এমএল মডেলগুলির বিকাশ, স্থাপনা এবং পরিচালনাকে স্ট্রিমলাইন করার জন্য স্কেলযোগ্য এবং দক্ষ মেশিন লার্নিং (এমএল) পাইপলাইন তৈরি করা অত্যন্ত গুরুত্বপূর্ণ। এই পোস্টে, আমরা একটি নির্দেশিত অ্যাসাইক্লিক গ্রাফ (DAG) তৈরির স্বয়ংক্রিয়তার জন্য একটি কাঠামো উপস্থাপন করছি অ্যামাজন সেজমেকার পাইপলাইন সাধারণ কনফিগারেশন ফাইলের উপর ভিত্তি করে। দ্য ফ্রেমওয়ার্ক কোড এবং উদাহরণ এখানে উপস্থাপিত শুধুমাত্র মডেল প্রশিক্ষণ পাইপলাইন কভার, কিন্তু সহজে ব্যাচ অনুমান পাইপলাইন পাশাপাশি প্রসারিত করা যেতে পারে.
এই ডাইনামিক ফ্রেমওয়ার্ক ব্যবহারকারী-সংজ্ঞায়িত পাইথন স্ক্রিপ্ট, অবকাঠামোগত চাহিদা (সহ আমাজন ভার্চুয়াল প্রাইভেট ক্লাউড (Amazon VPC) সাবনেট এবং নিরাপত্তা গ্রুপ, এডাব্লুএস আইডেন্টিটি এবং অ্যাক্সেস ম্যানেজমেন্ট (আইএএম) ভূমিকা, AWS কী ব্যবস্থাপনা পরিষেবা (AWS KMS) কী, কন্টেইনার রেজিস্ট্রি, এবং উদাহরণের ধরন), ইনপুট এবং আউটপুট আমাজন সিম্পল স্টোরেজ সার্ভিস (Amazon S3) পাথ, এবং রিসোর্স ট্যাগ। কনফিগারেশন ফাইল (YAML এবং JSON) ML অনুশীলনকারীদের ঘোষণামূলক সিনট্যাক্স ব্যবহার করে প্রশিক্ষণ পাইপলাইন অর্কেস্ট্রেট করার জন্য আলাদা কোড নির্দিষ্ট করার অনুমতি দেয়। এটি ডেটা বিজ্ঞানীদের দ্রুত ML মডেলগুলি তৈরি করতে এবং পুনরাবৃত্তি করতে সক্ষম করে এবং ML ইঞ্জিনিয়ারদের অবিচ্ছিন্ন একীকরণ এবং অবিচ্ছিন্ন ডেলিভারি (CI/CD) ML পাইপলাইনের মাধ্যমে দ্রুত চালানোর ক্ষমতা দেয়, মডেলগুলির উত্পাদনের সময় কমিয়ে দেয়৷
সমাধান ওভারভিউ
প্রস্তাবিত ফ্রেমওয়ার্ক কোড কনফিগারেশন ফাইল পড়ার মাধ্যমে শুরু হয়। এটি তারপরে কনফিগারেশন ফাইলগুলিতে ঘোষিত পদক্ষেপগুলি এবং ধাপগুলির মধ্যে মিথস্ক্রিয়া এবং নির্ভরতার উপর ভিত্তি করে গতিশীলভাবে একটি সেজমেকার পাইপলাইন ডিএজি তৈরি করে। এই অর্কেস্ট্রেশন ফ্রেমওয়ার্ক একক-মডেল এবং মাল্টি-মডেল ব্যবহারের ক্ষেত্রে উভয়ই পূরণ করে এবং ডেটা এবং প্রক্রিয়াগুলির একটি মসৃণ প্রবাহ প্রদান করে। এই সমাধানের মূল সুবিধাগুলি নিম্নরূপ:
- স্বয়ংক্রিয়তা - সম্পূর্ণ এমএল ওয়ার্কফ্লো, ডেটা প্রিপ্রসেসিং থেকে মডেল রেজিস্ট্রি পর্যন্ত, কোনও ম্যানুয়াল হস্তক্ষেপ ছাড়াই সাজানো হয়েছে৷ এটি মডেল পরীক্ষা এবং পরিচালনার জন্য প্রয়োজনীয় সময় এবং প্রচেষ্টাকে হ্রাস করে।
- reproducibility - একটি পূর্বনির্ধারিত কনফিগারেশন ফাইলের সাথে, ডেটা বিজ্ঞানী এবং এমএল ইঞ্জিনিয়াররা একাধিক রান এবং পরিবেশ জুড়ে সামঞ্জস্যপূর্ণ ফলাফল অর্জন করে সমগ্র কর্মপ্রবাহ পুনরুত্পাদন করতে পারে।
- স্কেলেবিলিটি - আমাজন সেজমেকার পাইপলাইন জুড়ে ব্যবহৃত হয়, এমএল অনুশীলনকারীদের বড় ডেটাসেট প্রক্রিয়া করতে এবং অবকাঠামোগত উদ্বেগ ছাড়াই জটিল মডেলগুলিকে প্রশিক্ষণ দিতে সক্ষম করে।
- নমনীয়তা – ফ্রেমওয়ার্কটি নমনীয় এবং ML ব্যবহারের ক্ষেত্রে বিস্তৃত পরিসর, ML ফ্রেমওয়ার্ক (যেমন XGBoost এবং TensorFlow), মাল্টি-মডেল ট্রেনিং এবং বহু-পদক্ষেপ প্রশিক্ষণের ব্যবস্থা করতে পারে। প্রশিক্ষণ DAG এর প্রতিটি ধাপ কনফিগারেশন ফাইলের মাধ্যমে কাস্টমাইজ করা যেতে পারে।
- মডেল শাসন - দ্য আমাজন সেজমেকার মডেল রেজিস্ট্রি ইন্টিগ্রেশন মডেল সংস্করণ ট্র্যাক করার অনুমতি দেয়, এবং সেইজন্য তাদের আত্মবিশ্বাসের সাথে উৎপাদনে উন্নীত করে।
নিম্নলিখিত স্থাপত্য চিত্রটি চিত্রিত করে যে আপনি এমএল মডেলগুলির পরীক্ষা এবং পরিচালনা উভয়ের সময় প্রস্তাবিত কাঠামোটি কীভাবে ব্যবহার করতে পারেন। পরীক্ষার সময়, আপনি এই পোস্টে প্রদত্ত ফ্রেমওয়ার্ক কোড সংগ্রহস্থল এবং আপনার প্রকল্প-নির্দিষ্ট উত্স কোড সংগ্রহস্থলগুলি ক্লোন করতে পারেন অ্যামাজন সেজমেকার স্টুডিও, এবং আপনার ভার্চুয়াল পরিবেশ সেট করুন (বিস্তারিত পরে এই পোস্টে)। তারপরে আপনি প্রিপ্রসেসিং, প্রশিক্ষণ এবং মূল্যায়ন স্ক্রিপ্টগুলির পাশাপাশি কনফিগারেশন পছন্দগুলির উপর পুনরাবৃত্তি করতে পারেন। একটি সেজমেকার পাইপলাইন প্রশিক্ষণ DAG তৈরি এবং চালানোর জন্য, আপনি ফ্রেমওয়ার্কের এন্ট্রি পয়েন্টে কল করতে পারেন, যা সমস্ত কনফিগারেশন ফাইল পড়বে, প্রয়োজনীয় পদক্ষেপগুলি তৈরি করবে এবং নির্দিষ্ট ধাপের ক্রম এবং নির্ভরতার উপর ভিত্তি করে সেগুলিকে অর্কেস্ট্রেট করবে৷
অপারেশনালাইজেশনের সময়, CI পাইপলাইন ফ্রেমওয়ার্ক কোড রিপোজিটরি এবং প্রজেক্ট-নির্দিষ্ট ট্রেনিং রিপোজিটরিকে ক্লোন করে এডাব্লুএস কোডবিল্ড job, যেখানে ফ্রেমওয়ার্কের এন্ট্রি পয়েন্ট স্ক্রিপ্টকে সেজমেকার পাইপলাইন প্রশিক্ষণ DAG তৈরি বা আপডেট করতে বলা হয় এবং তারপরে এটি চালান।

সংগ্রহস্থল কাঠামো
সার্জারির GitHub সংগ্রহস্থল নিম্নলিখিত ডিরেক্টরি এবং ফাইল রয়েছে:
- /framework/conf/ – এই ডিরেক্টরিতে একটি কনফিগারেশন ফাইল রয়েছে যা রানটাইমে সাবনেট, নিরাপত্তা গোষ্ঠী এবং IAM ভূমিকার মতো সমস্ত মডেলিং ইউনিট জুড়ে সাধারণ ভেরিয়েবল সেট করতে ব্যবহৃত হয়। একটি মডেলিং ইউনিট হল একটি এমএল মডেল প্রশিক্ষণের জন্য ছয়টি ধাপ পর্যন্ত একটি ক্রম।
- /ফ্রেমওয়ার্ক/createmodel/ – এই ডিরেক্টরিতে একটি পাইথন স্ক্রিপ্ট রয়েছে যা একটি তৈরি করে সেজমেকার মডেল একটি থেকে মডেল নিদর্শন উপর ভিত্তি করে বস্তু সেজমেকার পাইপলাইন প্রশিক্ষণ পদক্ষেপ. মডেল অবজেক্ট পরে ব্যবহৃত হয় a সেজমেকার ব্যাচের রূপান্তর একটি পরীক্ষা সেটে মডেল কর্মক্ষমতা মূল্যায়নের জন্য কাজ।
- /ফ্রেমওয়ার্ক/মডেলমেট্রিক্স/ – এই ডিরেক্টরিতে একটি পাইথন স্ক্রিপ্ট রয়েছে যা একটি তৈরি করে আমাজন সেজমেকার প্রসেসিং একটি SageMaker ব্যাচ ট্রান্সফর্ম কাজের ফলাফলের উপর ভিত্তি করে একটি প্রশিক্ষিত মডেলের জন্য একটি মডেল মেট্রিক্স জেএসওএন রিপোর্ট তৈরি করার কাজ।
- /ফ্রেমওয়ার্ক/পাইপলাইন/ – এই ডিরেক্টরিতে পাইথন স্ক্রিপ্ট রয়েছে যা নির্দিষ্ট কনফিগারেশনের উপর ভিত্তি করে একটি SageMaker Pipelines DAG তৈরি বা আপডেট করতে অন্যান্য ফ্রেমওয়ার্ক ডিরেক্টরিতে সংজ্ঞায়িত পাইথন ক্লাস ব্যবহার করে। model_unit.py স্ক্রিপ্টটি pipeline_service.py দ্বারা এক বা একাধিক মডেলিং ইউনিট তৈরি করতে ব্যবহার করা হয়। প্রতিটি মডেলিং ইউনিট হল একটি এমএল মডেল প্রশিক্ষণের জন্য ছয়টি ধাপ পর্যন্ত একটি ক্রম: প্রক্রিয়া, প্রশিক্ষণ, মডেল তৈরি, রূপান্তর, মেট্রিক্স এবং রেজিস্টার মডেল। প্রতিটি মডেলিং ইউনিটের জন্য কনফিগারেশন মডেলের সংশ্লিষ্ট সংগ্রহস্থলে নির্দিষ্ট করা উচিত। pipeline_service.py এছাড়াও সেজমেকার পাইপলাইন বিভাগের উপর ভিত্তি করে SageMaker পাইপলাইন পদক্ষেপগুলির মধ্যে নির্ভরতা সেট করে (কীভাবে মডেলিং ইউনিটের মধ্যে এবং জুড়ে ধাপগুলি ক্রমানুসারে বা চেইন করা হয়), যা মডেল সংগ্রহস্থলগুলির একটির কনফিগারেশন ফাইলে (অ্যাঙ্কর মডেল) সংজ্ঞায়িত করা উচিত। এটি আপনাকে সেজমেকার পাইপলাইন দ্বারা অনুমানকৃত ডিফল্ট নির্ভরতা ওভাররাইড করতে দেয়। আমরা এই পোস্টে পরে কনফিগারেশন ফাইলের কাঠামো নিয়ে আলোচনা করব।
- /ফ্রেমওয়ার্ক/প্রসেসিং/ - এই ডিরেক্টরিটিতে একটি পাইথন স্ক্রিপ্ট রয়েছে যা নির্দিষ্ট ডকার ইমেজ এবং এন্ট্রি পয়েন্ট স্ক্রিপ্টের উপর ভিত্তি করে একটি সেজমেকার প্রসেসিং কাজ তৈরি করে।
- /ফ্রেমওয়ার্ক/রেজিস্টারমডেল/ – এই ডিরেক্টরিতে সেজমেকার মডেল রেজিস্ট্রিতে গণনা করা মেট্রিক্স সহ একটি প্রশিক্ষিত মডেল নিবন্ধনের জন্য একটি পাইথন স্ক্রিপ্ট রয়েছে।
- /ফ্রেমওয়ার্ক/প্রশিক্ষণ/ – এই ডিরেক্টরিতে একটি পাইথন স্ক্রিপ্ট রয়েছে যা একটি সেজমেকার প্রশিক্ষণের কাজ তৈরি করে।
- /ফ্রেমওয়ার্ক/ট্রান্সফর্ম/ – এই ডিরেক্টরিতে একটি পাইথন স্ক্রিপ্ট রয়েছে যা সেজমেকার ব্যাচ ট্রান্সফর্ম কাজ তৈরি করে। মডেল প্রশিক্ষণের পরিপ্রেক্ষিতে, এটি পরীক্ষার ডেটাতে প্রশিক্ষিত মডেলের কর্মক্ষমতা মেট্রিক গণনা করতে ব্যবহৃত হয়।
- /ফ্রেমওয়ার্ক/ইউটিলিটিস/ – এই ডিরেক্টরিতে কনফিগারেশন ফাইল পড়ার এবং যোগদানের পাশাপাশি লগিং করার জন্য ইউটিলিটি স্ক্রিপ্ট রয়েছে।
- /framework_entrypoint.py - এই ফাইলটি ফ্রেমওয়ার্ক কোডের এন্ট্রি পয়েন্ট। এটি একটি SageMaker Pipelines DAG তৈরি বা আপডেট করতে /framework/pipeline/ ডিরেক্টরিতে সংজ্ঞায়িত একটি ফাংশনকে কল করে এবং এটি চালায়।
- /উদাহরণ – এই ডিরেক্টরিতে আপনি কীভাবে এই অটোমেশন ফ্রেমওয়ার্কটি ব্যবহার করে সহজ এবং জটিল প্রশিক্ষণ DAG তৈরি করতে পারেন তার বেশ কয়েকটি উদাহরণ রয়েছে।
- /env.env – এই ফাইলটি আপনাকে সাধারণ ভেরিয়েবল যেমন সাবনেট, সিকিউরিটি গ্রুপ এবং পরিবেশ ভেরিয়েবল হিসাবে IAM ভূমিকা সেট করতে দেয়।
- /requirements.txt - এই ফাইলটি পাইথন লাইব্রেরিগুলি নির্দিষ্ট করে যা ফ্রেমওয়ার্ক কোডের জন্য প্রয়োজনীয়।
পূর্বশর্ত
এই সমাধানটি স্থাপন করার আগে আপনার নিম্নলিখিত পূর্বশর্ত থাকা উচিত:
- একটি AWS অ্যাকাউন্ট
- সেজমেকার স্টুডিও
- Amazon S3 রিড/রাইট এবং AWS KMS এনক্রিপ্ট/ডিক্রিপ্ট অনুমতি সহ একটি SageMaker ভূমিকা
- ডেটা, স্ক্রিপ্ট এবং মডেল আর্টিফ্যাক্ট সংরক্ষণের জন্য একটি S3 বালতি
- ঐচ্ছিকভাবে, এডাব্লুএস কমান্ড লাইন ইন্টারফেস (AWS CLI)
- Python3 (Python 3.7 বা তার বেশি) এবং নিম্নলিখিত Python প্যাকেজগুলি:
- boto3
- ঋষি নির্মাতা
- PYAML
- আপনার কাস্টম স্ক্রিপ্টে ব্যবহৃত অতিরিক্ত পাইথন প্যাকেজ
সমাধান স্থাপন করুন
সমাধান স্থাপন করতে নিম্নলিখিত পদক্ষেপগুলি সম্পূর্ণ করুন:
- নিম্নলিখিত কাঠামো অনুযায়ী আপনার মডেল প্রশিক্ষণ সংগ্রহস্থল সংগঠিত করুন:
- গিট রিপোজিটরি থেকে ফ্রেমওয়ার্ক কোড এবং আপনার মডেল সোর্স কোড ক্লোন করুন:
-
- ক্লোন
dynamic-sagemaker-pipelines-frameworkএকটি প্রশিক্ষণ ডিরেক্টরিতে repo. নিম্নলিখিত কোডে, আমরা অনুমান করি যে প্রশিক্ষণ ডিরেক্টরি বলা হয়aws-train: - একই ডিরেক্টরির অধীনে মডেল সোর্স কোড ক্লোন করুন। মাল্টি-মডেল প্রশিক্ষণের জন্য, আপনাকে যতগুলো মডেল প্রশিক্ষণ দিতে হবে তার জন্য এই ধাপটি পুনরাবৃত্তি করুন।
- ক্লোন
একক-মডেল প্রশিক্ষণের জন্য, আপনার ডিরেক্টরিটি নিম্নলিখিতগুলির মতো হওয়া উচিত:
মাল্টি-মডেল প্রশিক্ষণের জন্য, আপনার ডিরেক্টরিটি নিম্নলিখিতগুলির মতো হওয়া উচিত:
- নিম্নলিখিত পরিবেশ ভেরিয়েবল সেট আপ করুন. তারকাচিহ্নগুলি প্রয়োজনীয় পরিবেশের ভেরিয়েবলগুলি নির্দেশ করে; বাকিগুলো ঐচ্ছিক।
| পরিবেশ সূচক | বিবরণ |
SMP_ACCOUNTID* |
AWS অ্যাকাউন্ট যেখানে SageMaker পাইপলাইন চালানো হয় |
SMP_REGION* |
AWS অঞ্চল যেখানে SageMaker পাইপলাইন চালানো হয় |
SMP_S3BUCKETNAME* |
S3 বালতির নাম |
SMP_ROLE* |
সেজমেকার ভূমিকা |
SMP_MODEL_CONFIGPATH* |
একক-মডেল বা বহু-মডেল কনফিগারেশন ফাইলের আপেক্ষিক পথ |
SMP_SUBNETS |
SageMaker নেটওয়ার্কিং কনফিগারেশনের জন্য সাবনেট আইডি |
SMP_SECURITYGROUPS |
SageMaker নেটওয়ার্কিং কনফিগারেশনের জন্য নিরাপত্তা গ্রুপ আইডি |
একক-মডেল ব্যবহারের ক্ষেত্রে, SMP_MODEL_CONFIGPATH হবে <MODEL-DIR>/conf/conf.yaml. বহু-মডেল ব্যবহারের ক্ষেত্রে, SMP_MODEL_CONFIGPATH হবে */conf/conf.yaml, যা আপনাকে সব খুঁজে পেতে অনুমতি দেয় conf.yaml পাইথনের গ্লোব মডিউল ব্যবহার করে ফাইলগুলিকে একত্রিত করে একটি গ্লোবাল কনফিগারেশন ফাইল তৈরি করে। পরীক্ষার সময় (স্থানীয় পরীক্ষা), আপনি env.env ফাইলের ভিতরে পরিবেশের ভেরিয়েবল নির্দিষ্ট করতে পারেন এবং তারপর আপনার টার্মিনালে নিম্নলিখিত কমান্ডটি চালিয়ে সেগুলি রপ্তানি করতে পারেন:
উল্লেখ্য যে পরিবেশ পরিবর্তনশীল এর মান env.env উদ্ধৃতি চিহ্নের ভিতরে স্থাপন করা উচিত (উদাহরণস্বরূপ, SMP_REGION="us-east-1") কার্যকরীকরণের সময়, এই পরিবেশের ভেরিয়েবলগুলি সিআই পাইপলাইন দ্বারা সেট করা উচিত।
- নিম্নলিখিত কমান্ডগুলি চালিয়ে একটি ভার্চুয়াল পরিবেশ তৈরি এবং সক্রিয় করুন:
- নিম্নলিখিত কমান্ডটি চালিয়ে প্রয়োজনীয় পাইথন প্যাকেজগুলি ইনস্টল করুন:
- আপনার মডেল প্রশিক্ষণ সম্পাদনা করুন
conf.yamlনথি পত্র. আমরা পরবর্তী বিভাগে কনফিগারেশন ফাইল কাঠামো নিয়ে আলোচনা করব। - টার্মিনাল থেকে, SageMaker পাইপলাইন প্রশিক্ষণ DAG তৈরি বা আপডেট করতে এবং চালানোর জন্য ফ্রেমওয়ার্কের এন্ট্রি পয়েন্টে কল করুন:
- সেজমেকার পাইপলাইনগুলি দেখুন এবং ডিবাগ করুন পাইপলাইন SageMaker স্টুডিও UI এর ট্যাব।
কনফিগারেশন ফাইল গঠন
প্রস্তাবিত সমাধানে দুটি ধরণের কনফিগারেশন ফাইল রয়েছে: ফ্রেমওয়ার্ক কনফিগারেশন এবং মডেল কনফিগারেশন। এই বিভাগে, আমরা প্রতিটি বিশদভাবে বর্ণনা করি।
ফ্রেমওয়ার্ক কনফিগারেশন
সার্জারির /framework/conf/conf.yaml ফাইল ভেরিয়েবল সেট করে যা সমস্ত মডেলিং ইউনিট জুড়ে সাধারণ। এটা অন্তর্ভুক্ত SMP_S3BUCKETNAME, SMP_ROLE, SMP_MODEL_CONFIGPATH, SMP_SUBNETS, SMP_SECURITYGROUPS, এবং SMP_MODELNAME. এই ভেরিয়েবলগুলির বর্ণনা এবং পরিবেশের ভেরিয়েবলের মাধ্যমে কীভাবে সেগুলি সেট করা যায় তার জন্য স্থাপনার নির্দেশাবলীর ধাপ 3 পড়ুন।
মডেল কনফিগারেশন
প্রকল্পের প্রতিটি মডেলের জন্য, আমাদের নিম্নলিখিতটি উল্লেখ করতে হবে <MODEL-DIR>/conf/conf.yaml ফাইল (তারকাগুলি প্রয়োজনীয় বিভাগগুলি নির্দেশ করে; বাকিগুলি ঐচ্ছিক):
- /conf/মডেল* - এই বিভাগে, আপনি এক বা একাধিক মডেলিং ইউনিট কনফিগার করতে পারেন। যখন ফ্রেমওয়ার্ক কোড চালানো হয়, এটি রানটাইম চলাকালীন সমস্ত কনফিগারেশন ফাইল স্বয়ংক্রিয়ভাবে পড়বে এবং সেগুলিকে কনফিগারেশন ট্রিতে যুক্ত করবে। তাত্ত্বিকভাবে, আপনি একই সাথে সমস্ত মডেলিং ইউনিট নির্দিষ্ট করতে পারেন
conf.yamlফাইল, তবে ত্রুটিগুলি কমানোর জন্য প্রতিটি মডেলিং ইউনিট কনফিগারেশন তার নিজ নিজ ডিরেক্টরিতে বা গিট সংগ্রহস্থলে নির্দিষ্ট করার পরামর্শ দেওয়া হচ্ছে। ইউনিটগুলি নিম্নরূপ:- {ণশড}* - মডেলের নাম।
- source_directory* - একটি সাধারণ
source_dirমডেলিং ইউনিটের মধ্যে সমস্ত পদক্ষেপের জন্য ব্যবহার করার পথ। - পূর্ব প্রক্রিয়া - এই বিভাগটি প্রিপ্রসেসিং পরামিতি নির্দিষ্ট করে।
- ট্রেন* - এই বিভাগে প্রশিক্ষণ কাজের পরামিতি নির্দিষ্ট করে।
- রূপান্তর* – এই বিভাগটি পরীক্ষার ডেটাতে ভবিষ্যদ্বাণী করার জন্য সেজমেকার ট্রান্সফর্ম কাজের পরামিতিগুলি নির্দিষ্ট করে৷
- মূল্যায়ন - এই বিভাগটি প্রশিক্ষিত মডেলের জন্য একটি মডেল মেট্রিক্স JSON রিপোর্ট তৈরি করার জন্য SageMaker প্রক্রিয়াকরণ কাজের পরামিতিগুলি নির্দিষ্ট করে৷
- রেজিস্ট্রি* - এই বিভাগটি সেজমেকার মডেল রেজিস্ট্রিতে প্রশিক্ষিত মডেল নিবন্ধনের জন্য পরামিতিগুলি নির্দিষ্ট করে৷
- /conf/sagemaker পাইপলাইন* - এই বিভাগটি ধাপগুলির মধ্যে নির্ভরতা সহ সেজমেকার পাইপলাইন প্রবাহকে সংজ্ঞায়িত করে। একক-মডেল ব্যবহারের ক্ষেত্রে, এই বিভাগটি কনফিগারেশন ফাইলের শেষে সংজ্ঞায়িত করা হয়েছে। মাল্টি-মডেল ব্যবহারের ক্ষেত্রে,
sagemakerPipelineবিভাগটি শুধুমাত্র একটি মডেলের কনফিগারেশন ফাইলে সংজ্ঞায়িত করা প্রয়োজন (যেকোনো মডেল)। আমরা হিসাবে এই মডেল উল্লেখ অ্যাঙ্কর মডেল. পরামিতিগুলি নিম্নরূপ:- পাইপলাইনের নাম* - সেজমেকার পাইপলাইনের নাম।
- মডেল* - মডেলিং ইউনিটগুলির নেস্টেড তালিকা:
- {ণশড}* – মডেল শনাক্তকারী, যা /conf/models বিভাগে একটি {model-name} শনাক্তকারীর সাথে মেলে।
- পদক্ষেপ* -
- ধাপ_নাম* - সেজমেকার পাইপলাইন ডিএজি-তে ধাপের নাম দেখানো হবে।
- ধাপ_শ্রেণী* – (ইউনিয়ন [প্রসেসিং, ট্রেনিং, ক্রিয়েট মডেল, ট্রান্সফর্ম, মেট্রিক্স, রেজিস্টার মডেল])
- step_type* - এই পরামিতিটি শুধুমাত্র প্রিপ্রসেসিং ধাপের জন্য প্রয়োজন, যার জন্য এটি প্রিপ্রসেসে সেট করা উচিত। এটি প্রিপ্রসেস আলাদা করার জন্য এবং ধাপগুলি মূল্যায়ন করার জন্য প্রয়োজন, উভয়েরই একটি আছে
step_classপ্রক্রিয়াকরণ - সক্ষম_ক্যাশে – ([ইউনিয়ন[সত্য, মিথ্যা]])। এটি সক্ষম করতে হবে কিনা তা নির্দেশ করে সেজমেকার পাইপলাইন ক্যাশিং এই পদক্ষেপের জন্য।
- chain_input_source_step – ([তালিকা[পদক্ষেপ_নাম]])। আপনি এই ধাপে ইনপুট হিসাবে অন্য ধাপের চ্যানেল আউটপুট সেট করতে এটি ব্যবহার করতে পারেন।
- chain_input_additional_prefix - এটি শুধুমাত্র রূপান্তরের পদক্ষেপের জন্য অনুমোদিত
step_class, এবং এর সাথে একযোগে ব্যবহার করা যেতে পারেchain_input_source_stepরূপান্তর ধাপে ইনপুট হিসাবে ব্যবহার করা উচিত এমন ফাইলটিকে চিহ্নিত করার পরামিতি।
- পদক্ষেপ* -
- {ণশড}* – মডেল শনাক্তকারী, যা /conf/models বিভাগে একটি {model-name} শনাক্তকারীর সাথে মেলে।
- নির্ভরতা - এই বিভাগটি সেজমেকার পাইপলাইনগুলির ধাপগুলি চালানো উচিত এমন ক্রমটি নির্দিষ্ট করে৷ আমরা এই বিভাগের জন্য Apache Airflow স্বরলিপি অভিযোজিত করেছি (উদাহরণস্বরূপ,
{step_name} >> {step_name}) যদি এই বিভাগটি ফাঁকা রাখা হয়, সুস্পষ্ট নির্ভরতা দ্বারা নির্দিষ্ট করা হয়েছেchain_input_source_stepপ্যারামিটার বা অন্তর্নিহিত নির্ভরতা সেজমেকার পাইপলাইন ডিএজি প্রবাহকে সংজ্ঞায়িত করে।
মনে রাখবেন যে আমরা প্রতি মডেলিং ইউনিটে একটি প্রশিক্ষণের ধাপ রাখার পরামর্শ দিই। যদি একটি মডেলিং ইউনিটের জন্য একাধিক প্রশিক্ষণের ধাপগুলি সংজ্ঞায়িত করা হয়, তাহলে পরবর্তী পদক্ষেপগুলি অন্তর্নিহিতভাবে মডেল অবজেক্ট তৈরি করতে, মেট্রিক্স গণনা করতে এবং মডেলটি নিবন্ধন করতে শেষ প্রশিক্ষণের পদক্ষেপ নেয়। আপনার যদি একাধিক মডেল প্রশিক্ষণের প্রয়োজন হয় তবে একাধিক মডেলিং ইউনিট তৈরি করার পরামর্শ দেওয়া হয়।
উদাহরণ
এই বিভাগে, আমরা উপস্থাপিত কাঠামো ব্যবহার করে তৈরি এমএল মডেল প্রশিক্ষণ DAG-এর তিনটি উদাহরণ প্রদর্শন করি।
একক-মডেল প্রশিক্ষণ: লাইটজিবিএম
এটি একটি শ্রেণীবিভাগ ব্যবহারের ক্ষেত্রে একটি একক-মডেল উদাহরণ যেখানে আমরা ব্যবহার করি SageMaker-এ স্ক্রিপ্ট মোডে LightGBM. দ্য ডেটা সেটটি বাইনারি লেবেল রাজস্বের পূর্বাভাস দিতে শ্রেণীবদ্ধ এবং সংখ্যাসূচক ভেরিয়েবল নিয়ে গঠিত (বিষয়টি ক্রয় করে কিনা তা ভবিষ্যদ্বাণী করতে)। দ্য প্রিপ্রসেসিং স্ক্রিপ্ট প্রশিক্ষণ এবং পরীক্ষার জন্য ডেটা মডেল করতে এবং তারপরে ব্যবহৃত হয় এটি একটি S3 বালতিতে স্টেজ করুন. S3 পাথ তারপর প্রদান করা হয় প্রশিক্ষণ পদক্ষেপ কনফিগারেশন ফাইলে।
যখন প্রশিক্ষণের ধাপটি চলে, তখন SageMaker ফাইলটি কন্টেইনারে লোড করে /opt/ml/input/data/{channelName}/, পরিবেশ পরিবর্তনশীল মাধ্যমে অ্যাক্সেসযোগ্য SM_CHANNEL_{channelName} পাত্রে (চ্যানেলের নাম = 'ট্রেন' বা 'পরীক্ষা').দ্য প্রশিক্ষণ স্ক্রিপ্ট নিম্নলিখিত কাজ করে:
- ব্যবহার করে স্থানীয় কন্টেইনার পাথ থেকে স্থানীয়ভাবে ফাইলগুলি লোড করুন NumPy লোড মডিউল।
- প্রশিক্ষণ অ্যালগরিদমের জন্য হাইপারপ্যারামিটার সেট করুন।
- স্থানীয় কন্টেইনার পাথে প্রশিক্ষিত মডেল সংরক্ষণ করুন
/opt/ml/model/.
সেজমেকার একটি টারবল তৈরি করতে /opt/ml/model/ এর অধীনে সামগ্রী নেয় যা হোস্টিংয়ের জন্য SageMaker-এ মডেল স্থাপন করতে ব্যবহৃত হয়।
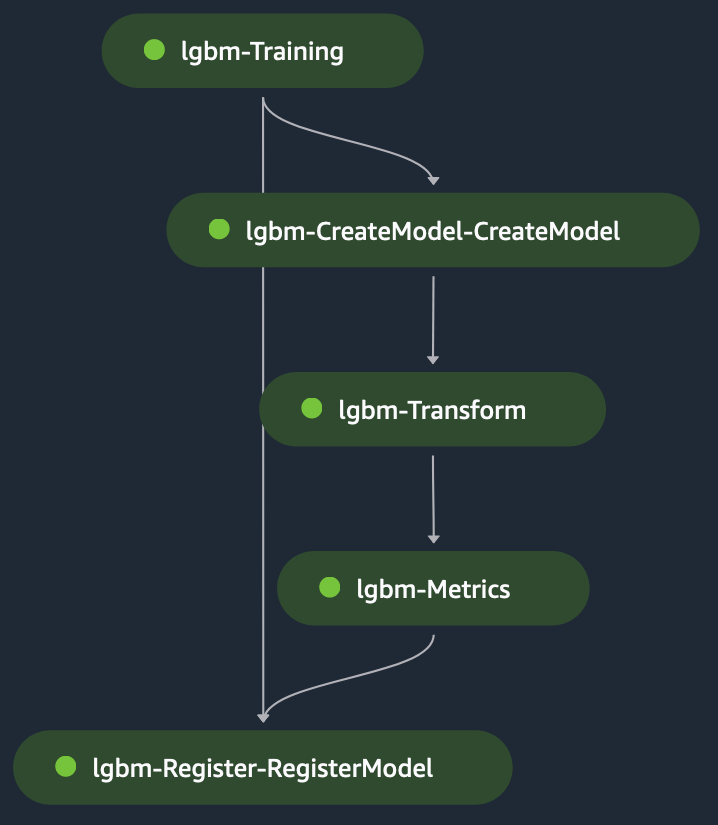
রূপান্তর পদক্ষেপটি স্টেজড ইনপুট হিসাবে নেয় ইনপুট হিসাবে পরীক্ষা ফাইল এবং প্রশিক্ষিত মডেলের উপর ভবিষ্যদ্বাণী করতে প্রশিক্ষিত মডেল। রূপান্তর ধাপের আউটপুট হয় শৃঙ্খলিত মডেলের বিপরীতে মূল্যায়ন করার জন্য মেট্রিক্স ধাপে কঠিন সত্য, যা স্পষ্টভাবে মেট্রিক্স ধাপে সরবরাহ করা হয়। পরিশেষে, মেট্রিক্স ধাপের আউটপুট মেট্রিক্স ধাপে উত্পাদিত মডেলের কর্মক্ষমতা সম্পর্কে তথ্য সহ সেজমেকার মডেল রেজিস্ট্রিতে মডেলটিকে নিবন্ধন করার জন্য রেজিস্টার ধাপে পরোক্ষভাবে চেইন করা হয়। নিচের চিত্রটি প্রশিক্ষণ DAG-এর একটি চাক্ষুষ উপস্থাপনা দেখায়। আপনি এই উদাহরণের জন্য স্ক্রিপ্ট এবং কনফিগারেশন ফাইল উল্লেখ করতে পারেন গিটহুব রেপো.
একক-মডেল প্রশিক্ষণ: এলএলএম ফাইন-টিউনিং
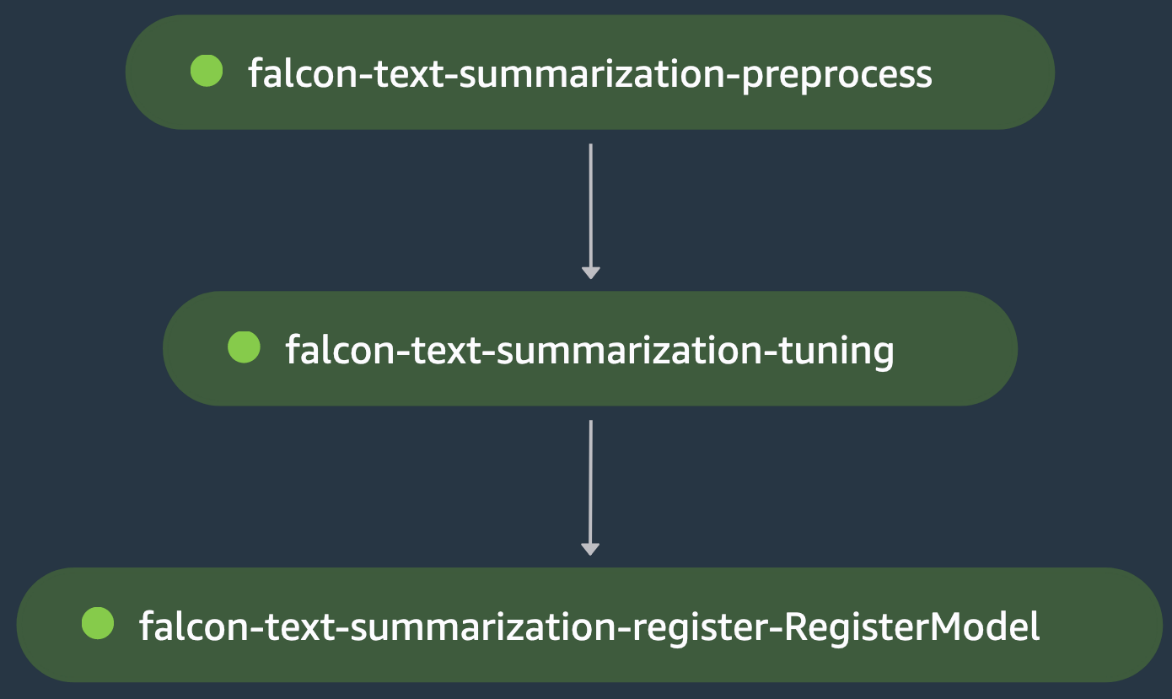
এটি আরেকটি একক-মডেল প্রশিক্ষণের উদাহরণ, যেখানে আমরা একটি পাঠ্য সংক্ষিপ্তকরণ ব্যবহারের ক্ষেত্রে হাগিং ফেস হাব থেকে Falcon-40B বড় ভাষা মডেল (LLM) এর ফাইন-টিউনিং অর্কেস্ট্রেট করি। দ্য প্রিপ্রসেসিং স্ক্রিপ্ট লোড করে সামসুম হাগিং ফেস থেকে ডেটাসেট, মডেলের জন্য টোকেনাইজার লোড করে এবং ফ্যালকন-টেক্সট-সারাংশ-প্রিপ্রসেস ধাপে এই ডোমেন ডেটাতে মডেলটিকে সূক্ষ্ম-টিউন করার জন্য ট্রেন/পরীক্ষার ডেটা বিভক্ত প্রক্রিয়া করে।
আউটপুট হয় শৃঙ্খলিত ফ্যালকন-টেক্সট-সারাংশ-টিউনিং ধাপে, যেখানে প্রশিক্ষণ স্ক্রিপ্ট হাগিং ফেস হাব থেকে Falcon-40B LLM লোড করে এবং ব্যবহার করে ত্বরান্বিত ফাইন-টিউনিং শুরু করে LoRA ট্রেন বিভক্ত উপর. মডেল সূক্ষ্ম-টিউনিং পরে একই ধাপে মূল্যায়ন করা হয়, যা দারোয়ান ফ্যালকন-টেক্সট-সংক্ষিপ্তকরণ-টিউনিং ধাপে ব্যর্থ হওয়ার জন্য মূল্যায়নের ক্ষতি, যার কারণে সেজমেকার পাইপলাইনটি সূক্ষ্ম-টিউনড মডেলটি নিবন্ধন করতে সক্ষম হওয়ার আগে বন্ধ হয়ে যায়। অন্যথায়, ফ্যালকন-টেক্সট-সারাংশ-টিউনিং ধাপটি সফলভাবে চলে এবং মডেলটি সেজমেকার মডেল রেজিস্ট্রিতে নিবন্ধিত হয়। নিম্নলিখিত চিত্রটি এলএলএম ফাইন-টিউনিং ডিএজি-এর একটি চাক্ষুষ উপস্থাপনা দেখায়। এই উদাহরণের জন্য স্ক্রিপ্ট এবং কনফিগারেশন ফাইল পাওয়া যায় গিটহুব রেপো.
মাল্টি মডেল প্রশিক্ষণ
এটি একটি মাল্টি-মডেল প্রশিক্ষণের উদাহরণ যেখানে একটি প্রধান উপাদান বিশ্লেষণ (পিসিএ) মডেলকে মাত্রিকতা হ্রাসের জন্য প্রশিক্ষণ দেওয়া হয় এবং একটি টেনসরফ্লো মাল্টিলেয়ার পারসেপ্ট্রন মডেলকে প্রশিক্ষণ দেওয়া হয় ক্যালিফোর্নিয়া হাউজিং মূল্য পূর্বাভাস. টেনসরফ্লো মডেলের প্রি-প্রসেসিং ধাপটি এর প্রশিক্ষণ ডেটার মাত্রা কমাতে একটি প্রশিক্ষিত PCA মডেল ব্যবহার করে। PCA মডেল রেজিস্ট্রেশনের পরে TensorFlow মডেল নিবন্ধিত হয়েছে তা নিশ্চিত করতে আমরা কনফিগারেশনে একটি নির্ভরতা যোগ করি। নিম্নলিখিত চিত্রটি মাল্টি-মডেল প্রশিক্ষণ DAG উদাহরণের একটি চাক্ষুষ উপস্থাপনা দেখায়। এই উদাহরণের জন্য স্ক্রিপ্ট এবং কনফিগারেশন ফাইল পাওয়া যায় গিটহুব রেপো.

পরিষ্কার কর
আপনার সংস্থানগুলি পরিষ্কার করতে নিম্নলিখিত পদক্ষেপগুলি সম্পূর্ণ করুন:
- এর জন্য AWS CLI ব্যবহার করুন তালিকা এবং অপসারণ পাইথন স্ক্রিপ্ট দ্বারা তৈরি যে কোনো অবশিষ্ট পাইপলাইন।
- ঐচ্ছিকভাবে, S3 বালতি বা SageMaker পাইপলাইনের বাইরে তৈরি IAM ভূমিকার মতো অন্যান্য AWS সম্পদ মুছুন।
উপসংহার
এই পোস্টে, আমরা কনফিগারেশন ফাইলের উপর ভিত্তি করে SageMaker পাইপলাইন DAG তৈরির স্বয়ংক্রিয়তার জন্য একটি কাঠামো উপস্থাপন করেছি। প্রস্তাবিত ফ্রেমওয়ার্ক জটিল এমএল ওয়ার্কলোড অর্কেস্ট্রেট করার চ্যালেঞ্জের জন্য একটি দূরদর্শী সমাধান প্রদান করে। একটি কনফিগারেশন ফাইল ব্যবহার করে, সেজমেকার পাইপলাইনগুলি ন্যূনতম কোডের সাথে অর্কেস্ট্রেশন তৈরি করার নমনীয়তা প্রদান করে, যাতে আপনি একক-মডেল এবং মাল্টি-মডেল উভয় পাইপলাইন তৈরি এবং পরিচালনা করার প্রক্রিয়াটিকে প্রবাহিত করতে পারেন। এই পদ্ধতিটি কেবল সময় এবং সংস্থানই সাশ্রয় করে না, তবে এমএলওপ্সের সর্বোত্তম অনুশীলনকেও প্রচার করে, এমএল উদ্যোগের সামগ্রিক সাফল্যে অবদান রাখে। বাস্তবায়নের বিবরণ সম্পর্কে আরও তথ্যের জন্য, পর্যালোচনা করুন গিটহুব রেপো.
লেখক সম্পর্কে
 লুইস ফেলিপ ইয়েপেজ ব্যারিওস, AWS পেশাদার পরিষেবা সহ একজন মেশিন লার্নিং ইঞ্জিনিয়ার, মেশিন লার্নিং (ML) ক্ষেত্রে বৈজ্ঞানিক উদ্ভাবন ত্বরান্বিত করার জন্য স্কেলেবল ডিস্ট্রিবিউটেড সিস্টেম এবং অটোমেশন টুলিংয়ের উপর দৃষ্টি নিবদ্ধ করে৷ অধিকন্তু, তিনি এন্টারপ্রাইজ ক্লায়েন্টদের AWS পরিষেবার মাধ্যমে তাদের মেশিন লার্নিং সমাধানগুলি অপ্টিমাইজ করতে সহায়তা করেন।
লুইস ফেলিপ ইয়েপেজ ব্যারিওস, AWS পেশাদার পরিষেবা সহ একজন মেশিন লার্নিং ইঞ্জিনিয়ার, মেশিন লার্নিং (ML) ক্ষেত্রে বৈজ্ঞানিক উদ্ভাবন ত্বরান্বিত করার জন্য স্কেলেবল ডিস্ট্রিবিউটেড সিস্টেম এবং অটোমেশন টুলিংয়ের উপর দৃষ্টি নিবদ্ধ করে৷ অধিকন্তু, তিনি এন্টারপ্রাইজ ক্লায়েন্টদের AWS পরিষেবার মাধ্যমে তাদের মেশিন লার্নিং সমাধানগুলি অপ্টিমাইজ করতে সহায়তা করেন।
 জিনঝাও ফেং, AWS প্রফেশনাল সার্ভিসে একজন মেশিন লার্নিং ইঞ্জিনিয়ার। তিনি বৃহৎ আকারের জেনারেটিভ এআই এবং ক্লাসিক্যাল এমএল পাইপলাইন সলিউশনের আর্কিটেক্টিং এবং বাস্তবায়নের দিকে মনোনিবেশ করেন। তিনি FMOps, LLMOps এবং বিতরণকৃত প্রশিক্ষণে বিশেষজ্ঞ।
জিনঝাও ফেং, AWS প্রফেশনাল সার্ভিসে একজন মেশিন লার্নিং ইঞ্জিনিয়ার। তিনি বৃহৎ আকারের জেনারেটিভ এআই এবং ক্লাসিক্যাল এমএল পাইপলাইন সলিউশনের আর্কিটেক্টিং এবং বাস্তবায়নের দিকে মনোনিবেশ করেন। তিনি FMOps, LLMOps এবং বিতরণকৃত প্রশিক্ষণে বিশেষজ্ঞ।
 হর্ষ আসনানি, AWS এ একজন মেশিন লার্নিং ইঞ্জিনিয়ার। তার ব্যাকগ্রাউন্ড অ্যাপ্লায়েড ডেটা সায়েন্সে রয়েছে যেখানে ক্লাউডে মেশিন লার্নিং ওয়ার্কলোডগুলিকে পরিচালন করার উপর ফোকাস রয়েছে।
হর্ষ আসনানি, AWS এ একজন মেশিন লার্নিং ইঞ্জিনিয়ার। তার ব্যাকগ্রাউন্ড অ্যাপ্লায়েড ডেটা সায়েন্সে রয়েছে যেখানে ক্লাউডে মেশিন লার্নিং ওয়ার্কলোডগুলিকে পরিচালন করার উপর ফোকাস রয়েছে।
 হাসান শোজাই, AWS প্রফেশনাল সার্ভিসেসের একজন সিনিয়র ডেটা সায়েন্টিস্ট, যেখানে তিনি বিগ ডেটা, মেশিন লার্নিং এবং ক্লাউড প্রযুক্তি ব্যবহারের মাধ্যমে বিভিন্ন শিল্পের গ্রাহকদের তাদের ব্যবসায়িক চ্যালেঞ্জগুলি সমাধান করতে সাহায্য করেন। এই ভূমিকার আগে, হাসান শীর্ষ শক্তি সংস্থাগুলির জন্য অভিনব পদার্থবিদ্যা-ভিত্তিক এবং ডেটা-চালিত মডেলিং কৌশলগুলি বিকাশের জন্য একাধিক উদ্যোগের নেতৃত্ব দিয়েছিলেন। কাজের বাইরে, হাসান বই, হাইকিং, ফটোগ্রাফি এবং ইতিহাস সম্পর্কে উত্সাহী।
হাসান শোজাই, AWS প্রফেশনাল সার্ভিসেসের একজন সিনিয়র ডেটা সায়েন্টিস্ট, যেখানে তিনি বিগ ডেটা, মেশিন লার্নিং এবং ক্লাউড প্রযুক্তি ব্যবহারের মাধ্যমে বিভিন্ন শিল্পের গ্রাহকদের তাদের ব্যবসায়িক চ্যালেঞ্জগুলি সমাধান করতে সাহায্য করেন। এই ভূমিকার আগে, হাসান শীর্ষ শক্তি সংস্থাগুলির জন্য অভিনব পদার্থবিদ্যা-ভিত্তিক এবং ডেটা-চালিত মডেলিং কৌশলগুলি বিকাশের জন্য একাধিক উদ্যোগের নেতৃত্ব দিয়েছিলেন। কাজের বাইরে, হাসান বই, হাইকিং, ফটোগ্রাফি এবং ইতিহাস সম্পর্কে উত্সাহী।
 অ্যালেক জেনাব, একজন মেশিন লার্নিং ইঞ্জিনিয়ার যিনি এন্টারপ্রাইজ গ্রাহকদের জন্য স্কেলে মেশিন লার্নিং সলিউশন তৈরি এবং চালু করতে বিশেষজ্ঞ। অ্যালেক বাজারে উদ্ভাবনী সমাধান আনার বিষয়ে উত্সাহী, বিশেষ করে এমন এলাকায় যেখানে মেশিন লার্নিং অর্থপূর্ণভাবে শেষ ব্যবহারকারীর অভিজ্ঞতা উন্নত করতে পারে। কাজের বাইরে, তিনি বাস্কেটবল খেলা, স্নোবোর্ডিং এবং সান ফ্রান্সিসকোতে লুকানো রত্ন আবিষ্কার করা উপভোগ করেন।
অ্যালেক জেনাব, একজন মেশিন লার্নিং ইঞ্জিনিয়ার যিনি এন্টারপ্রাইজ গ্রাহকদের জন্য স্কেলে মেশিন লার্নিং সলিউশন তৈরি এবং চালু করতে বিশেষজ্ঞ। অ্যালেক বাজারে উদ্ভাবনী সমাধান আনার বিষয়ে উত্সাহী, বিশেষ করে এমন এলাকায় যেখানে মেশিন লার্নিং অর্থপূর্ণভাবে শেষ ব্যবহারকারীর অভিজ্ঞতা উন্নত করতে পারে। কাজের বাইরে, তিনি বাস্কেটবল খেলা, স্নোবোর্ডিং এবং সান ফ্রান্সিসকোতে লুকানো রত্ন আবিষ্কার করা উপভোগ করেন।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- PlatoData.Network উল্লম্ব জেনারেটিভ Ai. নিজেকে ক্ষমতায়িত করুন। এখানে প্রবেশ করুন.
- প্লেটোএআইস্ট্রিম। Web3 ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- প্লেটোইএসজি। কার্বন, ক্লিনটেক, শক্তি, পরিবেশ সৌর, বর্জ্য ব্যবস্থাপনা. এখানে প্রবেশ করুন.
- প্লেটো হেলথ। বায়োটেক এবং ক্লিনিক্যাল ট্রায়াল ইন্টেলিজেন্স। এখানে প্রবেশ করুন.
- উত্স: https://aws.amazon.com/blogs/machine-learning/automate-amazon-sagemaker-pipelines-dag-creation/

