করা: চ্যাট বার্তা সংরক্ষণের বাইরে, ল্যাংচেইন এই বার্তাগুলির একটি দরকারী দৃশ্য তৈরি করতে ডেটা স্ট্রাকচার এবং অ্যালগরিদম নিয়োগ করে। সাধারণ মেমরি সিস্টেমগুলি সাম্প্রতিক বার্তাগুলি ফিরিয়ে দিতে পারে, যখন আরও উন্নত সিস্টেমগুলি অতীতের মিথস্ক্রিয়াগুলির সংক্ষিপ্তসার করতে পারে বা বর্তমান মিথস্ক্রিয়ায় উল্লিখিত সত্তাগুলিতে ফোকাস করতে পারে।
ল্যাংচেইনে মেমরির ব্যবহার প্রদর্শন করতে, বিবেচনা করুন ConversationBufferMemory ক্লাস, একটি সাধারণ মেমরি ফর্ম যা একটি বাফারে চ্যাট বার্তা সংরক্ষণ করে। এখানে একটি উদাহরণ:
from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("Hello!")
memory.chat_memory.add_ai_message("How can I assist you?")
একটি শৃঙ্খলে মেমরি সংহত করার সময়, মেমরি থেকে ফিরে আসা ভেরিয়েবলগুলি এবং কীভাবে সেগুলি চেইনে ব্যবহার করা হয় তা বোঝা গুরুত্বপূর্ণ। উদাহরণস্বরূপ, load_memory_variables পদ্ধতি চেইনের প্রত্যাশার সাথে মেমরি থেকে পড়া ভেরিয়েবলগুলিকে সারিবদ্ধ করতে সহায়তা করে।
LangChain সহ এন্ড-টু-এন্ড উদাহরণ
ব্যবহার বিবেচনা করুন ConversationBufferMemory একটি মধ্যে LLMChain. চেইন, একটি উপযুক্ত প্রম্পট টেমপ্লেট এবং মেমরির সাথে মিলিত, একটি বিরামহীন কথোপকথন অভিজ্ঞতা প্রদান করে। এখানে একটি সরলীকৃত উদাহরণ:
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory llm = OpenAI(temperature=0)
template = "Your conversation template here..."
prompt = PromptTemplate.from_template(template)
memory = ConversationBufferMemory(memory_key="chat_history")
conversation = LLMChain(llm=llm, prompt=prompt, memory=memory) response = conversation({"question": "What's the weather like?"})
এই উদাহরণটি ব্যাখ্যা করে যে কীভাবে ল্যাংচেইনের মেমরি সিস্টেম একটি সুসংগত এবং প্রাসঙ্গিকভাবে সচেতন কথোপকথন অভিজ্ঞতা প্রদান করতে তার চেইনের সাথে সংহত করে।
ল্যাংচেইনে মেমরির ধরন
ল্যাংচেইন বিভিন্ন ধরনের মেমরি অফার করে যা এআই মডেলের সাথে মিথস্ক্রিয়া বাড়ানোর জন্য ব্যবহার করা যেতে পারে। প্রতিটি মেমরি টাইপের নিজস্ব প্যারামিটার এবং রিটার্নের ধরন রয়েছে, যা তাদের বিভিন্ন পরিস্থিতিতে উপযুক্ত করে তোলে। আসুন কোড উদাহরণ সহ ল্যাংচেইনে উপলব্ধ কিছু মেমরি প্রকারগুলি অন্বেষণ করি।
1. কথোপকথন বাফার মেমরি
এই মেমরি টাইপ আপনাকে কথোপকথন থেকে বার্তা সংরক্ষণ এবং নিষ্কাশন করতে দেয়। আপনি একটি স্ট্রিং হিসাবে বা বার্তাগুলির একটি তালিকা হিসাবে ইতিহাস বের করতে পারেন।
from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory()
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({}) # Extract history as a string
{'history': 'Human: hinAI: whats up'} # Extract history as a list of messages
{'history': [HumanMessage(content='hi', additional_kwargs={}), AIMessage(content='whats up', additional_kwargs={})]}
আপনি চ্যাটের মত ইন্টারঅ্যাকশনের জন্য একটি চেইনে কথোপকথন বাফার মেমরি ব্যবহার করতে পারেন।
2. কথোপকথন বাফার উইন্ডো মেমরি
এই মেমরি টাইপ সাম্প্রতিক মিথস্ক্রিয়াগুলির একটি তালিকা রাখে এবং শেষ K মিথস্ক্রিয়া ব্যবহার করে, বাফারটিকে খুব বড় হতে বাধা দেয়।
from langchain.memory import ConversationBufferWindowMemory memory = ConversationBufferWindowMemory(k=1)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
memory.load_memory_variables({}) {'history': 'Human: not much younAI: not much'}
কথোপকথন বাফার মেমরির মতো, আপনি চ্যাটের মতো ইন্টারঅ্যাকশনের জন্য এই মেমরি টাইপটি একটি চেইনে ব্যবহার করতে পারেন।
3. কথোপকথন সত্তা মেমরি
এই মেমরি টাইপ একটি কথোপকথনে নির্দিষ্ট সত্তা সম্পর্কে তথ্য মনে রাখে এবং একটি LLM ব্যবহার করে তথ্য বের করে।
from langchain.memory import ConversationEntityMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationEntityMemory(llm=llm)
_input = {"input": "Deven & Sam are working on a hackathon project"}
memory.load_memory_variables(_input)
memory.save_context( _input, {"output": " That sounds like a great project! What kind of project are they working on?"}
)
memory.load_memory_variables({"input": 'who is Sam'}) {'history': 'Human: Deven & Sam are working on a hackathon projectnAI: That sounds like a great project! What kind of project are they working on?', 'entities': {'Sam': 'Sam is working on a hackathon project with Deven.'}}
4. কথোপকথন জ্ঞান গ্রাফ মেমরি
এই মেমরি টাইপ মেমরি পুনরায় তৈরি করতে একটি জ্ঞান গ্রাফ ব্যবহার করে। আপনি বার্তাগুলি থেকে বর্তমান সত্তা এবং জ্ঞানের ত্রিগুণ বের করতে পারেন।
from langchain.memory import ConversationKGMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationKGMemory(llm=llm)
memory.save_context({"input": "say hi to sam"}, {"output": "who is sam"})
memory.save_context({"input": "sam is a friend"}, {"output": "okay"})
memory.load_memory_variables({"input": "who is sam"}) {'history': 'On Sam: Sam is friend.'}
আপনি কথোপকথন-ভিত্তিক জ্ঞান পুনরুদ্ধারের জন্য এই মেমরি টাইপটি একটি চেইনে ব্যবহার করতে পারেন।
5. কথোপকথনের সারাংশ মেমরি
এই মেমরি টাইপটি সময়ের সাথে সাথে কথোপকথনের একটি সারাংশ তৈরি করে, যা দীর্ঘ কথোপকথন থেকে তথ্য ঘনীভূত করার জন্য দরকারী।
from langchain.memory import ConversationSummaryMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationSummaryMemory(llm=llm)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({}) {'history': 'nThe human greets the AI, to which the AI responds.'}
6. কথোপকথনের সারাংশ বাফার মেমরি
এই মেমরি টাইপ কথোপকথনের সারাংশ এবং বাফারকে একত্রিত করে, সাম্প্রতিক মিথস্ক্রিয়া এবং একটি সারাংশের মধ্যে ভারসাম্য বজায় রাখে। কখন মিথস্ক্রিয়া ফ্লাশ করতে হবে তা নির্ধারণ করতে এটি টোকেন দৈর্ঘ্য ব্যবহার করে।
from langchain.memory import ConversationSummaryBufferMemory
from langchain.llms import OpenAI llm = OpenAI()
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
memory.load_memory_variables({}) {'history': 'System: nThe human says "hi", and the AI responds with "whats up".nHuman: not much younAI: not much'}
আপনি ল্যাংচেইনের এআই মডেলগুলির সাথে আপনার মিথস্ক্রিয়া উন্নত করতে এই মেমরি প্রকারগুলি ব্যবহার করতে পারেন। প্রতিটি মেমরি টাইপ একটি নির্দিষ্ট উদ্দেশ্যে কাজ করে এবং আপনার প্রয়োজনীয়তার উপর ভিত্তি করে নির্বাচন করা যেতে পারে।
7. কথোপকথন টোকেন বাফার মেমরি
ConversationTokenBufferMemory হল আরেকটি মেমরি টাইপ যা মেমরিতে সাম্প্রতিক মিথস্ক্রিয়াগুলির একটি বাফার রাখে। পূর্ববর্তী মেমরি প্রকারের বিপরীতে যা ইন্টারঅ্যাকশনের সংখ্যার উপর ফোকাস করে, এটি কখন মিথস্ক্রিয়াগুলি ফ্লাশ করতে হবে তা নির্ধারণ করতে টোকেন দৈর্ঘ্য ব্যবহার করে।
এলএলএম এর সাথে মেমরি ব্যবহার করা:
from langchain.memory import ConversationTokenBufferMemory
from langchain.llms import OpenAI llm = OpenAI() memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"}) memory.load_memory_variables({}) {'history': 'Human: not much younAI: not much'}
এই উদাহরণে, মেমরি ইন্টারঅ্যাকশনের সংখ্যার পরিবর্তে টোকেন দৈর্ঘ্যের উপর ভিত্তি করে মিথস্ক্রিয়া সীমিত করতে সেট করা হয়েছে।
এই মেমরি টাইপ ব্যবহার করার সময় আপনি বার্তাগুলির একটি তালিকা হিসাবে ইতিহাসও পেতে পারেন।
memory = ConversationTokenBufferMemory( llm=llm, max_token_limit=10, return_messages=True
)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
একটি চেইন ব্যবহার করে:
আপনি AI মডেলের সাথে মিথস্ক্রিয়া বাড়ানোর জন্য একটি চেইনে ConversationTokenBufferMemory ব্যবহার করতে পারেন।
from langchain.chains import ConversationChain conversation_with_summary = ConversationChain( llm=llm, # We set a very low max_token_limit for the purposes of testing. memory=ConversationTokenBufferMemory(llm=OpenAI(), max_token_limit=60), verbose=True,
)
conversation_with_summary.predict(input="Hi, what's up?")
এই উদাহরণে, কথোপকথন পরিচালনা করতে এবং টোকেন দৈর্ঘ্যের উপর ভিত্তি করে মিথস্ক্রিয়া সীমিত করতে ConversationTokenBufferMemory একটি ConversationChain-এ ব্যবহৃত হয়।
8. VectorStoreRetrieverMemory
VectorStoreRetrieverMemory একটি ভেক্টর স্টোরে স্মৃতি সঞ্চয় করে এবং যখনই কল করা হয় তখন টপ-কে সবচেয়ে "প্রধান" নথিগুলি জিজ্ঞাসা করে৷ এই মেমরি টাইপ স্পষ্টভাবে ইন্টারঅ্যাকশনের ক্রম ট্র্যাক করে না কিন্তু প্রাসঙ্গিক স্মৃতি আনতে ভেক্টর পুনরুদ্ধার ব্যবহার করে।
from datetime import datetime
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.memory import VectorStoreRetrieverMemory
from langchain.chains import ConversationChain
from langchain.prompts import PromptTemplate # Initialize your vector store (specifics depend on the chosen vector store)
import faiss
from langchain.docstore import InMemoryDocstore
from langchain.vectorstores import FAISS embedding_size = 1536 # Dimensions of the OpenAIEmbeddings
index = faiss.IndexFlatL2(embedding_size)
embedding_fn = OpenAIEmbeddings().embed_query
vectorstore = FAISS(embedding_fn, index, InMemoryDocstore({}), {}) # Create your VectorStoreRetrieverMemory
retriever = vectorstore.as_retriever(search_kwargs=dict(k=1))
memory = VectorStoreRetrieverMemory(retriever=retriever) # Save context and relevant information to the memory
memory.save_context({"input": "My favorite food is pizza"}, {"output": "that's good to know"})
memory.save_context({"input": "My favorite sport is soccer"}, {"output": "..."})
memory.save_context({"input": "I don't like the Celtics"}, {"output": "ok"}) # Retrieve relevant information from memory based on a query
print(memory.load_memory_variables({"prompt": "what sport should i watch?"})["history"])
এই উদাহরণে, ভেক্টর পুনরুদ্ধারের উপর ভিত্তি করে একটি কথোপকথন থেকে প্রাসঙ্গিক তথ্য সংরক্ষণ এবং পুনরুদ্ধার করতে VectorStoreRetrieverMemory ব্যবহার করা হয়।
আপনি কথোপকথন-ভিত্তিক জ্ঞান পুনরুদ্ধারের জন্য একটি চেইনে VectorStoreRetrieverMemory ব্যবহার করতে পারেন, যেমনটি আগের উদাহরণগুলিতে দেখানো হয়েছে।
ল্যাংচেইনের এই বিভিন্ন মেমরির ধরনগুলি কথোপকথন থেকে তথ্য পরিচালনা এবং পুনরুদ্ধার করার বিভিন্ন উপায় প্রদান করে, ব্যবহারকারীর প্রশ্ন এবং প্রসঙ্গে বোঝার এবং উত্তর দেওয়ার ক্ষেত্রে AI মডেলগুলির ক্ষমতা বৃদ্ধি করে। আপনার অ্যাপ্লিকেশনের নির্দিষ্ট প্রয়োজনীয়তার উপর ভিত্তি করে প্রতিটি মেমরির ধরন নির্বাচন করা যেতে পারে।
এখন আমরা শিখব কিভাবে LLMCchain দিয়ে মেমরি ব্যবহার করতে হয়। একটি LLMCchain-এ মেমরি মডেলটিকে আরও সুসঙ্গত এবং প্রসঙ্গ-সচেতন প্রতিক্রিয়া প্রদানের জন্য পূর্ববর্তী মিথস্ক্রিয়া এবং প্রসঙ্গ মনে রাখার অনুমতি দেয়।
একটি LLMCchain এ মেমরি সেট আপ করতে, আপনাকে একটি মেমরি ক্লাস তৈরি করতে হবে, যেমন ConversationBufferMemory। আপনি কিভাবে এটি সেট আপ করতে পারেন তা এখানে:
from langchain.chains import LLMChain
from langchain.llms import OpenAI
from langchain.memory import ConversationBufferMemory
from langchain.prompts import PromptTemplate template = """You are a chatbot having a conversation with a human. {chat_history}
Human: {human_input}
Chatbot:""" prompt = PromptTemplate( input_variables=["chat_history", "human_input"], template=template
)
memory = ConversationBufferMemory(memory_key="chat_history") llm = OpenAI()
llm_chain = LLMChain( llm=llm, prompt=prompt, verbose=True, memory=memory,
) llm_chain.predict(human_input="Hi there my friend")
এই উদাহরণে, কথোপকথনের ইতিহাস সংরক্ষণ করতে ConversationBufferMemory ব্যবহার করা হয়। দ্য memory_key প্যারামিটার কথোপকথনের ইতিহাস সংরক্ষণ করতে ব্যবহৃত কী নির্দিষ্ট করে।
আপনি যদি একটি সমাপ্তি-শৈলী মডেলের পরিবর্তে একটি চ্যাট মডেল ব্যবহার করেন, আপনি মেমরিটিকে আরও ভালভাবে ব্যবহার করার জন্য আপনার প্রম্পটগুলিকে আলাদাভাবে গঠন করতে পারেন। মেমরি সহ একটি চ্যাট মডেল-ভিত্তিক LLMCchain কীভাবে সেট আপ করবেন তার একটি উদাহরণ এখানে রয়েছে:
from langchain.chat_models import ChatOpenAI
from langchain.schema import SystemMessage
from langchain.prompts import ( ChatPromptTemplate, HumanMessagePromptTemplate, MessagesPlaceholder,
) # Create a ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages( [ SystemMessage( content="You are a chatbot having a conversation with a human." ), # The persistent system prompt MessagesPlaceholder( variable_name="chat_history" ), # Where the memory will be stored. HumanMessagePromptTemplate.from_template( "{human_input}" ), # Where the human input will be injected ]
) memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True) llm = ChatOpenAI() chat_llm_chain = LLMChain( llm=llm, prompt=prompt, verbose=True, memory=memory,
) chat_llm_chain.predict(human_input="Hi there my friend")
এই উদাহরণে, ChatPromptTemplate প্রম্পট গঠন করতে ব্যবহৃত হয়, এবং কথোপকথন ইতিহাস সংরক্ষণ এবং পুনরুদ্ধার করতে ConversationBufferMemory ব্যবহার করা হয়। এই পদ্ধতিটি চ্যাট-স্টাইলের কথোপকথনের জন্য বিশেষভাবে উপযোগী যেখানে প্রসঙ্গ এবং ইতিহাস একটি গুরুত্বপূর্ণ ভূমিকা পালন করে।
মেমরি একাধিক ইনপুট সহ একটি চেইনে যোগ করা যেতে পারে, যেমন একটি প্রশ্ন/উত্তর চেইন। একটি প্রশ্ন/উত্তর শৃঙ্খলে কীভাবে মেমরি সেট আপ করবেন তার একটি উদাহরণ এখানে রয়েছে:
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.embeddings.cohere import CohereEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
from langchain.vectorstores import Chroma
from langchain.docstore.document import Document
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.memory import ConversationBufferMemory # Split a long document into smaller chunks
with open("../../state_of_the_union.txt") as f: state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union) # Create an ElasticVectorSearch instance to index and search the document chunks
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_texts( texts, embeddings, metadatas=[{"source": i} for i in range(len(texts))]
) # Perform a question about the document
query = "What did the president say about Justice Breyer"
docs = docsearch.similarity_search(query) # Set up a prompt for the question-answering chain with memory
template = """You are a chatbot having a conversation with a human. Given the following extracted parts of a long document and a question, create a final answer. {context} {chat_history}
Human: {human_input}
Chatbot:""" prompt = PromptTemplate( input_variables=["chat_history", "human_input", "context"], template=template
)
memory = ConversationBufferMemory(memory_key="chat_history", input_key="human_input")
chain = load_qa_chain( OpenAI(temperature=0), chain_type="stuff", memory=memory, prompt=prompt
) # Ask the question and retrieve the answer
query = "What did the president say about Justice Breyer"
result = chain({"input_documents": docs, "human_input": query}, return_only_outputs=True) print(result)
print(chain.memory.buffer)
এই উদাহরণে, ছোট খণ্ডে বিভক্ত একটি নথি ব্যবহার করে একটি প্রশ্নের উত্তর দেওয়া হয়। ConversationBufferMemory কথোপকথনের ইতিহাস সংরক্ষণ এবং পুনরুদ্ধার করতে ব্যবহৃত হয়, মডেলটিকে প্রসঙ্গ-সচেতন উত্তর প্রদান করার অনুমতি দেয়।
একটি এজেন্টের সাথে মেমরি যোগ করা এটিকে প্রশ্নের উত্তর দিতে এবং প্রসঙ্গ-সচেতন প্রতিক্রিয়া প্রদান করতে পূর্ববর্তী মিথস্ক্রিয়াগুলি মনে রাখতে এবং ব্যবহার করতে দেয়। এখানে আপনি কিভাবে একটি এজেন্ট মেমরি সেট আপ করতে পারেন:
from langchain.agents import ZeroShotAgent, Tool, AgentExecutor
from langchain.memory import ConversationBufferMemory
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.utilities import GoogleSearchAPIWrapper # Create a tool for searching
search = GoogleSearchAPIWrapper()
tools = [ Tool( name="Search", func=search.run, description="useful for when you need to answer questions about current events", )
] # Create a prompt with memory
prefix = """Have a conversation with a human, answering the following questions as best you can. You have access to the following tools:"""
suffix = """Begin!" {chat_history}
Question: {input}
{agent_scratchpad}""" prompt = ZeroShotAgent.create_prompt( tools, prefix=prefix, suffix=suffix, input_variables=["input", "chat_history", "agent_scratchpad"],
)
memory = ConversationBufferMemory(memory_key="chat_history") # Create an LLMChain with memory
llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=prompt)
agent = ZeroShotAgent(llm_chain=llm_chain, tools=tools, verbose=True)
agent_chain = AgentExecutor.from_agent_and_tools( agent=agent, tools=tools, verbose=True, memory=memory
) # Ask a question and retrieve the answer
response = agent_chain.run(input="How many people live in Canada?")
print(response) # Ask a follow-up question
response = agent_chain.run(input="What is their national anthem called?")
print(response)
এই উদাহরণে, মেমরি একটি এজেন্টে যোগ করা হয়, যা এটিকে পূর্ববর্তী কথোপকথনের ইতিহাস মনে রাখতে এবং প্রসঙ্গ-সচেতন উত্তর প্রদান করতে দেয়। এটি এজেন্টকে মেমরিতে সঞ্চিত তথ্যের উপর ভিত্তি করে সঠিকভাবে ফলো-আপ প্রশ্নের উত্তর দিতে সক্ষম করে।
ল্যাংচেইন এক্সপ্রেশন ভাষা
প্রাকৃতিক ভাষা প্রক্রিয়াকরণ এবং মেশিন লার্নিংয়ের জগতে, অপারেশনের জটিল চেইন রচনা করা একটি কঠিন কাজ হতে পারে। সৌভাগ্যবশত, ল্যাংচেইন এক্সপ্রেশন ল্যাঙ্গুয়েজ (এলসিইএল) অত্যাধুনিক ভাষা প্রক্রিয়াকরণ পাইপলাইন তৈরি এবং স্থাপন করার একটি ঘোষণামূলক এবং কার্যকর উপায় প্রদান করে। LCEL চেইন রচনার প্রক্রিয়াকে সহজ করার জন্য ডিজাইন করা হয়েছে, যার ফলে প্রোটোটাইপিং থেকে উৎপাদনে সহজে যাওয়া সম্ভব। এই ব্লগে, আমরা LCEL কী এবং কেন আপনি এটি ব্যবহার করতে চাইতে পারেন, এর ক্ষমতাগুলি ব্যাখ্যা করার জন্য ব্যবহারিক কোড উদাহরণ সহ অন্বেষণ করব।
LCEL, বা LangChain এক্সপ্রেশন ল্যাঙ্গুয়েজ, ভাষা প্রক্রিয়াকরণ চেইন রচনা করার জন্য একটি শক্তিশালী হাতিয়ার। ব্যাপক কোড পরিবর্তনের প্রয়োজন ছাড়াই প্রোটোটাইপিং থেকে উৎপাদনে নির্বিঘ্নে রূপান্তরকে সমর্থন করার উদ্দেশ্যে এটি তৈরি করা হয়েছিল। আপনি একটি সাধারণ "প্রম্পট + LLM" চেইন বা শত শত ধাপ সহ একটি জটিল পাইপলাইন তৈরি করছেন না কেন, LCEL আপনাকে কভার করেছে।
আপনার ভাষা প্রক্রিয়াকরণ প্রকল্পগুলিতে LCEL ব্যবহার করার কিছু কারণ এখানে রয়েছে:
- দ্রুত টোকেন স্ট্রিমিং: LCEL একটি ভাষা মডেল থেকে টোকেনগুলিকে রিয়েল-টাইমে একটি আউটপুট পার্সারে সরবরাহ করে, প্রতিক্রিয়াশীলতা এবং দক্ষতা উন্নত করে।
- বহুমুখী API: LCEL প্রোটোটাইপিং এবং উত্পাদন ব্যবহারের জন্য সিঙ্ক্রোনাস এবং অ্যাসিঙ্ক্রোনাস উভয় API সমর্থন করে, একাধিক অনুরোধ দক্ষতার সাথে পরিচালনা করে।
- স্বয়ংক্রিয় সমান্তরালকরণ: LCEL যখন সম্ভব সমান্তরাল সম্পাদনকে অপ্টিমাইজ করে, উভয় সিঙ্ক এবং অ্যাসিঙ্ক ইন্টারফেসে বিলম্ব কমায়৷
- নির্ভরযোগ্য কনফিগারেশন: বিকাশে স্ট্রিমিং সমর্থন সহ স্কেলে বর্ধিত চেইন নির্ভরযোগ্যতার জন্য পুনরায় চেষ্টা এবং ফলব্যাকগুলি কনফিগার করুন।
- স্ট্রিম মধ্যবর্তী ফলাফল: ব্যবহারকারীর আপডেট বা ডিবাগিং উদ্দেশ্যে প্রক্রিয়াকরণের সময় মধ্যবর্তী ফলাফলগুলি অ্যাক্সেস করুন৷
- স্কিমা জেনারেশন: LCEL ইনপুট এবং আউটপুট বৈধতার জন্য Pydantic এবং JSONSchema স্কিমা তৈরি করে।
- ব্যাপক ট্রেসিং: ল্যাংস্মিথ স্বয়ংক্রিয়ভাবে পর্যবেক্ষণযোগ্যতা এবং ডিবাগিংয়ের জন্য জটিল চেইনের সমস্ত ধাপ ট্রেস করে।
- সহজ স্থাপনা: ল্যাংসার্ভ ব্যবহার করে অনায়াসে এলসিইএল-তৈরি চেইন স্থাপন করুন।
এখন, আসুন ব্যবহারিক কোড উদাহরণগুলিতে ডুব দেওয়া যাক যা LCEL এর শক্তি প্রদর্শন করে। আমরা সাধারণ কাজ এবং পরিস্থিতিগুলি অন্বেষণ করব যেখানে LCEL উজ্জ্বল হয়৷
প্রম্পট + এলএলএম
সবচেয়ে মৌলিক রচনার মধ্যে রয়েছে একটি প্রম্পট এবং একটি ভাষা মডেলকে একত্রিত করে একটি চেইন তৈরি করা যা ব্যবহারকারীর ইনপুট নেয়, এটি একটি প্রম্পটে যোগ করে, এটি একটি মডেলে পাস করে এবং কাঁচা মডেলের আউটপুট প্রদান করে। এখানে একটি উদাহরণ:
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI prompt = ChatPromptTemplate.from_template("tell me a joke about {foo}")
model = ChatOpenAI()
chain = prompt | model result = chain.invoke({"foo": "bears"})
print(result)
এই উদাহরণে, চেইন ভালুক সম্পর্কে একটি রসিকতা তৈরি করে।
এটি কীভাবে পাঠ্য প্রক্রিয়া করে তা নিয়ন্ত্রণ করতে আপনি আপনার চেইনে স্টপ সিকোয়েন্স সংযুক্ত করতে পারেন। উদাহরণ স্বরূপ:
chain = prompt | model.bind(stop=["n"])
result = chain.invoke({"foo": "bears"})
print(result)
একটি নতুন লাইন অক্ষর সম্মুখীন হলে এই কনফিগারেশন টেক্সট তৈরি বন্ধ করে দেয়।
LCEL আপনার চেইনে ফাংশন কল তথ্য সংযুক্ত করা সমর্থন করে। এখানে একটি উদাহরণ:
functions = [ { "name": "joke", "description": "A joke", "parameters": { "type": "object", "properties": { "setup": {"type": "string", "description": "The setup for the joke"}, "punchline": { "type": "string", "description": "The punchline for the joke", }, }, "required": ["setup", "punchline"], }, }
]
chain = prompt | model.bind(function_call={"name": "joke"}, functions=functions)
result = chain.invoke({"foo": "bears"}, config={})
print(result)
এই উদাহরণটি একটি কৌতুক তৈরি করতে ফাংশন কল তথ্য সংযুক্ত করে।
প্রম্পট + এলএলএম + আউটপুট পার্সার
কাঁচা মডেলের আউটপুটকে আরও কার্যকরী বিন্যাসে রূপান্তর করতে আপনি একটি আউটপুট পার্সার যোগ করতে পারেন। আপনি কিভাবে এটি করতে পারেন তা এখানে:
from langchain.schema.output_parser import StrOutputParser chain = prompt | model | StrOutputParser()
result = chain.invoke({"foo": "bears"})
print(result)
আউটপুট এখন একটি স্ট্রিং বিন্যাসে রয়েছে, যা ডাউনস্ট্রিম কাজের জন্য আরও সুবিধাজনক।
ফেরত দেওয়ার জন্য একটি ফাংশন নির্দিষ্ট করার সময়, আপনি LCEL ব্যবহার করে সরাসরি এটি পার্স করতে পারেন। উদাহরণ স্বরূপ:
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser chain = ( prompt | model.bind(function_call={"name": "joke"}, functions=functions) | JsonOutputFunctionsParser()
)
result = chain.invoke({"foo": "bears"})
print(result)
এই উদাহরণটি সরাসরি "কৌতুক" ফাংশনের আউটপুট বিশ্লেষণ করে।
LCEL কীভাবে জটিল ভাষা প্রক্রিয়াকরণের কাজগুলিকে সহজ করে তোলে তার কয়েকটি উদাহরণ। আপনি চ্যাটবট তৈরি করছেন, বিষয়বস্তু তৈরি করছেন বা জটিল টেক্সট ট্রান্সফর্মেশন করছেন না কেন, LCEL আপনার ওয়ার্কফ্লোকে স্ট্রিমলাইন করতে পারে এবং আপনার কোডকে আরও রক্ষণাবেক্ষণযোগ্য করে তুলতে পারে।
RAG (পুনরুদ্ধার-বর্ধিত প্রজন্ম)
LCEL পুনরুদ্ধার-বর্ধিত প্রজন্মের চেইন তৈরি করতে ব্যবহার করা যেতে পারে, যা পুনরুদ্ধার এবং ভাষা তৈরির ধাপগুলিকে একত্রিত করে। এখানে একটি উদাহরণ:
from operator import itemgetter from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.vectorstores import FAISS # Create a vector store and retriever
vectorstore = FAISS.from_texts( ["harrison worked at kensho"], embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever() # Define templates for prompts
template = """Answer the question based only on the following context:
{context} Question: {question} """
prompt = ChatPromptTemplate.from_template(template) model = ChatOpenAI() # Create a retrieval-augmented generation chain
chain = ( {"context": retriever, "question": RunnablePassthrough()} | prompt | model | StrOutputParser()
) result = chain.invoke("where did harrison work?")
print(result)
এই উদাহরণে, চেইনটি প্রসঙ্গ থেকে প্রাসঙ্গিক তথ্য পুনরুদ্ধার করে এবং প্রশ্নের উত্তর তৈরি করে।
কথোপকথন পুনরুদ্ধার চেইন
আপনি সহজেই আপনার চেইনে কথোপকথনের ইতিহাস যোগ করতে পারেন। এখানে একটি কথোপকথন পুনরুদ্ধার চেইনের একটি উদাহরণ:
from langchain.schema.runnable import RunnableMap
from langchain.schema import format_document from langchain.prompts.prompt import PromptTemplate # Define templates for prompts
_template = """Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question, in its original language. Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:"""
CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template(_template) template = """Answer the question based only on the following context:
{context} Question: {question} """
ANSWER_PROMPT = ChatPromptTemplate.from_template(template) # Define input map and context
_inputs = RunnableMap( standalone_question=RunnablePassthrough.assign( chat_history=lambda x: _format_chat_history(x["chat_history"]) ) | CONDENSE_QUESTION_PROMPT | ChatOpenAI(temperature=0) | StrOutputParser(),
)
_context = { "context": itemgetter("standalone_question") | retriever | _combine_documents, "question": lambda x: x["standalone_question"],
}
conversational_qa_chain = _inputs | _context | ANSWER_PROMPT | ChatOpenAI() result = conversational_qa_chain.invoke( { "question": "where did harrison work?", "chat_history": [], }
)
print(result)
এই উদাহরণে, চেইন একটি কথোপকথন প্রসঙ্গে একটি ফলো-আপ প্রশ্ন পরিচালনা করে।
মেমরি এবং রিটার্নিং সোর্স ডকুমেন্ট সহ
এছাড়াও LCEL মেমরি এবং রিটার্নিং সোর্স ডকুমেন্ট সমর্থন করে। এখানে আপনি কিভাবে একটি চেইনে মেমরি ব্যবহার করতে পারেন:
from operator import itemgetter
from langchain.memory import ConversationBufferMemory # Create a memory instance
memory = ConversationBufferMemory( return_messages=True, output_key="answer", input_key="question"
) # Define steps for the chain
loaded_memory = RunnablePassthrough.assign( chat_history=RunnableLambda(memory.load_memory_variables) | itemgetter("history"),
) standalone_question = { "standalone_question": { "question": lambda x: x["question"], "chat_history": lambda x: _format_chat_history(x["chat_history"]), } | CONDENSE_QUESTION_PROMPT | ChatOpenAI(temperature=0) | StrOutputParser(),
} retrieved_documents = { "docs": itemgetter("standalone_question") | retriever, "question": lambda x: x["standalone_question"],
} final_inputs = { "context": lambda x: _combine_documents(x["docs"]), "question": itemgetter("question"),
} answer = { "answer": final_inputs | ANSWER_PROMPT | ChatOpenAI(), "docs": itemgetter("docs"),
} # Create the final chain by combining the steps
final_chain = loaded_memory | standalone_question | retrieved_documents | answer inputs = {"question": "where did harrison work?"}
result = final_chain.invoke(inputs)
print(result)
এই উদাহরণে, কথোপকথনের ইতিহাস এবং উত্স নথি সংরক্ষণ এবং পুনরুদ্ধার করতে মেমরি ব্যবহার করা হয়।
একাধিক চেইন
আপনি Runnables ব্যবহার করে একাধিক চেইন একসাথে স্ট্রিং করতে পারেন। এখানে একটি উদাহরণ:
from operator import itemgetter from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser prompt1 = ChatPromptTemplate.from_template("what is the city {person} is from?")
prompt2 = ChatPromptTemplate.from_template( "what country is the city {city} in? respond in {language}"
) model = ChatOpenAI() chain1 = prompt1 | model | StrOutputParser() chain2 = ( {"city": chain1, "language": itemgetter("language")} | prompt2 | model | StrOutputParser()
) result = chain2.invoke({"person": "obama", "language": "spanish"})
print(result)
এই উদাহরণে, একটি নির্দিষ্ট ভাষায় একটি শহর এবং তার দেশ সম্পর্কে তথ্য তৈরি করতে দুটি চেইন একত্রিত হয়।
শাখা এবং মার্জিং
LCEL আপনাকে RunnableMaps ব্যবহার করে চেইনগুলিকে বিভক্ত এবং মার্জ করার অনুমতি দেয়। এখানে শাখা এবং মার্জ করার একটি উদাহরণ:
from operator import itemgetter from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser planner = ( ChatPromptTemplate.from_template("Generate an argument about: {input}") | ChatOpenAI() | StrOutputParser() | {"base_response": RunnablePassthrough()}
) arguments_for = ( ChatPromptTemplate.from_template( "List the pros or positive aspects of {base_response}" ) | ChatOpenAI() | StrOutputParser()
)
arguments_against = ( ChatPromptTemplate.from_template( "List the cons or negative aspects of {base_response}" ) | ChatOpenAI() | StrOutputParser()
) final_responder = ( ChatPromptTemplate.from_messages( [ ("ai", "{original_response}"), ("human", "Pros:n{results_1}nnCons:n{results_2}"), ("system", "Generate a final response given the critique"), ] ) | ChatOpenAI() | StrOutputParser()
) chain = ( planner | { "results_1": arguments_for, "results_2": arguments_against, "original_response": itemgetter("base_response"), } | final_responder
) result = chain.invoke({"input": "scrum"})
print(result)
এই উদাহরণে, একটি ব্রাঞ্চিং এবং মার্জিং চেইন একটি যুক্তি তৈরি করতে এবং একটি চূড়ান্ত প্রতিক্রিয়া তৈরি করার আগে এর সুবিধা এবং অসুবিধাগুলি মূল্যায়ন করতে ব্যবহৃত হয়।
LCEL দিয়ে পাইথন কোড লেখা
ল্যাংচেইন এক্সপ্রেশন ল্যাঙ্গুয়েজ (এলসিইএল) এর শক্তিশালী অ্যাপ্লিকেশনগুলির মধ্যে একটি হল ব্যবহারকারীর সমস্যা সমাধানের জন্য পাইথন কোড লেখা। পাইথন কোড লিখতে কীভাবে LCEL ব্যবহার করবেন তার একটি উদাহরণ নীচে দেওয়া হল:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain_experimental.utilities import PythonREPL template = """Write some python code to solve the user's problem. Return only python code in Markdown format, e.g.: ```python
....
```"""
prompt = ChatPromptTemplate.from_messages([("system", template), ("human", "{input}")]) model = ChatOpenAI() def _sanitize_output(text: str): _, after = text.split("```python") return after.split("```")[0] chain = prompt | model | StrOutputParser() | _sanitize_output | PythonREPL().run result = chain.invoke({"input": "what's 2 plus 2"})
print(result)
এই উদাহরণে, একজন ব্যবহারকারী ইনপুট প্রদান করে এবং সমস্যা সমাধানের জন্য LCEL পাইথন কোড তৈরি করে। কোডটি তারপর একটি পাইথন REPL ব্যবহার করে কার্যকর করা হয় এবং এর ফলে পাইথন কোডটি মার্কডাউন ফর্ম্যাটে ফেরত দেওয়া হয়।
অনুগ্রহ করে মনে রাখবেন যে একটি পাইথন REPL ব্যবহার করে নির্বিচারে কোড চালাতে পারে, তাই এটি সতর্কতার সাথে ব্যবহার করুন।
একটি চেইনে মেমরি যোগ করা হচ্ছে
অনেক কথোপকথন এআই অ্যাপ্লিকেশনে মেমরি অপরিহার্য। একটি নির্বিচারে শৃঙ্খলে মেমরি যুক্ত করার উপায় এখানে:
from operator import itemgetter
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder model = ChatOpenAI()
prompt = ChatPromptTemplate.from_messages( [ ("system", "You are a helpful chatbot"), MessagesPlaceholder(variable_name="history"), ("human", "{input}"), ]
) memory = ConversationBufferMemory(return_messages=True) # Initialize memory
memory.load_memory_variables({}) chain = ( RunnablePassthrough.assign( history=RunnableLambda(memory.load_memory_variables) | itemgetter("history") ) | prompt | model
) inputs = {"input": "hi, I'm Bob"}
response = chain.invoke(inputs)
response # Save the conversation in memory
memory.save_context(inputs, {"output": response.content}) # Load memory to see the conversation history
memory.load_memory_variables({})
এই উদাহরণে, কথোপকথনের ইতিহাস সংরক্ষণ এবং পুনরুদ্ধার করতে মেমরি ব্যবহার করা হয়, যা চ্যাটবটকে প্রসঙ্গ বজায় রাখতে এবং যথাযথভাবে প্রতিক্রিয়া জানাতে দেয়।
Runnables সহ বাহ্যিক সরঞ্জাম ব্যবহার করা
LCEL আপনাকে রানেবলের সাথে বাহ্যিক সরঞ্জামগুলিকে নির্বিঘ্নে সংহত করতে দেয়। এখানে DuckDuckGo অনুসন্ধান টুল ব্যবহার করে একটি উদাহরণ:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.tools import DuckDuckGoSearchRun search = DuckDuckGoSearchRun() template = """Turn the following user input into a search query for a search engine: {input}"""
prompt = ChatPromptTemplate.from_template(template) model = ChatOpenAI() chain = prompt | model | StrOutputParser() | search search_result = chain.invoke({"input": "I'd like to figure out what games are tonight"})
print(search_result)
এই উদাহরণে, LCEL DuckDuckGo সার্চ টুলটিকে চেইনের মধ্যে সংহত করে, এটি ব্যবহারকারীর ইনপুট থেকে একটি অনুসন্ধান ক্যোয়ারী তৈরি করতে এবং অনুসন্ধান ফলাফল পুনরুদ্ধার করার অনুমতি দেয়।
LCEL এর নমনীয়তা আপনার ভাষা প্রক্রিয়াকরণ পাইপলাইনে বিভিন্ন বাহ্যিক সরঞ্জাম এবং পরিষেবাগুলিকে অন্তর্ভুক্ত করা সহজ করে, তাদের ক্ষমতা এবং কার্যকারিতা বাড়ায়।
একটি এলএলএম অ্যাপ্লিকেশনে সংযম যোগ করা
আপনার LLM অ্যাপ্লিকেশানটি বিষয়বস্তু নীতিগুলি মেনে চলে এবং সংযম সুরক্ষাগুলি অন্তর্ভুক্ত করে তা নিশ্চিত করতে, আপনি আপনার চেইনে সংযম চেকগুলিকে একীভূত করতে পারেন৷ ল্যাংচেইন ব্যবহার করে কীভাবে সংযম যোগ করবেন তা এখানে:
from langchain.chains import OpenAIModerationChain
from langchain.llms import OpenAI
from langchain.prompts import ChatPromptTemplate moderate = OpenAIModerationChain() model = OpenAI()
prompt = ChatPromptTemplate.from_messages([("system", "repeat after me: {input}")]) chain = prompt | model # Original response without moderation
response_without_moderation = chain.invoke({"input": "you are stupid"})
print(response_without_moderation) moderated_chain = chain | moderate # Response after moderation
response_after_moderation = moderated_chain.invoke({"input": "you are stupid"})
print(response_after_moderation)
এই উদাহরণে, OpenAIModerationChain এলএলএম দ্বারা উত্পন্ন প্রতিক্রিয়াতে সংযম যোগ করতে ব্যবহৃত হয়। মডারেশন চেইন OpenAI এর বিষয়বস্তু নীতি লঙ্ঘন করে এমন সামগ্রীর প্রতিক্রিয়া পরীক্ষা করে। কোনো লঙ্ঘন পাওয়া গেলে, এটি সেই অনুযায়ী প্রতিক্রিয়া ফ্ল্যাগ করবে।
শব্দার্থিক সাদৃশ্য দ্বারা রাউটিং
LCEL আপনাকে ব্যবহারকারীর ইনপুটের শব্দার্থগত মিলের উপর ভিত্তি করে কাস্টম রাউটিং যুক্তি প্রয়োগ করতে দেয়। ব্যবহারকারীর ইনপুটের উপর ভিত্তি করে কীভাবে গতিশীলভাবে চেইন লজিক নির্ধারণ করা যায় তার একটি উদাহরণ এখানে দেওয়া হল:
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import PromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableLambda, RunnablePassthrough
from langchain.utils.math import cosine_similarity physics_template = """You are a very smart physics professor. You are great at answering questions about physics in a concise and easy to understand manner. When you don't know the answer to a question you admit that you don't know. Here is a question:
{query}""" math_template = """You are a very good mathematician. You are great at answering math questions. You are so good because you are able to break down hard problems into their component parts, answer the component parts, and then put them together to answer the broader question. Here is a question:
{query}""" embeddings = OpenAIEmbeddings()
prompt_templates = [physics_template, math_template]
prompt_embeddings = embeddings.embed_documents(prompt_templates) def prompt_router(input): query_embedding = embeddings.embed_query(input["query"]) similarity = cosine_similarity([query_embedding], prompt_embeddings)[0] most_similar = prompt_templates[similarity.argmax()] print("Using MATH" if most_similar == math_template else "Using PHYSICS") return PromptTemplate.from_template(most_similar) chain = ( {"query": RunnablePassthrough()} | RunnableLambda(prompt_router) | ChatOpenAI() | StrOutputParser()
) print(chain.invoke({"query": "What's a black hole"}))
print(chain.invoke({"query": "What's a path integral"}))
এই উদাহরণে, prompt_router ফাংশন ব্যবহারকারীর ইনপুট এবং পদার্থবিদ্যা এবং গণিত প্রশ্নের জন্য পূর্বনির্ধারিত প্রম্পট টেমপ্লেটের মধ্যে কোসাইন সাদৃশ্য গণনা করে। সাদৃশ্য স্কোরের উপর ভিত্তি করে, চেইন গতিশীলভাবে সবচেয়ে প্রাসঙ্গিক প্রম্পট টেমপ্লেট নির্বাচন করে, নিশ্চিত করে যে চ্যাটবট ব্যবহারকারীর প্রশ্নের যথাযথভাবে উত্তর দেয়।
এজেন্ট এবং রানেবল ব্যবহার করে
LangChain আপনাকে Runnables, প্রম্পট, মডেল এবং টুলস একত্রিত করে এজেন্ট তৈরি করতে দেয়। এখানে একটি এজেন্ট তৈরি এবং এটি ব্যবহার করার একটি উদাহরণ:
from langchain.agents import XMLAgent, tool, AgentExecutor
from langchain.chat_models import ChatAnthropic model = ChatAnthropic(model="claude-2") @tool
def search(query: str) -> str: """Search things about current events.""" return "32 degrees" tool_list = [search] # Get prompt to use
prompt = XMLAgent.get_default_prompt() # Logic for going from intermediate steps to a string to pass into the model
def convert_intermediate_steps(intermediate_steps): log = "" for action, observation in intermediate_steps: log += ( f"<tool>{action.tool}</tool><tool_input>{action.tool_input}" f"</tool_input><observation>{observation}</observation>" ) return log # Logic for converting tools to a string to go in the prompt
def convert_tools(tools): return "n".join([f"{tool.name}: {tool.description}" for tool in tools]) agent = ( { "question": lambda x: x["question"], "intermediate_steps": lambda x: convert_intermediate_steps( x["intermediate_steps"] ), } | prompt.partial(tools=convert_tools(tool_list)) | model.bind(stop=["</tool_input>", "</final_answer>"]) | XMLAgent.get_default_output_parser()
) agent_executor = AgentExecutor(agent=agent, tools=tool_list, verbose=True) result = agent_executor.invoke({"question": "What's the weather in New York?"})
print(result)
এই উদাহরণে, একটি মডেল, টুলস, একটি প্রম্পট এবং মধ্যবর্তী পদক্ষেপ এবং টুল রূপান্তরের জন্য একটি কাস্টম লজিক একত্রিত করে একটি এজেন্ট তৈরি করা হয়। ব্যবহারকারীর প্রশ্নের উত্তর প্রদান করে, এজেন্টকে তখন কার্যকর করা হয়।
একটি এসকিউএল ডাটাবেস জিজ্ঞাসা
আপনি একটি SQL ডাটাবেস অনুসন্ধান করতে এবং ব্যবহারকারীর প্রশ্নের উপর ভিত্তি করে SQL কোয়েরি তৈরি করতে LangChain ব্যবহার করতে পারেন। এখানে একটি উদাহরণ:
from langchain.prompts import ChatPromptTemplate template = """Based on the table schema below, write a SQL query that would answer the user's question:
{schema} Question: {question}
SQL Query:"""
prompt = ChatPromptTemplate.from_template(template) from langchain.utilities import SQLDatabase # Initialize the database (you'll need the Chinook sample DB for this example)
db = SQLDatabase.from_uri("sqlite:///./Chinook.db") def get_schema(_): return db.get_table_info() def run_query(query): return db.run(query) from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough model = ChatOpenAI() sql_response = ( RunnablePassthrough.assign(schema=get_schema) | prompt | model.bind(stop=["nSQLResult:"]) | StrOutputParser()
) result = sql_response.invoke({"question": "How many employees are there?"})
print(result) template = """Based on the table schema below, question, SQL query, and SQL response, write a natural language response:
{schema} Question: {question}
SQL Query: {query}
SQL Response: {response}"""
prompt_response = ChatPromptTemplate.from_template(template) full_chain = ( RunnablePassthrough.assign(query=sql_response) | RunnablePassthrough.assign( schema=get_schema, response=lambda x: db.run(x["query"]), ) | prompt_response | model
) response = full_chain.invoke({"question": "How many employees are there?"})
print(response)
এই উদাহরণে, LangChain ব্যবহারকারীর প্রশ্নের উপর ভিত্তি করে SQL কোয়েরি তৈরি করতে এবং SQL ডাটাবেস থেকে প্রতিক্রিয়া পুনরুদ্ধার করতে ব্যবহৃত হয়। প্রম্পট এবং প্রতিক্রিয়া ডাটাবেসের সাথে প্রাকৃতিক ভাষা মিথস্ক্রিয়া প্রদানের জন্য বিন্যাসিত হয়।
আমাদের AI-চালিত ওয়ার্কফ্লো নির্মাতার সাথে ম্যানুয়াল কাজ এবং ওয়ার্কফ্লোগুলি স্বয়ংক্রিয় করুন, আপনার এবং আপনার দলের জন্য Nanonets দ্বারা ডিজাইন করা হয়েছে৷
ল্যাংসার্ভ এবং ল্যাংস্মিথ
ল্যাংসার্ভ ডেভেলপারদের ল্যাংচেইন রানেবল এবং চেইনকে REST API হিসাবে স্থাপন করতে সাহায্য করে। এই লাইব্রেরিটি FastAPI এর সাথে একত্রিত এবং ডেটা যাচাইকরণের জন্য pydantic ব্যবহার করে। অতিরিক্তভাবে, এটি একটি ক্লায়েন্ট সরবরাহ করে যা একটি সার্ভারে স্থাপন করা রানেবলগুলিতে কল করতে ব্যবহার করা যেতে পারে এবং একটি জাভাস্ক্রিপ্ট ক্লায়েন্ট LangChainJS-এ উপলব্ধ।
বৈশিষ্ট্য
- ইনপুট এবং আউটপুট স্কিমাগুলি আপনার LangChain অবজেক্ট থেকে স্বয়ংক্রিয়ভাবে অনুমান করা হয় এবং সমৃদ্ধ ত্রুটি বার্তা সহ প্রতিটি API কলে প্রয়োগ করা হয়।
- JSONSchema এবং Swagger সহ একটি API ডক্স পৃষ্ঠা উপলব্ধ।
- একটি একক সার্ভারে অনেক সমসাময়িক অনুরোধের সমর্থন সহ দক্ষ /আমন্ত্রণ, /ব্যাচ এবং /স্ট্রিম এন্ডপয়েন্ট।
- আপনার চেইন/এজেন্ট থেকে সমস্ত (বা কিছু) মধ্যবর্তী ধাপ স্ট্রিম করার জন্য /stream_log এন্ডপয়েন্ট।
- স্ট্রিমিং আউটপুট এবং মধ্যবর্তী ধাপ সহ /খেলার মাঠে খেলার মাঠ পৃষ্ঠা।
- অন্তর্নির্মিত (ঐচ্ছিক) ল্যাংস্মিথের ট্রেসিং; শুধু আপনার API কী যোগ করুন (নির্দেশাবলী দেখুন)।
- যুদ্ধ-পরীক্ষিত ওপেন সোর্স পাইথন লাইব্রেরি যেমন FastAPI, Pydantic, uvloop এবং asyncio দিয়ে তৈরি করা হয়েছে।
সীমাবদ্ধতা
- ক্লায়েন্ট কলব্যাকগুলি এখনও সার্ভারে উদ্ভূত ইভেন্টগুলির জন্য সমর্থিত নয়৷
- Pydantic V2 ব্যবহার করার সময় OpenAPI ডক্স তৈরি করা হবে না। FastAPI pydantic v1 এবং v2 নামস্থান মিশ্রিত করা সমর্থন করে না। আরো বিস্তারিত জানার জন্য নীচের বিভাগ দেখুন.
একটি LangServe প্রকল্পকে দ্রুত বুটস্ট্র্যাপ করতে LangChain CLI ব্যবহার করুন। ল্যাংচেন সিএলআই ব্যবহার করতে, নিশ্চিত করুন যে আপনার কাছে ল্যাংচেইন-ক্লি-এর সাম্প্রতিক সংস্করণ ইনস্টল করা আছে। আপনি পিপ ইন্সটল -U langchain-cli দিয়ে ইন্সটল করতে পারেন।
langchain app new ../path/to/directory
LangChain টেমপ্লেটগুলির সাথে আপনার LangServe দৃষ্টান্ত দ্রুত শুরু করুন। আরও উদাহরণের জন্য, টেমপ্লেট সূচী বা উদাহরণ ডিরেক্টরি দেখুন।
এখানে একটি সার্ভার রয়েছে যা একটি OpenAI চ্যাট মডেল, একটি নৃতাত্ত্বিক চ্যাট মডেল এবং একটি চেইন স্থাপন করে যা একটি বিষয় সম্পর্কে একটি রসিকতা বলার জন্য নৃতাত্ত্বিক মডেল ব্যবহার করে৷
#!/usr/bin/env python
from fastapi import FastAPI
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatAnthropic, ChatOpenAI
from langserve import add_routes app = FastAPI( title="LangChain Server", version="1.0", description="A simple api server using Langchain's Runnable interfaces",
) add_routes( app, ChatOpenAI(), path="/openai",
) add_routes( app, ChatAnthropic(), path="/anthropic",
) model = ChatAnthropic()
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
add_routes( app, prompt | model, path="/chain",
) if __name__ == "__main__": import uvicorn uvicorn.run(app, host="localhost", port=8000)
একবার আপনি উপরের সার্ভারটি স্থাপন করার পরে, আপনি এটি ব্যবহার করে জেনারেট করা OpenAPI ডক্স দেখতে পারেন:
curl localhost:8000/docs
/docs প্রত্যয় যোগ করতে ভুলবেন না।
from langchain.schema import SystemMessage, HumanMessage
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnableMap
from langserve import RemoteRunnable openai = RemoteRunnable("https://localhost:8000/openai/")
anthropic = RemoteRunnable("https://localhost:8000/anthropic/")
joke_chain = RemoteRunnable("https://localhost:8000/chain/") joke_chain.invoke({"topic": "parrots"}) # or async
await joke_chain.ainvoke({"topic": "parrots"}) prompt = [ SystemMessage(content='Act like either a cat or a parrot.'), HumanMessage(content='Hello!')
] # Supports astream
async for msg in anthropic.astream(prompt): print(msg, end="", flush=True) prompt = ChatPromptTemplate.from_messages( [("system", "Tell me a long story about {topic}")]
) # Can define custom chains
chain = prompt | RunnableMap({ "openai": openai, "anthropic": anthropic,
}) chain.batch([{ "topic": "parrots" }, { "topic": "cats" }])
TypeScript-এ (LangChain.js সংস্করণ 0.0.166 বা তার পরে প্রয়োজন):
import { RemoteRunnable } from "langchain/runnables/remote"; const chain = new RemoteRunnable({ url: `https://localhost:8000/chain/invoke/`,
});
const result = await chain.invoke({ topic: "cats",
});
অনুরোধ ব্যবহার করে পাইথন:
import requests
response = requests.post( "https://localhost:8000/chain/invoke/", json={'input': {'topic': 'cats'}}
)
response.json()
আপনি কার্ল ব্যবহার করতে পারেন:
curl --location --request POST 'https://localhost:8000/chain/invoke/' --header 'Content-Type: application/json' --data-raw '{ "input": { "topic": "cats" } }'
নিম্নলিখিত কোড:
...
add_routes( app, runnable, path="/my_runnable",
)
সার্ভারে এই শেষ পয়েন্ট যোগ করে:
- POST/my_runnable/invoke - একটি একক ইনপুটে রানেবলকে আহ্বান করুন
- POST/my_runnable/batch - ইনপুটগুলির একটি ব্যাচে রানেবলকে আহ্বান করুন
- POST/my_runnable/stream - একটি একক ইনপুট চালু করুন এবং আউটপুট স্ট্রিম করুন
- POST/my_runnable/stream_log - একটি একক ইনপুট চালু করুন এবং আউটপুটটি স্ট্রিম করুন, যার মধ্যে মধ্যবর্তী ধাপের আউটপুটটি তৈরি করা হয়েছে।
- GET /my_runnable/input_schema – রানেবল ইনপুট করার জন্য json স্কিমা
- GET /my_runnable/output_schema - রানেবলের আউটপুটের জন্য json স্কিমা
- GET /my_runnable/config_schema - রানেবলের কনফিগারেশনের জন্য json স্কিমা
আপনি /my_runnable/playground এ আপনার রানেবলের জন্য একটি খেলার মাঠ পৃষ্ঠা খুঁজে পেতে পারেন। এটি স্ট্রিমিং আউটপুট এবং মধ্যবর্তী ধাপগুলির সাথে আপনার রানেবলকে কনফিগার করতে এবং আহ্বান করতে একটি সাধারণ UI প্রকাশ করে।
ক্লায়েন্ট এবং সার্ভার উভয়ের জন্য:
pip install "langserve[all]"
অথবা ক্লায়েন্ট কোডের জন্য পিপ ইনস্টল "ল্যাংসার্ভ[ক্লায়েন্ট]" এবং সার্ভার কোডের জন্য পিপ ইনস্টল "ল্যাংসার্ভ[সার্ভার]"।
আপনার সার্ভারে প্রমাণীকরণ যোগ করার প্রয়োজন হলে, অনুগ্রহ করে FastAPI এর নিরাপত্তা ডকুমেন্টেশন এবং মিডলওয়্যার ডকুমেন্টেশন উল্লেখ করুন।
আপনি নিম্নলিখিত কমান্ড ব্যবহার করে GCP ক্লাউড রানে স্থাপন করতে পারেন:
gcloud run deploy [your-service-name] --source . --port 8001 --allow-unauthenticated --region us-central1 --set-env-vars=OPENAI_API_KEY=your_key
LangServe কিছু সীমাবদ্ধতা সহ Pydantic 2 এর জন্য সমর্থন প্রদান করে। Pydantic V2 ব্যবহার করার সময় invoke/batch/stream/stream_log-এর জন্য OpenAPI ডক্স তৈরি করা হবে না। ফাস্ট API pydantic v1 এবং v2 নেমস্পেস মিশ্রিত করা সমর্থন করে না। LangChain Pydantic v1 এ v2 নামস্থান ব্যবহার করে। LangChain এর সাথে সামঞ্জস্যতা নিশ্চিত করতে অনুগ্রহ করে নিম্নলিখিত নির্দেশিকা পড়ুন। এই সীমাবদ্ধতাগুলি ব্যতীত, আমরা আশা করি এপিআই এন্ডপয়েন্ট, খেলার মাঠ এবং অন্যান্য বৈশিষ্ট্যগুলি প্রত্যাশিত হিসাবে কাজ করবে।
এলএলএম অ্যাপ্লিকেশনগুলি প্রায়শই ফাইলগুলির সাথে কাজ করে। ফাইল প্রসেসিং বাস্তবায়নের জন্য বিভিন্ন আর্কিটেকচার তৈরি করা যেতে পারে; উচ্চ স্তরে:
- ফাইলটি একটি ডেডিকেটেড এন্ডপয়েন্টের মাধ্যমে সার্ভারে আপলোড করা হতে পারে এবং একটি পৃথক এন্ডপয়েন্ট ব্যবহার করে প্রক্রিয়া করা হতে পারে।
- ফাইলটি মান (ফাইলের বাইট) বা রেফারেন্স (যেমন, ফাইল সামগ্রীতে s3 ইউআরএল) দ্বারা আপলোড করা যেতে পারে।
- প্রসেসিং এন্ডপয়েন্ট ব্লকিং বা অ-ব্লকিং হতে পারে।
- উল্লেখযোগ্য প্রক্রিয়াকরণের প্রয়োজন হলে, প্রক্রিয়াকরণ একটি ডেডিকেটেড প্রসেস পুলে অফলোড করা যেতে পারে।
আপনার আবেদনের জন্য উপযুক্ত আর্কিটেকচার কি তা নির্ধারণ করা উচিত। বর্তমানে, একটি রানেবলে মান অনুযায়ী ফাইল আপলোড করতে, ফাইলের জন্য base64 এনকোডিং ব্যবহার করুন (মাল্টিপার্ট/ফর্ম-ডেটা এখনও সমর্থিত নয়)।
এখানে একটি উদাহরণ এটি দেখায় কিভাবে একটি দূরবর্তী রানেবলে একটি ফাইল পাঠাতে base64 এনকোডিং ব্যবহার করতে হয়। মনে রাখবেন, আপনি সবসময় রেফারেন্সের মাধ্যমে ফাইল আপলোড করতে পারেন (যেমন, s3 url) অথবা একটি ডেডিকেটেড এন্ডপয়েন্টে মাল্টিপার্ট/ফর্ম-ডেটা হিসেবে আপলোড করতে পারেন।
ইনপুট এবং আউটপুট প্রকারগুলি সমস্ত রানেবলে সংজ্ঞায়িত করা হয়। আপনি input_schema এবং output_schema বৈশিষ্ট্যের মাধ্যমে তাদের অ্যাক্সেস করতে পারেন। ল্যাংসার্ভ এই ধরনের বৈধতা এবং ডকুমেন্টেশনের জন্য ব্যবহার করে। আপনি যদি ডিফল্ট অনুমানকৃত প্রকারগুলিকে ওভাররাইড করতে চান তবে আপনি with_types পদ্ধতিটি ব্যবহার করতে পারেন।
ধারণাটি ব্যাখ্যা করার জন্য এখানে একটি খেলনা উদাহরণ:
from typing import Any
from fastapi import FastAPI
from langchain.schema.runnable import RunnableLambda app = FastAPI() def func(x: Any) -> int: """Mistyped function that should accept an int but accepts anything.""" return x + 1 runnable = RunnableLambda(func).with_types( input_schema=int,
) add_routes(app, runnable)
CustomUserType থেকে ইনহেরিট করুন যদি আপনি ডেটাকে সমতুল্য ডিক্ট উপস্থাপনার পরিবর্তে একটি পাইডান্টিক মডেলে ডিসিরিয়ালাইজ করতে চান। এই মুহূর্তে, এই ধরনের শুধুমাত্র সার্ভার-সাইড কাজ করে এবং পছন্দসই ডিকোডিং আচরণ নির্দিষ্ট করতে ব্যবহৃত হয়। যদি এই ধরনের থেকে উত্তরাধিকারসূত্রে পাওয়া যায়, সার্ভার ডিকোড টাইপটিকে একটি ডিক্টে রূপান্তরিত করার পরিবর্তে একটি পাইডানটিক মডেল হিসাবে রাখবে।
from fastapi import FastAPI
from langchain.schema.runnable import RunnableLambda
from langserve import add_routes
from langserve.schema import CustomUserType app = FastAPI() class Foo(CustomUserType): bar: int def func(foo: Foo) -> int: """Sample function that expects a Foo type which is a pydantic model""" assert isinstance(foo, Foo) return foo.bar add_routes(app, RunnableLambda(func), path="/foo")
খেলার মাঠ আপনাকে ব্যাকএন্ড থেকে আপনার চালানোর জন্য কাস্টম উইজেটগুলি সংজ্ঞায়িত করতে দেয়। একটি উইজেট ফিল্ড লেভেলে নির্দিষ্ট করা হয় এবং ইনপুট টাইপের JSON স্কিমার অংশ হিসেবে পাঠানো হয়। একটি উইজেটে অবশ্যই টাইপ নামক একটি কী থাকতে হবে যার মানটি উইজেটের একটি সুপরিচিত তালিকার একটি। অন্যান্য উইজেট কীগুলি এমন মানগুলির সাথে যুক্ত হবে যা একটি JSON অবজেক্টে পাথ বর্ণনা করে।
সাধারণ স্কিমা:
type JsonPath = number | string | (number | string)[];
type NameSpacedPath = { title: string; path: JsonPath }; // Using title to mimic json schema, but can use namespace
type OneOfPath = { oneOf: JsonPath[] }; type Widget = { type: string // Some well-known type (e.g., base64file, chat, etc.) [key: string]: JsonPath | NameSpacedPath | OneOfPath;
};
বেস64 এনকোডেড স্ট্রিং হিসাবে আপলোড করা ফাইলগুলির জন্য UI খেলার মাঠে একটি ফাইল আপলোড ইনপুট তৈরি করার অনুমতি দেয়৷ এখানে সম্পূর্ণ উদাহরণ.
try: from pydantic.v1 import Field
except ImportError: from pydantic import Field from langserve import CustomUserType # ATTENTION: Inherit from CustomUserType instead of BaseModel otherwise
# the server will decode it into a dict instead of a pydantic model.
class FileProcessingRequest(CustomUserType): """Request including a base64 encoded file.""" # The extra field is used to specify a widget for the playground UI. file: str = Field(..., extra={"widget": {"type": "base64file"}}) num_chars: int = 100
আমাদের AI-চালিত ওয়ার্কফ্লো নির্মাতার সাথে ম্যানুয়াল কাজ এবং ওয়ার্কফ্লোগুলি স্বয়ংক্রিয় করুন, আপনার এবং আপনার দলের জন্য Nanonets দ্বারা ডিজাইন করা হয়েছে৷
ল্যাংস্মিথের পরিচিতি
LangChain LLM অ্যাপ্লিকেশন এবং এজেন্ট প্রোটোটাইপ করা সহজ করে তোলে। যাইহোক, উৎপাদনে এলএলএম অ্যাপ্লিকেশন সরবরাহ করা প্রতারণামূলকভাবে কঠিন হতে পারে। একটি উচ্চ-মানের পণ্য তৈরি করার জন্য আপনাকে সম্ভবত আপনার প্রম্পট, চেইন এবং অন্যান্য উপাদানগুলিতে ব্যাপকভাবে কাস্টমাইজ এবং পুনরাবৃত্তি করতে হবে।
এই প্রক্রিয়ায় সাহায্য করার জন্য, ল্যাংস্মিথ চালু করা হয়েছিল, আপনার LLM অ্যাপ্লিকেশনগুলি ডিবাগিং, পরীক্ষা এবং নিরীক্ষণের জন্য একটি একীভূত প্ল্যাটফর্ম।
এই কখন কাজে আসতে পারে? আপনি যখন একটি নতুন চেইন, এজেন্ট, বা টুলের সেট দ্রুত ডিবাগ করতে চান, কম্পোনেন্ট (চেইন, এলএলএমএস, রিট্রিভারস, ইত্যাদি) কীভাবে সম্পর্কযুক্ত এবং ব্যবহার করা হয় তা কল্পনা করতে, একটি একক উপাদানের জন্য বিভিন্ন প্রম্পট এবং এলএলএম মূল্যায়ন করতে চাইলে এটি আপনার কাজে লাগতে পারে, একটি প্রদত্ত চেইন একটি ডেটাসেটের উপর কয়েকবার চালান যাতে এটি ধারাবাহিকভাবে একটি গুণমানের বারের সাথে মিলিত হয়, বা ব্যবহারের চিহ্নগুলি ক্যাপচার করে এবং অন্তর্দৃষ্টি তৈরি করতে এলএলএম বা বিশ্লেষণ পাইপলাইন ব্যবহার করে।
পূর্বশর্ত:
- একটি ল্যাংস্মিথ অ্যাকাউন্ট তৈরি করুন এবং একটি API কী তৈরি করুন (নীচের বাম কোণে দেখুন)।
- ডক্সের মাধ্যমে প্ল্যাটফর্মের সাথে নিজেকে পরিচিত করুন।
এখন, শুরু করা যাক!
প্রথমে, ল্যাংচেইনকে ট্রেস লগ করতে বলার জন্য আপনার পরিবেশের ভেরিয়েবল কনফিগার করুন। LANGCHAIN_TRACING_V2 এনভায়রনমেন্ট ভেরিয়েবলকে সত্যে সেট করে এটি করা হয়। আপনি LANGCHAIN_PROJECT এনভায়রনমেন্ট ভেরিয়েবল সেট করে কোন প্রোজেক্টে লগ করতে হবে তা LangChain কে বলতে পারেন (যদি এটি সেট করা না থাকে, তাহলে রানগুলি ডিফল্ট প্রোজেক্টে লগ করা হবে)। এটি স্বয়ংক্রিয়ভাবে আপনার জন্য প্রকল্প তৈরি করবে যদি এটি বিদ্যমান না থাকে। এছাড়াও আপনাকে অবশ্যই LANGCHAIN_ENDPOINT এবং LANGCHAIN_API_KEY পরিবেশ ভেরিয়েবল সেট করতে হবে৷
দ্রষ্টব্য: আপনি ব্যবহার করে ট্রেস লগ করতে পাইথনে একটি প্রসঙ্গ পরিচালকও ব্যবহার করতে পারেন:
from langchain.callbacks.manager import tracing_v2_enabled with tracing_v2_enabled(project_name="My Project"): agent.run("How many people live in canada as of 2023?")
যাইহোক, এই উদাহরণে, আমরা পরিবেশ ভেরিয়েবল ব্যবহার করব।
%pip install openai tiktoken pandas duckduckgo-search --quiet import os
from uuid import uuid4 unique_id = uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"Tracing Walkthrough - {unique_id}"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "<YOUR-API-KEY>" # Update to your API key # Used by the agent in this tutorial
os.environ["OPENAI_API_KEY"] = "<YOUR-OPENAI-API-KEY>"
API এর সাথে ইন্টারঅ্যাক্ট করতে ল্যাংস্মিথ ক্লায়েন্ট তৈরি করুন:
from langsmith import Client client = Client()
একটি LangChain উপাদান তৈরি করুন এবং প্ল্যাটফর্মে লগ রান করুন। এই উদাহরণে, আমরা একটি সাধারণ অনুসন্ধান টুল (DuckDuckGo) অ্যাক্সেস সহ একটি ReAct-শৈলী এজেন্ট তৈরি করব। এজেন্টের প্রম্পট এখানে হাবে দেখা যেতে পারে:
from langchain import hub
from langchain.agents import AgentExecutor
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.chat_models import ChatOpenAI
from langchain.tools import DuckDuckGoSearchResults
from langchain.tools.render import format_tool_to_openai_function # Fetches the latest version of this prompt
prompt = hub.pull("wfh/langsmith-agent-prompt:latest") llm = ChatOpenAI( model="gpt-3.5-turbo-16k", temperature=0,
) tools = [ DuckDuckGoSearchResults( name="duck_duck_go" ), # General internet search using DuckDuckGo
] llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools]) runnable_agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
) agent_executor = AgentExecutor( agent=runnable_agent, tools=tools, handle_parsing_errors=True
)
লেটেন্সি কমাতে আমরা একাধিক ইনপুটে একযোগে এজেন্ট চালাচ্ছি। রানগুলি ব্যাকগ্রাউন্ডে ল্যাংস্মিথের সাথে লগ করা হয়, তাই কার্যকর করার লেটেন্সি প্রভাবিত হয় না:
inputs = [ "What is LangChain?", "What's LangSmith?", "When was Llama-v2 released?", "What is the langsmith cookbook?", "When did langchain first announce the hub?",
] results = agent_executor.batch([{"input": x} for x in inputs], return_exceptions=True) results[:2]
ধরে নিই যে আপনি সফলভাবে আপনার পরিবেশ সেট আপ করেছেন, আপনার এজেন্ট ট্রেসগুলি অ্যাপের প্রকল্প বিভাগে প্রদর্শিত হবে। অভিনন্দন!
দেখে মনে হচ্ছে এজেন্ট যদিও কার্যকরভাবে সরঞ্জামগুলি ব্যবহার করছে না। এর মূল্যায়ন করা যাক তাই আমাদের একটি বেসলাইন আছে।
লগিং রান ছাড়াও, ল্যাংস্মিথ আপনাকে আপনার LLM অ্যাপ্লিকেশনগুলি পরীক্ষা এবং মূল্যায়ন করার অনুমতি দেয়।
এই বিভাগে, আপনি একটি বেঞ্চমার্ক ডেটাসেট তৈরি করতে এবং এজেন্টের উপর এআই-সহায়ক মূল্যায়নকারীদের চালাতে ল্যাংস্মিথের সাহায্য নেবেন। আপনি কয়েকটি ধাপে তা করবেন:
- একটি ল্যাংস্মিথ ডেটাসেট তৈরি করুন:
নীচে, আমরা উপরে থেকে ইনপুট প্রশ্ন এবং একটি তালিকা লেবেল থেকে একটি ডেটাসেট তৈরি করতে ল্যাংস্মিথ ক্লায়েন্ট ব্যবহার করি। আপনি একটি নতুন এজেন্টের জন্য কর্মক্ষমতা পরিমাপ করতে পরে এগুলি ব্যবহার করবেন৷ একটি ডেটাসেট হল উদাহরণের একটি সংগ্রহ, যেগুলি ইনপুট-আউটপুট জোড়া ছাড়া আর কিছুই নয় যা আপনি আপনার অ্যাপ্লিকেশনের পরীক্ষার ক্ষেত্রে ব্যবহার করতে পারেন:
outputs = [ "LangChain is an open-source framework for building applications using large language models. It is also the name of the company building LangSmith.", "LangSmith is a unified platform for debugging, testing, and monitoring language model applications and agents powered by LangChain", "July 18, 2023", "The langsmith cookbook is a github repository containing detailed examples of how to use LangSmith to debug, evaluate, and monitor large language model-powered applications.", "September 5, 2023",
] dataset_name = f"agent-qa-{unique_id}" dataset = client.create_dataset( dataset_name, description="An example dataset of questions over the LangSmith documentation.",
) for query, answer in zip(inputs, outputs): client.create_example( inputs={"input": query}, outputs={"output": answer}, dataset_id=dataset.id )
- বেঞ্চমার্কে একটি নতুন এজেন্ট শুরু করুন:
ল্যাংস্মিথ আপনাকে যেকোনো এলএলএম, চেইন, এজেন্ট বা এমনকি একটি কাস্টম ফাংশন মূল্যায়ন করতে দেয়। কথোপকথন এজেন্ট রাষ্ট্রীয় (তাদের স্মৃতি আছে); ডেটাসেট রানের মধ্যে এই অবস্থাটি ভাগ করা হয়নি তা নিশ্চিত করতে, আমরা একটি চেইন_ফ্যাক্টরিতে পাস করব (
ওরফে একটি কনস্ট্রাক্টর) ফাংশন প্রতিটি কলের জন্য আরম্ভ করার জন্য:
# Since chains can be stateful (e.g. they can have memory), we provide
# a way to initialize a new chain for each row in the dataset. This is done
# by passing in a factory function that returns a new chain for each row.
def agent_factory(prompt): llm_with_tools = llm.bind( functions=[format_tool_to_openai_function(t) for t in tools] ) runnable_agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser() ) return AgentExecutor(agent=runnable_agent, tools=tools, handle_parsing_errors=True)
- মূল্যায়ন কনফিগার করুন:
UI-তে চেইনের ফলাফল ম্যানুয়ালি তুলনা করা কার্যকর, তবে এটি সময়সাপেক্ষ হতে পারে। আপনার উপাদানের কর্মক্ষমতা মূল্যায়ন করতে স্বয়ংক্রিয় মেট্রিক্স এবং এআই-সহায়ক প্রতিক্রিয়া ব্যবহার করা সহায়ক হতে পারে:
from langchain.evaluation import EvaluatorType
from langchain.smith import RunEvalConfig evaluation_config = RunEvalConfig( evaluators=[ EvaluatorType.QA, EvaluatorType.EMBEDDING_DISTANCE, RunEvalConfig.LabeledCriteria("helpfulness"), RunEvalConfig.LabeledScoreString( { "accuracy": """
Score 1: The answer is completely unrelated to the reference.
Score 3: The answer has minor relevance but does not align with the reference.
Score 5: The answer has moderate relevance but contains inaccuracies.
Score 7: The answer aligns with the reference but has minor errors or omissions.
Score 10: The answer is completely accurate and aligns perfectly with the reference.""" }, normalize_by=10, ), ], custom_evaluators=[],
)
- এজেন্ট এবং মূল্যায়নকারীদের চালান:
আপনার মডেল মূল্যায়ন করতে run_on_dataset (বা অ্যাসিঙ্ক্রোনাস arun_on_dataset) ফাংশন ব্যবহার করুন। এটা হবে:
- নির্দিষ্ট ডেটাসেট থেকে উদাহরণ সারি আনুন.
- প্রতিটি উদাহরণে আপনার এজেন্ট (বা কোনো কাস্টম ফাংশন) চালান।
- স্বয়ংক্রিয় প্রতিক্রিয়া তৈরি করতে ফলস্বরূপ রান ট্রেস এবং সংশ্লিষ্ট রেফারেন্স উদাহরণগুলিতে মূল্যায়নকারীদের প্রয়োগ করুন।
ফলাফল LangSmith অ্যাপে দৃশ্যমান হবে:
chain_results = run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=functools.partial(agent_factory, prompt=prompt), evaluation=evaluation_config, verbose=True, client=client, project_name=f"runnable-agent-test-5d466cbc-{unique_id}", tags=[ "testing-notebook", "prompt:5d466cbc", ],
)
এখন যেহেতু আমাদের পরীক্ষা চালানোর ফলাফল আছে, আমরা আমাদের এজেন্টে পরিবর্তন করতে পারি এবং সেগুলিকে বেঞ্চমার্ক করতে পারি। একটি ভিন্ন প্রম্পট দিয়ে এটি আবার চেষ্টা করুন এবং ফলাফল দেখুন:
candidate_prompt = hub.pull("wfh/langsmith-agent-prompt:39f3bbd0") chain_results = run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=functools.partial(agent_factory, prompt=candidate_prompt), evaluation=evaluation_config, verbose=True, client=client, project_name=f"runnable-agent-test-39f3bbd0-{unique_id}", tags=[ "testing-notebook", "prompt:39f3bbd0", ],
)
ল্যাংস্মিথ আপনাকে সরাসরি ওয়েব অ্যাপে CSV বা JSONL-এর মতো সাধারণ ফর্ম্যাটে ডেটা রপ্তানি করতে দেয়। আপনি আরও বিশ্লেষণের জন্য রান আনতে, আপনার নিজস্ব ডাটাবেসে সঞ্চয় করতে বা অন্যদের সাথে ভাগ করতে ক্লায়েন্টকে ব্যবহার করতে পারেন। চলুন মূল্যায়ন রান থেকে রান ট্রেস নিয়ে আসা যাক:
runs = client.list_runs(project_name=chain_results["project_name"], execution_order=1) # After some time, these will be populated.
client.read_project(project_name=chain_results["project_name"]).feedback_stats
এটি শুরু করার জন্য একটি দ্রুত নির্দেশিকা ছিল, কিন্তু আপনার বিকাশকারী প্রবাহকে গতিশীল করতে এবং আরও ভাল ফলাফল তৈরি করতে ল্যাংস্মিথ ব্যবহার করার আরও অনেক উপায় রয়েছে৷
আপনি কীভাবে ল্যাংস্মিথ থেকে সর্বাধিক সুবিধা পেতে পারেন সে সম্পর্কে আরও তথ্যের জন্য, ল্যাংস্মিথ ডকুমেন্টেশন দেখুন।
ন্যানোনেটের সাথে লেভেল আপ করুন
ল্যাংচেইন আপনার অ্যাপ্লিকেশনের সাথে ভাষা মডেল (LLM) একীভূত করার জন্য একটি মূল্যবান হাতিয়ার হলেও, এন্টারপ্রাইজ ব্যবহারের ক্ষেত্রে এটি সীমাবদ্ধতার সম্মুখীন হতে পারে। এই চ্যালেঞ্জ মোকাবেলায় Nanonets কিভাবে LangChain এর বাইরে যায় তা অন্বেষণ করা যাক:
1. ব্যাপক ডেটা সংযোগ:
LangChain সংযোগকারীগুলি অফার করে, তবে এটি ব্যবসার উপর নির্ভর করে এমন সমস্ত কর্মক্ষেত্র অ্যাপ এবং ডেটা ফর্ম্যাটগুলিকে কভার নাও করতে পারে৷ Nanonets 100 টিরও বেশি বহুল ব্যবহৃত ওয়ার্কস্পেস অ্যাপের জন্য ডেটা সংযোগকারী সরবরাহ করে, যার মধ্যে Slack, Notion, Google Suite, Salesforce, Zendesk এবং আরও অনেক কিছু রয়েছে। এটি পিডিএফ, TXT, ছবি, অডিও ফাইল এবং ভিডিও ফাইলের পাশাপাশি CSV, স্প্রেডশীট, MongoDB এবং SQL ডাটাবেসের মতো স্ট্রাকচার্ড ডেটা টাইপগুলির মতো সমস্ত অসংগঠিত ডেটা প্রকারগুলিকেও সমর্থন করে৷

2. ওয়ার্কস্পেস অ্যাপের জন্য টাস্ক অটোমেশন:
যদিও টেক্সট/প্রতিক্রিয়া জেনারেশন দুর্দান্ত কাজ করে, ল্যাংচেইনের ক্ষমতা সীমিত যখন এটি বিভিন্ন অ্যাপ্লিকেশনে কাজ সম্পাদন করার জন্য প্রাকৃতিক ভাষা ব্যবহার করে আসে। Nanonets সর্বাধিক জনপ্রিয় ওয়ার্কস্পেস অ্যাপের জন্য ট্রিগার/অ্যাকশন এজেন্ট অফার করে, যা আপনাকে ওয়ার্কফ্লো সেট আপ করার অনুমতি দেয় যা ইভেন্টের জন্য শোনে এবং ক্রিয়া সম্পাদন করে। উদাহরণস্বরূপ, আপনি প্রাকৃতিক ভাষা কমান্ডের মাধ্যমে ইমেল প্রতিক্রিয়া, CRM এন্ট্রি, SQL কোয়েরি এবং আরও অনেক কিছু স্বয়ংক্রিয়ভাবে করতে পারেন।

3. রিয়েল-টাইম ডেটা সিঙ্ক:
LangChain ডেটা সংযোগকারীর সাথে স্ট্যাটিক ডেটা নিয়ে আসে, যা উৎস ডাটাবেসের ডেটা পরিবর্তনের সাথে নাও থাকতে পারে। বিপরীতে, Nanonets ডেটা উত্সগুলির সাথে রিয়েল-টাইম সিঙ্ক্রোনাইজেশন নিশ্চিত করে, নিশ্চিত করে যে আপনি সর্বদা সর্বশেষ তথ্য নিয়ে কাজ করছেন।

3. সরলীকৃত কনফিগারেশন:
ল্যাংচেইন পাইপলাইনের উপাদানগুলি কনফিগার করা, যেমন পুনরুদ্ধারকারী এবং সিন্থেসাইজার, একটি জটিল এবং সময়সাপেক্ষ প্রক্রিয়া হতে পারে। Nanonets প্রতিটি ডেটা টাইপের জন্য অপ্টিমাইজ করা ডেটা ইনজেশন এবং ইন্ডেক্সিং প্রদান করে এটিকে স্ট্রীমলাইন করে, যা এআই অ্যাসিস্ট্যান্ট দ্বারা ব্যাকগ্রাউন্ডে পরিচালিত হয়। এটি ফাইন-টিউনিংয়ের বোঝা কমায় এবং সেট আপ এবং ব্যবহার করা সহজ করে তোলে।
4. একীভূত সমাধান:
LangChain এর বিপরীতে, যার প্রতিটি কাজের জন্য অনন্য বাস্তবায়নের প্রয়োজন হতে পারে, Nanonets আপনার ডেটা LLM-এর সাথে সংযুক্ত করার জন্য এক-স্টপ সমাধান হিসাবে কাজ করে। আপনার LLM অ্যাপ্লিকেশন বা AI ওয়ার্কফ্লো তৈরি করতে হবে না কেন, Nanonets আপনার বিভিন্ন প্রয়োজনের জন্য একটি ইউনিফাইড প্ল্যাটফর্ম অফার করে।
Nanonets AI ওয়ার্কফ্লোস
Nanonets Workflows হল একটি নিরাপদ, বহুমুখী AI সহকারী যা LLM-এর সাথে আপনার জ্ঞান এবং ডেটার একীকরণকে সহজ করে এবং নো-কোড অ্যাপ্লিকেশন এবং ওয়ার্কফ্লো তৈরির সুবিধা দেয়। এটি একটি সহজে ব্যবহারযোগ্য ইউজার ইন্টারফেস অফার করে, এটি ব্যক্তি এবং সংস্থা উভয়ের জন্যই অ্যাক্সেসযোগ্য করে তোলে।
শুরু করার জন্য, আপনি আমাদের AI বিশেষজ্ঞদের একজনের সাথে একটি কলের সময়সূচী করতে পারেন, যিনি আপনার নির্দিষ্ট ব্যবহারের ক্ষেত্রে তৈরি করা Nanonets Workflows-এর একটি ব্যক্তিগতকৃত ডেমো এবং ট্রায়াল প্রদান করতে পারেন।
একবার সেট আপ হয়ে গেলে, আপনি আপনার অ্যাপস এবং ডেটার সাথে নির্বিঘ্নে একত্রিত হয়ে LLM দ্বারা চালিত জটিল অ্যাপ্লিকেশন এবং ওয়ার্কফ্লোগুলি ডিজাইন এবং কার্যকর করতে প্রাকৃতিক ভাষা ব্যবহার করতে পারেন।

অ্যাপ তৈরি করতে এবং এআই-চালিত অ্যাপ্লিকেশান এবং ওয়ার্কফ্লোগুলির সাথে আপনার ডেটা একীভূত করতে Nanonets AI এর সাথে আপনার টিমগুলিকে সুপারচার্জ করুন, আপনার দলগুলিকে সত্যিকারের গুরুত্বপূর্ণ বিষয়গুলিতে ফোকাস করার অনুমতি দেয়৷
আমাদের AI-চালিত ওয়ার্কফ্লো নির্মাতার সাথে ম্যানুয়াল কাজ এবং ওয়ার্কফ্লোগুলি স্বয়ংক্রিয় করুন, আপনার এবং আপনার দলের জন্য Nanonets দ্বারা ডিজাইন করা হয়েছে৷
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- PlatoData.Network উল্লম্ব জেনারেটিভ Ai. নিজেকে ক্ষমতায়িত করুন। এখানে প্রবেশ করুন.
- প্লেটোএআইস্ট্রিম। Web3 ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- প্লেটোইএসজি। কার্বন, ক্লিনটেক, শক্তি, পরিবেশ সৌর, বর্জ্য ব্যবস্থাপনা. এখানে প্রবেশ করুন.
- প্লেটো হেলথ। বায়োটেক এবং ক্লিনিক্যাল ট্রায়াল ইন্টেলিজেন্স। এখানে প্রবেশ করুন.
- উত্স: https://nanonets.com/blog/langchain/

