لغة الاستعلام الهيكلية (SQL) هي لغة معقدة تتطلب فهم قواعد البيانات والبيانات الوصفية. اليوم، الذكاء الاصطناعي التوليدي يمكن تمكين الأشخاص الذين ليس لديهم معرفة بـ SQL. تسمى مهمة الذكاء الاصطناعي التوليدية هذه تحويل النص إلى SQL، والتي تولد استعلامات SQL من معالجة اللغة الطبيعية (NLP) وتحول النص إلى SQL صحيح لغويًا. يهدف الحل الموجود في هذا المنشور إلى الارتقاء بعمليات تحليل المؤسسة إلى المستوى التالي عن طريق اختصار المسار إلى بياناتك باستخدام اللغة الطبيعية.
مع ظهور نماذج اللغات الكبيرة (LLMs)، شهد إنشاء SQL المستند إلى البرمجة اللغوية العصبية (NLP) تحولًا كبيرًا. من خلال إظهار الأداء الاستثنائي، أصبح طلاب LLM الآن قادرين على إنشاء استعلامات SQL دقيقة من أوصاف اللغة الطبيعية. ومع ذلك، لا تزال هناك تحديات. أولا، اللغة البشرية غامضة بطبيعتها وتعتمد على السياق، في حين أن لغة SQL دقيقة ورياضية ومنظمة. قد تؤدي هذه الفجوة إلى تحويل غير دقيق لاحتياجات المستخدم إلى SQL الذي تم إنشاؤه. ثانيًا، قد تحتاج إلى إنشاء ميزات تحويل النص إلى SQL لكل قاعدة بيانات لأن البيانات غالبًا لا يتم تخزينها في هدف واحد. قد يتعين عليك إعادة إنشاء القدرة لكل قاعدة بيانات لتمكين المستخدمين من إنشاء SQL المستند إلى البرمجة اللغوية العصبية (NLP). ثالثًا، على الرغم من الاعتماد الأكبر على حلول التحليلات المركزية مثل مستودعات البيانات والمستودعات، فإن التعقيد يرتفع مع اختلاف أسماء الجداول وبيانات التعريف الأخرى المطلوبة لإنشاء SQL للمصادر المطلوبة. ولذلك، فإن جمع بيانات وصفية شاملة وعالية الجودة لا يزال يمثل تحديًا أيضًا. لمعرفة المزيد حول أفضل ممارسات تحويل النص إلى SQL وأنماط التصميم، راجع توليد القيمة من بيانات المؤسسة: أفضل الممارسات لـ Text2SQL والذكاء الاصطناعي التوليدي.
يهدف حلنا إلى معالجة تلك التحديات باستخدام أمازون بيدروك و خدمات تحليلات AWS. نحن نستخدم الأنثروبي كلود v2.1 على Amazon Bedrock بصفته LLM لدينا. ولمواجهة التحديات، يتضمن الحل الذي نقدمه أولاً البيانات الوصفية لمصادر البيانات داخل كتالوج بيانات AWS Glue لزيادة دقة استعلام SQL الذي تم إنشاؤه. يتضمن سير العمل أيضًا حلقة تقييم وتصحيح نهائية، في حالة تحديد أي مشكلات تتعلق بـ SQL أمازون أثينا، والذي يتم استخدامه كمحرك SQL. تسمح لنا أثينا أيضًا باستخدام عدد كبير من نقاط النهاية والموصلات المدعومة لتغطية مجموعة كبيرة من مصادر البيانات.
بعد أن نستعرض خطوات بناء الحل، نقدم نتائج بعض سيناريوهات الاختبار بمستويات مختلفة من تعقيد SQL. وأخيرًا، نناقش مدى سهولة دمج مصادر البيانات المختلفة في استعلامات SQL الخاصة بك.
حل نظرة عامة
هناك ثلاثة مكونات مهمة في بنيتنا: إنشاء الاسترجاع المعزز (RAG) مع بيانات تعريف قاعدة البيانات، وحلقة تصحيح ذاتي متعددة الخطوات، وAthena كمحرك SQL الخاص بنا.
نحن نستخدم طريقة RAG لاسترداد أوصاف الجدول وأوصاف المخطط (الأعمدة) من AWS Glue metastore للتأكد من أن الطلب مرتبط بالجدول ومجموعات البيانات الصحيحة. في الحل الذي نقدمه، قمنا ببناء الخطوات الفردية لتشغيل إطار عمل RAG باستخدام كتالوج بيانات AWS Glue لأغراض العرض التوضيحي. ومع ذلك، يمكنك أيضًا استخدام قواعد المعرفة في Amazon Bedrock لبناء حلول RAG بسرعة.
يسمح المكون متعدد الخطوات لـ LLM بتصحيح استعلام SQL الذي تم إنشاؤه للتأكد من دقته. هنا، يتم إرسال SQL الذي تم إنشاؤه لأخطاء بناء الجملة. نحن نستخدم رسائل خطأ Athena لإثراء مطالبتنا بـ LLM للحصول على تصحيحات أكثر دقة وفعالية في SQL الذي تم إنشاؤه.
يمكنك اعتبار رسائل الخطأ الواردة أحيانًا من أثينا مثل التعليقات. تعتبر الآثار المترتبة على تكلفة خطوة تصحيح الخطأ ضئيلة مقارنة بالقيمة المقدمة. يمكنك أيضًا تضمين هذه الخطوات التصحيحية كأمثلة للتعلم المعزز الخاضع للإشراف لضبط ماجستير إدارة الأعمال الخاص بك. ومع ذلك، فإننا لم نغطي هذا التدفق في منشورنا لأغراض التبسيط.
لاحظ أن هناك دائمًا خطر متأصل يتمثل في عدم الدقة، وهو ما يأتي بطبيعة الحال مع حلول الذكاء الاصطناعي التوليدية. حتى إذا كانت رسائل خطأ Athena فعالة للغاية في التخفيف من هذه المخاطر، فيمكنك إضافة المزيد من عناصر التحكم وطرق العرض، مثل التعليقات البشرية أو نماذج الاستعلامات للضبط الدقيق، لتقليل هذه المخاطر بشكل أكبر.
لا تسمح لنا Athena بتصحيح استعلامات SQL فحسب، بل إنها تبسط أيضًا المشكلة الإجمالية بالنسبة لنا لأنها تعمل كمركز، حيث يكون المتحدث عبارة عن مصادر بيانات متعددة. يتم التعامل مع إدارة الوصول وبناء جملة SQL والمزيد عبر Athena.
يوضح الرسم البياني التالي بنية الحل.
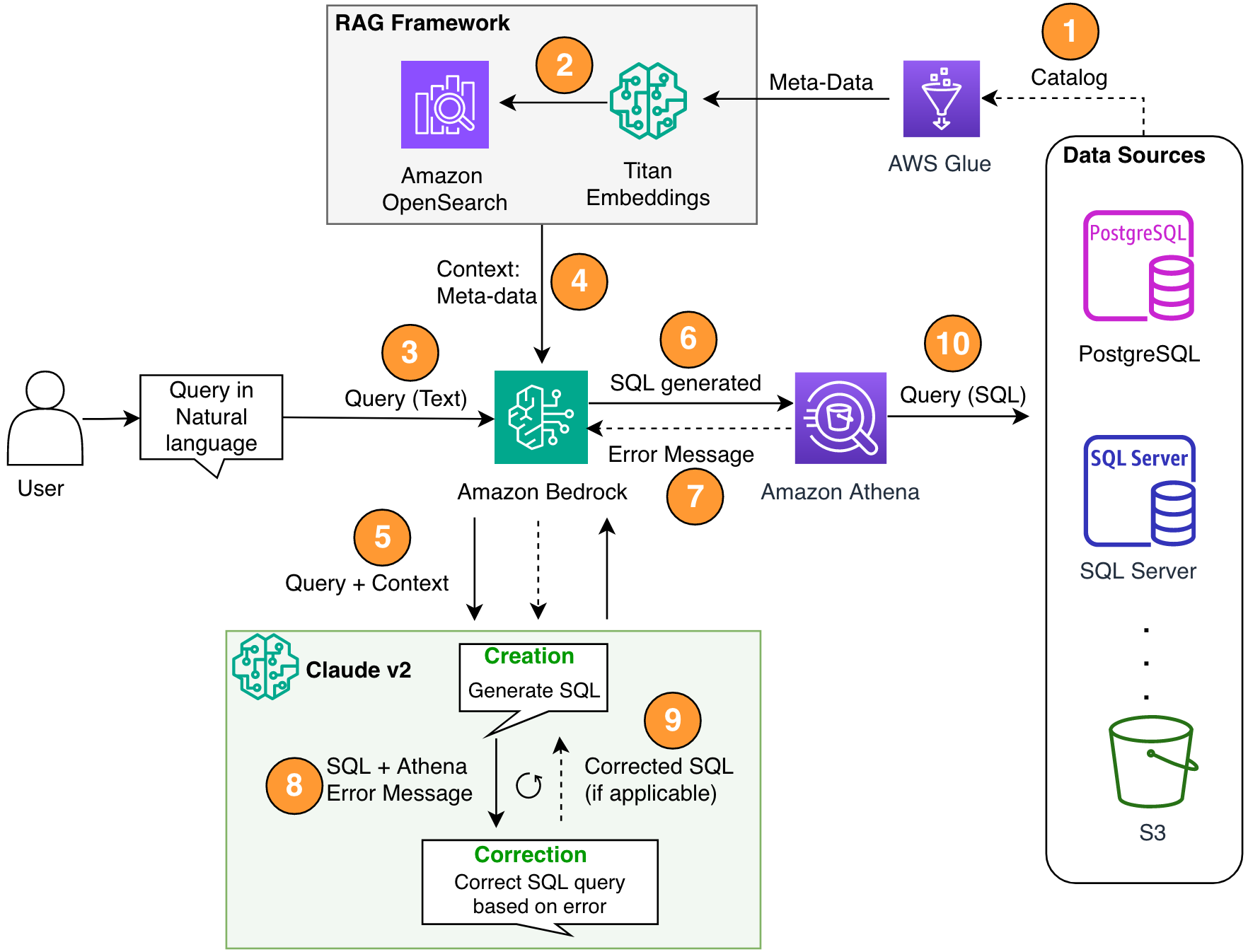
الشكل 1. بنية الحل وتدفق العملية.
يتضمن سير العملية الخطوات التالية:
- قم بإنشاء كتالوج بيانات AWS Glue باستخدام زاحف AWS Glue (أو طريقة مختلفة).
- باستخدام نموذج Titan-Text-Embeddings على Amazon Bedrock، قم بتحويل البيانات الوصفية إلى تضمينات وقم بتخزينها في ملف أمازون أوبن سيرش سيرفرليس متجر ناقلات، والتي تعد بمثابة قاعدة معرفتنا في إطار عمل RAG الخاص بنا.
في هذه المرحلة، تكون العملية جاهزة لتلقي الاستعلام باللغة الطبيعية. تمثل الخطوات من 7 إلى 9 حلقة تصحيح، إن أمكن.
- يقوم المستخدم بإدخال استعلامه باللغة الطبيعية. يمكنك استخدام أي تطبيق ويب لتوفير واجهة مستخدم الدردشة. لذلك، لم نقم بتغطية تفاصيل واجهة المستخدم في منشورنا.
- يطبق الحل إطار عمل RAG عبر بحث التشابه، الذي يضيف السياق الإضافي من البيانات التعريفية من قاعدة بيانات المتجهات. يُستخدم هذا الجدول للعثور على الجدول وقاعدة البيانات والسمات الصحيحة.
- يتم دمج الاستعلام مع السياق وإرساله إلى الأنثروبي كلود v2.1 على أمازون بيدروك.
- يحصل النموذج على استعلام SQL الذي تم إنشاؤه ويتصل بـ Athena للتحقق من صحة بناء الجملة.
- إذا قدمت Athena رسالة خطأ تشير إلى أن بناء الجملة غير صحيح، فسيستخدم النموذج نص الخطأ من استجابة Athena.
- يضيف الموجه الجديد استجابة أثينا.
- يقوم النموذج بإنشاء SQL المصحح ويستمر في العملية. يمكن تنفيذ هذا التكرار عدة مرات.
- وأخيرًا، نقوم بتشغيل SQL باستخدام Athena وإنشاء المخرجات. وهنا يتم عرض الإخراج للمستخدم. ومن أجل البساطة المعمارية لم نعرض هذه الخطوة.
المتطلبات الأساسية المسبقة
بالنسبة لهذا المنشور ، يجب عليك إكمال المتطلبات الأساسية التالية:
- أحصل على حساب AWS.
- تثبيت ال واجهة سطر الأوامر AWS (AWS CLI).
- إعداد SDK لبيثون (Boto3).
- قم بإنشاء كتالوج بيانات AWS Glue باستخدام زاحف AWS Glue (أو طريقة مختلفة).
- باستخدام نموذج Titan-Text-Embeddings على Amazon Bedrock، قم بتحويل البيانات التعريفية إلى تضمينات وقم بتخزينها في OpenSearch Serverless متجر ناقلات.
تنفيذ الحل
يمكنك استخدام ما يلي دفتر جوبيتر، والذي يتضمن كافة مقتطفات التعليمات البرمجية المتوفرة في هذا القسم، لبناء الحل. نوصي باستخدام أمازون ساجميكر ستوديو لفتح دفتر الملاحظات هذا بمثيل ml.t3.medium مع نواة Python 3 (علوم البيانات). للحصول على التعليمات، راجع تدريب نموذج التعلم الآلي. أكمل الخطوات التالية لإعداد الحل:
- قم بإنشاء قاعدة المعرفة في خدمة OpenSearch لإطار عمل RAG:
- بناء المطالبة (
final_question) من خلال الجمع بين مدخلات المستخدم باللغة الطبيعية (user_query)، البيانات الوصفية ذات الصلة من متجر المتجهات (vector_search_match)، وتعليماتنا (details): - قم باستدعاء Amazon Bedrock للحصول على LLM (Claude v2) واطلب منه إنشاء استعلام SQL. في التعليمة البرمجية التالية، يقوم بمحاولات متعددة لتوضيح خطوة التصحيح الذاتي:x
- إذا تم تلقي أية مشكلات في استعلام SQL الذي تم إنشاؤه (
{sqlgenerated}) من رد أثينا ({syntaxcheckmsg})، المطالبة الجديدة (prompt) بناءً على الاستجابة ويحاول النموذج مرة أخرى إنشاء SQL الجديد: - بعد إنشاء SQL، يتم استدعاء عميل Athena لتشغيل وإنشاء الإخراج:
اختبر المحلول
في هذا القسم، نقوم بتشغيل الحل الخاص بنا باستخدام سيناريوهات أمثلة مختلفة لاختبار مستويات التعقيد المختلفة لاستعلامات SQL.
لاختبار تحويل النص إلى SQL، نستخدم اثنين مجموعات البيانات المتاحة من موقع IMDB. مجموعات فرعية من بيانات IMDb متاحة للاستخدام الشخصي وغير التجاري. يمكنك تنزيل مجموعات البيانات وتخزينها فيها خدمة تخزين أمازون البسيطة (أمازون إس 3). يمكنك استخدام مقتطف Spark SQL التالي لإنشاء جداول في AWS Glue. في هذا المثال نستخدم title_ratings و title:
قم بتخزين البيانات في Amazon S3 والبيانات التعريفية في AWS Glue
في هذا السيناريو، يتم تخزين مجموعة البيانات الخاصة بنا في حاوية S3. تمتلك Athena موصل S3 الذي يسمح لك باستخدام Amazon S3 كمصدر بيانات يمكن الاستعلام عنه.
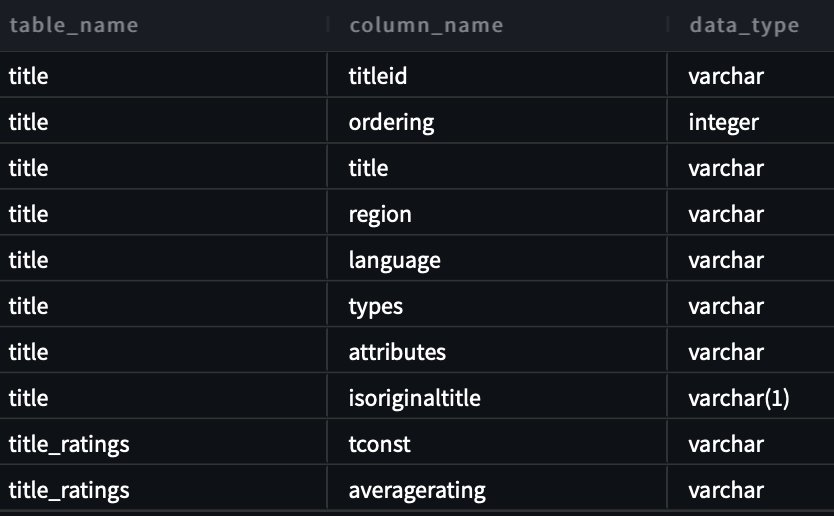
بالنسبة للاستعلام الأول، نقدم الإدخال "أنا جديد على هذا. هل يمكنك مساعدتي في رؤية جميع الجداول والأعمدة في مخطط imdb؟
فيما يلي الاستعلام الذي تم إنشاؤه:
تظهر لقطة الشاشة والكود التاليين مخرجاتنا.
بالنسبة للاستعلام الثاني، نسأل "أرني كل العناوين والتفاصيل في منطقة الولايات المتحدة التي يزيد تصنيفها عن 9.5".
ما يلي هو الاستعلام الذي تم إنشاؤه:
الرد على النحو التالي.

بالنسبة للاستعلام الثالث، ندخل "استجابة رائعة! أرني الآن جميع العناوين من النوع الأصلي التي لديها تقييمات تزيد عن 7.5 وليست في منطقة الولايات المتحدة.
تم إنشاء الاستعلام التالي:
نحصل على النتائج التالية.

إنشاء SQL ذاتي التصحيح
يحاكي هذا السيناريو استعلام SQL به مشكلات في بناء الجملة. هنا، سيتم تصحيح SQL الذي تم إنشاؤه ذاتيًا بناءً على استجابة Athena. في الرد التالي، أعطت أثينا أ COLUMN_NOT_FOUND خطأ وذكر ذلك table_description لا يمكن حلها:
استخدام الحل مع مصادر البيانات الأخرى
لاستخدام الحل مع مصادر بيانات أخرى، تتولى Athena المهمة نيابةً عنك. للقيام بذلك، تستخدم أثينا موصلات مصدر البيانات التي يمكن استخدامها مع الاستفسارات الموحدة. يمكنك اعتبار الموصل بمثابة امتداد لمحرك استعلام Athena. توجد موصلات مصدر بيانات Athena المعدة مسبقًا لمصادر البيانات مثل سجلات الأمازون CloudWatch, الأمازون DynamoDB, Amazon DocumentDB (مع التوافق مع MongoDB)و خدمة قاعدة بيانات الأمازون (Amazon RDS)، ومصادر البيانات الارتباطية المتوافقة مع JDBC مثل MySQL وPostgreSQL بموجب ترخيص Apache 2.0. بعد إعداد اتصال بأي مصدر بيانات، يمكنك استخدام قاعدة التعليمات البرمجية السابقة لتوسيع الحل. لمزيد من المعلومات، راجع استعلم عن أي مصدر بيانات باستخدام الاستعلام الموحد الجديد الخاص بـ Amazon Athena.
تنظيف
لتنظيف الموارد، يمكنك البدء بها تنظيف دلو S3 الخاص بك حيث توجد البيانات. ما لم يستدعي تطبيقك Amazon Bedrock، فلن يتحمل أي تكلفة. من أجل أفضل ممارسات إدارة البنية التحتية، نوصي بحذف الموارد التي تم إنشاؤها في هذا العرض التوضيحي.
وفي الختام
في هذا المنشور، قدمنا حلاً يسمح لك باستخدام البرمجة اللغوية العصبية (NLP) لإنشاء استعلامات SQL معقدة باستخدام مجموعة متنوعة من الموارد التي تتيحها Athena. لقد قمنا أيضًا بزيادة دقة استعلامات SQL التي تم إنشاؤها عبر حلقة تقييم متعددة الخطوات استنادًا إلى رسائل الخطأ الواردة من العمليات النهائية. بالإضافة إلى ذلك، استخدمنا البيانات التعريفية في AWS Glue Data Catalog للنظر في أسماء الجداول المطلوبة في الاستعلام من خلال إطار عمل RAG. قمنا بعد ذلك باختبار الحل في سيناريوهات واقعية مختلفة بمستويات مختلفة من تعقيد الاستعلام. أخيرًا، ناقشنا كيفية تطبيق هذا الحل على مصادر البيانات المختلفة التي تدعمها Athena.
تقع Amazon Bedrock في مركز هذا الحل. يمكن أن تساعدك Amazon Bedrock في إنشاء العديد من تطبيقات الذكاء الاصطناعي المنتجة. للبدء مع Amazon Bedrock، نوصي باتباع البداية السريعة فيما يلي جيثب ريبو والتعرف على بناء تطبيقات الذكاء الاصطناعي المنتجة. يمكنك أيضًا المحاولة قواعد المعرفة في Amazon Bedrock لبناء حلول RAG هذه بسرعة.
حول المؤلف
 سانجيب باندا هو مهندس البيانات وتعلم الآلة في أمازون. من خلال خلفيته في الذكاء الاصطناعي/التعلم الآلي وعلوم البيانات والبيانات الضخمة، يقوم سانجيب بتصميم وتطوير حلول البيانات والتعلم الآلي المبتكرة التي تحل التحديات التقنية المعقدة وتحقق الأهداف الإستراتيجية لبائعي الأطراف الثالثة العالميين الذين يديرون أعمالهم على أمازون. بعيدًا عن عمله كمهندس بيانات وتعلم الآلة في أمازون، يعد سانجيب باندا من عشاق الطعام والموسيقى.
سانجيب باندا هو مهندس البيانات وتعلم الآلة في أمازون. من خلال خلفيته في الذكاء الاصطناعي/التعلم الآلي وعلوم البيانات والبيانات الضخمة، يقوم سانجيب بتصميم وتطوير حلول البيانات والتعلم الآلي المبتكرة التي تحل التحديات التقنية المعقدة وتحقق الأهداف الإستراتيجية لبائعي الأطراف الثالثة العالميين الذين يديرون أعمالهم على أمازون. بعيدًا عن عمله كمهندس بيانات وتعلم الآلة في أمازون، يعد سانجيب باندا من عشاق الطعام والموسيقى.
 بوراك غوزلوكلو هو مهندس حلول متخصص رئيسي في الذكاء الاصطناعي/تعلم الآلة يقع في بوسطن، ماساتشوستس. إنه يساعد العملاء الاستراتيجيين على اعتماد تقنيات AWS وتحديدًا حلول الذكاء الاصطناعي التوليدية لتحقيق أهداف أعمالهم. حصل بوراك على درجة الدكتوراه في هندسة الطيران من جامعة METU، ودرجة الماجستير في هندسة النظم، ودرجة ما بعد الدكتوراه في ديناميكيات النظام من معهد ماساتشوستس للتكنولوجيا في كامبريدج، ماساتشوستس. لا يزال بوراك أحد الباحثين التابعين لمعهد ماساتشوستس للتكنولوجيا. بوراك شغوف باليوجا والتأمل.
بوراك غوزلوكلو هو مهندس حلول متخصص رئيسي في الذكاء الاصطناعي/تعلم الآلة يقع في بوسطن، ماساتشوستس. إنه يساعد العملاء الاستراتيجيين على اعتماد تقنيات AWS وتحديدًا حلول الذكاء الاصطناعي التوليدية لتحقيق أهداف أعمالهم. حصل بوراك على درجة الدكتوراه في هندسة الطيران من جامعة METU، ودرجة الماجستير في هندسة النظم، ودرجة ما بعد الدكتوراه في ديناميكيات النظام من معهد ماساتشوستس للتكنولوجيا في كامبريدج، ماساتشوستس. لا يزال بوراك أحد الباحثين التابعين لمعهد ماساتشوستس للتكنولوجيا. بوراك شغوف باليوجا والتأمل.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/build-a-robust-text-to-sql-solution-generating-complex-queries-self-correcting-and-querying-diverse-data-sources/

