গ্রাহকরা ক্রমবর্ধমান যেমন গভীর শিক্ষা পদ্ধতি ব্যবহার করতে চান বড় ভাষার মডেল (LLMs) তথ্য এবং অন্তর্দৃষ্টি নিষ্কাশন স্বয়ংক্রিয় করতে. অনেক শিল্পের জন্য, মেশিন লার্নিং (ML) এর জন্য উপযোগী ডেটাতে ব্যক্তিগতভাবে শনাক্তযোগ্য তথ্য (PII) থাকতে পারে। গ্রাহকের গোপনীয়তা নিশ্চিত করতে এবং প্রশিক্ষণ, ফাইন-টিউনিং এবং ডিপ লার্নিং মডেল ব্যবহার করার সময় নিয়ন্ত্রক সম্মতি বজায় রাখতে, প্রায়শই উৎস ডেটা থেকে প্রথমে PII সংশোধন করা প্রয়োজন।
এই পোস্টটি কীভাবে ব্যবহার করবেন তা প্রদর্শন করে অ্যামাজন সেজমেকার ডেটা র্যাংলার এবং অ্যামাজন সমঝোতা আপনার অংশ হিসাবে ট্যাবুলার ডেটা থেকে স্বয়ংক্রিয়ভাবে PII সংশোধন করতে মেশিন লার্নিং অপারেশন (ML Ops) কর্মপ্রবাহ।
সমস্যা: ML ডেটা যাতে PII রয়েছে৷
PII তথ্যের কোনো উপস্থাপনা হিসাবে সংজ্ঞায়িত করা হয় যা একজন ব্যক্তির পরিচয়ের অনুমতি দেয় যার কাছে তথ্যটি প্রত্যক্ষ বা পরোক্ষ উপায়ে যুক্তিসঙ্গতভাবে অনুমান করা যায়। PII হল এমন তথ্য যা হয় সরাসরি একজন ব্যক্তিকে শনাক্ত করে (নাম, ঠিকানা, সামাজিক নিরাপত্তা নম্বর বা অন্য শনাক্তকারী নম্বর বা কোড, টেলিফোন নম্বর, ইমেল ঠিকানা ইত্যাদি) অথবা এমন তথ্য যা একটি সংস্থা অন্যদের সাথে একত্রে নির্দিষ্ট ব্যক্তিদের সনাক্ত করতে ব্যবহার করতে চায়। তথ্য উপাদান, যথা, পরোক্ষ সনাক্তকরণ.
ব্যবসায়িক ডোমেনে গ্রাহকরা যেমন আর্থিক, খুচরা, আইনি, এবং সরকার নিয়মিতভাবে PII ডেটার সাথে ডিল করে। বিভিন্ন সরকারী প্রবিধান এবং নিয়মের কারণে, গ্রাহকদের নিয়ন্ত্রক জরিমানা, সম্ভাব্য জালিয়াতি এবং মানহানি এড়াতে যথাযথ নিরাপত্তা ব্যবস্থা সহ এই সংবেদনশীল ডেটা পরিচালনা করার জন্য একটি পদ্ধতি খুঁজে বের করতে হবে। PII রিডাকশন হল একটি নথি থেকে সংবেদনশীল তথ্যকে মুখোশ বা অপসারণ করার প্রক্রিয়া যাতে এটি ব্যবহার এবং বিতরণ করা যায়, যদিও এখনও গোপনীয় তথ্য সুরক্ষিত থাকে।
এমএল ব্যবহার করে ব্যবসায়িকদের আনন্দদায়ক গ্রাহক অভিজ্ঞতা এবং আরও ভালো ব্যবসায়িক ফলাফল প্রদান করতে হবে। PII ডেটার রিডাকশন প্রায়ই বৃহত্তর এবং সমৃদ্ধ ডেটা স্ট্রীমগুলি ব্যবহার বা সূক্ষ্ম-টিউন করার জন্য প্রয়োজনীয় প্রথম পদক্ষেপ। জেনারেটিভ এআই মডেল, তাদের এন্টারপ্রাইজ ডেটা (বা তাদের গ্রাহকদের) আপস করা হবে কিনা তা নিয়ে চিন্তা না করে।
সমাধান ওভারভিউ
এই সমাধানটি একটি নমুনা ডেটাসেট থেকে স্বয়ংক্রিয়ভাবে PII ডেটা সংশোধন করতে Amazon Comprehend এবং SageMaker Data Wrangler ব্যবহার করে।
Amazon Comprehend হল একটি ন্যাচারাল ল্যাঙ্গুয়েজ প্রসেসিং (NLP) পরিষেবা যা ML ব্যবহার করে অসংগঠিত ডেটাতে অন্তর্দৃষ্টি এবং সম্পর্কগুলি উন্মোচন করতে, কোন পরিকাঠামো পরিচালনা বা ML অভিজ্ঞতার প্রয়োজন নেই৷ এটি সনাক্ত করার কার্যকারিতা প্রদান করে বিভিন্ন PII সত্তা প্রকার পাঠ্যের মধ্যে, উদাহরণস্বরূপ নাম বা ক্রেডিট কার্ড নম্বর। যদিও সাম্প্রতিক জেনারেটিভ এআই মডেলগুলি কিছু PII রিডাকশন ক্ষমতা প্রদর্শন করেছে, তারা সাধারণত PII শনাক্তকরণ বা স্ট্রাকচার্ড ডেটার জন্য কোন কনফিডেন্স স্কোর প্রদান করে না যা সংশোধন করা হয়েছে তা বর্ণনা করে। Amazon Comprehend-এর PII কার্যকারিতা উভয়ই ফেরত দেয়, আপনাকে রিডাকশন ওয়ার্কফ্লো তৈরি করতে সক্ষম করে যা স্কেলে সম্পূর্ণরূপে নিরীক্ষণযোগ্য। অতিরিক্তভাবে, অ্যামাজন কম্প্রেহেন্ড ব্যবহার করে AWS প্রাইভেট লিঙ্ক মানে গ্রাহকের ডেটা কখনই AWS নেটওয়ার্ক ছেড়ে যায় না এবং আপনার বাকি অ্যাপ্লিকেশনগুলির মতো একই ডেটা অ্যাক্সেস এবং গোপনীয়তা নিয়ন্ত্রণের সাথে ক্রমাগত সুরক্ষিত থাকে৷
আমাজন বোঝার অনুরূপ, অ্যামাজন ম্যাকি সংরক্ষিত সংবেদনশীল ডেটা (পিআইআই সহ) সনাক্ত করতে একটি নিয়ম-ভিত্তিক ইঞ্জিন ব্যবহার করে আমাজন সিম্পল স্টোরেজ সার্ভিস (Amazon S3)। যাইহোক, এর নিয়ম-ভিত্তিক পদ্ধতি নির্দিষ্ট কীওয়ার্ড থাকার উপর নির্ভর করে যা সেই ডেটার কাছাকাছি অবস্থিত সংবেদনশীল ডেটা নির্দেশ করে (30 অক্ষরের মধ্যে) বিপরীতে, Amazon Comprehend-এর NLP-ভিত্তিক ML পন্থা PII শনাক্ত করতে টেক্সটের দীর্ঘ অংশের সেম্যাটিক বোঝাপড়া ব্যবহার করে, এটিকে অসংগঠিত ডেটার মধ্যে PII খোঁজার জন্য আরও উপযোগী করে তোলে।
উপরন্তু, CSV বা প্লেইন টেক্সট ফাইলের মতো ট্যাবুলার ডেটার জন্য, Macie কম বিস্তারিত অবস্থানের তথ্য প্রদান করে Amazon Comprehend (যথাক্রমে একটি সারি/কলাম সূচক বা একটি লাইন সংখ্যা, কিন্তু শুরু এবং শেষ অক্ষর অফসেট নয়) থেকে। এটি একটি সারণী বিন্যাসে সংরক্ষিত পিআইআই এবং নন-পিআইআই শব্দের মিশ্রণ (উদাহরণস্বরূপ, সমর্থন টিকিট বা এলএলএম প্রম্পট) ধারণ করতে পারে এমন অসংগঠিত পাঠ্য থেকে PII সংশোধন করার জন্য অ্যামাজন কম্প্রিহেন্ডকে বিশেষভাবে সহায়ক করে তোলে।
আমাজন সেজমেকার ML লাইফসাইকেল জুড়ে প্রসেসগুলিকে স্বয়ংক্রিয় এবং মানসম্মত করার জন্য ML টিমের জন্য উদ্দেশ্য-নির্মিত সরঞ্জাম সরবরাহ করে। SageMaker MLOps সরঞ্জামগুলির সাহায্যে, দলগুলি সহজেই এমএল মডেলগুলি প্রস্তুত, প্রশিক্ষণ, পরীক্ষা, সমস্যা সমাধান, স্থাপন এবং পরিচালনা করতে পারে, উত্পাদনে মডেলের কার্যকারিতা বজায় রেখে ডেটা বিজ্ঞানী এবং এমএল ইঞ্জিনিয়ারদের উত্পাদনশীলতা বাড়ায়। নিম্নলিখিত চিত্রটি SageMaker MLOps কর্মপ্রবাহকে চিত্রিত করে৷
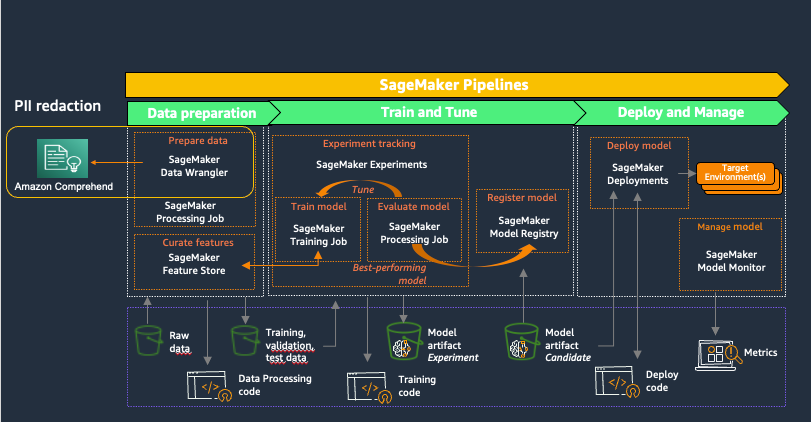
SageMaker Data Wrangler এর একটি বৈশিষ্ট্য অ্যামাজন সেজমেকার স্টুডিও যা Amazon S3 এর মতো অবস্থানে সংরক্ষিত ডেটাসেট আমদানি, প্রস্তুত, রূপান্তর, বৈশিষ্ট্যযুক্ত এবং বিশ্লেষণের জন্য একটি শেষ থেকে শেষ সমাধান প্রদান করে অ্যামাজন অ্যাথেনা, ML জীবনচক্রের একটি সাধারণ প্রথম ধাপ। আপনি বিল্ট-ইন, নো-কোড ট্রান্সফরমেশন ব্যবহার করে বা আপনার নিজস্ব পাইথন স্ক্রিপ্টগুলির সাথে কাস্টমাইজ করে ডেটাসেট প্রিপ্রসেসিং এবং বৈশিষ্ট্য ইঞ্জিনিয়ারিংকে সরল এবং প্রবাহিত করতে সেজমেকার ডেটা র্যাংলার ব্যবহার করতে পারেন।
একটি SageMaker ডেটা র্যাংলার ডেটা প্রস্তুতির কর্মপ্রবাহের অংশ হিসাবে PII সংশোধন করতে Amazon Comprehend ব্যবহার করে ডেটার সমস্ত ডাউনস্ট্রিম ব্যবহার যেমন মডেল প্রশিক্ষণ বা অনুমান, আপনার প্রতিষ্ঠানের PII প্রয়োজনীয়তার সাথে সারিবদ্ধভাবে রাখে৷ আপনি সেজমেকার ডেটা র্যাংলারের সাথে একীভূত করতে পারেন অ্যামাজন সেজমেকার পাইপলাইন ডেটা প্রস্তুতি এবং PII রিডাকশন সহ এন্ড-টু-এন্ড ML অপারেশন স্বয়ংক্রিয় করতে। আরো বিস্তারিত জানার জন্য, পড়ুন সেজমেকার পাইপলাইনগুলির সাথে সেজমেকার ডেটা র্যাংলারকে একীভূত করা. এই পোস্টের বাকি অংশটি একটি SageMaker ডেটা র্যাংলার প্রবাহ প্রদর্শন করে যা ট্যাবুলার ডেটা বিন্যাসে সংরক্ষিত পাঠ্য থেকে PII সংশোধন করতে Amazon Comprehend ব্যবহার করে।
এই সমাধান একটি পাবলিক ব্যবহার করে সিন্থেটিক ডেটাসেট একটি কাস্টম সেজমেকার ডেটা র্যাংলার ফ্লো সহ, একটি ফাইল হিসাবে উপলব্ধ GitHub. পিআইআই সংশোধন করতে সেজমেকার ডেটা র্যাংলার ফ্লো ব্যবহার করার পদক্ষেপগুলি নিম্নরূপ:
- সেজমেকার স্টুডিও খুলুন।
- সেজমেকার ডেটা র্যাংলার ফ্লো ডাউনলোড করুন।
- সেজমেকার ডেটা র্যাংলার প্রবাহ পর্যালোচনা করুন।
- একটি গন্তব্য নোড যোগ করুন।
- একটি সেজমেকার ডেটা র্যাংলার এক্সপোর্ট কাজ তৈরি করুন।
রপ্তানি কাজ চালানো সহ এই ওয়াকথ্রুটি সম্পূর্ণ হতে 20-25 মিনিট সময় নিতে হবে।
পূর্বশর্ত
এই ওয়াকথ্রুটির জন্য আপনার নিম্নলিখিতগুলি থাকা উচিত:
সেজমেকার স্টুডিও খুলুন
SageMaker স্টুডিও খুলতে, নিম্নলিখিত পদক্ষেপগুলি সম্পূর্ণ করুন:
- সেজমেকার কনসোলে, নির্বাচন করুন স্টুডিও নেভিগেশন ফলকে।
- ডোমেন এবং ব্যবহারকারী প্রোফাইল চয়ন করুন
- বেছে নিন ওপেন স্টুডিও.
SageMaker Data Wrangler-এর নতুন ক্ষমতার সাথে শুরু করার জন্য, এটি সুপারিশ করা হয় সর্বশেষ রিলিজে আপগ্রেড করুন.
সেজমেকার ডেটা র্যাংলার ফ্লো ডাউনলোড করুন
আপনাকে প্রথমে গিটহাব থেকে সেজমেকার ডেটা র্যাংলার ফ্লো ফাইলটি পুনরুদ্ধার করতে হবে এবং এটিকে সেজমেকার স্টুডিওতে আপলোড করতে হবে। নিম্নলিখিত পদক্ষেপগুলি সম্পূর্ণ করুন:
- সেজমেকার ডেটা র্যাংলারে নেভিগেট করুন
redact-pii.flowGitHub এ ফাইল। - GitHub-এ, আপনার স্থানীয় কম্পিউটারে ফ্লো ফাইল ডাউনলোড করতে ডাউনলোড আইকনটি বেছে নিন।
- সেজমেকার স্টুডিওতে, নেভিগেশন প্যানে ফাইল আইকনটি বেছে নিন।
- আপলোড আইকন চয়ন করুন, তারপর চয়ন করুন
redact-pii.flow.
সেজমেকার ডেটা র্যাংলার প্রবাহ পর্যালোচনা করুন
SageMaker স্টুডিওতে, খুলুন redact-pii.flow. কয়েক মিনিট পরে, প্রবাহটি লোড করা শেষ করবে এবং প্রবাহ চিত্রটি দেখাবে (নিম্নলিখিত স্ক্রিনশটটি দেখুন)। প্রবাহে ছয়টি ধাপ রয়েছে: একটি S3 উৎস পাঁচটি রূপান্তর ধাপ অনুসরণ করে ধাপ।

ফ্লো ডায়াগ্রামে, শেষ ধাপটি বেছে নিন, PII রিডাক্ট করুন. দ্য সমস্ত পদক্ষেপ প্যান ডানদিকে খোলে এবং প্রবাহের ধাপগুলির একটি তালিকা দেখায়। আপনি বিস্তারিত দেখতে, প্যারামিটার পরিবর্তন করতে এবং সম্ভাব্য কাস্টম কোড যোগ করতে প্রতিটি ধাপ প্রসারিত করতে পারেন।
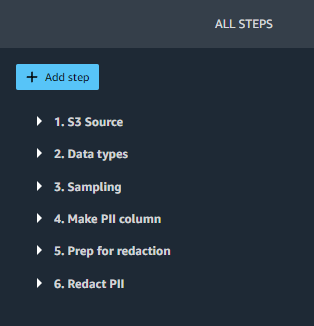
চলুন প্রবাহের প্রতিটি ধাপে হেঁটে যাই।
ধাপ 1 (S3 উৎস) এবং 2 (তথ্যের ধরণ) SageMaker Data Wrangler দ্বারা যোগ করা হয় যখনই একটি নতুন প্রবাহের জন্য ডেটা আমদানি করা হয়। ভিতরে S3 উৎস, দ্য S3 URI ক্ষেত্রটি নমুনা ডেটাসেটের দিকে নির্দেশ করে, যা Amazon S3 এ সংরক্ষিত একটি CSV ফাইল। ফাইলটিতে প্রায় 116,000 সারি রয়েছে এবং প্রবাহটি এর মান নির্ধারণ করে আদর্শ ফিল্ড 1,000, যার মানে SageMaker ডেটা র্যাংলার ইউজার ইন্টারফেসে প্রদর্শনের জন্য 1,000 সারি নমুনা করবে। তথ্যের ধরণ আমদানি করা ডেটার প্রতিটি কলামের জন্য ডেটা টাইপ সেট করে।
ধাপ ২ (আদর্শ) সেজমেকার ডেটা র্যাংলার একটি রপ্তানি কাজের জন্য সারির সংখ্যা 5,000 সেট করে আনুমানিক নমুনা আকার ক্ষেত্র মনে রাখবেন যে এটি ব্যবহারকারী ইন্টারফেসে প্রদর্শনের জন্য নমুনাযুক্ত সারির সংখ্যা থেকে আলাদা (ধাপ 1)। আরও সারি সহ ডেটা এক্সপোর্ট করতে, আপনি এই সংখ্যা বাড়াতে পারেন বা ধাপ 3 সরাতে পারেন।
ধাপ 4, 5, এবং 6 ব্যবহার করুন সেজমেকার ডেটা র্যাংলার কাস্টম রূপান্তর. কাস্টম রূপান্তরগুলি আপনাকে ডেটা র্যাংলার প্রবাহের মধ্যে আপনার নিজস্ব পাইথন বা SQL কোড চালানোর অনুমতি দেয়। কাস্টম কোড চারটি উপায়ে লেখা যেতে পারে:
- এসকিউএল-এ, ডেটাসেট পরিবর্তন করতে PySpark SQL ব্যবহার করে
- পাইথনে, ডেটাসেট পরিবর্তন করতে একটি PySpark ডেটা ফ্রেম এবং লাইব্রেরি ব্যবহার করে
- পাইথনে, একটি ব্যবহার করে পান্ডাস ডেটাসেট পরিবর্তন করতে ডেটা ফ্রেম এবং লাইব্রেরি
- পাইথনে, ডেটাসেটের একটি কলাম পরিবর্তন করতে একটি ব্যবহারকারী-সংজ্ঞায়িত ফাংশন ব্যবহার করে
পাইথন (পান্ডাস) পদ্ধতির জন্য আপনার ডেটাসেটকে মেমরিতে ফিট করতে হবে এবং এটি কেবলমাত্র একটি একক উদাহরণে চালানো যেতে পারে, দক্ষতার সাথে স্কেল করার ক্ষমতা সীমিত করে। বৃহত্তর ডেটাসেটের সাথে পাইথনে কাজ করার সময়, আমরা পাইথন (PySpark) বা পাইথন (ব্যবহারকারী-সংজ্ঞায়িত ফাংশন) পদ্ধতি ব্যবহার করার পরামর্শ দিই। সেজমেকার ডেটা র্যাংলার পাইথন ব্যবহারকারী-সংজ্ঞায়িত ফাংশন অপ্টিমাইজ করে একটি Apache Spark প্লাগইনের মত কর্মক্ষমতা প্রদান করতে, PySpark বা Pandas জানার প্রয়োজন ছাড়াই। এই সমাধানটিকে যতটা সম্ভব অ্যাক্সেসযোগ্য করার জন্য, এই পোস্টটি বিশুদ্ধ পাইথনে লেখা একটি পাইথন ব্যবহারকারী-সংজ্ঞায়িত ফাংশন ব্যবহার করে।
ধাপ 4 প্রসারিত করুন (PII কলাম তৈরি করুন) এর বিশদ বিবরণ দেখতে। এই ধাপটি একাধিক কলাম থেকে বিভিন্ন ধরনের PII ডেটা একত্রিত করে একটি একক বাক্যাংশে যা একটি নতুন কলামে সংরক্ষিত হয়, pii_col. নিম্নলিখিত সারণীটি ডেটা সহ একটি উদাহরণ সারি দেখায়।
| ক্রেতার নাম | গ্রাহক_চাকরি | বিলিং_ঠিকানা | গ্রাহক_ইমেল |
| কেটি | সাংবাদিক | 19009 ভ্যাং স্কোয়ার স্যুট 805 | [ইমেল সুরক্ষিত] |
এটি এই বাক্যাংশের সাথে মিলিত হয়েছে "কেটি একজন সাংবাদিক যিনি 19009 Vang Squares Suite 805-এ থাকেন এবং এখানে ইমেল করা যেতে পারে [ইমেল সুরক্ষিত]” শব্দগুচ্ছ সংরক্ষিত হয় pii_col, যা এই পোস্টটি সংশোধিত করার লক্ষ্য কলাম হিসাবে ব্যবহার করে।
ধাপ ২ (সংশোধনের জন্য প্রস্তুতি নিন) সংশোধন করতে একটি কলাম লাগে (pii_col) এবং একটি নতুন কলাম তৈরি করে (pii_col_prep) যেটি অ্যামাজন কম্প্রেহেন্ড ব্যবহার করে কার্যকরী সংশোধনের জন্য প্রস্তুত। একটি ভিন্ন কলাম থেকে PII সংশোধন করতে, আপনি পরিবর্তন করতে পারেন৷ ইনপুট কলাম এই ধাপের ক্ষেত্র।
Amazon Comprehend ব্যবহার করে দক্ষতার সাথে ডেটা রিডাক্ট করার জন্য দুটি বিষয় বিবেচনা করতে হবে:
- সার্জারির PII সনাক্ত করতে খরচ প্রতি-ইউনিট ভিত্তিতে সংজ্ঞায়িত করা হয়, যেখানে 1 ইউনিট = 100 অক্ষর, প্রতিটি নথির জন্য 3-ইউনিট ন্যূনতম চার্জ সহ। যেহেতু ট্যাবুলার ডেটাতে প্রায়ই প্রতি কক্ষে অল্প পরিমাণে পাঠ্য থাকে, তাই অ্যামাজন কম্প্রিহেন্ডে পাঠানোর জন্য একাধিক কোষ থেকে পাঠ্য একত্রিত করা সাধারণত বেশি সময়- এবং খরচ-দক্ষ। এটি করা অনেক পুনরাবৃত্ত ফাংশন কল থেকে ওভারহেড জমা হওয়া এড়ায় এবং নিশ্চিত করে যে পাঠানো ডেটা সর্বদা 3-ইউনিট ন্যূনতম থেকে বেশি।
- যেহেতু আমরা সেজমেকার ডেটা র্যাংলার প্রবাহের এক ধাপ হিসেবে রিডাকশন করছি, তাই আমরা অ্যামাজন কম্প্রেহেন্ডকে সিঙ্ক্রোনাসভাবে কল করব। Amazon Comprehend সেট ক 100 KB (100,000 অক্ষর) সীমা প্রতি সিঙ্ক্রোনাস ফাংশন কল, তাই আমাদের নিশ্চিত করতে হবে যে আমরা যে কোনও পাঠ্য পাঠাই সেই সীমার মধ্যে।
এই বিষয়গুলির প্রেক্ষিতে, ধাপ 5 প্রতিটি কক্ষে পাঠ্যের শেষে একটি বিভেদক স্ট্রিং যুক্ত করে Amazon Comprehend-এ পাঠানোর জন্য ডেটা প্রস্তুত করে। ডিলিমিটারের জন্য, আপনি যে কোনও স্ট্রিং ব্যবহার করতে পারেন যা কলামে সংশোধিত হয় না (আদর্শভাবে, একটি যেটি যতটা সম্ভব কম অক্ষর, কারণ সেগুলি Amazon Comprehend ক্যারেক্টারের মোট অন্তর্ভুক্ত)। এই সেল ডিলিমিটার যোগ করার ফলে আমরা অ্যামাজন কম্প্রিহেন্ডে কলটি অপ্টিমাইজ করতে পারি এবং ধাপ 6 এ আরও আলোচনা করা হবে।
মনে রাখবেন যে কোনও পৃথক কক্ষের পাঠ্যটি যদি অ্যামাজন বোঝার সীমার চেয়ে দীর্ঘ হয়, তবে এই ধাপে কোডটি 100,000 অক্ষরে (মোটামুটিভাবে 15,000 শব্দ বা 30টি একক-স্পেসযুক্ত পৃষ্ঠার সমতুল্য)। যদিও এই পরিমাণ পাঠ্য একটি একক কক্ষে সংরক্ষিত হওয়ার সম্ভাবনা নেই, আপনি প্রয়োজনে এই প্রান্তের ক্ষেত্রে অন্য উপায়ে পরিচালনা করতে রূপান্তর কোডটি পরিবর্তন করতে পারেন।
ধাপ ২ (PII রিডাক্ট করুন) ইনপুট হিসাবে সংশোধন করতে একটি কলামের নাম নেয় (pii_col_prep) এবং সংশোধিত পাঠ্যটিকে একটি নতুন কলামে সংরক্ষণ করে (pii_redacted) আপনি যখন পাইথন কাস্টম ফাংশন ট্রান্সফর্ম ব্যবহার করেন, তখন সেজমেকার ডেটা র্যাংলার একটি খালি সংজ্ঞায়িত করে custom_func যে একটি পান্ডা লাগে ক্রম (টেক্সটের একটি কলাম) ইনপুট হিসাবে এবং একই দৈর্ঘ্যের একটি পরিবর্তিত পান্ডাস সিরিজ প্রদান করে। নিম্নলিখিত স্ক্রিনশট এর অংশ দেখায় PII রিডাক্ট করুন ধাপ।
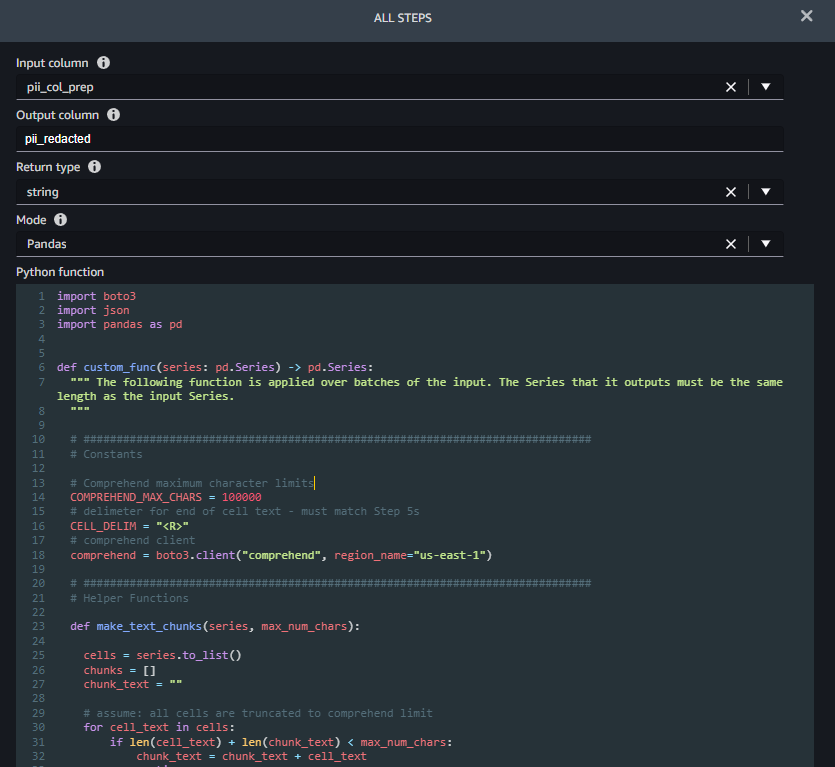
কাজ custom_func দুটি সহায়ক (অভ্যন্তরীণ) ফাংশন রয়েছে:
make_text_chunks– এই ফাংশনটি অ্যামাজন কম্প্রিহেন্ডে পাঠানোর জন্য সিরিজের (তাদের সীমানা সহ) পৃথক কোষ থেকে পাঠ্যকে আরও লম্বা স্ট্রিংগুলিতে (খণ্ডে) সংযুক্ত করার কাজ করে।redact_pii– এই ফাংশনটি পাঠ্যকে ইনপুট হিসাবে গ্রহণ করে, পিআইআই সনাক্ত করতে অ্যামাজন কম্প্রেহেন্ডকে কল করে, যে কোনওটি পাওয়া যায় তা সংশোধন করে এবং সংশোধিত পাঠ্য ফেরত দেয়। বর্গাকার বন্ধনীতে পাওয়া PII প্রকারের সাথে যেকোনো PII টেক্সট প্রতিস্থাপন করে সংশোধন করা হয়, উদাহরণস্বরূপ জন স্মিথকে [NAME] দিয়ে প্রতিস্থাপন করা হবে। আপনি PII কে যেকোন স্ট্রিং দিয়ে প্রতিস্থাপন করতে এই ফাংশনটি পরিবর্তন করতে পারেন, এটিকে সরানোর জন্য খালি স্ট্রিং ("") সহ। এছাড়াও আপনি প্রতিটি PII সত্তার আত্মবিশ্বাসের স্কোর পরীক্ষা করার জন্য ফাংশনটি পরিবর্তন করতে পারেন এবং শুধুমাত্র যদি এটি একটি নির্দিষ্ট থ্রেশহোল্ডের উপরে থাকে তবেই সংশোধন করতে পারেন।
অভ্যন্তরীণ ফাংশন সংজ্ঞায়িত করার পরে, custom_func নিম্নলিখিত কোড উদ্ধৃতিতে দেখানো হিসাবে, সংশোধিত করতে তাদের ব্যবহার করে। রিডাকশন সম্পূর্ণ হলে, এটি অংশগুলিকে মূল কোষে রূপান্তরিত করে, যা এটি সংরক্ষণ করে pii_redacted কলাম।
একটি গন্তব্য নোড যোগ করুন
আপনার রূপান্তরের ফলাফল দেখতে, SageMaker Data Wrangler Amazon S3, SageMaker Pipelines, এ রপ্তানি করা সমর্থন করে আমাজন সেজমেকার ফিচার স্টোর, এবং পাইথন কোড। অ্যামাজন S3 এ সংশোধিত ডেটা রপ্তানি করতে, আমাদের প্রথমে একটি গন্তব্য নোড তৈরি করতে হবে:
- সেজমেকার ডেটা র্যাংলার ফ্লো ডায়াগ্রামে, পাশের প্লাস চিহ্নটি বেছে নিন PII রিডাক্ট করুন ধাপ।
- বেছে নিন গন্তব্য যোগ করুন, তাহলে বেছে নাও আমাজন S3.
- আপনার রূপান্তরিত ডেটাসেটের জন্য একটি আউটপুট নাম প্রদান করুন।
- সংশোধিত ডেটা ফাইল সংরক্ষণ করতে ব্রাউজ করুন বা S3 অবস্থান লিখুন।
- বেছে নিন গন্তব্য যোগ করুন.
আপনার এখন আপনার ডেটা প্রবাহের শেষে গন্তব্য নোডটি দেখতে হবে।
একটি সেজমেকার ডেটা র্যাংলার এক্সপোর্ট কাজ তৈরি করুন
এখন গন্তব্য নোড যোগ করা হয়েছে, আমরা ডেটাসেট প্রক্রিয়া করার জন্য রপ্তানি কাজ তৈরি করতে পারি:
- সেজমেকার ডেটা র্যাংলারে, নির্বাচন করুন চাকরি তৈরি করুন.
- আপনি যে গন্তব্য নোডটি যোগ করেছেন তা ইতিমধ্যেই নির্বাচন করা উচিত। পছন্দ করা পরবর্তী.
- অন্য সব বিকল্পের জন্য ডিফল্ট গ্রহণ করুন, তারপর নির্বাচন করুন চালান.
এটি তৈরি করে a সেজমেকার প্রসেসিং কাজ. কাজের স্থিতি দেখতে, SageMaker কনসোলে নেভিগেট করুন। নেভিগেশন ফলকে, প্রসারিত করুন প্রসেসিং বিভাগ এবং নির্বাচন করুন কাজ প্রক্রিয়াকরণ. ডিফল্ট রপ্তানি কাজের সেটিংস ব্যবহার করে লক্ষ্য কলামের সমস্ত 116,000 কোষগুলিকে রিড্যাক্ট করতে প্রায় 5.4 মিনিট সময় লাগে এবং প্রায় $8 খরচ হয়৷ কাজ শেষ হলে, আউটপুট ফাইলটি ডাউনলোড করুন আমাজন S0.25 থেকে রিডাক্ট করা কলাম সহ।
পরিষ্কার কর
SageMaker Data Wrangler অ্যাপ্লিকেশনটি একটি ml.m5.4xlarge ইন্সট্যান্সে চলে। এটি বন্ধ করতে, সেজমেকার স্টুডিওতে, নির্বাচন করুন টার্মিনাল এবং কার্নেল চলমান নেভিগেশন ফলকে। মধ্যে চলমান উদাহরণ বিভাগে, লেবেলযুক্ত উদাহরণ খুঁজুন ডেটা র্যাংলার এবং এর পাশে শাটডাউন আইকনটি নির্বাচন করুন। এটি উদাহরণে চলমান SageMaker ডেটা র্যাংলার অ্যাপ্লিকেশনটিকে বন্ধ করে দেয়।
উপসংহার
এই পোস্টে, আমরা আলোচনা করেছি কিভাবে সেজমেকার ডেটা র্যাংলার এবং অ্যামাজন কম্প্রেহেন্ড-এ কাস্টম রূপান্তর ব্যবহার করে আপনার ML ডেটাসেট থেকে PII ডেটা রিডাক্ট করতে হয়। তুমি পারবে ডাউনলোড SageMaker ডেটা র্যাংলার ফ্লো এবং আজই আপনার ট্যাবুলার ডেটা থেকে PII সংশোধন করা শুরু করুন।
SageMaker ডেটা র্যাংলার কাস্টম রূপান্তর ব্যবহার করে আপনার MLOps ওয়ার্কফ্লো উন্নত করার অন্যান্য উপায়ের জন্য, চেক আউট করুন NLTK এবং SciPy ব্যবহার করে Amazon SageMaker Data Wrangler-এ কাস্টম রূপান্তর লেখা হচ্ছে. আরও ডেটা প্রস্তুতির বিকল্পগুলির জন্য, ব্লগ পোস্ট সিরিজটি দেখুন যা ব্যাখ্যা করে যে কীভাবে অ্যামাজন কম্প্রেহেন্ড ব্যবহার করতে হয় প্রতিক্রিয়া, অনুবাদ এবং উভয়ের পাঠ্য বিশ্লেষণ করতে অ্যামাজন অ্যাথেনা or আমাজন রেডশিফ্ট.
লেখক সম্পর্কে
 ট্রিসিয়া জেমিসন তিনি AWS প্রোটোটাইপিং এবং ক্লাউড অ্যাক্সিলারেশন (PACE) টিমের একজন সিনিয়র প্রোটোটাইপিং আর্কিটেক্ট, যেখানে তিনি AWS গ্রাহকদের মেশিন লার্নিং, ইন্টারনেট অফ থিংস (IoT) এবং সার্ভারহীন প্রযুক্তির সাথে চ্যালেঞ্জিং সমস্যার উদ্ভাবনী সমাধান বাস্তবায়নে সহায়তা করেন। তিনি নিউ ইয়র্ক সিটিতে থাকেন এবং বাস্কেটবল, দীর্ঘ দূরত্বের ট্রেক এবং তার সন্তানদের থেকে এক ধাপ এগিয়ে থাকা উপভোগ করেন।
ট্রিসিয়া জেমিসন তিনি AWS প্রোটোটাইপিং এবং ক্লাউড অ্যাক্সিলারেশন (PACE) টিমের একজন সিনিয়র প্রোটোটাইপিং আর্কিটেক্ট, যেখানে তিনি AWS গ্রাহকদের মেশিন লার্নিং, ইন্টারনেট অফ থিংস (IoT) এবং সার্ভারহীন প্রযুক্তির সাথে চ্যালেঞ্জিং সমস্যার উদ্ভাবনী সমাধান বাস্তবায়নে সহায়তা করেন। তিনি নিউ ইয়র্ক সিটিতে থাকেন এবং বাস্কেটবল, দীর্ঘ দূরত্বের ট্রেক এবং তার সন্তানদের থেকে এক ধাপ এগিয়ে থাকা উপভোগ করেন।
 নীলম কোশিয়া AWS-এর একজন এন্টারপ্রাইজ সলিউশন আর্কিটেক্ট। সফ্টওয়্যার প্রকৌশলের পটভূমির সাথে, তিনি অর্গানিকভাবে একটি স্থাপত্য ভূমিকায় চলে আসেন। তার বর্তমান ফোকাস এন্টারপ্রাইজ গ্রাহকদের কৌশলগত ব্যবসায়িক ফলাফলের জন্য তাদের ক্লাউড গ্রহণের যাত্রায় সাহায্য করছে যার গভীরতা AI/ML হচ্ছে। তিনি উদ্ভাবন এবং অন্তর্ভুক্তি সম্পর্কে উত্সাহী. তার অবসর সময়ে, তিনি পড়া এবং বাইরে থাকা উপভোগ করেন।
নীলম কোশিয়া AWS-এর একজন এন্টারপ্রাইজ সলিউশন আর্কিটেক্ট। সফ্টওয়্যার প্রকৌশলের পটভূমির সাথে, তিনি অর্গানিকভাবে একটি স্থাপত্য ভূমিকায় চলে আসেন। তার বর্তমান ফোকাস এন্টারপ্রাইজ গ্রাহকদের কৌশলগত ব্যবসায়িক ফলাফলের জন্য তাদের ক্লাউড গ্রহণের যাত্রায় সাহায্য করছে যার গভীরতা AI/ML হচ্ছে। তিনি উদ্ভাবন এবং অন্তর্ভুক্তি সম্পর্কে উত্সাহী. তার অবসর সময়ে, তিনি পড়া এবং বাইরে থাকা উপভোগ করেন।
 অ্যাডেলেকে কোকার AWS সহ একজন গ্লোবাল সলিউশন আর্কিটেক্ট। তিনি বিশ্বব্যাপী গ্রাহকদের সাথে কাজ করে AWS-এ স্কেলে উৎপাদন কাজের লোড স্থাপনে নির্দেশনা এবং প্রযুক্তিগত সহায়তা প্রদান করতে। তার অবসর সময়ে, তিনি শেখা, পড়া, গেমিং এবং খেলাধুলার ইভেন্টগুলি দেখতে উপভোগ করেন।
অ্যাডেলেকে কোকার AWS সহ একজন গ্লোবাল সলিউশন আর্কিটেক্ট। তিনি বিশ্বব্যাপী গ্রাহকদের সাথে কাজ করে AWS-এ স্কেলে উৎপাদন কাজের লোড স্থাপনে নির্দেশনা এবং প্রযুক্তিগত সহায়তা প্রদান করতে। তার অবসর সময়ে, তিনি শেখা, পড়া, গেমিং এবং খেলাধুলার ইভেন্টগুলি দেখতে উপভোগ করেন।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- PlatoData.Network উল্লম্ব জেনারেটিভ Ai. নিজেকে ক্ষমতায়িত করুন। এখানে প্রবেশ করুন.
- প্লেটোএআইস্ট্রিম। Web3 ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- প্লেটোইএসজি। কার্বন, ক্লিনটেক, শক্তি, পরিবেশ সৌর, বর্জ্য ব্যবস্থাপনা. এখানে প্রবেশ করুন.
- প্লেটো হেলথ। বায়োটেক এবং ক্লিনিক্যাল ট্রায়াল ইন্টেলিজেন্স। এখানে প্রবেশ করুন.
- উত্স: https://aws.amazon.com/blogs/machine-learning/automatically-redact-pii-for-machine-learning-using-amazon-sagemaker-data-wrangler/

