تعد خدمة قاعدة مستخدمين كبيرة ببيانات موثوقة ومتسقة وذات زمن انتقال منخفض تحديًا صعبًا للغاية لأي فريق خلفي. في Ledger ، اتخذنا خيارًا استراتيجيًا لاستضافة خدمات البيانات الأساسية الخاصة بنا من blockchain. من خلال عدم الاعتماد على أطراف ثالثة ، يمكننا إدارة بيانات عملائنا بأنفسنا ، والتأكد من أن العمليات الأساسية تلتزم بإرشادات الأمان الخاصة بنا وأهداف مستوى الخدمة (SLO) الموجهة نحو الأداء.
لكن هذه الاستراتيجية تجلب معها مجموعة التحديات الخاصة بها أيضًا.
يتمثل التحدي الأول الذي يواجهنا في ترحيل خدمات توفير البيانات الأساسية هذه بعيدًا عن أدوات noSQL الرائعة والبراقة. في هذه المقالة ، سوف أتعمق في سبب اتخاذنا لهذا القرار الصعب ، والتعقيدات التي واجهناها والفوائد التي جنيها.
الهدف من هذه المقالة هو إظهار الجوانب التقنية التي دفعتنا إلى اختيار PostgreSQL كطبقة تخزين أساسية جديدة لبيانات blockchain.
الغوص العميق في بيانات Blockchain

تحتوي بيانات Blockchain على العديد من الميزات الرئيسية.
أولاً ، إنه ينمو باستمرار ، ولا يتم حذف أي شيء منه. ومع ذلك ، من الناحية العملية ، على الرغم من أن معظم blockchain غير قابل للتغيير ، فقد يتغير الجزء الأصغر من blockchain بسبب التعارضات التي يجب حلها. في الواقع ، نظرًا لأن السلسلة عبارة عن شبكة نظير إلى نظير ، فقد تتعايش عدة كتل مشروعة بشكل مؤقت. عادة ، يتم حذف الأقدم ، مما يؤدي إلى ما نسميه إعادة التنظيم. باختصار ، يتم تقسيم البيانات بين ذيل بارد غير قابل للتغيير وحالة رأس نادراً ما تتغير.
المشكلة التي نحاول حلها هي أنه في حين أن blockchain رائع لامتلاك بيانات بيزنطية متسامحة مع الأخطاء ، إلا أنها أقل فاعلية في تقطيعها وتقطيعها على العديد من المحاور. على وجه التحديد ، الحصول على قائمة العمليات التي أثرت على الحساب أمر صعب للغاية. حتى الحصول على رصيد حساب على blockchain مثل bitcoin يمثل تحديًا عندما لا يكون لديك بالفعل قائمة المعاملات.
للتغلب على هذه التحديات ، تقوم Ledger Explorer Services بفهرسة blockchain بالكامل .. إنها خدمة كبيرة وحاسمة وحساسة للأداء مكتوبة بالكامل في Scala ، باستخدام تأثير القطط وقت تشغيل عالي الأداء. لقد تجاوزنا 10k rps على البيتكوين ، مع الحفاظ على زمن انتقال p95 أقل من 100 مللي ثانية. نحن أيضا نوظف 😊.
قليلا من التاريخ
في بداية قصتنا ، قبل انضمامي إلى الشركة بوقت طويل ، تمت معالجة طبقة خدمة بيانات دفتر الأستاذ بواسطة قاعدة بيانات Neo4j مضمنة. كان كل صندوق تقديم يفهرس بياناته ويقدمها محليًا ، مما تسبب في الكثير من المشكلات.
لم يكن اتساق البيانات بين الحالات مضمونًا ، ولم يكن الحجم الهائل للحالة التي يجب فهرستها ، جنبًا إلى جنب مع استخدام قرص neo4j وذاكرة الوصول العشوائي ، قابلاً للتطوير. تفاقمت هذه المشكلة مع نمو الشركة ، مما زاد من صعوبة إنتاج حالات جديدة.
كاساندرا تم اختياره بعد ذلك ليكون المحرك الرئيسي لهذا الإعداد الجديد: فهو عبارة عن قاعدة بيانات مجمعة وقابلة للتحجيم أفقيًا موجودة في جانب AP من نظرية CAP. إنه يحل المشكلات المتعلقة بمشاركة البيانات ويسمح بفصل واضح بين الفهرسة ومكون blockchain وخوادم API بدون رؤوس.

ولكن ما هو الهدف من إتاحة الحالة التاريخية بأكملها إذا لم نكن نرغب في القراءة منها فعليًا؟
فيما يتعلق بحالة الاستخدام الخاصة بنا ، نادرًا ما تكون هناك حاجة إلى البيانات التاريخية الأولية لأنه يمكن تجميع حالة حساب المستخدم لدينا منها. قادنا هذا إلى تحدي حل تخزين البيانات الحالي الذي يعتمد على قاعدة بيانات كاساندرا الموزعة.
حجم البيانات التي نحتاج إلى تخزينها لكل blockchain ، على الرغم من أنه في نطاق تيرابايت ، ليس ما يمكن أن نطلق عليه "البيانات الكبيرة". علاوة على ذلك ، فإن الجزء المتعلق بما إذا كان سيتم استخدامه للإجابة على معظم الاستفسارات (المعروف أيضًا باسم المسار السريع) يكون أصغر. في الوقت الحاضر ، يمكن للمرء بسهولة العثور على خوادم أجهزة سلعة تحتوي على أكثر من 16 تيرابايت من تخزين NVMe SSD. القياس العمودي هو أداة قوية للغاية ، وقاعدة البيانات العلائقية هي أيضًا.
أخيرًا ، كانت المشكلة الرئيسية التي واجهتنا مع إعداد كاساندرا الحالي لا تتعلق بنموذج التخزين المهدر ولا حالة استخدام البيانات سيئة التجهيز ، ولكن عدم ملاءمة المطورين. أثبت تطوير ميزة جديدة قائمة على البيانات في كاساندرا أنها تستغرق وقتًا طويلاً بلا داعٍ. لقد سعينا جاهدين لتنفيذ كل محور جديد نحتاج إلى توفير البيانات عليه.
بالنظر إلى خبرة فريقنا في مهارات نمذجة البيانات وإتقان SQL ، كيو كان المرشح المثالي. هذا الحل تم اختباره في المعركة ، وهو قوي وسهل التمديد ، مما يجعله خيارًا مثاليًا.
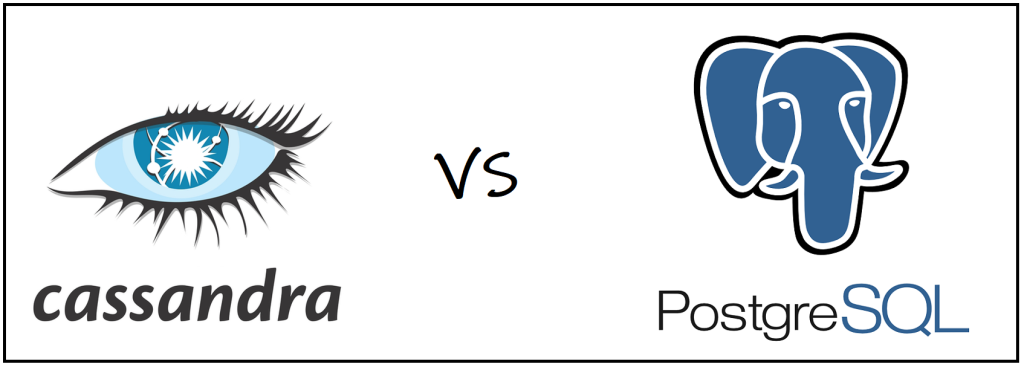
لماذا اخترنا SQL على NoSQL:
- يقرأ / يكتب الأرصدة: تم انحراف حالة استخدام بيانات blockchain بشدة في عمليات القراءة بدلاً من الكتابة (يكتب blockchain عددًا قليلاً جدًا من البيانات بمعدل معقول جدًا ، حتى بالنسبة إلى blockchain مثل Polygon). لدى Cassandra القدرة على استيعاب قدر كبير جدًا من الكتابات - مسار القراءة هو في الواقع يعد من مسار الكتابة.
- دعم الفهرسة: المؤشرات هي عنصر أساسي في نظام إدارة قواعد البيانات (DBMS) للرد على الاستفسارات وحالات العمل أو الفرص الجديدة. كاساندرا لديها دعم محدود للفهرسة. تكون الفهارس فعالة فقط إذا كان الاستعلام يحدد بالفعل طريقة لتقييد القسم الذي سيتم تشغيل الاستعلام عليه. نحن ندفع هنا تكلفة الحصول على ملف توزيع تعسفي قاعدة البيانات. دعم PostgreSQL للمؤشرات يتسم بالكفاءة ، وقابل للتوسيع ، وعلى الحافة.
- دعم التجميع: نفس الحالة للتجميع ؛ نظرًا لأن Cassandra لا تسمح بالتجميع متعدد الأقسام ولا تتسامح مع أي عبارة GROUP BY في لغة الاستعلام الخاصة بها ، فإن دعمها يفتقر إلى نوع ما. تقترح PostgreSQL دعمًا شاملاً للتجميع ، حتى على أنواع البيانات الغريبة مثل النطاقات و jsonb blobs.
- نمذجة البيانات: Cassandra مقيدة جدًا جدًا في الطريقة التي يمكن بها نمذجة البيانات. يجب إنشاء جدول تقريبًا لكل طلب تريد الإجابة عليه ، ويجب إلغاء تنسيق البيانات إلى صفوف كبيرة (باستخدام مخزن العمود الواسع جانب من C * وكذلك حقيقة أن الكتاب رخيصين للغاية). تتيح لنا PostgreSQL الاستفادة من الجانب العلائقي لـ blockchain (المكالمات والمعاملات والكتل) ومساحة القرص الاحتياطية ، مما يشجع على إعادة استخدام البيانات.
- الاستفسارات الخاصة والتدقيق: القدرة على استخدام المعيار الكامل لـ SQL والقيام باستعلامات عشوائية تعني أنه يمكننا استكشاف السبب الجذري للخطأ المحتمل والبحث عنه أو الحصول على بيانات استكشافية لحالات الاستخدام المستقبلية. يمكننا حقًا استخدام قاعدة البيانات كأداة تفاعلية وذكية بدلاً من تخزين غبي. القيام بذلك على Cassandra بدون مجموعة تحليلات شاملة ومكلفة مثل Presto و Spark وما إلى ذلك (وبما أننا نعمل على خوادم معدنية عارية ، لا يمكننا الوصول إلى أدوات تحليل البيانات الموزعة بسهولة مثل EMR).
- استخدام التخزين: تفترض كاساندرا أن التخزين رخيص جدًا وأنه يمكن توسيع الكتلة بسهولة بآلات جديدة. هذا يعني أن يجب دفع جميع القيود المفروضة على كل من المؤشرات والتجميعات من خلال التخزين. عدم وجود مؤشرات فعالة عالميًا والانضمام إلى الدعم يعني أنه يتعين علينا إلغاء تسوية وتخزين نسخة من الجدول بالكامل لكل محور نريد الاستعلام عنه. توفر لنا PostgreSQL مساحة تخزين تبلغ تيرابايت.
- اتساق: نظرًا لأن Cassandra هي قاعدة بيانات موزعة وموجهة نحو AP (يتم الاتصال بالثرثرة بين العقد) ، يكون الاتساق في النهاية فقط من حيث الكتابة. يمكنك ضبط سياسة التناسق لكل عبارة للقراءة والكتابة ، ولكن الهدف من قاعدة البيانات هذه لم يكن أبدًا أن يكون الاتساق قويًا. تتمتع PostgreSQL بقصة قوية حول استخدامها في المهام الحرجة وتتميز بالمرونة العالية. أن تكون مركزيًا يعني أيضًا عدم وجود شبكة متورطة في مسار الكتابة.
- المعاملات و MVCC:
- المعاملات: تدعم كاساندرا فقط المعاملات خفيفة الوزن على استعلامات DML. يمكن تطبيق بعض الدُفعات (الوثيقة) ولكن هناك العديد من المحاذير ، وهي أن الصفوف يجب أن تكون في نفس الخادم (= القسم) حتى لا يكون لها أداء فظيع.
- MVCC: تدعم Cassandra ختم وقت الصف ولكن لا يتم ضمان MVCC الكامل. يمكن للضغط أن يمحو البيانات التي لا معنى لها ولا توجد طريقة لإخبار C * أنه لا ينبغي (مثل معاملة في PG).
- تدعم PostgreSQL نموذج MVCC قويًا يضمن مسار قراءة ثابتًا لمستخدمينا.
- تزيين: تمتلك PostgreSQL العديد من الأدوات التي تُستخدم على نطاق واسع لتشغيل قاعدة البيانات بسهولة. علاوة على ذلك ، أداة مثل عن طريق الطيران يضمن أننا نحافظ على إصدار قوي لمخطط قاعدة البيانات. لقد قمنا بالفعل بدمجها مع قاعدة التعليمات البرمجية الخاصة بنا بنجاح. لا يوجد ما يعادل هذا المستوى من النضج على كاساندرا.
- قابلية التوسع الأفقي: هذه هي نقطة البيع الرئيسية في Cassandra ، ما عليك سوى إضافة المزيد من الآلات مع توسع بياناتك. لا يوجد مكافئ لـ PostgreSQL حيث يجب إجراء التجزئة والتجزئة يدويًا.
كيف نخطط للقياس
كما رأينا ، فإن الجانب السلبي الوحيد لاستخدام إعداد Postgres هو التوسع في كل من القراءات والتخزين. ما الذي يمكننا فعله للتغلب على هذا القيد؟
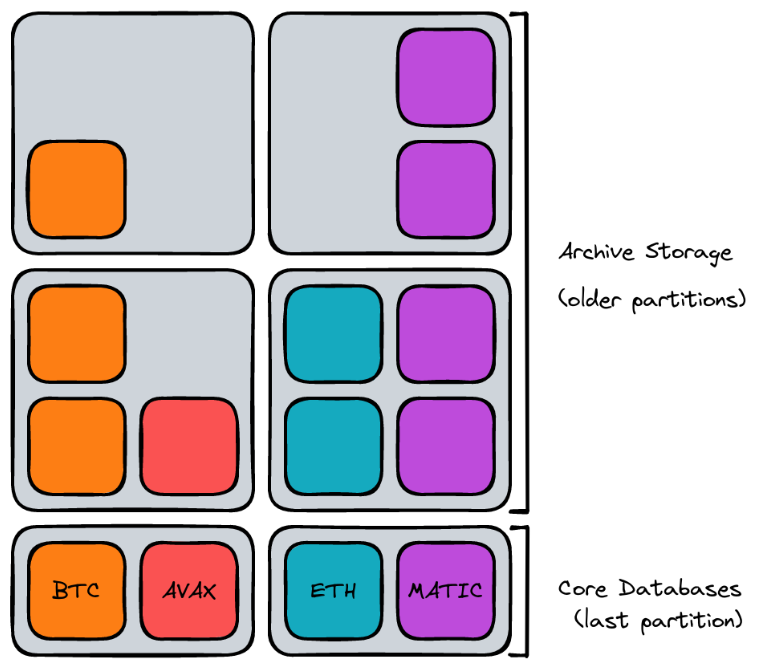
أول أداة فعالة لدينا هي فصل كل بروتوكول أو blockchain ندعمه في قاعدة البيانات الخاصة به ، وبالتالي يمكن توسيع نطاقه بشكل مناسب نظرًا للحجم وحركة المرور. يضمن التقسيم حسب مجال الأعمال الطبقة الأولى من القياس.
من خلال أخذ هذا المفهوم إلى أبعد من ذلك ، يمكننا أيضًا تقسيم البيانات التاريخية الباردة إلى قسم زمني. لقد حسنت الإصدارات الأخيرة من Postgres كثيرًا من قابلية استخدام الجداول المقسمة ، والتي يمكن أن تمكن من نقل البيانات بسلاسة عبر مجموعة من الأجهزة. على سبيل المثال ، يمكننا استخدام أجهزة أرخص ذات قدرة حوسبية أقل لاستضافة غالبية البيانات التاريخية ، مع الاحتفاظ بخدمات المستخدم العملاقة المكدسة بذاكرة الوصول العشوائي (RAM) لاستضافة الجداول المجمعة وأحدث عمليات المستخدم.
يعمل هذا النهج جيدًا في حالة الاستخدام الخاصة بنا لأنه لا توجد مفاتيح خارجية للتقسيم العرضي في التخزين التاريخي (كل شيء مرتبط في النهاية بالكتلة). من منظور الخادم الرئيسي ، يمكن الوصول إلى البيانات التاريخية بشفافية باستخدام التقسيم وامتداد postgres_fdw.
من أجل المساعدة في وضع كل هذا في مكانه الصحيح ، نظرنا أيضًا في ملحق TimescaleDB. يضيف هذا الامتداد الكثير من الوظائف إلى postgres الأساسية ، ومعظمها مناسب تمامًا لحالات الاستخدام لدينا:
- التقسيم التلقائي للجداول بناءً على وقت مثل العمود (في حالتنا ، نقوم بتكييفه من خلال اتخاذ ارتفاع blockchain كمرجع لنا).
- تلقائي ، نوع البيانات مع علم وضغط قائم على العمود للكتل القديمة. هذا يضمن نسبة ضغط مثالية تقريبًا باستخدام خوارزميات حديثة على البيانات المتشابهة جدًا.
- تجميع فعال يعتمد على مقدار الوقت من أجل حساب الأرصدة التاريخية والرسوم البيانية لبيانات السوق بسهولة.
ما زلنا في بداية التجريب فيما يتعلق بالتخزين ، وهذا يفتح الكثير من حالات الاستخدام. إثبات المفاهيم باستخدام كمية صغيرة من البيانات (حوالي 10 آلاف كتلة على شبكة إيثيريوم الرئيسية ، أي حوالي يومين من البيانات) أظهر تقليل مساحة القرص بنسبة تصل إلى 40٪.
كما رأينا ، لا يمثل حجم البيانات ، بشرط استخدام الإستراتيجية الصحيحة ، مشكلة. ولكن كيف تتناسب مع حجم قاعدة مستخدمينا؟
لدينا بالفعل ميزة رائعة هنا: نقوم بفهرسة بيانات blockchain بأكملها. وبالتالي ، لن ينمو التخزين المطلوب مثل عدد المستخدمين ، ولكن مثل الحجم الإجمالي لـ blockchain. تعتبر تحسينات التخزين والقراءة متعامدة تمامًا في الدقة.
هذا الإعداد ، جنبًا إلى جنب مع الحاجة المنخفضة جدًا للكتابة بما يتناسب مع حجم القراءة الذي يجب تقديمه ، هو الإعداد الحلم لنمط نسخة متماثلة من القادة والمتابعين. من أجل تعزيز المزيد من الأداء والإنتاجية ، يمكننا أيضًا وضع النسخ المتماثلة للقراءة postgres على نفس الأجهزة مثل خوادم API والاستفادة من مآخذ مجال UNIX لتخطي رحلات الشبكة ذهابًا وإيابًا.
فيما يلي مثال على استراتيجية نسخ البيانات التي يمكننا استخدامها لتوسيع نطاق قراءاتنا. تمثل الصناديق ذات اللون الرمادي الفاتح خوادم فردية. يمكننا أن نرى هنا أن قرون واجهة برمجة التطبيقات يتم وضعها بشكل مشترك مع النسخ المتماثلة لأهم البيانات لضمان أقل وقت نقل بين التخزين والمستخدمين. لم يتم تمثيل مثيلات الأرشيف الموصوفة مسبقًا لعدم تعقيد المخطط كثيرًا.

ملاحظات ختامية
بصفتي مستخدم Cassandra على المدى الطويل ، أود التأكيد على أنها قاعدة بيانات رائعة في تصميمها ، وتناسب مجموعة متنوعة من التطبيقات. لسوء الحظ ، تم الاختيار الذي تم إجراؤه في Ledger لاستخدامه في حالة استخدام البيانات التي لم تتحقق أبدًا.
لقد تأثرت إنتاجية فريقنا ، ونتطلع إلى التحديات التي يتعين علينا حلها ، واخترنا أن نتغلب عليها وأن لا نقع في مغالطة التكلفة الغارقة.
في كثير من الحالات ، لا تكون بياناتك بيانات ضخمة. إدارة توزيع البيانات ليست مهمة صعبة في معظم الحالات ، والمفاضلات الخاصة بقاعدة البيانات الموزعة الكاملة تحتاج حقًا إلى النظر فيها بعناية. الاعتبار الرئيسي هو تجربة المطور لأنها توفر وقتًا ثمينًا لبناء أي شيء آخر ، هذه هي حالة الاستخدام الحقيقية التي نحتاج إلى الاستثمار فيها بشكل كبير.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- أفلاطونايستريم. ذكاء بيانات Web3. تضخيم المعرفة. الوصول هنا.
- سك المستقبل مع أدرين أشلي. الوصول هنا.
- شراء وبيع الأسهم في شركات ما قبل الاكتتاب مع PREIPO®. الوصول هنا.
- المصدر https://www.ledger.com/blog/serving-web3-at-web2-scale

