يعتمد إنشاء حلول تعلم آلي عالية الأداء (ML) على استكشاف معلمات التدريب وتحسينها، والمعروفة أيضًا باسم المعلمات الفائقة. المعلمات الفائقة هي المقابض والرافعات التي نستخدمها لضبط عملية التدريب، مثل معدل التعلم، وحجم الدفعة، وقوة التنظيم، وغيرها، اعتمادًا على النموذج المحدد والمهمة التي بين أيدينا. يتضمن استكشاف المعلمات الفائقة تغييرًا منهجيًا لقيم كل معلمة ومراقبة التأثير على أداء النموذج. وعلى الرغم من أن هذه العملية تتطلب جهودًا إضافية، إلا أن فوائدها كبيرة. يمكن أن يؤدي تحسين المعلمة الفائقة (HPO) إلى أوقات تدريب أسرع وتحسين دقة النموذج وتعميم أفضل للبيانات الجديدة.
نواصل رحلتنا من البريد قم بتحسين المعلمات الفائقة باستخدام الضبط التلقائي للنموذج Amazon SageMaker. لقد استكشفنا سابقًا تحسين وظيفة واحدة، وتصورنا نتائج خوارزمية SageMaker المدمجة، وتعرفنا على تأثير قيم معلمات تشعبية معينة. علاوة على استخدام HPO كتحسين لمرة واحدة في نهاية دورة إنشاء النموذج، يمكننا أيضًا استخدامه عبر خطوات متعددة بطريقة محادثة. تساعدنا كل مهمة ضبط على الاقتراب من الأداء الجيد، ولكن بالإضافة إلى ذلك، نتعلم أيضًا مدى حساسية النموذج لبعض المعلمات الفائقة ويمكننا استخدام هذا الفهم لإبلاغ مهمة الضبط التالية. يمكننا مراجعة المعلمات الفائقة ونطاقات قيمتها بناءً على ما تعلمناه وبالتالي تحويل جهد التحسين هذا إلى محادثة. وبنفس الطريقة التي نقوم بها كممارسين لتعلم الآلة، بتجميع المعرفة عبر هذه العمليات، الضبط التلقائي للنموذج Amazon SageMaker (AMT) مع بدايات دافئة، يمكن الحفاظ على هذه المعرفة المكتسبة في وظائف الضبط السابقة لمهمة الضبط التالية أيضًا.
في هذا المنشور، نقوم بتشغيل العديد من وظائف HPO باستخدام خوارزمية تدريب مخصصة واستراتيجيات HPO مختلفة مثل التحسين Bayesian والبحث العشوائي. نحن أيضًا نضع البدايات الدافئة موضع التنفيذ ونقارن تجاربنا بصريًا لتحسين استكشاف الفضاء ذي المعلمات الفائقة.
المفاهيم المتقدمة لـ SageMaker AMT
في الأقسام التالية، سنلقي نظرة فاحصة على كل موضوع من المواضيع التالية ونوضح كيف يمكن أن يساعدك SageMaker AMT في تنفيذها في مشاريع تعلم الآلة الخاصة بك:
- استخدم كود التدريب المخصص وإطار عمل تعلم الآلة الشهير Scikit-learn في تدريب SageMaker
- حدد مقاييس التقييم المخصصة بناءً على سجلات التقييم والتحسين
- أداء HPO باستخدام استراتيجية مناسبة
- استخدم عمليات البدء الدافئة لتحويل بحث واحد عن معلمة تشعبية إلى مربع حوار مع نموذجنا
- استخدم تقنيات التصور المتقدمة باستخدام مكتبة الحلول الخاصة بنا لمقارنة استراتيجيتين HPO وضبط نتائج المهام
سواء كنت تستخدم الخوارزميات المضمنة المستخدمة في منشورنا الأول أو رمز التدريب الخاص بك، فإن SageMaker AMT يقدم تجربة مستخدم سلسة لتحسين نماذج تعلم الآلة. فهو يوفر وظيفة أساسية تسمح لك بالتركيز على مشكلة تعلم الآلة المطروحة مع تتبع التجارب والنتائج تلقائيًا. وفي الوقت نفسه، يقوم تلقائيًا بإدارة البنية التحتية الأساسية لك.
في هذا المنشور، نبتعد عن خوارزمية SageMaker المضمنة ونستخدم تعليمات برمجية مخصصة. نحن نستخدم غابة عشوائية من سك ليرن. لكننا نلتزم بنفس مهمة ML ومجموعة البيانات كما هو الحال في موقعنا أول مشاركة، وهو الكشف عن الأرقام المكتوبة بخط اليد. نحن نغطي محتوى دفتر Jupyter 2_advanced_tuning_with_custom_training_and_visualizing.ipynb وندعوك لاستدعاء الكود جنبًا إلى جنب لقراءة المزيد.
دعونا نتعمق أكثر ونكتشف كيف يمكننا استخدام تعليمات برمجية مخصصة للتدريب ونشرها وتشغيلها، أثناء استكشاف مساحة بحث المعلمات الفائقة لتحسين نتائجنا.
كيفية بناء نموذج ML وإجراء تحسين المعلمات الفائقة
كيف تبدو العملية النموذجية لبناء حل تعلم الآلة؟ على الرغم من وجود العديد من حالات الاستخدام المحتملة ومجموعة كبيرة ومتنوعة من مهام تعلم الآلة، إلا أننا نقترح النموذج الذهني التالي لنهج تدريجي:
- افهم سيناريو ML الموجود لديك وحدد خوارزمية بناءً على المتطلبات. على سبيل المثال، قد ترغب في حل مهمة التعرف على الصور باستخدام خوارزمية التعلم الخاضع للإشراف. في هذا المنشور، نواصل استخدام سيناريو التعرف على الصور المكتوبة بخط اليد ونفس مجموعة البيانات كما في منشورنا الأول.
- حدد تنفيذ الخوارزمية في تدريب SageMaker الذي تريد استخدامه. هناك العديد من الخيارات، داخل SageMaker أو خيارات خارجية. بالإضافة إلى ذلك، تحتاج إلى تحديد المقياس الأساسي الذي يناسب مهمتك بشكل أفضل وتريد تحسينه (مثل الدقة أو درجة F1 أو ROC). يدعم SageMaker أربعة خيارات حسب احتياجاتك ومواردك:
- استخدم نموذجًا مدربًا مسبقًا عبر أمازون سيج ميكر جومب ستارت، والتي يمكنك استخدامها خارج الصندوق أو مجرد ضبطها.
- استخدم إحدى الخوارزميات المدمجة للتدريب والضبط، مثل XGBoost، كما فعلنا في منشورنا السابق.
- قم بتدريب وضبط نموذج مخصص استنادًا إلى أحد أطر العمل الرئيسية مثل Scikit-learn أو TensorFlow أو PyTorch. توفر AWS مجموعة مختارة من صور Docker المعدة مسبقًا لهذا الغرض. في هذا المنشور، نستخدم هذا الخيار، والذي يسمح لك بالتجربة بسرعة عن طريق تشغيل التعليمات البرمجية الخاصة بك أعلى صورة الحاوية المعدة مسبقًا.
- قم بإحضار صورة Docker المخصصة الخاصة بك في حالة رغبتك في استخدام إطار عمل أو برنامج غير مدعوم. يتطلب هذا الخيار أقصى قدر من الجهد، ولكنه يوفر أيضًا أعلى درجة من المرونة والتحكم.
- تدريب النموذج باستخدام بياناتك. اعتمادًا على تنفيذ الخوارزمية من الخطوة السابقة، يمكن أن يكون ذلك بسيطًا مثل الرجوع إلى بيانات التدريب الخاصة بك وتشغيل مهمة التدريب أو عن طريق توفير تعليمات برمجية مخصصة للتدريب بالإضافة إلى ذلك. في حالتنا، نستخدم بعض أكواد التدريب المخصصة في لغة Python استنادًا إلى Scikit-learn.
- قم بتطبيق تحسين المعلمة الفائقة (كـ "محادثة" مع نموذج ML الخاص بك). بعد التدريب، تريد عادةً تحسين أداء النموذج الخاص بك عن طريق العثور على مجموعة القيم الواعدة للمعلمات الفائقة للخوارزمية الخاصة بك.
اعتمادًا على خوارزمية تعلم الآلة وحجم النموذج، قد تكون الخطوة الأخيرة لتحسين المعلمة الفائقة بمثابة تحدي أكبر من المتوقع. الأسئلة التالية نموذجية لممارسي تعلم الآلة في هذه المرحلة وقد تبدو مألوفة بالنسبة لك:
- ما نوع المعلمات الفائقة المؤثرة على مشكلة تعلم الآلة الخاصة بي؟
- كيف يمكنني البحث بشكل فعال في مساحة ضخمة من المعلمات الفائقة للعثور على تلك القيم الأفضل أداءً؟
- كيف يؤثر الجمع بين بعض قيم المعلمات الفائقة على مقياس الأداء الخاص بي؟
- التكاليف مهمة؛ كيف يمكنني استخدام مواردي بطريقة فعالة؟
- ما هي أنواع تجارب الضبط الجديرة بالاهتمام، وكيف يمكنني مقارنتها؟
ليس من السهل الإجابة على هذه الأسئلة، ولكن هناك أخبار جيدة. يأخذ SageMaker AMT العبء الثقيل عليك، ويتيح لك التركيز على اختيار استراتيجية HPO المناسبة ونطاقات القيمة التي تريد استكشافها. بالإضافة إلى ذلك، يعمل حل التصور الخاص بنا على تسهيل عملية التحليل والتجريب التكرارية للعثور بكفاءة على قيم المعلمات الفائقة ذات الأداء الجيد.
في الأقسام التالية، سنبني نموذجًا للتعرف على الأرقام من الصفر باستخدام Scikit-Learn ونعرض كل هذه المفاهيم أثناء العمل.
حل نظرة عامة
يقدم SageMaker بعض الميزات المفيدة جدًا لتدريب نموذجنا وتقييمه وضبطه. وهو يغطي جميع وظائف دورة حياة تعلم الآلة من البداية إلى النهاية، لذلك لا نحتاج حتى إلى ترك دفتر Jupyter الخاص بنا.
في مشاركتنا الأولى، استخدمنا خوارزمية SageMaker المضمنة XGBoost. لأغراض العرض التوضيحي، قمنا هذه المرة بالتبديل إلى مصنف Random Forest لأنه يمكننا بعد ذلك إظهار كيفية توفير كود التدريب الخاص بك. لقد اخترنا توفير برنامج Python النصي الخاص بنا واستخدام Scikit-learn كإطار عمل خاص بنا. الآن، كيف نعبر عن رغبتنا في استخدام إطار عمل محدد لتعلم الآلة؟ كما سنرى، يستخدم SageMaker خدمة AWS أخرى في الخلفية لاسترداد صورة حاوية Docker المبنية مسبقًا للتدريب —سجل الأمازون المرنة للحاويات (أمازون ECR).
نحن نغطي الخطوات التالية بالتفصيل، بما في ذلك مقتطفات التعليمات البرمجية والرسوم البيانية لتوصيل النقاط. كما ذكرنا من قبل، إذا كانت لديك الفرصة، فافتح دفتر الملاحظات وقم بتشغيل خلايا التعليمات البرمجية خطوة بخطوة لإنشاء العناصر في بيئة AWS الخاصة بك. لا توجد طريقة أفضل للتعلم النشط.
- أولا، تحميل وإعداد البيانات. نحن نستخدم خدمة تخزين أمازون البسيطة (Amazon S3) لتحميل ملف يحتوي على بياناتنا الرقمية المكتوبة بخط اليد.
- بعد ذلك، قم بإعداد البرنامج النصي للتدريب وتبعيات الإطار. نحن نقدم كود التدريب المخصص في لغة بايثون، ونشير إلى بعض المكتبات التابعة، ونجري اختبارًا.
- لتحديد مقاييس الهدف المخصصة، يتيح لنا SageMaker تحديد تعبير عادي لاستخراج المقاييس التي نحتاجها من ملفات سجل الحاوية.
- تدريب النموذج باستخدام إطار عمل scikit-Learn. من خلال الرجوع إلى صورة حاوية تم إنشاؤها مسبقًا، نقوم بإنشاء كائن تقديري مطابق وتمرير البرنامج النصي التدريبي المخصص الخاص بنا.
- تمكننا AMT من تجربة استراتيجيات HPO المختلفة. نحن نركز على اثنين منهم في هذا المنشور: البحث العشوائي والبحث البايزي.
- اختر من بين استراتيجيات SageMaker HPO.
- تصور وتحليل ومقارنة نتائج الضبط. تتيح لنا حزمة التصور الخاصة بنا اكتشاف الإستراتيجية التي تحقق أداءً أفضل وقيم المعلمات الفائقة التي توفر أفضل أداء استنادًا إلى مقاييسنا.
- استمر في استكشاف مساحة المعلمة الفائقة وابدأ وظائف HPO الدافئة.
تعتني AMT بتوسيع نطاق البنية التحتية للحوسبة الأساسية وإدارتها لتشغيل وظائف الضبط المختلفة الأمازون الحوسبة المرنة السحابية (أمازون EC2) مثيلات. بهذه الطريقة، لا تحتاج إلى تحميل نفسك عبء توفير المثيلات، أو التعامل مع أي مشكلات في نظام التشغيل والأجهزة، أو تجميع ملفات السجل بنفسك. يتم استرداد صورة إطار عمل ML من Amazon ECR ويتم تخزين عناصر النموذج بما في ذلك نتائج الضبط في Amazon S3. يتم جمع كافة السجلات والمقاييس في الأمازون CloudWatch لسهولة الوصول إليها وإجراء مزيد من التحليل إذا لزم الأمر.
المتطلبات الأساسية المسبقة
نظرًا لأن هذا استمرار لسلسلة، فمن المستحسن قراءته، ولكن ليس بالضرورة مطلوبًا منشورنا الأول حول SageMaker AMT وHPO. وبصرف النظر عن ذلك، فإن المعرفة الأساسية بمفاهيم ML وبرمجة Python مفيدة. نوصي أيضًا بالمتابعة مع كل خطوة في مفكرة مرافقة من مستودع GitHub الخاص بنا أثناء قراءة هذا المنشور. يمكن تشغيل دفتر الملاحظات بشكل مستقل عن الأول، ولكنه يحتاج إلى بعض التعليمات البرمجية من المجلدات الفرعية. تأكد من استنساخ المستودع الكامل في بيئتك كما هو موضح في ملف README.
تعمل تجربة الكود واستخدام خيارات التصور التفاعلي على تحسين تجربة التعلم الخاصة بك بشكل كبير. إذا من فضلك تفقدها.
تحميل وإعداد البيانات
كخطوة أولى، نتأكد من تنزيله بيانات الأرقام ما نحتاجه للتدريب متاح لـ SageMaker. يتيح لنا Amazon S3 القيام بذلك بطريقة آمنة وقابلة للتطوير. ارجع إلى دفتر الملاحظات للحصول على كود المصدر الكامل ولا تتردد في تكييفه مع بياناتك الخاصة.
• digits.csv يحتوي الملف على بيانات الميزات والتسميات. يتم تمثيل كل رقم بقيم البكسل في صورة مقاس 8×8، كما هو موضح في الصورة التالية للرقم 4.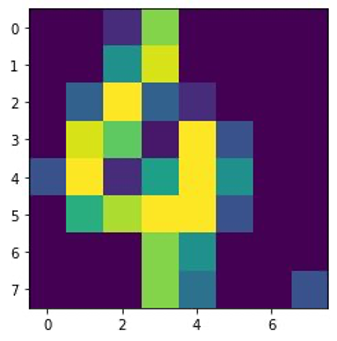
قم بإعداد البرنامج النصي للتدريب وتبعيات الإطار
الآن بعد أن تم تخزين البيانات في حاوية S3 الخاصة بنا، يمكننا تحديد البرنامج النصي التدريبي المخصص الخاص بنا بناءً على ذلك Scikit تعلم في بايثون. يمنحنا SageMaker خيار الرجوع إلى ملف Python لاحقًا للتدريب. يمكن توفير أي تبعيات مثل مكتبات Scikit-learn أو Pandas بطريقتين:
- يمكن تحديدها بشكل صريح في أ
requirements.txtملف - يتم تثبيتها مسبقًا في صورة حاوية ML الأساسية، والتي يتم توفيرها إما بواسطة SageMaker أو مصممة خصيصًا
يعتبر كلا الخيارين بشكل عام طرقًا قياسية لإدارة التبعية، لذا قد تكون على دراية بهما بالفعل. يدعم سيج ميكر مجموعة متنوعة من أطر ML في بيئة مُدارة جاهزة للاستخدام. يتضمن ذلك العديد من أطر علوم البيانات وتعلم الآلة الأكثر شيوعًا مثل PyTorch أو TensorFlow أو Scikit-learn، كما في حالتنا. نحن لا نستخدم إضافية requirements.txt الملف، ولكن لا تتردد في إضافة بعض المكتبات لتجربته.
يحتوي رمز التنفيذ الخاص بنا على طريقة تسمى fit()، الذي يقوم بإنشاء مصنف جديد لمهمة التعرف على الأرقام وتدريبه. على عكس منشورنا الأول الذي استخدمنا فيه خوارزمية XGBoost المضمنة في SageMaker، فإننا نستخدم الآن RandomForestClassifier مقدمة من مكتبة ML sklearn. نداء ال fit() تبدأ الطريقة على كائن المصنف عملية التدريب باستخدام مجموعة فرعية (80٪) من بيانات CSV الخاصة بنا:
شاهد النص الكامل في دفتر Jupyter الخاص بنا على GitHub جيثب:.
قبل أن تقوم بتدوير موارد الحاوية لعملية التدريب الكاملة، هل حاولت تشغيل البرنامج النصي مباشرة؟ تعد هذه ممارسة جيدة للتأكد بسرعة من عدم احتواء التعليمات البرمجية على أخطاء في بناء الجملة، والتحقق من مطابقة أبعاد هياكل البيانات الخاصة بك، وبعض الأخطاء الأخرى في وقت مبكر.
هناك طريقتان لتشغيل التعليمات البرمجية الخاصة بك محليًا. أولاً، يمكنك تشغيله على الفور في دفتر الملاحظات، مما يسمح لك أيضًا باستخدام Python Debugger pdb:
وبدلاً من ذلك، قم بتشغيل البرنامج النصي Train من سطر الأوامر بنفس الطريقة التي قد ترغب في استخدامها في الحاوية. ويدعم هذا أيضًا تعيين معلمات مختلفة والكتابة فوق القيم الافتراضية حسب الحاجة، على سبيل المثال:
كمخرج، يمكنك رؤية النتائج الأولى لأداء النموذج استنادًا إلى دقة المقاييس الموضوعية والاستدعاء ودرجة F1. على سبيل المثال، pre: 0.970 rec: 0.969 f1: 0.969.
ليس سيئا لمثل هذا التدريب السريع. ولكن من أين أتت هذه الأرقام وماذا نفعل بها؟
تحديد مقاييس الهدف المخصصة
تذكر أن هدفنا هو تدريب نموذجنا وضبطه بشكل كامل بناءً على المقاييس الموضوعية التي نعتبرها ذات صلة بمهمتنا. نظرًا لأننا نستخدم برنامجًا نصيًا تدريبيًا مخصصًا، فإننا نحتاج إلى تحديد تلك المقاييس لـ SageMaker بشكل صريح.
يُصدر البرنامج النصي الخاص بنا دقة المقاييس والاستدعاء ودرجة F1 أثناء التدريب ببساطة عن طريق استخدام print وظيفة:
يتم التقاط الإخراج القياسي بواسطة SageMaker وإرساله إلى CloudWatch كتدفق سجل. لاسترداد قيم القياس والعمل معها لاحقًا في SageMaker AMT، نحتاج إلى تقديم بعض المعلومات حول كيفية تحليل هذا الناتج. يمكننا تحقيق ذلك من خلال تعريف عبارات التعبير العادي (لمزيد من المعلومات، راجع مراقبة وتحليل وظائف التدريب باستخدام Amazon CloudWatch Metrics):
دعنا نتعرف معًا على التعريف المتري الأول في الكود السابق. سيبحث SageMaker عن المخرجات في السجل الذي يبدأ بـ pre: ويتبعه مسافة بيضاء واحدة أو أكثر ثم الرقم الذي نريد استخراجه، ولهذا السبب نستخدم القوس الدائري. في كل مرة يجد فيها SageMaker قيمة كهذه، فإنه يحولها إلى مقياس CloudWatch بالاسم valid-precision.
تدريب النموذج باستخدام إطار عمل Scikit-Learn
بعد أن نقوم بإنشاء البرنامج النصي التدريبي الخاص بنا train.py وإرشاد SageMaker حول كيفية مراقبة المقاييس داخل CloudWatch، نحدد أ مقدر SageMaker هدف. يبدأ مهمة التدريب ويستخدم نوع المثيل الذي نحدده. ولكن كيف يمكن أن يختلف نوع المثيل هذا عن النوع الذي تقوم بتشغيله أمازون ساجميكر ستوديو دفتر على، ولماذا؟ يقوم SageMaker Studio بتشغيل مهام التدريب (والاستدلال) الخاصة بك على مثيلات حوسبة منفصلة عن الكمبيوتر الدفتري الخاص بك. يسمح لك هذا بمواصلة العمل في دفتر الملاحظات الخاص بك أثناء تشغيل المهام في الخلفية.
المعلمة framework_version يشير إلى إصدار Scikit-learn الذي نستخدمه في مهمتنا التدريبية. بدلا من ذلك، يمكننا أن نمرر image_uri إلى estimator. يمكنك التحقق مما إذا كان إطار العمل المفضل لديك أو مكتبة ML متاحة كملف صورة SageMaker Docker المبنية مسبقًا واستخدامها كما هي أو مع ملحقات.
علاوة على ذلك، يمكننا تشغيل وظائف تدريب SageMaker على مثيلات EC2 Spot من خلال الإعداد use_spot_instances إلى True. إنها حالات ذات قدرة احتياطية يمكنها ذلك توفير ما يصل إلى 90% من التكاليف. توفر هذه المثيلات المرونة عند تشغيل وظائف التدريب.
بعد إعداد كائن المُقدِّر، نبدأ التدريب عن طريق استدعاء fit() وظيفة، وتوفير المسار إلى مجموعة بيانات التدريب على Amazon S3. يمكننا استخدام نفس الطريقة لتوفير بيانات التحقق والاختبار. قمنا بتعيين wait المعلمة ل True حتى نتمكن من استخدام النموذج المدرب في خلايا التعليمات البرمجية اللاحقة.
estimator.fit({'train': s3_data_url}, wait=True)تحديد المعلمات الفائقة وتشغيل وظائف الضبط
لقد قمنا حتى الآن بتدريب النموذج باستخدام مجموعة واحدة من قيم المعلمات الفائقة. لكن هل كانت تلك القيم جيدة؟ أم يمكننا البحث عن الأفضل؟ دعونا نستخدم فئة HyperparameterTuner لإجراء بحث منهجي على مساحة المعلمة الفائقة. كيف نبحث في هذه المساحة بالموالف؟ المعلمات الضرورية هي اسم المقياس الموضوعي ونوع الهدف الذي سيوجه عملية التحسين. تعد استراتيجية التحسين وسيطة رئيسية أخرى للموالف لأنها تحدد مساحة البحث بشكل أكبر. فيما يلي أربع استراتيجيات مختلفة للاختيار من بينها:
- بحث الشبكة
- بحث عشوائي
- تحسين بايزي (افتراضي)
- هايبرباند
نحن نصف هذه الاستراتيجيات أيضًا ونزودك ببعض الإرشادات لاختيار واحدة لاحقًا في هذا المنشور.
قبل أن نحدد ونشغل كائن الموالف الخاص بنا، دعونا نلخص فهمنا من منظور الهندسة المعمارية. لقد قمنا بتغطية النظرة العامة المعمارية لـ SageMaker AMT في آخر مشاركة لدينا وإعادة إنتاج مقتطف منه هنا للراحة.
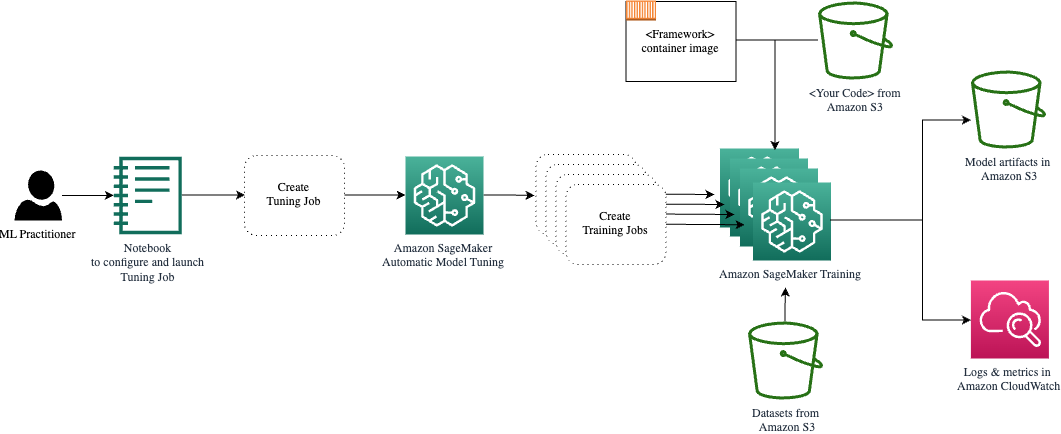
يمكننا اختيار المعلمات الفائقة التي نريد ضبطها أو تركها ثابتة. بالنسبة للمعلمات الفائقة الديناميكية، نحن نقدم hyperparameter_ranges التي يمكن استخدامها لتحسين المعلمات الفائقة القابلة للضبط. نظرًا لأننا نستخدم مصنف Random Forest، فقد استخدمنا المعلمات الفائقة من ملف Scikit-Learn وثائق الغابة العشوائية.
نقوم أيضًا بتحديد الموارد بأقصى عدد ممكن من وظائف التدريب ووظائف التدريب الموازية التي يمكن للموالف استخدامها. سنرى كيف تساعدنا هذه الحدود في مقارنة نتائج الاستراتيجيات المختلفة مع بعضها البعض.
على غرار المقدر fit وظيفة، نبدأ مهمة ضبط استدعاء الموالف fit:
هذا هو كل ما يتعين علينا القيام به للسماح لـ SageMaker بإدارة وظائف التدريب (n=50) في الخلفية، كل منها يستخدم مجموعة مختلفة من المعلمات الفائقة. سنستكشف النتائج لاحقًا في هذا المنشور. ولكن قبل ذلك، دعونا نبدأ مهمة ضبط أخرى، هذه المرة بتطبيق استراتيجية التحسين الافتراضية. سنقوم بمقارنة كلا الاستراتيجيتين بصريا بعد الانتهاء منهما.
لاحظ أنه يمكن تشغيل كلتا مهمتي الموالف بالتوازي لأن SageMaker يقوم بتنسيق مثيلات الحوسبة المطلوبة بشكل مستقل عن بعضها البعض. وهذا مفيد جدًا للممارسين الذين يقومون بتجربة طرق مختلفة في نفس الوقت، كما نفعل هنا.
اختر من بين استراتيجيات SageMaker HPO
عندما يتعلق الأمر باستراتيجيات الضبط، لديك عدد قليل من الخيارات مع SageMaker AMT: بحث الشبكة، والبحث العشوائي، والتحسين Bayesian، والنطاق الفائق. تحدد هذه الاستراتيجيات كيفية استكشاف خوارزميات الضبط التلقائي للنطاقات المحددة من المعلمات الفائقة.
البحث العشوائي واضح جدًا. فهو يختار بشكل عشوائي مجموعات من القيم من النطاقات المحددة ويمكن تشغيله بطريقة تسلسلية أو متوازية. إنه مثل رمي السهام معصوب العينين، على أمل إصابة الهدف. لقد بدأنا بهذه الاستراتيجية، ولكن هل ستتحسن النتائج باستراتيجية أخرى؟
يتخذ تحسين بايزي أسلوبًا مختلفًا عن البحث العشوائي. فهو يأخذ في الاعتبار تاريخ التحديدات السابقة ويختار القيم التي من المحتمل أن تسفر عن أفضل النتائج. إذا كنت تريد التعلم من الاستكشافات السابقة، فلا يمكنك تحقيق ذلك إلا من خلال تشغيل مهمة ضبط جديدة بعد المهام السابقة. فمن المنطقي، أليس كذلك؟ بهذه الطريقة، يعتمد تحسين بايزي على عمليات التشغيل السابقة. ولكن هل ترى ما هي استراتيجية HPO التي تسمح بتوازي أعلى؟
هايبرباند هو واحد مثير للاهتمام! ويستخدم استراتيجية متعددة الإخلاص، مما يعني أنه يخصص الموارد ديناميكيًا لوظائف التدريب الواعدة ويوقف تلك التي تكون ذات أداء ضعيف. لذلك، يتميز Hyperband بالكفاءة الحسابية باستخدام الموارد، والتعلم من وظائف التدريب السابقة. بعد إيقاف التكوينات ذات الأداء الضعيف، يبدأ تكوين جديد، ويتم اختيار قيمه بشكل عشوائي.
اعتمادًا على احتياجاتك وطبيعة النموذج الخاص بك، يمكنك الاختيار بين البحث العشوائي أو تحسين Bayesian أو Hyperband كإستراتيجية الضبط الخاصة بك. ولكل منها منهجها ومزاياها الخاصة، لذلك من المهم التفكير في أي منها يعمل بشكل أفضل لاستكشاف تعلم الآلة. الخبر السار لممارسي ML هو أنه يمكنك اختيار أفضل استراتيجية HPO من خلال المقارنة المرئية لتأثير كل تجربة على المقياس الموضوعي. في القسم التالي، نرى كيفية التعرف بصريًا على تأثير الاستراتيجيات المختلفة.
تصور وتحليل ومقارنة نتائج الضبط
عندما تكتمل مهام الضبط لدينا، يصبح الأمر مثيرًا. ما هي النتائج التي يحققونها؟ ما نوع التعزيز الذي يمكن أن تتوقعه في مقياسنا مقارنة بنموذجك الأساسي؟ ما هي المعلمات الفائقة الأفضل أداءً لحالة الاستخدام لدينا؟
هناك طريقة سريعة ومباشرة لعرض نتائج HPO وهي زيارة وحدة تحكم SageMaker. تحت وظائف ضبط Hyperparameter، يمكننا أن نرى (لكل مهمة ضبط) مجموعة قيم المعلمات الفائقة التي تم اختبارها وتقديم أفضل أداء كما تم قياسه بواسطة مقياسنا الموضوعي (valid-f1).
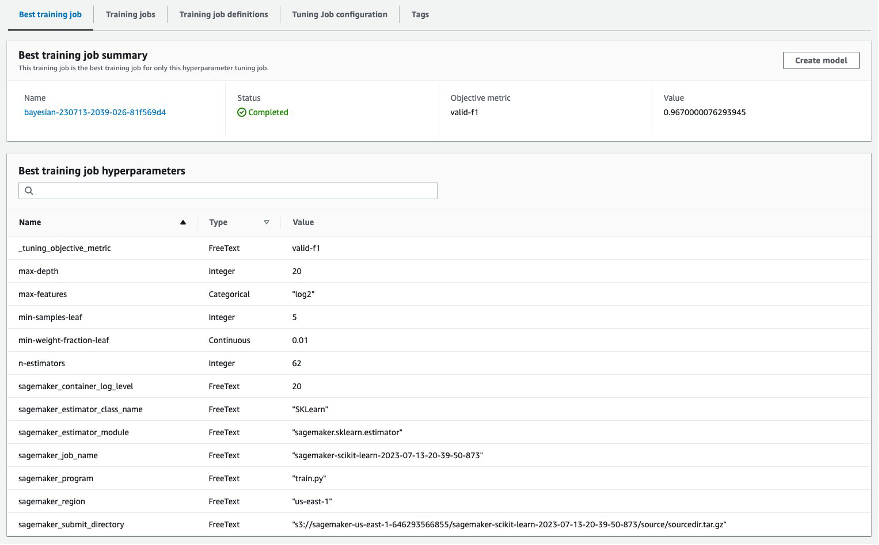
هل هذا كل ما تحتاجه؟ باعتبارك ممارسًا لتعلم الآلة، قد لا تكون مهتمًا بهذه القيم فحسب، بل تريد بالتأكيد معرفة المزيد حول الأعمال الداخلية لنموذجك لاستكشاف إمكاناته الكاملة وتعزيز حدسك من خلال التعليقات التجريبية.
يمكن أن تساعدك أداة التصور الجيدة بشكل كبير على فهم التحسين الذي تم إجراؤه بواسطة HPO بمرور الوقت والحصول على تعليقات تجريبية حول قرارات التصميم الخاصة بنموذج ML الخاص بك. فهو يوضح تأثير كل معلمة تشعبية فردية على مقياس الهدف الخاص بك ويوفر إرشادات لتحسين نتائج الضبط بشكل أكبر.
نستخدم amtviz حزمة تصور مخصصة لتصور وتحليل وظائف الضبط. إنه سهل الاستخدام ويوفر ميزات مفيدة. نوضح فائدته من خلال تفسير بعض المخططات الفردية، وأخيرًا مقارنة البحث العشوائي جنبًا إلى جنب مع التحسين الافتراضي.
أولاً، لنقم بإنشاء تصور للبحث العشوائي. يمكننا القيام بذلك عن طريق الاتصال visualize_tuning_job() تبدأ من amtviz وتمرير كائن الموالف الأول كوسيطة:
سترى بعض الرسوم البيانية، ولكن دعونا نأخذ الأمر خطوة بخطوة. يبدو المخطط المبعثر الأول من المخرجات كما يلي ويعطينا بالفعل بعض الأدلة المرئية التي لن نتعرف عليها في أي جدول.

تمثل كل نقطة أداء مهمة تدريبية فردية (هدفنا valid-f1 على المحور الصادي) استنادًا إلى وقت البداية (المحور السيني)، الناتج عن مجموعة محددة من المعلمات الفائقة. لذلك، فإننا ننظر إلى أداء نموذجنا أثناء تقدمه خلال مدة مهمة الضبط.
يسلط الخط المنقط الضوء على أفضل نتيجة تم العثور عليها حتى الآن ويشير إلى التحسن بمرور الوقت. حققت أفضل وظيفتين تدريبيتين درجة F1 تبلغ حوالي 0.91.
إلى جانب الخط المنقط الذي يوضح التقدم التراكمي، هل ترى اتجاهًا في الرسم البياني؟
على الاغلب لا. وهذا أمر متوقع، لأننا نشاهد نتائج استراتيجية HPO العشوائية. تم تشغيل كل مهمة تدريبية باستخدام مجموعة مختلفة ولكن تم اختيارها عشوائيًا من المعلمات الفائقة. إذا واصلنا مهمة الضبط (أو قمنا بتشغيل مهمة أخرى بنفس الإعداد)، فمن المحتمل أن نرى بعض النتائج الأفضل بمرور الوقت، ولكن لا يمكننا التأكد. العشوائية شيء صعب.
تساعدك المخططات التالية على قياس تأثير المعلمات الفائقة على الأداء العام. يتم تصور جميع المعلمات الفائقة، ولكن من أجل الإيجاز، نركز على اثنين منها: n-estimators و max-depth.

تم استخدام أفضل وظيفتين تدريبيتين لدينا n-estimators حوالي 20 و 80 و max-depth حوالي 10 و18 على التوالي. يتم عرض قيم المعلمات الفائقة الدقيقة عبر تلميح الأدوات لكل نقطة (مهمة تدريب). ويتم إبرازها ديناميكيًا عبر جميع المخططات وتمنحك رؤية متعددة الأبعاد! هل رأيت ذلك؟ يتم رسم كل معلمة تشعبية مقابل المقياس الموضوعي، كمخطط منفصل.
الآن، ما نوع الأفكار التي نحصل عليها؟ n-estimators?
استنادًا إلى الرسم البياني الأيسر، يبدو أن نطاقات القيمة المنخفضة جدًا (أقل من 10) تؤدي في كثير من الأحيان إلى نتائج سيئة مقارنة بالقيم الأعلى. لذلك، قد تساعد القيم الأعلى نموذجك على الأداء بشكل أفضل، وهو أمر مثير للاهتمام.
وفي المقابل فإن الارتباط بين max-depth المعلمة الفائقة لمقياسنا الموضوعي منخفضة إلى حد ما. لا يمكننا أن نحدد بوضوح نطاقات القيمة التي تحقق أداءً أفضل من منظور عام.
باختصار، يمكن أن يساعدك البحث العشوائي في العثور على مجموعة جيدة الأداء من المعلمات الفائقة حتى في فترة زمنية قصيرة نسبيًا. كما أنها ليست منحازة نحو الحل الجيد ولكنها تعطي رؤية متوازنة لمساحة البحث. ومع ذلك، قد لا يكون استخدامك للموارد فعالاً للغاية. ويستمر في تشغيل وظائف تدريبية ذات معلمات مفرطة في نطاقات القيمة المعروفة بأنها تحقق نتائج سيئة.
دعونا نفحص نتائج مهمة الضبط الثانية باستخدام تحسين بايزي. يمكننا ان نستخدم amtviz لتصور النتائج بنفس الطريقة التي فعلناها حتى الآن لموالف البحث العشوائي. أو الأفضل من ذلك، يمكننا استخدام قدرة الوظيفة لمقارنة مهمتي الضبط في مجموعة واحدة من المخططات. مفيد جدا!
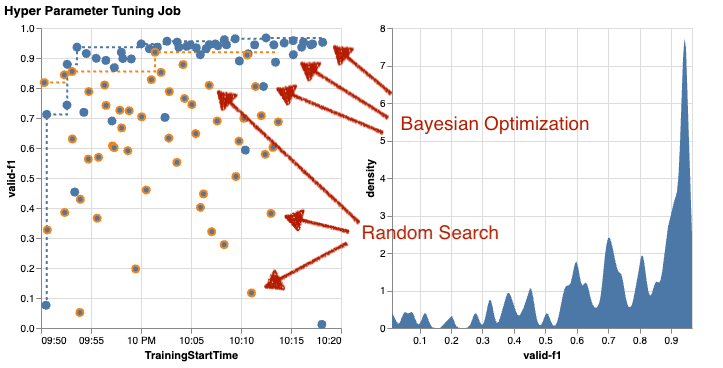
هناك المزيد من النقاط الآن لأننا نتصور نتائج جميع المهام التدريبية لكل من البحث العشوائي (النقاط البرتقالية) والتحسين بايزي (النقاط الزرقاء). على الجانب الأيمن، يمكنك رؤية مخطط الكثافة الذي يصور توزيع جميع درجات F1. حققت غالبية الوظائف التدريبية نتائج في الجزء العلوي من مقياس F1 (أكثر من 0.6) - وهذا جيد!
ما هي الوجبات الرئيسية هنا؟ تُظهر المؤامرة المبعثرة بوضوح فائدة التحسين بايزي. إنه يحقق نتائج أفضل بمرور الوقت لأنه يمكنه التعلم من عمليات التشغيل السابقة. ولهذا السبب حققنا نتائج أفضل بكثير باستخدام بايزي مقارنة بالعشوائية (0.967 مقابل 0.919) مع نفس العدد من المهام التدريبية.
هناك المزيد الذي يمكنك فعله به amtviz. دعونا الحفر في.
إذا أعطيت SageMaker AMT التعليمات لتشغيل عدد أكبر من المهام للضبط، فقد تصبح رؤية العديد من التجارب في وقت واحد أمرًا فوضويًا. وهذا أحد الأسباب وراء جعلنا هذه المخططات تفاعلية. يمكنك النقر والسحب على كل مخطط مبعثر للمعلمات التشعبية لتكبير نطاقات قيمة معينة وتحسين تفسيرك المرئي للنتائج. يتم تحديث جميع المخططات الأخرى تلقائيًا. هذا مفيد جدًا، أليس كذلك؟ انظر إلى المخططات التالية كمثال وجربها بنفسك في دفترك!
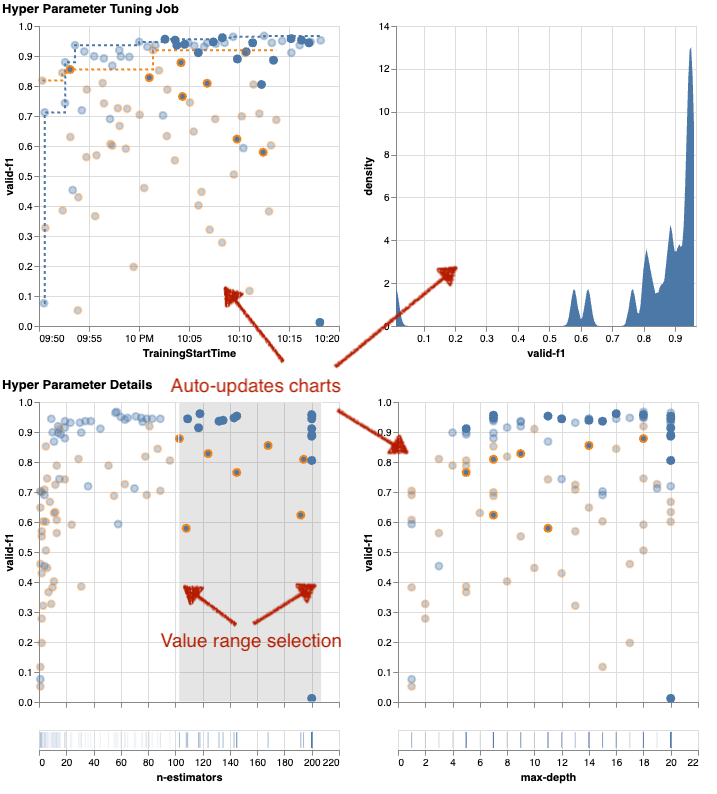
باعتبارك متخصصًا في الضبط، قد تقرر أيضًا أن تشغيل وظيفة ضبط معلمة تشعبية أخرى قد يؤدي إلى تحسين أداء النموذج الخاص بك. ولكن هذه المرة، يمكن استكشاف نطاق أكثر تحديدًا من قيم المعلمات الفائقة لأنك تعرف بالفعل (تقريبًا) أين تتوقع نتائج أفضل. على سبيل المثال، يمكنك اختيار التركيز على القيم بين 100-200 لـ n-estimators، كما هو موضح في الرسم البياني. يتيح ذلك لشركة AMT التركيز على وظائف التدريب الواعدة وزيادة كفاءة الضبط لديك.
ليتم تلخيصه، amtviz يوفر لك مجموعة غنية من إمكانات التصور التي تتيح لك فهم تأثير المعلمات الفائقة للنموذج الخاص بك بشكل أفضل على الأداء وتمكين اتخاذ قرارات أكثر ذكاءً في أنشطة الضبط الخاصة بك.
استمر في استكشاف مساحة المعلمة الفائقة وابدأ وظائف HPO الدافئة
لقد رأينا أن AMT يساعدنا في استكشاف مساحة البحث ذات المعلمات الفائقة بكفاءة. ولكن ماذا لو كنا بحاجة إلى جولات متعددة من الضبط لتحسين نتائجنا بشكل متكرر؟ كما ذكرنا في البداية، نريد إنشاء دورة تعليقات للتحسين - "محادثتنا" مع النموذج. هل يجب علينا أن نبدأ من الصفر في كل مرة؟
دعونا نلقي نظرة على مفهوم تشغيل بداية دافئة لوظيفة ضبط المعلمة الفائقة. فهو لا يبدأ مهام ضبط جديدة من الصفر، بل يعيد استخدام ما تم تعلمه في عمليات تشغيل HPO السابقة. وهذا يساعدنا على أن نكون أكثر كفاءة في ضبط الوقت وحساب الموارد. يمكننا التكرار بشكل أكبر على نتائجنا السابقة. لاستخدام البدايات الدافئة، نقوم بإنشاء WarmStartConfig وتحديد warm_start_type as IDENTICAL_DATA_AND_ALGORITHM. هذا يعني أننا نغير قيم المعلمات الفائقة ولكننا لا نغير البيانات أو الخوارزمية. نطلب من AMT نقل المعرفة السابقة إلى وظيفة الضبط الجديدة لدينا.
من خلال الإشارة إلى وظائفنا السابقة لتحسين بايزي وضبط البحث العشوائي كـ parentsيمكننا استخدامهما معًا للبداية الدافئة:
لمعرفة فائدة استخدام البدء الدافئ، راجع المخططات التالية. يتم إنشاء هذه بواسطة amtviz بطريقة مماثلة كما فعلنا سابقًا، ولكن هذه المرة أضفنا وظيفة ضبط أخرى بناءً على البداية الدافئة.
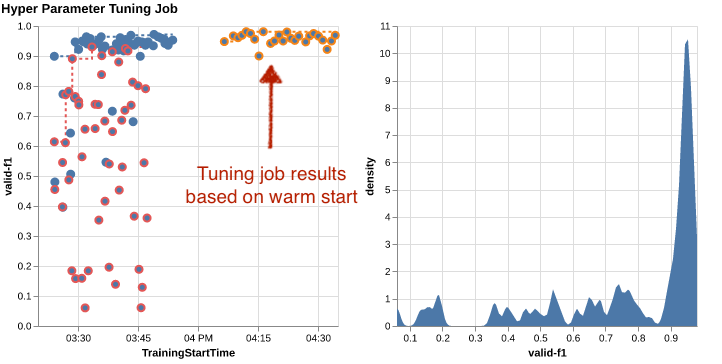
في الرسم البياني الأيسر، يمكننا أن نلاحظ أن وظائف الضبط الجديدة تقع في الغالب في الزاوية العلوية اليمنى من الرسم البياني لمقياس الأداء (انظر النقاط المميزة باللون البرتقالي). لقد أعادت البداية الدافئة بالفعل استخدام النتائج السابقة، ولهذا السبب كانت نقاط البيانات هذه في أعلى النتائج لنتيجة الفورمولا 1. وينعكس هذا التحسن أيضًا في مخطط الكثافة الموجود على اليمين.
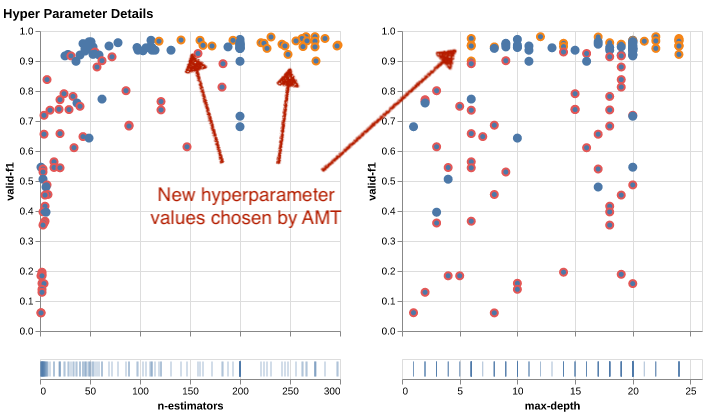
بمعنى آخر، تختار AMT تلقائيًا مجموعات واعدة من قيم المعلمات الفائقة بناءً على معرفتها من التجارب السابقة. يظهر هذا في الرسم البياني التالي. على سبيل المثال، ستختبر الخوارزمية قيمة منخفضة لـ n-estimators في كثير من الأحيان لأنه من المعروف أنها تنتج درجات ضعيفة في F1. نحن لا نضيع أي موارد على ذلك، وذلك بفضل البدايات الدافئة.
تنظيف
لتجنب تكبد تكاليف غير مرغوب فيها عند الانتهاء من تجربة HPO ، يجب عليك إزالة جميع الملفات الموجودة في حاوية S3 بالبادئة amt-visualize-demo و أيضا قم بإيقاف تشغيل موارد SageMaker Studio.
قم بتشغيل التعليمة البرمجية التالية في دفتر ملاحظاتك لإزالة جميع ملفات S3 من هذا المنشور:
إذا كنت ترغب في الاحتفاظ بمجموعات البيانات أو عناصر النموذج ، فيمكنك تعديل البادئة في الكود إلى amt-visualize-demo/data لحذف البيانات فقط أو amt-visualize-demo/output لحذف عيوب النموذج فقط.
وفي الختام
لقد تعلمنا كيف يتضمن فن بناء حلول تعلم الآلة استكشاف المعلمات الفائقة وتحسينها. يعد ضبط هذه المقابض والأذرع عملية متطلبة ولكنها مجزية تؤدي إلى أوقات تدريب أسرع وتحسين دقة النموذج وحلول تعلم الآلة بشكل عام أفضل. تساعدنا وظيفة SageMaker AMT على تشغيل مهام ضبط متعددة وبدء تشغيلها بشكل جيد، وتوفر نقاط بيانات لمزيد من المراجعة والمقارنة المرئية والتحليل.
في هذا المنشور، نظرنا في استراتيجيات HPO التي نستخدمها مع SageMaker AMT. لقد بدأنا بالبحث العشوائي، وهو عبارة عن إستراتيجية واضحة وفعالة حيث يتم أخذ عينات من المعلمات الفائقة بشكل عشوائي من مساحة البحث. بعد ذلك، قمنا بمقارنة النتائج بالتحسين الافتراضي، الذي يستخدم النماذج الاحتمالية لتوجيه البحث عن المعلمات الفائقة المثالية. بعد أن حددنا استراتيجية HPO مناسبة ونطاقات قيمة جيدة للمعلمات الفائقة من خلال التجارب الأولية، أظهرنا كيفية استخدام البدايات الدافئة لتبسيط وظائف HPO المستقبلية.
يمكنك استكشاف مساحة بحث المعلمات الفائقة من خلال مقارنة النتائج الكمية. لقد اقترحنا المقارنة المرئية جنبًا إلى جنب وقدمنا الحزمة اللازمة للاستكشاف التفاعلي. أخبرنا في التعليقات بمدى فائدة ذلك بالنسبة لك في رحلة ضبط المعلمة الفائقة!
عن المؤلفين
 أوميت يولداس هو مهندس حلول أول في Amazon Web Services. يعمل مع عملاء المؤسسات عبر الصناعات في ألمانيا. إنه مدفوع لترجمة مفاهيم الذكاء الاصطناعي إلى حلول واقعية. خارج العمل، يستمتع بوقته مع العائلة، ويتذوق الطعام الجيد، ويمارس اللياقة البدنية.
أوميت يولداس هو مهندس حلول أول في Amazon Web Services. يعمل مع عملاء المؤسسات عبر الصناعات في ألمانيا. إنه مدفوع لترجمة مفاهيم الذكاء الاصطناعي إلى حلول واقعية. خارج العمل، يستمتع بوقته مع العائلة، ويتذوق الطعام الجيد، ويمارس اللياقة البدنية.
 إلينا ليسيك هو مهندس الحلول الموجود في ميونيخ. إنها تركز على عملاء المؤسسات من صناعة الخدمات المالية. في أوقات فراغها، يمكنك أن تجد Elina وهي تبني تطبيقات باستخدام الذكاء الاصطناعي التوليدي في بعض اجتماعات تكنولوجيا المعلومات، أو تقود فكرة جديدة حول إصلاح تغير المناخ بسرعة، أو تركض في الغابة للتحضير لنصف ماراثون مع انحراف نموذجي عن الجدول الزمني المخطط له.
إلينا ليسيك هو مهندس الحلول الموجود في ميونيخ. إنها تركز على عملاء المؤسسات من صناعة الخدمات المالية. في أوقات فراغها، يمكنك أن تجد Elina وهي تبني تطبيقات باستخدام الذكاء الاصطناعي التوليدي في بعض اجتماعات تكنولوجيا المعلومات، أو تقود فكرة جديدة حول إصلاح تغير المناخ بسرعة، أو تركض في الغابة للتحضير لنصف ماراثون مع انحراف نموذجي عن الجدول الزمني المخطط له.
 ماريانو كامب هو مهندس الحلول الرئيسي في Amazon Web Services. يعمل مع البنوك وشركات التأمين في ألمانيا على التعلم الآلي. في أوقات فراغه، يستمتع ماريانو بالمشي لمسافات طويلة مع زوجته.
ماريانو كامب هو مهندس الحلول الرئيسي في Amazon Web Services. يعمل مع البنوك وشركات التأمين في ألمانيا على التعلم الآلي. في أوقات فراغه، يستمتع ماريانو بالمشي لمسافات طويلة مع زوجته.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/explore-advanced-techniques-for-hyperparameter-optimization-with-amazon-sagemaker-automatic-model-tuning/

