المُقدّمة
أنا متأكد من أن معظمكم قد سمع عن ChatGPT وجربه للإجابة على أسئلتك! هل تساءلت يومًا ماذا يحدث تحت الغطاء؟ إنه مدعوم من نموذج لغة كبير GPT-3 تم تطويره بواسطة Open AI. هذه النماذج اللغوية الكبيرة ، التي يشار إليها غالبًا باسم LLM ، فتحت العديد من الاحتمالات في معالجة اللغات الطبيعية.
ما هي نماذج اللغات الكبيرة؟
يتم تدريب نماذج LLM على كميات هائلة من البيانات النصية ، مما يمكنهم من فهم اللغة البشرية بالمعنى والسياق. في السابق ، تم تدريب معظم النماذج باستخدام النهج الخاضع للإشراف ، حيث نقوم بتغذية ميزات الإدخال والتسميات المقابلة. على عكس هذا ، يتم تدريب LLM من خلال التعلم غير الخاضع للإشراف ، حيث يتم تغذيتهم بكميات هائلة من البيانات النصية دون أي تسميات وتعليمات. ومن ثم ، فإن LLM تتعلم المعنى والعلاقات بين كلمات اللغة بكفاءة. يمكن استخدامها في مجموعة متنوعة من المهام مثل إنشاء النص والإجابة على الأسئلة والترجمة من لغة إلى أخرى وغير ذلك الكثير.
ككرز في الأعلى ، يمكن ضبط نماذج اللغات الكبيرة هذه على مجموعة البيانات المخصصة الخاصة بك للمهام الخاصة بالمجال. في هذه المقالة ، سأتحدث عن الحاجة إلى الضبط الدقيق ، LLMs المختلفة المتاحة ، وكذلك عرض مثال.
فهم الضبط الدقيق لـ LLM
لنفترض أنك تدير مجتمعًا لدعم مرض السكري وتريد إنشاء خط مساعدة عبر الإنترنت للإجابة على الأسئلة. يتم تدريب LLM الذي تم تدريبه مسبقًا بشكل عام ولن يكون قادرًا على تقديم أفضل الإجابات للأسئلة الخاصة بالمجال وفهم المصطلحات والمختصرات الطبية. يمكن حل ذلك عن طريق الضبط الدقيق.
ماذا نعني بضبط؟ لنقول باختصار ، توصيل
تعلم! يتم تدريب نماذج اللغات الكبيرة على مجموعات بيانات ضخمة باستخدام موارد ثقيلة ولديها ملايين من المعلمات. يتم نقل التمثيلات وأنماط اللغة التي تعلمتها LLM أثناء التدريب السابق إلى مهمتك الحالية في متناول اليد. من الناحية الفنية ، نقوم بتهيئة نموذج باستخدام الأوزان المدربة مسبقًا ، ثم نقوم بتدريبه على بياناتنا الخاصة بالمهمة للوصول إلى المزيد من الأوزان المحسّنة للمهام للمعلمات. يمكنك أيضًا إجراء تغييرات في بنية النموذج وتعديل الطبقات حسب حاجتك.
لماذا يجب عليك صقل النماذج؟
- وفر الوقت والموارد: يمكن أن يساعدك الضبط الدقيق في تقليل وقت التدريب والموارد المطلوبة من التدريب من البداية.
- متطلبات البيانات المخفضة: إذا كنت ترغب في تدريب نموذج من البداية ، فستحتاج إلى كميات هائلة من البيانات المصنفة والتي غالبًا ما تكون غير متاحة للأفراد والشركات الصغيرة. يمكن أن يساعدك الضبط الدقيق في تحقيق أداء جيد حتى مع وجود كمية أقل من البيانات.
- التخصيص حسب احتياجاتك: قد لا تتمكن LLM المدربة مسبقًا من التعرف على المصطلحات والاختصارات الخاصة بالمجال الخاص بك. على سبيل المثال ، لن يتعرف LLM العادي على أن "النوع 1" و "النوع 2" يشير إلى أنواع مرض السكري ، في حين أن الشخص الذي يتم ضبطه بدقة يمكنه ذلك.
- تمكين التعلم المستمر: لنفترض أننا قمنا بضبط نموذجنا على بيانات معلومات مرض السكري ونشرناه. ماذا لو كانت هناك خطة نظام غذائي جديد أو علاج متوفر تريد تضمينه؟ يمكنك استخدام أوزان النموذج الذي تم ضبطه مسبقًا وتعديله ليشمل بياناتك الجديدة. يمكن أن يساعد هذا المؤسسات على تحديث نماذجها بطريقة فعالة.
اختيار نموذج مفتوح المصدر LLM
ستكون الخطوة التالية هي اختيار نموذج لغة كبير لمهمتك. ما هي خياراتك؟ تتضمن أحدث نماذج اللغات الكبيرة المتوفرة حاليًا GPT-3 و Bloom و BERT و T5 و XLNet. من بين هؤلاء ، أظهرت GPT-3 (المحولات التوليدية مسبقة الصنع) أفضل أداء ، حيث تم تدريبها على 175 مليار معلمة ويمكنها التعامل مع مهام NLU المتنوعة. ولكن ، لا يمكن الوصول إلى ضبط GPT-3 إلا من خلال اشتراك مدفوع وهو أغلى نسبيًا من الخيارات الأخرى.
من ناحية أخرى ، BERT هو نموذج لغة كبير مفتوح المصدر ويمكن ضبطه مجانًا. بيرت لتقف على محولات فك التشفير ثنائية الاتجاه. يقوم BERT بعمل ممتاز لفهم تمثيلات الكلمات السياقية.
كيف تختار؟
إذا كانت مهمتك أكثر توجهاً نحو إنشاء النص ، فستكون نماذج GPT-3 (المدفوعة) أو GPT-2 (مفتوحة المصدر) خيارًا أفضل. إذا كانت مهمتك تندرج تحت تصنيف النص أو الإجابة عن الأسئلة أو التعرف على الكيان ، فيمكنك استخدام BERT. بالنسبة لحالتي التي أجابت فيها عن سؤالي حول مرض السكري ، سأستمر في نموذج BERT.
تحضير مجموعة البيانات الخاصة بك ومعالجتها مسبقًا
هذه هي الخطوة الأكثر أهمية في الضبط الدقيق ، حيث يختلف تنسيق البيانات بناءً على النموذج والمهمة. بالنسبة لهذه الحالة ، قمت بإنشاء نموذج مستند نصي يحتوي على معلومات عن مرض السكري قمت بشرائه من المعهد الوطني للصحة موقع الكتروني. يمكنك استخدام البيانات الخاصة بك.
لضبط مهمة BERT للإجابة على الأسئلة ، يوصى بتحويل بياناتك إلى تنسيق SQuAD. SQuAD عبارة عن مجموعة بيانات للإجابة على الأسئلة في جامعة ستانفورد ، وقد تم اعتماد هذا التنسيق على نطاق واسع لتدريب نماذج البرمجة اللغوية العصبية لمهام الإجابة على الأسئلة. يجب أن تكون البيانات بتنسيق JSON ، حيث يتكون كل حقل من:
context: الجملة أو الفقرة مع النص الذي سيبحث النموذج بناءً عليه عن إجابة السؤالquestion: الاستعلام الذي نريد أن يجيب عليه بيرت. ستحتاج إلى وضع إطار لهذه الأسئلة بناءً على كيفية تفاعل المستخدم النهائي مع نموذج ضمان الجودة.answers: تحتاج إلى تقديم الإجابة المطلوبة ضمن هذا الحقل. هناك نوعان من المكونات الفرعية تحت هذا ،textوanswer_start.textسيكون لديه سلسلة الإجابة. بينما،answer_startيشير إلى الفهرس ، حيث تبدأ الإجابة في فقرة السياق.
كما يمكنك أن تتخيل ، سيستغرق الأمر وقتًا طويلاً لإنشاء هذه البيانات للمستند الخاص بك إذا كنت ستقوم بذلك يدويًا. لا تقلق ، سأوضح لك كيفية القيام بذلك بسهولة باستخدام أداة التعليقات التوضيحية Haystack.
كيفية إنشاء البيانات بتنسيق SQuAD باستخدام Haystack؟
باستخدام أداة التعليقات التوضيحية Haystack ، يمكنك إنشاء مجموعة بيانات معنونة بسرعة لمهام الإجابة على الأسئلة. يمكنك الوصول إلى الأداة عن طريق إنشاء حساب على الموقع. قم بإنشاء مشروع جديد وقم بتحميل المستند الخاص بك. يمكنك عرضها ضمن علامة التبويب "المستندات" ، وانتقل إلى "الإجراءات" ويمكنك رؤية خيار إنشاء أسئلتك. يمكنك كتابة سؤالك وتمييز الإجابة في المستند ، وسيجد Haystack تلقائيًا فهرس البداية الخاص به. لقد أوضحت كيف فعلت ذلك على المستند الخاص بي في الصورة أدناه.
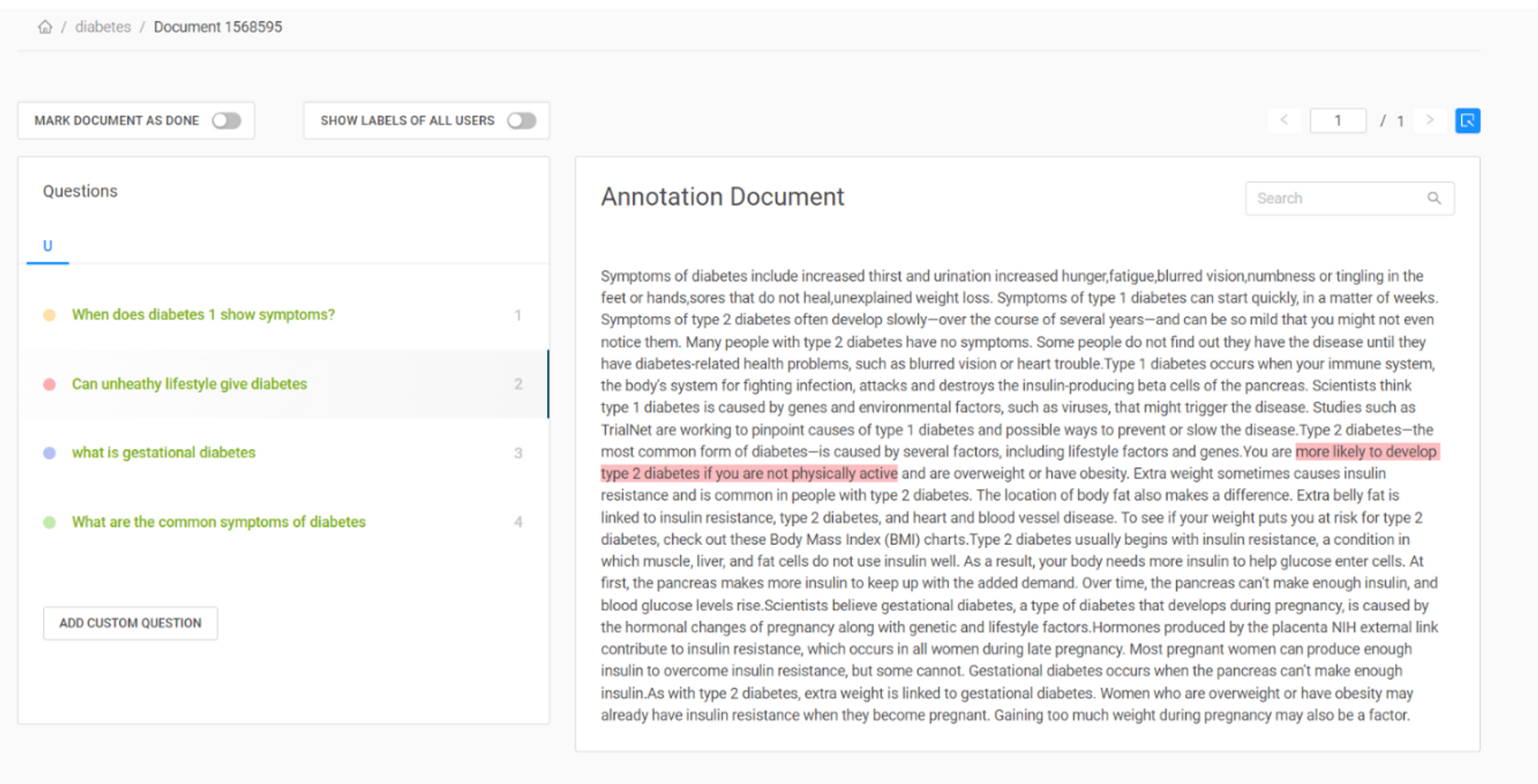
الشكل 1: إنشاء مجموعة بيانات معنونة للإجابة على الأسئلة باستخدام كومة القش
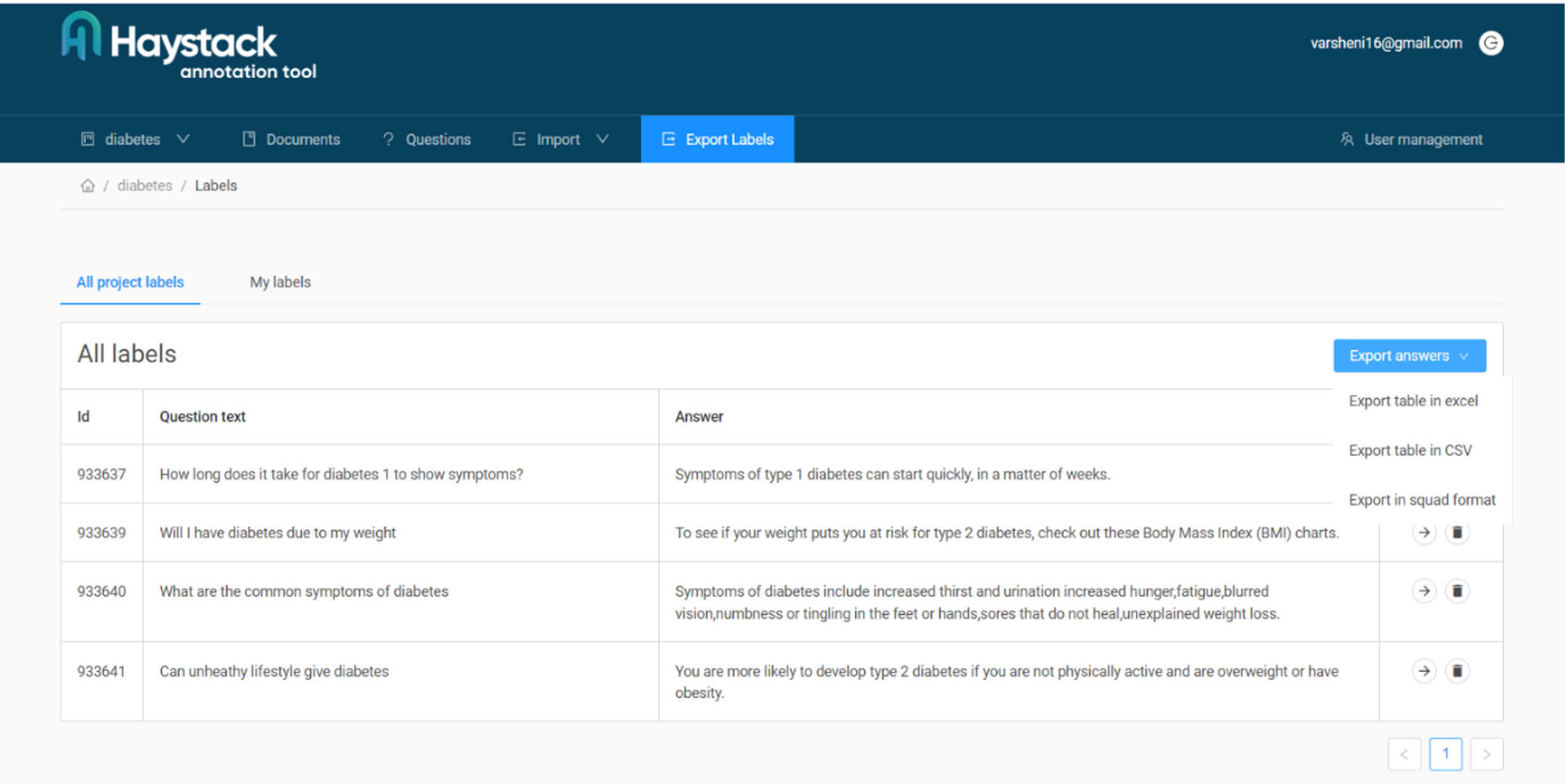
عند الانتهاء من إنشاء عدد كافٍ من أزواج الأسئلة والأجوبة للضبط الدقيق ، يجب أن تكون قادرًا على رؤية ملخص لها كما هو موضح أدناه. ضمن علامة التبويب "تصدير الملصقات" ، يمكنك العثور على خيارات متعددة للتنسيق الذي تريد التصدير به. نختار تنسيق المجموعة لحالتنا. إذا كنت بحاجة إلى مزيد من المساعدة في استخدام الأداة ، فيمكنك التحقق من ملفات توثيق. لدينا الآن ملف JSON الخاص بنا الذي يحتوي على أزواج QA للضبط الدقيق.
كيف يتم الضبط؟
تقدم Python العديد من الحزم مفتوحة المصدر التي يمكنك استخدامها لضبطها. لقد استخدمت حزمة Pytorch and Transformers لحالتي. ابدأ باستيراد وحدات الحزمة باستخدام pip ، مدير الحزم. ال transformers توفر المكتبة أ BERTTokenizer، وهو مخصص بشكل خاص لإدخال رموز رمزية إلى نموذج BERT.
!pip install torch
!pip install transformers import json
import torch
from transformers import BertTokenizer, BertForQuestionAnswering
from torch.utils.data import DataLoader, Dataset
تحديد مجموعة البيانات المخصصة للتحميل والمعالجة المسبقة
الخطوة التالية هي تحميل البيانات ومعالجتها مسبقًا. يمكنك استخدام ال Dataset فئة من pytorch's utils.data وحدة لتحديد فئة مخصصة لمجموعة البيانات الخاصة بك. لقد قمت بإنشاء فئة مجموعة بيانات مخصصة diabetes كما ترى في مقتطف الشفرة أدناه. ال init هي المسؤولة عن تهيئة المتغيرات. ال file_path هي وسيطة ستدخل مسار ملف تدريب JSON الخاص بك وسيتم استخدامها للتهيئة data. نقوم بتهيئة ملف BertTokenizer هنا أيضا.
بعد ذلك ، نحدد ملف load_data() وظيفة. ستقرأ هذه الوظيفة ملف JSON في كائن بيانات JSON واستخراج السياق والسؤال والإجابات وفهرسها منه. يقوم بإلحاق الحقول المستخرجة في قائمة وإرجاعها.
• getitem يستخدم رمز BERT المميز لتشفير السؤال والسياق في موترات الإدخال input_ids و attention_mask. encode_plus سيقوم بترميز النص ، ويضيف الرموز المميزة الخاصة (مثل [CLS] و [SEP]). لاحظ أننا نستخدم ملف squeeze() طريقة لإزالة أي أبعاد مفردة قبل الإدخال إلى BERT. أخيرًا ، تقوم بإرجاع موتر الإدخال المعالج.
class diabetes(Dataset): def __init__(self, file_path): self.data = self.load_data(file_path) self.tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') def load_data(self, file_path): with open(file_path, 'r') as f: data = json.load(f) paragraphs = data['data'][0]['paragraphs'] extracted_data = [] for paragraph in paragraphs: context = paragraph['context'] for qa in paragraph['qas']: question = qa['question'] answer = qa['answers'][0]['text'] start_pos = qa['answers'][0]['answer_start'] extracted_data.append({ 'context': context, 'question': question, 'answer': answer, 'start_pos': start_pos, }) return extracted_data def __len__(self): return len(self.data) def __getitem__(self, index): example = self.data[index] question = example['question'] context = example['context'] answer = example['answer'] inputs = self.tokenizer.encode_plus(question, context, add_special_tokens=True, padding='max_length', max_length=512, truncation=True, return_tensors='pt') input_ids = inputs['input_ids'].squeeze() attention_mask = inputs['attention_mask'].squeeze() start_pos = torch.tensor(example['start_pos']) return input_ids, attention_mask, start_pos, end_pos
بمجرد تحديده ، يمكنك المضي قدمًا وإنشاء مثيل لهذه الفئة عن طريق تمرير file_path حجة لذلك.
file_path = 'diabetes.json'
dataset = diabetes(file_path)
تدريب النموذج
سأستخدم ملف BertForQuestionAnswering نموذج لأنه الأنسب لمهام ضمان الجودة. يمكنك تهيئة الأوزان المدربة مسبقًا الخاصة بـ bert-base-uncased النموذج عن طريق استدعاء from_pretrained تعمل على النموذج. يجب عليك أيضًا اختيار وظيفة خسارة التقييم والمحسن الذي ستستخدمه للتدريب.
تحقق من دليلنا العملي العملي لتعلم Git ، مع أفضل الممارسات ، والمعايير المقبولة في الصناعة ، وورقة الغش المضمنة. توقف عن أوامر Googling Git وفي الواقع تعلم ذلك!
أنا أستخدم مُحسِّن آدم ووظيفة فقدان الانتروبيا. يمكنك استخدام فئة Pytorch DataLoader لتحميل البيانات على دفعات مختلفة وكذلك خلطها عشوائيًا لتجنب أي تحيز.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = BertForQuestionAnswering.from_pretrained('bert-base-uncased')
model.to(device) optimizer = torch.optim.AdamW(model.parameters(), lr=2e-5)
loss_fn = torch.nn.CrossEntropyLoss()
batch_size = 8
num_epochs = 50 data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
بمجرد تحديد أداة تحميل البيانات ، يمكنك المضي قدمًا وكتابة حلقة التدريب النهائية. خلال كل تكرار ، يتم الحصول على كل دفعة من data_loader يحتوي batch_size عدد من الأمثلة التي يتم تنفيذ الانتشار الأمامي والخلفي عليها. يحاول الكود العثور على أفضل مجموعة من الأوزان للمعلمات ، والتي ستكون الخسارة عندها ضئيلة.
for epoch in range(num_epochs): model.train() total_loss = 0 for batch in data_loader: input_ids = batch[0].to(device) attention_mask = batch[1].to(device) start_positions = batch[2].to(device) optimizer.zero_grad() outputs = model(input_ids, attention_mask=attention_mask, start_positions=start_positions) loss = outputs.loss loss.backward() optimizer.step() total_loss += loss.item() avg_loss = total_loss / len(data_loader) print(f"Epoch {epoch+1}/{num_epochs} - Average Loss: {avg_loss:.4f}")
هذا يكمل صقلك! يمكنك اختبار النموذج من خلال ضبطه على model.eval(). يمكنك أيضًا استخدام الضبط الدقيق لمعدل التعلم ، وعدم استخدام أي من معلمات العصور للحصول على أفضل النتائج على بياناتك.
أفضل النصائح والممارسات
إليك بعض النقاط التي يجب ملاحظتها أثناء ضبط أي نماذج لغة كبيرة على البيانات المخصصة:
- تحتاج مجموعة البيانات الخاصة بك إلى تمثيل المجال أو المهمة المستهدفة التي تريد أن يتفوق فيها نموذج اللغة. نظيف والبيانات جيدة التنظيم ضرورية.
- تأكد من أن لديك أمثلة تدريب كافية في بياناتك للنموذج لتعلم الأنماط. عدا ذلك ، قد يحفظ النموذج الأمثلة ويزيد من عدم القدرة على ذلك عمم لأمثلة غير مرئية.
- اختر نموذجًا مدربًا مسبقًا تم تدريبه على مجموعة ذات صلة بمهمتك الحالية. للإجابة على الأسئلة ، نختار نموذجًا مُدرَّبًا مسبقًا تم تدريبه على مجموعة بيانات ستانفورد للإجابة على الأسئلة. على غرار ذلك ، هناك نماذج مختلفة متاحة لمهام مثل تحليل المشاعر ، وإنشاء النص ، والتلخيص ، وتصنيف النص ، والمزيد.
- جرّب تراكم التدرج إذا كانت لديك ذاكرة GPU محدودة. في هذه الطريقة ، بدلاً من تحديث أوزان النموذج بعد كل دفعة ، يتم تجميع التدرجات على دفعات صغيرة متعددة قبل إجراء التحديث.
- إذا كنت تواجه مشكلة فرط التجهيز أثناء الضبط ، فاستخدم تسوية تكنكيوس. تتضمن بعض الطرق الشائعة الاستخدام إضافة طبقات متسربة إلى بنية النموذج ، وتنفيذ انحلال الوزن وتطبيع الطبقة.
وفي الختام
يمكن أن تساعدك نماذج اللغات الكبيرة في أتمتة العديد من المهام بطريقة سريعة وفعالة. يساعدك الضبط الدقيق لـ LLM على الاستفادة من قوة تعلم النقل وتخصيصه لمجالك الخاص. يمكن أن يكون الضبط الدقيق أمرًا ضروريًا إذا كانت مجموعة البيانات الخاصة بك في مجالات مثل المجالات الطبية والتقنية ومجموعات البيانات المالية والمزيد.
في هذه المقالة استخدمنا BERT لأنه مفتوح المصدر ويعمل بشكل جيد للاستخدام الشخصي. إذا كنت تعمل على مشروع واسع النطاق ، فيمكنك اختيار LLMs أكثر قوة ، مثل GPT3 ، أو بدائل أخرى مفتوحة المصدر. تذكر أن ضبط نماذج اللغات الكبيرة يمكن أن يكون مكلفًا من الناحية الحسابية ويستغرق وقتًا طويلاً. تأكد من أن لديك موارد حسابية كافية ، بما في ذلك وحدات معالجة الرسومات (GPU) أو وحدات المعالجة الحرارية (TPU) بناءً على المقياس.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون السيارات / المركبات الكهربائية ، كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- BlockOffsets. تحديث ملكية الأوفست البيئية. الوصول هنا.
- المصدر https://stackabuse.com/guide-to-fine-tuning-open-source-llms-on-custom-data/

