এই ব্লগ পোস্টটি Veoneer থেকে ক্যারোলিন চুং-এর সাথে সহ-লিখিত।
Veoneer হল একটি বিশ্বব্যাপী স্বয়ংচালিত ইলেকট্রনিক্স কোম্পানি এবং স্বয়ংচালিত ইলেকট্রনিক নিরাপত্তা ব্যবস্থায় বিশ্বনেতা। তারা সর্বোত্তম-শ্রেণীর সংযম নিয়ন্ত্রণ ব্যবস্থা অফার করে এবং বিশ্বব্যাপী গাড়ি নির্মাতাদের কাছে 1 বিলিয়নেরও বেশি ইলেকট্রনিক কন্ট্রোল ইউনিট এবং ক্র্যাশ সেন্সর সরবরাহ করেছে। কোম্পানিটি স্বয়ংচালিত নিরাপত্তা উন্নয়নের 70 বছরের ইতিহাস তৈরি করে চলেছে, অত্যাধুনিক হার্ডওয়্যার এবং সিস্টেম যা ট্র্যাফিক ঘটনা প্রতিরোধ করে এবং দুর্ঘটনা প্রশমিত করে।
অটোমোটিভ ইন-কেবিন সেন্সিং (ICS) হল একটি উদীয়মান স্থান যা বিভিন্ন ধরনের সেন্সর যেমন ক্যামেরা এবং রাডার এবং কৃত্রিম বুদ্ধিমত্তা (AI) এবং মেশিন লার্নিং (ML) ভিত্তিক অ্যালগরিদম ব্যবহার করে নিরাপত্তা বাড়ানো এবং রাইডিং অভিজ্ঞতা উন্নত করার জন্য। এই ধরনের একটি সিস্টেম নির্মাণ একটি জটিল কাজ হতে পারে। ডেভেলপারদের প্রশিক্ষণ এবং পরীক্ষার উদ্দেশ্যে ম্যানুয়ালি বড় আকারের ইমেজ টীকা করতে হবে। এটি খুবই সময়সাপেক্ষ এবং সম্পদ নিবিড়। এই ধরনের কাজের জন্য টার্নআরাউন্ড সময় কয়েক সপ্তাহ। তদ্ব্যতীত, সংস্থাগুলিকে মানবিক ত্রুটির কারণে অসঙ্গতিপূর্ণ লেবেলের মতো সমস্যাগুলি মোকাবেলা করতে হবে।
AWS আপনার বিকাশের গতি বাড়াতে এবং এমএল-এর মতো উন্নত বিশ্লেষণের মাধ্যমে এই ধরনের সিস্টেম তৈরির জন্য আপনার খরচ কমাতে সাহায্য করার উপর দৃষ্টি নিবদ্ধ করে। আমাদের দৃষ্টিভঙ্গি হল স্বয়ংক্রিয় টীকা করার জন্য ML ব্যবহার করা, নিরাপত্তা মডেলগুলির পুনঃপ্রশিক্ষণ সক্ষম করা এবং সামঞ্জস্যপূর্ণ এবং নির্ভরযোগ্য কর্মক্ষমতা মেট্রিক্স নিশ্চিত করা। এই পোস্টে, আমরা কীভাবে অ্যামাজনের বিশ্বব্যাপী বিশেষজ্ঞ সংস্থার সাথে সহযোগিতার মাধ্যমে শেয়ার করি জেনারেটিভ এআই ইনোভেশন সেন্টার, আমরা ইন-কেবিন ইমেজ হেড বাউন্ডিং বাক্স এবং মূল পয়েন্ট টীকা জন্য একটি সক্রিয় শেখার পাইপলাইন বিকাশ. সমাধানটি 90% এর বেশি খরচ কমায়, টার্নঅ্যারাউন্ড সময়ের পরিপ্রেক্ষিতে টীকা প্রক্রিয়াটিকে কয়েক সপ্তাহ থেকে ঘন্টা পর্যন্ত ত্বরান্বিত করে এবং অনুরূপ ML ডেটা লেবেলিংয়ের কাজগুলির জন্য পুনরায় ব্যবহারযোগ্যতা সক্ষম করে।
সমাধান ওভারভিউ
সক্রিয় শিক্ষা হল একটি এমএল পদ্ধতি যা একটি মডেলকে প্রশিক্ষণের জন্য সর্বাধিক তথ্যপূর্ণ ডেটা নির্বাচন এবং টীকা করার একটি পুনরাবৃত্তিমূলক প্রক্রিয়া জড়িত। লেবেলযুক্ত ডেটার একটি ছোট সেট এবং লেবেলবিহীন ডেটার একটি বড় সেট দেওয়া, সক্রিয় শিক্ষা মডেলের কার্যকারিতা উন্নত করে, লেবেল করার প্রচেষ্টাকে হ্রাস করে এবং শক্তিশালী ফলাফলের জন্য মানুষের দক্ষতাকে একীভূত করে। এই পোস্টে, আমরা AWS পরিষেবাগুলির সাথে ইমেজ টীকাগুলির জন্য একটি সক্রিয় শিক্ষার পাইপলাইন তৈরি করি৷
নিম্নলিখিত চিত্রটি আমাদের সক্রিয় শেখার পাইপলাইনের সামগ্রিক কাঠামো প্রদর্শন করে। লেবেলিং পাইপলাইন একটি থেকে ছবি নেয় আমাজন সিম্পল স্টোরেজ সার্ভিস (Amazon S3) ML মডেল এবং মানুষের দক্ষতার সহযোগিতায় বালতি এবং আউটপুট টীকাযুক্ত ছবি। প্রশিক্ষণ পাইপলাইন ডেটা প্রিপ্রসেস করে এবং এমএল মডেলগুলিকে প্রশিক্ষণের জন্য ব্যবহার করে। প্রাথমিক মডেলটি ম্যানুয়ালি লেবেল করা ডেটার একটি ছোট সেটে সেট আপ এবং প্রশিক্ষিত করা হয়েছে এবং লেবেলিং পাইপলাইনে ব্যবহার করা হবে। লেবেলিং পাইপলাইন এবং প্রশিক্ষণ পাইপলাইন মডেলের কর্মক্ষমতা বাড়ানোর জন্য আরও লেবেলযুক্ত ডেটা দিয়ে ধীরে ধীরে পুনরাবৃত্তি করা যেতে পারে।
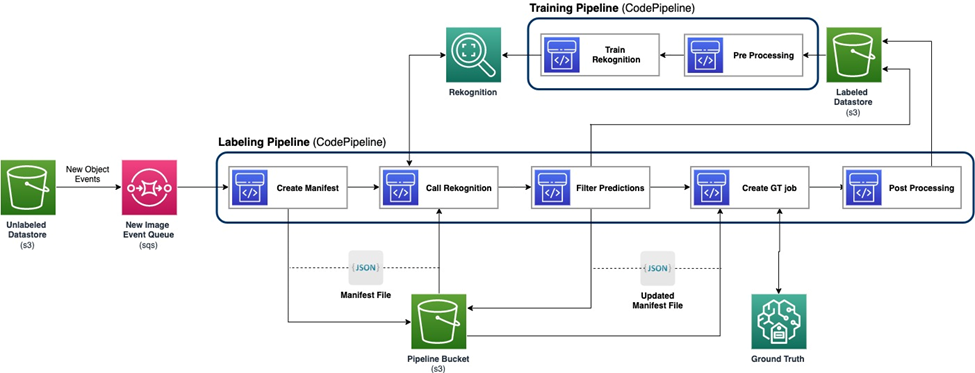
লেবেলিং পাইপলাইনে, একটি Amazon S3 ইভেন্ট বিজ্ঞপ্তি লেবেলবিহীন ডেটাস্টোর S3 বালতিতে যখন একটি নতুন ব্যাচ ইমেজ আসে, তখন লেবেলিং পাইপলাইন সক্রিয় করা হয়। মডেলটি নতুন চিত্রগুলিতে অনুমান ফলাফল তৈরি করে। একটি কাস্টমাইজড জাজমেন্ট ফাংশন ইনফারেন্স কনফিডেন্স স্কোর বা অন্যান্য ব্যবহারকারী-সংজ্ঞায়িত ফাংশনের উপর ভিত্তি করে ডেটার অংশ নির্বাচন করে। এই ডেটা, তার অনুমান ফলাফল সহ, একটি মানব লেবেলিং কাজের জন্য পাঠানো হয়৷ আমাজন সেজমেকার গ্রাউন্ড ট্রুথ পাইপলাইন দ্বারা নির্মিত। মানব লেবেলিং প্রক্রিয়া ডেটা টীকা করতে সাহায্য করে এবং পরিবর্তিত ফলাফলগুলি অবশিষ্ট স্বয়ংক্রিয় টীকাযুক্ত ডেটার সাথে মিলিত হয়, যা পরবর্তীতে প্রশিক্ষণ পাইপলাইন দ্বারা ব্যবহার করা যেতে পারে।
মডেল পুনঃপ্রশিক্ষণ প্রশিক্ষণ পাইপলাইনে ঘটে, যেখানে আমরা মডেল পুনরায় প্রশিক্ষণের জন্য মানব-লেবেলযুক্ত ডেটা ধারণকারী ডেটাসেট ব্যবহার করি। ফাইলগুলি কোথায় সংরক্ষণ করা হয় তা বর্ণনা করার জন্য একটি ম্যানিফেস্ট ফাইল তৈরি করা হয় এবং একই প্রাথমিক মডেল নতুন ডেটাতে পুনরায় প্রশিক্ষণ দেওয়া হয়। পুনঃপ্রশিক্ষণের পরে, নতুন মডেলটি প্রাথমিক মডেলটিকে প্রতিস্থাপন করে, এবং সক্রিয় শেখার পাইপলাইনের পরবর্তী পুনরাবৃত্তি শুরু হয়।
মডেল মোতায়েন
লেবেলিং পাইপলাইন এবং প্রশিক্ষণ পাইপলাইন উভয়ই স্থাপন করা হয় AWS কোড পাইপলাইন. এডাব্লুএস কোডবিল্ড উদাহরণগুলি বাস্তবায়নের জন্য ব্যবহার করা হয়, যা নমনীয় এবং অল্প পরিমাণ ডেটার জন্য দ্রুত। যখন গতির প্রয়োজন হয়, আমরা ব্যবহার করি আমাজন সেজমেকার GPU দৃষ্টান্তের উপর ভিত্তি করে শেষ পয়েন্টগুলি প্রক্রিয়াটিকে সমর্থন এবং ত্বরান্বিত করতে আরও সংস্থান বরাদ্দ করতে।
মডেল পুনঃপ্রশিক্ষণ পাইপলাইন চালু করা যেতে পারে যখন নতুন ডেটাসেট থাকে বা যখন মডেলের কর্মক্ষমতা উন্নতির প্রয়োজন হয়। পুনঃপ্রশিক্ষণ পাইপলাইনের একটি গুরুত্বপূর্ণ কাজ হল প্রশিক্ষণ ডেটা এবং মডেল উভয়ের জন্য সংস্করণ নিয়ন্ত্রণ ব্যবস্থা থাকা। যদিও AWS পরিষেবা যেমন আমাজন রেকোনিশন ইন্টিগ্রেটেড সংস্করণ নিয়ন্ত্রণ বৈশিষ্ট্য আছে, যা পাইপলাইনকে কার্যকর করার জন্য সহজতর করে তোলে, কাস্টমাইজড মডেলের জন্য মেটাডেটা লগিং বা অতিরিক্ত সংস্করণ নিয়ন্ত্রণ সরঞ্জাম প্রয়োজন।
সম্পূর্ণ ওয়ার্কফ্লো ব্যবহার করে বাস্তবায়িত হয় এডাব্লুএস ক্লাউড ডেভেলপমেন্ট কিট (AWS CDK) নিম্নলিখিতগুলি সহ প্রয়োজনীয় AWS উপাদান তৈরি করতে:
- CodePipeline এবং SageMaker কাজের জন্য দুটি ভূমিকা
- দুটি কোড পাইপলাইন কাজ, যা কর্মপ্রবাহকে অর্কেস্ট্রেট করে
- পাইপলাইনের কোড আর্টিফ্যাক্টের জন্য দুটি S3 বালতি
- কাজের ম্যানিফেস্ট, ডেটাসেট এবং মডেল লেবেল করার জন্য একটি S3 বালতি
- প্রিপ্রসেসিং এবং পোস্টপ্রসেসিং এডাব্লুএস ল্যাম্বদা সেজমেকার গ্রাউন্ড ট্রুথ লেবেলিং কাজের জন্য ফাংশন
AWS CDK স্ট্যাকগুলি অত্যন্ত মডুলারাইজড এবং বিভিন্ন কাজে পুনরায় ব্যবহারযোগ্য। প্রশিক্ষণ, অনুমান কোড, এবং সেজমেকার গ্রাউন্ড ট্রুথ টেমপ্লেট যেকোন অনুরূপ সক্রিয় শেখার পরিস্থিতির জন্য প্রতিস্থাপন করা যেতে পারে।
মডেল প্রশিক্ষণ
মডেল প্রশিক্ষণে দুটি কাজ রয়েছে: হেড বাউন্ডিং বক্স টীকা এবং মানব কী পয়েন্ট টীকা। আমরা এই বিভাগে তাদের উভয়ের পরিচয় করিয়ে দিই।
হেড বাউন্ডিং বক্স টীকা
হেড বাউন্ডিং বক্সের টীকা হল একটি ছবিতে মানুষের মাথার বাউন্ডিং বক্সের অবস্থানের পূর্বাভাস দেওয়ার কাজ। আমরা একটি ব্যবহার অ্যামাজন স্বীকৃতি কাস্টম লেবেল হেড বাউন্ডিং বক্স টীকা জন্য মডেল. অনুসরণ নমুনা নোটবুক সেজমেকারের মাধ্যমে একটি স্বীকৃতি কাস্টম লেবেল মডেলকে কীভাবে প্রশিক্ষণ দেওয়া যায় সে সম্পর্কে একটি ধাপে ধাপে টিউটোরিয়াল প্রদান করে।
প্রশিক্ষণ শুরু করার জন্য আমাদের প্রথমে ডেটা প্রস্তুত করতে হবে। আমরা প্রশিক্ষণের জন্য একটি ম্যানিফেস্ট ফাইল এবং পরীক্ষার ডেটাসেটের জন্য একটি ম্যানিফেস্ট ফাইল তৈরি করি। একটি ম্যানিফেস্ট ফাইলে একাধিক আইটেম রয়েছে, যার প্রতিটি একটি ছবির জন্য। নিম্নলিখিতটি ম্যানিফেস্ট ফাইলের একটি উদাহরণ, যেটিতে চিত্রের পথ, আকার এবং টীকা তথ্য অন্তর্ভুক্ত রয়েছে:
ম্যানিফেস্ট ফাইলগুলি ব্যবহার করে, আমরা প্রশিক্ষণ এবং পরীক্ষার জন্য একটি স্বীকৃতি কাস্টম লেবেল মডেলে ডেটাসেট লোড করতে পারি। আমরা বিভিন্ন পরিমাণ প্রশিক্ষণ ডেটা সহ মডেলটিকে পুনরাবৃত্তি করেছি এবং একই 239টি অদেখা ছবিতে এটি পরীক্ষা করেছি। এই পরীক্ষায়, দ mAP_50 স্কোর 0.33 থেকে 114টি ট্রেনিং ইমেজ সহ 0.95টি 957টি ট্রেনিং ইমেজ সহ বেড়েছে। নিম্নলিখিত স্ক্রিনশটটি চূড়ান্ত স্বীকৃতি কাস্টম লেবেল মডেলের কার্যকারিতা মেট্রিক্স দেখায়, যা F1 স্কোর, নির্ভুলতা এবং স্মরণের ক্ষেত্রে দুর্দান্ত পারফরম্যান্স দেয়৷

আমরা আরও 1,128 টি ছবি আছে এমন একটি আটকে রাখা ডেটাসেটে মডেলটি পরীক্ষা করেছি। মডেলটি অবিচ্ছিন্নভাবে অদেখা ডেটাতে সঠিক বাউন্ডিং বক্সের পূর্বাভাস দেয়, উচ্চ ফলন দেয় mAP_50 94.9% এর। নিম্নলিখিত উদাহরণটি একটি হেড বাউন্ডিং বাক্স সহ একটি স্বয়ংক্রিয়-টীকাযুক্ত চিত্র দেখায়৷

মূল পয়েন্ট টীকা
কী পয়েন্ট টীকা চোখ, কান, নাক, মুখ, ঘাড়, কাঁধ, কনুই, কব্জি, নিতম্ব এবং গোড়ালি সহ মূল পয়েন্টগুলির অবস্থান তৈরি করে। অবস্থানের পূর্বাভাস ছাড়াও, এই নির্দিষ্ট কাজটিতে ভবিষ্যদ্বাণী করার জন্য প্রতিটি বিন্দুর দৃশ্যমানতা প্রয়োজন, যার জন্য আমরা একটি অভিনব পদ্ধতি ডিজাইন করি।
মূল পয়েন্ট টীকা জন্য, আমরা একটি ব্যবহার Yolo 8 পোজ মডেল প্রাথমিক মডেল হিসাবে সেজমেকারে। আমরা প্রথমে প্রশিক্ষণের জন্য ডেটা প্রস্তুত করি, যার মধ্যে লেবেল ফাইল তৈরি করা এবং Yolo এর প্রয়োজনীয়তা অনুসরণ করে একটি কনফিগারেশন .yaml ফাইল রয়েছে। ডেটা প্রস্তুত করার পরে, আমরা মডেলটিকে প্রশিক্ষণ দিই এবং মডেলের ওজন ফাইল সহ আর্টিফ্যাক্টগুলি সংরক্ষণ করি। প্রশিক্ষিত মডেল ওজন ফাইলের সাথে, আমরা নতুন ছবি টীকা করতে পারি।
প্রশিক্ষণ পর্যায়ে, দৃশ্যমান পয়েন্ট এবং অক্লুডেড পয়েন্ট সহ অবস্থান সহ লেবেল করা সমস্ত পয়েন্ট প্রশিক্ষণের জন্য ব্যবহার করা হয়। অতএব, এই মডেলটি ডিফল্টরূপে ভবিষ্যদ্বাণীর অবস্থান এবং আস্থা প্রদান করে। নিচের চিত্রে, 0.6-এর কাছাকাছি একটি বৃহৎ আত্মবিশ্বাস থ্রেশহোল্ড (প্রধান থ্রেশহোল্ড) ক্যামেরার ভিউপয়েন্টের বাইরে দৃশ্যমান বা আটকানো পয়েন্টগুলিকে ভাগ করতে সক্ষম। যাইহোক, আবদ্ধ বিন্দু এবং দৃশ্যমান বিন্দু আত্মবিশ্বাস দ্বারা পৃথক করা হয় না, যার মানে ভবিষ্যদ্বাণী করা আত্মবিশ্বাস দৃশ্যমানতার পূর্বাভাস দেওয়ার জন্য উপযোগী নয়।

দৃশ্যমানতার পূর্বাভাস পেতে, আমরা শুধুমাত্র দৃশ্যমান পয়েন্ট ধারণ করে ডেটাসেটে প্রশিক্ষিত একটি অতিরিক্ত মডেল প্রবর্তন করি, ক্যামেরার ভিউপয়েন্ট এবং ক্যামেরার ভিউপয়েন্টের বাইরে উভয়ই বাদ দিয়ে। নিম্নলিখিত চিত্রটি বিভিন্ন দৃশ্যমানতার সাথে পয়েন্টের বন্টন দেখায়। দৃশ্যমান পয়েন্ট এবং অন্যান্য পয়েন্ট অতিরিক্ত মডেলে আলাদা করা যেতে পারে। আমরা দৃশ্যমান পয়েন্ট পেতে 0.6 এর কাছাকাছি একটি থ্রেশহোল্ড (অতিরিক্ত থ্রেশহোল্ড) ব্যবহার করতে পারি। এই দুটি মডেলকে একত্রিত করে, আমরা অবস্থান এবং দৃশ্যমানতার পূর্বাভাস দেওয়ার জন্য একটি পদ্ধতি ডিজাইন করি।

একটি মূল পয়েন্ট প্রথমে মূল মডেল দ্বারা অবস্থান এবং প্রধান আত্মবিশ্বাসের সাথে ভবিষ্যদ্বাণী করা হয়, তারপর আমরা অতিরিক্ত মডেল থেকে অতিরিক্ত আত্মবিশ্বাসের পূর্বাভাস পাই। এর দৃশ্যমানতা নিম্নলিখিত হিসাবে শ্রেণীবদ্ধ করা হয়:
- দৃশ্যমান, যদি এর প্রধান আত্মবিশ্বাস তার মূল থ্রেশহোল্ডের চেয়ে বেশি হয় এবং এর অতিরিক্ত আত্মবিশ্বাস অতিরিক্ত থ্রেশহোল্ডের চেয়ে বেশি হয়
- আবদ্ধ, যদি এর প্রধান আত্মবিশ্বাস তার মূল থ্রেশহোল্ডের চেয়ে বেশি হয় এবং এর অতিরিক্ত আত্মবিশ্বাস অতিরিক্ত থ্রেশহোল্ডের চেয়ে কম বা সমান হয়
- ক্যামেরার পর্যালোচনার বাইরে, অন্যথায়
মূল পয়েন্ট টীকাগুলির একটি উদাহরণ নিম্নলিখিত চিত্রটিতে প্রদর্শিত হয়েছে, যেখানে কঠিন চিহ্নগুলি দৃশ্যমান বিন্দু এবং ফাঁপা চিহ্নগুলি আবদ্ধ বিন্দু। এর বাইরে ক্যামেরার রিভিউ পয়েন্ট দেখানো হয় না।

স্ট্যান্ডার্ডের উপর ভিত্তি করে OKS MS-COCO ডেটাসেটের সংজ্ঞা, আমাদের পদ্ধতি অদেখা পরীক্ষার ডেটাসেটে 50% এর mAP_98.4 অর্জন করতে সক্ষম। দৃশ্যমানতার পরিপ্রেক্ষিতে, পদ্ধতিটি একই ডেটাসেটে 79.2% শ্রেণীবিভাগ নির্ভুলতা প্রদান করে।
মানুষের লেবেলিং এবং পুনরায় প্রশিক্ষণ
যদিও মডেলগুলি পরীক্ষার ডেটাতে দুর্দান্ত পারফরম্যান্স অর্জন করে, তবুও নতুন বাস্তব-বিশ্বের ডেটাতে ভুল করার সম্ভাবনা রয়েছে। হিউম্যান লেবেলিং হল পুনঃপ্রশিক্ষণ ব্যবহার করে মডেল কর্মক্ষমতা বাড়ানোর জন্য এই ভুলগুলি সংশোধন করার প্রক্রিয়া। আমরা একটি বিচার ফাংশন ডিজাইন করেছি যা সমস্ত হেড বাউন্ডিং বাক্স বা মূল পয়েন্টগুলির আউটপুটের জন্য ML মডেলগুলি থেকে আউটপুট যে আত্মবিশ্বাসের মানকে একত্রিত করে। আমরা এই ভুলগুলি এবং ফলস্বরূপ খারাপ লেবেলযুক্ত ছবিগুলি সনাক্ত করতে চূড়ান্ত স্কোর ব্যবহার করি, যা মানব লেবেলিং প্রক্রিয়াতে পাঠানো প্রয়োজন।
খারাপ লেবেলযুক্ত ছবিগুলি ছাড়াও, ছবির একটি ছোট অংশ এলোমেলোভাবে মানুষের লেবেলিংয়ের জন্য বেছে নেওয়া হয়। এই মানব-লেবেলযুক্ত চিত্রগুলি পুনরায় প্রশিক্ষণের জন্য প্রশিক্ষণ সেটের বর্তমান সংস্করণে যোগ করা হয়েছে, মডেলের কার্যকারিতা উন্নত করা এবং সামগ্রিক টীকা নির্ভুলতা।
বাস্তবায়নে, আমরা এর জন্য সেজমেকার গ্রাউন্ড ট্রুথ ব্যবহার করি মানুষের লেবেলিং প্রক্রিয়া সেজমেকার গ্রাউন্ড ট্রুথ ডেটা লেবেলিংয়ের জন্য একটি ব্যবহারকারী-বান্ধব এবং স্বজ্ঞাত UI প্রদান করে। নিম্নলিখিত স্ক্রিনশটটি হেড বাউন্ডিং বক্স টীকাটির জন্য একটি সেজমেকার গ্রাউন্ড ট্রুথ লেবেলিং কাজ প্রদর্শন করে৷
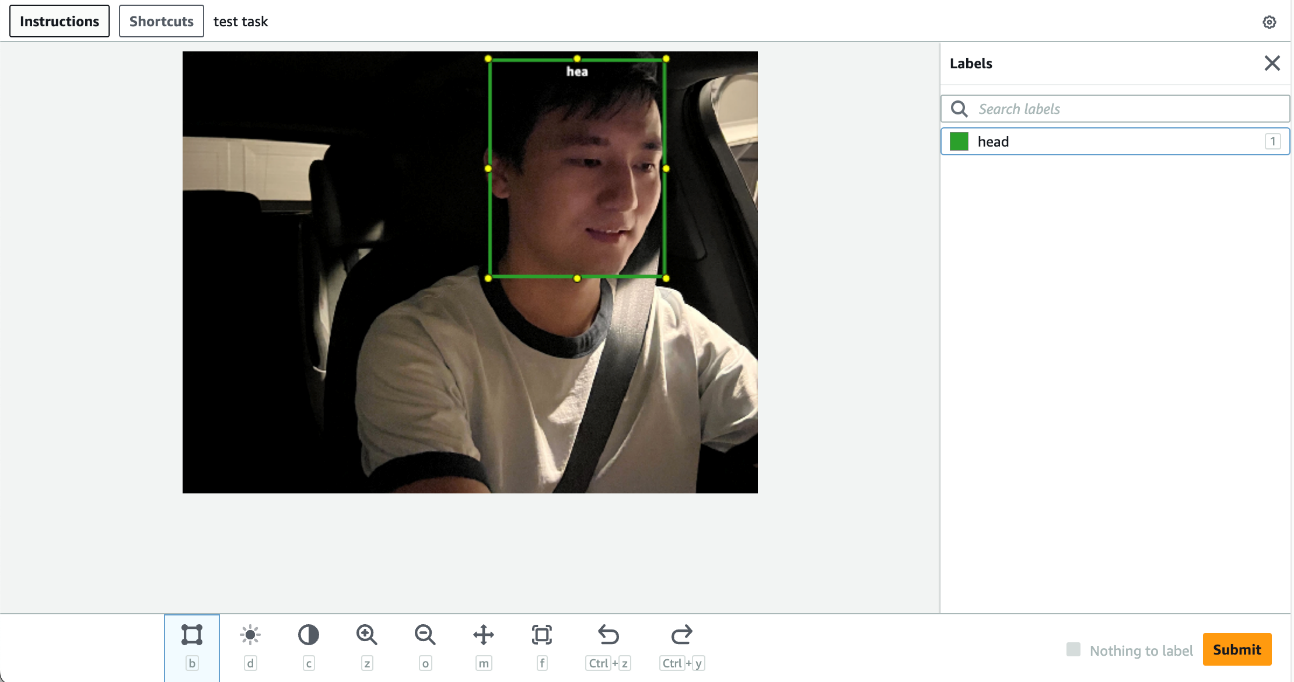
নিম্নলিখিত স্ক্রিনশটটি মূল পয়েন্ট টীকাটির জন্য একটি সেজমেকার গ্রাউন্ড ট্রুথ লেবেলিং কাজ প্রদর্শন করে।

খরচ, গতি এবং পুনরায় ব্যবহারযোগ্যতা
নিম্নোক্ত সারণীতে দেখানো হয়েছে মানুষের লেবেলিংয়ের তুলনায় আমাদের সমাধান ব্যবহার করার মূল সুবিধা হল খরচ এবং গতি। আমরা খরচ সঞ্চয় এবং গতি ত্বরণ প্রতিনিধিত্ব করতে এই টেবিল ব্যবহার. অ্যাক্সিলারেটেড GPU SageMaker ইন্সট্যান্স ml.g4dn.xlarge ব্যবহার করে, 100,000 ইমেজের পুরো জীবনের প্রশিক্ষণ এবং অনুমান খরচ মানুষের লেবেলিংয়ের খরচের চেয়ে 99% কম, যখন গতি মানুষের লেবেলিংয়ের চেয়ে 10-10,000 গুণ বেশি, নির্ভর করে টাস্ক
প্রথম সারণী খরচ কর্মক্ষমতা মেট্রিক্স সারসংক্ষেপ.
| মডেল | mAP_50 1,128টি পরীক্ষার চিত্রের উপর ভিত্তি করে | 100,000 ছবির উপর ভিত্তি করে প্রশিক্ষণ খরচ | 100,000 ছবির উপর ভিত্তি করে অনুমান খরচ | মানুষের টীকা তুলনায় খরচ হ্রাস | 100,000 ছবির উপর ভিত্তি করে অনুমান সময় | মানুষের টীকা তুলনায় সময়ের ত্বরণ |
| স্বীকৃতি মাথা আবদ্ধ বাক্স | 0.949 | $4 | $22 | 99 কম% | 5.5 ঘন্টা | দিন |
| Yolo মূল পয়েন্ট | 0.984 | $27.20 | * $10 | 99.9 কম% | মিনিট | সপ্তাহ |
নিম্নলিখিত সারণী কর্মক্ষমতা মেট্রিক্স সারসংক্ষেপ.
| টীকা টাস্ক | mAP_50 (%) | প্রশিক্ষণ খরচ ($) | অনুমান খরচ ($) | অনুমান সময় |
| হেড বাউন্ডিং বক্স | 94.9 | 4 | 22 | 5.5 ঘণ্টা |
| গুরুত্বপূর্ণ দিক | 98.4 | 27 | 10 | 5 মিনিট |
অধিকন্তু, আমাদের সমাধান অনুরূপ কাজের জন্য পুনরায় ব্যবহারযোগ্যতা প্রদান করে। অন্যান্য সিস্টেমের জন্য ক্যামেরা উপলব্ধি উন্নয়ন যেমন উন্নত ড্রাইভার সহায়তা সিস্টেম (ADAS) এবং ইন-কেবিন সিস্টেমগুলিও আমাদের সমাধান গ্রহণ করতে পারে।
সারাংশ
এই পোস্টে, আমরা AWS পরিষেবাগুলি ব্যবহার করে ইন-কেবিন ইমেজগুলির স্বয়ংক্রিয় টীকাগুলির জন্য একটি সক্রিয় শেখার পাইপলাইন কীভাবে তৈরি করা যায় তা দেখিয়েছি। আমরা ML-এর শক্তি প্রদর্শন করি, যা আপনাকে টীকা প্রক্রিয়াটিকে স্বয়ংক্রিয় এবং ত্বরান্বিত করতে সক্ষম করে এবং ফ্রেমওয়ার্কের নমনীয়তা যা AWS পরিষেবা দ্বারা সমর্থিত বা SageMaker-এ কাস্টমাইজ করা মডেলগুলি ব্যবহার করে। Amazon S3, SageMaker, Lambda, এবং SageMaker Ground Truth-এর সাহায্যে, আপনি ডেটা স্টোরেজ, টীকা, প্রশিক্ষণ এবং স্থাপনাকে স্ট্রীমলাইন করতে পারেন এবং খরচগুলি উল্লেখযোগ্যভাবে কমিয়ে পুনরায় ব্যবহারযোগ্যতা অর্জন করতে পারেন৷ এই সমাধানটি বাস্তবায়ন করে, স্বয়ংচালিত কোম্পানিগুলি এমএল-ভিত্তিক উন্নত বিশ্লেষণ যেমন স্বয়ংক্রিয় চিত্র টীকা ব্যবহার করে আরও চটপটে এবং সাশ্রয়ী হতে পারে।
আজই শুরু করুন এবং এর পাওয়ার আনলক করুন AWS পরিষেবা এবং আপনার অটোমোটিভ ইন-কেবিন সেন্সিং ব্যবহারের ক্ষেত্রে মেশিন লার্নিং!
লেখক সম্পর্কে
 ইয়াংজিয়াং ইউ অ্যামাজন জেনারেটিভ এআই ইনোভেশন সেন্টারের একজন ফলিত বিজ্ঞানী। শিল্প অ্যাপ্লিকেশনের জন্য AI এবং মেশিন লার্নিং সলিউশন তৈরি করার 9 বছরেরও বেশি অভিজ্ঞতার সাথে, তিনি জেনারেটিভ AI, কম্পিউটার ভিশন এবং টাইম সিরিজ মডেলিংয়ে বিশেষজ্ঞ।
ইয়াংজিয়াং ইউ অ্যামাজন জেনারেটিভ এআই ইনোভেশন সেন্টারের একজন ফলিত বিজ্ঞানী। শিল্প অ্যাপ্লিকেশনের জন্য AI এবং মেশিন লার্নিং সলিউশন তৈরি করার 9 বছরেরও বেশি অভিজ্ঞতার সাথে, তিনি জেনারেটিভ AI, কম্পিউটার ভিশন এবং টাইম সিরিজ মডেলিংয়ে বিশেষজ্ঞ।
 তিয়ানি মাও শিকাগো এলাকার বাইরে অবস্থিত AWS-এর একজন ফলিত বিজ্ঞানী। মেশিন লার্নিং এবং ডিপ লার্নিং সলিউশন তৈরিতে তার 5+ বছরের অভিজ্ঞতা রয়েছে এবং তিনি মানুষের ফিডব্যাক সহ কম্পিউটার ভিশন এবং রিইনফোর্সমেন্ট লার্নিং এর উপর ফোকাস করেন। তিনি গ্রাহকদের সাথে কাজ করে তাদের চ্যালেঞ্জগুলি বুঝতে এবং AWS পরিষেবাগুলি ব্যবহার করে উদ্ভাবনী সমাধান তৈরি করে তাদের সমাধান করতে উপভোগ করেন।
তিয়ানি মাও শিকাগো এলাকার বাইরে অবস্থিত AWS-এর একজন ফলিত বিজ্ঞানী। মেশিন লার্নিং এবং ডিপ লার্নিং সলিউশন তৈরিতে তার 5+ বছরের অভিজ্ঞতা রয়েছে এবং তিনি মানুষের ফিডব্যাক সহ কম্পিউটার ভিশন এবং রিইনফোর্সমেন্ট লার্নিং এর উপর ফোকাস করেন। তিনি গ্রাহকদের সাথে কাজ করে তাদের চ্যালেঞ্জগুলি বুঝতে এবং AWS পরিষেবাগুলি ব্যবহার করে উদ্ভাবনী সমাধান তৈরি করে তাদের সমাধান করতে উপভোগ করেন।
 ইয়ানরু জিয়াও অ্যামাজন জেনারেটিভ এআই ইনোভেশন সেন্টারের একজন ফলিত বিজ্ঞানী, যেখানে তিনি গ্রাহকদের বাস্তব-বিশ্বের ব্যবসায়িক সমস্যার জন্য এআই/এমএল সমাধান তৈরি করেন। তিনি উত্পাদন, শক্তি এবং কৃষি সহ বিভিন্ন ক্ষেত্রে কাজ করেছেন। ইয়ানরু তার পিএইচ.ডি. ওল্ড ডোমিনিয়ন ইউনিভার্সিটি থেকে কম্পিউটার সায়েন্সে।
ইয়ানরু জিয়াও অ্যামাজন জেনারেটিভ এআই ইনোভেশন সেন্টারের একজন ফলিত বিজ্ঞানী, যেখানে তিনি গ্রাহকদের বাস্তব-বিশ্বের ব্যবসায়িক সমস্যার জন্য এআই/এমএল সমাধান তৈরি করেন। তিনি উত্পাদন, শক্তি এবং কৃষি সহ বিভিন্ন ক্ষেত্রে কাজ করেছেন। ইয়ানরু তার পিএইচ.ডি. ওল্ড ডোমিনিয়ন ইউনিভার্সিটি থেকে কম্পিউটার সায়েন্সে।
 পল জর্জ স্বয়ংচালিত প্রযুক্তিতে 15 বছরের বেশি অভিজ্ঞতা সহ একজন দক্ষ পণ্য নেতা। তিনি নেতৃস্থানীয় পণ্য ব্যবস্থাপনা, কৌশল, গো-টু-মার্কেট এবং সিস্টেম ইঞ্জিনিয়ারিং দলগুলিতে পারদর্শী। তিনি বিশ্বব্যাপী বেশ কয়েকটি নতুন সংবেদনশীল এবং উপলব্ধি পণ্য উন্মোচন করেছেন এবং চালু করেছেন। AWS-এ, তিনি স্বায়ত্তশাসিত যানবাহনের কাজের চাপের জন্য কৌশল এবং বাজারে যেতে নেতৃত্ব দিচ্ছেন।
পল জর্জ স্বয়ংচালিত প্রযুক্তিতে 15 বছরের বেশি অভিজ্ঞতা সহ একজন দক্ষ পণ্য নেতা। তিনি নেতৃস্থানীয় পণ্য ব্যবস্থাপনা, কৌশল, গো-টু-মার্কেট এবং সিস্টেম ইঞ্জিনিয়ারিং দলগুলিতে পারদর্শী। তিনি বিশ্বব্যাপী বেশ কয়েকটি নতুন সংবেদনশীল এবং উপলব্ধি পণ্য উন্মোচন করেছেন এবং চালু করেছেন। AWS-এ, তিনি স্বায়ত্তশাসিত যানবাহনের কাজের চাপের জন্য কৌশল এবং বাজারে যেতে নেতৃত্ব দিচ্ছেন।
 ক্যারোলিন চুং তিনি ভিওনির (ম্যাগনা ইন্টারন্যাশনাল দ্বারা অর্জিত) এর একজন প্রকৌশল ব্যবস্থাপক, তার সেন্সিং এবং উপলব্ধি সিস্টেম বিকাশের 14 বছরের বেশি অভিজ্ঞতা রয়েছে। তিনি বর্তমানে ম্যাগনা ইন্টারন্যাশনালের অভ্যন্তরীণ সেন্সিং প্রাক-উন্নয়ন প্রোগ্রামের নেতৃত্ব দিচ্ছেন যা কম্পিউট ভিশন ইঞ্জিনিয়ার এবং ডেটা বিজ্ঞানীদের একটি দল পরিচালনা করে।
ক্যারোলিন চুং তিনি ভিওনির (ম্যাগনা ইন্টারন্যাশনাল দ্বারা অর্জিত) এর একজন প্রকৌশল ব্যবস্থাপক, তার সেন্সিং এবং উপলব্ধি সিস্টেম বিকাশের 14 বছরের বেশি অভিজ্ঞতা রয়েছে। তিনি বর্তমানে ম্যাগনা ইন্টারন্যাশনালের অভ্যন্তরীণ সেন্সিং প্রাক-উন্নয়ন প্রোগ্রামের নেতৃত্ব দিচ্ছেন যা কম্পিউট ভিশন ইঞ্জিনিয়ার এবং ডেটা বিজ্ঞানীদের একটি দল পরিচালনা করে।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- PlatoData.Network উল্লম্ব জেনারেটিভ Ai. নিজেকে ক্ষমতায়িত করুন। এখানে প্রবেশ করুন.
- প্লেটোএআইস্ট্রিম। Web3 ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- প্লেটোইএসজি। কার্বন, ক্লিনটেক, শক্তি, পরিবেশ সৌর, বর্জ্য ব্যবস্থাপনা. এখানে প্রবেশ করুন.
- প্লেটো হেলথ। বায়োটেক এবং ক্লিনিক্যাল ট্রায়াল ইন্টেলিজেন্স। এখানে প্রবেশ করুন.
- উত্স: https://aws.amazon.com/blogs/machine-learning/build-an-active-learning-pipeline-for-automatic-annotation-of-images-with-aws-services/

