জানুয়ারী 2024 তে, আমাজন সেজমেকার একটি নতুন সংস্করণ চালু করেছে (0.26.0) লার্জ মডেল ইনফারেন্স (LMI) ডিপ লার্নিং কন্টেইনার (DLCs)। এই সংস্করণটি নতুন মডেলের (বিশেষজ্ঞদের মিশ্রণ সহ), অনুমান ব্যাকএন্ড জুড়ে কর্মক্ষমতা এবং ব্যবহারযোগ্যতার উন্নতি, সেইসাথে বর্ধিত নিয়ন্ত্রণ এবং পূর্বাভাস ব্যাখ্যাযোগ্যতার জন্য নতুন প্রজন্মের বিশদ (যেমন প্রজন্মের সমাপ্তির কারণ এবং টোকেন স্তর লগ সম্ভাব্যতা) জন্য সমর্থন সরবরাহ করে।
LMI DLCs একটি কম-কোড ইন্টারফেস অফার করে যা অত্যাধুনিক ইনফারেন্স অপ্টিমাইজেশান কৌশল এবং হার্ডওয়্যার ব্যবহার করে সহজ করে। LMI আপনাকে টেনসর সমান্তরালতা প্রয়োগ করতে দেয়; সর্বশেষ দক্ষ মনোযোগ, ব্যাচিং, কোয়ান্টাইজেশন, এবং মেমরি ব্যবস্থাপনা কৌশল; টোকেন স্ট্রিমিং; এবং আরও অনেক কিছু, শুধুমাত্র মডেল আইডি এবং ঐচ্ছিক মডেল পরামিতি প্রয়োজন দ্বারা। SageMaker-এ LMI DLC-এর সাহায্যে আপনি আপনার জন্য সময়-টু-মূল্য ত্বরান্বিত করতে পারেন জেনারেটিভ কৃত্রিম বুদ্ধিমত্তা (AI) অ্যাপ্লিকেশন, অফলোড অবকাঠামো-সম্পর্কিত ভারী উত্তোলন, এবং সর্বোত্তম-শ্রেণীর মূল্য-কর্মক্ষমতা অর্জনের জন্য আপনার পছন্দের হার্ডওয়্যারের জন্য বড় ভাষা মডেল (LLM) অপ্টিমাইজ করুন।
এই পোস্টে, আমরা এই রিলিজে প্রবর্তিত সর্বশেষ বৈশিষ্ট্যগুলি অন্বেষণ করি, পারফরম্যান্সের বেঞ্চমার্কগুলি পরীক্ষা করি এবং উচ্চ কার্যসম্পাদনে LMI DLC সহ নতুন LLM গুলি মোতায়েন করার বিষয়ে একটি বিশদ নির্দেশিকা প্রদান করি৷
LMI DLC সহ নতুন বৈশিষ্ট্য
এই বিভাগে, আমরা LMI ব্যাকএন্ড জুড়ে নতুন বৈশিষ্ট্যগুলি নিয়ে আলোচনা করি এবং ব্যাকএন্ড-নির্দিষ্ট কিছু অন্যের উপর ড্রিল ডাউন করি। LMI বর্তমানে নিম্নলিখিত ব্যাকএন্ড সমর্থন করে:
- LMI- বিতরণ করা লাইব্রেরি - ফলাফলের সর্বোত্তম সম্ভাব্য বিলম্ব এবং নির্ভুলতা অর্জনের জন্য ওএসএস থেকে অনুপ্রাণিত LLM-এর সাথে অনুমান চালানোর জন্য এটি AWS কাঠামো
- এলএমআই ভিএলএলএম - এটি মেমরি-দক্ষ এর AWS ব্যাকএন্ড বাস্তবায়ন ভিএলএলএম অনুমান লাইব্রেরি
- LMI TensorRT-LLM টুলকিট - এটি হল AWS ব্যাকএন্ড বাস্তবায়ন NVIDIA TensorRT-LLM, যা বিভিন্ন GPU-তে কর্মক্ষমতা অপ্টিমাইজ করতে GPU-নির্দিষ্ট ইঞ্জিন তৈরি করে
- এলএমআই ডিপস্পিড - এটি AWS এর অভিযোজন ডিপস্পিড, যা সত্য ক্রমাগত ব্যাচিং, স্মুথকোয়ান্ট কোয়ান্টাইজেশন এবং অনুমানের সময় মেমরিকে গতিশীলভাবে সামঞ্জস্য করার ক্ষমতা যোগ করে
- এলএমআই নিউরনএক্স - আপনি এটি স্থাপনের জন্য ব্যবহার করতে পারেন AWS Inferentia2 এবং এডব্লিউএস ট্রেনিয়াম-ভিত্তিক দৃষ্টান্ত, এর উপর ভিত্তি করে সত্য ক্রমাগত ব্যাচিং এবং স্পিডআপ সমন্বিত AWS নিউরন SDK
নিম্নলিখিত সারণীতে নতুন যোগ করা বৈশিষ্ট্যগুলিকে সংক্ষিপ্ত করা হয়েছে, উভয় সাধারণ এবং ব্যাকএন্ড-নির্দিষ্ট।
|
ব্যাকএন্ড জুড়ে সাধারণ |
|||
|
|||
|
ব্যাকএন্ড নির্দিষ্ট |
|||
|
LMI- বিতরণ করা হয়েছে |
ভিএলএলএম | টেনসরআরটি-এলএলএম |
নিউরনএক্স |
|
|
|
|
নতুন মডেল সমর্থিত
নতুন জনপ্রিয় মডেলগুলি ব্যাকএন্ড জুড়ে সমর্থিত, যেমন Mistral-7B (সমস্ত ব্যাকএন্ড), MoE-ভিত্তিক Mixtral (Transformers-NeuronX ছাড়া সমস্ত ব্যাকএন্ড), এবং Llama2-70B (Transformers-NeuronX)।
প্রসঙ্গ উইন্ডো এক্সটেনশন কৌশল
রোটারি পজিশনাল এমবেডিং (RoPE)-ভিত্তিক প্রসঙ্গ স্কেলিং এখন LMI-Dist, vLLM, এবং TensorRT-LLM ব্যাকএন্ডে উপলব্ধ। RoPE স্কেলিং সূক্ষ্ম-টিউনিংয়ের প্রয়োজন ছাড়াই কার্যত যেকোনো আকারের অনুমানের সময় একটি মডেলের ক্রম দৈর্ঘ্যের প্রসারণকে সক্ষম করে।
RoPE ব্যবহার করার সময় নিম্নলিখিত দুটি গুরুত্বপূর্ণ বিবেচনা রয়েছে:
- মডেল বিভ্রান্তি - ক্রম দৈর্ঘ্য বাড়ার সাথে সাথে, তাই করতে পারেন মডেল এর বিভ্রান্তি. মূল প্রশিক্ষণে ব্যবহৃত ইনপুট সিকোয়েন্সের চেয়ে বড় ইনপুট ক্রমগুলিতে ন্যূনতম সূক্ষ্ম-টিউনিং পরিচালনা করে এই প্রভাবটি আংশিকভাবে অফসেট করা যেতে পারে। কিভাবে RoPE মডেলের গুণমানকে প্রভাবিত করে তার গভীরভাবে বোঝার জন্য, পড়ুন RoPE প্রসারিত করা হচ্ছে.
- অনুমান কর্মক্ষমতা - দীর্ঘ ক্রম দৈর্ঘ্য উচ্চতর এক্সিলারেটরের উচ্চ ব্যান্ডউইথ মেমরি (HBM) গ্রাস করবে। এই বর্ধিত মেমরি ব্যবহার আপনার অ্যাক্সিলারেটর পরিচালনা করতে পারে এমন একযোগে অনুরোধের সংখ্যাকে বিরূপভাবে প্রভাবিত করতে পারে।
প্রজন্মের বিবরণ যোগ করা হয়েছে
আপনি এখন প্রজন্মের ফলাফল সম্পর্কে দুটি সূক্ষ্ম বিবরণ পেতে পারেন:
- শেষ_কারণ - এটি প্রজন্মের সমাপ্তির কারণ দেয়, যা সর্বোচ্চ প্রজন্মের দৈর্ঘ্যে পৌঁছাতে পারে, একটি এন্ড-অফ-সেন্টেন্স (EOS) টোকেন তৈরি করতে পারে বা ব্যবহারকারী-সংজ্ঞায়িত স্টপ টোকেন তৈরি করতে পারে। এটি শেষ প্রবাহিত সিকোয়েন্স খণ্ডের সাথে ফেরত দেওয়া হয়।
- log_probs - এটি স্ট্রিম করা সিকোয়েন্স খণ্ডে প্রতিটি টোকেনের জন্য মডেল দ্বারা নির্ধারিত লগ সম্ভাব্যতা প্রদান করে। আপনি এগুলিকে মডেলের আস্থার মোটামুটি অনুমান হিসাবে ব্যবহার করতে পারেন একটি ক্রমটির যৌথ সম্ভাব্যতার যোগফল হিসাবে গণনা করে
log_probsপৃথক টোকেনগুলির মধ্যে, যা মডেল আউটপুটগুলি স্কোরিং এবং র্যাঙ্কিংয়ের জন্য কার্যকর হতে পারে। মনে রাখবেন যে LLM টোকেনের সম্ভাবনাগুলি সাধারণত ক্রমাঙ্কন ছাড়াই অতিরিক্ত আত্মবিশ্বাসী হয়৷
আপনি LMI তে আপনার ইনপুট পেলোডে বিবরণ=True যোগ করে জেনারেশন ফলাফলের আউটপুট সক্ষম করতে পারেন, অন্য সমস্ত প্যারামিটার অপরিবর্তিত রেখে:
payload = {“inputs”:“your prompt”,
“parameters”:{max_new_tokens”:256,...,“details”:True}
}একত্রিত কনফিগারেশন পরামিতি
অবশেষে, LMI কনফিগারেশন পরামিতিগুলিও একত্রিত করা হয়েছে। সমস্ত সাধারণ এবং ব্যাকএন্ড-নির্দিষ্ট স্থাপনার কনফিগারেশন প্যারামিটার সম্পর্কে আরও তথ্যের জন্য, দেখুন বড় মডেল ইনফারেন্স কনফিগারেশন.
LMI- বিতরণ করা ব্যাকএন্ড
AWS re:Invent 2023-এ, LMI-Dist নতুন, অপ্টিমাইজ করা যৌথ ক্রিয়াকলাপগুলিকে GPU-গুলির মধ্যে যোগাযোগের গতি বাড়ানোর জন্য যুক্ত করেছে, যার ফলে একটি একক GPU-এর জন্য খুব বড় মডেলগুলির জন্য কম লেটেন্সি এবং উচ্চতর থ্রুপুট। এই সমষ্টিগুলি শুধুমাত্র P4d উদাহরণের জন্য SageMaker-এর জন্য উপলব্ধ।
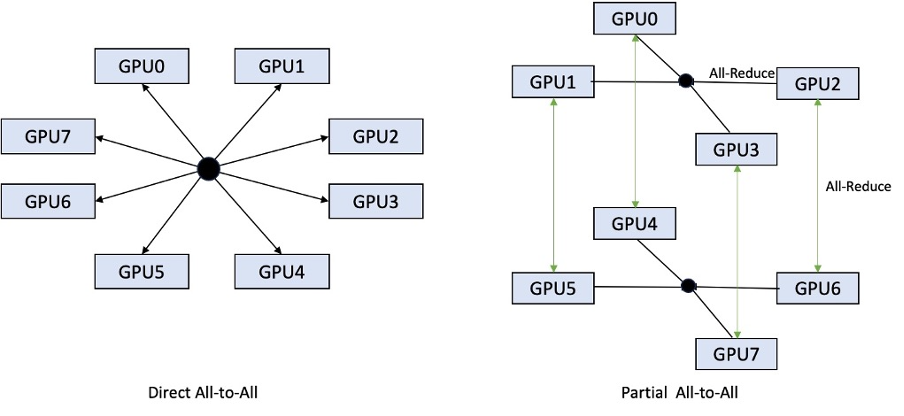
যেখানে পূর্ববর্তী পুনরাবৃত্তি শুধুমাত্র সমস্ত 8টি GPU তে শার্ডিং সমর্থন করেছিল, LMI 0.26.0 একটি আংশিক অল-টু-অল প্যাটার্নে 4 এর টেনসর সমান্তরাল ডিগ্রির জন্য সমর্থন প্রবর্তন করে। এই সঙ্গে মিলিত হতে পারে SageMaker অনুমান উপাদান, যার সাহায্যে আপনি একটি এন্ডপয়েন্টের পিছনে স্থাপন করা প্রতিটি মডেলের জন্য কতগুলি অ্যাক্সিলারেটর বরাদ্দ করা উচিত তা দানাদারভাবে কনফিগার করতে পারেন। একত্রে, এই বৈশিষ্ট্যগুলি অন্তর্নিহিত উদাহরণের সম্পদ ব্যবহারের উপর আরও ভাল নিয়ন্ত্রণ প্রদান করে, আপনাকে একটি শেষ পয়েন্টের পিছনে বিভিন্ন মডেল হোস্ট করে মডেল মাল্টি-টেনেন্সি বাড়াতে সক্ষম করে, অথবা আপনার মডেল এবং ট্র্যাফিক বৈশিষ্ট্যের সাথে মেলে আপনার স্থাপনার সামগ্রিক থ্রুপুটকে সূক্ষ্ম-টিউন করতে।
নিচের চিত্রটি আংশিক সব-থেকে-অল-এর সাথে সরাসরি অল-টু-অল-এর তুলনা করে।
TensorRT-LLM ব্যাকএন্ড
NVIDIA-এর TensorRT-LLM পূর্ববর্তী LMI DLC রিলিজ (0.25.0) এর অংশ হিসাবে চালু করা হয়েছিল, যা NVIDIA GPU ব্যবহার করার সময় অত্যাধুনিক GPU কর্মক্ষমতা এবং SmoothQuant, FP8 এর মত অপ্টিমাইজেশন এবং LLM-এর জন্য ক্রমাগত ব্যাচিং সক্ষম করে।
TensorRT-LLM এর জন্য মডেলগুলিকে স্থাপনের আগে দক্ষ ইঞ্জিনে কম্পাইল করা প্রয়োজন। LMI TensorRT-LLM DLC স্বয়ংক্রিয়ভাবে সার্ভার শুরু করার আগে এবং রিয়েল-টাইম ইনফারেন্সের জন্য মডেল লোড করার আগে সমর্থিত মডেলগুলির একটি তালিকা জাস্ট-ইন-টাইম (JIT) কম্পাইল করা পরিচালনা করতে পারে। DLC-এর সংস্করণ 0.26.0 JIT সংকলনের জন্য সমর্থিত মডেলগুলির তালিকা বৃদ্ধি করে, Baichuan, ChatGLM , GPT2, GPT-J, InternLM, Mistral, Mixtral, Qwen, SantaCoder এবং StarCoder মডেলগুলি প্রবর্তন করে৷
JIT সংকলন এন্ডপয়েন্ট প্রভিশনিং এবং স্কেলিং টাইমে ওভারহেডের কয়েক মিনিট যোগ করে, তাই আপনার মডেলকে আগে থেকে কম্পাইল করার পরামর্শ দেওয়া হয়। এটি কীভাবে করবেন তার নির্দেশিকা এবং সমর্থিত মডেলগুলির একটি তালিকার জন্য, দেখুন TensorRT-LLM মডেল টিউটোরিয়ালের আগাম সংকলন. আপনার নির্বাচিত মডেল এখনও সমর্থিত না হলে, পড়ুন TensorRT-LLM মডেল টিউটোরিয়ালের ম্যানুয়াল সংকলন TensorRT-LLM দ্বারা সমর্থিত অন্য কোনো মডেল কম্পাইল করতে।
অতিরিক্তভাবে, LMI এখন টোকেন বা চ্যানেলের মাধ্যমে আলফা এবং স্কেলিং ফ্যাক্টর নিয়ন্ত্রণ করার পরামিতি সহ স্থানীয় TensorRT-LLM SmootQuant কোয়ান্টাইজেশন প্রকাশ করে। সম্পর্কিত কনফিগারেশন সম্পর্কে আরও তথ্যের জন্য, পড়ুন টেনসরআরটি-এলএলএম.
vLLM ব্যাকএন্ড
LMI DLC-তে অন্তর্ভুক্ত vLLM-এর আপডেট করা রিলিজটিতে CUDA গ্রাফ মোডের পরিবর্তে 50% পর্যন্ত পারফরম্যান্স উন্নতির বৈশিষ্ট্য রয়েছে। CUDA গ্রাফগুলি পৃথকভাবে চালু করার পরিবর্তে এক সাথে একাধিক GPU ক্রিয়াকলাপ চালু করার মাধ্যমে GPU কাজের চাপকে ত্বরান্বিত করে, যা ওভারহেডগুলি হ্রাস করে। টেনসর সমান্তরালতা ব্যবহার করার সময় এটি ছোট মডেলের জন্য বিশেষভাবে কার্যকর।
যোগ করা কর্মক্ষমতা যোগ করা GPU মেমরি খরচ একটি ট্রেড-অফ আসে. CUDA গ্রাফ মোড এখন vLLM ব্যাকএন্ডের জন্য ডিফল্ট, তাই আপনি যদি উপলব্ধ GPU মেমরির পরিমাণে সীমাবদ্ধ থাকেন, আপনি সেট করতে পারেন option.enforce_eager=True PyTorch আগ্রহী মোড জোর করতে.
ট্রান্সফরমার-নিউরনএক্স ব্যাকএন্ড
আপডেট রিলিজ নিউরনএক্স LMI নিউরনএক্স ডিএলসি-তে অন্তর্ভুক্ত এখন এমন মডেলগুলিকে সমর্থন করে যেগুলি গ্রুপড-কোয়েরি অ্যাটেনশন মেকানিজম, যেমন Mistral-7B এবং LLama2-70B বৈশিষ্ট্যযুক্ত। দলবদ্ধ-কোয়েরি মনোযোগ হল ডিফল্ট ট্রান্সফরমার মনোযোগ প্রক্রিয়ার একটি গুরুত্বপূর্ণ অপ্টিমাইজেশান, যেখানে মডেলটিকে ক্যোয়ারী হেডের তুলনায় কম কী এবং ভ্যালু হেড দিয়ে প্রশিক্ষিত করা হয়। এটি জিপিইউ মেমরিতে কেভি ক্যাশের আকার হ্রাস করে, বৃহত্তর একত্রিত হওয়ার অনুমতি দেয় এবং মূল্য-কর্মক্ষমতা উন্নত করে।
নিম্নলিখিত চিত্রটি মাল্টি-হেড, গ্রুপড-কোয়েরি এবং মাল্টি-কোয়েরি মনোযোগের পদ্ধতিগুলিকে চিত্রিত করে (উৎস).
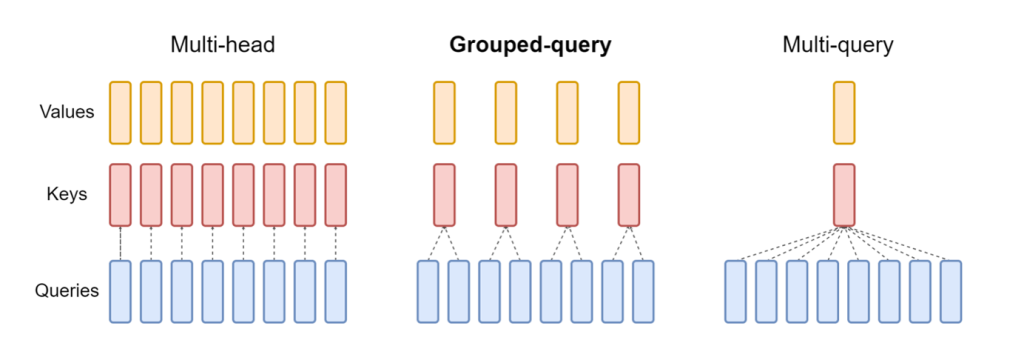
বিভিন্ন ধরনের কাজের চাপের জন্য বিভিন্ন কেভি ক্যাশে শার্ডিং কৌশল উপলব্ধ। শার্ডিং কৌশল সম্পর্কে আরও তথ্যের জন্য, দেখুন গ্রুপড-কোয়েরি অ্যাটেনশন (GQA) সমর্থন. আপনি আপনার পছন্দসই কৌশল সক্ষম করতে পারেন (shard-over-heads, উদাহরণস্বরূপ) নিম্নলিখিত কোড সহ:
অতিরিক্তভাবে, NeuronX DLC-এর নতুন বাস্তবায়ন TransformerNeuronX-এর জন্য একটি ক্যাশে API প্রবর্তন করে যা KV ক্যাশে অ্যাক্সেস সক্ষম করে। এটি আপনাকে নতুন অনুরোধ থেকে KV ক্যাশে সারিগুলি সন্নিবেশ এবং অপসারণ করার অনুমতি দেয় যখন আপনি ব্যাচ করা অনুমান হস্তান্তর করছেন। এই API প্রবর্তনের আগে, নতুন যোগ করা অনুরোধের জন্য KV ক্যাশে পুনরায় গণনা করা হয়েছিল। LMI V7 (0.25.0) এর সাথে তুলনা করে, আমরা সমসাময়িক অনুরোধের সাথে 33% এর বেশি লেটেন্সি উন্নত করেছি এবং অনেক বেশি থ্রুপুট সমর্থন করি।
ডান ব্যাকএন্ড নির্বাচন করা হচ্ছে
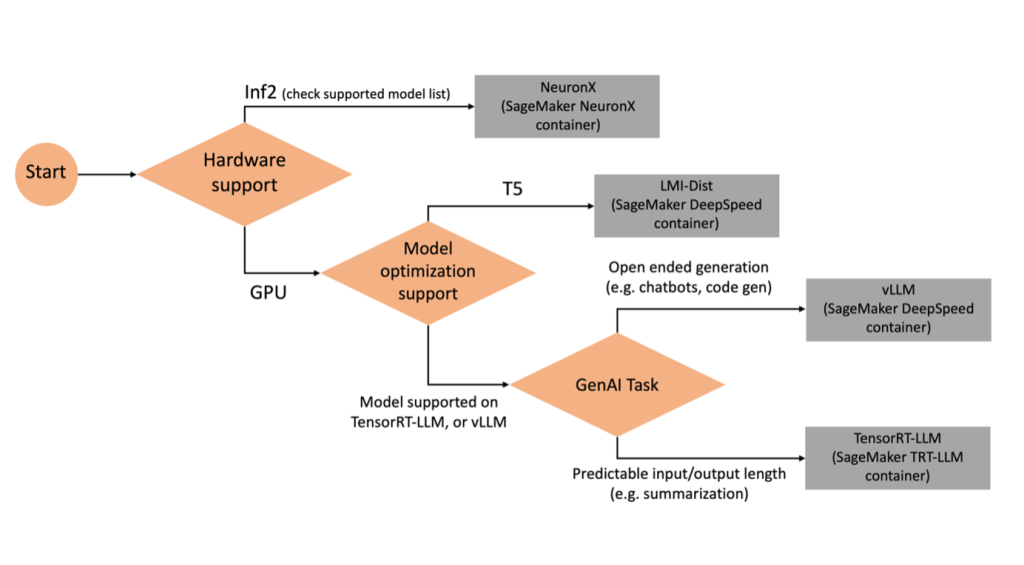
নির্বাচিত মডেল এবং টাস্কের উপর ভিত্তি করে কোন ব্যাকএন্ড ব্যবহার করবেন তা নির্ধারণ করতে, নিম্নলিখিত ফ্লো চার্টটি ব্যবহার করুন। সমর্থিত মডেল সহ পৃথক ব্যাকএন্ড ব্যবহারকারী গাইডের জন্য, দেখুন LMI ব্যাকএন্ড ব্যবহারকারীর নির্দেশিকা.
অতিরিক্ত বৈশিষ্ট্য সহ LMI DLC এর সাথে Mixtral স্থাপন করুন
আসুন জেনে নেই কিভাবে আপনি LMI 8 কন্টেইনার সহ Mixtral-7x0.26.0B মডেলটি স্থাপন করতে পারেন এবং অতিরিক্ত বিবরণ তৈরি করতে পারেন log_prob এবং finish_reason আউটপুট অংশ হিসাবে। কন্টেন্ট জেনারেশন ব্যবহারের ক্ষেত্রে আপনি কীভাবে এই অতিরিক্ত বৈশিষ্ট্যগুলি থেকে উপকৃত হতে পারেন তাও আমরা আলোচনা করি।
বিস্তারিত নির্দেশাবলী সহ সম্পূর্ণ নোটবুক পাওয়া যায় গিটহুব রেপো.
আমরা লাইব্রেরি আমদানি করে এবং সেশন পরিবেশ কনফিগার করে শুরু করি:
আপনি কোনো অতিরিক্ত অনুমান কোড ছাড়াই মডেল হোস্ট করতে SageMaker LMI পাত্রে ব্যবহার করতে পারেন। আপনি এনভায়রনমেন্ট ভেরিয়েবল বা একটি মাধ্যমে মডেল সার্ভার কনফিগার করতে পারেন serving.properties ফাইল ঐচ্ছিকভাবে, আপনি একটি থাকতে পারে model.py কোনো প্রিপ্রসেসিং বা পোস্টপ্রসেসিংয়ের জন্য ফাইল এবং ক requirements.txt ইনস্টল করা প্রয়োজন যে কোনো অতিরিক্ত প্যাকেজ জন্য ফাইল.
এই ক্ষেত্রে, আমরা ব্যবহার করি serving.properties পরামিতি কনফিগার করতে এবং LMI ধারক আচরণ কাস্টমাইজ করার জন্য ফাইল। আরো বিস্তারিত জানার জন্য, পড়ুন গিটহুব রেপো. রেপো বিভিন্ন কনফিগারেশন প্যারামিটারের বিশদ ব্যাখ্যা করে যা আপনি সেট করতে পারেন। আমাদের নিম্নলিখিত মূল পরামিতিগুলির প্রয়োজন:
- ইঞ্জিন - DJL ব্যবহারের জন্য রানটাইম ইঞ্জিন নির্দিষ্ট করে। এটি মডেলের জন্য এক্সিলারেটরে শার্ডিং এবং মডেল লোডিং কৌশল চালায়।
- option.model_id - নির্দিষ্ট করে আমাজন সিম্পল স্টোরেজ সার্ভিস (Amazon S3) প্রাক-প্রশিক্ষিত মডেলের URI বা একটি মডেল সংগ্রহস্থলের ভিতরে হোস্ট করা একটি পূর্বপ্রশিক্ষিত মডেলের মডেল ID আলিঙ্গন মুখ. এই ক্ষেত্রে, আমরা Mixtral-8x7B মডেলের মডেল আইডি প্রদান করি।
- option.tensor_parallel_degree - GPU ডিভাইসের সংখ্যা সেট করে যেগুলির উপর মডেলটিকে পার্টিশন করার জন্য Accelerate প্রয়োজন। এই প্যারামিটারটি মডেল প্রতি কর্মীদের সংখ্যা নিয়ন্ত্রণ করে যেগুলি DJL পরিবেশন চলাকালীন শুরু হবে। আমরা এই মান সেট
max(বর্তমান মেশিনে সর্বাধিক GPU)। - option.rolling_batch - এক্সিলারেটর ব্যবহার এবং সামগ্রিক থ্রুপুট অপ্টিমাইজ করতে ক্রমাগত ব্যাচিং সক্ষম করে। TensorRT-LLM কন্টেইনারের জন্য, আমরা ব্যবহার করি
auto. - option.model_loading_timeout - অনুমান পরিবেশন করার জন্য মডেলটি ডাউনলোড এবং লোড করার সময়সীমার মান সেট করে।
- option.max_rolling_batch - কোন নির্দিষ্ট সময়ে সমান্তরালভাবে কতগুলি সিকোয়েন্স প্রক্রিয়া করা যেতে পারে তা নির্ধারণ করে ক্রমাগত ব্যাচের সর্বাধিক আকার সেট করে।
আমরা প্যাকেজ serving.properties tar.gz ফরম্যাটে কনফিগারেশন ফাইল, যাতে এটি SageMaker হোস্টিং প্রয়োজনীয়তা পূরণ করে। আমরা ডিজেএল এলএমআই কন্টেইনারের সাথে কনফিগার করি tensorrtllm ব্যাকএন্ড ইঞ্জিন হিসাবে। উপরন্তু, আমরা ধারকটির সর্বশেষ সংস্করণ (0.26.0) নির্দিষ্ট করি।
এর পরে, আমরা স্থানীয় টারবল আপলোড করি (এটি রয়েছে serving.properties কনফিগারেশন ফাইল) একটি S3 উপসর্গে। SageMaker মডেল অবজেক্ট তৈরি করতে আমরা DJL কন্টেইনার এবং Amazon S3 অবস্থানের জন্য ইমেজ URI ব্যবহার করি যেখানে মডেল পরিবেশনকারী আর্টিফ্যাক্ট টারবল আপলোড করা হয়েছিল।
LMI 0.26.0 এর অংশ হিসাবে, আপনি এখন উত্পন্ন আউটপুট সম্পর্কে দুটি অতিরিক্ত সূক্ষ্ম বিবরণ ব্যবহার করতে পারেন:
- log_probs - এটি স্ট্রিম করা সিকোয়েন্স খণ্ডে প্রতিটি টোকেনের জন্য মডেল দ্বারা নির্ধারিত লগ সম্ভাবনা। আপনি পৃথক টোকেনগুলির লগ সম্ভাব্যতার যোগফল হিসাবে একটি অনুক্রমের যৌথ সম্ভাব্যতা গণনা করে মডেল আত্মবিশ্বাসের মোটামুটি অনুমান হিসাবে ব্যবহার করতে পারেন, যা মডেল আউটপুটগুলি স্কোর এবং র্যাঙ্ক করার জন্য কার্যকর হতে পারে। মনে রাখবেন যে LLM টোকেনের সম্ভাবনাগুলি সাধারণত ক্রমাঙ্কন ছাড়াই অতিরিক্ত আত্মবিশ্বাসী হয়৷
- শেষ_কারণ - এটি প্রজন্মের সমাপ্তির কারণ, যা সর্বোচ্চ প্রজন্মের দৈর্ঘ্যে পৌঁছাতে পারে, একটি EOS টোকেন তৈরি করতে পারে, বা ব্যবহারকারী-সংজ্ঞায়িত স্টপ টোকেন তৈরি করতে পারে। এটি শেষ প্রবাহিত সিকোয়েন্স খণ্ডের সাথে ফেরত দেওয়া হয়।
আপনি পাস করে এই সক্রিয় করতে পারেন "details"=True মডেলে আপনার ইনপুটের অংশ হিসাবে।
আসুন দেখি কিভাবে আপনি এই বিশদগুলি তৈরি করতে পারেন। আমরা তাদের অ্যাপ্লিকেশন বোঝার জন্য একটি বিষয়বস্তু প্রজন্মের উদাহরণ ব্যবহার করি।
আমরা একটি সংজ্ঞায়িত LineIterator হেল্পার ক্লাস, যার ফাংশন আছে অলসভাবে একটি রেসপন্স স্ট্রিম থেকে বাইট আনয়ন করে, সেগুলিকে বাফার করে এবং বাফারটিকে লাইনে ভেঙ্গে দেয়। ধারণাটি হল অ্যাসিঙ্ক্রোনাসভাবে স্ট্রীম থেকে আরও বাইট আনার সময় বাফার থেকে বাইট পরিবেশন করা।
একটি অতিরিক্ত বিবরণ হিসাবে টোকেন সম্ভাব্যতা তৈরি এবং ব্যবহার করুন
একটি ব্যবহারের ক্ষেত্রে বিবেচনা করুন যেখানে আমরা সামগ্রী তৈরি করছি। বিশেষত, জীবনধারা-কেন্দ্রিক ওয়েবসাইটের জন্য নিয়মিত ব্যায়াম করার সুবিধা সম্পর্কে একটি সংক্ষিপ্ত অনুচ্ছেদ লেখার দায়িত্ব আমাদের দেওয়া হয়েছে। আমরা বিষয়বস্তু তৈরি করতে চাই এবং উত্পন্ন সামগ্রীতে মডেলের যে আত্মবিশ্বাস রয়েছে তার কিছু সূচক স্কোর আউটপুট করতে চাই।
আমরা আমাদের প্রম্পটের সাথে মডেল এন্ডপয়েন্টকে আহ্বান করি এবং জেনারেট হওয়া প্রতিক্রিয়া ক্যাপচার করি। আমরা সেট "details": True মডেলের ইনপুটের মধ্যে রানটাইম প্যারামিটার হিসাবে। যেহেতু প্রতিটি আউটপুট টোকেনের জন্য লগ সম্ভাব্যতা তৈরি হয়, তাই আমরা একটি তালিকায় পৃথক লগ সম্ভাব্যতা যুক্ত করি। আমরা প্রতিক্রিয়া থেকে সম্পূর্ণ উত্পন্ন পাঠ্য ক্যাপচার.
সামগ্রিক আত্মবিশ্বাসের স্কোর গণনা করার জন্য, আমরা সমস্ত পৃথক টোকেন সম্ভাব্যতার গড় গণনা করি এবং পরবর্তীতে 0 এবং 1-এর মধ্যে সূচকীয় মান পাই। এটি তৈরি করা পাঠ্যের জন্য আমাদের অনুমানকৃত সামগ্রিক আত্মবিশ্বাসের স্কোর, যা এই ক্ষেত্রে সুবিধাগুলি সম্পর্কে একটি অনুচ্ছেদ। নিয়মিত ব্যায়াম করা।

আপনি কীভাবে তৈরি এবং ব্যবহার করতে পারেন তার এটি একটি উদাহরণ ছিল log_prob, একটি বিষয়বস্তু প্রজন্মের ব্যবহারের ক্ষেত্রে। একইভাবে, আপনি ব্যবহার করতে পারেন log_prob শ্রেণীবিভাগ ব্যবহারের ক্ষেত্রে আত্মবিশ্বাসের স্কোরের পরিমাপ হিসাবে।
বিকল্পভাবে, আপনি এটিকে সামগ্রিক আউটপুট ক্রম বা বাক্য-স্তরের স্কোরিংয়ের জন্য ব্যবহার করতে পারেন যাতে উৎপন্ন আউটপুটে তাপমাত্রার মতো পরামিতিগুলির প্রভাব মূল্যায়ন করা যায়।
একটি অতিরিক্ত বিবরণ হিসাবে ফিনিস কারণ তৈরি করুন এবং ব্যবহার করুন
আসুন একই ব্যবহারের ক্ষেত্রে তৈরি করা যাক, কিন্তু এবার আমাদের একটি দীর্ঘ নিবন্ধ লেখার দায়িত্ব দেওয়া হয়েছে। উপরন্তু, আমরা নিশ্চিত করতে চাই যে প্রজন্মের দৈর্ঘ্যের সমস্যা (সর্বোচ্চ টোকেন দৈর্ঘ্য) বা টোকেন স্টপ হওয়ার কারণে আউটপুটটি কাটা না হয়।
এটি সম্পন্ন করার জন্য, আমরা ব্যবহার করি finish_reason আউটপুটে উত্পন্ন বৈশিষ্ট্য, এর মান নিরীক্ষণ করুন এবং সম্পূর্ণ আউটপুট তৈরি না হওয়া পর্যন্ত জেনারেট করা চালিয়ে যান।
আমরা একটি অনুমান ফাংশন সংজ্ঞায়িত করি যা একটি পেলোড ইনপুট নেয় এবং সেজমেকার এন্ডপয়েন্টকে কল করে, একটি প্রতিক্রিয়া ফিরিয়ে দেয় এবং জেনারেট করা পাঠ্য বের করার জন্য প্রতিক্রিয়া প্রক্রিয়া করে। পেলোডে ইনপুট এবং সর্বোচ্চ টোকেন এবং বিশদ বিবরণের মতো পরামিতি হিসাবে প্রম্পট পাঠ্য রয়েছে। প্রতিক্রিয়াটি একটি স্ট্রীমে পড়া হয় এবং একটি তালিকায় জেনারেট করা টেক্সট টোকেনগুলি বের করার জন্য লাইন দ্বারা প্রক্রিয়া করা হয়। আমরা মত বিবরণ নিষ্কাশন finish_reason. প্রতিবার আরও প্রসঙ্গ যোগ করার সময় আমরা অনুমান ফাংশনটিকে একটি লুপে (শৃঙ্খলযুক্ত অনুরোধ) কল করি এবং মডেলটি শেষ না হওয়া পর্যন্ত উত্পন্ন টোকেনের সংখ্যা এবং পাঠানো অনুরোধের সংখ্যা ট্র্যাক করি।
আমরা দেখতে পারেন, যদিও max_new_token প্যারামিটারটি 256 এ সেট করা হয়েছে, আমরা সম্পূর্ণ আউটপুট তৈরি না হওয়া পর্যন্ত এন্ডপয়েন্টে একাধিক অনুরোধ চেইন করতে আউটপুটের অংশ হিসাবে finish_reason বিস্তারিত বৈশিষ্ট্য ব্যবহার করি।

একইভাবে, আপনার ব্যবহারের ক্ষেত্রের উপর ভিত্তি করে, আপনি ব্যবহার করতে পারেন stop_reason প্রদত্ত কাজের জন্য নির্দিষ্ট করা অপর্যাপ্ত আউটপুট ক্রম দৈর্ঘ্য সনাক্ত করতে বা মানব স্টপ সিকোয়েন্সের কারণে অনিচ্ছাকৃত সমাপ্তি।
উপসংহার
এই পোস্টে, আমরা AWS LMI কন্টেইনারের v0.26.0 রিলিজের মধ্য দিয়ে হেঁটেছি। আমরা মূল কর্মক্ষমতা উন্নতি, নতুন মডেল সমর্থন, এবং নতুন ব্যবহারযোগ্যতা বৈশিষ্ট্য হাইলাইট. এই ক্ষমতাগুলির সাহায্যে, আপনি আপনার শেষ-ব্যবহারকারীদের একটি ভাল অভিজ্ঞতা প্রদান করার সাথে সাথে খরচ এবং কর্মক্ষমতা বৈশিষ্ট্যগুলিকে আরও ভালভাবে ভারসাম্য করতে পারেন৷
LMI DLC ক্ষমতা সম্পর্কে আরও জানতে, পড়ুন মডেল সমান্তরালতা এবং বড় মডেল অনুমান. আপনি SageMaker থেকে এই নতুন ক্ষমতাগুলি কীভাবে ব্যবহার করছেন তা দেখে আমরা উত্তেজিত।
লেখক সম্পর্কে
 জোয়াও মৌরা AWS-এর একজন সিনিয়র এআই/এমএল স্পেশালিস্ট সলিউশন আর্কিটেক্ট। João AWS গ্রাহকদের সাহায্য করে - ছোট স্টার্টআপ থেকে শুরু করে বৃহৎ এন্টারপ্রাইজ - প্রশিক্ষণ এবং দক্ষতার সাথে বড় মডেল স্থাপন, এবং আরও বিস্তৃতভাবে AWS-এ ML প্ল্যাটফর্ম তৈরি করে৷
জোয়াও মৌরা AWS-এর একজন সিনিয়র এআই/এমএল স্পেশালিস্ট সলিউশন আর্কিটেক্ট। João AWS গ্রাহকদের সাহায্য করে - ছোট স্টার্টআপ থেকে শুরু করে বৃহৎ এন্টারপ্রাইজ - প্রশিক্ষণ এবং দক্ষতার সাথে বড় মডেল স্থাপন, এবং আরও বিস্তৃতভাবে AWS-এ ML প্ল্যাটফর্ম তৈরি করে৷
 রাহুল শর্মা তিনি AWS-এর একজন সিনিয়র সলিউশন আর্কিটেক্ট, AWS গ্রাহকদের AI/ML সলিউশন ডিজাইন ও তৈরি করতে সাহায্য করেন। AWS-এ যোগদানের আগে, রাহুল অর্থ ও বীমা খাতে বেশ কয়েক বছর কাটিয়েছেন, গ্রাহকদের ডেটা এবং বিশ্লেষণাত্মক প্ল্যাটফর্ম তৈরি করতে সহায়তা করেছেন।
রাহুল শর্মা তিনি AWS-এর একজন সিনিয়র সলিউশন আর্কিটেক্ট, AWS গ্রাহকদের AI/ML সলিউশন ডিজাইন ও তৈরি করতে সাহায্য করেন। AWS-এ যোগদানের আগে, রাহুল অর্থ ও বীমা খাতে বেশ কয়েক বছর কাটিয়েছেন, গ্রাহকদের ডেটা এবং বিশ্লেষণাত্মক প্ল্যাটফর্ম তৈরি করতে সহায়তা করেছেন।
 কিং ল্যান AWS-এর একজন সফটওয়্যার ডেভেলপমেন্ট ইঞ্জিনিয়ার। তিনি অ্যামাজনে বেশ কিছু চ্যালেঞ্জিং প্রোডাক্ট নিয়ে কাজ করছেন, যার মধ্যে রয়েছে হাই পারফরম্যান্স এমএল ইনফারেন্স সলিউশন এবং হাই পারফরম্যান্স লগিং সিস্টেম। Qing-এর দল সফলভাবে অ্যামাজন বিজ্ঞাপনে প্রথম বিলিয়ন-প্যারামিটার মডেল লঞ্চ করেছে খুব কম বিলম্বের প্রয়োজনে। কিং এর অবকাঠামো অপ্টিমাইজেশান এবং গভীর শিক্ষার ত্বরণ সম্পর্কে গভীর জ্ঞান রয়েছে।
কিং ল্যান AWS-এর একজন সফটওয়্যার ডেভেলপমেন্ট ইঞ্জিনিয়ার। তিনি অ্যামাজনে বেশ কিছু চ্যালেঞ্জিং প্রোডাক্ট নিয়ে কাজ করছেন, যার মধ্যে রয়েছে হাই পারফরম্যান্স এমএল ইনফারেন্স সলিউশন এবং হাই পারফরম্যান্স লগিং সিস্টেম। Qing-এর দল সফলভাবে অ্যামাজন বিজ্ঞাপনে প্রথম বিলিয়ন-প্যারামিটার মডেল লঞ্চ করেছে খুব কম বিলম্বের প্রয়োজনে। কিং এর অবকাঠামো অপ্টিমাইজেশান এবং গভীর শিক্ষার ত্বরণ সম্পর্কে গভীর জ্ঞান রয়েছে।
 জিয়ান সেং অ্যামাজন ওয়েব সার্ভিসেস-এর একজন সফটওয়্যার ডেভেলপমেন্ট ইঞ্জিনিয়ার যিনি মেশিন লার্নিং সিস্টেমের বিভিন্ন গুরুত্বপূর্ণ দিক নিয়ে কাজ করেছেন। গভীর শিক্ষার সংকলন এবং ফ্রেমওয়ার্ক রানটাইম অপ্টিমাইজেশানের উপর ফোকাস করে সেজমেকার নিও পরিষেবাতে তিনি একটি মূল অবদানকারী। সম্প্রতি, তিনি তার প্রচেষ্টার নির্দেশ দিয়েছেন এবং বড় মডেল অনুমানের জন্য মেশিন লার্নিং সিস্টেমকে অপ্টিমাইজ করতে অবদান রেখেছেন।
জিয়ান সেং অ্যামাজন ওয়েব সার্ভিসেস-এর একজন সফটওয়্যার ডেভেলপমেন্ট ইঞ্জিনিয়ার যিনি মেশিন লার্নিং সিস্টেমের বিভিন্ন গুরুত্বপূর্ণ দিক নিয়ে কাজ করেছেন। গভীর শিক্ষার সংকলন এবং ফ্রেমওয়ার্ক রানটাইম অপ্টিমাইজেশানের উপর ফোকাস করে সেজমেকার নিও পরিষেবাতে তিনি একটি মূল অবদানকারী। সম্প্রতি, তিনি তার প্রচেষ্টার নির্দেশ দিয়েছেন এবং বড় মডেল অনুমানের জন্য মেশিন লার্নিং সিস্টেমকে অপ্টিমাইজ করতে অবদান রেখেছেন।
 টাইলার ওস্টারবার্গ AWS-এর একজন সফটওয়্যার ডেভেলপমেন্ট ইঞ্জিনিয়ার। তিনি সেজমেকারের মধ্যে উচ্চ-পারফরম্যান্স মেশিন লার্নিং ইনফারেন্স অভিজ্ঞতা তৈরিতে বিশেষজ্ঞ। সম্প্রতি, সেজমেকার প্ল্যাটফর্মে ইনফরেন্টিয়া ডিপ লার্নিং কন্টেইনারগুলির কার্যক্ষমতাকে অপ্টিমাইজ করার দিকে তার ফোকাস রয়েছে৷ টাইলার বৃহৎ ভাষার মডেলের জন্য পারফরম্যান্স হোস্টিং সলিউশন বাস্তবায়নে এবং অত্যাধুনিক প্রযুক্তি ব্যবহার করে ব্যবহারকারীর অভিজ্ঞতা বাড়াতে পারদর্শী।
টাইলার ওস্টারবার্গ AWS-এর একজন সফটওয়্যার ডেভেলপমেন্ট ইঞ্জিনিয়ার। তিনি সেজমেকারের মধ্যে উচ্চ-পারফরম্যান্স মেশিন লার্নিং ইনফারেন্স অভিজ্ঞতা তৈরিতে বিশেষজ্ঞ। সম্প্রতি, সেজমেকার প্ল্যাটফর্মে ইনফরেন্টিয়া ডিপ লার্নিং কন্টেইনারগুলির কার্যক্ষমতাকে অপ্টিমাইজ করার দিকে তার ফোকাস রয়েছে৷ টাইলার বৃহৎ ভাষার মডেলের জন্য পারফরম্যান্স হোস্টিং সলিউশন বাস্তবায়নে এবং অত্যাধুনিক প্রযুক্তি ব্যবহার করে ব্যবহারকারীর অভিজ্ঞতা বাড়াতে পারদর্শী।
 রুপিন্দর গ্রেওয়াল AWS সহ একজন সিনিয়র AI/ML বিশেষজ্ঞ সমাধান স্থপতি। তিনি বর্তমানে Amazon SageMaker-এ মডেল এবং MLOps পরিবেশন করার দিকে মনোনিবেশ করেন। এই ভূমিকার আগে, তিনি মেশিন লার্নিং ইঞ্জিনিয়ার বিল্ডিং এবং হোস্টিং মডেল হিসাবে কাজ করেছিলেন। কাজের বাইরে, তিনি টেনিস খেলা এবং পাহাড়ের পথে বাইক চালানো উপভোগ করেন।
রুপিন্দর গ্রেওয়াল AWS সহ একজন সিনিয়র AI/ML বিশেষজ্ঞ সমাধান স্থপতি। তিনি বর্তমানে Amazon SageMaker-এ মডেল এবং MLOps পরিবেশন করার দিকে মনোনিবেশ করেন। এই ভূমিকার আগে, তিনি মেশিন লার্নিং ইঞ্জিনিয়ার বিল্ডিং এবং হোস্টিং মডেল হিসাবে কাজ করেছিলেন। কাজের বাইরে, তিনি টেনিস খেলা এবং পাহাড়ের পথে বাইক চালানো উপভোগ করেন।
 ধাওয়াল প্যাটেল AWS-এর একজন প্রধান মেশিন লার্নিং আর্কিটেক্ট। তিনি ডিস্ট্রিবিউটেড কম্পিউটিং এবং কৃত্রিম বুদ্ধিমত্তা সম্পর্কিত সমস্যা নিয়ে বড় উদ্যোগ থেকে শুরু করে মাঝারি আকারের স্টার্টআপ পর্যন্ত সংস্থাগুলির সাথে কাজ করেছেন। তিনি এনএলপি এবং কম্পিউটার ভিশন ডোমেন সহ গভীর শিক্ষার উপর ফোকাস করেন। তিনি গ্রাহকদের SageMaker-এ উচ্চ কর্মক্ষমতা মডেল অনুমান অর্জনে সহায়তা করেন।
ধাওয়াল প্যাটেল AWS-এর একজন প্রধান মেশিন লার্নিং আর্কিটেক্ট। তিনি ডিস্ট্রিবিউটেড কম্পিউটিং এবং কৃত্রিম বুদ্ধিমত্তা সম্পর্কিত সমস্যা নিয়ে বড় উদ্যোগ থেকে শুরু করে মাঝারি আকারের স্টার্টআপ পর্যন্ত সংস্থাগুলির সাথে কাজ করেছেন। তিনি এনএলপি এবং কম্পিউটার ভিশন ডোমেন সহ গভীর শিক্ষার উপর ফোকাস করেন। তিনি গ্রাহকদের SageMaker-এ উচ্চ কর্মক্ষমতা মডেল অনুমান অর্জনে সহায়তা করেন।
 রঘু রমেশা অ্যামাজন সেজমেকার সার্ভিস টিমের সাথে একজন সিনিয়র এমএল সলিউশন আর্কিটেক্ট। তিনি গ্রাহকদের এমএল উৎপাদন কাজের লোডগুলিকে সেজমেকারে স্কেলে তৈরি, স্থাপন এবং স্থানান্তর করতে সহায়তা করার দিকে মনোনিবেশ করেন। তিনি মেশিন লার্নিং, এআই, এবং কম্পিউটার ভিশন ডোমেনে বিশেষজ্ঞ এবং UT ডালাস থেকে কম্পিউটার সায়েন্সে স্নাতকোত্তর ডিগ্রি অর্জন করেছেন। তার অবসর সময়ে, তিনি ভ্রমণ এবং ফটোগ্রাফি উপভোগ করেন।
রঘু রমেশা অ্যামাজন সেজমেকার সার্ভিস টিমের সাথে একজন সিনিয়র এমএল সলিউশন আর্কিটেক্ট। তিনি গ্রাহকদের এমএল উৎপাদন কাজের লোডগুলিকে সেজমেকারে স্কেলে তৈরি, স্থাপন এবং স্থানান্তর করতে সহায়তা করার দিকে মনোনিবেশ করেন। তিনি মেশিন লার্নিং, এআই, এবং কম্পিউটার ভিশন ডোমেনে বিশেষজ্ঞ এবং UT ডালাস থেকে কম্পিউটার সায়েন্সে স্নাতকোত্তর ডিগ্রি অর্জন করেছেন। তার অবসর সময়ে, তিনি ভ্রমণ এবং ফটোগ্রাফি উপভোগ করেন।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- PlatoData.Network উল্লম্ব জেনারেটিভ Ai. নিজেকে ক্ষমতায়িত করুন। এখানে প্রবেশ করুন.
- প্লেটোএআইস্ট্রিম। Web3 ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- প্লেটোইএসজি। কার্বন, ক্লিনটেক, শক্তি, পরিবেশ সৌর, বর্জ্য ব্যবস্থাপনা. এখানে প্রবেশ করুন.
- প্লেটো হেলথ। বায়োটেক এবং ক্লিনিক্যাল ট্রায়াল ইন্টেলিজেন্স। এখানে প্রবেশ করুন.
- উত্স: https://aws.amazon.com/blogs/machine-learning/boost-inference-performance-for-mixtral-and-llama-2-models-with-new-amazon-sagemaker-containers/

