এটি মেটার পাইটর্চ টিমের সাথে সহ-লেখা একটি অতিথি পোস্ট এবং এর ধারাবাহিকতা পার্ট 1 এই সিরিজের, যেখানে আমরা AWS-এ PyTorch 2.0 চালানোর পারফরম্যান্স এবং সহজতা প্রদর্শন করি।
মেশিন লার্নিং (এমএল) গবেষণা প্রমাণ করেছে যে উল্লেখযোগ্যভাবে বড় ডেটাসেটের সাথে প্রশিক্ষিত বড় ভাষা মডেল (এলএলএম) মডেলের গুণমান উন্নত করে। গত কয়েক বছরে, বর্তমান প্রজন্মের মডেলগুলির আকার উল্লেখযোগ্যভাবে বৃদ্ধি পেয়েছে, এবং তাদের দক্ষতার সাথে এবং স্কেলে প্রশিক্ষিত করার জন্য আধুনিক সরঞ্জাম এবং অবকাঠামো প্রয়োজন। পাইটর্চ ডিস্ট্রিবিউটেড ডেটা প্যারালেলিজম (ডিডিপি) সহজ এবং শক্তিশালী পদ্ধতিতে ডেটা প্রক্রিয়া করতে সহায়তা করে, তবে এটির জন্য মডেলটিকে একটি জিপিইউতে ফিট করতে হবে। PyTorch Fully Sharded Data Parallel (FSDP) লাইব্রেরি ডেটা সমান্তরাল কর্মীদের জুড়ে বড় মডেলদের প্রশিক্ষণের জন্য মডেল শার্ডিং সক্ষম করে এই বাধা ভেঙে দেয়।
বিতরণকৃত মডেল প্রশিক্ষণের জন্য কর্মী নোডগুলির একটি ক্লাস্টার প্রয়োজন যা স্কেল করতে পারে। অ্যামাজন ইলাস্টিক কুবারনেটস পরিষেবা (Amazon EKS) হল একটি জনপ্রিয় Kubernetes-conformant পরিষেবা যা AI/ML ওয়ার্কলোড চালানোর প্রক্রিয়াকে ব্যাপকভাবে সরল করে, এটিকে আরও পরিচালনাযোগ্য এবং কম সময়সাপেক্ষ করে তোলে।
এই ব্লগ পোস্টে, AWS আমাজন EKS ব্যবহার করে নির্বিঘ্নে AWS-এ গভীর শিক্ষার মডেলগুলির রৈখিক স্কেলিং অর্জনের জন্য PyTorch FSDP লাইব্রেরি কীভাবে ব্যবহার করতে হয় তা নিয়ে আলোচনা করতে মেটার পাইটর্চ টিমের সাথে সহযোগিতা করে এবং AWS ডিপ লার্নিং কন্টেইনার (DLCs)। আমরা 7 এর সাথে Amazon EKS ব্যবহার করে 13B, 70B, এবং 2B Llama16 মডেলের প্রশিক্ষণের ধাপে ধাপে বাস্তবায়নের মাধ্যমে এটি প্রদর্শন করি। অ্যামাজন ইলাস্টিক কম্পিউট ক্লাউড (আমাজন ইসি 2) p4de.24x বড় উদাহরণ (প্রতিটি 8টি NVIDIA A100 টেনসর কোর GPU এবং প্রতিটি GPU 80 GB HBM2e মেমরি সহ) বা 16 EC2 p5.48 বড় দৃষ্টান্ত (প্রতিটি 8টি NVIDIA H100 টেনসর কোর GPU এবং প্রতিটি GPU 80 GB HBM3 মেমরি সহ), থ্রুপুটে কাছাকাছি রৈখিক স্কেলিং অর্জন করা এবং শেষ পর্যন্ত দ্রুত প্রশিক্ষণের সময় সক্ষম করা।
নিম্নলিখিত স্কেলিং চার্ট দেখায় যে p5.48x বড় উদাহরণগুলি একটি 87-নোড ক্লাস্টার কনফিগারেশনে FSDP Llama2 ফাইন-টিউনিং সহ 16% স্কেলিং দক্ষতা প্রদান করে।

এলএলএম প্রশিক্ষণের চ্যালেঞ্জ
বিভিন্ন ধরনের অ্যাপ্লিকেশনে দক্ষতা এবং নির্ভুলতা বাড়ানোর জন্য ভার্চুয়াল সহকারী, অনুবাদ, বিষয়বস্তু তৈরি এবং কম্পিউটার ভিশন সহ বিভিন্ন কাজের জন্য ব্যবসাগুলি ক্রমবর্ধমানভাবে এলএলএম গ্রহণ করছে।
যাইহোক, কাস্টম ব্যবহারের ক্ষেত্রে এই বৃহৎ মডেলগুলিকে প্রশিক্ষণ বা ফাইন-টিউনিংয়ের জন্য প্রচুর পরিমাণে ডেটা এবং গণনা শক্তির প্রয়োজন, যা ML স্ট্যাকের সামগ্রিক প্রকৌশল জটিলতাকে যুক্ত করে। এটি একটি একক GPU-তে উপলব্ধ সীমিত মেমরির কারণেও, যা প্রশিক্ষিত মডেলের আকারকে সীমাবদ্ধ করে এবং প্রশিক্ষণের সময় ব্যবহৃত প্রতি-GPU ব্যাচের আকারকেও সীমাবদ্ধ করে।
এই চ্যালেঞ্জ মোকাবেলা করার জন্য, বিভিন্ন মডেল সমান্তরাল কৌশল যেমন ডিপস্পীড জিরো এবং পাইটর্চ এফএসডিপি আপনাকে সীমিত GPU মেমরির এই বাধা অতিক্রম করার অনুমতি দেওয়ার জন্য তৈরি করা হয়েছিল। এটি একটি শার্ড ডেটা সমান্তরাল কৌশল অবলম্বন করে করা হয়, যেখানে প্রতিটি অ্যাক্সিলারেটর একটি স্লাইস ধারণ করে (একটি ঠিকরা) সম্পূর্ণ মডেলের প্রতিরূপের পরিবর্তে একটি মডেলের প্রতিরূপ, যা নাটকীয়ভাবে প্রশিক্ষণ কাজের মেমরি পদচিহ্নকে হ্রাস করে।
এই পোস্টটি দেখায় যে আপনি কীভাবে অ্যামাজন ইকেএস ব্যবহার করে Llama2 মডেলটিকে ফাইন-টিউন করতে PyTorch FSDP ব্যবহার করতে পারেন। আমরা মডেলের প্রয়োজনীয়তাগুলিকে মোকাবেলা করার জন্য গণনা এবং GPU ক্ষমতা স্কেল করে এটি অর্জন করি।
FSDP ওভারভিউ
পাইটর্চ ডিডিপি প্রশিক্ষণে, প্রতিটি জিপিইউ (এ হিসাবে উল্লেখ করা হয় কর্মী PyTorch এর প্রেক্ষাপটে) মডেলের ওজন, গ্রেডিয়েন্ট এবং অপ্টিমাইজার স্টেট সহ মডেলের একটি সম্পূর্ণ অনুলিপি ধারণ করে। প্রতিটি কর্মী ডেটার একটি ব্যাচ প্রক্রিয়া করে এবং, ব্যাকওয়ার্ড পাসের শেষে, একটি ব্যবহার করে সব কমানো বিভিন্ন কর্মীদের মধ্যে গ্রেডিয়েন্ট সিঙ্ক্রোনাইজ করার জন্য অপারেশন।
প্রতিটি জিপিইউতে মডেলের একটি প্রতিরূপ থাকা মডেলের আকারকে সীমাবদ্ধ করে যা একটি ডিডিপি ওয়ার্কফ্লোতে মিটমাট করা যেতে পারে। FSDP মডেল প্যারামিটার, অপ্টিমাইজার স্টেট এবং ডেটা সমান্তরাল কর্মীদের জুড়ে গ্রেডিয়েন্ট শার্ড করে এই সীমাবদ্ধতা কাটিয়ে উঠতে সাহায্য করে যখন এখনও ডেটা সমান্তরালতার সরলতা সংরক্ষণ করে।
এটি নিম্নলিখিত চিত্রে প্রদর্শিত হয়েছে, যেখানে ডিডিপির ক্ষেত্রে, প্রতিটি জিপিইউ অপ্টিমাইজার স্টেট (ওএস), গ্রেডিয়েন্ট (জি), এবং প্যারামিটার (পি): এম(ওএস + জি) সহ মডেল স্টেটের একটি সম্পূর্ণ অনুলিপি ধারণ করে + পি)। এফএসডিপি-তে, প্রতিটি জিপিইউ অপ্টিমাইজার স্টেট (ওএস), গ্রেডিয়েন্ট (জি), এবং প্যারামিটার (পি) সহ মডেল স্টেটের একটি স্লাইস ধারণ করে: এম (OS + G + P)। FSDP ব্যবহারের ফলে সমস্ত কর্মীদের মধ্যে DDP-এর তুলনায় উল্লেখযোগ্যভাবে ছোট GPU মেমরি ফুটপ্রিন্ট পাওয়া যায়, খুব বড় মডেলের প্রশিক্ষণ সক্ষম করে বা প্রশিক্ষণের কাজের জন্য বড় ব্যাচের আকার ব্যবহার করে।

এটি, যাইহোক, বর্ধিত যোগাযোগের ওভারহেডের খরচে আসে, যা FSDP অপ্টিমাইজেশানের মাধ্যমে প্রশমিত হয় যেমন ওভারল্যাপিং যোগাযোগ এবং গণনা প্রক্রিয়াগুলির মতো বৈশিষ্ট্যগুলির সাথে প্রি-ফেচিং. আরো বিস্তারিত তথ্যের জন্য, পড়ুন সম্পূর্ণরূপে শার্ডেড ডেটা প্যারালাল (FSDP) দিয়ে শুরু করা.
FSDP বিভিন্ন পরামিতি অফার করে যা আপনাকে আপনার প্রশিক্ষণের কাজের পারফরম্যান্স এবং দক্ষতার সমন্বয় করতে দেয়। FSDP-এর কিছু মূল বৈশিষ্ট্য এবং ক্ষমতার মধ্যে রয়েছে:
- ট্রান্সফরমার মোড়ানো নীতি
- নমনীয় মিশ্র নির্ভুলতা
- সক্রিয়করণ চেকপয়েন্টিং
- বিভিন্ন নেটওয়ার্ক গতি এবং ক্লাস্টার টপোলজির জন্য বিভিন্ন শার্ডিং কৌশল:
- FULL_SHARD - শার্ড মডেল প্যারামিটার, গ্রেডিয়েন্ট এবং অপ্টিমাইজার স্টেট
- HYBRID_SHARD - নোড জুড়ে একটি নোড DDP-এর মধ্যে সম্পূর্ণ শার্ড; মডেলের সম্পূর্ণ প্রতিরূপের জন্য একটি নমনীয় শার্ডিং গ্রুপকে সমর্থন করে (HSDP)
- SHARD_GRAD_OP - শার্ড শুধুমাত্র গ্রেডিয়েন্ট এবং অপ্টিমাইজার অবস্থা
- NO_SHARD - ডিডিপির অনুরূপ
FSDP সম্পর্কে আরও তথ্যের জন্য, পড়ুন Pytorch FSDP এবং AWS এর সাথে দক্ষ বৃহৎ-স্কেল প্রশিক্ষণ.
নিম্নলিখিত চিত্রটি দেখায় কিভাবে FSDP দুটি ডেটা সমান্তরাল প্রক্রিয়ার জন্য কাজ করে।
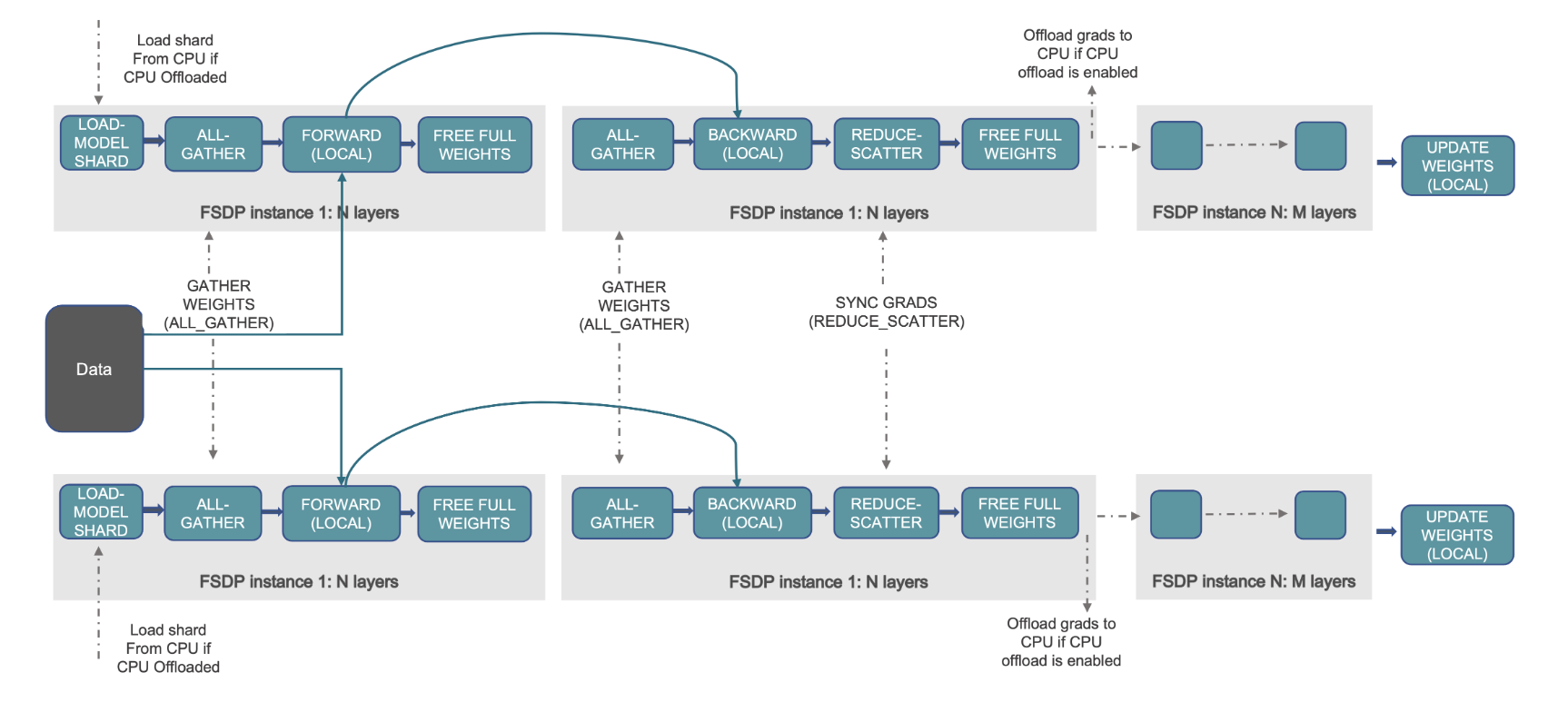
সমাধান ওভারভিউ
এই পোস্টে, আমরা Amazon EKS ব্যবহার করে একটি কম্পিউট ক্লাস্টার সেট আপ করেছি, যা AWS ক্লাউড এবং অন-প্রিমিসেস ডেটা সেন্টারে Kubernetes চালানোর জন্য একটি পরিচালিত পরিষেবা। অনেক গ্রাহক কুবারনেটস-ভিত্তিক AI/ML ওয়ার্কলোডগুলি চালানোর জন্য Amazon EKS কে আলিঙ্গন করছেন, এর কার্যকারিতা, পরিমাপযোগ্যতা, নির্ভরযোগ্যতা এবং উপলব্ধতার পাশাপাশি AWS নেটওয়ার্কিং, নিরাপত্তা এবং অন্যান্য পরিষেবাগুলির সাথে এর একীকরণের সুবিধা গ্রহণ করছেন।
আমাদের FSDP ব্যবহারের ক্ষেত্রে, আমরা ব্যবহার করি কুবেফ্লো ট্রেনিং অপারেটর Amazon EKS-এ, যা একটি কুবারনেটস-নেটিভ প্রজেক্ট যা এমএল মডেলের জন্য ফাইন-টিউনিং এবং স্কেলযোগ্য বিতরণ প্রশিক্ষণের সুবিধা দেয়। এটি PyTorch সহ বিভিন্ন ML ফ্রেমওয়ার্ককে সমর্থন করে, যা আপনি স্কেলে PyTorch প্রশিক্ষণের কাজগুলি স্থাপন এবং পরিচালনা করতে ব্যবহার করতে পারেন।
Kubeflow ট্রেনিং অপারেটরের PyTorchJob কাস্টম রিসোর্স ব্যবহার করে, আমরা Kubernetes-এ একটি কনফিগারযোগ্য সংখ্যক কর্মী প্রতিলিপি দিয়ে প্রশিক্ষণের কাজ চালাই যা আমাদের সম্পদের ব্যবহার অপ্টিমাইজ করতে দেয়।
নীচে প্রশিক্ষণ অপারেটরের কয়েকটি উপাদান রয়েছে যা আমাদের Llama2 ফাইন-টিউনিং ব্যবহারের ক্ষেত্রে ভূমিকা পালন করে:
- একটি কেন্দ্রীভূত Kubernetes নিয়ন্ত্রক যে PyTorch-এর জন্য প্রশিক্ষণের কাজ বিতরণ করে।
- PyTorchJob, PyTorch-এর জন্য Kubernetes কাস্টম রিসোর্স, Kubernetes-এ Llama2 প্রশিক্ষণের কাজ সংজ্ঞায়িত ও স্থাপন করার জন্য Kubeflow ট্রেনিং অপারেটর দ্বারা সরবরাহ করা হয়েছে।
- etcd, যা পাইটর্চ মডেলের বিতরণ করা প্রশিক্ষণের সমন্বয়ের জন্য মিলন প্রক্রিয়ার বাস্তবায়নের সাথে সম্পর্কিত। এই
etcdসার্ভার, মিলন প্রক্রিয়ার অংশ হিসাবে, বিতরণ করা প্রশিক্ষণের সময় অংশগ্রহণকারী কর্মীদের সমন্বয় এবং সমন্বয় সাধন করে।
নিম্নলিখিত চিত্রটি সমাধানের স্থাপত্যকে চিত্রিত করে।

বেশিরভাগ বিবরণ অটোমেশন স্ক্রিপ্ট দ্বারা বিমূর্ত করা হবে যা আমরা Llama2 উদাহরণ চালানোর জন্য ব্যবহার করি।
এই ব্যবহারের ক্ষেত্রে আমরা নিম্নলিখিত কোড রেফারেন্স ব্যবহার করি:
Llama2 কি?
Llama2 হল একটি LLM যা টেক্সট এবং কোডের 2 ট্রিলিয়ন টোকেনের উপর প্রি-প্রশিক্ষিত। এটি আজ উপলব্ধ সবচেয়ে বড় এবং সবচেয়ে শক্তিশালী LLMগুলির মধ্যে একটি আপনি প্রাকৃতিক ভাষা প্রক্রিয়াকরণ (NLP), পাঠ্য তৈরি এবং অনুবাদ সহ বিভিন্ন কাজের জন্য Llama2 ব্যবহার করতে পারেন। আরো তথ্যের জন্য, পড়ুন লামা দিয়ে শুরু করা.
Llama2 তিনটি ভিন্ন মডেলের আকারে পাওয়া যায়:
- Llama2-70b - এটি 2 বিলিয়ন প্যারামিটার সহ বৃহত্তম Llama70 মডেল। এটি সবচেয়ে শক্তিশালী Llama2 মডেল এবং এটি সবচেয়ে চাহিদাপূর্ণ কাজের জন্য ব্যবহার করা যেতে পারে।
- Llama2-13b - এটি একটি মাঝারি আকারের Llama2 মডেল, 13 বিলিয়ন প্যারামিটার সহ। এটি কর্মক্ষমতা এবং দক্ষতার মধ্যে একটি ভাল ভারসাম্য, এবং বিভিন্ন কাজের জন্য ব্যবহার করা যেতে পারে।
- Llama2-7b - এটি 2 বিলিয়ন প্যারামিটার সহ সবচেয়ে ছোট Llama7 মডেল। এটি সবচেয়ে দক্ষ Llama2 মডেল, এবং এটি এমন কাজের জন্য ব্যবহার করা যেতে পারে যেগুলির পারফরম্যান্সের সর্বোচ্চ স্তরের প্রয়োজন হয় না৷
এই পোস্টটি আপনাকে অ্যামাজন ইকেএস-এ এই সমস্ত মডেলগুলিকে সূক্ষ্ম-টিউন করতে সক্ষম করে। একটি EKS ক্লাস্টার তৈরি এবং এটিতে FSDP কাজ চালানোর একটি সহজ এবং পুনরুত্পাদনযোগ্য অভিজ্ঞতা প্রদান করতে, আমরা ব্যবহার করি aws-do-eks প্রকল্প উদাহরণটি পূর্ব-বিদ্যমান EKS ক্লাস্টারের সাথেও কাজ করবে।
একটি স্ক্রিপ্টেড ওয়াকথ্রু পাওয়া যায় GitHub বাক্সের বাইরের অভিজ্ঞতার জন্য। নিম্নলিখিত বিভাগগুলিতে, আমরা শেষ থেকে শেষ প্রক্রিয়াটি আরও বিশদে ব্যাখ্যা করি।
সমাধান পরিকাঠামো প্রদান
এই পোস্টে বর্ণিত পরীক্ষার জন্য, আমরা p4de (A100 GPU) এবং p5 (H100 GPU) নোড সহ ক্লাস্টার ব্যবহার করি।
p4de.24x বড় নোড সহ ক্লাস্টার
p4de নোড সহ আমাদের ক্লাস্টারের জন্য, আমরা নিম্নলিখিত ব্যবহার করি eks-gpu-p4de-odcr.yaml লিপি:
ব্যবহার eksctl এবং পূর্ববর্তী ক্লাস্টার ম্যানিফেস্ট, আমরা p4de নোড সহ একটি ক্লাস্টার তৈরি করি:
p5.48x বড় নোড সহ ক্লাস্টার
P5 নোড সহ একটি EKS ক্লাস্টারের জন্য একটি টেরাফর্ম টেমপ্লেট নিম্নলিখিতটিতে অবস্থিত গিটহুব রেপো.
আপনি এর মাধ্যমে ক্লাস্টারটি কাস্টমাইজ করতে পারেন variables.tf ফাইল করুন এবং তারপরে এটি টেরাফর্ম CLI এর মাধ্যমে তৈরি করুন:
আপনি একটি সাধারণ kubectl কমান্ড চালিয়ে ক্লাস্টারের প্রাপ্যতা যাচাই করতে পারেন:
এই কমান্ডের আউটপুট প্রস্তুত অবস্থায় নোডের প্রত্যাশিত সংখ্যা দেখালে ক্লাস্টারটি স্বাস্থ্যকর।
পূর্বশর্ত স্থাপন
Amazon EKS-এ FSDP চালানোর জন্য, আমরা ব্যবহার করি PyTorchJob কাস্টম সম্পদ। এটি প্রয়োজন ইত্যাদি এবং কুবেফ্লো ট্রেনিং অপারেটর পূর্বশর্ত হিসাবে।
নিম্নলিখিত কোড দিয়ে etcd স্থাপন করুন:
নিম্নলিখিত কোড সহ Kubeflow প্রশিক্ষণ অপারেটর স্থাপন করুন:
Amazon ECR-তে একটি FSDP কন্টেইনার ইমেজ তৈরি করুন এবং পুশ করুন
একটি FSDP কন্টেইনার ইমেজ তৈরি করতে নিম্নলিখিত কোড ব্যবহার করুন এবং এটিতে ধাক্কা দিন অ্যামাজন ইলাস্টিক কনটেইনার রেজিস্ট্রি (আমাজন ইসিআর):
FSDP PyTorchJob ম্যানিফেস্ট তৈরি করুন
আপনার ঢোকান আলিঙ্গন করা মুখের টোকেন এটি চালানোর আগে নিম্নলিখিত স্নিপেটে:
এর সাথে আপনার PyTorchJob কনফিগার করুন .env ফাইল বা সরাসরি আপনার পরিবেশ ভেরিয়েবলে নিচের মত করে:
ব্যবহার করে PyTorchJob ম্যানিফেস্ট তৈরি করুন fsdp টেমপ্লেট এবং generate.sh স্ক্রিপ্ট বা নীচের স্ক্রিপ্ট ব্যবহার করে সরাসরি এটি তৈরি করুন:
PyTorchJob চালান
নিম্নলিখিত কোড দিয়ে PyTorchJob চালান:
আপনি এফডিএসপি কর্মী পডের নির্দিষ্ট সংখ্যক তৈরি দেখতে পাবেন এবং, ছবিটি টানার পরে, তারা একটি চলমান অবস্থায় প্রবেশ করবে।
PyTorchJob এর অবস্থা দেখতে, নিম্নলিখিত কোড ব্যবহার করুন:
PyTorchJob বন্ধ করতে, নিম্নলিখিত কোড ব্যবহার করুন:
একটি কাজ সম্পূর্ণ হওয়ার পরে, এটি একটি নতুন রান শুরু করার আগে মুছে ফেলা প্রয়োজন। আমরা মুছে ফেলা যে পর্যবেক্ষণ করেছিetcdপড এবং একটি নতুন কাজ শুরু করার আগে এটি পুনরায় চালু করতে দেওয়া একটি এড়াতে সাহায্য করে RendezvousClosedError.
ক্লাস্টার স্কেল করুন
ক্লাস্টারে কর্মী নোডের সংখ্যা এবং উদাহরণের ধরন পরিবর্তন করার সময় আপনি কাজ তৈরি এবং চালানোর পূর্ববর্তী ধাপগুলি পুনরাবৃত্তি করতে পারেন। এটি আপনাকে আগের দেখানোর মতো স্কেলিং চার্ট তৈরি করতে সক্ষম করে। সাধারণভাবে, ক্লাস্টারে আরও নোড যোগ করা হলে আপনি GPU মেমরির পদচিহ্নে হ্রাস, যুগের সময় হ্রাস এবং থ্রুপুট বৃদ্ধি দেখতে পাবেন। পূর্ববর্তী চার্টটি আকারে 5-1 নোড থেকে পরিবর্তিত একটি p16 নোড গ্রুপ ব্যবহার করে বেশ কয়েকটি পরীক্ষা পরিচালনা করে তৈরি করা হয়েছিল।
FSDP প্রশিক্ষণ কাজের চাপ পর্যবেক্ষণ করুন
জেনারেটিভ কৃত্রিম বুদ্ধিমত্তার কাজের লোডের পর্যবেক্ষণ আপনার চলমান চাকরিতে দৃশ্যমানতার অনুমতি দেওয়ার পাশাপাশি আপনার গণনা সংস্থানগুলির সর্বাধিক ব্যবহারে সহায়তা করার জন্য গুরুত্বপূর্ণ। এই পোস্টে, আমরা এই উদ্দেশ্যে কয়েকটি কুবারনেটস-নেটিভ এবং ওপেন সোর্স অবজারভেবিলিটি টুল ব্যবহার করি। এই সরঞ্জামগুলি আপনাকে ত্রুটি, পরিসংখ্যান এবং মডেল আচরণ ট্র্যাক করতে সক্ষম করে, যে কোনও ব্যবসায়িক ব্যবহারের ক্ষেত্রে এআই পর্যবেক্ষণযোগ্যতাকে একটি গুরুত্বপূর্ণ অংশ করে তোলে। এই বিভাগে, আমরা FSDP প্রশিক্ষণের কাজগুলি পর্যবেক্ষণ করার জন্য বিভিন্ন পদ্ধতি দেখাই।
শ্রমিক পড লগ
সর্বাধিক মৌলিক স্তরে, আপনাকে আপনার প্রশিক্ষণ পডগুলির লগগুলি দেখতে সক্ষম হতে হবে। Kubernetes-নেটিভ কমান্ড ব্যবহার করে এটি সহজেই করা যেতে পারে।
প্রথমে, পডগুলির একটি তালিকা পুনরুদ্ধার করুন এবং আপনি যেটির জন্য লগ দেখতে চান তার নামটি সনাক্ত করুন:
তারপর নির্বাচিত পডের লগগুলি দেখুন:

শুধুমাত্র একজন কর্মী (নির্বাচিত নেতা) পড লগ সামগ্রিক কাজের পরিসংখ্যান তালিকাভুক্ত করবে। নির্বাচিত নেতা পডের নাম প্রতিটি কর্মী পড লগের শুরুতে পাওয়া যায়, যা কী দ্বারা চিহ্নিত করা হয় master_addr=.
CPU ব্যবহার
বিতরণকৃত প্রশিক্ষণের কাজের জন্য CPU এবং GPU উভয় সংস্থান প্রয়োজন। এই কাজের চাপগুলি অপ্টিমাইজ করার জন্য, এই সংস্থানগুলি কীভাবে ব্যবহার করা হয় তা বোঝা গুরুত্বপূর্ণ৷ সৌভাগ্যবশত, কিছু দুর্দান্ত ওপেন সোর্স ইউটিলিটি উপলব্ধ রয়েছে যা CPU এবং GPU ব্যবহারকে কল্পনা করতে সাহায্য করে। CPU ব্যবহার দেখার জন্য, আপনি ব্যবহার করতে পারেনhtop. যদি আপনার ওয়ার্কার পডগুলিতে এই ইউটিলিটি থাকে তবে আপনি নীচের কমান্ডটি ব্যবহার করে একটি শেল একটি পডে খুলতে পারেন এবং তারপরে চালাতে পারেনhtop.
বিকল্পভাবে, আপনি একটি htop স্থাপন করতে পারেনdaemonsetনিচের দেওয়া একটি মত গিটহুব রেপো.
সার্জারির daemonsetপ্রতিটি নোডে একটি হালকা htop পড চালাবে। আপনি এই পডগুলির মধ্যে যেকোনও চালাতে পারেন এবং চালাতে পারেনhtopকমান্ড প্রয়োগ করুন:
নিম্নলিখিত স্ক্রিনশট ক্লাস্টারের একটি নোডের CPU ব্যবহার দেখায়। এই ক্ষেত্রে, আমরা একটি P5.48x বড় উদাহরণ দেখছি, যার 192টি vCPU আছে। মডেলের ওজন ডাউনলোড করার সময় প্রসেসরের কোরগুলি নিষ্ক্রিয় থাকে এবং মডেলের ওজনগুলি GPU মেমরিতে লোড হওয়ার সময় আমরা ক্রমবর্ধমান ব্যবহার দেখতে পাই।

GPU ব্যবহার
যদিnvtopইউটিলিটি আপনার পডে উপলব্ধ, আপনি নীচে ব্যবহার করে এটি চালাতে পারেন এবং তারপর চালাতে পারেনnvtop.
বিকল্পভাবে, আপনি একটি nvtop স্থাপন করতে পারেনdaemonsetনিচের দেওয়া একটি মত গিটহুব রেপো.
এটি একটি চালাবেnvtopপ্রতিটি নোডে পড। আপনি যে কোনো পড এবং চালাতে চালাতে পারেনnvtop:
নিম্নলিখিত স্ক্রিনশটটি প্রশিক্ষণ ক্লাস্টারের একটি নোডের GPU ব্যবহার দেখায়। এই ক্ষেত্রে, আমরা একটি P5.48x বড় উদাহরণ দেখছি, যার 8টি NVIDIA H100 GPU আছে। মডেল ওজনগুলি ডাউনলোড করার সময় GPU গুলি নিষ্ক্রিয় থাকে, তারপর GPU মেমরির ব্যবহার বৃদ্ধি পায় কারণ মডেল ওজনগুলি GPU-তে লোড করা হয় এবং প্রশিক্ষণের পুনরাবৃত্তি চলাকালীন GPU ব্যবহার 100% পর্যন্ত বেড়ে যায়৷

গ্রাফানা ড্যাশবোর্ড
এখন আপনি বুঝতে পেরেছেন যে কীভাবে আপনার সিস্টেম পড এবং নোড স্তরে কাজ করে, ক্লাস্টার স্তরে মেট্রিকগুলি দেখাও গুরুত্বপূর্ণ। NVIDIA DCGM রপ্তানিকারক এবং প্রমিথিউস দ্বারা সমষ্টিগত ব্যবহারের মেট্রিক্স সংগ্রহ করা যেতে পারে এবং Grafana-এ ভিজ্যুয়ালাইজ করা যেতে পারে।
প্রমিথিউস-গ্রাফানা স্থাপনার একটি উদাহরণ নিম্নলিখিতটিতে পাওয়া যায় গিটহুব রেপো.
একটি উদাহরণ DCGM রপ্তানিকারক স্থাপনা নিম্নলিখিত পাওয়া যায় গিটহুব রেপো.
একটি সাধারণ Grafana ড্যাশবোর্ড নিম্নলিখিত স্ক্রিনশটে দেখানো হয়েছে। এটি নিম্নলিখিত DCGM মেট্রিক্স নির্বাচন করে নির্মিত হয়েছিল: DCGM_FI_DEV_GPU_UTIL, DCGM_FI_MEM_COPY_UTIL, DCGM_FI_DEV_XID_ERRORS, DCGM_FI_DEV_SM_CLOCK, DCGM_FI_DEV_GPU_TEMP, এবং DCGM_FI_DEV_POWER_USAGE. ড্যাশবোর্ড থেকে প্রমিথিউসে আমদানি করা যেতে পারে GitHub.
নিম্নলিখিত ড্যাশবোর্ডটি Llama2 7b একক যুগের প্রশিক্ষণ কাজের এক রান দেখায়। গ্রাফগুলি দেখায় যে স্ট্রিমিং মাল্টিপ্রসেসর (এসএম) ঘড়ি বৃদ্ধির সাথে সাথে জিপিইউ এবং মেমরি ব্যবহারের সাথে সাথে জিপিইউগুলির পাওয়ার ড্র এবং তাপমাত্রাও বৃদ্ধি পায়। আপনি এটিও দেখতে পারেন যে কোনও XID ত্রুটি ছিল না এবং এই রানের সময় GPU গুলি সুস্থ ছিল৷

মার্চ 2024 থেকে EKS-এর জন্য GPU পর্যবেক্ষণযোগ্যতা স্থানীয়ভাবে সমর্থিত CloudWatch কন্টেইনার অন্তর্দৃষ্টি. এই কার্যকারিতা সক্ষম করতে শুধুমাত্র আপনার EKS ক্লাস্টারে ক্লাউডওয়াচ পর্যবেক্ষণযোগ্যতা অ্যাড-অন স্থাপন করুন। তারপর আপনি কন্টেইনার অন্তর্দৃষ্টিতে পূর্ব-কনফিগার করা এবং কাস্টমাইজযোগ্য ড্যাশবোর্ডের মাধ্যমে পড, নোড এবং ক্লাস্টার স্তরের মেট্রিক্স ব্রাউজ করতে সক্ষম হবেন।
পরিষ্কার কর
আপনি যদি এই ব্লগে দেওয়া উদাহরণগুলি ব্যবহার করে আপনার ক্লাস্টার তৈরি করেন, তাহলে আপনি ক্লাস্টার এবং VPC সহ এর সাথে সম্পর্কিত যেকোন সংস্থান মুছে ফেলতে নিম্নলিখিত কোডটি চালাতে পারেন:
eksctl এর জন্য:
টেরাফর্মের জন্য:
আসন্ন বৈশিষ্ট্য
FSDP প্রতি-প্যারামিটার শার্ডিং বৈশিষ্ট্য অন্তর্ভুক্ত করবে বলে আশা করা হচ্ছে, যার লক্ষ্য GPU প্রতি এর মেমরি ফুটপ্রিন্ট আরও উন্নত করা। উপরন্তু, FP8 সমর্থনের চলমান বিকাশের লক্ষ্য H100 GPU-তে FSDP কর্মক্ষমতা উন্নত করা। অবশেষে, যখন FSDP এর সাথে একীভূত হয়torch.compile, আমরা অতিরিক্ত কর্মক্ষমতা উন্নতি এবং নির্বাচনী অ্যাক্টিভেশন চেকপয়েন্টিংয়ের মতো বৈশিষ্ট্যগুলির সক্ষমতা দেখতে আশা করি৷
উপসংহার
এই পোস্টে, আমরা আলোচনা করেছি কিভাবে FSDP প্রতিটি GPU-তে মেমরির পদচিহ্ন কমিয়ে দেয়, বড় মডেলের প্রশিক্ষণকে আরও দক্ষতার সাথে সক্ষম করে এবং থ্রুপুটে কাছাকাছি রৈখিক স্কেলিং অর্জন করে। আমরা P2de এবং P4 দৃষ্টান্তে Amazon EKS ব্যবহার করে Llama5 মডেলের প্রশিক্ষণের ধাপে ধাপে বাস্তবায়নের মাধ্যমে এটি প্রদর্শন করেছি এবং লগ নিরীক্ষণের জন্য kubectl, htop, nvtop, এবং dcgm এর মতো পর্যবেক্ষণযোগ্য সরঞ্জামগুলি ব্যবহার করেছি, সেইসাথে CPU এবং GPU ব্যবহার।
আমরা আপনাকে আপনার নিজস্ব LLM প্রশিক্ষণের চাকরির জন্য PyTorch FSDP-এর সুবিধা নিতে উৎসাহিত করি। এ শুরু করুন aws-do-fsdp.
লেখক সম্পর্কে
 কানওয়ালজিৎ খুরমি আমাজন ওয়েব সার্ভিসেসের একজন প্রধান AI/ML সলিউশন আর্কিটেক্ট। তিনি AWS গ্রাহকদের সাথে নির্দেশিকা এবং প্রযুক্তিগত সহায়তা প্রদানের জন্য কাজ করেন, তাদের AWS-এ তাদের মেশিন লার্নিং সমাধানের মান উন্নত করতে সহায়তা করে। কানওয়ালজিৎ গ্রাহকদের কনটেইনারাইজড, ডিস্ট্রিবিউটেড কম্পিউটিং এবং ডিপ লার্নিং অ্যাপ্লিকেশানগুলির সাহায্যে বিশেষজ্ঞ।
কানওয়ালজিৎ খুরমি আমাজন ওয়েব সার্ভিসেসের একজন প্রধান AI/ML সলিউশন আর্কিটেক্ট। তিনি AWS গ্রাহকদের সাথে নির্দেশিকা এবং প্রযুক্তিগত সহায়তা প্রদানের জন্য কাজ করেন, তাদের AWS-এ তাদের মেশিন লার্নিং সমাধানের মান উন্নত করতে সহায়তা করে। কানওয়ালজিৎ গ্রাহকদের কনটেইনারাইজড, ডিস্ট্রিবিউটেড কম্পিউটিং এবং ডিপ লার্নিং অ্যাপ্লিকেশানগুলির সাহায্যে বিশেষজ্ঞ।
 অ্যালেক্স ইয়ানকুলস্কি একজন প্রিন্সিপাল সলিউশন আর্কিটেক্ট, AWS-এ স্ব-পরিচালিত মেশিন লার্নিং। তিনি একজন পূর্ণ-স্ট্যাক সফ্টওয়্যার এবং অবকাঠামো প্রকৌশলী যিনি গভীর, হাতে-কলমে কাজ করতে পছন্দ করেন। তার ভূমিকায়, তিনি কন্টেইনার-চালিত AWS পরিষেবাগুলিতে ML এবং AI ওয়ার্কলোডের কন্টেইনারাইজেশন এবং অর্কেস্ট্রেশনের সাথে গ্রাহকদের সাহায্য করার দিকে মনোনিবেশ করেন। তিনি ওপেন সোর্সের লেখকও কাঠামো করা এবং একজন ডকার ক্যাপ্টেন যিনি বিশ্বের বৃহত্তম চ্যালেঞ্জগুলি সমাধান করার সময় উদ্ভাবনের গতিকে ত্বরান্বিত করতে কন্টেইনার প্রযুক্তি প্রয়োগ করতে পছন্দ করেন।
অ্যালেক্স ইয়ানকুলস্কি একজন প্রিন্সিপাল সলিউশন আর্কিটেক্ট, AWS-এ স্ব-পরিচালিত মেশিন লার্নিং। তিনি একজন পূর্ণ-স্ট্যাক সফ্টওয়্যার এবং অবকাঠামো প্রকৌশলী যিনি গভীর, হাতে-কলমে কাজ করতে পছন্দ করেন। তার ভূমিকায়, তিনি কন্টেইনার-চালিত AWS পরিষেবাগুলিতে ML এবং AI ওয়ার্কলোডের কন্টেইনারাইজেশন এবং অর্কেস্ট্রেশনের সাথে গ্রাহকদের সাহায্য করার দিকে মনোনিবেশ করেন। তিনি ওপেন সোর্সের লেখকও কাঠামো করা এবং একজন ডকার ক্যাপ্টেন যিনি বিশ্বের বৃহত্তম চ্যালেঞ্জগুলি সমাধান করার সময় উদ্ভাবনের গতিকে ত্বরান্বিত করতে কন্টেইনার প্রযুক্তি প্রয়োগ করতে পছন্দ করেন।
 আনা সিমোস একজন প্রধান মেশিন লার্নিং বিশেষজ্ঞ, AWS-এ ML Frameworks. তিনি ক্লাউডে HPC পরিকাঠামোতে বৃহৎ পরিসরে AI, ML, এবং জেনারেটিভ AI স্থাপনকারী গ্রাহকদের সমর্থন করেন। Ana নতুন কাজের চাপের জন্য মূল্য-পারফরম্যান্স অর্জন করতে এবং জেনারেটিভ এআই এবং মেশিন লার্নিংয়ের জন্য কেস ব্যবহার করতে গ্রাহকদের সমর্থন করার উপর দৃষ্টি নিবদ্ধ করে।
আনা সিমোস একজন প্রধান মেশিন লার্নিং বিশেষজ্ঞ, AWS-এ ML Frameworks. তিনি ক্লাউডে HPC পরিকাঠামোতে বৃহৎ পরিসরে AI, ML, এবং জেনারেটিভ AI স্থাপনকারী গ্রাহকদের সমর্থন করেন। Ana নতুন কাজের চাপের জন্য মূল্য-পারফরম্যান্স অর্জন করতে এবং জেনারেটিভ এআই এবং মেশিন লার্নিংয়ের জন্য কেস ব্যবহার করতে গ্রাহকদের সমর্থন করার উপর দৃষ্টি নিবদ্ধ করে।
 হামিদ শোজানাজেরী PyTorch-এর একজন অংশীদার প্রকৌশলী ওপেন সোর্স, উচ্চ-পারফরম্যান্স মডেল অপ্টিমাইজেশান, বিতরণ প্রশিক্ষণ (এফএসডিপি), এবং অনুমান। তিনি এর সহ-স্রষ্টা লামা-রেসিপি এবং অবদানকারী টর্চ সার্ভ. তার প্রধান আগ্রহ হল খরচ-দক্ষতা উন্নত করা, AI-কে বৃহত্তর সম্প্রদায়ের কাছে আরও অ্যাক্সেসযোগ্য করে তোলা।
হামিদ শোজানাজেরী PyTorch-এর একজন অংশীদার প্রকৌশলী ওপেন সোর্স, উচ্চ-পারফরম্যান্স মডেল অপ্টিমাইজেশান, বিতরণ প্রশিক্ষণ (এফএসডিপি), এবং অনুমান। তিনি এর সহ-স্রষ্টা লামা-রেসিপি এবং অবদানকারী টর্চ সার্ভ. তার প্রধান আগ্রহ হল খরচ-দক্ষতা উন্নত করা, AI-কে বৃহত্তর সম্প্রদায়ের কাছে আরও অ্যাক্সেসযোগ্য করে তোলা।
 কম রাইট পাইটর্চে একজন এআই/পার্টনার ইঞ্জিনিয়ার। তিনি ট্রাইটন/সিউডিএ কার্নেলে কাজ করেন (SplitK কাজের পচন সহ ডিকুয়ান্টকে ত্বরান্বিত করা); পেজড, স্ট্রিমিং এবং কোয়ান্টাইজড অপ্টিমাইজার; এবং পাইটর্চ বিতরণ করা হয়েছে (পাইটর্চ এফএসডিপি).
কম রাইট পাইটর্চে একজন এআই/পার্টনার ইঞ্জিনিয়ার। তিনি ট্রাইটন/সিউডিএ কার্নেলে কাজ করেন (SplitK কাজের পচন সহ ডিকুয়ান্টকে ত্বরান্বিত করা); পেজড, স্ট্রিমিং এবং কোয়ান্টাইজড অপ্টিমাইজার; এবং পাইটর্চ বিতরণ করা হয়েছে (পাইটর্চ এফএসডিপি).
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- PlatoData.Network উল্লম্ব জেনারেটিভ Ai. নিজেকে ক্ষমতায়িত করুন। এখানে প্রবেশ করুন.
- প্লেটোএআইস্ট্রিম। Web3 ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- প্লেটোইএসজি। কার্বন, ক্লিনটেক, শক্তি, পরিবেশ সৌর, বর্জ্য ব্যবস্থাপনা. এখানে প্রবেশ করুন.
- প্লেটো হেলথ। বায়োটেক এবং ক্লিনিক্যাল ট্রায়াল ইন্টেলিজেন্স। এখানে প্রবেশ করুন.
- উত্স: https://aws.amazon.com/blogs/machine-learning/scale-llms-with-pytorch-2-0-fsdp-on-amazon-eks-part-2/

