দক্ষ নিয়ন্ত্রণ নীতিগুলি শিল্প সংস্থাগুলিকে অনির্ধারিত ডাউনটাইম এবং শক্তি খরচ কমিয়ে উত্পাদনশীলতাকে সর্বাধিক করে তাদের মুনাফা বাড়াতে সক্ষম করে৷ সর্বোত্তম নিয়ন্ত্রণ নীতিগুলি সন্ধান করা একটি জটিল কাজ কারণ রাসায়নিক চুল্লি এবং বায়ু টারবাইনের মতো ভৌত সিস্টেমগুলি প্রায়শই মডেল করা কঠিন এবং কারণ প্রক্রিয়া গতিশীলতার প্রবাহ সময়ের সাথে সাথে কর্মক্ষমতার অবনতি ঘটাতে পারে। অফলাইন রিইনফোর্সমেন্ট লার্নিং হল একটি নিয়ন্ত্রণ কৌশল যা শিল্প কোম্পানীগুলিকে একটি সুস্পষ্ট প্রক্রিয়া মডেলের প্রয়োজন ছাড়াই সম্পূর্ণরূপে ঐতিহাসিক ডেটা থেকে নিয়ন্ত্রণ নীতি তৈরি করতে দেয়। এই পদ্ধতির জন্য একটি অন্বেষণ পর্যায়ে সরাসরি প্রক্রিয়াটির সাথে মিথস্ক্রিয়া প্রয়োজন হয় না, যা নিরাপত্তা-সমালোচনামূলক অ্যাপ্লিকেশনগুলিতে শক্তিবৃদ্ধি শিক্ষা গ্রহণের জন্য একটি বাধা দূর করে। এই পোস্টে, আমরা শুধুমাত্র ঐতিহাসিক ডেটা ব্যবহার করে সর্বোত্তম নিয়ন্ত্রণ নীতিগুলি খুঁজে পেতে একটি এন্ড-টু-এন্ড সমাধান তৈরি করব আমাজন সেজমেকার রে এর ব্যবহার করে আরএললিব লাইব্রেরি শক্তিবৃদ্ধি শেখার বিষয়ে আরও জানতে, দেখুন Amazon SageMaker এর সাথে রিইনফোর্সমেন্ট লার্নিং ব্যবহার করুন।
ব্যবহারের ক্ষেত্রে
শিল্প নিয়ন্ত্রণে দক্ষ এবং নির্ভরযোগ্য অপারেশন নিশ্চিত করতে জটিল সিস্টেমের ব্যবস্থাপনা জড়িত, যেমন উত্পাদন লাইন, শক্তি গ্রিড এবং রাসায়নিক উদ্ভিদ। অনেক প্রথাগত নিয়ন্ত্রণ কৌশল পূর্বনির্ধারিত নিয়ম এবং মডেলের উপর ভিত্তি করে তৈরি করা হয়, যার জন্য প্রায়ই ম্যানুয়াল অপ্টিমাইজেশন প্রয়োজন। কিছু শিল্পে কর্মক্ষমতা নিরীক্ষণ করা এবং নিয়ন্ত্রণ নীতি সামঞ্জস্য করা একটি আদর্শ অভ্যাস, উদাহরণস্বরূপ, যখন সরঞ্জামগুলি ক্ষয় হতে শুরু করে বা পরিবেশগত অবস্থার পরিবর্তন হয়। রিটিউনিংয়ে কয়েক সপ্তাহ সময় লাগতে পারে এবং ট্রায়াল-এন্ড-এরর পদ্ধতিতে এর প্রতিক্রিয়া রেকর্ড করতে সিস্টেমে বাহ্যিক উত্তেজনা ইনজেকশনের প্রয়োজন হতে পারে।
পরিবেশের সাথে মিথস্ক্রিয়া করার মাধ্যমে সর্বোত্তম নিয়ন্ত্রণ নীতিগুলি শিখতে প্রক্রিয়া নিয়ন্ত্রণের একটি নতুন দৃষ্টান্ত হিসাবে শক্তিবৃদ্ধি শিক্ষা আবির্ভূত হয়েছে। এই প্রক্রিয়াটির জন্য ডেটাকে তিনটি বিভাগে বিভক্ত করা প্রয়োজন: 1) শারীরিক সিস্টেম থেকে উপলব্ধ পরিমাপ, 2) সিস্টেমে নেওয়া যেতে পারে এমন ক্রিয়াগুলির সেট এবং 3) সরঞ্জামের কার্যকারিতার একটি সংখ্যাসূচক মেট্রিক (পুরস্কার)৷ একটি নীতিকে প্রদত্ত পর্যবেক্ষণে কর্মটি খুঁজে বের করার জন্য প্রশিক্ষিত করা হয়, যা ভবিষ্যতে সর্বোচ্চ পুরষ্কার তৈরি করতে পারে।
অফলাইন শক্তিবৃদ্ধি শেখার ক্ষেত্রে, কেউ এটিকে উৎপাদনে মোতায়েন করার আগে ঐতিহাসিক তথ্যের উপর একটি নীতি প্রশিক্ষণ দিতে পারে। এই ব্লগ পোস্টে প্রশিক্ষিত অ্যালগরিদম বলা হয় "রক্ষণশীল প্রশ্ন শিক্ষা” (CQL)। CQL-এ একটি "অভিনেতা" মডেল এবং একটি "সমালোচক" মডেল রয়েছে এবং একটি প্রস্তাবিত পদক্ষেপ নেওয়ার পরে রক্ষণশীলভাবে তার নিজস্ব কর্মক্ষমতা ভবিষ্যদ্বাণী করার জন্য ডিজাইন করা হয়েছে। এই পোস্টে, প্রক্রিয়াটি একটি দৃষ্টান্তমূলক কার্ট-পোল নিয়ন্ত্রণ সমস্যার সাথে প্রদর্শিত হয়েছে। লক্ষ্য হল একটি এজেন্টকে একটি কার্টের একটি খুঁটিতে ভারসাম্য বজায় রাখার জন্য প্রশিক্ষণ দেওয়া যখন একই সাথে কার্টটিকে একটি নির্দিষ্ট লক্ষ্য অবস্থানের দিকে নিয়ে যায়৷ প্রশিক্ষণ পদ্ধতি অফলাইন ডেটা ব্যবহার করে, যা এজেন্টকে আগে থেকে বিদ্যমান তথ্য থেকে শিখতে দেয়। এই কার্ট-পোল কেস স্টাডি প্রশিক্ষণ প্রক্রিয়া এবং সম্ভাব্য বাস্তব-বিশ্বের অ্যাপ্লিকেশনগুলিতে এর কার্যকারিতা প্রদর্শন করে।
সমাধান ওভারভিউ
এই পোস্টে উপস্থাপিত সমাধানটি ঐতিহাসিক ডেটা সহ অফলাইন শক্তিবৃদ্ধি শেখার জন্য শেষ-থেকে-এন্ড ওয়ার্কফ্লো স্থাপনকে স্বয়ংক্রিয় করে। নিম্নলিখিত চিত্রটি এই কর্মপ্রবাহে ব্যবহৃত আর্কিটেকচার বর্ণনা করে। পরিমাপ ডেটা শিল্প সরঞ্জামের একটি অংশ দ্বারা প্রান্তে উত্পাদিত হয় (এখানে একটি দ্বারা অনুকরণ করা হয় এডাব্লুএস ল্যাম্বদা ফাংশন)। তথ্য একটি করা হয় আমাজন কিনেসিস ডেটা ফায়ারহোস, যা এটি সংরক্ষণ করে আমাজন সিম্পল স্টোরেজ সার্ভিস (Amazon S3)। Amazon S3 হল একটি টেকসই, কার্যকরী, এবং কম খরচে স্টোরেজ সলিউশন যা আপনাকে একটি মেশিন লার্নিং প্রশিক্ষণ প্রক্রিয়ায় প্রচুর পরিমাণে ডেটা পরিবেশন করতে দেয়।
এডাব্লুএস আঠালো ডেটা ক্যাটালগ করে এবং এটি ব্যবহার করে জিজ্ঞাসাযোগ্য করে তোলে অ্যামাজন অ্যাথেনা. এথেনা পরিমাপ ডেটাকে একটি ফর্মে রূপান্তরিত করে যা একটি শক্তিবৃদ্ধি শেখার অ্যালগরিদম গ্রহণ করতে পারে এবং তারপরে এটিকে আবার অ্যামাজন S3 এ আনলোড করে। Amazon SageMaker একটি প্রশিক্ষণের কাজে এই ডেটা লোড করে এবং একটি প্রশিক্ষিত মডেল তৈরি করে। SageMaker তারপর একটি SageMaker এন্ডপয়েন্টে সেই মডেলটি পরিবেশন করে। শিল্প সরঞ্জাম তারপর কর্ম সুপারিশ পেতে যে শেষ পয়েন্ট জিজ্ঞাসা করতে পারেন.
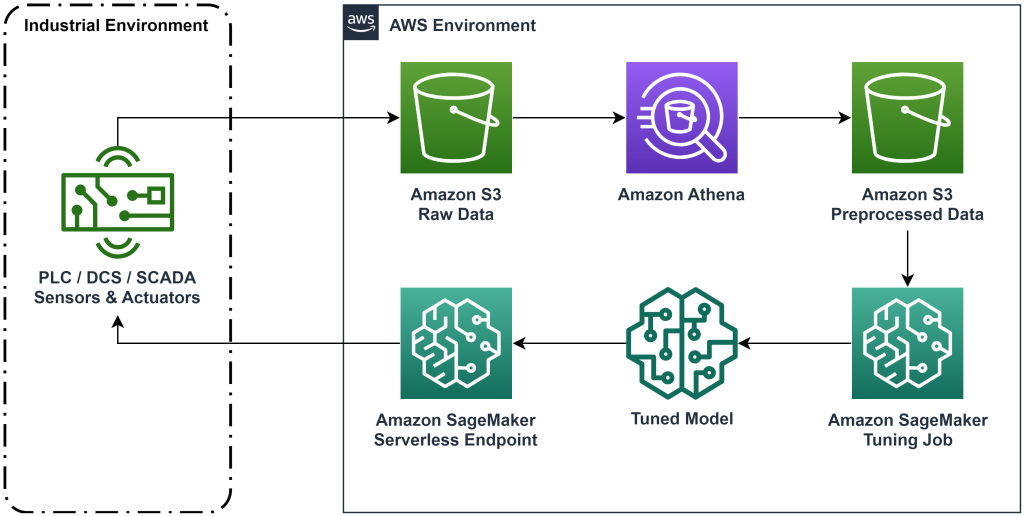
চিত্র 1: আর্কিটেকচার ডায়াগ্রাম এন্ড-টু-এন্ড রিইনফোর্সমেন্ট লার্নিং ওয়ার্কফ্লো দেখাচ্ছে।
এই পোস্টে, আমরা নিম্নলিখিত ধাপে ওয়ার্কফ্লো ভেঙে দেব:
- সমস্যাটি প্রণয়ন করুন। কোন পদক্ষেপ নেওয়া যেতে পারে, কোন পরিমাপের ভিত্তিতে সুপারিশ করতে হবে তা নির্ধারণ করুন এবং প্রতিটি ক্রিয়া কতটা ভালভাবে সম্পাদন করেছে তা সংখ্যাগতভাবে নির্ধারণ করুন।
- ডেটা প্রস্তুত করুন। মেশিন লার্নিং অ্যালগরিদম ব্যবহার করতে পারে এমন একটি ফর্ম্যাটে পরিমাপের টেবিলে রূপান্তর করুন।
- সেই ডেটাতে অ্যালগরিদমকে প্রশিক্ষণ দিন।
- প্রশিক্ষণ মেট্রিক্সের উপর ভিত্তি করে চালানো সেরা প্রশিক্ষণ নির্বাচন করুন।
- মডেলটিকে সেজমেকার এন্ডপয়েন্টে স্থাপন করুন।
- উত্পাদনে মডেলের কর্মক্ষমতা মূল্যায়ন করুন।
পূর্বশর্ত
এই ওয়াকথ্রু সম্পূর্ণ করতে, আপনার একটি থাকতে হবে এডাব্লুএস অ্যাকাউন্ট এবং এর সাথে একটি কমান্ড লাইন ইন্টারফেস AWS SAM ইনস্টল করা হয়েছে. এই ওয়ার্কফ্লো চালানোর জন্য AWS SAM টেমপ্লেট স্থাপন করতে এবং প্রশিক্ষণের ডেটা তৈরি করতে এই পদক্ষেপগুলি অনুসরণ করুন:
- কমান্ড দিয়ে কোড সংগ্রহস্থল ডাউনলোড করুন
- রেপোতে ডিরেক্টরি পরিবর্তন করুন:
- রেপো তৈরি করুন:
- রেপো স্থাপন করুন
- একটি ব্যাশ স্ক্রিপ্ট কল করতে নিম্নলিখিত কমান্ডগুলি ব্যবহার করুন, যা একটি AWS Lambda ফাংশন ব্যবহার করে মক ডেটা তৈরি করে।
sudo yum install jqcd utilssh generate_mock_data.sh
সমাধান ওয়াকথ্রু
প্রণয়ন সমস্যা
এই ব্লগ পোস্টে আমাদের সিস্টেম হল একটি কার্ট যার উপরে একটি খুঁটি সুষম। মেরুটি খাড়া হলে এবং কার্টের অবস্থান লক্ষ্য অবস্থানের কাছাকাছি থাকলে সিস্টেমটি ভালভাবে কাজ করে। পূর্বশর্ত পদক্ষেপে, আমরা এই সিস্টেম থেকে ঐতিহাসিক ডেটা তৈরি করেছি।
নিম্নলিখিত টেবিলটি সিস্টেম থেকে সংগৃহীত ঐতিহাসিক তথ্য দেখায়।
| কার্ট অবস্থান | কার্টের বেগ | মেরু কোণ | মেরু কৌণিক বেগ | লক্ষ্য অবস্থান | বাহ্যিক শক্তি | পুরষ্কার | সময় |
| 0.53 | -0.79 | -0.08 | 0.16 | 0.50 | -0.04 | 11.5 | 5:37:54 অপরাহ্ন |
| 0.51 | -0.82 | -0.07 | 0.17 | 0.50 | -0.04 | 11.9 | 5:37:55 অপরাহ্ন |
| 0.50 | -0.84 | -0.07 | 0.18 | 0.50 | -0.03 | 12.2 | 5:37:56 অপরাহ্ন |
| 0.48 | -0.85 | -0.07 | 0.18 | 0.50 | -0.03 | 10.5 | 5:37:57 অপরাহ্ন |
| 0.46 | -0.87 | -0.06 | 0.19 | 0.50 | -0.03 | 10.3 | 5:37:58 অপরাহ্ন |
আপনি নিম্নলিখিত প্রশ্নের সাথে Amazon Athena ব্যবহার করে ঐতিহাসিক সিস্টেম তথ্য জিজ্ঞাসা করতে পারেন:
এই সিস্টেমের অবস্থা কার্টের অবস্থান, কার্টের বেগ, মেরু কোণ, মেরু কৌণিক বেগ এবং লক্ষ্য অবস্থান দ্বারা সংজ্ঞায়িত করা হয়। প্রতিটি ধাপে গৃহীত পদক্ষেপ হল কার্টে প্রয়োগ করা বাহ্যিক শক্তি। সিমুলেটেড এনভায়রনমেন্ট একটি পুরষ্কার মান আউটপুট করে যা বেশি হয় যখন কার্টটি লক্ষ্য অবস্থানের কাছাকাছি থাকে এবং মেরুটি আরও খাড়া থাকে।
ডেটা প্রস্তুত করুন
রিইনফোর্সমেন্ট লার্নিং মডেলে সিস্টেমের তথ্য উপস্থাপন করতে, এটিকে JSON অবজেক্টে রূপান্তরিত করুন যা মানগুলিকে স্টেটে (যাকে পর্যবেক্ষণও বলা হয়), অ্যাকশন এবং পুরষ্কার শ্রেণীতে শ্রেণীবদ্ধ করে। Amazon S3 তে এই বস্তুগুলি সংরক্ষণ করুন। এখানে পূর্ববর্তী টেবিলের সময় ধাপ থেকে উত্পাদিত JSON বস্তুর একটি উদাহরণ।
|
{“obs”:[[0.53,-0.79,-0.08,0.16,0.5]], “action”:[[-0.04]], “reward”:[11.5] ,”next_obs”:[[0.51,-0.82,-0.07,0.17,0.5]]} |
|
{“obs”:[[0.51,-0.82,-0.07,0.17,0.5]], “action”:[[-0.04]], “reward”:[11.9], “next_obs”:[[0.50,-0.84,-0.07,0.18,0.5]]} |
|
{“obs”:[[0.50,-0.84,-0.07,0.18,0.5]], “action”:[[-0.03]], “reward”:[12.2], “next_obs”:[[0.48,-0.85,-0.07,0.18,0.5]]} |
AWS CloudFormation স্ট্যাকে একটি আউটপুট বলা হয় AthenaQueryToCreateJsonFormatedData. রূপান্তর সঞ্চালন এবং Amazon S3 এ JSON অবজেক্ট সংরক্ষণ করতে Amazon Athena-এ এই ক্যোয়ারীটি চালান। রিইনফোর্সমেন্ট লার্নিং অ্যালগরিদম এই JSON অবজেক্টের গঠন ব্যবহার করে বোঝা যায় কোন মানের উপর ভিত্তি করে সুপারিশ করা হবে এবং ঐতিহাসিক ডেটাতে পদক্ষেপ নেওয়ার ফলাফল।
ট্রেন এজেন্ট
এখন আমরা একটি প্রশিক্ষিত কর্ম সুপারিশ মডেল তৈরি করার জন্য একটি প্রশিক্ষণ কাজ শুরু করতে পারি। বিভিন্ন কনফিগারেশন ফলাফল প্রশিক্ষিত মডেলকে কীভাবে প্রভাবিত করে তা দেখতে Amazon SageMaker আপনাকে দ্রুত একাধিক প্রশিক্ষণ কাজ চালু করতে দেয়। নাম Lambda ফাংশন কল TuningJobLauncherFunction একটি হাইপারপ্যারামিটার টিউনিং কাজ শুরু করতে যা অ্যালগরিদম প্রশিক্ষণের সময় হাইপারপ্যারামিটারের চারটি ভিন্ন সেট নিয়ে পরীক্ষা করে।
সেরা প্রশিক্ষণ রান নির্বাচন করুন
প্রশিক্ষণের কাজগুলির মধ্যে কোনটি সেরা মডেল তৈরি করেছে তা খুঁজে বের করতে, প্রশিক্ষণের সময় উত্পাদিত ক্ষতি বক্ররেখা পরীক্ষা করুন। সিকিউএল-এর সমালোচক মডেল একটি প্রস্তাবিত পদক্ষেপ নেওয়ার পরে অভিনেতার কর্মক্ষমতা (একটি Q মান বলা হয়) অনুমান করে। সমালোচকের ক্ষতি ফাংশন অংশ সময়গত পার্থক্য ত্রুটি অন্তর্ভুক্ত. এই মেট্রিক সমালোচকের Q মান নির্ভুলতা পরিমাপ করে। একটি উচ্চ গড় Q মান এবং একটি কম সাময়িক পার্থক্য ত্রুটি সহ প্রশিক্ষণের জন্য দেখুন। এই কাগজ, অফলাইন মডেল-মুক্ত রোবোটিক শক্তিবৃদ্ধি শেখার জন্য একটি কর্মপ্রবাহ, বিশদ বিবরণ কিভাবে সেরা প্রশিক্ষণ রান নির্বাচন করতে হয়. কোড সংগ্রহস্থল একটি ফাইল আছে, /utils/investigate_training.py, যা সর্বশেষ প্রশিক্ষণের কাজের বর্ণনা দিয়ে একটি চক্রান্তমূলক HTML চিত্র তৈরি করে। এই ফাইলটি চালান এবং সেরা প্রশিক্ষণ রান বাছাই করতে আউটপুট ব্যবহার করুন।
প্রশিক্ষিত মডেলের কর্মক্ষমতা অনুমান করতে আমরা গড় Q মান ব্যবহার করতে পারি। Q মানগুলিকে রক্ষণশীলভাবে ছাড় দেওয়া ভবিষ্যৎ পুরস্কারের মানগুলির সমষ্টির পূর্বাভাস দেওয়ার জন্য প্রশিক্ষিত করা হয়। দীর্ঘ-চলমান প্রক্রিয়াগুলির জন্য, আমরা Q মানকে (1-"ডিসকাউন্ট রেট") দ্বারা গুণ করে এই সংখ্যাটিকে একটি সূচকীয় ওজনযুক্ত গড়তে রূপান্তর করতে পারি। এই সেটে চালানো সেরা প্রশিক্ষণটি 539 এর গড় Q মান অর্জন করেছে। আমাদের ছাড়ের হার হল 0.99, তাই মডেলটি প্রতি ধাপে কমপক্ষে 5.39 গড় পুরস্কারের পূর্বাভাস দিচ্ছে। নতুন মডেল ঐতিহাসিক নিয়ন্ত্রণ নীতিকে ছাড়িয়ে যাবে কিনা তা বোঝার জন্য আপনি এই মানটিকে ঐতিহাসিক সিস্টেমের কর্মক্ষমতার সাথে তুলনা করতে পারেন। এই পরীক্ষায়, ঐতিহাসিক ডেটার গড় পুরষ্কার প্রতি টাইম ধাপ ছিল 4.3, তাই CQL মডেলটি ঐতিহাসিকভাবে অর্জিত সিস্টেমের তুলনায় 25 শতাংশ ভাল পারফরম্যান্সের পূর্বাভাস দিচ্ছে।
মডেল স্থাপন
অ্যামাজন সেজমেকার এন্ডপয়েন্টগুলি আপনাকে বিভিন্ন ধরণের ব্যবহারের ক্ষেত্রে বিভিন্ন উপায়ে মেশিন লার্নিং মডেলগুলি পরিবেশন করতে দেয়। এই পোস্টে, আমরা সার্ভারহীন এন্ডপয়েন্ট টাইপ ব্যবহার করব যাতে আমাদের এন্ডপয়েন্ট স্বয়ংক্রিয়ভাবে চাহিদার সাথে স্কেল করে, এবং আমরা শুধুমাত্র তখনই গণনা ব্যবহারের জন্য অর্থ প্রদান করি যখন এন্ডপয়েন্ট একটি অনুমান তৈরি করে। একটি সার্ভারহীন এন্ডপয়েন্ট স্থাপন করতে, একটি অন্তর্ভুক্ত করুন ProductionVariantServerless Config মধ্যে উত্পাদন বৈকল্পিক SageMaker এর শেষ পয়েন্ট কনফিগারেশন. নিম্নলিখিত কোড স্নিপেট দেখায় কিভাবে এই উদাহরণে সার্ভারহীন এন্ডপয়েন্টটি পাইথনের জন্য Amazon SageMaker সফটওয়্যার ডেভেলপমেন্ট কিট ব্যবহার করে স্থাপন করা হয়েছে। এ মডেলটি স্থাপন করতে ব্যবহৃত নমুনা কোডটি খুঁজুন sagemaker-অফলাইন-রিইনফোর্সমেন্ট-লার্নিং-রে-cql.
প্রতিটি প্রশিক্ষণ চালানোর জন্য প্রশিক্ষিত মডেল ফাইলগুলি S3 মডেলের আর্টিফ্যাক্টগুলিতে অবস্থিত। মেশিন লার্নিং মডেল স্থাপন করতে, সেরা ট্রেনিং চালানোর মডেল ফাইলগুলি সনাক্ত করুন এবং Lambda ফাংশনটিকে "নামে কল করুনModelDeployerFunction” এই মডেল ডেটা ধারণ করে এমন একটি ইভেন্ট সহ৷ Lambda ফাংশন প্রশিক্ষিত মডেল পরিবেশন করার জন্য একটি SageMaker সার্ভারহীন শেষ পয়েন্ট চালু করবে। "কে কল করার সময় ব্যবহার করার নমুনা ইভেন্টModelDeployerFunction":
প্রশিক্ষিত মডেল কর্মক্ষমতা মূল্যায়ন
আমাদের প্রশিক্ষিত মডেল উৎপাদনে কেমন করছে তা দেখার সময়! নতুন মডেলের পারফরম্যান্স পরীক্ষা করতে, ল্যাম্বডা ফাংশনকে কল করুন "RunPhysicsSimulationFunctionইভেন্টে সেজমেকার এন্ডপয়েন্ট নামের সাথে। এটি এন্ডপয়েন্ট দ্বারা প্রস্তাবিত ক্রিয়াগুলি ব্যবহার করে সিমুলেশন চালাবে। কল করার সময় ব্যবহার করার জন্য নমুনা ইভেন্ট RunPhysicsSimulatorFunction:
প্রশিক্ষিত মডেলের পারফরম্যান্সের সাথে ঐতিহাসিক সিস্টেম পারফরম্যান্সের তুলনা করতে নিম্নলিখিত এথেনা ক্যোয়ারীটি ব্যবহার করুন।
| কর্ম উৎস | প্রতি সময় ধাপে গড় পুরস্কার |
trained_model |
10.8 |
historic_data |
4.3 |
নিম্নলিখিত অ্যানিমেশনগুলি প্রশিক্ষণ ডেটা থেকে একটি নমুনা পর্ব এবং একটি পর্বের মধ্যে পার্থক্য দেখায় যেখানে প্রশিক্ষিত মডেলটি কোন পদক্ষেপ নিতে হবে তা বেছে নিতে ব্যবহৃত হয়েছিল৷ অ্যানিমেশনে, নীল বক্স হল কার্ট, নীল রেখা হল মেরু, এবং সবুজ আয়তক্ষেত্র হল লক্ষ্যের অবস্থান৷ লাল তীরটি প্রতিটি ধাপে কার্টে প্রয়োগ করা বল দেখায়। প্রশিক্ষণের ডেটাতে লাল তীরটি বেশ খানিকটা সামনে পিছনে লাফিয়ে যায় কারণ ডেটা 50 শতাংশ বিশেষজ্ঞ অ্যাকশন এবং 50 শতাংশ র্যান্ডম অ্যাকশন ব্যবহার করে তৈরি করা হয়েছিল। প্রশিক্ষিত মডেল একটি নিয়ন্ত্রণ নীতি শিখেছে যা কার্টটিকে দ্রুত লক্ষ্যের অবস্থানে নিয়ে যায়, স্থিতিশীলতা বজায় রেখে সম্পূর্ণরূপে অ-বিশেষজ্ঞ প্রদর্শনী পর্যবেক্ষণ করে।
 |
 |
পরিষ্কার কর
এই কর্মপ্রবাহে ব্যবহৃত সংস্থানগুলি মুছতে, Amazon CloudFormation স্ট্যাকের সংস্থান বিভাগে নেভিগেট করুন এবং S3 বাকেট এবং IAM ভূমিকাগুলি মুছুন৷ তারপর ক্লাউডফর্মেশন স্ট্যাক নিজেই মুছে ফেলুন।
উপসংহার
অফলাইন রিইনফোর্সমেন্ট লার্নিং শিল্প কোম্পানিগুলিকে ঐতিহাসিক ডেটা ব্যবহার করে নিরাপত্তার সঙ্গে আপস না করেই সর্বোত্তম নীতির সন্ধানে স্বয়ংক্রিয়ভাবে সাহায্য করতে পারে। আপনার ক্রিয়াকলাপে এই পদ্ধতির প্রয়োগ করতে, একটি রাষ্ট্র-নির্ধারিত সিস্টেম তৈরি করে এমন পরিমাপ, আপনি যে ক্রিয়াগুলি নিয়ন্ত্রণ করতে পারেন, এবং পছন্দসই কর্মক্ষমতা নির্দেশ করে এমন মেট্রিকগুলি সনাক্ত করে শুরু করুন। তারপর, অ্যাক্সেস এই GitHub সংগ্রহস্থল Ray এবং Amazon SageMaker ব্যবহার করে একটি স্বয়ংক্রিয় এন্ড-টু-এন্ড সমাধান বাস্তবায়নের জন্য।
আপনি Amazon SageMaker RL এর সাথে কী করতে পারেন পোস্টটি কেবল তার পৃষ্ঠকে স্ক্র্যাচ করে। একবার চেষ্টা করে দেখুন, এবং অনুগ্রহ করে আমাদের মতামত পাঠান, হয় তে অ্যামাজন সেজমেকার আলোচনা ফোরাম অথবা আপনার সাধারণ AWS পরিচিতির মাধ্যমে।
লেখক সম্পর্কে
 ওয়াল্ট মেফিল্ড AWS-এর একজন সলিউশন আর্কিটেক্ট এবং শক্তি কোম্পানিগুলিকে আরও নিরাপদে এবং দক্ষতার সাথে কাজ করতে সাহায্য করে৷ এডব্লিউএস-এ যোগদানের আগে, ওয়াল্ট হিলকর্প এনার্জি কোম্পানির অপারেশন ইঞ্জিনিয়ার হিসেবে কাজ করেছেন। তিনি অবসর সময়ে বাগান করতে এবং মাছ উড়তে পছন্দ করেন।
ওয়াল্ট মেফিল্ড AWS-এর একজন সলিউশন আর্কিটেক্ট এবং শক্তি কোম্পানিগুলিকে আরও নিরাপদে এবং দক্ষতার সাথে কাজ করতে সাহায্য করে৷ এডব্লিউএস-এ যোগদানের আগে, ওয়াল্ট হিলকর্প এনার্জি কোম্পানির অপারেশন ইঞ্জিনিয়ার হিসেবে কাজ করেছেন। তিনি অবসর সময়ে বাগান করতে এবং মাছ উড়তে পছন্দ করেন।
 ফেলিপ লোপেজ তেল ও গ্যাস উৎপাদন কার্যক্রমে মনোযোগ সহ AWS-এর একজন সিনিয়র সলিউশন আর্কিটেক্ট। AWS-এ যোগদানের আগে, Felipe GE Digital এবং Schlumberger-এর সাথে কাজ করেছিলেন, যেখানে তিনি শিল্প অ্যাপ্লিকেশনের জন্য মডেলিং এবং অপ্টিমাইজেশন পণ্যগুলিতে মনোনিবেশ করেছিলেন।
ফেলিপ লোপেজ তেল ও গ্যাস উৎপাদন কার্যক্রমে মনোযোগ সহ AWS-এর একজন সিনিয়র সলিউশন আর্কিটেক্ট। AWS-এ যোগদানের আগে, Felipe GE Digital এবং Schlumberger-এর সাথে কাজ করেছিলেন, যেখানে তিনি শিল্প অ্যাপ্লিকেশনের জন্য মডেলিং এবং অপ্টিমাইজেশন পণ্যগুলিতে মনোনিবেশ করেছিলেন।
 ইংওয়েই ইউ জেনারেটিভ এআই ইনকিউবেটর, AWS-এর একজন ফলিত বিজ্ঞানী। প্রাকৃতিক ভাষা প্রক্রিয়াকরণ, সময় সিরিজ বিশ্লেষণ, এবং ভবিষ্যদ্বাণীমূলক রক্ষণাবেক্ষণ সহ মেশিন লার্নিং-এ ধারণার বিভিন্ন প্রমাণের উপর শিল্প জুড়ে বিভিন্ন সংস্থার সাথে কাজ করার অভিজ্ঞতা রয়েছে তার। তার অবসর সময়ে, তিনি সাঁতার কাটা, চিত্রাঙ্কন, হাইকিং এবং পরিবার এবং বন্ধুদের সাথে সময় কাটাতে উপভোগ করেন।
ইংওয়েই ইউ জেনারেটিভ এআই ইনকিউবেটর, AWS-এর একজন ফলিত বিজ্ঞানী। প্রাকৃতিক ভাষা প্রক্রিয়াকরণ, সময় সিরিজ বিশ্লেষণ, এবং ভবিষ্যদ্বাণীমূলক রক্ষণাবেক্ষণ সহ মেশিন লার্নিং-এ ধারণার বিভিন্ন প্রমাণের উপর শিল্প জুড়ে বিভিন্ন সংস্থার সাথে কাজ করার অভিজ্ঞতা রয়েছে তার। তার অবসর সময়ে, তিনি সাঁতার কাটা, চিত্রাঙ্কন, হাইকিং এবং পরিবার এবং বন্ধুদের সাথে সময় কাটাতে উপভোগ করেন।
 হাওঝু ওয়াং অ্যামাজন বেডরকের একজন গবেষণা বিজ্ঞানী অ্যামাজনের টাইটান ফাউন্ডেশন মডেল তৈরির দিকে মনোনিবেশ করছেন। পূর্বে তিনি রিইনফোর্সমেন্ট লার্নিং ভার্টিক্যালের সহ-প্রধান হিসেবে অ্যামাজন এমএল সলিউশন ল্যাবে কাজ করেছেন এবং রিইনফোর্সমেন্ট লার্নিং, ন্যাচারাল ল্যাঙ্গুয়েজ প্রসেসিং এবং গ্রাফ লার্নিং-এর উপর সর্বশেষ গবেষণার মাধ্যমে গ্রাহকদের উন্নত এমএল সমাধান তৈরি করতে সাহায্য করেছেন। হাওঝু মিশিগান ইউনিভার্সিটি থেকে ইলেকট্রিক্যাল অ্যান্ড কম্পিউটার ইঞ্জিনিয়ারিংয়ে পিএইচডি ডিগ্রি লাভ করেন।
হাওঝু ওয়াং অ্যামাজন বেডরকের একজন গবেষণা বিজ্ঞানী অ্যামাজনের টাইটান ফাউন্ডেশন মডেল তৈরির দিকে মনোনিবেশ করছেন। পূর্বে তিনি রিইনফোর্সমেন্ট লার্নিং ভার্টিক্যালের সহ-প্রধান হিসেবে অ্যামাজন এমএল সলিউশন ল্যাবে কাজ করেছেন এবং রিইনফোর্সমেন্ট লার্নিং, ন্যাচারাল ল্যাঙ্গুয়েজ প্রসেসিং এবং গ্রাফ লার্নিং-এর উপর সর্বশেষ গবেষণার মাধ্যমে গ্রাহকদের উন্নত এমএল সমাধান তৈরি করতে সাহায্য করেছেন। হাওঝু মিশিগান ইউনিভার্সিটি থেকে ইলেকট্রিক্যাল অ্যান্ড কম্পিউটার ইঞ্জিনিয়ারিংয়ে পিএইচডি ডিগ্রি লাভ করেন।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- PlatoData.Network উল্লম্ব জেনারেটিভ Ai. নিজেকে ক্ষমতায়িত করুন। এখানে প্রবেশ করুন.
- প্লেটোএআইস্ট্রিম। Web3 ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- প্লেটোইএসজি। মোটরগাড়ি / ইভি, কার্বন, ক্লিনটেক, শক্তি, পরিবেশ সৌর, বর্জ্য ব্যবস্থাপনা. এখানে প্রবেশ করুন.
- প্লেটো হেলথ। বায়োটেক এবং ক্লিনিক্যাল ট্রায়াল ইন্টেলিজেন্স। এখানে প্রবেশ করুন.
- চার্টপ্রাইম। ChartPrime এর সাথে আপনার ট্রেডিং গেমটি উন্নত করুন। এখানে প্রবেশ করুন.
- ব্লকঅফসেট। পরিবেশগত অফসেট মালিকানার আধুনিকীকরণ। এখানে প্রবেশ করুন.
- উত্স: https://aws.amazon.com/blogs/machine-learning/optimize-equipment-performance-with-historical-data-ray-and-amazon-sagemaker/

