شارك في تأليف هذا المقال أناتولي خومينكو، مهندس التعلم الآلي، وعبد النور بزوه، الرئيس التنفيذي للتكنولوجيا في Talent.com.
أنشئت في 2011، Talent.com يجمع قوائم الوظائف المدفوعة الأجر من عملائه وقوائم الوظائف العامة، وقد أنشأ منصة موحدة يمكن البحث فيها بسهولة. يغطي Talent.com أكثر من 30 مليون قائمة وظائف في أكثر من 75 دولة ويغطي لغات وصناعات وقنوات توزيع مختلفة، ويلبي الاحتياجات المتنوعة للباحثين عن عمل، ويربط بشكل فعال الملايين من الباحثين عن عمل بفرص العمل.
مهمة Talent.com هي تسهيل اتصالات القوى العاملة العالمية. ولتحقيق ذلك، يقوم موقع Talent.com بتجميع قوائم الوظائف من مصادر مختلفة على الويب، مما يوفر للباحثين عن عمل إمكانية الوصول إلى مجموعة واسعة تضم أكثر من 30 مليون فرصة عمل مصممة خصيصًا لتناسب مهاراتهم وخبراتهم. وتماشيًا مع هذه المهمة، تعاون موقع Talent.com مع AWS لتطوير محرك متطور لتوصيات الوظائف يعتمد على التعلم العميق، ويهدف إلى مساعدة المستخدمين في تطوير حياتهم المهنية.
لضمان التشغيل الفعال لمحرك توصية الوظائف هذا، من الضروري تنفيذ مسار معالجة بيانات واسع النطاق مسؤول عن استخراج الميزات وتحسينها من قوائم الوظائف المجمعة في Talent.com. هذا المسار قادر على معالجة 5 ملايين سجل يومي في أقل من ساعة واحدة، ويسمح بمعالجة عدة أيام من السجلات بالتوازي. بالإضافة إلى ذلك، يسمح هذا الحل بالنشر السريع في الإنتاج. المصدر الأساسي للبيانات لخط الأنابيب هذا هو تنسيق خطوط JSON المخزنة فيه خدمة تخزين أمازون البسيطة (Amazon S3) ومقسمة حسب التاريخ. كل يوم، يؤدي هذا إلى إنشاء عشرات الآلاف من ملفات JSON Lines، مع تحديثات تدريجية تحدث يوميًا.
الهدف الأساسي من مسار معالجة البيانات هذا هو تسهيل إنشاء الميزات اللازمة للتدريب ونشر محرك التوصية الوظيفية على Talent.com. تجدر الإشارة إلى أن خط الأنابيب هذا يجب أن يدعم التحديثات المتزايدة ويلبي متطلبات استخراج الميزات المعقدة اللازمة لوحدات التدريب والنشر الضرورية لنظام التوصية الوظيفية. ينتمي خط الأنابيب الخاص بنا إلى عائلة عمليات ETL العامة (الاستخراج والتحويل والتحميل) التي تجمع البيانات من مصادر متعددة في مستودع مركزي كبير.
لمزيد من الأفكار حول كيفية قيام Talent.com وAWS بشكل تعاوني ببناء معالجة متطورة للغة الطبيعية وتقنيات التدريب على نماذج التعلم العميق، وذلك باستخدام الأمازون SageMaker لصياغة نظام التوصية الوظيفية، راجع من النص إلى وظيفة الأحلام: بناء توصية للوظائف قائمة على البرمجة اللغوية العصبية في Talent.com مع Amazon SageMaker. يتضمن النظام هندسة الميزات، وتصميم بنية نموذج التعلم العميق، وتحسين المعلمات الفائقة، وتقييم النموذج، حيث يتم تشغيل جميع الوحدات باستخدام Python.
يوضح هذا المنشور كيف استخدمنا SageMaker لإنشاء مسار واسع النطاق لمعالجة البيانات لإعداد الميزات لمحرك توصيات الوظائف على Talent.com. يمكّن الحل الناتج عالم البيانات من التفكير في استخراج الميزات في دفتر ملاحظات SageMaker باستخدام مكتبات Python، مثل سكيكيت ليرن or PyTorch، ثم نشر نفس الكود بسرعة في مسار معالجة البيانات الذي يقوم باستخراج الميزات على نطاق واسع. لا يتطلب الحل نقل كود استخراج الميزة لاستخدام PySpark، كما هو مطلوب عند الاستخدام غراء AWS كحل ETL. يمكن تطوير الحل الخاص بنا ونشره فقط بواسطة عالم البيانات بشكل شامل باستخدام SageMaker فقط، ولا يتطلب معرفة بحلول ETL الأخرى، مثل دفعة AWS. يمكن أن يؤدي هذا إلى تقليل الوقت اللازم لنشر مسار التعلم الآلي (ML) في الإنتاج بشكل كبير. يتم تشغيل خط الأنابيب من خلال لغة Python ويتكامل بسلاسة مع سير عمل استخراج الميزات، مما يجعله قابلاً للتكيف مع مجموعة واسعة من تطبيقات تحليلات البيانات.
حل نظرة عامة
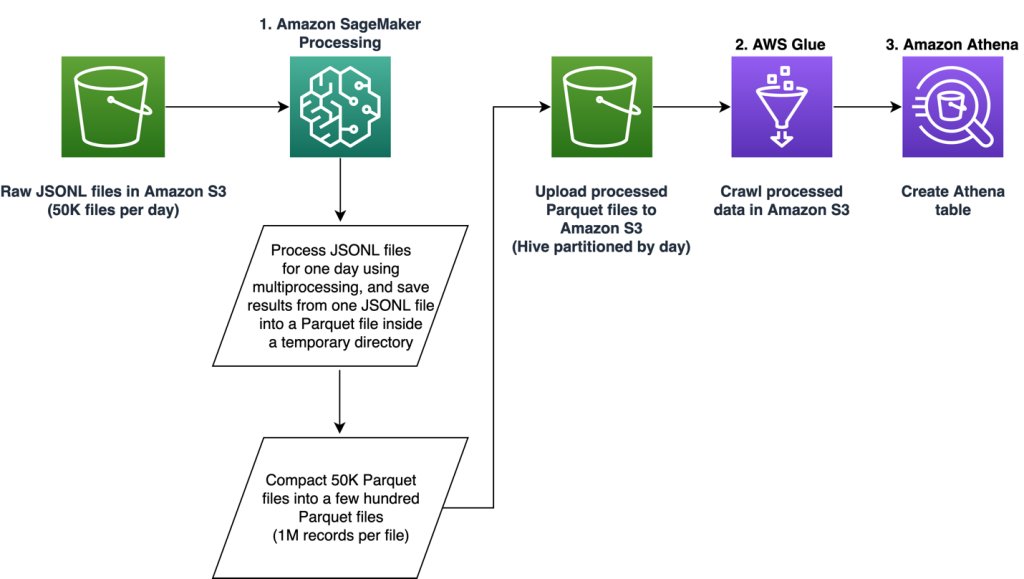
يتكون خط الأنابيب من ثلاث مراحل أساسية:
- استخدم ملف أمازون SageMaker معالجة مهمة للتعامل مع ملفات JSONL الأولية المرتبطة بيوم محدد. يمكن معالجة عدة أيام من البيانات عن طريق مهام معالجة منفصلة في وقت واحد.
- توظيف غراء AWS للزحف إلى البيانات بعد معالجة عدة أيام من البيانات.
- قم بتحميل الميزات التي تمت معالجتها لنطاق زمني محدد باستخدام SQL من ملف أمازون أثينا الجدول، ثم قم بتدريب ونشر نموذج التوصية بالوظيفة.
معالجة ملفات JSONL الخام
نقوم بمعالجة ملفات JSONL الأولية ليوم محدد باستخدام مهمة معالجة SageMaker. تنفذ الوظيفة استخراج الميزات وضغط البيانات، وتحفظ الميزات المعالجة في ملفات Parquet بمليون سجل لكل ملف. نحن نستفيد من موازاة وحدة المعالجة المركزية (CPU) لإجراء استخراج الميزات لكل ملف JSONL خام بالتوازي. يتم حفظ نتائج معالجة كل ملف JSONL في ملف Parquet منفصل داخل دليل مؤقت. بعد معالجة جميع ملفات JSONL، نقوم بضغط آلاف ملفات Parquet الصغيرة في عدة ملفات بمعدل مليون سجل لكل ملف. يتم بعد ذلك تحميل ملفات Parquet المضغوطة إلى Amazon S1 كمخرجات لمهمة المعالجة. يضمن ضغط البيانات الزحف الفعال واستعلامات SQL في المراحل التالية من المسار.
فيما يلي نموذج التعليمات البرمجية لجدولة مهمة معالجة SageMaker ليوم محدد، على سبيل المثال 2020-01-01، باستخدام SageMaker SDK. تقرأ المهمة ملفات JSONL الأولية من Amazon S3 (على سبيل المثال من s3://bucket/raw-data/2020/01/01) ويحفظ ملفات Parquet المضغوطة في Amazon S3 (على سبيل المثال s3://bucket/processed/table-name/day_partition=2020-01-01/).
### install dependencies %pip install sagemaker pyarrow s3fs awswrangler import sagemaker
import boto3 from sagemaker.processing import FrameworkProcessor
from sagemaker.sklearn.estimator import SKLearn
from sagemaker import get_execution_role
from sagemaker.processing import ProcessingInput, ProcessingOutput region = boto3.session.Session().region_name
role = get_execution_role()
bucket = sagemaker.Session().default_bucket() ### we use instance with 16 CPUs and 128 GiB memory
### note that the script will NOT load the entire data into memory during compaction
### depending on the size of individual jsonl files, larger instance may be needed
instance = "ml.r5.4xlarge"
n_jobs = 8 ### we use 8 process workers
date = "2020-01-01" ### process data for one day est_cls = SKLearn
framework_version_str = "0.20.0" ### schedule processing job
script_processor = FrameworkProcessor( role=role, instance_count=1, instance_type=instance, estimator_cls=est_cls, framework_version=framework_version_str, volume_size_in_gb=500,
) script_processor.run( code="processing_script.py", ### name of the main processing script source_dir="../src/etl/", ### location of source code directory ### our processing script loads raw jsonl files directly from S3 ### this avoids long start-up times of the processing jobs, ### since raw data does not need to be copied into instance inputs=[], ### processing job input is empty outputs=[ ProcessingOutput(destination="s3://bucket/processed/table-name/", source="/opt/ml/processing/output"), ], arguments=[ ### directory with job's output "--output", "/opt/ml/processing/output", ### temporary directory inside instance "--tmp_output", "/opt/ml/tmp_output", "--n_jobs", str(n_jobs), ### number of process workers "--date", date, ### date to process ### location with raw jsonl files in S3 "--path", "s3://bucket/raw-data/", ], wait=False
)
مخطط التعليمات البرمجية التالي للبرنامج النصي الرئيسي (processing_script.py) الذي يقوم بتشغيل مهمة معالجة SageMaker كما يلي:
import concurrent
import pyarrow.dataset as ds
import os
import s3fs
from pathlib import Path ### function to process raw jsonl file and save extracted features into parquet file from process_data import process_jsonl ### parse command line arguments
args = parse_args() ### we use s3fs to crawl S3 input path for raw jsonl files
fs = s3fs.S3FileSystem()
### we assume raw jsonl files are stored in S3 directories partitioned by date
### for example: s3://bucket/raw-data/2020/01/01/
jsons = fs.find(os.path.join(args.path, *args.date.split('-'))) ### temporary directory location inside the Processing job instance
tmp_out = os.path.join(args.tmp_output, f"day_partition={args.date}") ### directory location with job's output
out_dir = os.path.join(args.output, f"day_partition={args.date}") ### process individual jsonl files in parallel using n_jobs process workers
futures=[]
with concurrent.futures.ProcessPoolExecutor(max_workers=args.n_jobs) as executor: for file in jsons: inp_file = Path(file) out_file = os.path.join(tmp_out, inp_file.stem + ".snappy.parquet") ### process_jsonl function reads raw jsonl file from S3 location (inp_file) ### and saves result into parquet file (out_file) inside temporary directory futures.append(executor.submit(process_jsonl, file, out_file)) ### wait until all jsonl files are processed for future in concurrent.futures.as_completed(futures): result = future.result() ### compact parquet files
dataset = ds.dataset(tmp_out) if len(dataset.schema) > 0: ### save compacted parquet files with 1MM records per file ds.write_dataset(dataset, out_dir, format="parquet", max_rows_per_file=1024 * 1024)
تعد قابلية التوسع سمة أساسية لخط الأنابيب لدينا. أولاً، يمكن استخدام مهام معالجة SageMaker المتعددة لمعالجة البيانات لعدة أيام في وقت واحد. ثانيًا، نتجنب تحميل البيانات المعالجة أو الأولية بالكامل إلى الذاكرة مرة واحدة، أثناء معالجة كل يوم محدد من البيانات. يتيح ذلك معالجة البيانات باستخدام أنواع المثيلات التي لا يمكنها استيعاب بيانات يوم كامل في الذاكرة الأساسية. الشرط الوحيد هو أن نوع المثيل يجب أن يكون قادرًا على تحميل N ملفات JSONL الخام أو ملفات Parquet المعالجة في الذاكرة في وقت واحد، مع كون N هو عدد العاملين في المعالجة قيد الاستخدام.
الزحف إلى البيانات المعالجة باستخدام AWS Glue
بعد معالجة جميع البيانات الأولية لعدة أيام، يمكننا إنشاء جدول Athena من مجموعة البيانات بأكملها باستخدام زاحف AWS Glue. نحن نستخدم ال AWS SDK للباندا (Awswrangler) مكتبة لإنشاء الجدول باستخدام المقتطف التالي:
import awswrangler as wr ### crawl processed data in S3
res = wr.s3.store_parquet_metadata( path='s3://bucket/processed/table-name/', database="database_name", table="table_name", dataset=True, mode="overwrite", sampling=1.0, path_suffix='.parquet',
) ### print table schema
print(res[0])
تحميل الميزات المعالجة للتدريب
يمكن الآن تحميل الميزات التي تمت معالجتها لنطاق زمني محدد من جدول Athena باستخدام SQL، ويمكن بعد ذلك استخدام هذه الميزات لتدريب نموذج التوصية بالوظيفة. على سبيل المثال، يقوم المقتطف التالي بتحميل شهر واحد من الميزات التي تمت معالجتها في DataFrame باستخدام awswrangler مكتبة:
import awswrangler as wr query = """ SELECT * FROM table_name WHERE day_partition BETWEN '2020-01-01' AND '2020-02-01' """ ### load 1 month of data from database_name.table_name into a DataFrame
df = wr.athena.read_sql_query(query, database='database_name')
بالإضافة إلى ذلك، يمكن توسيع استخدام SQL لتحميل الميزات المعالجة للتدريب لاستيعاب حالات الاستخدام الأخرى المتنوعة. على سبيل المثال، يمكننا تطبيق مسار مماثل للحفاظ على جدولي Athena منفصلين: أحدهما لتخزين مرات ظهور المستخدم والآخر لتخزين نقرات المستخدم على مرات الظهور هذه. باستخدام عبارات ربط SQL، يمكننا استرداد مرات الظهور التي نقر عليها المستخدمون أو لم ينقروا عليها ثم تمرير مرات الظهور هذه إلى مهمة تدريب نموذجية.
فوائد الحل
يؤدي تنفيذ الحل المقترح إلى جلب العديد من المزايا لسير العمل الحالي لدينا، بما في ذلك:
- تنفيذ مبسط - يتيح الحل إمكانية تنفيذ استخراج الميزات في Python باستخدام مكتبات ML الشائعة. ولا يتطلب الأمر نقل الكود إلى PySpark. يؤدي هذا إلى تبسيط عملية استخراج الميزات حيث سيتم تنفيذ نفس التعليمات البرمجية التي طورها عالم البيانات في دفتر ملاحظات بواسطة هذا المسار.
- المسار السريع للإنتاج - يمكن تطوير الحل ونشره بواسطة أحد علماء البيانات لإجراء استخراج الميزات على نطاق واسع، مما يمكنهم من تطوير نموذج توصية تعلم الآلة مقابل هذه البيانات. وفي الوقت نفسه، يمكن نشر نفس الحل في الإنتاج بواسطة مهندس تعلم الآلة مع الحاجة إلى تعديلات بسيطة.
- إعادة استخدام – يوفر الحل نمطًا قابلاً لإعادة الاستخدام لاستخراج الميزات على نطاق واسع، ويمكن تكييفه بسهولة مع حالات الاستخدام الأخرى بما يتجاوز بناء نماذج التوصية.
- الكفاءة - يقدم الحل أداءً جيدًا: معالجة يوم واحد من Talent.comاستغرقت بيانات أقل من ساعة واحدة.
- تحديثات تدريجية – يدعم الحل أيضًا التحديثات المتزايدة. يمكن معالجة البيانات اليومية الجديدة باستخدام مهمة معالجة SageMaker، ويمكن إعادة الزحف إلى موقع S3 الذي يحتوي على البيانات المعالجة لتحديث جدول Athena. يمكننا أيضًا استخدام وظيفة cron لتحديث بيانات اليوم عدة مرات يوميًا (على سبيل المثال، كل 3 ساعات).
استخدمنا خط أنابيب ETL هذا لمساعدة Talent.com على معالجة 50,000 ملف يوميًا تحتوي على 5 ملايين سجل، وإنشاء بيانات تدريب باستخدام الميزات المستخرجة من 90 يومًا من البيانات الأولية من Talent.com - بإجمالي 450 مليون سجل عبر 900,000 ملف. ساعد خط الإنتاج الخاص بنا Talent.com في بناء نظام التوصيات ونشره في الإنتاج خلال أسبوعين فقط. أجرى الحل جميع عمليات تعلم الآلة بما في ذلك ETL على Amazon SageMaker دون استخدام خدمات AWS الأخرى. أدى نظام التوصية الوظيفية إلى زيادة بنسبة 2% في نسبة النقر إلى الظهور في اختبار A/B عبر الإنترنت مقارنةً بالحل السابق المستند إلى XGBoost، مما ساعد على ربط الملايين من مستخدمي Talent.com بوظائف أفضل.
وفي الختام
يوضح هذا المنشور مسار ETL الذي قمنا بتطويره لمعالجة الميزات للتدريب ونشر نموذج التوصية الوظيفية على Talent.com. يستخدم مسارنا وظائف معالجة SageMaker لمعالجة البيانات بكفاءة واستخراج الميزات على نطاق واسع. يتم تنفيذ كود استخراج الميزات في Python مما يتيح استخدام مكتبات ML الشائعة لإجراء استخراج الميزات على نطاق واسع، دون الحاجة إلى نقل الكود لاستخدام PySpark.
نحن نشجع القراء على استكشاف إمكانية استخدام المسار المعروض في هذه المدونة كقالب لحالات الاستخدام الخاصة بهم حيث يلزم استخراج الميزات على نطاق واسع. يمكن لعالم البيانات الاستفادة من خط الأنابيب لبناء نموذج تعلم الآلة، ويمكن بعد ذلك اعتماد نفس المسار بواسطة مهندس تعلم الآلة لتشغيله في الإنتاج. وهذا يمكن أن يقلل بشكل كبير من الوقت اللازم لإنتاج حل تعلم الآلة بشكل شامل، كما كان الحال مع Talent.com. ويمكن للقراء الرجوع إلى البرنامج التعليمي لإعداد وتشغيل وظائف معالجة SageMaker. ونحيل القراء أيضًا لمشاهدة المنشور من النص إلى وظيفة الأحلام: بناء توصية للوظائف قائمة على البرمجة اللغوية العصبية في Talent.com مع Amazon SageMaker، حيث نناقش تقنيات التدريب على نموذج التعلم العميق الأمازون SageMaker لبناء نظام التوصية الوظيفية الخاص بـ Talent.com.
عن المؤلفين
 دميتري بيسبالوف هو عالم تطبيقي كبير في Amazon Machine Learning Solutions Lab ، حيث يساعد عملاء AWS في مختلف الصناعات على تسريع تبني الذكاء الاصطناعي والسحابة.
دميتري بيسبالوف هو عالم تطبيقي كبير في Amazon Machine Learning Solutions Lab ، حيث يساعد عملاء AWS في مختلف الصناعات على تسريع تبني الذكاء الاصطناعي والسحابة.
 يي شيانغ هي عالمة تطبيقية II في Amazon Machine Learning Solutions Lab، حيث تساعد عملاء AWS عبر مختلف الصناعات على تسريع اعتماد الذكاء الاصطناعي والسحابة.
يي شيانغ هي عالمة تطبيقية II في Amazon Machine Learning Solutions Lab، حيث تساعد عملاء AWS عبر مختلف الصناعات على تسريع اعتماد الذكاء الاصطناعي والسحابة.
 تونغ وانغ هو عالم تطبيقي كبير في Amazon Machine Learning Solutions Lab ، حيث يساعد عملاء AWS في مختلف الصناعات على تسريع تبني الذكاء الاصطناعي والسحابة.
تونغ وانغ هو عالم تطبيقي كبير في Amazon Machine Learning Solutions Lab ، حيث يساعد عملاء AWS في مختلف الصناعات على تسريع تبني الذكاء الاصطناعي والسحابة.
 أناتولي خومينكو هو مهندس أول للتعلم الآلي في Talent.com مع شغف بمعالجة اللغة الطبيعية ومطابقة الأشخاص الجيدين بالوظائف الجيدة.
أناتولي خومينكو هو مهندس أول للتعلم الآلي في Talent.com مع شغف بمعالجة اللغة الطبيعية ومطابقة الأشخاص الجيدين بالوظائف الجيدة.
 عبد النور بزوح هو مدير تنفيذي يتمتع بخبرة تزيد عن 25 عامًا في بناء وتقديم الحلول التقنية التي تصل إلى ملايين العملاء. شغل عبد النور منصب الرئيس التنفيذي للتكنولوجيا (CTO) في Talent.com عندما قام فريق AWS بتصميم وتنفيذ هذا الحل المحدد لـ Talent.com.
عبد النور بزوح هو مدير تنفيذي يتمتع بخبرة تزيد عن 25 عامًا في بناء وتقديم الحلول التقنية التي تصل إلى ملايين العملاء. شغل عبد النور منصب الرئيس التنفيذي للتكنولوجيا (CTO) في Talent.com عندما قام فريق AWS بتصميم وتنفيذ هذا الحل المحدد لـ Talent.com.
 يانجون تشي هو مدير أول للعلوم التطبيقية في مختبر حلول التعلم الآلي في أمازون. إنها تبتكر وتطبق التعلم الآلي لمساعدة عملاء AWS على تسريع تبني الذكاء الاصطناعي والسحابة.
يانجون تشي هو مدير أول للعلوم التطبيقية في مختبر حلول التعلم الآلي في أمازون. إنها تبتكر وتطبق التعلم الآلي لمساعدة عملاء AWS على تسريع تبني الذكاء الاصطناعي والسحابة.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/streamlining-etl-data-processing-at-talent-com-with-amazon-sagemaker/

