ম্যানুফ্যাকচারিংয়ের ক্রমবর্ধমান ল্যান্ডস্কেপে, এআই এবং মেশিন লার্নিং (এমএল)-এর রূপান্তরকারী শক্তি স্পষ্ট, একটি ডিজিটাল বিপ্লব চালায় যা অপারেশনকে স্ট্রিমলাইন করে এবং উত্পাদনশীলতা বাড়ায়। যাইহোক, এই অগ্রগতি ডেটা-চালিত সমাধানগুলি নেভিগেট করার উদ্যোগগুলির জন্য অনন্য চ্যালেঞ্জের পরিচয় দেয়। শিল্প সুবিধাগুলি সেন্সর, টেলিমেট্রি সিস্টেম এবং উত্পাদন লাইন জুড়ে ছড়িয়ে থাকা সরঞ্জামগুলি থেকে উৎসারিত বিশাল পরিমাণে অসংগঠিত ডেটা নিয়ে লড়াই করে। রিয়েল-টাইম ডেটা ভবিষ্যদ্বাণীমূলক রক্ষণাবেক্ষণ এবং অসঙ্গতি সনাক্তকরণের মতো অ্যাপ্লিকেশনগুলির জন্য গুরুত্বপূর্ণ, তবুও এই জাতীয় টাইম সিরিজ ডেটা সহ প্রতিটি শিল্প ব্যবহারের ক্ষেত্রে কাস্টম এমএল মডেলগুলি বিকাশ করা ডেটা বিজ্ঞানীদের কাছ থেকে যথেষ্ট সময় এবং সংস্থান দাবি করে, যা ব্যাপক গ্রহণে বাধা দেয়।
জেনারেটিভ এআই বড় প্রাক-প্রশিক্ষিত ফাউন্ডেশন মডেল ব্যবহার করে (FMs) যেমন ক্লদ সহজ পাঠ্য প্রম্পটের উপর ভিত্তি করে কথোপকথনমূলক পাঠ্য থেকে কম্পিউটার কোড পর্যন্ত দ্রুত বিভিন্ন বিষয়বস্তু তৈরি করতে পারে, যা নামে পরিচিত জিরো-শট প্রম্পটিং. এটি প্রতিটি ব্যবহারের ক্ষেত্রে ম্যানুয়ালি নির্দিষ্ট এমএল মডেল তৈরি করার জন্য ডেটা বিজ্ঞানীদের প্রয়োজনীয়তা দূর করে এবং তাই এআই অ্যাক্সেসকে গণতান্ত্রিক করে তোলে, এমনকি ছোট নির্মাতাদেরও উপকার করে। কর্মীরা AI-উত্পাদিত অন্তর্দৃষ্টির মাধ্যমে উত্পাদনশীলতা অর্জন করে, প্রকৌশলীরা সক্রিয়ভাবে অসঙ্গতি সনাক্ত করতে পারে, সরবরাহ চেইন ম্যানেজাররা ইনভেন্টরিগুলি অপ্টিমাইজ করে এবং উদ্ভিদ নেতৃত্ব তথ্য-চালিত সিদ্ধান্ত নেয়।
তবুও, স্বতন্ত্র এফএমগুলি প্রসঙ্গ আকারের সীমাবদ্ধতার সাথে জটিল শিল্প ডেটা পরিচালনা করার ক্ষেত্রে সীমাবদ্ধতার সম্মুখীন হয় (সাধারণত 200,000 টোকেনের কম), যা চ্যালেঞ্জ তৈরি করে। এটি মোকাবেলা করার জন্য, আপনি প্রাকৃতিক ভাষা প্রশ্নের (NLQs) উত্তরে কোড তৈরি করার জন্য FM-এর ক্ষমতা ব্যবহার করতে পারেন। এজেন্ট পছন্দ করে পান্ডাসএআই এই কোডটি উচ্চ-রেজোলিউশন টাইম সিরিজ ডেটাতে চালানো এবং FM ব্যবহার করে ত্রুটিগুলি পরিচালনা করা। পান্ডাসএআই হল একটি পাইথন লাইব্রেরি যা পান্ডাগুলিতে জেনারেটিভ এআই ক্ষমতা যুক্ত করে, জনপ্রিয় ডেটা বিশ্লেষণ এবং ম্যানিপুলেশন টুল।
যাইহোক, জটিল NLQs, যেমন টাইম সিরিজ ডেটা প্রসেসিং, মাল্টি-লেভেল অ্যাগ্রিগেশন, এবং পিভট বা জয়েন্ট টেবিল অপারেশন, শূন্য-শট প্রম্পটের সাথে অসঙ্গত পাইথন স্ক্রিপ্টের সঠিকতা প্রদান করতে পারে।
কোড জেনারেশন নির্ভুলতা বাড়ানোর জন্য, আমরা গতিশীলভাবে নির্মাণের প্রস্তাব করি মাল্টি-শট প্রম্পট NLQ এর জন্য। মাল্টি-শট প্রম্পটিং এফএমকে একই ধরনের প্রম্পটের জন্য কাঙ্খিত আউটপুটের বেশ কয়েকটি উদাহরণ দেখিয়ে, নির্ভুলতা এবং ধারাবাহিকতা বৃদ্ধি করে অতিরিক্ত প্রসঙ্গ সরবরাহ করে। এই পোস্টে, মাল্টি-শট প্রম্পটগুলি একটি এম্বেডিং থেকে পুনরুদ্ধার করা হয়েছে যেটি সফল পাইথন কোড সমন্বিত একটি অনুরূপ ডেটা টাইপে চালিত হয়েছে (উদাহরণস্বরূপ, ইন্টারনেট অফ থিংস ডিভাইস থেকে উচ্চ-রেজোলিউশন টাইম সিরিজ ডেটা)। গতিশীলভাবে নির্মিত মাল্টি-শট প্রম্পটটি এফএম-কে সবচেয়ে প্রাসঙ্গিক প্রেক্ষাপট প্রদান করে এবং উন্নত গণিত গণনা, টাইম সিরিজ ডেটা প্রসেসিং এবং ডেটা সংক্ষিপ্ত বোঝার ক্ষেত্রে এফএম-এর ক্ষমতা বাড়ায়। এই উন্নত প্রতিক্রিয়া এন্টারপ্রাইজ কর্মীদের এবং অপারেশনাল দলগুলিকে ডেটার সাথে জড়িত হতে, ব্যাপক ডেটা বিজ্ঞানের দক্ষতার প্রয়োজন ছাড়াই অন্তর্দৃষ্টি অর্জন করতে সহায়তা করে।
টাইম সিরিজ ডেটা বিশ্লেষণের বাইরে, FM বিভিন্ন শিল্প অ্যাপ্লিকেশনে মূল্যবান প্রমাণ করে। রক্ষণাবেক্ষণ দলগুলি সম্পদের স্বাস্থ্যের মূল্যায়ন করে, এর জন্য চিত্রগুলি ক্যাপচার করে আমাজন রেকোনিশন-ভিত্তিক কার্যকারিতা সংক্ষিপ্তসার, এবং বুদ্ধিমান অনুসন্ধান ব্যবহার করে অসঙ্গতি মূল কারণ বিশ্লেষণ পুনরুদ্ধার অগমেন্টেড জেনারেশন (RAG)। এই কর্মপ্রবাহকে সহজ করার জন্য, AWS চালু করেছে আমাজন বেডরক, আপনাকে অত্যাধুনিক প্রাক-প্রশিক্ষিত এফএম সহ জেনারেটিভ এআই অ্যাপ্লিকেশনগুলি তৈরি করতে এবং স্কেল করতে সক্ষম করে ক্লদ v2। সঙ্গে আমাজন বেডরকের জন্য জ্ঞানের ভিত্তি, আপনি উদ্ভিদ শ্রমিকদের জন্য আরো সঠিক অসঙ্গতি মূল কারণ বিশ্লেষণ প্রদান করতে RAG উন্নয়ন প্রক্রিয়া সহজ করতে পারেন। আমাদের পোস্টটি অ্যামাজন বেডরক দ্বারা চালিত শিল্প ব্যবহারের ক্ষেত্রে একজন বুদ্ধিমান সহকারীকে দেখায়, NLQ চ্যালেঞ্জ মোকাবেলা করা, ছবি থেকে অংশের সারাংশ তৈরি করা এবং RAG পদ্ধতির মাধ্যমে সরঞ্জাম নির্ণয়ের জন্য FM প্রতিক্রিয়া উন্নত করা।
সমাধান ওভারভিউ
নিম্নলিখিত চিত্রটি সমাধানের স্থাপত্যকে চিত্রিত করে।

ওয়ার্কফ্লোতে তিনটি স্বতন্ত্র ব্যবহারের ক্ষেত্রে অন্তর্ভুক্ত রয়েছে:
কেস 1 ব্যবহার করুন: টাইম সিরিজ ডেটা সহ NLQ
টাইম সিরিজ ডেটা সহ NLQ এর জন্য ওয়ার্কফ্লো নিম্নলিখিত পদক্ষেপগুলি নিয়ে গঠিত:
- আমরা অসঙ্গতি সনাক্তকরণের জন্য এমএল ক্ষমতা সহ একটি শর্ত পর্যবেক্ষণ সিস্টেম ব্যবহার করি, যেমন আমাজন মনিটরন, শিল্প সরঞ্জাম স্বাস্থ্য নিরীক্ষণ. অ্যামাজন মনিটরন সরঞ্জামের কম্পন এবং তাপমাত্রা পরিমাপ থেকে সম্ভাব্য সরঞ্জামের ব্যর্থতা সনাক্ত করতে সক্ষম।
- আমরা প্রক্রিয়াকরণের মাধ্যমে টাইম সিরিজ ডেটা সংগ্রহ করি আমাজন মনিটরন মাধ্যমে ডেটা অ্যামাজন কিনসিস ডেটা স্ট্রিম এবং আমাজন ডেটা ফায়ারহোস, এটিকে একটি ট্যাবুলার CSV ফরম্যাটে রূপান্তর করা এবং একটিতে সংরক্ষণ করা আমাজন সিম্পল স্টোরেজ সার্ভিস (অ্যামাজন এস 3) বালতি।
- শেষ-ব্যবহারকারী স্ট্রিমলিট অ্যাপে একটি প্রাকৃতিক ভাষা ক্যোয়ারী পাঠিয়ে Amazon S3-এ তাদের টাইম সিরিজ ডেটার সাথে চ্যাট করা শুরু করতে পারে।
- স্ট্রিমলিট অ্যাপ ব্যবহারকারীর প্রশ্নগুলিকে ফরওয়ার্ড করে অ্যামাজন বেডরক টাইটান টেক্সট এমবেডিং মডেল এই ক্যোয়ারী এমবেড করতে, এবং একটি এর মধ্যে একটি মিল অনুসন্ধান করে আমাজন ওপেন সার্চ সার্ভিস সূচক, যা পূর্বের NLQ এবং উদাহরণ কোড ধারণ করে।
- মিল অনুসন্ধানের পরে, NLQ প্রশ্ন, ডেটা স্কিমা এবং পাইথন কোড সহ শীর্ষ অনুরূপ উদাহরণগুলি একটি কাস্টম প্রম্পটে ঢোকানো হয়।
- PandasAI এই কাস্টম প্রম্পটটি Amazon Bedrock Claude v2 মডেলে পাঠায়।
- অ্যাপটি Amazon Bedrock Claude v2 মডেলের সাথে ইন্টারঅ্যাক্ট করার জন্য PandasAI এজেন্ট ব্যবহার করে, Amazon Monitron ডেটা বিশ্লেষণ এবং NLQ প্রতিক্রিয়াগুলির জন্য পাইথন কোড তৈরি করে।
- Amazon Bedrock Claude v2 মডেল পাইথন কোড ফেরত দেওয়ার পরে, PandasAI অ্যাপ থেকে আপলোড করা Amazon Monitron ডেটাতে Python কোয়েরি চালায়, কোড আউটপুট সংগ্রহ করে এবং ব্যর্থ রানের জন্য প্রয়োজনীয় পুনঃপ্রচারের সমাধান করে।
- স্ট্রিমলিট অ্যাপ পান্ডাসএআই-এর মাধ্যমে প্রতিক্রিয়া সংগ্রহ করে এবং ব্যবহারকারীদের আউটপুট প্রদান করে। যদি আউটপুট সন্তোষজনক হয়, ব্যবহারকারী এটিকে সহায়ক হিসাবে চিহ্নিত করতে পারেন, ওপেনসার্চ পরিষেবাতে NLQ এবং Claude-উত্পন্ন পাইথন কোড সংরক্ষণ করে৷
কেস 2 ব্যবহার করুন: ত্রুটিপূর্ণ অংশগুলির সারাংশ তৈরি করুন
আমাদের সারাংশ প্রজন্মের ব্যবহারের ক্ষেত্রে নিম্নলিখিত পদক্ষেপগুলি রয়েছে:
- ব্যবহারকারীর জানার পরে কোন শিল্প সম্পদ অস্বাভাবিক আচরণ দেখায়, তারা ত্রুটিপূর্ণ অংশটির চিত্র আপলোড করতে পারে যাতে এটির প্রযুক্তিগত বৈশিষ্ট্য এবং অপারেশন অবস্থা অনুসারে এই অংশটিতে শারীরিকভাবে কিছু ভুল আছে কিনা তা সনাক্ত করতে পারে।
- ব্যবহারকারী এটি ব্যবহার করতে পারেন Amazon Recognition DetectText API এই ছবিগুলি থেকে পাঠ্য ডেটা বের করতে।
- নিষ্কাশিত পাঠ্য ডেটা Amazon Bedrock Claude v2 মডেলের প্রম্পটে অন্তর্ভুক্ত করা হয়েছে, যা মডেলটিকে ত্রুটিপূর্ণ অংশের 200-শব্দের সারাংশ তৈরি করতে সক্ষম করে। ব্যবহারকারী অংশটির আরও পরিদর্শন করতে এই তথ্য ব্যবহার করতে পারেন।
কেস 3 ব্যবহার করুন: মূল কারণ নির্ণয়
আমাদের মূল কারণ নির্ণয়ের ব্যবহারের ক্ষেত্রে নিম্নলিখিত পদক্ষেপগুলি রয়েছে:
- ব্যবহারকারী বিভিন্ন ডকুমেন্ট ফরম্যাটে (PDF, TXT, এবং আরও অনেক কিছু) ত্রুটিপূর্ণ সম্পদের সাথে সম্পর্কিত এন্টারপ্রাইজ ডেটা পায় এবং সেগুলিকে একটি S3 বালতিতে আপলোড করে।
- টাইটান টেক্সট এম্বেডিং মডেল এবং একটি ডিফল্ট ওপেনসার্চ সার্ভিস ভেক্টর স্টোর সহ অ্যামাজন বেডরকে এই ফাইলগুলির একটি জ্ঞানের ভিত্তি তৈরি করা হয়েছে।
- ব্যবহারকারী ত্রুটিযুক্ত সরঞ্জামগুলির জন্য মূল কারণ নির্ণয়ের সাথে সম্পর্কিত প্রশ্ন উত্থাপন করেন। একটি RAG পদ্ধতির সাথে অ্যামাজন বেডরক নলেজ বেসের মাধ্যমে উত্তর তৈরি করা হয়।
পূর্বশর্ত
এই পোস্টটি অনুসরণ করতে, আপনাকে নিম্নলিখিত পূর্বশর্তগুলি পূরণ করতে হবে:
সমাধান পরিকাঠামো স্থাপন
আপনার সমাধান সংস্থান সেট আপ করতে, নিম্নলিখিত পদক্ষেপগুলি সম্পূর্ণ করুন:
- স্থাপন করুন এডাব্লুএস ক্লাউডফর্মেশন টেমপ্লেট opensearchsagemaker.yml, যা একটি OpenSearch পরিষেবা সংগ্রহ এবং সূচক তৈরি করে, আমাজন সেজমেকার নোটবুক উদাহরণ, এবং S3 বালতি। আপনি এই AWS CloudFormation স্ট্যাকের নাম দিতে পারেন:
genai-sagemaker. - JupyterLab এ SageMaker নোটবুক উদাহরণটি খুলুন। আপনি নিম্নলিখিত পাবেন গিটহুব রেপো ইতিমধ্যে এই উদাহরণে ডাউনলোড করা হয়েছে: আনলকিং-এর-সম্ভাব্য-অফ-জেনারেটিভ-এআই-ইন-ইন্ডাস্ট্রিয়াল-অপারেশন.
- এই সংগ্রহস্থলে নিম্নলিখিত ডিরেক্টরি থেকে নোটবুকটি চালান: আনলকিং-দ্য-সম্ভাব্য-অফ-জেনারেটিভ-এআই-ইন-ইন্ডাস্ট্রিয়াল-অপারেশন/সেজমেকার নোটবুক/nlq-vector-rag-embedding.ipynb. এই নোটবুকটি সেজমেকার নোটবুক ব্যবহার করে ওপেনসার্চ পরিষেবা সূচক লোড করবে যা থেকে কী-মান জোড়া সঞ্চয় করবে বিদ্যমান 23 NLQ উদাহরণ.
- ডেটা ফোল্ডার থেকে নথি আপলোড করুন assetpartdoc ক্লাউডফরমেশন স্ট্যাক আউটপুটে তালিকাভুক্ত S3 বালতিতে GitHub সংগ্রহস্থলে।

এর পরে, আপনি Amazon S3-এ নথিগুলির জন্য জ্ঞানের ভিত্তি তৈরি করুন৷
- অ্যামাজন বেডরক কনসোলে, বেছে নিন জ্ঞানভিত্তিক নেভিগেশন ফলকে।
- বেছে নিন জ্ঞানের ভিত্তি তৈরি করুন.
- জন্য জ্ঞানের ভিত্তির নাম, একটি নাম লিখুন।
- জন্য রানটাইম ভূমিকা, নির্বাচন করুন একটি নতুন পরিষেবা ভূমিকা তৈরি করুন এবং ব্যবহার করুন.

- জন্য ডেটা উত্সের নাম, আপনার ডেটা উৎসের নাম লিখুন।
- জন্য S3 URI, বালতির S3 পাথ লিখুন যেখানে আপনি মূল কারণ নথি আপলোড করেছেন৷
- বেছে নিন পরবর্তী.
 টাইটান এমবেডিং মডেল স্বয়ংক্রিয়ভাবে নির্বাচিত হয়।
টাইটান এমবেডিং মডেল স্বয়ংক্রিয়ভাবে নির্বাচিত হয়। - নির্বাচন করা দ্রুত একটি নতুন ভেক্টর স্টোর তৈরি করুন.

- আপনার সেটিংস পর্যালোচনা করুন এবং নির্বাচন করে জ্ঞানের ভিত্তি তৈরি করুন জ্ঞানের ভিত্তি তৈরি করুন.
- জ্ঞানের ভিত্তি সফলভাবে তৈরি হওয়ার পরে, নির্বাচন করুন সিঙ্ক S3 বালতিকে জ্ঞানের ভিত্তির সাথে সিঙ্ক করতে।

- আপনি জ্ঞানের ভিত্তি সেট আপ করার পরে, আপনি "আমার অ্যাকচুয়েটর ধীর গতিতে ভ্রমণ করে, সমস্যা কী হতে পারে?" এর মতো প্রশ্ন জিজ্ঞাসা করে মূল কারণ নির্ণয়ের জন্য RAG পদ্ধতি পরীক্ষা করতে পারেন।

পরবর্তী ধাপ হল আপনার পিসি বা EC2 ইন্সট্যান্স (উবুন্টু সার্ভার 22.04 এলটিএস) এ প্রয়োজনীয় লাইব্রেরি প্যাকেজ সহ অ্যাপটি স্থাপন করা।
- আপনার AWS শংসাপত্র সেট আপ করুন আপনার স্থানীয় পিসিতে AWS CLI সহ। সরলতার জন্য, আপনি ক্লাউডফরমেশন স্ট্যাক স্থাপন করার জন্য একই অ্যাডমিন ভূমিকা ব্যবহার করতে পারেন। আপনি যদি Amazon EC2 ব্যবহার করেন, উদাহরণে একটি উপযুক্ত IAM ভূমিকা সংযুক্ত করুন.
- ক্লোন গিটহুব রেপো:
- ডিরেক্টরি পরিবর্তন করুন
unlocking-the-potential-of-generative-ai-in-industrial-operations/srcএবং রানsetup.shLangChain এবং PandasAI সহ প্রয়োজনীয় প্যাকেজগুলি ইনস্টল করতে এই ফোল্ডারে স্ক্রিপ্ট:cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - নিম্নলিখিত কমান্ড দিয়ে Streamlit অ্যাপ চালান:
source monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
আগের ধাপ থেকে Amazon Bedrock-এ আপনার তৈরি করা OpenSearch পরিষেবা সংগ্রহ ARN প্রদান করুন।
আপনার সম্পদ স্বাস্থ্য সহকারীর সাথে চ্যাট করুন
আপনি এন্ড-টু-এন্ড ডিপ্লয়মেন্ট সম্পূর্ণ করার পরে, আপনি পোর্ট 8501-এ লোকালহোস্টের মাধ্যমে অ্যাপটি অ্যাক্সেস করতে পারেন, যা ওয়েব ইন্টারফেসের সাথে একটি ব্রাউজার উইন্ডো খোলে। আপনি যদি একটি EC2 উদাহরণে অ্যাপটি স্থাপন করেন, নিরাপত্তা গ্রুপ ইনবাউন্ড নিয়মের মাধ্যমে পোর্ট 8501 অ্যাক্সেসের অনুমতি দিন. আপনি বিভিন্ন ব্যবহারের ক্ষেত্রে বিভিন্ন ট্যাবে নেভিগেট করতে পারেন।
ব্যবহার কেস 1 অন্বেষণ
প্রথম ব্যবহারের ক্ষেত্রে অন্বেষণ করতে, নির্বাচন করুন ডেটা অন্তর্দৃষ্টি এবং চার্ট. আপনার টাইম সিরিজ ডেটা আপলোড করে শুরু করুন। ব্যবহার করার জন্য আপনার কাছে বিদ্যমান টাইম সিরিজ ডেটা ফাইল না থাকলে, আপনি নিম্নলিখিতগুলি আপলোড করতে পারেন৷ নমুনা CSV ফাইল বেনামী অ্যামাজন মনিটরন প্রকল্প ডেটা সহ। আপনার যদি ইতিমধ্যেই একটি অ্যামাজন মনিটরন প্রকল্প থাকে তবে পড়ুন Amazon Monitron এবং Amazon Kinesis এর সাথে ভবিষ্যদ্বাণীমূলক রক্ষণাবেক্ষণ পরিচালনার জন্য কর্মযোগ্য অন্তর্দৃষ্টি তৈরি করুন আপনার Amazon Monitron ডেটা Amazon S3 এ স্ট্রিম করতে এবং এই অ্যাপ্লিকেশনটির সাথে আপনার ডেটা ব্যবহার করতে।
আপলোড সম্পূর্ণ হলে, আপনার ডেটার সাথে কথোপকথন শুরু করতে একটি প্রশ্ন লিখুন। বাম সাইডবার আপনার সুবিধার জন্য উদাহরণ প্রশ্নের একটি পরিসীমা অফার করে. নিম্নলিখিত স্ক্রিনশটগুলি একটি প্রশ্ন ইনপুট করার সময় FM দ্বারা জেনারেট করা প্রতিক্রিয়া এবং পাইথন কোডকে চিত্রিত করে যেমন "আমাকে যথাক্রমে সতর্কতা বা অ্যালার্ম হিসাবে দেখানো প্রতিটি সাইটের জন্য সেন্সরের অনন্য সংখ্যা বলুন?" (একটি হার্ড-লেভেল প্রশ্ন) বা "সেন্সরগুলির জন্য তাপমাত্রা সংকেত স্বাস্থ্যকর নয় হিসাবে দেখানো হয়েছে, আপনি কি অস্বাভাবিক কম্পন সংকেত দেখানো প্রতিটি সেন্সরের জন্য দিনের মধ্যে সময়কাল গণনা করতে পারেন?" (একটি চ্যালেঞ্জ-স্তরের প্রশ্ন)। অ্যাপটি আপনার প্রশ্নের উত্তর দেবে এবং এই ধরনের ফলাফল তৈরি করার জন্য এটি করা ডেটা বিশ্লেষণের পাইথন স্ক্রিপ্টও দেখাবে।


আপনি উত্তর দিয়ে সন্তুষ্ট হলে, আপনি এটি হিসাবে চিহ্নিত করতে পারেন সহায়ক, NLQ এবং Claude-উত্পন্ন পাইথন কোড একটি OpenSearch Service সূচকে সংরক্ষণ করা হচ্ছে।

ব্যবহার কেস 2 অন্বেষণ
দ্বিতীয় ব্যবহারের ক্ষেত্রে অন্বেষণ করতে, নির্বাচন করুন ক্যাপচার করা ছবির সারাংশ স্ট্রিমলিট অ্যাপে ট্যাব। আপনি আপনার শিল্প সম্পদের একটি ছবি আপলোড করতে পারেন, এবং অ্যাপ্লিকেশনটি ছবির তথ্যের উপর ভিত্তি করে এর প্রযুক্তিগত স্পেসিফিকেশন এবং অপারেশন অবস্থার 200-শব্দের সারাংশ তৈরি করবে। নীচের স্ক্রিনশটটি একটি বেল্ট মোটর ড্রাইভের একটি চিত্র থেকে উত্পন্ন সারাংশ দেখায়। এই বৈশিষ্ট্যটি পরীক্ষা করার জন্য, আপনার যদি উপযুক্ত চিত্রের অভাব থাকে তবে আপনি নিম্নলিখিতটি ব্যবহার করতে পারেন উদাহরণ চিত্র.
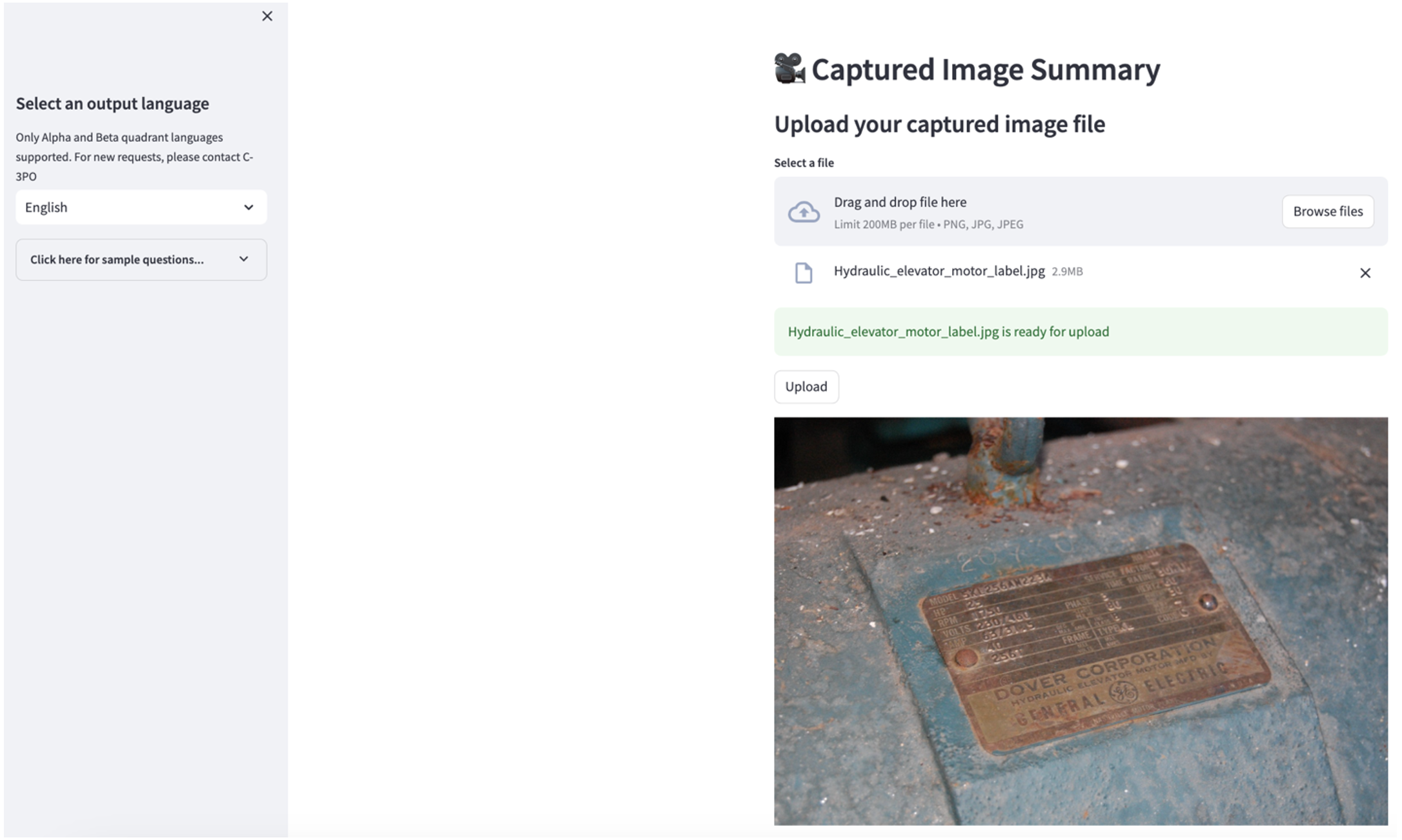
হাইড্রোলিক লিফট মোটর লেবেলক্লারেন্স Risher দ্বারা লাইসেন্স করা হয় অধীনে সিসি বাই-এসএ 2.0.

ব্যবহার কেস 3 অন্বেষণ
তৃতীয় ব্যবহারের ক্ষেত্রে অন্বেষণ করতে, নির্বাচন করুন মূল কারণ নির্ণয় ট্যাব আপনার ভাঙা শিল্প সম্পদ সম্পর্কিত একটি প্রশ্ন ইনপুট করুন, যেমন, "আমার অ্যাকচুয়েটর ধীর গতিতে ভ্রমণ করে, সমস্যা কী হতে পারে?" নিম্নলিখিত স্ক্রিনশটে চিত্রিত হিসাবে, অ্যাপ্লিকেশনটি উত্তর তৈরি করতে ব্যবহৃত উত্স নথির অংশের সাথে একটি প্রতিক্রিয়া সরবরাহ করে।

কেস 1 ব্যবহার করুন: ডিজাইনের বিশদ বিবরণ
এই বিভাগে, আমরা প্রথম ব্যবহারের ক্ষেত্রে অ্যাপ্লিকেশন কর্মপ্রবাহের নকশার বিবরণ নিয়ে আলোচনা করি।
কাস্টম প্রম্পট বিল্ডিং
ব্যবহারকারীর স্বাভাবিক ভাষা প্রশ্ন বিভিন্ন কঠিন স্তরের সাথে আসে: সহজ, কঠিন এবং চ্যালেঞ্জ।
সহজবোধ্য প্রশ্নে নিম্নলিখিত অনুরোধগুলি অন্তর্ভুক্ত থাকতে পারে:
- অনন্য মান নির্বাচন করুন
- মোট সংখ্যা গণনা
- মান সাজান
এই প্রশ্নগুলির জন্য, PandasAI প্রক্রিয়াকরণের জন্য পাইথন স্ক্রিপ্ট তৈরি করতে সরাসরি FM-এর সাথে যোগাযোগ করতে পারে।
কঠিন প্রশ্নগুলির জন্য মৌলিক একত্রীকরণ অপারেশন বা টাইম সিরিজ বিশ্লেষণ প্রয়োজন, যেমন নিম্নলিখিত:
- প্রথমে মান নির্বাচন করুন এবং শ্রেণিবদ্ধভাবে ফলাফলগুলিকে গোষ্ঠীভুক্ত করুন
- প্রাথমিক রেকর্ড নির্বাচনের পর পরিসংখ্যান সম্পাদন করুন
- টাইমস্ট্যাম্প গণনা (উদাহরণস্বরূপ, সর্বনিম্ন এবং সর্বোচ্চ)
কঠিন প্রশ্নের জন্য, বিস্তারিত ধাপে ধাপে নির্দেশাবলী সহ একটি প্রম্পট টেমপ্লেট FM-কে সঠিক প্রতিক্রিয়া প্রদানে সহায়তা করে।
চ্যালেঞ্জ-স্তরের প্রশ্নগুলির জন্য উন্নত গণিত গণনা এবং সময় সিরিজ প্রক্রিয়াকরণ প্রয়োজন, যেমন নিম্নলিখিত:
- প্রতিটি সেন্সরের জন্য অসঙ্গতি সময়কাল গণনা করুন
- মাসিক ভিত্তিতে সাইটের জন্য অসঙ্গতি সেন্সর গণনা করুন
- স্বাভাবিক অপারেশন এবং অস্বাভাবিক অবস্থার অধীনে সেন্সর রিডিং তুলনা করুন
এই প্রশ্নগুলির জন্য, আপনি প্রতিক্রিয়া নির্ভুলতা উন্নত করতে একটি কাস্টম প্রম্পটে মাল্টি-শট ব্যবহার করতে পারেন। এই ধরনের মাল্টি-শটগুলি উন্নত টাইম সিরিজ প্রক্রিয়াকরণ এবং গণিত গণনার উদাহরণ দেখায় এবং অনুরূপ বিশ্লেষণে প্রাসঙ্গিক অনুমান সঞ্চালনের জন্য FM-এর জন্য প্রসঙ্গ প্রদান করবে। গতিশীলভাবে একটি NLQ প্রশ্ন ব্যাঙ্ক থেকে প্রম্পটে সবচেয়ে প্রাসঙ্গিক উদাহরণ সন্নিবেশ করানো একটি চ্যালেঞ্জ হতে পারে। একটি সমাধান হল বিদ্যমান NLQ প্রশ্নের নমুনাগুলি থেকে এম্বেডিং তৈরি করা এবং এই এম্বেডিংগুলিকে OpenSearch Service এর মতো একটি ভেক্টর স্টোরে সংরক্ষণ করা। যখন একটি প্রশ্ন Streamlit অ্যাপে পাঠানো হয়, তখন প্রশ্নটি ভেক্টরাইজ করা হবে বেডরক এমবেডিংস. যে প্রশ্নে শীর্ষ এন সবচেয়ে প্রাসঙ্গিক এম্বেডিংগুলি ব্যবহার করে পুনরুদ্ধার করা হয়েছে৷ opensearch_vector_search.similarity_search এবং একটি মাল্টি-শট প্রম্পট হিসাবে প্রম্পট টেমপ্লেটে ঢোকানো হয়েছে।
নিম্নলিখিত চিত্রটি এই কর্মপ্রবাহকে চিত্রিত করে।

এমবেডিং স্তরটি তিনটি মূল সরঞ্জাম ব্যবহার করে নির্মিত হয়:
- এমবেডিং মডেল - আমরা অ্যামাজন বেডরকের মাধ্যমে উপলব্ধ অ্যামাজন টাইটান এম্বেডিং ব্যবহার করি (amazon.titan-এম্বেড-টেক্সট-v1) পাঠ্য নথির সংখ্যাসূচক উপস্থাপনা তৈরি করতে।
- ভেক্টর স্টোর – আমাদের ভেক্টর স্টোরের জন্য, আমরা ল্যাংচেইন ফ্রেমওয়ার্কের মাধ্যমে OpenSearch পরিষেবা ব্যবহার করি, এই নোটবুকের NLQ উদাহরণ থেকে জেনারেট করা এম্বেডিংয়ের স্টোরেজকে স্ট্রিমলাইন করে।
- সূচক – ওপেনসার্চ সার্ভিস ইনডেক্স ইনপুট এম্বেডিংকে ডকুমেন্ট এম্বেডিংয়ের সাথে তুলনা করতে এবং প্রাসঙ্গিক নথি পুনরুদ্ধারের সুবিধার্থে একটি গুরুত্বপূর্ণ ভূমিকা পালন করে। যেহেতু পাইথন উদাহরণ কোডগুলি একটি JSON ফাইল হিসাবে সংরক্ষিত হয়েছিল, সেগুলিকে ওপেনসার্চ পরিষেবাতে ভেক্টর হিসাবে সূচিত করা হয়েছিল OpenSearchVevtorSearch.fromtexts API কল।
স্ট্রিমলিটের মাধ্যমে মানব-নিরীক্ষিত উদাহরণগুলির ক্রমাগত সংগ্রহ
অ্যাপ ডেভেলপমেন্টের শুরুতে, আমরা এম্বেডিং হিসাবে OpenSearch Service সূচকে শুধুমাত্র 23টি সংরক্ষিত উদাহরণ দিয়ে শুরু করেছি। অ্যাপটি মাঠে লাইভ হওয়ার সাথে সাথে ব্যবহারকারীরা অ্যাপের মাধ্যমে তাদের NLQs ইনপুট করা শুরু করে। যাইহোক, টেমপ্লেটে উপলব্ধ সীমিত উদাহরণগুলির কারণে, কিছু NLQ অনুরূপ প্রম্পট খুঁজে নাও পেতে পারে। এই এমবেডিংগুলিকে ক্রমাগত সমৃদ্ধ করতে এবং আরও প্রাসঙ্গিক ব্যবহারকারীর প্রম্পট অফার করতে, আপনি মানব-নিরীক্ষিত উদাহরণ সংগ্রহের জন্য Streamlit অ্যাপ ব্যবহার করতে পারেন।
অ্যাপের মধ্যে, নিম্নলিখিত ফাংশনটি এই উদ্দেশ্যে কাজ করে। যখন শেষ-ব্যবহারকারীরা আউটপুটকে সহায়ক মনে করে এবং নির্বাচন করে সহায়ক, অ্যাপ্লিকেশন এই পদক্ষেপগুলি অনুসরণ করে:
- Python স্ক্রিপ্ট সংগ্রহ করতে PandasAI থেকে কলব্যাক পদ্ধতি ব্যবহার করুন।
- Python স্ক্রিপ্ট, ইনপুট প্রশ্ন, এবং CSV মেটাডেটা একটি স্ট্রিং-এ রিফর্ম্যাট করুন।
- এই NLQ উদাহরণটি ব্যবহার করে বর্তমান OpenSearch পরিষেবা সূচকে ইতিমধ্যেই বিদ্যমান কিনা তা পরীক্ষা করুন opensearch_vector_search.similarity_search_with_score.
- যদি কোন অনুরূপ উদাহরণ না থাকে, এই NLQ ব্যবহার করে OpenSearch পরিষেবা সূচকে যোগ করা হয় opensearch_vector_search.add_texts.
ইভেন্ট যে একটি ব্যবহারকারী নির্বাচন সহায়ক নয়, কোনো ব্যবস্থা নেওয়া হয় না। এই পুনরাবৃত্ত প্রক্রিয়াটি নিশ্চিত করে যে ব্যবহারকারীর অবদানের উদাহরণগুলি অন্তর্ভুক্ত করে সিস্টেমটি ক্রমাগত উন্নতি করে।
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str = ''
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results[0][1])<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
হিউম্যান অডিটিং অন্তর্ভুক্ত করার মাধ্যমে, প্রম্পট এম্বেডিংয়ের জন্য উপলব্ধ ওপেনসার্চ পরিষেবাতে উদাহরণের পরিমাণ অ্যাপের ব্যবহার বাড়ার সাথে সাথে বৃদ্ধি পায়। এই বর্ধিত এমবেডিং ডেটাসেটের ফলে সময়ের সাথে সাথে সার্চের সঠিকতা বৃদ্ধি পায়। বিশেষভাবে, চ্যালেঞ্জিং NLQ-এর জন্য, প্রতিটি NLQ প্রশ্নের জন্য কাস্টম প্রম্পট তৈরি করতে গতিশীলভাবে অনুরূপ উদাহরণ সন্নিবেশ করার সময় FM-এর প্রতিক্রিয়া নির্ভুলতা প্রায় 90% পর্যন্ত পৌঁছে যায়। মাল্টি-শট প্রম্পট ছাড়াই পরিস্থিতির তুলনায় এটি একটি উল্লেখযোগ্য 28% বৃদ্ধির প্রতিনিধিত্ব করে।
কেস 2 ব্যবহার করুন: ডিজাইনের বিশদ বিবরণ
স্ট্রিমলিট অ্যাপে ক্যাপচার করা ছবির সারাংশ ট্যাব, আপনি সরাসরি একটি ইমেজ ফাইল আপলোড করতে পারেন। এটি Amazon Recognition API (ডিটেক্ট_টেক্সট API), ইমেজ লেবেল থেকে মেশিনের স্পেসিফিকেশনের বিবরণ দিয়ে টেক্সট বের করা। পরবর্তীকালে, এক্সট্রাক্ট করা টেক্সট ডেটা অ্যামাজন বেডরক ক্লড মডেলে প্রম্পটের প্রেক্ষাপট হিসেবে পাঠানো হয়, যার ফলে 200-শব্দের সারাংশ পাওয়া যায়।
ব্যবহারকারীর অভিজ্ঞতার দৃষ্টিকোণ থেকে, একটি পাঠ্য সংক্ষিপ্তকরণ কাজের জন্য স্ট্রিমিং কার্যকারিতা সক্ষম করা সর্বাপেক্ষা গুরুত্বপূর্ণ, ব্যবহারকারীদের সম্পূর্ণ আউটপুটের জন্য অপেক্ষা না করে ছোট অংশে FM-উত্পন্ন সারাংশ পড়তে দেয়। আমাজন বেডরক তার API এর মাধ্যমে স্ট্রিমিং এর সুবিধা দেয় (bedrock_runtime.invoke_model_with_response_stream).
কেস 3 ব্যবহার করুন: ডিজাইনের বিশদ বিবরণ
এই পরিস্থিতিতে, আমরা RAG পদ্ধতি ব্যবহার করে মূল কারণ বিশ্লেষণের উপর দৃষ্টি নিবদ্ধ করে একটি চ্যাটবট অ্যাপ্লিকেশন তৈরি করেছি। এই চ্যাটবট মূল কারণ বিশ্লেষণের সুবিধার্থে ভারবহন সরঞ্জাম সম্পর্কিত একাধিক নথি থেকে আঁকে। এই RAG-ভিত্তিক মূল কারণ বিশ্লেষণ চ্যাটবট ভেক্টর টেক্সট উপস্থাপনা বা এমবেডিং তৈরি করার জন্য জ্ঞানের ভিত্তি ব্যবহার করে। Amazon Bedrock-এর জন্য নলেজ বেস হল একটি সম্পূর্ণরূপে পরিচালিত ক্ষমতা যা আপনাকে সম্পূর্ণ RAG কার্যপ্রবাহ বাস্তবায়ন করতে সাহায্য করে, ইনজেশন থেকে পুনরুদ্ধার এবং প্রম্পট অগমেন্টেশন পর্যন্ত, ডেটা উত্সগুলিতে কাস্টম ইন্টিগ্রেশন তৈরি না করে বা ডেটা প্রবাহ এবং RAG বাস্তবায়নের বিবরণ পরিচালনা না করেই৷
আপনি যখন অ্যামাজন বেডরক থেকে জ্ঞানের ভিত্তি প্রতিক্রিয়া নিয়ে সন্তুষ্ট হন, তখন আপনি জ্ঞানের ভিত্তি থেকে স্ট্রিমলিট অ্যাপে মূল কারণ প্রতিক্রিয়া সংহত করতে পারেন।
পরিষ্কার কর
খরচ বাঁচাতে, আপনি এই পোস্টে তৈরি সংস্থানগুলি মুছুন:
- অ্যামাজন বেডরক থেকে জ্ঞানের ভিত্তি মুছুন।
- OpenSearch Service সূচক মুছুন।
- genai-sagemaker CloudFormation স্ট্যাক মুছুন।
- আপনি যদি Streamlit অ্যাপ চালানোর জন্য EC2 ইন্সট্যান্স ব্যবহার করেন তাহলে EC2 ইন্সট্যান্স বন্ধ করুন।
উপসংহার
জেনারেটিভ এআই অ্যাপ্লিকেশনগুলি ইতিমধ্যেই বিভিন্ন ব্যবসায়িক প্রক্রিয়াকে রূপান্তরিত করেছে, কর্মীদের উৎপাদনশীলতা এবং দক্ষতা বৃদ্ধি করেছে। যাইহোক, সময় সিরিজের ডেটা বিশ্লেষণ পরিচালনার ক্ষেত্রে FM-এর সীমাবদ্ধতা শিল্প গ্রাহকদের দ্বারা তাদের সম্পূর্ণ ব্যবহারকে বাধাগ্রস্ত করেছে। এই সীমাবদ্ধতা দৈনিক প্রক্রিয়াকৃত প্রধান ডেটা টাইপের জন্য জেনারেটিভ এআই-এর প্রয়োগকে বাধাগ্রস্ত করেছে।
এই পোস্টে, আমরা শিল্প ব্যবহারকারীদের জন্য এই চ্যালেঞ্জ উপশম করার জন্য ডিজাইন করা একটি জেনারেটিভ AI অ্যাপ্লিকেশন সমাধান উপস্থাপন করেছি। এই অ্যাপ্লিকেশনটি একটি ওপেন সোর্স এজেন্ট, PandasAI ব্যবহার করে, একটি FM এর টাইম সিরিজ বিশ্লেষণ ক্ষমতাকে শক্তিশালী করতে। সরাসরি FM-এ টাইম সিরিজ ডেটা পাঠানোর পরিবর্তে, অ্যাপটি পান্ডাসআই-কে নিযুক্ত করে অসংগঠিত টাইম সিরিজ ডেটা বিশ্লেষণের জন্য পাইথন কোড তৈরি করতে। পাইথন কোড জেনারেশনের নির্ভুলতা বাড়ানোর জন্য, মানুষের অডিটিং সহ একটি কাস্টম প্রম্পট জেনারেশন ওয়ার্কফ্লো প্রয়োগ করা হয়েছে।
তাদের সম্পদের স্বাস্থ্য সম্পর্কে অন্তর্দৃষ্টি দিয়ে ক্ষমতায়িত, শিল্পকর্মীরা মূল কারণ নির্ণয় এবং অংশ প্রতিস্থাপন পরিকল্পনা সহ বিভিন্ন ব্যবহারের ক্ষেত্রে জেনারেটিভ এআই-এর সম্ভাবনাকে পুরোপুরি কাজে লাগাতে পারে। অ্যামাজন বেডরকের জন্য জ্ঞানের ভিত্তি সহ, RAG সমাধানটি বিকাশকারীদের জন্য তৈরি এবং পরিচালনা করার জন্য সহজ।
এন্টারপ্রাইজ ডেটা ম্যানেজমেন্ট এবং অপারেশনের গতিপথ কার্যক্ষম স্বাস্থ্যের ব্যাপক অন্তর্দৃষ্টির জন্য জেনারেটিভ এআই-এর সাথে গভীর একীকরণের দিকে নিঃসন্দেহে এগিয়ে চলেছে। অ্যামাজন বেডরকের নেতৃত্বে এই পরিবর্তনটি এলএলএম-এর মতো ক্রমবর্ধমান দৃঢ়তা এবং সম্ভাবনার দ্বারা উল্লেখযোগ্যভাবে প্রসারিত হয়েছে আমাজন বেডরক ক্লড 3 সমাধান আরও উন্নত করতে। আরও জানতে, পরামর্শ দেখুন আমাজন বেডরক ডকুমেন্টেশন, এবং সঙ্গে হাত পেতে আমাজন বেডরক ওয়ার্কশপ.
লেখক সম্পর্কে
 জুলিয়া হু আমাজন ওয়েব সার্ভিসেসের একজন সিনিয়র এআই/এমএল সলিউশন আর্কিটেক্ট। তিনি জেনারেটিভ এআই, অ্যাপ্লাইড ডেটা সায়েন্স এবং আইওটি আর্কিটেকচারে বিশেষজ্ঞ। বর্তমানে তিনি Amazon Q দলের অংশ, এবং মেশিন লার্নিং টেকনিক্যাল ফিল্ড কমিউনিটির একজন সক্রিয় সদস্য/পরামর্শদাতা। তিনি AWSome জেনারেটিভ এআই সমাধান বিকাশের জন্য স্টার্ট-আপ থেকে শুরু করে এন্টারপ্রাইজ পর্যন্ত গ্রাহকদের সাথে কাজ করেন। তিনি বিশেষভাবে উন্নত ডেটা অ্যানালিটিক্সের জন্য বড় ল্যাঙ্গুয়েজ মডেলের ব্যবহার এবং বাস্তব-বিশ্বের চ্যালেঞ্জ মোকাবেলা করে এমন ব্যবহারিক অ্যাপ্লিকেশনগুলি অন্বেষণ করার বিষয়ে বিশেষভাবে উত্সাহী৷
জুলিয়া হু আমাজন ওয়েব সার্ভিসেসের একজন সিনিয়র এআই/এমএল সলিউশন আর্কিটেক্ট। তিনি জেনারেটিভ এআই, অ্যাপ্লাইড ডেটা সায়েন্স এবং আইওটি আর্কিটেকচারে বিশেষজ্ঞ। বর্তমানে তিনি Amazon Q দলের অংশ, এবং মেশিন লার্নিং টেকনিক্যাল ফিল্ড কমিউনিটির একজন সক্রিয় সদস্য/পরামর্শদাতা। তিনি AWSome জেনারেটিভ এআই সমাধান বিকাশের জন্য স্টার্ট-আপ থেকে শুরু করে এন্টারপ্রাইজ পর্যন্ত গ্রাহকদের সাথে কাজ করেন। তিনি বিশেষভাবে উন্নত ডেটা অ্যানালিটিক্সের জন্য বড় ল্যাঙ্গুয়েজ মডেলের ব্যবহার এবং বাস্তব-বিশ্বের চ্যালেঞ্জ মোকাবেলা করে এমন ব্যবহারিক অ্যাপ্লিকেশনগুলি অন্বেষণ করার বিষয়ে বিশেষভাবে উত্সাহী৷
 সুদেশ শশীধরন এনার্জি দলের মধ্যে AWS-এর একজন সিনিয়র সলিউশন আর্কিটেক্ট। সুদেশ নতুন প্রযুক্তি নিয়ে পরীক্ষা-নিরীক্ষা করতে এবং জটিল ব্যবসায়িক চ্যালেঞ্জের সমাধান করে এমন উদ্ভাবনী সমাধান তৈরি করতে পছন্দ করে। তিনি যখন সমাধান ডিজাইন করছেন না বা অত্যাধুনিক প্রযুক্তির সাথে টেঙ্কারিং করছেন না, তখন আপনি তাকে টেনিস কোর্টে তার ব্যাকহ্যান্ডে কাজ করে দেখতে পাবেন।
সুদেশ শশীধরন এনার্জি দলের মধ্যে AWS-এর একজন সিনিয়র সলিউশন আর্কিটেক্ট। সুদেশ নতুন প্রযুক্তি নিয়ে পরীক্ষা-নিরীক্ষা করতে এবং জটিল ব্যবসায়িক চ্যালেঞ্জের সমাধান করে এমন উদ্ভাবনী সমাধান তৈরি করতে পছন্দ করে। তিনি যখন সমাধান ডিজাইন করছেন না বা অত্যাধুনিক প্রযুক্তির সাথে টেঙ্কারিং করছেন না, তখন আপনি তাকে টেনিস কোর্টে তার ব্যাকহ্যান্ডে কাজ করে দেখতে পাবেন।
 নীল দেশাই কৃত্রিম বুদ্ধিমত্তা (AI), ডেটা সায়েন্স, সফ্টওয়্যার ইঞ্জিনিয়ারিং এবং এন্টারপ্রাইজ আর্কিটেকচারে 20 বছরের বেশি অভিজ্ঞতা সহ একজন প্রযুক্তি নির্বাহী। AWS-এ, তিনি বিশ্বব্যাপী AI পরিষেবার বিশেষজ্ঞ সমাধান আর্কিটেক্টদের একটি দলের নেতৃত্ব দেন যারা গ্রাহকদের উদ্ভাবনী জেনারেটিভ এআই-চালিত সমাধান তৈরি করতে, গ্রাহকদের সাথে সেরা অনুশীলনগুলি ভাগ করতে এবং পণ্যের রোডম্যাপ চালাতে সহায়তা করে। ভেস্তাস, হানিওয়েল এবং কোয়েস্ট ডায়াগনস্টিকসে তার আগের ভূমিকাগুলিতে, নিল উদ্ভাবনী পণ্য এবং পরিষেবাগুলি বিকাশ এবং চালু করার ক্ষেত্রে নেতৃত্বের ভূমিকা পালন করেছে যা কোম্পানিগুলিকে তাদের ক্রিয়াকলাপগুলিকে উন্নত করতে, খরচ কমাতে এবং আয় বাড়াতে সাহায্য করেছে৷ তিনি বাস্তব-বিশ্বের সমস্যা সমাধানের জন্য প্রযুক্তি ব্যবহার করার বিষয়ে উত্সাহী এবং সাফল্যের প্রমাণিত ট্র্যাক রেকর্ডের সাথে একজন কৌশলগত চিন্তাবিদ।
নীল দেশাই কৃত্রিম বুদ্ধিমত্তা (AI), ডেটা সায়েন্স, সফ্টওয়্যার ইঞ্জিনিয়ারিং এবং এন্টারপ্রাইজ আর্কিটেকচারে 20 বছরের বেশি অভিজ্ঞতা সহ একজন প্রযুক্তি নির্বাহী। AWS-এ, তিনি বিশ্বব্যাপী AI পরিষেবার বিশেষজ্ঞ সমাধান আর্কিটেক্টদের একটি দলের নেতৃত্ব দেন যারা গ্রাহকদের উদ্ভাবনী জেনারেটিভ এআই-চালিত সমাধান তৈরি করতে, গ্রাহকদের সাথে সেরা অনুশীলনগুলি ভাগ করতে এবং পণ্যের রোডম্যাপ চালাতে সহায়তা করে। ভেস্তাস, হানিওয়েল এবং কোয়েস্ট ডায়াগনস্টিকসে তার আগের ভূমিকাগুলিতে, নিল উদ্ভাবনী পণ্য এবং পরিষেবাগুলি বিকাশ এবং চালু করার ক্ষেত্রে নেতৃত্বের ভূমিকা পালন করেছে যা কোম্পানিগুলিকে তাদের ক্রিয়াকলাপগুলিকে উন্নত করতে, খরচ কমাতে এবং আয় বাড়াতে সাহায্য করেছে৷ তিনি বাস্তব-বিশ্বের সমস্যা সমাধানের জন্য প্রযুক্তি ব্যবহার করার বিষয়ে উত্সাহী এবং সাফল্যের প্রমাণিত ট্র্যাক রেকর্ডের সাথে একজন কৌশলগত চিন্তাবিদ।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- PlatoData.Network উল্লম্ব জেনারেটিভ Ai. নিজেকে ক্ষমতায়িত করুন। এখানে প্রবেশ করুন.
- প্লেটোএআইস্ট্রিম। Web3 ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- প্লেটোইএসজি। কার্বন, ক্লিনটেক, শক্তি, পরিবেশ সৌর, বর্জ্য ব্যবস্থাপনা. এখানে প্রবেশ করুন.
- প্লেটো হেলথ। বায়োটেক এবং ক্লিনিক্যাল ট্রায়াল ইন্টেলিজেন্স। এখানে প্রবেশ করুন.
- উত্স: https://aws.amazon.com/blogs/machine-learning/unlock-the-potential-of-generative-ai-in-industrial-operations/

